328 奇偶链表
给定一个单链表,把所有的奇数节点和偶数节点分别排在一起。请注意,这里的奇数节点和偶数节点指的是节点编号的奇偶性,而不是节点的值的奇偶性。 请尝试使用原地算法完成。你的算法的空间复杂度应为 O(1),时间复杂度应为 O(nodes),nodes 为节点总数。
示例1:
输入: 1->2->3->4->5->NULL
输出: 1->3->5->2->4->NULL
示例2:
输入: 2->1->3->5->6->4->7->NULL
输出: 2->3->6->7->1->5->4->NULL
代码(c++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* oddEvenList(ListNode* head) {
if(!head||!head->next) return head;
ListNode *h1=head,*h2=head->next,*p=h2->next,*p1=h1,*p2=h2;
int c = 0;
while(p){
if(c){
//奇结点
p2->next = p;
p2=p;
c = 0;
}else{
//偶结点
p1->next = p;
p1 = p;
c = 1;
}
p=p->next;
}
p1->next = h2;
p2->next = NULL;
return h1;
}
};332 重新安排行程
给定一个机票的字符串二维数组 [from, to],子数组中的两个成员分别表示飞机出发和降落的机场地点,对该行程进行重新规划排序。所有这些机票都属于一个从JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 出发。
说明:
- 如果存在多种有效的行程,你可以按字符自然排序返回最小的行程组合。例如,行程 ["JFK", "LGA"] 与 ["JFK", "LGB"] 相比就更小,排序更靠前
- 所有的机场都用三个大写字母表示(机场代码)。
- 假定所有机票至少存在一种合理的行程。
示例1:
输入: [["MUC", "LHR"], ["JFK", "MUC"], ["SFO", "SJC"], ["LHR", "SFO"]]
输出: ["JFK", "MUC", "LHR", "SFO", "SJC"]
示例2:
输入: [["JFK","SFO"],["JFK","ATL"],["SFO","ATL"],["ATL","JFK"],["ATL","SFO"]]
输出: ["JFK","ATL","JFK","SFO","ATL","SFO"]
解释: 另一种有效的行程是 ["JFK","SFO","ATL","JFK","ATL","SFO"]。但是它自然排序更大更靠后。
代码(java)
/**
* 自己做出来了但是效率很低,代码冗长。
* 主要思路
* 先构造图,将所有票中的机场名称加入TreeSet,TreeSet会去重而且排好序
* 然后建立机场名称和排序下标的双向映射,分别以Map和List建立,这样是方便待会进行dfs和图邻接矩阵的建立
* 然后按照dfs回溯,每经过一条路径,将路径上的权值减一,当所有机票都走过后就获取了路线
* 由于邻接矩阵是按照机场名称排序建立的,这样获得的路线一定是字典序最小的
* 最后根据路线记录id将所有机场名称加入结果集
*/
public class Solution {
Stack<Integer> flightRecord = new Stack<>();
int c;
boolean dfs(int[][] matrix,int cur,int count){
if (count==c){
return true;//所有路线已经走完
}
for(int i=0;i<matrix.length;i++){
if (matrix[cur][i]>=1){//dfs回溯
matrix[cur][i]-=1;//这条路线已经走过,消除它
flightRecord.push(i);//记录机场编号
if (dfs(matrix,i,count+1))return true;//这条路已经走通,直接返回
flightRecord.pop();//上面的路走不通,回溯
matrix[cur][i] += 1;
}
}
return false;
}
public List<String> findItinerary(List<List<String>> tickets) {
TreeSet<String> airPorts = new TreeSet<>();
for (List<String> ticket:tickets){
airPorts.addAll(ticket);
}
int idx=0,start=0;
Map<String,Integer> map = new HashMap<>();
List<String>airPortId = new ArrayList<>();
for (String airPort : airPorts) {
map.put(airPort, idx);//机场名称到下标的映射
airPortId.add(airPort);//下标到机场名称的映射,根据id获取机场名即可
if (airPort.equals("JFK")) start=idx;//记录起点
idx++;
}
int[][] matrix = new int[idx][idx];//图的邻接矩阵
for (List<String> ticket:tickets){//建立矩阵
int from = map.get(ticket.get(0)),to = map.get(ticket.get(1));
matrix[from][to] += 1;//会有重复的机票,每经过一次加1
}
c = tickets.size();
flightRecord.push(start);//最开始已经在JFK机场
dfs(matrix,start,0);
List<String> res = new ArrayList<>();
for (Integer id:flightRecord){
res.add(airPortId.get(id));//根据路线记录的id将机场名称按顺序加入结果集
}
return res;
}
}347 前 K 个高频元素
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
- 你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
- 你的算法的时间复杂度必须优于 O(n log n) , n 是数组的大小。
- 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
- 你可以按任意顺序返回答案。
代码(java)
/**
* map记录每个数字出现的次数
* 然后将map以二维数组的形式表示
* 对二维数组排序,比较时按照第二个值即频率比较
* 然后取出频率前k高的
*
* 记录出现次数O(n),排序O(n Log n)
* 总复杂度O(n log n)
*/
class Solution {
public int[] topKFrequent(int[] nums, int k) {
Map<Integer,Integer>map = new HashMap<>();
for(int i:nums){
if(map.containsKey(i)){
map.put(i,map.get(i)+1);
}else{
map.put(i,1);
}
}
int[][] list = new int[map.size()][2];
int i=0;
for (Map.Entry<Integer,Integer> entry:map.entrySet()){
list[i][0]=entry.getKey();
list[i][1]=entry.getValue();
i+=1;
}
Arrays.sort(list, new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
if (o1[1]==o2[1])return 0;
return o1[1]<o2[1]?-1:1;
}
});
int size = list.length;
int[] res = new int[k];
for (int j=0;j<k;j++){
res[j] = list[size-1-j][0];
}
return res;
}
}15 三数之和
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。 注意:答案中不可以包含重复的三元组。
示例:
给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为:
[
[-1, 0, 1],
[-1, -1, 2]
]
代码(python3)
'''
将列表数据排序,然后开始查找
首先确定一个数nums[i],再确定另外两个数,另外两个数按按以下方式寻找。首先给定两个指针,left=i+1,right=len(nums)-1,如果nums[i]+nums[left]+nums[right]<0,则将left指针右移,如果nums[i]+nums[left]+nums[right]>0,则将right指针左移。这样每个nums[i]总能找到与之对应的另外两个数
排序时间复杂度为O(n log n),确定其中一个数为O(n),内部循环确定另外两个数用到了序列有序的性质,只需要O(n),这个总循环为O(n^2),总时间复杂度为O(n^2)
'''
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
nums.sort()
le = len(nums)
i=0
res = []
while i<len(nums)-2 and nums[i]<=0:
if i>0 and nums[i]==nums[i-1]:
i+=1
continue
left = i+1
right = len(nums)-1
while left<right:#左右同时查找
if nums[i]+nums[left]+nums[right]<0:
left+=1
elif nums[i]+nums[left]+nums[right]>0:
right-=1
else:
tr = [nums[i],nums[left],nums[right]]
res.append(tr)
left+=1
while left<right and nums[left]==nums[left-1]:#去重
left+=1
i+=1
return res386 字典序排数
给定一个整数 n, 返回从 1 到 n 的字典顺序。 例如, 给定 n =1 3,返回 [1,10,11,12,13,2,3,4,5,6,7,8,9] 。 请尽可能的优化算法的时间复杂度和空间复杂度。 输入的数据 n 小于等于 5,000,000。
代码(python3)
'''
以n=1000为例
添加顺序为1,10,100,101,102,103...
每次对前一个数乘以10,也就是添加一个0,如果满足小于n则加入结果集,否则将他整除10,再加1,继续判断
'''
class Solution:
def lexicalOrder(self, n: int) -> List[int]:
res = []
cur = 1
for i in range(n):
res.append(cur)
if cur*10<=n:
cur*=10
else:
if cur>=n:
cur//=10
cur+=1
while cur%10==0:
cur//=10
return res;图书馆中每本书都有一个图书编码,可以用于快速检索图书,这个图书编码是一个 正整数。 每位借书的读者手中有一个需求码,这个需求码也是一个正整数。如果一本书的图 书编码恰好以读者的需求码结尾,那么这本书就是这位读者所需要的。 小 D 刚刚当上图书馆的管理员,她知道图书馆里所有书的图书编码,她请你帮她写 一个程序,对于每一位读者,求出他所需要的书中图书编码最小的那本书,如果没有他 需要的书,请输出-1。
输入格式
第一行,包含两个正整数 n , q。n,q,以一个空格分开,分别代表图书馆里 书的数量和读者的数量。
接下来的 n 行,每行包含一个正整数,代表图书馆里某本书的图书编码。
接下来的 q 行,每行包含两个正整数,以一个空格分开,第一个正整数代表图书馆 里读者的需求码的长度,第二个正整数代表读者的需求码。
输出格式
q 行,每行包含一个整数,如果存在第 i 个读者所需要的书,则在第 i 行输出第 i 个读者所需要的书中图书编码最小的那本书的图书编码,否则输出-1。
输入输出样例
输入
5 5
2123
1123
23
24
24
2 23
3 123
3 124
2 12
2 12
输出
23
1123
-1
-1
-1
代码(python3)
def judge(s1,s2):
i = len(s1)-1
j = len(s2)-1
while i>=0 and j>=0 and s1[i]==s2[j]:
i-=1
j-=1
return j<0
n,q = map(int,input().split())
lst = []
for i in range(n):
t = int(input())
lst.append(t)
lst.sort()
res = []
for i in range(q):
le,num= input().split()
f=0
for n in lst:
if judge(str(n),num):
f=1
res.append(n)
break
if f==0:
res.append(-1)
for i in res:
print(i)
删除二叉树结点
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。 一般来说,删除节点可分为两个步骤: 首先找到需要删除的节点; 如果找到了,删除它。 说明: 要求算法时间复杂度为 O(h),h 为树的高度。
示例:
root = [5,3,6,2,4,null,7]
key = 3
5
/ \
3 6
/ \ \
2 4 7
给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。
一个正确的答案是 [5,4,6,2,null,null,7], 如下图所示。
5
/ \
4 6
/ \
2 7
另一个正确答案是 [5,2,6,null,4,null,7]。
5
/ \
2 6
\ \
4 7
代码(python3)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def deleteNode(self, root: TreeNode, key: int) -> TreeNode:
if root == None:
return root
if root.val == key:
if root.left == None:
return root.right
elif root.right == None:
return root.left
else:
node = root.right
while node.left:
node = node.left
node.left = root.left
return root.right
elif root.val > key:
root.left = self.deleteNode(root.left,key);
else:
root.right = self.deleteNode(root.right,key);
return root
583 两个字符串的删除操作
给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。
示例:
输入: "sea", "eat"
输出: 2
解释: 第一步将"sea"变为"ea",第二步将"eat"变为"ea"
代码(python3)
'''
先求出两个串的最长公共子序列,假设其长度为n,那么需要修改的步数就为len1-n+len2-n,即len1+len2-2*n
'''
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
len1 = len(word1)
len2 = len(word2)
dp = [[0]*(len2+1) for i in range(len1+1)]
for i in range(1,len1+1):
for j in range(1,len2+1):
# print(dp[i][j],end=' ')
if word1[i-1]==word2[j-1]:
dp[i][j] = dp[i-1][j-1]+1
else:
dp[i][j] = max(dp[i-1][j],dp[i][j-1])
return len1+len2-2*dp[len1][len2]648 单词替换
在英语中,我们有一个叫做 词根(root)的概念,它可以跟着其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。 现在,给定一个由许多词根组成的词典和一个句子。你需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。 你需要输出替换之后的句子。
示例
输入:dict(词典) = ["cat", "bat", "rat"] sentence(句子) = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"
说明
- 输入只包含小写字母。
- 1 <= dict.length <= 1000
- 1 <= dict[i].length <= 100
- 1 <= 句中词语数 <= 1000
- 1 <= 句中词语长度 <= 1000
- 词根在单词开头处 代码(python3)
class Solution:
def replaceWords(self, dict: List[str], sentence: str) -> str:
res=''
dic = set(dict)
for s in sentence.split():
tlen = 10001
for i in range(len(s)):
if s[0:i+1] in dic and i+1<tlen:
res+=str(s[0:i+1])
tlen = i+1
break
if tlen==10001:
res+=s
res+=' '
return res.strip()1300转变数组后最接近目标值的数组和
给你一个整数数组 arr 和一个目标值 target ,请你返回一个整数 value ,使得将数组中所有大于 value 的值变成 value 后,数组的和最接近 target (最接近表示两者之差的绝对值最小)。 如果有多种使得和最接近 target 的方案,请你返回这些整数中的最小值。 请注意,答案不一定是 arr 中的数字。
示例 1:
输入:arr = [4,9,3], target = 10
输出:3
解释:当选择 value 为 3 时,数组会变成 [3, 3, 3],和为 9 ,这是最接近 target 的方案。
示例2:
输入:arr = [2,3,5], target = 10
输出:5
示例3:
输入:arr = [60864,25176,27249,21296,20204], target = 56803
输出:11361
说明:
- 1 <= arr.length <= 10^4
- 1 <= arr[i], target <= 10^5 代码(python3)
'''
暴力解,先将列表排序,从头开始累加,设累加和为s,当前累加到第i个。每次计算s+(n-i)*arr[i]是否大于等于target,如果已经大于等于target,那么答案一定在arr[i]和arr[i-1]之间,此时退出循环,进一步处理答案。进一步处理直接计算t = (target-s)/(n-i),这个值要么是t,要么是t+1
'''
class Solution:
def findBestValue(self, arr: List[int], target: int) -> int:
arr.sort()
n = len(arr)
if arr[0]*n>=target:
if abs(target//n*n-target)<=abs((target//n+1)*n-target):
return target//n
else:
return target//n+1
else:
s=0
i=0
while i < n and s+(n-i)*arr[i]<target:
s+=arr[i]
i+=1
if i==n:
return arr[n-1]
else:
#print(i,s)
ntar = target-s
l = n-i
#print(ntar,l)
if abs(ntar//l*l-ntar) <= abs((ntar//l+1)*l-ntar):
return ntar//l
else:
return ntar//l+1
501二叉搜索树中的众数
给定一个有相同值的二叉搜索树(BST),找出 BST 中的所有众数(出现频率最高的元素)。
例如: 给定 BST [1,null,2,2],
1
\
2
/
2
返回[2]. 如果众数超过1个,不需考虑输出顺序 代码(python3)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def findMode(self, root: TreeNode) -> List[int]:
res = [] #结果集
if not root:
return res
maxcnt = 0 #出现的最多次数
cnt = 0 #当前数字出现的次数
cur = None #当前数字
stack = []
p = root
while p or stack:
if p:
stack.append(p)
p = p.left
else:
p = stack.pop()
#print(cur)
if p.val==cur:
cnt+=1
else:
if cnt>maxcnt:
maxcnt = cnt
res.clear()
res.append(cur)
elif cnt==maxcnt:
res.append(cur)
cur=p.val
cnt=1
p = p.right
if cnt>maxcnt:
res.clear()
res.append(cur)
elif cnt==maxcnt:
res.append(cur)
return res576出界的路径数
给定一个 m × n 的网格和一个球。球的起始坐标为 (i,j) ,你可以将球移到相邻的单元格内,或者往上、下、左、右四个方向上移动使球穿过网格边界。但是,你最多可以移动 N 次。找出可以将球移出边界的路径数量。答案可能非常大,返回 结果 mod 109 + 7 的值。
示例:
输入: m = 2, n = 2, N = 2, i = 0, j = 0
输出: 6
解释:
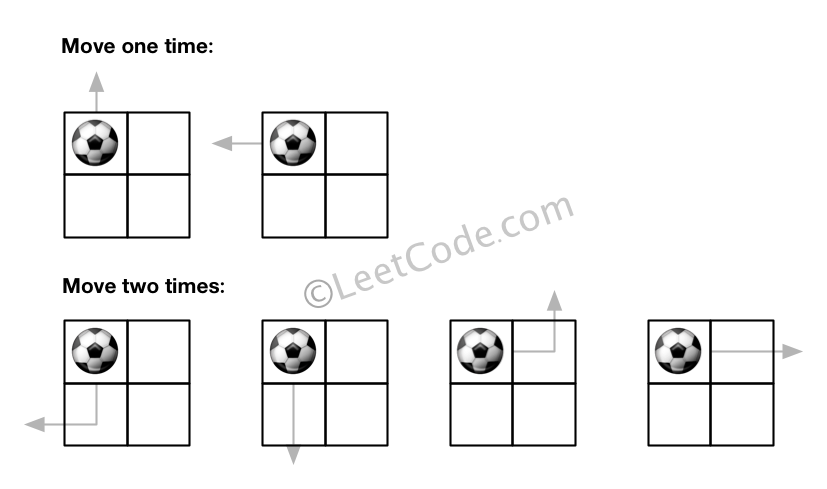
说明:
- 球一旦出界,就不能再被移动回网格内。
- 网格的长度和高度在 [1,50] 的范围内。
- N 在 [0,50] 的范围内。 代码(python3)
'''
#记忆化递归,用book[i][j][k]记录剩余k步,当前坐标为(i,j)时有多少种方法,初始化为-1,当前递归到(i,j,k)时判断book[i][j][k]是否大于0,如果大于0直接返回,这样能够优化深度优先的复杂度,不至于超时
'''
class Solution:
##还剩k步可走,坐标为(i,j),有多少种走法可以出界
def dfs(self,m,n,i,j,k,book):
if i<0 or j<0 or i>=m or j>=n:
return 1
if k<=0:
return 0
if book[i][j][k]>=0:
return book[i][j][k]
steps = self.dfs(m,n,i-1,j,k-1,book)+self.dfs(m,n,i+1,j,k-1,book)+self.dfs(m,n,i,j-1,k-1,book)+self.dfs(m,n,i,j+1,k-1,book);
steps %= 1000000007
book[i][j][k] = steps
return steps
def findPaths(self, m: int, n: int, N: int, i: int, j: int) -> int:
#book[i][j][k]记录还剩k步可以走,当前坐标为(i,j)时,有多少种走法
book = [[[-1]*(N+1) for j in range(n)] for i in range(m)]
return self.dfs(m,n,i,j,N,book)%100000000714 最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 ""。
示例1:
输入: ["flower","flow","flight"]
输出: "fl"
示例2:
输入: ["dog","racecar","car"]
输出: ""
解释: 输入不存在公共前缀。
代码(python3)
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if len(strs)==0:
return ""
res = strs[0]
for i in range(1,len(strs)):
j = 0
while j < min(len(res),len(strs[i])) and strs[i][j]==res[j]:
j+=1
res = res[:j]
return res670 最大交换
给定一个非负整数,你至多可以交换一次数字中的任意两位。返回你能得到的最大值。
示例.
输入: 2736
输出: 7236
解释: 交换数字2和数字7。
输入: 9973
输出: 9973
解释: 不需要交换。
代码(python3
'''
数字逐渐递减一定是最大值。
如果数字能够交换得到更大的数字,这个数可以分为两部分。前半部分数字是递减的(相等也视作递减),出现第一次递增的后面全部是第二部分。只要从后半部分中找到最大的数字,且越靠后越好,把它与前面最大的且小于它的数字交换即可得到答案。
每次循环都为O(n),总体复杂度为O(n)
'''
class Solution:
def maximumSwap(self, num: int) -> int:
i = 1
num = list(str(num))
while i<len(num) and num[i]<=num[i-1]:
i+=1
if i==len(num):
return int("".join(num))
j = i-1
mi = i
while i<len(num):
mi = i if num[i]>=num[mi] else mi
i+=1
f=0
while j>=0 and num[mi]>num[j]:
f=1
j-=1
if f==1:
j+=1
num[j],num[mi] = num[mi],num[j]
return int("".join(num))给你一根长度为n的绳子,请把绳子剪成整数长的m段(m、n都是整数,n>1并且m>1),每段绳子的长度记为k[0],k[1],...,k[m]。请问k[0]xk[1]x...xk[m]可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
输入一个数,输出结果
代码(java)
public class Solution {
/**
*动态规划,设dp[i]是前i米剪完之后能得到的最大乘积,那么
*dp[i] = max(dp[j]*(i-j)),其中1<=j<i
*还有另外一种情况是只剪一刀,即只在j处剪一刀,此时乘积为j*(i-j)
*取两种情况下较大者
*/
public int cutRope(int target) {
int[] dp = new int[target+1];
dp[1]=1;
dp[2]=1;
for(int i=3;i<=target;i++){
for(int j=1;j<i;j++){
dp[i] = Math.max(dp[i],dp[j]*(i-j));
dp[i] = Math.max(dp[i],j*(i-j));
}
}
return dp[target];
}
}请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。路径可以从矩阵中的任意一个格子开始,每一步可以在矩阵中向左,向右,向上,向下移动一个格子。如果一条路径经过了矩阵中的某一个格子,则该路径不能再进入该格子。 例如
a b c c
s f c s
a d e e
矩阵中包含一条字符串"bcced"的路径,但是矩阵中不包含"abcb"路径,因为字符串的第一个字符b占据了矩阵中的第一行第二个格子之后,路径不能再次进入该格子。
代码(java)
public class Solution {
/**
*回溯,每次判断一个字符,走过矩阵中这个地方后把它置为0,返回时
*重新变为原来的字符
*/
int[][] dir = {{0,1},{0,-1},{1,0},{-1,0}};
int rows,cols;
public boolean dfs(char[] matrix,int x,int y,char[] str,int idx){
// System.out.println(x+" "+y);
if (idx == str.length)return true;
char t = matrix[x*cols+y];
matrix[x*cols+y]=0;
for (int i=0;i<4;i++) {
int nrow = x + dir[i][0], ncol = y + dir[i][1];
if (nrow >= 0 && nrow < rows && ncol >= 0 && ncol < cols) {
if (matrix[nrow * cols + ncol] != 0 && matrix[nrow * cols + ncol] == str[idx]) {
if (dfs(matrix, nrow, ncol, str, idx + 1)) return true;
}
}
}
matrix[x*cols+y]=t;
return false;
}
public boolean hasPath(char[] matrix, int rows, int cols, char[] str)
{
this.rows = rows;
this.cols = cols;
for (int i=0;i<rows;i++){
for (int j=0;j<cols;j++){
if (matrix[i*cols+j]==str[0]){
if (dfs(matrix,i,j,str,1))return true;
}
}
}
return false;
}
}1014最佳观光组合
给定正整数数组 A,A[i] 表示第 i 个观光景点的评分,并且两个景点 i 和 j 之间的距离为 j - i。 一对景点(i < j)组成的观光组合的得分为(A[i] + A[j] + i - j):景点的评分之和减去它们两者之间的距离。 返回一对观光景点能取得的最高分。
输入:[8,1,5,2,6]
输出:11
解释:i = 0, j = 2, A[i] + A[j] + i - j = 8 + 5 + 0 - 2 = 11
- 2 <= A.length <= 50000
- 1 <= A[i] <= 1000
代码(python3)
'''
o(n^2)复杂度会超时,使用动态规划。将原得分公式变化为
(A[i]+i) + (A[j]-j).
A[i]+i为左部分最大值,可以记录
'''
class Solution:
def maxScoreSightseeingPair(self, A: List[int]) -> int:
left = A[0]
res = -1
for i in range(1,len(A)):
res = max(res,left+A[i]-i)
left = max(left,A[i]+i)
return res684 冗余连接
在本问题中, 树指的是一个连通且无环的无向图。 输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, ..., N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。 结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v] ,满足 u < v,表示连接顶点u 和v的无向图的边。 返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边 [u, v] 应满足相同的格式 u < v。
示例:
输入: [[1,2], [1,3], [2,3]]
输出: [2,3]
解释: 给定的无向图为:
1
/ \
2 - 3
输入: [[1,2], [2,3], [3,4], [1,4], [1,5]]
输出: [1,4]
解释: 给定的无向图为:
5 - 1 - 2
| |
4 - 3
- 输入的二维数组大小在 3 到 1000。
- 二维数组中的整数在1到N之间,其中N是输入数组的大小。
代码(python3)
'''
使用并查集检查每条边的两个顶点是否已经属于同一个父亲,如果是则直接返回这条边,否则将两者并和,继续向下寻找
'''
class Solution:
def find(self,p,x):
while p[x]!=x:
x = p[x]
return x
def findRedundantConnection(self, edges: List[List[int]]) -> List[int]:
p = [i for i in range(1001)]
for lst in edges:
n1, n2 = lst[0],lst[1]
p1 = self.find(p,n1)
p2 = self.find(p,n2)
if p1==p2:
return lst
else:
p[p1]=p2
return None816 模糊坐标
我们有一些二维坐标,如 "(1, 3)" 或 "(2, 0.5)",然后我们移除所有逗号,小数点和空格,得到一个字符串S。返回所有可能的原始字符串到一个列表中。 原始的坐标表示法不会存在多余的零,所以不会出现类似于"00", "0.0", "0.00", "1.0", "001", "00.01"或一些其他更小的数来表示坐标。此外,一个小数点前至少存在一个数,所以也不会出现“.1”形式的数字。 最后返回的列表可以是任意顺序的。而且注意返回的两个数字中间(逗号之后)都有一个空格。
示例:
输入: "(123)"
输出: ["(1, 23)", "(12, 3)", "(1.2, 3)", "(1, 2.3)"]
输入: "(00011)"
输出: ["(0.001, 1)", "(0, 0.011)"]
解释:
0.0, 00, 0001 或 00.01 是不被允许的。
输入: "(0123)"
输出: ["(0, 123)", "(0, 12.3)", "(0, 1.23)", "(0.1, 23)", "(0.1, 2.3)", "(0.12, 3)"]
输入: "(100)"
输出: [(10, 0)]
解释:
1.0 是不被允许的。
代码(python3)
class Solution:
def fun(self,s):
n = len(s)
res = []
if n==1:
res.append(s)
return res
if s[0]=='0':
if s[n-1]=='0':
return []
else:
res.append(s[0]+'.'+s[1:])
else:
res.append(s)
if s[n-1]=='0':
return res
else:
for i in range(len(s)-1):
res.append(s[:i+1]+'.'+s[i+1:])
return res
def ambiguousCoordinates(self, S: str) -> List[str]:
'''
先用逗号将数字分为两部分,再分别判断两部分可以拆成哪些数字
如果数字开头是0,而且结尾也是0,那么这个数字无效
如果数字开头是0,结尾不是0,它只有一种拆解方法,即0.xxx
如果开头数字不是0,它本身就是一种拆解方法,然后看末尾是不是0,如果末尾是0,那么它不能再拆解,否则,
每个数字之间都可以添加小数点
'''
res = []
for i in range(2,len(S)-1):
r1 = self.fun(S[1:i])
r2 = self.fun(S[i:len(S)-1])
if not r1 or not r2:
continue
for s1 in r1:
for s2 in r2:
res.append('('+s1+', '+s2+')')
return res给你n根火柴棍,你可以拼出多少个形如“A+B=C”的等式?等式中的A、B、C是用火柴棍拼出的整数(若该数非零,则最高位不能是0)。用火柴棍拼数字0-9的拼法如图所示:
注意: 加号与等号各自需要两根火柴棍 如果A≠B,则A+B=C与B+A=C视为不同的等式(A,B,C>=0) n根火柴棍必须全部用上

输入一个整数n(n<=24) 输出一个数表示能拼成的不同等式的数目。
如输入18,输出9
9个等式为:
0+4=4
0+11=11
1+10=11
2+2=4
2+7=9
4+0=4
7+2=9
10+1=11
11+0=11
代码(python3)
'''
因为输入的n小于24,数据量不是很大,可以摆出的最大数字不超过1000.穷举出0-2000的表示需要的火柴棒数,然后查找所有满足条件等式的种数
'''
n = int(input())
n-=4
book = [6,2,5,5,4,5,6,3,7,6]
a = [0]*2001
a[0]=6
for i in range(1,2001):
j = i
while j>0:
a[i]+=book[j%10]
j//=10
#print(a[i],end=' ')
res=0
for i in range(1001):
for j in range(1001):
if a[i]+a[j]+a[i+j]==n:
res+=1
print(res)125验证回文串
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
说明:本题中,我们将空字符串定义为有效的回文串。
示例:
输入: "A man, a plan, a canal: Panama"
输出: true
输入: "race a car"
输出: false
代码(python3)
class Solution:
def isPalindrome(self, s: str) -> bool:
s=s.lower()
i,j=0,len(s)-1
while i<j:
while i<j and not (s[i]>='a' and s[i]<='z') and not(s[i]>='0' and s[i]<='9'):
i+=1
while i<j and not (s[j]>='a' and s[j]<='z') and not(s[j]>='0' and s[j]<='9'):
j-=1
if i>=j:
break
if s[i]!=s[j]:
return False
i+=1
j-=1
return True863 二叉树中所有距离为 K 的结点
给定一个二叉树(具有根结点 root), 一个目标结点 target ,和一个整数值 K 。 返回到目标结点 target 距离为 K 的所有结点的值的列表。 答案可以以任何顺序返回。
示例:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], target = 5, K = 2
输出:[7,4,1]
解释:
所求结点为与目标结点(值为 5)距离为 2 的结点,
值分别为 7,4,以及 1
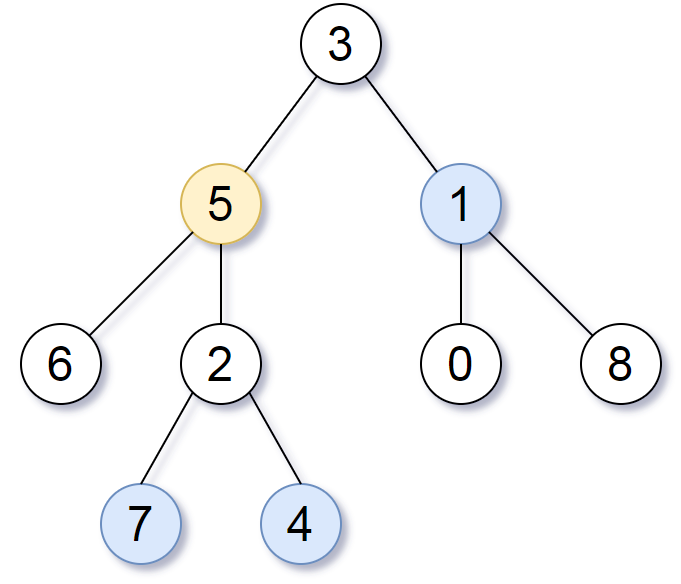
- 给定的树是非空的。
- 树上的每个结点都具有唯一的值 0 <= node.val <= 500 。
- 目标结点 target 是树上的结点。
- 0 <= K <= 1000.
代码(c++)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
map<int,TreeNode*>parents;
void findTarget(TreeNode *root,TreeNode *parent,TreeNode *target){
if(root==NULL){
return;
}
parents[root->val] = parent;
if(root==target)return;
findTarget(root->left,root,target);
findTarget(root->right,root,target);
}
vector<int> distanceK(TreeNode* root, TreeNode* target, int K) {
/**
*把树转换为图,然后进行广度优先遍历
*由于每个结点的子节点可以找到,转换过程中我们只需记录每个结点的父节点即可,
*可以用map记录,以结点值为键,父结点指针为值记录父子关系。
*BFS从target结点开始,进行BFS时先找到当前结点的左右子节点,再到map中找到它的父亲,如果父亲还未遍历,则入队
*/
set<int>book;//记录结点是否已经遍历过
findTarget(root,NULL,target);
vector<int>res;
queue<TreeNode*>q;
q.push(target);
book.insert(target->val);
int dis = 0;//记录距离
while(!q.empty()){
int size = q.size();
if(dis==K)break;
for(int i=0;i<size;i++){
TreeNode *t = q.front();
q.pop();
if(!t)continue;
if(t->left && book.count(t->left->val)==0){//找左孩子
book.insert(t->left->val);
q.push(t->left);
}
if(t->right && book.count(t->right->val)==0){//找右孩子
book.insert(t->right->val);
q.push(t->right);
}
if(parents.count(t->val)){//找父亲
TreeNode *p = parents[t->val];
if(p&&book.count(p->val)==0){
book.insert(p->val);
q.push(p);
}
}
}
dis++;
}
while(!q.empty()){
res.push_back(q.front()->val);
q.pop();
}
return res;
}
};923 三数之和的多种可能
给定一个整数数组 A,以及一个整数 target 作为目标值,返回满足 i < j < k 且 A[i] + A[j] + A[k] == target 的元组 i, j, k 的数量。 由于结果会非常大,请返回 结果除以 10^9 + 7 的余数。
示例:
输入:A = [1,1,2,2,3,3,4,4,5,5], target = 8
输出:20
解释:
按值枚举(A[i],A[j],A[k]):
(1, 2, 5) 出现 8 次;
(1, 3, 4) 出现 8 次;
(2, 2, 4) 出现 2 次;
(2, 3, 3) 出现 2 次。
输入:A = [1,1,2,2,2,2], target = 5
输出:12
解释:
A[i] = 1,A[j] = A[k] = 2 出现 12 次:
我们从 [1,1] 中选择一个 1,有 2 种情况,
从 [2,2,2,2] 中选出两个 2,有 6 种情况。
- 3 <= A.length <= 3000
- 0 <= A[i] <= 100
- 0 <= target <= 300
代码(c++)
class Solution {
public:
int threeSumMulti(vector<int>& A, int target) {
/*
由于A[i]在0-100之间,可以用数组记录0-100之间的数字出现次数,然后选出数字之和为target数字进行组合
每次确定一个数字i,再寻找另外两个数字,这两个数字可以用双指针寻找,复杂度压缩为o(n)。
外部复杂度为o(n),总复杂度为O(n^2)
*/
int mod = 1e9+7,midx = 0,t;
long res=0;
int a[101] = {0};
for(int i=0;i<A.size();i++){
a[A[i]]+=1;
midx = max(midx,A[i]);
}
for(int i=0;i<=target/2+1&&i<=100;i++){
if(a[i]<=0) continue;
if(i*3==target){
if(a[i]>=3){
res=(res+(long)a[i]*(a[i]-1)*(a[i]-2)/6)%mod;
}
}else if(a[i]>=2 && target-i*2>=0 && target-i*2<=100 && a[target-i*2]>0){
res = (res+a[i]*(a[i]-1)/2*a[target-i*2])%mod;
}
int left = i+1,right = midx;
while(left<right){
t = i+left+right;
if(t>target){
right--;
}else if(t<target){
left++;
}else{
res = (res+a[i]*a[left]*a[right])%mod;
left++;
}
}
}
return res;
}
};1052 爱生气的书店老板
今天,书店老板有一家店打算试营业 customers.length 分钟。每分钟都有一些顾客(customers[i])会进入书店,所有这些顾客都会在那一分钟结束后离开。 在某些时候,书店老板会生气。 如果书店老板在第 i 分钟生气,那么 grumpy[i] = 1,否则 grumpy[i] = 0。 当书店老板生气时,那一分钟的顾客就会不满意,不生气则他们是满意的。 书店老板知道一个秘密技巧,能抑制自己的情绪,可以让自己连续 X 分钟不生气,但却只能使用一次。 请你返回这一天营业下来,最多有多少客户能够感到满意的数量。
示例:
输入:customers = [1,0,1,2,1,1,7,5], grumpy = [0,1,0,1,0,1,0,1], X = 3
输出:16
解释:
书店老板在最后 3 分钟保持冷静。
感到满意的最大客户数量 = 1 + 1 + 1 + 1 + 7 + 5 = 16.
代码(python3)
class Solution:
'''
先计算老板在不能控制情绪时感到满意的顾客数量,然后用滑动窗口计算控制情绪后最大能增加多少满意的顾客
'''
def maxSatisfied(self, customers: List[int], grumpy: List[int], X: int) -> int:
n = len(grumpy)
c = 0
add = 0
for i in range(0,n):
c += customers[i] if grumpy[i]==0 else 0
i,j=0,0
while j<X:
add += customers[j] if grumpy[j]==1 else 0
j+=1
t = add
while j<n:
t -= customers[i] if grumpy[i]==1 else 0
i+=1
t += customers[j] if grumpy[j]==1 else 0
j+=1
add = max(add,t)
return c+add1022 从根到叶的二进制数之和
给出一棵二叉树,其上每个结点的值都是 0 或 1 。每一条从根到叶的路径都代表一个从最高有效位开始的二进制数。例如,如果路径为 0 -> 1 -> 1 -> 0 -> 1,那么它表示二进制数 01101,也就是 13 。 对树上的每一片叶子,我们都要找出从根到该叶子的路径所表示的数字。 以 10^9 + 7 为模,返回这些数字之和。
示例:
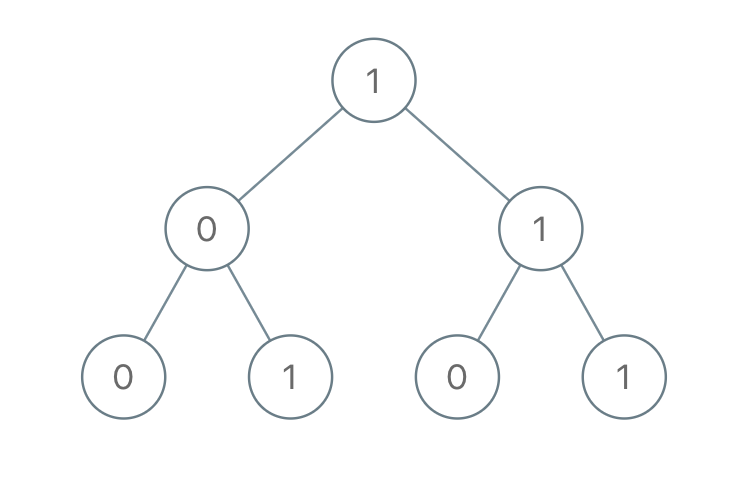
输入:[1,0,1,0,1,0,1]
输出:22
解释:(100) + (101) + (110) + (111) = 4 + 5 + 6 + 7 = 22
代码(c++)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int mod = 1e9+7;
int res=0;
void fun(TreeNode *root,int val){
val = val*2+root->val;
if(root->left==NULL && root->right==NULL){
res = (res+val)%mod;
return;
}
if(root->left)fun(root->left,val);
if(root->right)fun(root->right,val);
}
int sumRootToLeaf(TreeNode* root) {
fun(root,0);
return res;
}
};1023 驼峰式匹配
如果我们可以将小写字母插入模式串 pattern 得到待查询项 query,那么待查询项与给定模式串匹配。(我们可以在任何位置插入每个字符,也可以插入 0 个字符。) 给定待查询列表 queries,和模式串 pattern,返回由布尔值组成的答案列表 answer。只有在待查项 queries[i] 与模式串 pattern 匹配时, answer[i] 才为 true,否则为 false。
示例:
输入:queries = ["FooBar","FooBarTest","FootBall","FrameBuffer","ForceFeedBack"], pattern = "FB"
输出:[true,false,true,true,false]
示例:
"FooBar" 可以这样生成:"F" + "oo" + "B" + "ar"。
"FootBall" 可以这样生成:"F" + "oot" + "B" + "all".
"FrameBuffer" 可以这样生成:"F" + "rame" + "B" + "uffer".
输入:queries = ["FooBar","FooBarTest","FootBall","FrameBuffer","ForceFeedBack"], pattern = "FoBa"
输出:[true,false,true,false,false]
解释:
"FooBar" 可以这样生成:"Fo" + "o" + "Ba" + "r".
"FootBall" 可以这样生成:"Fo" + "ot" + "Ba" + "ll".
代码(python3)
class Solution:
def camelMatch(self, queries: List[str], pattern: str) -> List[bool]:
n,plen = len(queries),len(pattern)
res = [False]*n
for i in range(n):
j,k,f = 0,0,1
while j<plen and k<len(queries[i]):
while k<len(queries[i]) and queries[i][k]!=pattern[j]:
if pattern[j]>='a' and pattern[j]<='z':
if queries[i][k]>='A' and queries[i][k]<='Z':
f=0
break
elif pattern[j]>='A' and pattern[j]<='Z':
if queries[i][k]>='A' and queries[i][k]<='Z' and queries[i][k]!=pattern[j]:
f=0
break
k+=1
if k>=len(queries[i]) or queries[i][k]!=pattern[j]:
f = 0
break
j+=1
k+=1
while k<len(queries[i]):
if queries[i][k]>='A' and queries[i][k]<='Z':
f=0
break
k+=1
if f==1:
res[i] = True
return res 1024 视频拼接
你将会获得一系列视频片段,这些片段来自于一项持续时长为 T 秒的体育赛事。这些片段可能有所重叠,也可能长度不一。 视频片段 clips[i] 都用区间进行表示:开始于 clips[i][0] 并于 clips[i][1] 结束。我们甚至可以对这些片段自由地再剪辑,例如片段 [0, 7] 可以剪切成 [0, 1] + [1, 3] + [3, 7] 三部分。 我们需要将这些片段进行再剪辑,并将剪辑后的内容拼接成覆盖整个运动过程的片段([0, T])。返回所需片段的最小数目,如果无法完成该任务,则返回 -1 。
示例:
输入:clips = [[0,2],[4,6],[8,10],[1,9],[1,5],[5,9]], T = 10
输出:3
解释:
我们选中 [0,2], [8,10], [1,9] 这三个片段。
然后,按下面的方案重制比赛片段:
将 [1,9] 再剪辑为 [1,2] + [2,8] + [8,9] 。
现在我们手上有 [0,2] + [2,8] + [8,10],而这些涵盖了整场比赛 [0, 10]。
输入:clips = [[0,1],[1,2]], T = 5
输出:-1
解释:
我们无法只用 [0,1] 和 [0,2] 覆盖 [0,5] 的整个过程。
输入:clips = [[0,4],[2,8]], T = 5
输出:2
解释:
注意,你可能录制超过比赛结束时间的视频。
代码(python3)
class Solution:
def cmp(self, lst1, lst2):
if lst1[0]<lst2[0]:
return -1
elif lst1[0]>lst2[0]:
return 1
elif lst1[1]<lst2[1]:
return 1
else:
return -1
def videoStitching(self, clips: List[List[int]], T: int) -> int:
'''
将区间按照左端值排序,然后贪心选择使得区间连续而且能够达到的最右区间值
排序O(n log n),选择O(n^2),总复杂度O(n^2)
'''
clips = sorted(clips,key=functools.cmp_to_key(self.cmp))
if clips[0][0]!=0:
return -1
left,right = clips[0][0],clips[0][1]
c,i,le = 1,1,len(clips)
while right<T:
tright = right
idx = -1
for j in range(i,le):
if clips[j][0]>right:
break
if clips[j][0]<=right and clips[j][1]>=tright:
idx = j
tright = clips[j][1]
if idx==-1:
return -1
c+=1
left = clips[idx][0]
right = clips[idx][1]
i = idx+1
if right>=T:
return c
return -11026 节点与其祖先之间的最大差值
给定二叉树的根节点 root,找出存在于不同节点 A 和 B 之间的最大值 V,其中 V = |A.val - B.val|,且 A 是 B 的祖先。 (如果 A 的任何子节点之一为 B,或者 A 的任何子节点是 B 的祖先,那么我们认为 A 是 B 的祖先)
示例:
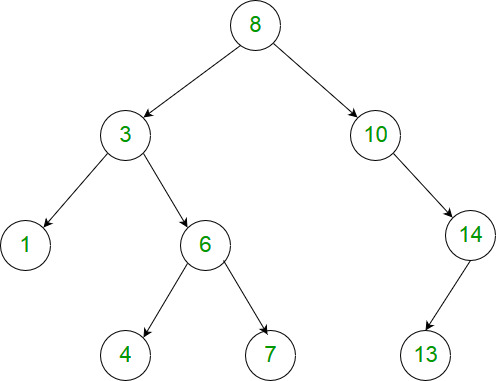
输入:[8,3,10,1,6,null,14,null,null,4,7,13]
输出:7
解释:
我们有大量的节点与其祖先的差值,其中一些如下:
|8 - 3| = 5
|3 - 7| = 4
|8 - 1| = 7
|10 - 13| = 3
在所有可能的差值中,最大值 7 由 |8 - 1| = 7 得出。
代码(python3)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def dfs(self,root,maxv,minv):
if not root:
return 0
maxv = max(maxv,root.val)
minv = min(minv,root.val)
if not root.left and not root.right:
return maxv-minv
return max(self.dfs(root.left,maxv,minv),self.dfs(root.right,maxv,minv))
def maxAncestorDiff(self, root: TreeNode) -> int:
return max(self.dfs(root.left,root.val,root.val),self.dfs(root.right,root.val,root.val)) 67 二进制求和
给你两个二进制字符串,返回它们的和(用二进制表示)。 输入为 非空 字符串且只包含数字 1 和 0。
示例 1:
输入: a = "11", b = "1"
输出: "100"
代码(java)
class Solution {
public String addBinary(String a, String b) {
StringBuilder sb = new StringBuilder();
int len1 = a.length(),len2 = b.length();
int i = len1-1,j = len2-1,n1,n2,carry=0;
while(i>=0||j>=0||carry!=0){
n1 = i>=0 ? a.charAt(i)-'0':0;
n2 = j>=0 ? b.charAt(j)-'0':0;
sb.append((n1 + n2 + carry) % 2);
carry = (n1+n2+carry)/2;
i--;
j--;
}
return sb.reverse().toString();
}
}1030 距离顺序排列矩阵单元格
给出 R 行 C 列的矩阵,其中的单元格的整数坐标为 (r, c),满足 0 <= r < R 且 0 <= c < C。 另外,我们在该矩阵中给出了一个坐标为 (r0, c0) 的单元格。 返回矩阵中的所有单元格的坐标,并按到 (r0, c0) 的距离从最小到最大的顺序排,其中,两单元格(r1, c1) 和 (r2, c2) 之间的距离是曼哈顿距离,|r1 - r2| + |c1 - c2|。(你可以按任何满足此条件的顺序返回答案。)
示例 :
输入:R = 1, C = 2, r0 = 0, c0 = 0
输出:[[0,0],[0,1]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1]
输入:R = 2, C = 2, r0 = 0, c0 = 1
输出:[[0,1],[0,0],[1,1],[1,0]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2]
[[0,1],[1,1],[0,0],[1,0]] 也会被视作正确答案。
代码(java)
class Solution {
class Point{
int x,y;
public Point(int x,int y){
this.x = x;
this.y = y;
}
}
public int[][] allCellsDistOrder(int R, int C, int r0, int c0) {
//简单bfs
int[][] res = new int[R*C][2];
int[][] book = new int[R][C];
int[][] dir = {{-1,0},{1,0},{0,1},{0,-1}};
int k=0;
Queue<Point> queue = new LinkedList<>();
queue.offer(new Point(r0,c0));
book[r0][c0]=1;
while (!queue.isEmpty()){
int size = queue.size();
for (int i=0;i<size;i++){
Point p = queue.poll();
res[k][0] = p.x;
res[k++][1] = p.y;
for (int j=0;j<4;j++){
int nrow = p.x+dir[j][0],ncol=p.y+dir[j][1];
if (nrow>=0 && nrow<R && ncol>=0 && ncol<C){
if (book[nrow][ncol]==0){
book[nrow][ncol] = 1;
queue.offer(new Point(nrow,ncol));
}
}
}
}
}
return res;
}
}16 最接近的三数之和
给定一个包括 n 个整数的数组 nums 和 一个目标值 target。找出 nums 中的三个整数,使得它们的和与 target 最接近。返回这三个数的和。假定每组输入只存在唯一答案。
示例:
输入:nums = [-1,2,1,-4], target = 1
输出:2
解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2) 。
- 3 <= nums.length <= 10^3
- -10^3 <= nums[i] <= 10^3
- -10^4 <= target <= 10^4
代码(java)
class Solution {
public int threeSumClosest(int[] nums, int target) {
Arrays.sort(nums);
int res = nums[0]+nums[1]+nums[2];
int left,right,sum;
for (int i=0;i<nums.length;i++){
left = i+1;
right=nums.length-1;
while(left<right){
sum = nums[i]+nums[left]+nums[right];
if(Math.abs(sum-target)<Math.abs(res-target)){
res = sum;
}
if (sum>target){
right--;
}else if(sum<target){
left++;
}else{
return target;
}
}
}
return res;
}
}1031 两个非重叠子数组的最大和
给出非负整数数组 A ,返回两个非重叠(连续)子数组中元素的最大和,子数组的长度分别为 L 和 M。(这里需要澄清的是,长为 L 的子数组可以出现在长为 M 的子数组之前或之后。) 从形式上看,返回最大的 V,而 V = (A[i] + A[i+1] + ... + A[i+L-1]) + (A[j] + A[j+1] + ... + A[j+M-1]) 并满足下列条件之一:
- 0 <= i < i + L - 1 < j < j + M - 1 < A.length,
- 0 <= j < j + M - 1 < i < i + L - 1 < A.length
示例:
输入:A = [0,6,5,2,2,5,1,9,4], L = 1, M = 2
输出:20
解释:子数组的一种选择中,[9] 长度为 1,[6,5] 长度为 2。
输入:A = [3,8,1,3,2,1,8,9,0], L = 3, M = 2
输出:29
解释:子数组的一种选择中,[3,8,1] 长度为 3,[8,9] 长度为 2。
输入:A = [2,1,5,6,0,9,5,0,3,8], L = 4, M = 3
输出:31
解释:子数组的一种选择中,[5,6,0,9] 长度为 4,[0,3,8] 长度为 3。
- L >= 1
- M >= 1
- L + M <= A.length <= 1000
- 0 <= A[i] <= 1000
代码(java)
class Solution {
public int maxSumTwoNoOverlap(int[] A, int L, int M) {
/**
* 先求得数组的前缀和,然后暴力穷举所有结果
*/
int n = A.length;
int[] sum = new int[n+1];
for (int i=1;i<=n;i++){
sum[i]=sum[i-1]+A[i-1];
}
int res = Integer.MIN_VALUE;
for (int i=1;i<=n-1;i++){
for (int j=i+1;j<=n;j++){
if (i>=L && j-i>=M){
res = Math.max(sum[i]-sum[i-L]+sum[j]-sum[j-M],res);
}
if (i>=M && j-i>=L){
res = Math.max(sum[i]-sum[i-M]+sum[j]-sum[j-L],res);
}
}
}
return res;
}
}139 单词拆分
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。 拆分时可以重复使用字典中的单词。 你可以假设字典中没有重复的单词。
示例 :
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。
注意你可以重复使用字典中的单词。
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
输出: false
代码(java)
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
//为了加快字符串的查找速度可以将字典中的字符加入Set
//用动态规划判断字符是否可以有字典中的单词拼接而成,dp[i]=1代表前i个字符是否可以拼接
//dp[i] = 1 if s[j:i] in wordsDict,其中0<=j<i
Set<String> words = new HashSet<>(wordDict);
int[] dp = new int[s.length()+1];
dp[0] = 1;
for (int i=1;i<=s.length();i++){
for (int j=0;j<i;j++){
if (dp[j]==1&&words.contains(s.substring(j,i))){
dp[i]=1;
break;
}
}
}
return dp[s.length()]==1;
}
}1035 不相交的线
我们在两条独立的水平线上按给定的顺序写下 A 和 B 中的整数。 现在,我们可以绘制一些连接两个数字 A[i] 和 B[j] 的直线,只要 A[i] == B[j],且我们绘制的直线不与任何其他连线(非水平线)相交。 以这种方法绘制线条,并返回我们可以绘制的最大连线数。
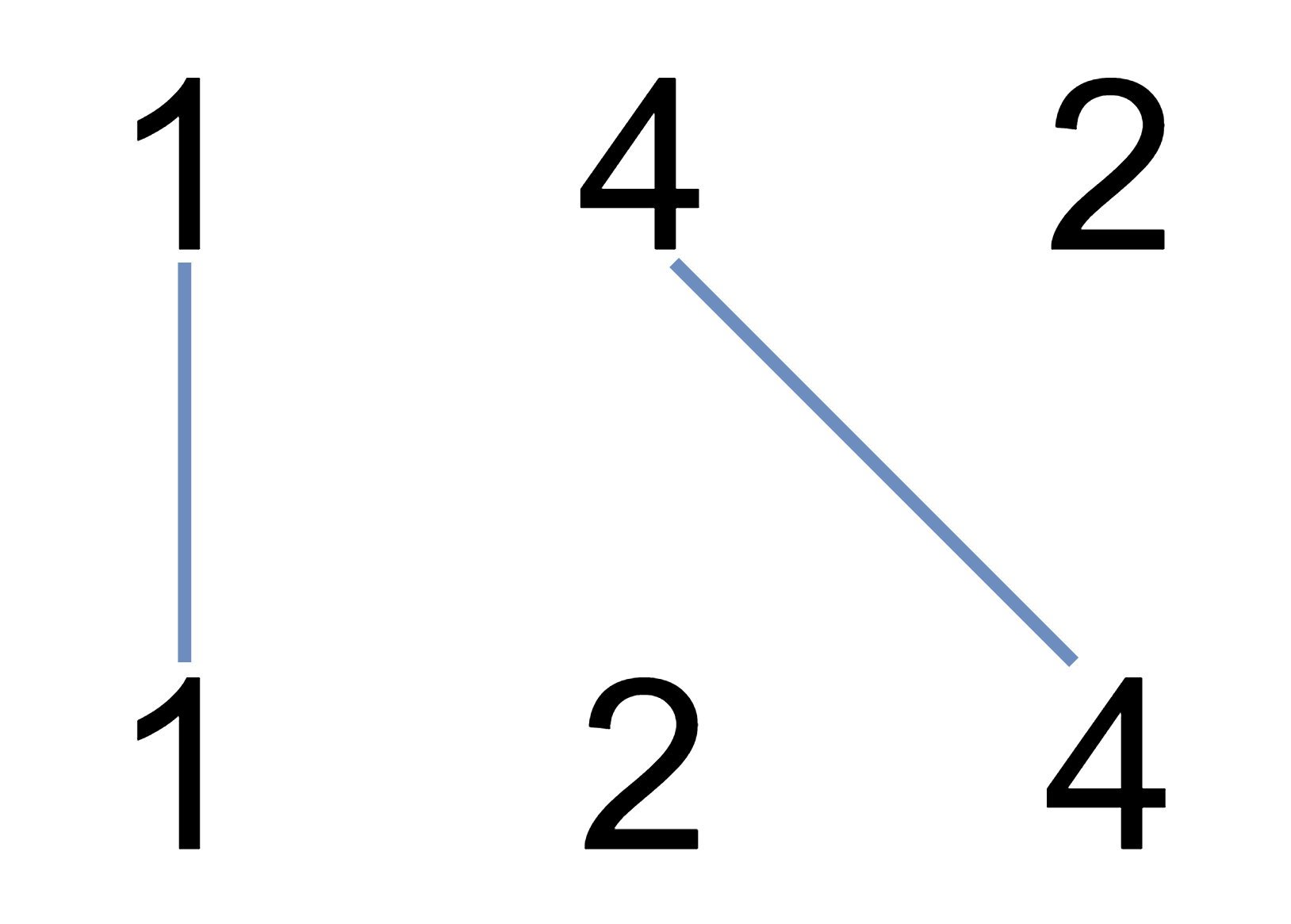
输入:A = [1,4,2], B = [1,2,4]
输出:2
解释:
我们可以画出两条不交叉的线,如上图所示。
我们无法画出第三条不相交的直线,因为从 A[1]=4 到 B[2]=4 的直线将与从 A[2]=2 到 B[1]=2 的直线相交。
输入:A = [2,5,1,2,5], B = [10,5,2,1,5,2]
输出:3
代码(java)
class Solution {
public int maxUncrossedLines(int[] A, int[] B) {
/**
* 可以这样想,既然连完线后他们不想交,我们可以把连线的两个数字移动对齐
* 这样其实就是求两个串的最长公共子串,动态规划即可
*/
int[][] dp = new int[A.length+1][B.length+1];
for (int i=1;i<=A.length;i++){
for (int j=1;j<=B.length;j++){
if (A[i-1]==B[j-1]){
dp[i][j] = dp[i-1][j-1]+1;
}else{
dp[i][j] = Math.max(dp[i-1][j],dp[i][j-1]);
}
}
}
return dp[A.length][B.length];
}
}1037 有效的回旋镖
回旋镖定义为一组三个点,这些点各不相同且不在一条直线上。 给出平面上三个点组成的列表,判断这些点是否可以构成回旋镖。
示例
输入:[[1,1],[2,3],[3,2]]
输出:true
输入:[[1,1],[2,2],[3,3]]
输出:false
代码(python3)
class Solution:
def isBoomerang(self, points: List[List[int]]) -> bool:
'''
三个点可以得到两个向量,判断向量是否平行即可
若向量a(x1,y1),b(x2,y2)平行,有a=kb,则x1*y2=y1*x2
'''
a1 = [points[1][0]-points[0][0],points[1][1]-points[0][1]]
a2 = [points[2][0]-points[1][0],points[2][1]-points[1][1]]
return a1[0]*a2[1]!=a1[1]*a2[0]编写代码,移除未排序链表中的重复节点。保留最开始出现的节点。
示例
输入:[1, 2, 3, 3, 2, 1]
输出:[1, 2, 3]
输入:[1, 1, 1, 1, 2]
输出:[1, 2]
代码·(python3)
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def removeDuplicateNodes(self, head: ListNode) -> ListNode:
if not head:
return head
book = set()
p = ListNode(0)
r = p
p.next = head
q = head
while q:
while q and q.val in book:
q = q.next
if q:
book.add(q.val)
p.next = q
p=q
q = q.next if q else None
return r.next1041 困于环中的机器人
在无限的平面上,机器人最初位于 (0, 0) 处,面朝北方。机器人可以接受下列三条指令之一: "G":直走 1 个单位, "L":左转 90 度 ,"R":右转 90 度 机器人按顺序执行指令 instructions,并一直重复它们。 只有在平面中存在环使得机器人永远无法离开时,返回 true。否则,返回 false。
示例
输入:"GGLLGG"
输出:true
解释:
机器人从 (0,0) 移动到 (0,2),转 180 度,然后回到 (0,0)。
重复这些指令,机器人将保持在以原点为中心,2 为半径的环中进行移动。
输入:"GG"
输出:false
解释:
机器人无限向北移动。
输入:"GL"
输出:true
解释:
机器人按 (0, 0) -> (0, 1) -> (-1, 1) -> (-1, 0) -> (0, 0) -> ... 进行移动。
- 1 <= instructions.length <= 100
- instructions[i] 在 {'G', 'L', 'R'} 中
代码(python3)
class Solution:
def isRobotBounded(self, instructions: str) -> bool:
'''
如果一轮指令后机器人回到了原点,那么它肯定是循环的,无法离开这个环
如果一轮指令后机器人没有回到原点,这时判断它的方向是否仍然指向北方,如果指向北方,那下一轮指令机器人还会
往北方走,这么一来它会无限往北方走。而一轮指令过后机器人指向其他方向,那经过四轮指令过后,机器人肯定会回
到原点,而且它的行动轨迹是一个正方形
'''
dire,x,y = 0,0,0
for ins in instructions:
if ins == 'G':
if dire==0:
y+=1
elif dire==1:
x+=1
elif dire==2:
y-=1
else:
x-=1
elif ins=='L':
dire = dire-1 if dire>0 else 3
else:
dire = (dire+1)%4
return (x==0 and y==0) or (dire!=0)1042 不邻接植花
有 N 个花园,按从 1 到 N 标记。在每个花园中,你打算种下四种花之一。 paths[i] = [x, y] 描述了花园 x 到花园 y 的双向路径。 另外,没有花园有 3 条以上的路径可以进入或者离开。 你需要为每个花园选择一种花,使得通过路径相连的任何两个花园中的花的种类互不相同。 以数组形式返回选择的方案作为答案 answer,其中 answer[i] 为在第 (i+1) 个花园中种植的花的种类。花的种类用 1, 2, 3, 4 表示。保证存在答案。
示例
输入:N = 3, paths = [[1,2],[2,3],[3,1]]
输出:[1,2,3]
输入:N = 4, paths = [[1,2],[3,4]]
输出:[1,2,1,2]
输入:N = 4, paths = [[1,2],[2,3],[3,4],[4,1],[1,3],[2,4]]
输出:[1,2,3,4]
- 1 <= N <= 10000
- 0 <= paths.size <= 20000
- 不存在花园有 4 条或者更多路径可以进入或离开。
- 保证存在答案。 代码(python3)
class Solution:
def gardenNoAdj(self, N: int, paths: List[List[int]]) -> List[int]:
'''
本题以邻接矩阵建图会超出内存,要使用邻接表建立,题目意思相当于为结点染色
遍历图中结点,再遍历一遍该结点的邻接结点,并记录其邻接结点的颜色
由于一个结点最多有三个邻接结点,而我们有四种颜色可以选择,所以总会用一种颜色还没有被邻接结点使用
选择为使用的颜色为该结点颜色
'''
book = [0,0,0,0]
graph = [[]for i in range(N)]
res = [0 for i in range(N)]
for pos in paths:
graph[pos[0]-1].append(pos[1]-1)
graph[pos[1]-1].append(pos[0]-1)
for i in range(N):
if res[i]!=0:
continue
book = [0,0,0,0]
for j in graph[i]:
if res[j]!=0:
book[res[j]-1]=1
for j in range(4):
if book[j]==0:
color = j
break
res[i] = color+1
return res1047 删除字符串中的所有相邻重复项
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。 在 S 上反复执行重复项删除操作,直到无法继续删除。 在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:
输入:"abbaca"
输出:"ca"
解释:
例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。
class Solution:
def removeDuplicates(self, S: str) -> str:
stack = []
for s in S:
if len(stack)>0 and stack[-1]==s:
stack.pop()
else:
stack.append(s)
return ''.join(stack)209 长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的连续子数组,并返回其长度。如果不存在符合条件的连续子数组,返回 0。
示例:
输入: s = 7, nums = [2,3,1,2,4,3]
输出: 2
解释: 子数组 [4,3] 是该条件下的长度最小的连续子数组。
代码(python3)
class Solution:
def minSubArrayLen(self, s: int, nums: List[int]) -> int:
#典型滑动窗口
n, c = len(nums), 0
left,right = 0,0,
res = 0x7fffffff
while right<n:
while right<n and c<s:
c+=nums[right]
right+=1
while c>=s:
c-=nums[left]
left+=1
res = min(right-left+1,res)
return res if res<=n else 01053 交换一次的先前排列
给你一个正整数的数组 A(其中的元素不一定完全不同),请你返回可在 一次交换(交换两数字 A[i] 和 A[j] 的位置)后得到的、按字典序排列小于 A 的最大可能排列。 如果无法这么操作,就请返回原数组。
示例:
输入:[3,2,1]
输出:[3,1,2]
解释:
交换 2 和 1
输入:[1,1,5]
输出:[1,1,5]
解释:
这已经是最小排列
输入:[1,9,4,6,7]
输出:[1,7,4,6,9]
解释:
交换 9 和 7
- 1 <= A.length <= 10000
- 1 <= A[i] <= 10000
代码(python3)
class Solution:
def prevPermOpt1(self, A: List[int]) -> List[int]:
'''
为了能使得找到的结果恰好字典序比原值大,要从后往前找
找到第一个下标,有A[i]>A[i+1],这个A[i]必定是要交换到后面去的
为了使得交换后的字典序最大,被交换的数字要尽可能大而且小于A[i]
'''
n = len(A)
i = n-2
while i>=0:
if A[i]>A[i+1]:
break
i-=1
if i<0:
return A
j = i
i+=1
c=i
while i<n:
if A[c]<A[i]<A[j]:
c=i
i+=1
A[j],A[c]=A[c],A[j]
return A215 数组中的第K个最大元素
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
代码(python3)
class Solution:
def quick_sort(self,nums,l,r,k):
pivot = nums[l]
left,right = l,r
while left<right:
while left<right and nums[right]<=pivot:
right-=1
nums[left] = nums[right]
while left<right and nums[left]>=pivot:
left+=1
nums[right]=nums[left]
nums[left]=pivot
if left==k-1:
return nums[left]
elif left>k-1:
return self.quick_sort(nums,l,left-1,k)
else:
return self.quick_sort(nums,left+1,r,k)
def findKthLargest(self, nums: List[int], k: int) -> int:
'''
基于快速排序的**,分治算法
实际上并没有库函数快
'''
return self.quick_sort(nums,0,len(nums)-1,k)
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
代码(python3)
class CQueue:
'''
stack1做队尾,stack2做队头,出队时如果stack2有值就从stack2栈顶弹出一个元素
如果stack2没有值,判断stack1是否有值,stack1没有值说明队列为空,返回-1,否则
将stack1里的元素全部弹出并入栈到stack2,然后从stack2栈顶弹出一个值即出队
'''
def __init__(self):
self.stack1 = []
self.stack2= []
def appendTail(self, value: int) -> None:
self.stack1.append(value)
def deleteHead(self) -> int:
if len(self.stack2)>0:
return self.stack2.pop()
else:
if len(self.stack1)==0:
return -1
else:
while len(self.stack1)>0:
self.stack2.append(self.stack1.pop())
return self.stack2.pop()
# Your CQueue object will be instantiated and called as such:
# obj = CQueue()
# obj.appendTail(value)
# param_2 = obj.deleteHead()1047 元素和为目标值的子矩阵数量
给出矩阵 matrix 和目标值 target,返回元素总和等于目标值的非空子矩阵的数量。 子矩阵 x1, y1, x2, y2 是满足 x1 <= x <= x2 且 y1 <= y <= y2 的所有单元 matrix[x][y] 的集合。 如果 (x1, y1, x2, y2) 和 (x1', y1', x2', y2') 两个子矩阵中部分坐标不同(如:x1 != x1'),那么这两个子矩阵也不同。
示例:
输入:matrix = [[0,1,0],[1,1,1],[0,1,0]], target = 0
输出:4
解释:四个只含 0 的 1x1 子矩阵。
输入:matrix = [[1,-1],[-1,1]], target = 0
输出:5
解释:两个 1x2 子矩阵,加上两个 2x1 子矩阵,再加上一个 2x2 子矩阵。
- 1 <= matrix.length <= 300
- 1 <= matrix[0].length <= 300
- -1000 <= matrix[i] <= 1000
- -10^8 <= target <= 10^8
代码(python3)
class Solution:
def numSubmatrixSumTarget(self, matrix: List[List[int]], target: int) -> int:
'''
参考最大子矩阵之和的解法,遍历所有子矩阵,不过遍历时子矩阵之和可以使用前缀和的形式稍微加速子矩阵之和的计算
这个解法实际上复杂度非常高,应该为O(r*r*(2c+c*c)),即O(r^2*c^2),最后一个测试用例超时,作弊通过
'''
if target==500:
return 27539
rows,cols = len(matrix),len(matrix[0])
res = 0
for i in range(rows):# i为表示从某一行为起始行
dp = [0]*cols
for j in range(i,rows):# 由第i行开始,加到第j行
for k in range(0,cols): # 每一列单独由上至下分别相加,计算他们的前缀和
dp[k]+=matrix[j][k]
tarray = copy.deepcopy(dp) #//每一次对所有列求完和后判断一次子矩阵,为了不改变原有数组,拷贝一份
tsum = [0]*cols #求个列之和的前缀和,由于这些列已经加上了上面行的数字,实际上就是子矩阵之和
tsum[0]=tarray[0]
for k in range(1,cols):
tsum[k]+=tsum[k-1]+tarray[k]
# 接下来每次选两个列坐标,判断子矩阵之和是否等于target
for p in range(0,cols):
for q in range(p,cols):
if tsum[q]-tsum[p]+tarray[p]==target:
res+=1
return res718 最长重复子数组
给两个整数数组 A 和 B ,返回两个数组中公共的、长度最长的子数组的长度。
示例 :
输入:
A: [1,2,3,2,1]
B: [3,2,1,4,7]
输出: 3
解释:
长度最长的公共子数组是 [3, 2, 1]。
代码(python3)
class Solution:
def findLength(self, A: List[int], B: List[int]) -> int:
n1,n2,res=len(A),len(B),0
dp = [[0]*(n2+1) for i in range(n1+1)]
for i in range(1,n1+1):
for j in range(1,n2+1):
dp[i][j] = dp[i-1][j-1]+1 if A[i-1]==B[j-1] else 0
res = max(dp[i][j],res)
return res- 1 <= len(A), len(B) <= 1000
- 0 <= A[i], B[i] < 100
红茶? 代码(python3)
input()
a = list(map(int,input().split()))
k = int(input())
a.sort()
f,s = True,set(a)
for n in a:
if k-n in s and n<k-n:
print(n,k-n)
f = False
if f:
print('NO')378 有序矩阵中第K小的元素
给定一个 n x n 矩阵,其中每行和每列元素均按升序排序,找到矩阵中第 k 小的元素。 请注意,它是排序后的第 k 小元素,而不是第 k 个不同的元素。 1<=k<=n^2
示例:
matrix = [
[ 1, 5, 9],
[10, 11, 13],
[12, 13, 15]
],
k = 8,
返回 13。
代码(python3)
class Solution:
def kthSmallest(self, matrix: List[List[int]], k: int) -> int:
'''
把矩阵每一行视为一个列表,将这些列表归并,归并到第k个元素时退出
时间复杂度O(k*n),用一个数组记录每一个列表归并的下标,空间复杂度O(n)
'''
n = len(matrix)
idx = [0 for i in range(n)]
cnt,res = 0,matrix[0][0]
while cnt<k:
t = 0
minv = 0x7fffffff
for i in range(n):
if idx[i]<n and matrix[i][idx[i]]<minv:
t = i
minv = matrix[i][idx[i]]
res = minv
idx[t]+=1
cnt+=1
return res1078 Bigram 分词
给出第一个词 first 和第二个词 second,考虑在某些文本 text 中可能以 "first second third" 形式出现的情况,其中 second 紧随 first 出现,third 紧随 second 出现。 对于每种这样的情况,将第三个词 "third" 添加到答案中,并返回答案。
示例 :
输入:text = "alice is a good girl she is a good student", first = "a", second = "good"
输出:["girl","student"]
输入:text = "we will we will rock you", first = "we", second = "will"
输出:["we","rock"]
代码(python3)
class Solution:
def findOcurrences(self, text: str, first: str, second: str) -> List[str]:
words = text.split()
res = []
for i in range(len(words)-2):
if words[i]==first and words[i+1]==second:
res.append(words[i+2])
return res108 将有序数组转换为二叉搜索树
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。 本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
示例:
给定有序数组: [-10,-3,0,5,9],
一个可能的答案是:[0,-3,9,-10,null,5],它可以表示下面这个高度平衡二叉搜索树:
0
/ \
-3 9
/ /
-10 5
代码(python3)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def create(self,nums,left,right):
if left>right:return None
mid = (left+right)//2
node = TreeNode(nums[mid])
left = self.create(nums,left,mid-1)
right = self.create(nums,mid+1,right)
node.left=left
node.right=right
return node
def sortedArrayToBST(self, nums: List[int]) -> TreeNode:
return self.create(nums,0,len(nums)-1)1079 活字印刷
你有一套活字字模 tiles,其中每个字模上都刻有一个字母 tiles[i]。返回你可以印出的非空字母序列的数目。 注意:本题中,每个活字字模只能使用一次。
示例
输入:"AAB"
输出:8
解释:可能的序列为 "A", "B", "AA", "AB", "BA", "AAB", "ABA", "BAA"。
输入:"AAABBC"
输出:188
- 1 <= tiles.length <= 7
- tiles 由大写英文字母组成
代码(python3)
class Solution:
def __init__(self):
self.res=0
self.book = set()
def back_track(self,tiles,lenth,curlen,curstr,visited):
if lenth==curlen:
if curstr not in self.book:
self.res+=1
self.book.add(curstr)
return
for i in range(0,len(tiles)):
if visited[i]==0:
visited[i]=1
self.back_track(tiles,lenth,curlen+1,curstr+tiles[i],visited)
visited[i]=0
def numTilePossibilities(self, tiles: str) -> int:
'''
由于字符串很短,可以深度优先遍历所有结果,并用set去重
'''
n = len(tiles)
visited = [0]*n
for i in range(1,n+1):
self.back_track(tiles,i,0,'',visited)
return self.res
############################################################
# 另一种高效的方法是直接记录可用的字母个数,然乎回溯遍历,这样可以免掉去重操作
class Solution:
def numTilePossibilities(self, tiles: str) -> int:
book = [0]*26
for a in tiles:
book[ord(a)-ord('A')]+=1
def dfs(book):
res = 0
for i in range(26):
if book[i]==0:
continue
res+=1
book[i]-=1
res+=dfs(book)
book[i]+=1
return res
return dfs(book)1081 不同字符的最小子序列
返回字符串 text 中按字典序排列最小的子序列,该子序列包含 text 中所有不同字符一次。
示例
输入:"cdadabcc"
输出:"adbc"
输入:"abcd"
输出:"abcd"
输入:"ecbacba"
输出:"eacb"
输入:"leetcode"
输出:"letcod"
- 1 <= text.length <= 1000
- text 由小写英文字母组成
代码(python3)
class Solution:
def smallestSubsequence(self, text: str) -> str:
'''
字典序最小一定是按字符升序排列的
因此遍历字符串,并将字符串各个字符入栈。
如果当前字符在之前已经出现过且已经在栈里。那当前字符就是要舍弃的
否则,不停检查栈顶字符,如果栈顶字符比当前字符要大,而且字符串后面还会出现栈顶字符,那么当前栈顶字符肯定可
以在后面的遍历中再次遇到,而且添加在当前字符的后面,也就是升序排列,因此将栈顶字符出栈
'''
n = len(text)
stack = []
for i in range(len(text)):
if text[i] in stack:
continue
while stack and stack[-1]>text[i] and text.find(stack[-1],i)!=-1:
stack.pop()
stack.append(text[i])
return ''.join(stack)44 通配符匹配
给定一个字符串 (s) 和一个字符模式 (p) ,实现一个支持 '?' 和 '' 的通配符匹配。 '?' 可以匹配任何单个字符。 '' 可以匹配任意字符串(包括空字符串)。 两个字符串完全匹配才算匹配成功。 s 可能为空,且只包含从 a-z 的小写字母。 p 可能为空,且只包含从 a-z 的小写字母,以及字符 ? 和 *。
示例:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
输入:
s = "aa"
p = "*"
输出: true
解释: '*' 可以匹配任意字符串。
输入:
s = "cb"
p = "?a"
输出: false
解释: '?' 可以匹配 'c', 但第二个 'a' 无法匹配 'b'。
输入:
s = "adceb"
p = "*a*b"
输出: true
解释: 第一个 '*' 可以匹配空字符串, 第二个 '*' 可以匹配字符串 "dce".
代码(python3)
class Solution:
def isMatch(self, s: str, p: str) -> bool:
'''
dp[i][j]表示s[0:i]和p[0:j]是否匹配
先初始化dp方程,空字符串肯定是匹配的,因此dp[0][0]=True,如果模式串第一个字符是*,可以无限向前匹配,直到遇到第一个不是*的字符
根据模式串p当前字符确定动态方程当前的值。
如果当前字符是*,那它可以为空字符,或者匹配任意字符,只要s[0:i-1],p[0:j-1]匹配,那p[0:j]肯定可以和s[0:i]匹配
如果当前字符是?那它可以变为s[i],即和s[i]相等,所以?和s[i]==p[j]是等效的,只有当s[0:i-1]和p[0:j-1]匹配时,加上这个字符他们才匹配
其他情况s[0:i]和p[0:j]不匹配
'''
len1,len2 = len(s),len(p)
dp = [[False]* (len2+1) for i in range(len1+1)]
for i in range(1,len2+1):
if p[i-1]=='*':dp[0][i]=True
else:break
dp[0][0] = True
for i in range(1,len1+1):
for j in range(1,len2+1):
if p[j-1]=='*':
dp[i][j] = dp[i-1][j] or dp[i][j-1]
elif p[j-1]=='?' or s[i-1]==p[j-1]:
dp[i][j] = dp[i-1][j-1]
return dp[len1][len2]1091 二进制矩阵中的最短路径
在一个 N × N 的方形网格中,每个单元格有两种状态:空(0)或者阻塞(1)。 一条从左上角到右下角、长度为 k 的畅通路径,由满足下述条件的单元格 C_1, C_2, ..., C_k 组成: 相邻单元格 C_i 和 C_{i+1} 在八个方向之一上连通(此时,C_i 和 C_{i+1} 不同且共享边或角) C_1 位于 (0, 0)(即,值为 grid[0][0]) C_k 位于 (N-1, N-1)(即,值为 grid[N-1][N-1]) 如果 C_i 位于 (r, c),则 grid[r][c] 为空(即,grid[r][c] == 0) 返回这条从左上角到右下角的最短畅通路径的长度。如果不存在这样的路径,返回 -1 。 1 <= grid.length == grid[0].length <= 100 grid[i][j] 为 0 或 1
示例:
输入:[[0,0,0],[1,1,0],[1,1,0]]
输出:4
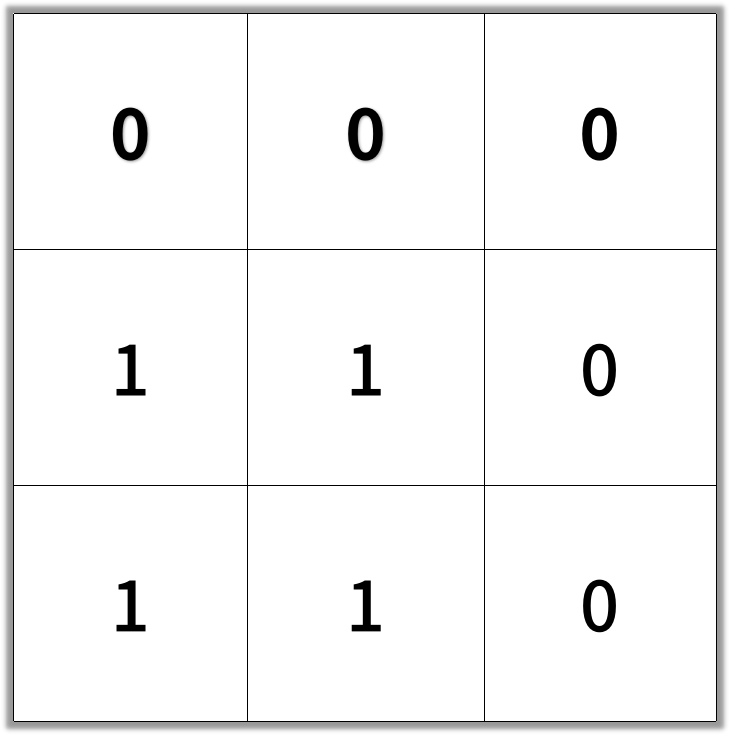
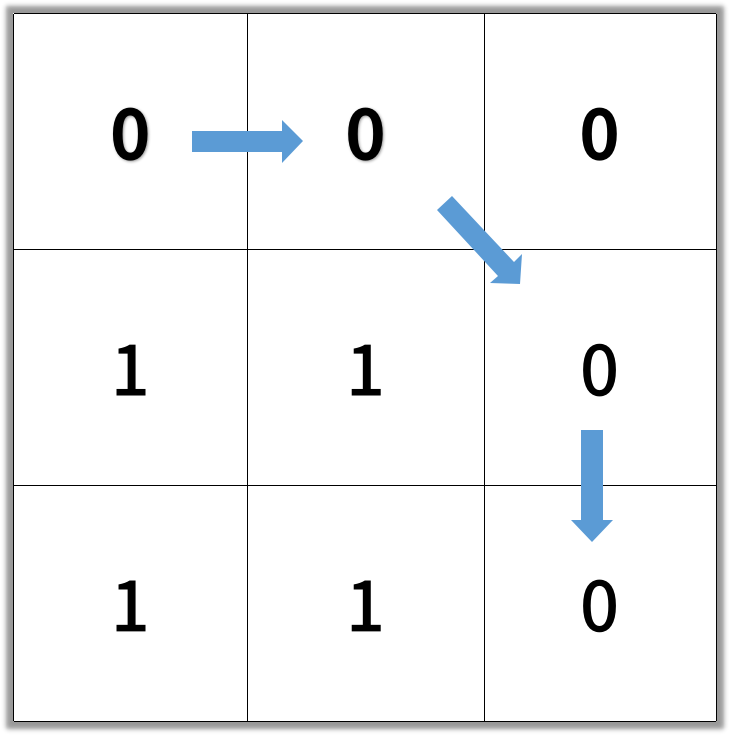
class Solution:
def shortestPathBinaryMatrix(self, grid: List[List[int]]) -> int:
# 标准BFS,注意将走过的格子置为其他值,表示该格子已经走过,如果不这样做会走重复路径,进入死循环
dire = [[1,0],[-1,0],[0,1],[0,-1],[-1,-1],[-1,1],[1,1],[1,-1]]
from collections import deque
rows,cols = len(grid),len(grid[0])
q = deque()
if grid[0][0]==1 or grid[rows-1][cols-1]==1:
return -1
q.append(0)
grid[0][0]=-1
res = 1
while q:
s = len(q)
while s>0:
t = q.popleft()
r,c = t//cols,t%cols
# print(r,c)
if r==rows-1 and c==cols-1:return res
for i in range(8):
nrow,ncol=r+dire[i][0],c+dire[i][1]
if nrow>=0 and nrow<rows and ncol>=0 and ncol<cols:
if nrow==rows-1 and ncol==cols-1:
return res+1
if grid[nrow][ncol]==0:
q.append(nrow*cols+ncol)
grid[nrow][ncol] = -1
s-=1
res+=1
return -163 不同路径 II
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。 现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径? 网格中的障碍物和空位置分别用 1 和 0 来表示。 m 和 n 的值均不超过 100。
示例
输入:
[
[0,0,0],
[0,1,0],
[0,0,0]
]
输出: 2
解释:
3x3 网格的正中间有一个障碍物。
从左上角到右下角一共有 2 条不同的路径:
1. 向右 -> 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右 -> 向右
代码(python3)
class Solution:
def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
rows,cols = len(obstacleGrid),len(obstacleGrid[0])
if obstacleGrid[0][0]==1 or obstacleGrid[rows-1][cols-1]==1:return 0
dp = [[0]*cols for i in range(rows)]
for i in range(rows):
if obstacleGrid[i][0]==1:
break
else:
dp[i][0]=1
for j in range(cols):
if obstacleGrid[0][j]==1:
break
else:
dp[0][j]=1
for i in range(1,rows):
for j in range(1,cols):
if obstacleGrid[i][j]==0:
dp[i][j] = dp[i-1][j]+dp[i][j-1]
return dp[rows-1][cols-1]112路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例: 给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
代码(python3)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def hasPathSum(self, root: TreeNode, sum: int) -> bool:
if not root:return False
if root and not root.left and not root.right:
return sum==root.val
else:
return self.hasPathSum(root.left,sum-root.val) or self.hasPathSum(root.right,sum-root.val)1093 大样本统计
我们对 0 到 255 之间的整数进行采样,并将结果存储在数组 count 中:count[k] 就是整数 k 的采样个数。 我们以 浮点数 数组的形式,分别返回样本的最小值、最大值、平均值、中位数和众数。其中,众数是保证唯一的。
示例:
输入:count = [0,1,3,4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
输出:[1.00000,3.00000,2.37500,2.50000,3.00000]
- count.length == 256
- 1 <= sum(count) <= 10^9
- 计数表示的众数是唯一的
- 答案与真实值误差在 10^-5 以内就会被视为正确答案
class Solution:
def sampleStats(self, count: List[int]) -> List[float]:
'''
主要是求中位数
'''
res = [257,0,0,0,0]
total,c,f = sum(count),0,0
for i in range(256):
if count[i]!=0:
c+=count[i]
res[0] = min(res[0],i)
res[1] = max(res[1],i)
res[2] += i*count[i]
res[4] = i if count[i]>count[res[4]] else res[4]
if c>=total/2 and f==0:
if (total&1)==1:
res[3] = i
elif c-1>=total/2:
res[3] = i
else:
j = i+1
while count[j]==0:j+=1
res[3] = (i+j)/2
f=1
res[2] = res[2]/total
return res哦,不!你不小心把一个长篇文章中的空格、标点都删掉了,并且大写也弄成了小写。像句子"I reset the computer. It still didn’t boot!"已经变成了"iresetthecomputeritstilldidntboot"。在处理标点符号和大小写之前,你得先把它断成词语。当然了,你有一本厚厚的词典dictionary,不过,有些词没在词典里。假设文章用sentence表示,设计一个算法,把文章断开,要求未识别的字符最少,返回未识别的字符数。 注意:本题相对原题稍作改动,只需返回未识别的字符数
示例:
输入:
dictionary = ["looked","just","like","her","brother"]
sentence = "jesslookedjustliketimherbrother"
输出: 7
解释: 断句后为"jess looked just like tim her brother",共7个未识别字符。
- 0 <= len(sentence) <= 1000
- dictionary中总字符数不超过 150000。
- 你可以认为dictionary和sentence中只包含小写字母。
代码(python3)
class Solution:
def respace(self, dictionary: List[str], sentence: str) -> int:
'''
每增加一个字符就遍历一次字典,从字典中找到一个单词使得以该单词结尾,到当前字符结束
未识别的字符最少
'''
n = len(sentence)
dp = [0]*(n+1)
for i in range(1,n+1):
dp[i] = dp[i-1]+1
for s in dictionary:
if len(s)<=i:
if s==sentence[i-len(s):i]:
dp[i] = min(dp[i],dp[i-len(s)])
return dp[n]309 最佳买卖股票时机含冷冻期
给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 。 设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票): 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
示例:
输入: [1,2,3,0,2]
输出: 3
解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]
代码(python3)
class Solution:
def maxProfit(self, prices: List[int]) -> int:
'''
状态动态规划,本质上就是一个状态机。三个状态,买入,卖出,冷冻。
每一天有三种选择,买入,卖出,不买也不卖,而每种选择都依靠前一天是何种状态
画图可以得到三种状态的变化,取变化中最大值就构成动态方程
'''
n = len(prices)
if n<=1:return 0
# dp[0][i]表示第i天卖出股票,dp[1][i]表示第i天买入股票,dp[2][i]表示第i天为冷冻期
dp = [[0]*n for i in range(3)]
dp[1][0] = -prices[0]
for i in range(1,n):
dp[0][i] = max(dp[0][i-1],dp[1][i-1]+prices[i])
dp[1][i] = max(dp[1][i-1],dp[2][i-1]-prices[i])
dp[2][i] = dp[0][i-1]
return max(dp[0][n-1],dp[2][i-1])1094 拼车
假设你是一位顺风车司机,车上最初有 capacity 个空座位可以用来载客。由于道路的限制,车 只能 向一个方向行驶(也就是说,不允许掉头或改变方向,你可以将其想象为一个向量)。 这儿有一份乘客行程计划表 trips[][],其中 trips[i] = [num_passengers, start_location, end_location] 包含了第 i 组乘客的行程信息:
- 必须接送的乘客数量;
- 乘客的上车地点;
- 以及乘客的下车地点。
这些给出的地点位置是从你的 初始 出发位置向前行驶到这些地点所需的距离(它们一定在你的行驶方向上)。 请你根据给出的行程计划表和车子的座位数,来判断你的车是否可以顺利完成接送所用乘客的任务(当且仅当你可以在所有给定的行程中接送所有乘客时,返回 true,否则请返回 false)。
示例:
输入:trips = [[2,1,5],[3,3,7]], capacity = 4
输出:false
输入:trips = [[2,1,5],[3,3,7]], capacity = 5
输出:true
输入:trips = [[3,2,7],[3,7,9],[8,3,9]], capacity = 11
输出:true
- 你可以假设乘客会自觉遵守 “先下后上” 的良好素质
- trips.length <= 1000
- trips[i].length == 3
- 1 <= trips[i][0] <= 100
- 0 <= trips[i][1] < trips[i][2] <= 1000
- 1 <= capacity <= 100000
代码(python3)
class Solution:
def carPooling(self, trips: List[List[int]], capacity: int) -> bool:
'''
路线最大长度已经固定,为1000。只需记录路线上每一点可能达到的最大人数,然后判断每一点是否超过容量即可
'''
count = [0]*1001
for t in trips:
for i in range(t[1],t[2]):
count[i]+=t[0]
for i in range(1001):
if count[i]>capacity:
return False
return True315 计算右侧小于当前元素的个数
给定一个整数数组 nums,按要求返回一个新数组 counts。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。
输入: [5,2,6,1]
输出: [2,1,1,0]
解释:
5 的右侧有 2 个更小的元素 (2 和 1).
2 的右侧仅有 1 个更小的元素 (1).
6 的右侧有 1 个更小的元素 (1).
1 的右侧有 0 个更小的元素.
代码(python3)
# 树结点的定义
class TreeNode:
def __init__(self,val):
self.left = None
self.right = None
self.val = val
self.leftcnt = 1 # 记录左子树有多少个结点,此处把自身也算入,应该是左子树结点个数加1
self.cnt = 1 #记录这个值出现了多少次
class Solution:
def __init__(self):
self.root = None
def insert(self,val):
# 树的插入方法
res = 0
if not self.root:
self.root = TreeNode(val)
return res
p,t,f = None,self.root,-1
node = TreeNode(val)
while t:
p=t
if val>t.val:
res+=t.leftcnt
t=t.right
f=0
elif val<t.val:
t.leftcnt+=1
t=t.left
f=1
else:
f=-1
#如果出现重复的数值,该节点不插入,仅增加一次重复出现的次数,
#而且可以根据leftcnt和cnt计算出小于当前结点的结点个数
res+=t.leftcnt-t.cnt
t.leftcnt+=1
t.cnt+=1
break
if f==0:
p.right=node
elif f==1:
p.left=node
return res
def countSmaller(self, nums: List[int]) -> List[int]:
'''
二叉搜索树的插入复杂度为O(log n),因此可用二叉搜索树来查找小于当前结点的数值个数
从后往前把每个数依次加入二叉搜索树,数结点可以增设一个记录值,记录该节点左孩子有多少个结点
这样每次把新节点插入后可以得到小于该结点的数值有多少个。麻烦的地方是重复的数字要如何记录,为了
解决重复的数字,再在数结点增设一个值,表示该数值出现了多少次
二叉搜索树极端情况下插入复杂度为O(n),因此算法最差时复杂度会变为o(n^2),平均情况下复杂度为o(n logn)
'''
n,root = len(nums),None
counts = [0]*n
# 必须要从右往左记录
for i in reversed(range(n)):
counts[i]=self.insert(nums[i])
return counts1104 二叉树寻路
在一棵无限的二叉树上,每个节点都有两个子节点,树中的节点 逐行 依次按 “之” 字形进行标记。 如下图所示,在奇数行(即,第一行、第三行、第五行……)中,按从左到右的顺序进行标记; 而偶数行(即,第二行、第四行、第六行……)中,按从右到左的顺序进行标记。
给你树上某一个节点的标号 label,请你返回从根节点到该标号为 label 节点的路径,该路径是由途经的节点标号所组成的。
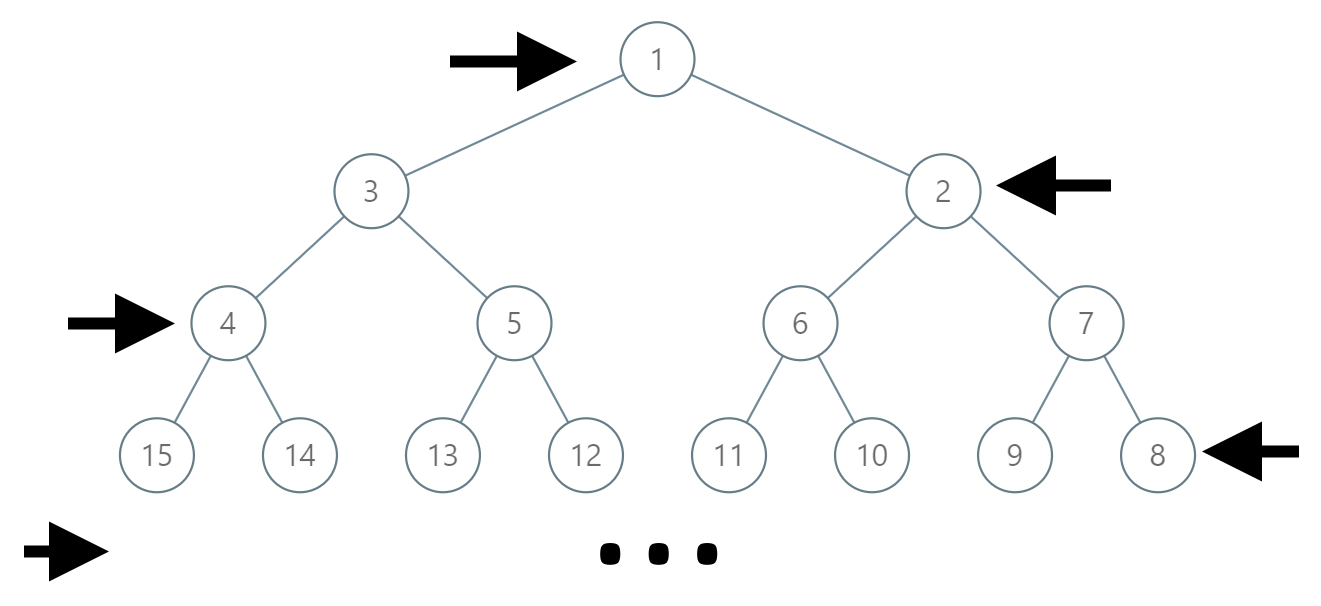
示例:
输入:label = 14
输出:[1,3,4,14]
代码(python3)
class Solution:
def pathInZigZagTree(self, label: int) -> List[int]:
'''
可以将二叉树视为给满二叉树按普通顺序编号后,再将偶数层数字顺序倒转。
这样一个数字的父亲结点与原二叉树该结点的父亲有一定的关系,他们肯定再同一层,
而且在这一层中应该是对称关系,由于满二叉树每一层第一个和最后一个结点可以计算得出
这样就可以获得某个结点的对称位置的数字
设在区间[a,b]上有一点c1,如果c2是c1的对称结点,一定有c1-a=b-c2,那么c2=b+a-c1,即
对称结点为 最大值+最小值-当前值
'''
import math
floor = (int)(math.log(label,2))+1
res = [label]
while floor>1:
floor-=1
label=2**(floor)-1+2**(floor-1)-label//2
res.append(label)
return reversed(res)350 两个数组的交集 II
给定两个数组,编写一个函数来计算它们的交集。 输出结果中每个元素出现的次数,应与元素在两个数组中出现的次数一致。 我们可以不考虑输出结果的顺序。
示例:
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2,2]
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [4,9]
代码(python3)
class Solution:
def intersect(self, nums1: List[int], nums2: List[int]) -> List[int]:
dic1,dic2 = dict(),dict()
n1,n2 = len(nums1),len(nums2)
for i in range(n1):
if nums1[i] in dic1:
dic1[nums1[i]]+=1
else:
dic1[nums1[i]]=1
for i in range(n2):
if nums2[i] in dic2:
dic2[nums2[i]]+=1
else:
dic2[nums2[i]]=1
res = list()
for k,v in dic1.items():
if k in dic2:
res += [k]*min(v,dic2[k])
return res1105 填充书架
附近的家居城促销,你买回了一直心仪的可调节书架,打算把自己的书都整理到新的书架上。 你把要摆放的书 books 都整理好,叠成一摞:从上往下,第 i 本书的厚度为 books[i][0],高度为 books[i][1]。 按顺序 将这些书摆放到总宽度为 shelf_width 的书架上。 先选几本书放在书架上(它们的厚度之和小于等于书架的宽度 shelf_width),然后再建一层书架。重复这个过程,直到把所有的书都放在书架上。 需要注意的是,在上述过程的每个步骤中,摆放书的顺序与你整理好的顺序相同。 例如,如果这里有 5 本书,那么可能的一种摆放情况是:第一和第二本书放在第一层书架上,第三本书放在第二层书架上,第四和第五本书放在最后一层书架上。 每一层所摆放的书的最大高度就是这一层书架的层高,书架整体的高度为各层高之和。 以这种方式布置书架,返回书架整体可能的最小高度。
- 1 <= books.length <= 1000
- 1 <= books[i][0] <= shelf_width <= 1000
- 1 <= books[i][1] <= 1000
示例:
输入:books = [[1,1],[2,3],[2,3],[1,1],[1,1],[1,1],[1,2]], shelf_width = 4
输出:6
解释:
3 层书架的高度和为 1 + 3 + 2 = 6 。
第 2 本书不必放在第一层书架上。
class Solution:
def minHeightShelves(self, books: List[List[int]], shelf_width: int) -> int:
'''
dp[i]表示前i本书的答案
对每一本新书,最开始把它作为新的一层,然后不断从上一层拿下书来与这本书挤到一层,
直到这一层书的厚度超过了书架的厚度。把书拿下来放到这一层的过程中,选择最优的答案
是得dp[i]最小
'''
n = len(books)
dp=[1000*1000]*(n+1)
dp[0]=0
for i in range(1,n+1):
twidth,j,h=0,i,0
while j>0:
twidth+=books[j-1][0]
if twidth>shelf_width:
break
h = max(h,books[j-1][1])
dp[i]=min(dp[i],dp[j-1]+h)
j-=1
return dp[-1]120 三角形最小路径和
给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。 相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。 例如,给定三角形:
[
[2],
[3,4],
[6,5,7],
[4,1,8,3]
]
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
代码(python3)
class Solution:
def minimumTotal(self, triangle: List[List[int]]) -> int:
'''
自底向上原地修改
'''
n = len(triangle)
for i in range(n-2,-1,-1):
for j in range(0,i+1):
triangle[i][j]+=min(triangle[i+1][j],triangle[i+1][j+1])
return triangle[0][0]1106 解析布尔表达式
给你一个以字符串形式表述的 布尔表达式(boolean) expression,返回该式的运算结果。 有效的表达式需遵循以下约定:
- "t",运算结果为 True
- "f",运算结果为 False
- "!(expr)",运算过程为对内部表达式 expr 进行逻辑 非的运算(NOT)
- "&(expr1,expr2,...)",运算过程为对 2 个或以上内部表达式 expr1, expr2, ... 进行逻辑 与的运算(AND)
- "|(expr1,expr2,...)",运算过程为对 2 个或以上内部表达式 expr1, expr2, ... 进行逻辑 或的运算(OR)
示例
输入:expression = "!(f)"
输出:true
输入:expression = "|(f,t)"
输出:true
输入:expression = "|(&(t,f,t),!(t))"
输出:false
- 1 <= expression.length <= 20000
- expression[i] 由 {'(', ')', '&', '|', '!', 't', 'f', ','} 中的字符组成。
- expression 是以上述形式给出的有效表达式,表示一个布尔值。
代码(python3)
class Solution:
def parseBoolExpr(self, expression: str) -> bool:
'''
用两个栈,一个记录符号,一个记录值
由于每个符号位后必有一个括号,因此以括号为一个符号的运算范围。
遍历字符串,遇到符号位入符号位栈,遇到右括号以外的字符全部入值栈
如果遇到右括号,表示一个运算符计算,根据符号栈栈顶字符对值栈进行计算并弹出该值,直到遇到值栈为左括号,该运算符结束
弹出左括号和该运算符,继续遍历
'''
sign,val = [],[]
for es in expression:
if es==',':continue # 跳过逗号
if es=='!' or es=='|' or es=='&': # 符号入栈
sign.append(es)
elif es!=')':
if es!='(':
val.append(True if es=='t' else False)
else:
val.append('(') #左括号入栈,作为某个符号位计算终止标志
else:
if sign[-1]=='!':
b = val.pop() # 弹出值
val.pop() # 弹出左括号
val.append(not b) # 取反
elif sign[-1]=='&':
r = True
while val and val[-1]!='(':
v = val.pop()
r = r and v
val.pop() # 弹出左括号
val.append(r)
else:
r = False
while val and val[-1]!='(':
v = val.pop()
r = r or v
val.pop() # 弹出左括号
val.append(r)
sign.pop() # 弹出该符号
return val[0]96 不同的二叉搜索树
给定一个整数 n,求以 1 ... n 为节点组成的二叉搜索树有多少种?
示例
输入: 3
输出: 5
解释:
给定 n = 3, 一共有 5 种不同结构的二叉搜索树:
1 3 3 2 1
\ / / / \ \
3 2 1 1 3 2
/ / \ \
2 1 2 3
代码(python3)
class Solution:
def numTrees(self, n: int) -> int:
'''
组成二叉树的种数与数值无关,与区间长度有关
设dp[i]是由区间长度为i所能组成的二叉搜索树的种数
那么可以选取1到i中任意一个数为二叉搜索树的根节点,此时组成二叉搜索树的种类就决定于左右子树的种类
设选取j+1为根节点,左子树的种类为dp[j],右子树区间长度为i-(j+1),即i-j-1,则dp[i]=dp[j]*dp[i-j-1],0<=j<i
'''
dp=[0]*(n+1)
dp[0],dp[1]=1,1
for i in range(2,n+1):
for j in range(0,i):
dp[i]+=(dp[j]*dp[i-j-1])
return dp[n]785 判断二分图
给定一个无向图graph,当这个图为二分图时返回true。 如果我们能将一个图的节点集合分割成两个独立的子集A和B,并使图中的每一条边的两个节点一个来自A集合,一个来自B集合,我们就将这个图称为二分图。 graph将会以邻接表方式给出,graph[i]表示图中与节点i相连的所有节点。每个节点都是一个在0到graph.length-1之间的整数。这图中没有自环和平行边: graph[i] 中不存在i,并且graph[i]中没有重复的值。
示例 1:
输入: [[1,3], [0,2], [1,3], [0,2]]
输出: true
解释:
无向图如下:
0----1
| |
| |
3----2
我们可以将节点分成两组: {0, 2} 和 {1, 3}。
示例 2:
输入: [[1,2,3], [0,2], [0,1,3], [0,2]]
输出: false
解释:
无向图如下:
0----1
| \ |
| \ |
3----2
我们不能将节点分割成两个独立的子集。
- graph 的长度范围为 [1, 100]。
- graph[i] 中的元素的范围为 [0, graph.length - 1]。
- graph[i] 不会包含 i 或者有重复的值。
- 图是无向的: 如果j 在 graph[i]里边, 那么 i 也会在 graph[j]里边。 代码(python3)
class Solution:
def isBipartite(self, graph: List[List[int]]) -> bool:
'''
bfs扩展,每扩展一层为结点染上不同颜色,如果能染色完成就返回true,否则返回false
注意不图不连通的情况也可能染色成功,要把所有结点都染色完毕才返回
'''
n=len(graph)
book=[0]*n
from collections import deque
q,f=deque(),2
for i in range(n):
if book[i]!=0:continue
book[i],f=1,2
q.appendleft(i)
while q:
c=len(q)
for i in range(c):
p=q.pop()
for k in graph[p]:
if book[k]==book[p]:return False
if book[k]==0:
book[k]=f
q.appendleft(k)
if f==2:f=1
else:f=2
return True1110 删点成林
给出二叉树的根节点 root,树上每个节点都有一个不同的值。 如果节点值在 to_delete 中出现,我们就把该节点从树上删去,最后得到一个森林(一些不相交的树构成的集合)。 返回森林中的每棵树。你可以按任意顺序组织答案。
示例
输入:root = [1,2,3,4,5,6,7], to_delete = [3,5]
输出:[[1,2,null,4],[6],[7]]
代码(python3)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def delNodes(self, root: TreeNode, to_delete: List[int]) -> List[TreeNode]:
# 后序遍历
res=[]
self.dfs(root,None,res,to_delete)
if root and root.val not in to_delete:
res.append(root)
return res
def dfs(self,root,parent,res,to_delete):
if not root:
return
self.dfs(root.left,root,res,to_delete)
self.dfs(root.right,root,res,to_delete)
if root.val in to_delete:
if root.left:
res.append(root.left)
if root.right:
res.append(root.right)
if parent and parent.left==root:
parent.left=None
elif parent and parent.right==root:
parent.right=None97交错字符串
给定三个字符串 s1, s2, s3, 验证 s3 是否是由 s1 和 s2 交错组成的。
示例
输入: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac"
输出: true
输入: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbbaccc"
输出: false
代码(python3)
class Solution:
def isInterleave(self, s1: str, s2: str, s3: str) -> bool:
'''
实际上仍然是字符串匹配题
dp[i][j]表示s1[0:i]、s2[0:j]是否与s3[0,i+j]匹配
那么dp[i][j]=(s1[i-1]==s3[i-1+j] and dp[i-1][j]) or (s2[j-1]==s3[i+j-1] and dp[i][j-1])
'''
len1,len2,len3=len(s1),len(s2),len(s3)
if len1+len2!=len3:return False
dp=[[False]*(len2+1) for _ in range(len1+1)]
dp[0][0]=True
for i in range(1,len1+1):
if s1[i-1]!=s3[i-1]:
break
dp[i][0]=True
for j in range(1,len2+1):
if s2[j-1]!=s3[j-1]:
break
dp[0][j]=True
for i in range(1,len1+1):
for j in range(1,len2+1):
dp[i][j]=(dp[i-1][j] and s1[i-1]==s3[i-1+j]) or (dp[i][j-1] and s2[j-1]==s3[i+j-1])
return dp[len1][len2] 1122数组的相对排序
给你两个数组,arr1 和 arr2, arr2 中的元素各不相同 arr2 中的每个元素都出现在 arr1 中 对 arr1 中的元素进行排序,使 arr1 中项的相对顺序和 arr2 中的相对顺序相同。未在 arr2 中出现过的元素需要按照升序放在 arr1 的末尾。
示例:
输入:arr1 = [2,3,1,3,2,4,6,7,9,2,19], arr2 = [2,1,4,3,9,6]
输出:[2,2,2,1,4,3,3,9,6,7,19]
- arr1.length, arr2.length <= 1000
- 0 <= arr1[i], arr2[i] <= 1000
- arr2 中的元素 arr2[i] 各不相同
- arr2 中的每个元素 arr2[i] 都出现在 arr1 中
代码(python3)
class Solution:
def relativeSortArray(self, arr1: List[int], arr2: List[int]) -> List[int]:
book=dict()
for n in arr2:
book[n]=0
leftlist=list()
for n in arr1:
if n in book:
book[n]+=1
else:
leftlist.append(n)
leftlist.sort()
l=list()
for k,v in book.items():
t=v
while t>0:
l.append(k)
t-=1
return l+leftlist给定一个已按照升序排列 的有序数组,找到两个数使得它们相加之和等于目标数。 函数应该返回这两个下标值 index1 和 index2,其中 index1 必须小于 index2。 说明: 返回的下标值(index1 和 index2)不是从零开始的。 你可以假设每个输入只对应唯一的答案,而且你不可以重复使用相同的元素。
示例:
输入: numbers = [2, 7, 11, 15], target = 9
输出: [1,2]
解释: 2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。
代码(python3)
class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
book = dict()
for i in range(len(numbers)):
if target-numbers[i] in book:
return [book[target-numbers[i]],i+1]
book[numbers[i]]=i+1
return -11128等价多米诺骨牌对的数量
给你一个由一些多米诺骨牌组成的列表 dominoes。 如果其中某一张多米诺骨牌可以通过旋转 0 度或 180 度得到另一张多米诺骨牌,我们就认为这两张牌是等价的。 形式上,dominoes[i] = [a, b] 和 dominoes[j] = [c, d] 等价的前提是a == c 且 b == d,或者a == d且b == c 在 0 <= i < j < dominoes.length 的前提下,找出满足 dominoes[i] 和 dominoes[j] 等价的骨牌对 (i, j) 的数量。
示例:
输入:dominoes = [[1,2],[2,1],[3,4],[5,6]]
输出:1
- 1 <= dominoes.length <= 40000
- 1 <= dominoes[i][j] <= 9
class Solution:
def numEquivDominoPairs(self, dominoes: List[List[int]]) -> int:
'''
将牌变为字符串后用hash表判断
'''
book=dict()
r=0
for domino in dominoes:
domino.sort()
s=str(domino)
if s in book:
book[s]+=1
else:
book[s]=1
for k,v in book.items():
if v>1:
r+=v*(v-1)//2
return r95 不同的二叉搜索树 II
给定一个整数 n(0<=n<=8),生成所有由 1 ... n 为节点所组成的 二叉搜索树 。
示例:
输入:3
输出:
[
[1,null,3,2],
[3,2,null,1],
[3,1,null,null,2],
[2,1,3],
[1,null,2,null,3]
]
解释:
以上的输出对应以下 5 种不同结构的二叉搜索树:
1 3 3 2 1
\ / / / \ \
3 2 1 1 3 2
/ / \ \
2 1 2 3
代码(python3)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def generateTrees(self, n: int) -> List[TreeNode]:
'''
分治递归,每次选择一个结点作为根节点,就将问题分为两个子问题,即求右子树和左子树
问题规模不大,递归也可得到答案
'''
if n==0:
return []
return self.generate(1,n)
def generate(self,begin,end):
if begin>end:return [None]
res=[]
for n in range(begin,end+1):
left_tree=self.generate(begin,n-1)
right_tree=self.generate(n+1,end)
for left in left_tree:
for right in right_tree:
node=TreeNode(n,left,right)
res.append(node)
return res1138 字母板上的路径
我们从一块字母板上的位置 (0, 0) 出发,该坐标对应的字符为 board[0][0]。 在本题里,字母板为board = ["abcde", "fghij", "klmno", "pqrst", "uvwxy", "z"],如下所示。

我们可以按下面的指令规则行动: 如果方格存在,'U' 意味着将我们的位置上移一行; 如果方格存在,'D' 意味着将我们的位置下移一行; 如果方格存在,'L' 意味着将我们的位置左移一列; 如果方格存在,'R' 意味着将我们的位置右移一列; '!' 会把在我们当前位置 (r, c) 的字符 board[r][c] 添加到答案中。 (注意,字母板上只存在有字母的位置。) 返回指令序列,用最小的行动次数让答案和目标 target 相同。你可以返回任何达成目标的路径。
示例
输入:target = "leet"
输出:"DDR!UURRR!!DDD!"
输入:target = "code"
输出:"RR!DDRR!UUL!R!"
代码(python3)
class Solution:
def alphabetBoardPath(self, target: str) -> str:
'''
字母坐标可以映射,计算可得出
可以想象一个棋子,在棋盘上每次确定一个位置,然后在棋盘上移动棋子,并记录移动轨迹,过程不复杂
但特殊的是最后一个字母z,它的右边没有格子了。每次移动时先往上移(如果需要的话),再往右移。
或者先往左移(如果需要),再往下移
'''
cols=5
cur_row,cur_col=0,0
i=0
res=''
while i<len(target):
word=ord(target[i])-ord('a')
r,c=word//cols,word%cols
if cur_row>r:
while cur_row>r:
cur_row-=1
res+='U'
if cur_col<c:
while cur_col<c:
cur_col+=1
res+='R'
if cur_col>c:
while cur_col>c:
cur_col-=1
res+='L'
if cur_row<r:
while cur_row<r:
cur_row+=1
res+='D'
res+='!'
i+=1
return res1144 递减元素使数组呈锯齿状
给你一个整数数组 nums,每次 操作 会从中选择一个元素并 将该元素的值减少 1。 如果符合下列情况之一,则数组 A 就是 锯齿数组: 每个偶数索引对应的元素都大于相邻的元素,即 A[0] > A[1] < A[2] > A[3] < A[4] > ... 或者,每个奇数索引对应的元素都大于相邻的元素,即 A[0] < A[1] > A[2] < A[3] > A[4] < ... 返回将数组 nums 转换为锯齿数组所需的最小操作次数。
示例
输入:nums = [1,2,3]
输出:2
解释:我们可以把 2 递减到 0,或把 3 递减到 1。
输入:nums = [9,6,1,6,2]
输出:4
代码(python3)
class Solution:
def movesToMakeZigzag(self, nums: List[int]) -> int:
'''
数组只能减少,题目较简单。
要么奇数位为波谷,要么偶数位为波谷,取两种方法中变动次数最少的
'''
c1,c2=0,0
for i in range(1,len(nums),2):
left=nums[i-1]
right=nums[i+1] if i+1<len(nums) else 0x7fffffff
t=min(left,right)
if nums[i]>=t:
c1+=nums[i]-t+1
for i in range(0,len(nums),2):
left=nums[i-1] if i-1>=0 else 0x7fffffff
right=nums[i+1] if i+1<len(nums) else 0x7fffffff
t=min(left,right)
if nums[i]>=t:
c2+=nums[i]-t+1
return min(c1,c2) 329矩阵中的最长递增路径
给定一个整数矩阵,找出最长递增路径的长度。 对于每个单元格,你可以往上,下,左,右四个方向移动。 你不能在对角线方向上移动或移动到边界外(即不允许环绕)。
示例:
输入: nums =
[
[9,9,4],
[6,6,8],
[2,1,1]
]
输出: 4
解释: 最长递增路径为 [1, 2, 6, 9]。
输入: nums =
[
[3,4,5],
[3,2,6],
[2,2,1]
]
输出: 4
解释: 最长递增路径是 [3, 4, 5, 6]。注意不允许在对角线方向上移动。
代码(python3)
class Solution:
def longestIncreasingPath(self, matrix: List[List[int]]) -> int:
'''
深度优先加记忆化搜索
'''
res=1
rows=len(matrix)
if rows==0:return 0
cols=len(matrix[0])
book=[[0]*cols for _ in range(rows)]
for i in range(rows):
for j in range(cols):
if book[i][j]==0:
self.dfs(matrix,i,j,-99999999,book)
res=max(res,book[i][j])
return res
def dfs(self,matrix,row,col,last,book):
dire=[[0,1],[0,-1],[1,0],[-1,0]]
rows,cols=len(matrix),len(matrix[0])
if matrix[row][col]<=last:return -1
if book[row][col]!=0:return book[row][col]
res=1
for i in range(4):
x,y=row+dire[i][0],col+dire[i][1]
if x>=0 and x<rows and y>=0 and y<cols:
res=max(self.dfs(matrix,x,y,matrix[row][col],book)+1,res)
book[row][col]=res
return res392判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 你可以认为 s 和 t 中仅包含英文小写字母。字符串 t 可能会很长(长度 ~= 500,000),而 s 是个短字符串(长度 <=100)。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
示例:
s = "abc", t = "ahbgdc"
返回 true.
s = "axc", t = "ahbgdc"
返回 false.
代码(python3)
class Solution:
def isSubsequence(self, s: str, t: str) -> bool:
'''
双指针
'''
i,j=0,0
while i<len(s) and j<len(t):
if s[i]==t[j]:
i+=1
j+=1
else:
j+=1
return i==len(s)1129颜色交替的最短路径
在一个有向图中,节点分别标记为 0, 1, ..., n-1。这个图中的每条边不是红色就是蓝色,且存在自环或平行边。 red_edges 中的每一个 [i, j] 对表示从节点 i 到节点 j 的红色有向边。类似地,blue_edges 中的每一个 [i, j] 对表示从节点 i 到节点 j 的蓝色有向边。 返回长度为 n 的数组 answer,其中 answer[X] 是从节点 0 到节点 X 的最短路径的长度,且路径上红色边和蓝色边交替出现。如果不存在这样的路径,那么 answer[x] = -1。
示例
输入:n = 3, red_edges = [[0,1],[1,2]], blue_edges = []
输出:[0,1,-1]
输入:n = 3, red_edges = [[0,1]], blue_edges = [[2,1]]
输出:[0,1,-1]
输入:n = 3, red_edges = [[1,0]], blue_edges = [[2,1]]
输出:[0,-1,-1]
输入:n = 3, red_edges = [[0,1]], blue_edges = [[1,2]]
输出:[0,1,2]
代码(python3)
class Solution:
def shortestAlternatingPaths(self, n: int, red_edges: List[List[int]], blue_edges: List[List[int]]) -> List[int]:
'''
最短路径问题可使用bfs
本题加了路径颜色限制,因此要记录上一条路径的颜色,并以上一条路径的颜色限制下一条路径的颜色
可以直接把红色路径到达和蓝色路径到达视为不同结点,这样与普通bfs求最短路径就统一**了
'''
inf=999999999999
redadj=[[] for _ in range(n)] #红色路径邻接表
blueadj=[[] for _ in range(n)] #蓝色路径邻接表
# 下面两个循环建立两种颜色的邻接表
for edge in red_edges:
redadj[edge[0]].append(edge[1])
for edge in blue_edges:
blueadj[edge[0]].append(edge[1])
answer=[inf]*n #初始化距离为无限远
answer[0]=0
# from collections import deque
q=deque()
q.appendleft([0,-1]) #队列元素是一个pair,第一个数记录路径上一个结点的编号,第二个数记录路径颜色,1代表红色,2代表蓝色
dis=1
redvist,bluevisit=[False]*n,[False]*n #记录是否通过红色路径和蓝色路径访问过该结点
while q:
size = len(q)
for i in range(size):
edge=q.pop()
if edge[1]!=1: # 如果上一条路径不是红色,就到红色邻接表中继续遍历
for node in redadj[edge[0]]:
if not redvist[node]:
redvist[node]=True
answer[node]=min(answer[node],dis)
q.appendleft([node,1])
if edge[1]!=2: # 如果上一条路径不是蓝色,就到蓝色邻接表中继续遍历
for node in blueadj[edge[0]]:
if not bluevisit[node]:
bluevisit[node]=True
answer[node]=min(answer[node],dis)
q.appendleft([node,2])
dis+=1 # 往外扩张一层,距离加1
for i in range(n):
if answer[i]==inf: #该点不可达,修改距离为-1
answer[i]=-1
return answer1147 段式回文
段式回文 其实与 一般回文 类似,只不过是最小的单位是 一段字符 而不是 单个字母。 举个例子,对于一般回文 "abcba" 是回文,而 "volvo" 不是,但如果我们把 "volvo" 分为 "vo"、"l"、"vo" 三段,则可以认为 “(vo)(l)(vo)” 是段式回文(分为 3 段)。 给你一个字符串 text,在确保它满足段式回文的前提下,请你返回 段 的 最大数量 k。
示例
输入:text = "ghiabcdefhelloadamhelloabcdefghi"
输出:7
解释:我们可以把字符串拆分成 "(ghi)(abcdef)(hello)(adam)(hello)(abcdef)(ghi)"。
输入:text = "merchant"
输出:1
解释:我们可以把字符串拆分成 "(merchant)"。
输入:text = "aaa"
输出:3
解释:我们可以把字符串拆分成 "(a)(a)(a)"。
代码(python3)
class Solution:
def longestDecomposition(self, text: str) -> int:
'''
双指针,左右指针互相向对方移动,当形成相同的字符串时分段加2,不能分段就加1
'''
n=len(text)
for i in range(1,n//2+1):
if text[0:i]==text[n-i:n]:
return self.longestDecomposition(text[i:n-i])+2
return min(1,len(text))1161最大层内元素和
给你一个二叉树的根节点 root。设根节点位于二叉树的第 1 层,而根节点的子节点位于第 2 层,依此类推。 请你找出层内元素之和 最大 的那几层(可能只有一层)的层号,并返回其中 最小 的那个。
示例
输入:[1,7,0,7,-8,null,null]
输出:2
解释:
第 1 层各元素之和为 1,
第 2 层各元素之和为 7 + 0 = 7,
第 3 层各元素之和为 7 + -8 = -1,
所以我们返回第 2 层的层号,它的层内元素之和最大。
代码(python3)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def maxLevelSum(self, root: TreeNode) -> int:
'''
实际上图的BFS和数的层序遍历是一个**,这里就是层序遍历,也可以说是BFS
'''
q=deque()
q.append(root)
level=1
maxsum=-99999999
r=1
while q:
size=len(q)
s=0
for i in range(size):
t=q.pop()
s+=t.val
if t.left:
q.appendleft(t.left)
if t.right:
q.appendleft(t.right)
if s>maxsum:
maxsum=s
r=level
level+=1
return r1169查询无效交易
如果出现下述两种情况,交易 可能无效:
- 交易金额超过 ¥1000
- 或者,它和另一个城市中同名的另一笔交易相隔不超过 60 分钟(包含 60 分钟整)
每个交易字符串 transactions[i] 由一些用逗号分隔的值组成,这些值分别表示交易的名称,时间(以分钟计),金额以及城市。
给你一份交易清单 transactions,返回可能无效的交易列表。你可以按任何顺序返回答案。
示例:
输入:transactions = ["alice,20,800,mtv","alice,50,100,beijing"]
输出:["alice,20,800,mtv","alice,50,100,beijing"]
解释:第一笔交易是无效的,因为第二笔交易和它间隔不超过 60 分钟、名称相同且发生在不同的城市。同样,第二笔交易也是无效的。
输入:transactions = ["alice,20,800,mtv","alice,50,1200,mtv"]
输出:["alice,50,1200,mtv"]
代码
class Solution:
def invalidTransactions(self, transactions: List[str]) -> List[str]:
'''
暴力法
遍历所有交易,将交易人姓名作为键,把交易人所有交易的编号组成的列表作为值,这样就组成了
交易人到其所有交易的映射
边遍历边判断交易是否合法
时间复杂度o(n^2)
'''
book = dict()
res=set()
for i in range(len(transactions)):
tra=transactions[i].split(',')
if int(tra[2])>1000:
res.add(transactions[i])
if tra[0] in book:
for n in book[tra[0]]:
oldtra=transactions[n].split(',')
if oldtra[3]!=tra[3] and abs(int(oldtra[1])-int(tra[1]))<=60:
res.add(transactions[n])
res.add(transactions[i])
book[tra[0]].append(i)
else:
li = list()
li.append(i)
book[tra[0]]=li
return list(res)1177 构建回文串检测(待重写)
给你一个字符串 s,请你对 s 的子串进行检测。 每次检测,待检子串都可以表示为 queries[i] = [left, right, k]。我们可以 重新排列 子串 s[left], ..., s[right],并从中选择 最多 k 项替换成任何小写英文字母。 如果在上述检测过程中,子串可以变成回文形式的字符串,那么检测结果为 true,否则结果为 false。 返回答案数组 answer[],其中 answer[i] 是第 i 个待检子串 queries[i] 的检测结果。 注意:在替换时,子串中的每个字母都必须作为 独立的 项进行计数,也就是说,如果 s[left..right] = "aaa" 且 k = 2,我们只能替换其中的两个字母。(另外,任何检测都不会修改原始字符串 s,可以认为每次检测都是独立的)
示例
输入:s = "abcda", queries = [[3,3,0],[1,2,0],[0,3,1],[0,3,2],[0,4,1]]
输出:[true,false,false,true,true]
解释:
queries[0] : 子串 = "d",回文。
queries[1] : 子串 = "bc",不是回文。
queries[2] : 子串 = "abcd",只替换 1 个字符是变不成回文串的。
queries[3] : 子串 = "abcd",可以变成回文的 "abba"。 也可以变成 "baab",先重新排序变成 "bacd",然后把 "cd" 替换为 "ab"。
queries[4] : 子串 = "abcda",可以变成回文的 "abcba"。
代码
class Solution:
def canMakePaliQueries(self, s: str, queries: List[List[int]]) -> List[bool]:
'''
遍历所有queries,统计left到right之间字母出现次数,出现次数为奇数的可以通过修改一个其他字母
使得出现次数变为偶数,因此当出现次数为奇数的字母种类小于k*2时答案为true,不过回文串允许一次
出现次数为奇数的字母
方法超时,最后三个用例无法通过
'''
answer=[False]*len(queries)
for i in range(len(queries)):
left,right,k=queries[i][0],queries[i][1],queries[i][2]
if k>=13:
answer[i]=True
continue
book=[0]*26
c=0
for j in range(left,right+1):
idx=ord(s[j])-ord('a')
book[idx]+=1
for j in range(26):
if book[j]&1:
c+=1
if c-1<=k*2:
answer[i]=True
return answer1184 公交站间的距离
环形公交路线上有 n 个站,按次序从 0 到 n - 1 进行编号。我们已知每一对相邻公交站之间的距离,distance[i] 表示编号为 i 的车站和编号为 (i + 1) % n 的车站之间的距离。 环线上的公交车都可以按顺时针和逆时针的方向行驶。 返回乘客从出发点 start 到目的地 destination 之间的最短距离。
示例
输入:distance = [1,2,3,4], start = 0, destination = 2
输出:3
解释:公交站 0 和 2 之间的距离是 3 或 7,最小值是 3。
代码
class Solution:
def distanceBetweenBusStops(self, distance: List[int], start: int, destination: int) -> int:
'''
顺时针和逆时针各走一遍
'''
n=len(distance)
c1,c2=0,0
if start<destination:
for i in range(start,destination):
c1+=distance[i]
for i in range(destination,n):
c2+=distance[i]
for i in range(start):
c2+=distance[i]
else:
for i in range(start,n):
c1+=distance[i]
for i in range(destination):
c1+=distance[i]
for i in range(destination,start):
c2+=distance[i]
return min(c1,c2)1185 一周中的第几天
给你一个日期,请你设计一个算法来判断它是对应一周中的哪一天。 输入为三个整数:day、month 和 year,分别表示日、月、年。 您返回的结果必须是这几个值中的一个 {"Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"}。 给出的日期一定是在 1971 到 2100 年之间的有效日期。
示例
输入:day = 31, month = 8, year = 2019
输出:"Saturday"
代码
class Solution:
def dayOfTheWeek(self, day: int, month: int, year: int) -> str:
'''
1971年1月1日是星期五,计算与这一天的时间天数,对7取余
'''
days=[0,31,28,31,30,31,30,31,31,30,31,30,31]
c=0
for y in range(1971,year):
if (y%4==0 and y%100!=0) or y%400==0:
c+=366
else:
c+=365
for m in range(month):
c+=days[m]
c+=day
if month>2 and ((year%4==0 and year%100!=0) or year%400==0):
c+=1
c-=1
c%=7
if c==0:
return "Friday"
elif c==1:
return "Saturday"
elif c==2:
return "Sunday"
elif c==3:
return "Monday"
elif c==4:
return "Tuesday"
elif c==5:
return "Wednesday"
else:
return "Thursday"207 课程表
你这个学期必须选修 numCourse 门课程,记为 0 到 numCourse-1 。 在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们:[0,1] 给定课程总量以及它们的先决条件,请你判断是否可能完成所有课程的学习?
示例
输入: 2, [[1,0],[0,1]]
输出: false
解释: 总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0;并且学习课程 0 之前,你还应先完成课程 1。这是不可能的。
代码
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
# 拓扑排序
degrees=[0]*numCourses # 结点入度记录表
graph=[[] for _ in range(numCourses)] # 邻接表
for i,j in prerequisites:
graph[j].append(i)
degrees[i]+=1
stack=[]
c=0
for i in range(numCourses):
if degrees[i]==0:
stack.append(i)
while stack:
k=stack.pop()
for n in graph[k]:
degrees[n]-=1
if degrees[n]==0:
stack.append(n)
c+=1
return c==numCourses1191 K 次串联后最大子数组之和
给你一个整数数组 arr 和一个整数 k。 首先,我们要对该数组进行修改,即把原数组 arr 重复 k 次。 举个例子,如果 arr = [1, 2] 且 k = 3,那么修改后的数组就是 [1, 2, 1, 2, 1, 2]。 然后,请你返回修改后的数组中的最大的子数组之和。 注意,子数组长度可以是 0,在这种情况下它的总和也是 0。 由于 结果可能会很大,所以需要 模(mod) 10^9 + 7 后再返回。
示例
输入:arr = [1,2], k = 3
输出:9
输入:arr = [1,-2,1], k = 5
输出:2
输入:arr = [-1,-2], k = 7
输出:0
- 1 <= arr.length <= 10^5
- 1 <= k <= 10^5
- -10^4 <= arr[i] <= 10^4
代码(java)
class Solution {
public int kConcatenationMaxSum(int[] arr, int k) {
/**
*有多种情况
*1. 最大和在arr的中间取得
*2. arr的和大于0,最大和为: 最大后缀和+(k-2)*sum(arr)+最大前缀和。k>=2
*3. arr的和小于0,最大和为: 最大后缀和+最大前缀和
*/
int len=arr.length;
if(len==0){
return 0;
}
long maxprefix=arr[0],maxsuffix=arr[len-1],t=arr[0],maxmid=arr[0];//最大前缀和,最大后缀和,最大中段和
long mod=(long)(1e9+7);
int prefix=arr[0];//当前前缀和
int suffix=arr[len-1];//当前后缀和
for(int i=1;i<len;i++){
prefix+=+arr[i];
suffix+=+arr[len-1-i];
maxprefix=Math.max(maxprefix,prefix);
maxsuffix=Math.max(maxsuffix,suffix);
//Kadane 算法
if(t+arr[i]<arr[i]){
t=arr[i];
}else{
t+=arr[i];
}
maxmid=Math.max(t,maxmid);
}
if(k==1){
return (int)Math.max(maxmid%mod,0);//k=1时,直接返回最大中段和,注意如果全部数都小于0,那就一个数都不取,返回0
}else{
long res1=(maxsuffix+maxprefix)%mod,res2=maxmid%mod;
if(prefix>0){
for(int i=0;i<k-2;i++){
res1+=prefix;
res1%=mod;
}
}
int r= (int)Math.max(res2,Math.max(res1,(maxprefix+maxsuffix)%mod));//返回三种情况下最大值
return Math.max(r,0);//再与0比较
}
}
}1200 最小绝对差
给你个整数数组 arr,其中每个元素都 不相同。
请你找到所有具有最小绝对差的元素对,并且按升序的顺序返回。
示例
输入:arr = [4,2,1,3]
输出:[[1,2],[2,3],[3,4]]
输入:arr = [3,8,-10,23,19,-4,-14,27]
输出:[[-14,-10],[19,23],[23,27]]
代码(java)
class Solution {
public List<List<Integer>> minimumAbsDifference(int[] arr) {
//最小绝对差的元素对一定是按顺序相邻的,排序后扫描一遍列表即可
Arrays.sort(arr);
int d=Integer.MAX_VALUE;
List<List<Integer>>res = new ArrayList<>();
for (int i=0;i<arr.length-1;i++){
if (Math.abs(arr[i]-arr[i+1])<d){
res.clear();
d=Math.abs(arr[i]-arr[i+1]);
}
if (Math.abs(arr[i]-arr[i+1])==d){
List<Integer>t=new ArrayList<>();
t.add(arr[i]);
t.add(arr[i+1]);
res.add(t);
}
}
return res;
}
}1202 交换字符串中的元素
给你一个字符串 s,以及该字符串中的一些「索引对」数组 pairs,其中 pairs[i] = [a, b] 表示字符串中的两个索引(编号从 0 开始)。 你可以 任意多次交换 在 pairs 中任意一对索引处的字符。 返回在经过若干次交换后,s 可以变成的按字典序最小的字符串。
示例:
输入:s = "dcab", pairs = [[0,3],[1,2]]
输出:"bacd"
解释:
交换 s[0] 和 s[3], s = "bcad"
交换 s[1] 和 s[2], s = "bacd"
输入:s = "dcab", pairs = [[0,3],[1,2],[0,2]]
输出:"abcd"
解释:
交换 s[0] 和 s[3], s = "bcad"
交换 s[0] 和 s[2], s = "acbd"
交换 s[1] 和 s[2], s = "abcd"
代码
class Solution:
def smallestStringWithSwaps(self, s: str, pairs: List[List[int]]) -> str:
'''
把pairs用并查集连接,这样处于同一簇下标之间的字符可以任意排列,把它们排好序
然后按照下标顺序,从前往后插入可以得到结果
时间控制很严格,对并查集的路径压缩后才能通过
'''
n=len(s)
# 构建并查集
p=[i for i in range(n)]
for pair in pairs:
p1=self.find(pair[0],p)
p2=self.find(pair[1],p)
if p1!=p2:
p[p1]=p2
d=dict()
rank=[]
for i in range(n):
t=self.find(i,p)
rank.append(t)
if t in d:
d[t]+=s[i]
else:
d[t]=s[i]
for k,v in d.items():
d[k]=sorted(v,reverse=True)
res=[]
for i in range(n):
res.append(d[rank[i]].pop())
return ''.join(res)
def find(self,x,p):
son=x
while x!=p[x]:
x=p[x]
while son!=x: # 并查集树的路径压缩
t=p[son]
p[son]=x
son=t
return x1208 尽可能使字符串相等
给你两个长度相同的字符串,s 和 t。 将 s 中的第 i 个字符变到 t 中的第 i 个字符需要 |s[i] - t[i]| 的开销(开销可能为 0),也就是两个字符的 ASCII 码值的差的绝对值。 用于变更字符串的最大预算是 maxCost。在转化字符串时,总开销应当小于等于该预算,这也意味着字符串的转化可能是不完全的。 如果你可以将 s 的子字符串转化为它在 t 中对应的子字符串,则返回可以转化的最大长度。 如果 s 中没有子字符串可以转化成 t 中对应的子字符串,则返回 0。
示例
输入:s = "abcd", t = "bcdf", cost = 3
输出:3
解释:s 中的 "abc" 可以变为 "bcd"。开销为 3,所以最大长度为 3。
输入:s = "abcd", t = "cdef", cost = 3
输出:1
解释:s 中的任一字符要想变成 t 中对应的字符,其开销都是 2。因此,最大长度为 1。
输入:s = "abcd", t = "acde", cost = 0
输出:1
解释:你无法作出任何改动,所以最大长度为 1。
代码
class Solution:
def equalSubstring(self, s: str, t: str, maxCost: int) -> int:
'''
滑动窗口
当需要的花费小于最大花费时移动右窗口,当需要的花费大于最大花费时移动左窗口
移动窗口的过程中记录窗口最大值
'''
i=c=last=res=0
while i<len(s):
c+=abs(ord(s[i])-ord(t[i]))
if c>maxCost:
while c>maxCost:
c-=abs(ord(s[last])-ord(t[last]))
last+=1
res=max(i-last+1,res)
i+=1
return res93 复原IP地址
给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
有效的 IP 地址正好由四个整数(每个整数位于 0 到 255 之间组成),整数之间用 '.' 分隔。
示例
输入: "25525511135"
输出: ["255.255.11.135", "255.255.111.35"]
代码
class Solution:
def restoreIpAddresses(self, s: str) -> List[str]:
'''
最适合暴力枚举
'''
def judge(s):
if not s:
return False
if s[0]!='0':
return int(s)<=255
return len(s)==1
res=[]
n=len(s)
for i in range(0,min(n,3)):
for j in range(i+1,min(n,6)):
for k in range(j+1,min(n,9)):
s1=s[0:i+1]
s2=s[i+1:j+1]
s3=s[j+1:k+1]
s4=s[k+1:]
if judge(s1) and judge(s2) and judge(s3) and judge(s4):
res.append(s1+'.'+s2+'.'+s3+'.'+s4)
return res1219 黄金矿工
你要开发一座金矿,地质勘测学家已经探明了这座金矿中的资源分布,并用大小为 m * n 的网格 grid 进行了标注。每个单元格中的整数就表示这一单元格中的黄金数量;如果该单元格是空的,那么就是 0。 为了使收益最大化,矿工需要按以下规则来开采黄金: 每当矿工进入一个单元,就会收集该单元格中的所有黄金。 矿工每次可以从当前位置向上下左右四个方向走。 每个单元格只能被开采(进入)一次。 不得开采(进入)黄金数目为 0 的单元格。 矿工可以从网格中 任意一个 有黄金的单元格出发或者是停止。
示例
输入:grid = [[0,6,0],[5,8,7],[0,9,0]]
输出:24
解释:
[[0,6,0],
[5,8,7],
[0,9,0]]
一种收集最多黄金的路线是:9 -> 8 -> 7。
代码
class Solution:
def getMaximumGold(self, grid: List[List[int]]) -> int:
'''
典型回溯算法
'''
res=0
m,n=len(grid),len(grid[0])
visited=[[False]*n for _ in range(m)]
for i in range(m):
for j in range(n):
if grid[i][j]:
res=max(res,self.dfs(i,j,grid,visited))
return res
def dfs(self,x,y,grid,visited):
rows,cols=len(grid),len(grid[0])
dire=[[0,1],[0,-1],[1,0],[-1,0]]
visited[x][y]=True
ans=grid[x][y]
t=0
for i in range(4):
r,c=x+dire[i][0],y+dire[i][1]
if r>=0 and r<rows and c>=0 and c<cols:
if not visited[r][c] and grid[r][c]!=0:
t=max(t,self.dfs(r,c,grid,visited))
visited[x][y]=False
return ans+t130 被围绕的区域
给定一个二维的矩阵,包含 'X' 和 'O'(字母 O)。 找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
示例
输入
X X X X
X O O X
X X O X
X O X X
输出
X X X X
X X X X
X X X X
X O X X
代码
class Solution:
dire=[[0,1],[0,-1],[-1,0],[1,0]]
def solve(self, board: List[List[str]]) -> None:
"""
Do not return anything, modify board in-place instead.
"""
'''
先从边界入手,以边界O为起点,进行dfs,把与边界相连通的O修改为其他字母,这样剩下的O都是要填充为X的
再遍历一遍棋盘,把剩下的O修改为X,并将之前修改成其他字母的位置改为O
'''
rows=len(board)
if rows<=0:
return
cols=len(board[0])
for i in range(rows):
if board[i][0]=='O':
self.dfs(board,i,0)
if board[i][cols-1]=='O':
self.dfs(board,i,cols-1)
for j in range(cols):
if board[0][j]=='O':
self.dfs(board,0,j)
if board[rows-1][j]=='O':
self.dfs(board,rows-1,j)
for i in range(0,rows):
for j in range(0,cols):
if board[i][j]=='O':
board[i][j]='X'
if board[i][j]=='A':
board[i][j]='O'
def dfs(self,board,x,y):
board[x][y]='A'
rows,cols=len(board),len(board[0])
for i in range(4):
r,c=self.dire[i][0]+x,self.dire[i][1]+y
if r>=0 and r<rows and c>=0 and c<cols:
if board[r][c]=='O':
self.dfs(board,r,c)1220 统计元音字母序列的数目
给你一个整数 n,请你帮忙统计一下我们可以按下述规则形成多少个长度为 n 的字符串:
- 字符串中的每个字符都应当是小写元音字母('a', 'e', 'i', 'o', 'u')
- 每个元音 'a' 后面都只能跟着 'e'
- 每个元音 'e' 后面只能跟着 'a' 或者是 'i'
- 每个元音 'i' 后面 不能 再跟着另一个 'i'
- 每个元音 'o' 后面只能跟着 'i' 或者是 'u'
- 每个元音 'u' 后面只能跟着 'a' 由于答案可能会很大,所以请你返回 模 10^9 + 7 之后的结果。
示例
输入:n = 2
输出:10
解释:所有可能的字符串分别是:"ae", "ea", "ei", "ia", "ie", "io", "iu", "oi", "ou" 和 "ua"。
输入:n = 5
输出:68
代码
class Solution:
def countVowelPermutation(self, n: int) -> int:
'''
状态动态规划
dp[k][n] 0<=k<5 分别表示以aeiou结尾的长度为n的字符串种类数
可以根据题意直接得出dp[k][n]和dp[k][n-1]之间的状态变化
'''
mod=(int)(1e9+7)
dp=[[0]*n for _ in range(5)]
for i in range(5):
dp[i][0]=1
for i in range(1,n):
dp[0][i]=(dp[1][i-1]+dp[2][i-1]+dp[4][i-1])%mod
dp[1][i]=(dp[0][i-1]+dp[2][i-1])%mod
dp[2][i]=(dp[1][i-1]+dp[3][i-1])%mod
dp[3][i]=dp[2][i-1]
dp[4][i]=(dp[2][i-1]+dp[3][i-1])%mod
return (dp[0][n-1]+dp[1][n-1]+dp[2][n-1]+dp[3][n-1]+dp[4][n-1])%mod1222 可以攻击国王的皇后
在一个 8x8 的棋盘上,放置着若干「黑皇后」和一个「白国王」。 「黑皇后」在棋盘上的位置分布用整数坐标数组 queens 表示,「白国王」的坐标用数组 king 表示。 「黑皇后」的行棋规定是:横、直、斜都可以走,步数不受限制,但是,不能越子行棋。 请你返回可以直接攻击到「白国王」的所有「黑皇后」的坐标(任意顺序)。
示例
输入:queens = [[0,1],[1,0],[4,0],[0,4],[3,3],[2,4]], king = [0,0]
输出:[[0,1],[1,0],[3,3]]
解释:
[0,1] 的皇后可以攻击到国王,因为他们在同一行上。
[1,0] 的皇后可以攻击到国王,因为他们在同一列上。
[3,3] 的皇后可以攻击到国王,因为他们在同一条对角线上。
[0,4] 的皇后无法攻击到国王,因为她被位于 [0,1] 的皇后挡住了。
[4,0] 的皇后无法攻击到国王,因为她被位于 [1,0] 的皇后挡住了。
[2,4] 的皇后无法攻击到国王,因为她和国王不在同一行/列/对角线上。
代码
class Solution:
def queensAttacktheKing(self, queens: List[List[int]], king: List[int]) -> List[List[int]]:
'''
国王只有一个,因此从国王的位置开始朝八个方向去方向搜索皇后会比皇后的位置搜索国王快得多
'''
res=[]
n=8
dire=[[-1,0],[-1,1],[0,1],[1,1],[1,0],[1,-1],[0,-1],[-1,-1]]
for i in range(8):
x,y=king[0],king[1]
while x>=0 and x<n and y>=0 and y<n:
x+=dire[i][0]
y+=dire[i][1]
if [x,y] in queens:
res.append([x,y])
break
return res1223 掷骰子模拟
有一个骰子模拟器会每次投掷的时候生成一个 1 到 6 的随机数。 不过我们在使用它时有个约束,就是使得投掷骰子时,连续 掷出数字 i 的次数不能超过 rollMax[i](i 从 1 开始编号)。 现在,给你一个整数数组 rollMax 和一个整数 n,请你来计算掷 n 次骰子可得到的不同点数序列的数量。 假如两个序列中至少存在一个元素不同,就认为这两个序列是不同的。由于答案可能很大,所以请返回 模 10^9 + 7 之后的结果。
- 1 <= n <= 5000
- rollMax.length == 6
- 1 <= rollMax[i] <= 15
示例
输入:n = 2, rollMax = [1,1,2,2,2,3]
输出:34
解释:我们掷 2 次骰子,如果没有约束的话,共有 6 * 6 = 36 种可能的组合。但是根据 rollMax 数组,数字 1 和 2 最多连续出现一次,所以不会出现序列 (1,1) 和 (2,2)。因此,最终答案是 36-2 = 34。
代码
class Solution:
def dieSimulator(self, n: int, rollMax: List[int]) -> int:
'''
dp[i][j][k]表示掷骰子k次,得到以重复j个i结尾的序列的个数,其中 1<=i<=6, 1<=j<=15
那么可以得知,dp[i][1][k]表示投掷k次骰子,以1个i结尾的序列个数。由于结尾处只有一个i,除了前一个字符
是i的序列外,它前面可以是任意序列。因此dp[i][1][k]=sum(dp[p][q][k-1]) 1<=p<=6且p!=i,1<=q<=rollMax[p]
此外,当j>=2时,dp[i][j][k]表示的序列结尾必须是j个i,那么最后一个字符是i,它前一个字符固定也是i,故
此时dp[i][j][k]=dp[i][j-1][k-1],即只能是投掷了k-1次骰子,且得到了以j-1个i结尾的序列后再投出了一个i
为了方便,代码中将所有索引都移到从0开始
'''
mod=(int)(1e9+7)
dp = [[[0]*n for j in range(rollMax[i])] for i in range(6)]
for i in range(6): # 只投一次每中数字结尾,且长度为1的序列只有一种
dp[i][0][0]=1
for k in range(1,n): # 投掷k次
for i in range(6): # 以i结尾
# p ,q循环用来单独求dp[i][1][k]
for p in range(6):
if p==i:continue
for q in range(rollMax[p]):
dp[i][0][k]+=dp[p][q][k-1]
dp[i][0][k]%=mod
for j in range(1,rollMax[i]): # 以j个i结尾的序列1种类数
dp[i][j][k]=dp[i][j-1][k-1] # 直接等于投k-1次得到以j-1个i结尾的序列种类数
res=0
for i in range(6):
for j in range(rollMax[i]):
res+=dp[i][j][n-1]
res%=mod
return res 1232 缀点成线
一个 XY 坐标系中有一些点,我们用数组 coordinates 来分别记录它们的坐标,其中 coordinates[i] = [x, y] 表示横坐标为 x、纵坐标为 y 的点。 请你来判断,这些点是否在该坐标系中属于同一条直线上,是则返回 true,否则请返回 false。
示例
输入:coordinates = [[1,2],[2,3],[3,4],[4,5],[5,6],[6,7]]
输出:true
输入:coordinates = [[1,1],[2,2],[3,4],[4,5],[5,6],[7,7]]
输出:false
代码
class Solution:
def checkStraightLine(self, coordinates: List[List[int]]) -> bool:
'''
取三个点,构成两个向量
向量平衡时条件x1/x2=y1/y2,防止除0,变为x1*y2=x2*y1
'''
n=len(coordinates)
for i in range(n-2):
u=[coordinates[i][0]-coordinates[i+1][0],coordinates[i][1]-coordinates[i+1][1]]
v=[coordinates[i][0]-coordinates[i+2][0],coordinates[i][1]-coordinates[i+2][1]]
if v[0]*u[1]!=v[1]*u[0]:
return False
return True1233 删除子文件夹
你是一位系统管理员,手里有一份文件夹列表 folder,你的任务是要删除该列表中的所有 子文件夹,并以 任意顺序 返回剩下的文件夹。 我们这样定义「子文件夹」: 如果文件夹 folder[i] 位于另一个文件夹 folder[j] 下,那么 folder[i] 就是 folder[j] 的子文件夹。 文件夹的「路径」是由一个或多个按以下格式串联形成的字符串: / 后跟一个或者多个小写英文字母。 例如,/leetcode 和 /leetcode/problems 都是有效的路径,而空字符串和 / 不是。
示例
输入:folder = ["/a","/a/b","/c/d","/c/d/e","/c/f"]
输出:["/a","/c/d","/c/f"]
解释:"/a/b/" 是 "/a" 的子文件夹,而 "/c/d/e" 是 "/c/d" 的子文件夹。
输入:folder = ["/a","/a/b/c","/a/b/d"]
输出:["/a"]
解释:文件夹 "/a/b/c" 和 "/a/b/d/" 都会被删除,因为它们都是 "/a" 的子文件夹。
代码
class Solution:
def removeSubfolders(self, folder: List[str]) -> List[str]:
'''
将所有文件夹加入set
遍历所有文件夹,判断文件夹的前缀字符串是否在set中,如果在则该文件夹是某个文件夹的子文件夹
'''
book=set(folder)
res=[]
for f in folder:
flag=1
for i in range(len(f)):
if f[i]=='/':
if f[0:i] in book:
flag=0
break
if flag:
res.append(f)
return res1234 替换子串得到平衡字符串
有一个只含有 'Q', 'W', 'E', 'R' 四种字符,且长度为 n 的字符串。 假如在该字符串中,这四个字符都恰好出现 n/4 次,那么它就是一个「平衡字符串」。 给你一个这样的字符串 s,请通过「替换一个子串」的方式,使原字符串 s 变成一个「平衡字符串」。 你可以用和「待替换子串」长度相同的 任何 其他字符串来完成替换。 请返回待替换子串的最小可能长度。 如果原字符串自身就是一个平衡字符串,则返回 0。
示例
输入:s = "QWER"
输出:0
解释:s 已经是平衡的了。
输入:s = "QQWE"
输出:1
解释:我们需要把一个 'Q' 替换成 'R',这样得到的 "RQWE" (或 "QRWE") 是平衡的。
输入:s = "QQQW"
输出:2
解释:我们可以把前面的 "QQ" 替换成 "ER"。
输入:s = "QQQQ"
输出:3
解释:我们可以替换后 3 个 'Q',使 s = "QWER"。
代码
class Solution:
def balancedString(self, s: str) -> int:
'''
滑动窗口
先计算每个字符出现的次数,要考虑的只有出现次数大于n//4的,可以将这些出现次数大于n//4的变成任意其他不够的字符
在窗口内每滑动一次右窗口就检查窗口内字符是否满足条件,如果满足就不断滑动左窗口,将答案数值尽量减少,直到左右边界不满足条件为止
'''
res=n=len(s)
avg=n//4
book = dict()
# 计算每个字符出现的次数
for char in s:
if char in book:
book[char]+=1
else:
book[char]=1
items=list(book.items())
for k,v in items: # 将出现次数少于n//4的字符删除,只考虑出现次数大于n//4的
if book[k]<avg:
del book[k]
if not book: # 如果已经平衡返回0
return 0
left=right=0
while right<n:
if s[right] in book:
book[s[right]]-=1 # 可以把s[right]变为其他较少的字符
flag=True
while flag and left<n:
for k,v in book.items(): # 检查是否满足条件
if v>avg:
flag=False
break
if flag: # 满足条件就继续缩减左窗口,逼近答案
res=min(res,right-left+1)
if s[left] in book: book[s[left]]+=1
left+=1
right+=1
return res109 有序链表转换二叉搜索树
给定一个单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树。 本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
示例
给定的有序链表: [-10, -3, 0, 5, 9],
一个可能的答案是:[0, -3, 9, -10, null, 5], 它可以表示下面这个高度平衡二叉搜索树:
0
/ \
-3 9
/ /
-10 5
代码
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def sortedListToBST(self, head: ListNode) -> TreeNode:
'''
快慢指针寻找中间结点,递归完成建树
'''
if not head:
return None
fast=slow=head
pre=None
while fast and fast.next:
fast=fast.next.next
pre=slow
slow=slow.next
if pre:pre.next=None
res=TreeNode(slow.val)
if slow==head:
res.left=None
else:
res.left=self.sortedListToBST(head)
res.right=self.sortedListToBST(slow.next)
return res647 回文子串
给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
示例
输入:"abc"
输出:3
解释:三个回文子串: "a", "b", "c"
输入:"aaa"
输出:6
解释:6个回文子串: "a", "a", "a", "aa", "aa", "aaa"
代码
class Solution:
def countSubstrings(self, s: str) -> int:
'''
dp[i][j]==1表示s[i:j]是回文串
则dp[i][j]=1 if dp[i+1][j-1]==1 and s[i]==s[j]
由于dp[i][j]依赖于dp[i+1][j-1],i要倒着遍历,j顺着遍历
'''
n=len(s)
dp=[[1]*n for _ in range(n)]
for i in range(n-2,-1,-1):
for j in range(i+1,n):
if s[i]==s[j] and dp[i+1][j-1]==1:dp[i][j]=1
else:dp[i][j]=0
res=0
for i in range(n):
for j in range(i,n):
res+=dp[i][j]
return res529 扫雷游戏
让我们一起来玩扫雷游戏! 给定一个代表游戏板的二维字符矩阵。 'M' 代表一个未挖出的地雷,'E' 代表一个未挖出的空方块,'B' 代表没有相邻(上,下,左,右,和所有4个对角线)地雷的已挖出的空白方块,数字('1' 到 '8')表示有多少地雷与这块已挖出的方块相邻,'X' 则表示一个已挖出的地雷。 现在给出在所有未挖出的方块中('M'或者'E')的下一个点击位置(行和列索引),根据以下规则,返回相应位置被点击后对应的面板:
- 如果一个地雷('M')被挖出,游戏就结束了- 把它改为 'X'。
- 如果一个没有相邻地雷的空方块('E')被挖出,修改它为('B'),并且所有和其相邻的未挖出方块都应该被递归地揭露。
- 如果一个至少与一个地雷相邻的空方块('E')被挖出,修改它为数字('1'到'8'),表示相邻地雷的数量。
- 如果在此次点击中,若无更多方块可被揭露,则返回面板。
示例
输入:
[['E', 'E', 'E', 'E', 'E'],
['E', 'E', 'M', 'E', 'E'],
['E', 'E', 'E', 'E', 'E'],
['E', 'E', 'E', 'E', 'E']]
Click : [3,0]
输出:
[['B', '1', 'E', '1', 'B'],
['B', '1', 'M', '1', 'B'],
['B', '1', '1', '1', 'B'],
['B', 'B', 'B', 'B', 'B']]
代码
class Solution:
dire=[[-1,0],[-1,1],[0,1],[1,1],[1,0],[1,-1],[0,-1],[-1,-1]]
def updateBoard(self, board: List[List[str]], click: List[int]) -> List[List[str]]:
'''
按照题目意思深度优先递归即可
'''
x,y=click[0],click[1]
rows,cols=len(board),len(board[0])
if board[x][y]=='M':
board[x][y]='X'
elif board[x][y]=='E':
cnt=0
for i in range(8):
r,c=self.dire[i][0]+x,self.dire[i][1]+y
if r>=0 and r<rows and c>=0 and c<cols:
if board[r][c]=='M':
cnt+=1
if cnt>0:
board[x][y]=str(cnt)
else:
board[x][y]='B'
for i in range(8):
r,c=self.dire[i][0]+x,self.dire[i][1]+y
if r>=0 and r<rows and c>=0 and c<cols and board[r][c]=='E':
self.updateBoard(board,[r,c])
return board1239 串联字符串的最大长度
给定一个字符串数组 arr,字符串 s 是将 arr 某一子序列字符串连接所得的字符串,如果 s 中的每一个字符都只出现过一次,那么它就是一个可行解。 请返回所有可行解 s 中最长长度。
- 1 <= arr.length <= 16
- 1 <= arr[i].length <= 26
- arr[i] 中只含有小写英文字母
示例
输入:arr = ["un","iq","ue"]
输出:4
解释:所有可能的串联组合是 "","un","iq","ue","uniq" 和 "ique",最大长度为 4。
输入:arr = ["cha","r","act","ers"]
输出:6
解释:可能的解答有 "chaers" 和 "acters"。
代码
class Solution:
def maxLength(self, arr: List[str]) -> int:
'''
arr的长度最长不超过16,递归回溯可得答案
'''
return self.dfs(arr,0,'')
def dfs(self,arr,idx,s):
if idx==len(arr):
return 0
len1=0
if len(set(s+arr[idx]))==len(s+arr[idx]):
curlen=len(arr[idx])
len1=curlen+self.dfs(arr,idx+1,s+arr[idx])
len2 = self.dfs(arr,idx+1,s)
return max(len1,len2)1247 交换字符使得字符串相同
有两个长度相同的字符串 s1 和 s2,且它们其中 只含有 字符 "x" 和 "y",你需要通过「交换字符」的方式使这两个字符串相同。 每次「交换字符」的时候,你都可以在两个字符串中各选一个字符进行交换。 交换只能发生在两个不同的字符串之间,绝对不能发生在同一个字符串内部。也就是说,我们可以交换 s1[i] 和 s2[j],但不能交换 s1[i] 和 s1[j]。 最后,请你返回使 s1 和 s2 相同的最小交换次数,如果没有方法能够使得这两个字符串相同,则返回 -1 。
示例
输入:s1 = "xx", s2 = "yy"
输出:1
解释:
交换 s1[0] 和 s2[1],得到 s1 = "yx",s2 = "yx"。
输入:s1 = "xy", s2 = "yx"
输出:2
解释:
交换 s1[0] 和 s2[0],得到 s1 = "yy",s2 = "xx" 。
交换 s1[0] 和 s2[1],得到 s1 = "xy",s2 = "xy" 。
注意,你不能交换 s1[0] 和 s1[1] 使得 s1 变成 "yx",因为我们只能交换属于两个不同字符串的字符。
输入:s1 = "xx", s2 = "xy"
输出:-1
代码
class Solution:
def minimumSwap(self, s1: str, s2: str) -> int:
'''
字母相同的地方对结果无影响,因此字母的地方忽略
统计不同字母的x和y的个数
有出现xx和yy需要交换一次,有出现xy和yx需要交换两次
设x和y不同的次数为c1和c2
如果c1和c2为偶数,那么答案就是c1//2+c2//2,因为我们可以任意找一对x或y交换,且只要交换一次就能变为相同
如果c1和c2都为奇数,那么答案就是c1//2+c2//2+2,一直从x和y中取出一对交换,最终两者都剩一个,即xy和yx的情况,需要交换两次
如果两者c1和c2一个是奇数一个偶数,这种情况不能通过交换使字符串相同
'''
n=len(s1)
cnt = [0]*2
for i in range(n):
if s1[i]==s2[i]:continue
if s1[i]=='x':cnt[0]+=1
else:cnt[1]+=1
if (cnt[0]&1)==0 and (cnt[1]&1)==0:
return cnt[0]//2+cnt[1]//2
elif (cnt[0]&1)==1 and (cnt[1]&1)==1:
return cnt[0]//2+cnt[1]//2+2
else:
return -11249 移除无效的括号
给你一个由 '('、')' 和小写字母组成的字符串 s。 你需要从字符串中删除最少数目的 '(' 或者 ')' (可以删除任意位置的括号),使得剩下的「括号字符串」有效。 请返回任意一个合法字符串。 有效「括号字符串」应当符合以下 任意一条 要求: 空字符串或只包含小写字母的字符串 可以被写作 AB(A 连接 B)的字符串,其中 A 和 B 都是有效「括号字符串」 可以被写作 (A) 的字符串,其中 A 是一个有效的「括号字符串」
示例
输入:s = "lee(t(c)o)de)"
输出:"lee(t(c)o)de"
解释:"lee(t(co)de)" , "lee(t(c)ode)" 也是一个可行答案。
输入:s = "a)b(c)d"
输出:"ab(c)d"
输入:s = "))(("
输出:""
解释:空字符串也是有效的
代码
class Solution:
def minRemoveToMakeValid(self, s: str) -> str:
'''
如果一个字符串是合法字符串,那么从左遍历时左括号数一定大于等于右括号数。遍历时如果碰到右括号数大于左括号数
时这个右括号就是要删掉的。还有遍历完时剩下的左括号没有与之匹配的右括号也是要删掉的
从右往左遍历时也是同理。
三次遍历,一次记录从左往右遍历需要删除的字符下标,一次记录从右往左需要删除的字符下标,一次拼接答案
'''
stack = []
dis = set()
n=len(s)
for i in range(n):
if s[i]=='(':
stack.append(i)
elif s[i]==')':
if not stack:
dis.add(i)
else:
stack.pop()
for idx in stack:
dis.add(idx)
stack.clear()
for i in range(n-1,-1,-1):
if s[i]==')':
stack.append(i)
elif s[i]=='(':
if not stack:
dis.add(i)
else:
stack.pop()
for idx in stack:
dis.add(idx)
res=''
for i in range(n):
if i in dis:continue
res+=s[i]
return res1253 重构 2 行二进制矩阵
给你一个 2 行 n 列的二进制数组: 矩阵是一个二进制矩阵,这意味着矩阵中的每个元素不是 0 就是 1。
- 第 0 行的元素之和为 upper。
- 第 1 行的元素之和为 lower。
- 第 i 列(从 0 开始编号)的元素之和为 colsum[i],colsum 是一个长度为 n 的整数数组。
你需要利用 upper,lower 和 colsum 来重构这个矩阵,并以二维整数数组的形式返回它。 如果有多个不同的答案,那么任意一个都可以通过本题。 如果不存在符合要求的答案,就请返回一个空的二维数组。
示例
输入:upper = 2, lower = 1, colsum = [1,1,1]
输出:[[1,1,0],[0,0,1]]
解释:[[1,0,1],[0,1,0]] 和 [[0,1,1],[1,0,0]] 也是正确答案。
输入:upper = 2, lower = 3, colsum = [2,2,1,1]
输出:[]
代码
class Solution:
def reconstructMatrix(self, upper: int, lower: int, colsum: List[int]) -> List[List[int]]:
'''
贪心算法
每次判断当前位置的colsum,如果是2没得选择,上下都放1.如果是1,尽量往和大得那一方放一个1
每放一个1,就将该位置得记录指减一。如果数据刚好全部放完,记录纸也刚好全部减到0,则可以返回答案
其他情况都不存在解。
'''
n=len(colsum)
res = [[],[]]
for i in range(n):
if colsum[i]==2:
res[0].append(1)
res[1].append(1)
upper-=1
lower-=1
elif colsum[i] == 1:
if upper>=lower:
res[0].append(1)
res[1].append(0)
upper-=1
else:
res[0].append(0)
res[1].append(1)
lower-=1
else:
res[0].append(0)
res[1].append(0)
if upper<0 or lower<0:
return []
if upper>0 or lower>0:
return []
return res1254 统计封闭岛屿的数目
有一个二维矩阵 grid ,每个位置要么是陆地(记号为 0 )要么是水域(记号为 1 )。 我们从一块陆地出发,每次可以往上下左右 4 个方向相邻区域走,能走到的所有陆地区域,我们将其称为一座「岛屿」。 如果一座岛屿 完全 由水域包围,即陆地边缘上下左右所有相邻区域都是水域,那么我们将其称为 「封闭岛屿」。 请返回封闭岛屿的数目。
示例
输入:grid = [[1,1,1,1,1,1,1,0],[1,0,0,0,0,1,1,0],[1,0,1,0,1,1,1,0],[1,0,0,0,0,1,0,1],[1,1,1,1,1,1,1,0]]
输出:2
解释:
灰色区域的岛屿是封闭岛屿,因为这座岛屿完全被水域包围(即被 1 区域包围)。
代码
class Solution:
dire = [[0,1],[0,-1],[1,0],[-1,0]]
def closedIsland(self, grid: List[List[int]]) -> int:
rows,cols=len(grid),len(grid[0])
res=0
for i in range(0,rows):
for j in range(0,cols):
if grid[i][j]==0 and self.dfs(grid,i,j):
res+=1
return res
def dfs(self,grid,x,y):
rows,cols=len(grid),len(grid[0])
if x<0 or x>=rows or y<0 or y>=cols:
return False
if grid[x][y]==1:
return True
grid[x][y]=1
res=True
for i in range(4):
r,c=x+self.dire[i][0],y+self.dire[i][1]
t= self.dfs(grid,r,c)
if not t:
res=False
return res491 递增子序列
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
示例
输入: [4, 6, 7, 7]
输出: [[4, 6], [4, 7], [4, 6, 7], [4, 6, 7, 7], [6, 7], [6, 7, 7], [7,7], [4,7,7]]
- 给定数组的长度不会超过15。
- 数组中的整数范围是 [-100,100]。
- 给定数组中可能包含重复数字,相等的数字应该被视为递增的一种情况。
代码
class Solution:
def findSubsequences(self, nums: List[int]) -> List[List[int]]:
'''
回溯加set去重
回溯时用list保存,变为tuple加入set去重
效率较低
'''
book=set()
res=[]
self.dfs(nums,0,[],book)
for s in book:
res.append(list(s))
return res
def dfs(self,nums,idx,s,book):
if len(s)>=2:
book.add(tuple(s))
for i in range(idx,len(nums)):
if len(s)==0 or s[-1]<=nums[i]:
s.append(nums[i])
self.dfs(nums,i+1,s,book)
s.pop()
1267 统计参与通信的服务器
这里有一幅服务器分布图,服务器的位置标识在 m * n 的整数矩阵网格 grid 中,1 表示单元格上有服务器,0 表示没有。 如果两台服务器位于同一行或者同一列,我们就认为它们之间可以进行通信。 请你统计并返回能够与至少一台其他服务器进行通信的服务器的数量。
示例
输入:grid = [[1,0],[1,1]]
输出:3
解释:所有这些服务器都至少可以与一台别的服务器进行通信。
输入:grid = [[1,0],[0,1]]
输出:0
解释:没有一台服务器能与其他服务器进行通信。
代码
class Solution:
def countServers(self, grid: List[List[int]]) -> int:
'''
计数法,set去重剪枝
'''
rows,cols=len(grid),len(grid[0])
book=set()
for i in range(rows):
for j in range(cols):
if grid[i][j]==1 and i*cols+j not in book:
flag=False
for k in range(cols):
if grid[i][k]==1 and k!=j:
flag=True
book.add(i*cols+k)
for k in range(rows):
if grid[k][j]==1 and k!=i:
flag=True
book.add(k*cols+j)
if flag:
book.add(i*cols+j)
return len(book)1268 搜索推荐系统
给你一个产品数组 products 和一个字符串 searchWord ,products 数组中每个产品都是一个字符串。 请你设计一个推荐系统,在依次输入单词 searchWord 的每一个字母后,推荐 products 数组中前缀与 searchWord 相同的最多三个产品。如果前缀相同的可推荐产品超过三个,请按字典序返回最小的三个。 请你以二维列表的形式,返回在输入 searchWord 每个字母后相应的推荐产品的列表。
示例
输入:products = ["mobile","mouse","moneypot","monitor","mousepad"], searchWord = "mouse"
输出:[
["mobile","moneypot","monitor"],
["mobile","moneypot","monitor"],
["mouse","mousepad"],
["mouse","mousepad"],
["mouse","mousepad"]
]
解释:按字典序排序后的产品列表是 ["mobile","moneypot","monitor","mouse","mousepad"]
输入 m 和 mo,由于所有产品的前缀都相同,所以系统返回字典序最小的三个产品 ["mobile","moneypot","monitor"]
输入 mou, mous 和 mouse 后系统都返回 ["mouse","mousepad"]
代码
class Solution:
def suggestedProducts(self, products: List[str], searchWord: str) -> List[List[str]]:
'''
先将字符串按字典序排序,然后遍历判断前缀
'''
res=[]
n=len(searchWord)
products.sort()
for i in range(n):
t=[]
for j in range(len(products)):
if products[j].startswith(searchWord[0:i+1]) and len(t)<3:
t.append(products[j])
res.append(t)
return res841 钥匙和房间
有 N 个房间,开始时你位于 0 号房间。每个房间有不同的号码:0,1,2,...,N-1,并且房间里可能有一些钥匙能使你进入下一个房间。 在形式上,对于每个房间 i 都有一个钥匙列表 rooms[i],每个钥匙 rooms[i][j] 由 [0,1,...,N-1] 中的一个整数表示,其中 N = rooms.length。 钥匙 rooms[i][j] = v 可以打开编号为 v 的房间。 最初,除 0 号房间外的其余所有房间都被锁住。 你可以自由地在房间之间来回走动。 如果能进入每个房间返回 true,否则返回 false。
示例
输入: [[1],[2],[3],[]]
输出: true
解释:
我们从 0 号房间开始,拿到钥匙 1。
之后我们去 1 号房间,拿到钥匙 2。
然后我们去 2 号房间,拿到钥匙 3。
最后我们去了 3 号房间。
由于我们能够进入每个房间,我们返回 true。
代码
class Solution:
def canVisitAllRooms(self, rooms: List[List[int]]) -> bool:
book=set()
q=deque()
q.append(0)
book.add(0)
while q:
n=q.pop()
for i in rooms[n]:
if i not in book:
book.add(i)
q.appendleft(i)
return len(book)==len(rooms)1269 停在原地的方案数
有一个长度为 arrLen 的数组,开始有一个指针在索引 0 处。 每一步操作中,你可以将指针向左或向右移动 1 步,或者停在原地(指针不能被移动到数组范围外)。 给你两个整数 steps 和 arrLen ,请你计算并返回:在恰好执行 steps 次操作以后,指针仍然指向索引 0 处的方案数。 由于答案可能会很大,请返回方案数 模 10^9 + 7 后的结果。
- 1 <= steps <= 500
- 1 <= arrLen <= 10^6
示例
输入:steps = 3, arrLen = 2
输出:4
解释:3 步后,总共有 4 种不同的方法可以停在索引 0 处。
向右,向左,不动
不动,向右,向左
向右,不动,向左
不动,不动,不动
输入:steps = 2, arrLen = 4
输出:2
解释:2 步后,总共有 2 种不同的方法可以停在索引 0 处。
向右,向左
不动,不动
代码
class Solution:
def numWays(self, steps: int, arrLen: int) -> int:
'''
dp[i][j]表示经过i步到达坐标j的方案数,dp[0][0]=1
每一步可以向左、向右或者不动,那么dp[i][j]=dp[i-1][j-1]+dp[i-1][j+1]+dp[i-1][j]
'''
dp = [[0]*min(arrLen,steps+1) for _ in range(steps+1)]
dp[0][0]=1
mod=1000000007
for i in range(1,steps+1):
for j in range(min(arrLen,steps+1)):
if j-1>=0:
dp[i][j]=(dp[i][j]+dp[i-1][j-1])%mod
if j+1<min(arrLen,steps+1):
dp[i][j]=(dp[i][j]+dp[i-1][j+1])%mod
dp[i][j]=(dp[i][j]+dp[i-1][j])%mod
return dp[steps][0]1276 不浪费原料的汉堡制作方案
圣诞活动预热开始啦,汉堡店推出了全新的汉堡套餐。为了避免浪费原料,请你帮他们制定合适的制作计划。 给你两个整数 tomatoSlices 和 cheeseSlices,分别表示番茄片和奶酪片的数目。不同汉堡的原料搭配如下: 巨无霸汉堡:4 片番茄和 1 片奶酪 小皇堡:2 片番茄和 1 片奶酪 请你以 [total_jumbo, total_small]([巨无霸汉堡总数,小皇堡总数])的格式返回恰当的制作方案,使得剩下的番茄片 tomatoSlices 和奶酪片 cheeseSlices 的数量都是 0。 如果无法使剩下的番茄片 tomatoSlices 和奶酪片 cheeseSlices 的数量为 0,就请返回 []。
示例
输入:tomatoSlices = 16, cheeseSlices = 7
输出:[1,6]
解释:制作 1 个巨无霸汉堡和 6 个小皇堡需要 4*1 + 2*6 = 16 片番茄和 1 + 6 = 7 片奶酪。不会剩下原料。
输入:tomatoSlices = 17, cheeseSlices = 4
输出:[]
解释:只制作小皇堡和巨无霸汉堡无法用光全部原料。
代码
class Solution:
def numOfBurgers(self, tomatoSlices: int, cheeseSlices: int) -> List[int]:
'''
设tomatoSlices和cheeseSlices分别为t和c
制作巨无霸和小黄堡数量分别为x,y
则有4*x+2*x=t,x+y=c,求二元一次方程的正整数解
'''
t=tomatoSlices
c=cheeseSlices
if not (4*c-t)&1 and 4*c-t>=0 and 2*t-4*c>=0:
return [(2*t-4*c)//4,(4*c-t)//2]
else:
return []1282 用户分组
有 n 位用户参加活动,他们的 ID 从 0 到 n - 1,每位用户都 恰好 属于某一用户组。给你一个长度为 n 的数组 groupSizes,其中包含每位用户所处的用户组的大小,请你返回用户分组情况(存在的用户组以及每个组中用户的 ID)。 你可以任何顺序返回解决方案,ID 的顺序也不受限制。此外,题目给出的数据保证至少存在一种解决方案。
示例
输入:groupSizes = [3,3,3,3,3,1,3]
输出:[[5],[0,1,2],[3,4,6]]
解释:
其他可能的解决方案有 [[2,1,6],[5],[0,4,3]] 和 [[5],[0,6,2],[4,3,1]]。
输入:groupSizes = [2,1,3,3,3,2]
输出:[[1],[0,5],[2,3,4]]
代码
class Solution:
def groupThePeople(self, groupSizes: List[int]) -> List[List[int]]:
'''
hash表记录组大小的列表,边遍历边插入。因为题目保证有至少一种解决方案,不用担心键和值里的列表长度不匹配情况出现
'''
book = dict()
for i,s in enumerate(groupSizes):
if s in book:
if len(book[s][-1])<s:
book[s][-1].append(i)
else:
book[s].append([i])
else:
book[s]=[]
book[s].append([i])
res=[]
for k,v in book.items():
for lst in v:
res.append(lst)
return res1283 使结果不超过阈值的最小除数
给你一个整数数组 nums 和一个正整数 threshold ,你需要选择一个正整数作为除数,然后将数组里每个数都除以它,并对除法结果求和。 请你找出能够使上述结果小于等于阈值 threshold 的除数中 最小 的那个。 每个数除以除数后都向上取整,比方说 7/3 = 3 , 10/2 = 5 。 题目保证一定有解。
示例
输入:nums = [1,2,5,9], threshold = 6
输出:5
解释:如果除数为 1 ,我们可以得到和为 17 (1+2+5+9)。
如果除数为 4 ,我们可以得到和为 7 (1+1+2+3) 。如果除数为 5 ,和为 5 (1+1+1+2)。
输入:nums = [2,3,5,7,11], threshold = 11
输出:3
代码
class Solution:
def smallestDivisor(self, nums: List[int], threshold: int) -> int:
'''
可以将暴力法用二分优化
'''
l=1
r=max(nums)
mid=(l+r)//2
while l<r:
mid = (l+r)//2
c=0
for n in nums:
c+=ceil(n/mid)
if c<=threshold:
r=mid
else:
l=mid+1
return l1288 删除被覆盖区间
给你一个区间列表,请你删除列表中被其他区间所覆盖的区间。 只有当 c <= a 且 b <= d 时,我们才认为区间 [a,b]被区间[c,d]覆盖。请完成所有删除操作后列表中剩余区间的数目
示例
输入:intervals = [[1,4],[3,6],[2,8]]
输出:2
解释:区间 [3,6] 被区间 [2,8] 覆盖,所以它被删除了。
代码
class Solution:
def removeCoveredIntervals(self, intervals: List[List[int]]) -> int:
'''
把区间排序后只需要一直检查右边界即可,把右边界被前面区间覆盖的区间减去
'''
itvs=sorted(intervals,key=functools.cmp_to_key(comp))
i=j=0
res=0
# print(itvs)
while j<len(itvs):
j=i+1
while j<len(itvs) and itvs[j][1]<=itvs[i][1]:
j+=1
res+=1
i=j
return res
def comp(itv1,itv2):
if itv1[0]>itv2[0]:
return 1
elif itv1[0]<itv2[0]:
return -1
elif itv1[1]<itv2[1]:
return 1
else:
return -11291 顺次数
我们定义「顺次数」为:每一位上的数字都比前一位上的数字大 1 的整数。 请你返回由 [low, high] 范围内所有顺次数组成的 有序 列表(从小到大排序)。
示例
输出:low = 100, high = 300
输出:[123,234]
输出:low = 1000, high = 13000
输出:[1234,2345,3456,4567,5678,6789,12345]
代码
class Solution:
def sequentialDigits(self, low: int, high: int) -> List[int]:
'''
构造数字表
先获取数字长度,根据数字长度得到范围内的第一个顺次数
接下来只需要固定窗口大小滑动窗口获取所有数字即可,每次右窗口滑动到最右边时将左窗口重新放到最左端,将窗口
大小增大一个单位继续以上操作。
'''
n=len(str(low))
tb=[1,2,3,4,5,6,7,8,9]
i=0
t=self.get(tb,i,n)
while t<low and i<9:
i+=1
t=self.get(tb,i,n)
if i==9:
i=0
n+=1
res=[]
while i+n<10:
t=self.get(tb,i,n)
if low<=t<=high:
res.append(t)
else:
break
i+=1
if i+n==10:
i=0
n+=1
return res
def get(self,tb,idx,n):
c=0
for i in range(idx,min(idx+n,9)):
c=c*10+tb[i]
return c1292 元素和小于等于阈值的正方形的最大边长
给你一个大小为 m x n 的矩阵 mat 和一个整数阈值 threshold。 请你返回元素总和小于或等于阈值的正方形区域的最大边长;如果没有这样的正方形区域,则返回 0 。
示例
输入:mat = [[1,1,3,2,4,3,2],[1,1,3,2,4,3,2],[1,1,3,2,4,3,2]], threshold = 4
输出:2
解释:总和小于 4 的正方形的最大边长为 2,如图所示。
输入:mat = [[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2]], threshold = 1
输出:0
代码
class Solution:
def maxSideLength(self, mat: List[List[int]], threshold: int) -> int:
'''
前缀和加暴力法
计算矩阵的前缀和矩阵,s[i+1][j+1]表示以i,j为右下角、0,0为左上角的子矩阵所有元素之和
这样计算以i,j为左上角,边长为k的正方形矩阵元素之和的公式为s[i+k][j+k]-s[i+k][j]-s[i][j+k]+s[i][j]
'''
m,n=len(mat),len(mat[0])
s=[[0]*(n+1) for _ in range(m+1)]
f=True
for i in range(m):
for j in range(n):
if mat[i][j]<=threshold:
f=False
s[i+1][j+1]=s[i+1][j]+mat[i][j]
for j in range(1,n+1):
for i in range(1,m+1):
s[i][j]+=s[i-1][j]
res=0
if f:return 0
for i in range(0,m+1):
for j in range(0,n+1):
k=1
while i+k<=m and j+k<=n:
if s[i+k][j+k]-s[i+k][j]-s[i][j+k]+s[i][j]<=threshold:
res=max(res,k)
else:
break
k+=1
return res1296 划分数组为连续数字的集合
给你一个整数数组 nums 和一个正整数 k,请你判断是否可以把这个数组划分成一些由 k 个连续数字组成的集合。 如果可以,请返回 True;否则,返回 False。
示例
输入:nums = [1,2,3,3,4,4,5,6], k = 4
输出:true
解释:数组可以分成 [1,2,3,4] 和 [3,4,5,6]。
输入:nums = [3,2,1,2,3,4,3,4,5,9,10,11], k = 3
输出:true
解释:数组可以分成 [1,2,3] , [2,3,4] , [3,4,5] 和 [9,10,11]。
输入:nums = [1,2,3,4], k = 3
输出:false
解释:数组不能分成几个大小为 3 的子数组。。
代码
class Solution:
def isPossibleDivide(self, nums: List[int], k: int) -> bool:
'''
统计各个数字出现的次数,然后将数字排序
按照顺序选择数字,每选择一个数字就判断它在频率表中的剩余次数是否大于0
如果大于0,就从该数字开始,将与它相邻的k个数字删除,如果中途遇到无法删除的情况返回False
'''
book=dict()
for i in nums:
if i in book: book[i]+=1
else: book[i]=1
nums.sort()
for n in nums:
if book[n]>0:
t=0
while t<k:
if n+t not in book or book[n+t]<=0: return False
book[n+t]-=1
t+=1
return True1297 子串的最大出现次数
给你一个字符串 s ,请你返回满足以下条件且出现次数最大的 任意 子串的出现次数:
- 子串中不同字母的数目必须小于等于 maxLetters 。
- 子串的长度必须大于等于 minSize 且小于等于 maxSize 。
示例
输入:s = "aababcaab", maxLetters = 2, minSize = 3, maxSize = 4
输出:2
解释:子串 "aab" 在原字符串中出现了 2 次。
它满足所有的要求:2 个不同的字母,长度为 3 (在 minSize 和 maxSize 范围内)。
输入:s = "aaaa", maxLetters = 1, minSize = 3, maxSize = 3
输出:2
解释:子串 "aaa" 在原字符串中出现了 2 次,且它们有重叠部分。
输入:s = "abcde", maxLetters = 2, minSize = 3, maxSize = 3
输出:0
代码
class Solution:
def maxFreq(self, s: str, maxLetters: int, minSize: int, maxSize: int) -> int:
'''
较长的字符串会覆盖较短的字符串,只需统计最短的子字符串出现的次数
'''
book=dict()
res=0
for i in range(0,len(s)-minSize+1):
if len(set(s[i:i+minSize]))<=maxLetters: # 首先它的字母出现个数要满足条件
sub=s[i:i+minSize]
# print(sub)
if sub in book:
book[sub]+=1
else:
book[sub]=1
res=max(book[sub],res)
return res1302 层数最深叶子节点的和
给你一棵二叉树,请你返回层数最深的叶子节点的和。
示例
输入:root = [1,2,3,4,5,null,6,7,null,null,null,null,8]
输出:15
代码
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def deepestLeavesSum(self, root: TreeNode) -> int:
level=[]
q=deque()
q.append(root)
s=0
while len(q)>0:
size=len(q)
s=0
for i in range(size):
t=q.pop()
s+=t.val
if t.left:
q.appendleft(t.left)
if t.right:
q.appendleft(t.right)
return s1310异或查询
有一个正整数数组 arr,现给你一个对应的查询数组 queries,其中 queries[i] = [Li, Ri]。 对于每个查询 i,请你计算从 Li 到 Ri 的 XOR 值(即 arr[Li] xor arr[Li+1] xor ... xor arr[Ri])作为本次查询的结果。 并返回一个包含给定查询 queries 所有结果的数组。
示例
输入:arr = [1,3,4,8], queries = [[0,1],[1,2],[0,3],[3,3]]
输出:[2,7,14,8]
解释:
数组中元素的二进制表示形式是:
1 = 0001
3 = 0011
4 = 0100
8 = 1000
查询的 XOR 值为:
[0,1] = 1 xor 3 = 2
[1,2] = 3 xor 4 = 7
[0,3] = 1 xor 3 xor 4 xor 8 = 14
[3,3] = 8
代码
class Solution:
def xorQueries(self, arr: List[int], queries: List[List[int]]) -> List[int]:
'''
数据量很大,暴力法会超时
首先要清楚异或的性质:a^a=0,a^b=b^a,a^0=a
可以先求数组的前缀异或和数组book,设l,r为要求得子数组异或值的左右边界
那么book[l]=arr[0]^arr[1]...^arr[l-1],book[r+1]=arr[0]^arr[1]^...arr[l-1]^arr[l]^arr[l+1]...^arr[r]
即book[r+1]=book[l]^arr[l]^arr[l+1]...^arr[r],arr[l]^arr[l+1]...^arr[r]即为所求结果res
那么book[r+1]^book[l]=book[l]^res^book[l]=res
'''
n=len(arr)
book=[0]*(n+1)
for i in range(1,n+1):
book[i]=book[i-1]^arr[i-1]
res=[]
for l,r in queries:
res.append(book[l]^book[r+1])
return res77 组合
给定两个整数 n 和 k,返回 1 ... n 中所有可能的 k 个数的组合。
示例
输入: n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
代码
class Solution:
def __init__(self):
self.res=[]
self.path=[]
def combine(self, n: int, k: int) -> List[List[int]]:
self.dfs(n,1,k)
return self.res
def dfs(self,n,start,k):
if len(self.path)==k:
p=copy.deepcopy(self.path)
self.res.append(p)
return
for i in range(start,n+1):
self.path.append(i)
self.dfs(n,i+1,k)
self.path.pop()1311 获取你好友已观看的视频
有 n 个人,每个人都有一个 0 到 n-1 的唯一 id 。 给你数组 watchedVideos 和 friends ,其中 watchedVideos[i] 和 friends[i] 分别表示 id = i 的人观看过的视频列表和他的好友列表。 Level 1 的视频包含所有你好友观看过的视频,level 2 的视频包含所有你好友的好友观看过的视频,以此类推。一般的,Level 为 k 的视频包含所有从你出发,最短距离为 k 的好友观看过的视频。 给定你的 id 和一个 level 值,请你找出所有指定 level 的视频,并将它们按观看频率升序返回。如果有频率相同的视频,请将它们按字母顺序从小到大排列。
示例
输入:watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 1
输出:["B","C"]
解释:
你的 id 为 0(绿色),你的朋友包括(黄色):
id 为 1 -> watchedVideos = ["C"]
id 为 2 -> watchedVideos = ["B","C"]
你朋友观看过视频的频率为:
B -> 1
C -> 2
代码
class Solution:
def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:
'''
先通过bfs搜索到最短距离为level的好友,再记录这些还有观看视频的频率,根据频率排序。
'''
v=set()
q=deque()
q.append(id)
d=0
v.add(id)
# bfs获取距离为level的好友
while len(q):
size=len(q)
for i in range(size):
idx=q.pop()
for j in friends[idx]:
if j not in v:
q.appendleft(j)
v.add(j)
d+=1 # 每遍历一层距离加1
if d==level:
break
book=dict()
while len(q)>0:
i=q.pop()
for video in watchedVideos[i]:
if video not in book:
book[video]=1
else:
book[video]+=1
record=list(book.items())
record.sort(key=cmp_to_key(self.comp)) # 根据频率对视频排序
res=[]
for vi,c in record:
res.append(vi)
return res
def comp(self,r1,r2):
if r1[1]>r2[1]:return 1
elif r1[1]<r2[1]:return -1
elif r1[0]<r2[0]:return -1
else:return 11314 矩阵区域和
给你一个 m * n 的矩阵 mat 和一个整数 K ,请你返回一个矩阵 answer ,其中每个 answer[i][j] 是所有满足下述条件的元素 mat[r][c] 的和:
- i - K <= r <= i + K, j - K <= c <= j + K
- (r, c) 在矩阵内。
示例
输入:mat = [[1,2,3],[4,5,6],[7,8,9]], K = 1
输出:[[12,21,16],[27,45,33],[24,39,28]]
输入:mat = [[1,2,3],[4,5,6],[7,8,9]], K = 2
输出:[[45,45,45],[45,45,45],[45,45,45]]
代码
class Solution:
def matrixBlockSum(self, mat: List[List[int]], K: int) -> List[List[int]]:
'''
题目所求矩阵元素res[i][j]为mat的子矩阵mat[r1:r2][c1:c2]的和
构建矩阵前缀和,s[i][j]为以0,0为左上角,(i-1,j-1)为右下角的子矩阵元素和
则mat[r1:r2][c1:c2]的元素和为s[r2+1]+s[c2+1]-s[r2+1][c1]-s[r1][c2+1]+s[r1][c1]
'''
m,n=len(mat),len(mat[0])
s=[[0]*(n+1) for _ in range(m+1)]
for i in range(1,m+1):
for j in range(1,n+1):
s[i][j]=s[i][j-1]+mat[i-1][j-1]
for j in range(1,n+1):
s[i][j]+=s[i-1][j]
res=[[0]*n for _ in range(m)]
# print(s)
for i in range(m):
for j in range(n):
r1,c1=max(0,i-K),max(0,j-K)
r2,c2=min(m-1,i+K),min(n-1,j+K)
res[i][j]=s[r2+1][c2+1]-s[r2+1][c1]-s[r1][c2+1]+s[r1][c1]
return res1334 阈值距离内邻居最少的城市
有 n 个城市,按从 0 到 n-1 编号。给你一个边数组 edges,其中 edges[i] = [fromi, toi, weighti] 代表 fromi 和 toi 两个城市之间的双向加权边,距离阈值是一个整数 distanceThreshold。 返回能通过某些路径到达其他城市数目最少、且路径距离 最大 为 distanceThreshold 的城市。如果有多个这样的城市,则返回编号最大的城市。 注意,连接城市 i 和 j 的路径的距离等于沿该路径的所有边的权重之和。
示例
输入:n = 4, edges = [[0,1,3],[1,2,1],[1,3,4],[2,3,1]], distanceThreshold = 4
输出:3
解释:城市分布图如上。
每个城市阈值距离 distanceThreshold = 4 内的邻居城市分别是:
城市 0 -> [城市 1, 城市 2]
城市 1 -> [城市 0, 城市 2, 城市 3]
城市 2 -> [城市 0, 城市 1, 城市 3]
城市 3 -> [城市 1, 城市 2]
城市 0 和 3 在阈值距离 4 以内都有 2 个邻居城市,但是我们必须返回城市 3,因为它的编号最大。
- 2 <= n <= 100
- 1 <= edges.length <= n * (n - 1) / 2
- edges[i].length == 3
- 0 <= fromi < toi < n
- 1 <= weighti, distanceThreshold <= 10^4
- 所有 (fromi, toi) 都是不同的。
代码(java)
class Solution {
public int findTheCity(int n, int[][] edges, int distanceThreshold) {
/**
先用Floyd算法求解每个点到其他点的最短路径长度,再对每个点进行搜索
*/
int res=0;
int inf=99999999;
int[][] mat = new int[n][n];
for (int i=0;i<n;i++){
for(int j=0;j<n;j++)mat[i][j]=inf;
mat[i][i]=0;
}
//构建初始邻接矩阵
for(int[] edge:edges){
mat[edge[0]][edge[1]]=edge[2];
mat[edge[1]][edge[0]]=edge[2];
}
//Floyd算法。注意执行Floyd算法时,中间过渡结点要放最外层循环
for(int k=0;k<n;k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (mat[i][k] + mat[k][j] < mat[i][j]) {
mat[i][j] = mat[i][k] + mat[k][j];
mat[j][i] = mat[i][j];
}
}
}
}
int min=9999999,c=0;
//搜索每个结点
for (int i=0;i<n;i++){
c=0;
for (int j=0;j<n;j++){
if (mat[i][j]<=distanceThreshold)c+=1;
}
if (c<=min){
min=c;
res=i;
}
}
return res;
}
}37 解数独
编写一个程序,通过已填充的空格来解决数独问题。 一个数独的解法需遵循如下规则: 数字 1-9 在每一行只能出现一次。 数字 1-9 在每一列只能出现一次。 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。 空白格用 '.' 表示。
- 给定的数独序列只包含数字 1-9 和字符 '.' 。
- 你可以假设给定的数独只有唯一解。
- 给定数独永远是 9x9 形式的。
代码
class Solution:
def solveSudoku(self, board: List[List[str]]) -> None:
"""
Do not return anything, modify board in-place instead.
"""
'''
将字符串转为整数
'''
def to_int(s):
return ord(s)-ord('0')
row_book=[[False]*9 for _ in range(9)] # 记录行的出现数字
col_book=[[False]*9 for _ in range(9)] # 记录列的出现数字
block_book = [[[False]*9 for _a in range(9)] for _ in range(3)] # 记录子方块出现的数字
c=0
for i in range(9):
for j in range(9):
if '1'<=board[i][j]<='9':
n=to_int(board[i][j])-1
row_book[i][n]=True
col_book[j][n]=True
block_book[i//3][j//3][n]=True
else:c+=1
def dfs(c,row,col):
if c==0: # 如果所有的空白都已填满则返回True
return True
i,j=row,col
while i<9 and j<9 and board[i][j]!='.': # 找到下一个空白的格子
if j==8:
j=0
i+=1
else:j+=1
for k in range(1,10): # 开始回溯
if not row_book[i][k-1] and not col_book[j][k-1] and not block_book[i//3][j//3][k-1]:
row_book[i][k-1]=True
col_book[j][k-1]=True
block_book[i//3][j//3][k-1]=True
board[i][j]=str(k)
if dfs(c-1,i,j):return True
row_book[i][k-1]=False
col_book[j][k-1]=False
block_book[i//3][j//3][k-1]=False
board[i][j]='.'
return False # 如果没有数字可以填这个格子,返回False,方便继续回溯,因为题目保证有解,函数总会返回True,格子一定会被填满
dfs(c,0,0)1339 分裂二叉树的最大乘积
给你一棵二叉树,它的根为 root 。请你删除 1 条边,使二叉树分裂成两棵子树,且它们子树和的乘积尽可能大。 由于答案可能会很大,请你将结果对 10^9 + 7 取模后再返回。
示例
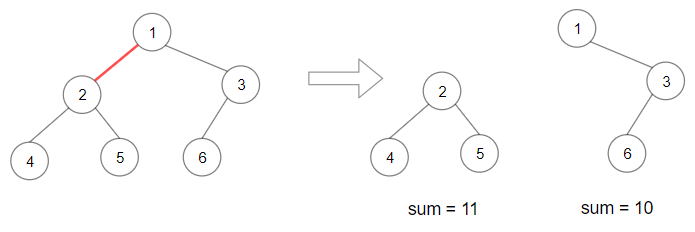
输入:root = [1,2,3,4,5,6]
输出:110
解释:删除红色的边,得到 2 棵子树,和分别为 11 和 10 。它们的乘积是 110 (11*10)
代码
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
'''
对二叉树进行遍历,把每个结点的值修改为:左子树的和+右子树的和+结点值
设树上所有结点值得和为su
再对二叉树进行遍历,并对每一个分支尝试断开,断开某一条分支后获得的乘积为
(su-root.left.val)*root.left.val
'''
def __init__(self):
self.res=0
def maxProduct(self, root: TreeNode) -> int:
su = self.summation(root)
# print(root.val)
stack=[]
p=root
while p or stack:
if p:
if p.left:
self.res=max(self.res,(su-p.left.val)*p.left.val)
stack.append(p)
p=p.left
else:
p=stack.pop()
if p.right:
self.res=max(self.res,(su-p.right.val)*p.right.val)
p=p.right
return self.res%1000000007
def summation(self,root):
if not root:return 0
left=self.summation(root.left)
right=self.summation(root.right)
root.val+=left
root.val+=right
return root.val1340 跳跃游戏 V
给你一个整数数组 arr 和一个整数 d 。每一步你可以从下标 i 跳到: i + x ,其中 i + x < arr.length 且 0 < x <= d 。 i - x ,其中 i - x >= 0 且 0 < x <= d 。 除此以外,你从下标 i 跳到下标 j 需要满足:arr[i] > arr[j] 且 arr[i] > arr[k] ,其中下标 k 是所有 i 到 j 之间的数字(更正式的,min(i, j) < k < max(i, j))。 你可以选择数组的任意下标开始跳跃。请你返回你 最多 可以访问多少个下标。 请注意,任何时刻你都不能跳到数组的外面。
示例
输入:arr = [6,4,14,6,8,13,9,7,10,6,12], d = 2
输出:4
解释:你可以从下标 10 出发,然后如上图依次经过 10 --> 8 --> 6 --> 7 。
注意,如果你从下标 6 开始,你只能跳到下标 7 处。你不能跳到下标 5 处因为 13 > 9 。你也不能跳到下标 4 处,因为下标 5 在下标 4 和 6 之间且 13 > 9 。
类似的,你不能从下标 3 处跳到下标 2 或者下标 1 处。
输入:arr = [3,3,3,3,3], d = 3
输出:1
解释:你可以从任意下标处开始且你永远无法跳到任何其他坐标。
输入:arr = [7,6,5,4,3,2,1], d = 1
输出:7
解释:从下标 0 处开始,你可以按照数值从大到小,访问所有的下标。
代码
class Solution:
def maxJumps(self, arr: List[int], d: int) -> int:
'''
记忆化搜索
设dp[i]表示从i开始最多能够访问的下标个数,dp[i]=max{dp[j}+1,其中j为i能到达的所有下标
每次我们都对该坐标两个方向搜索最多d步就可以得到dp[i]。
由于搜索时我们总是从按照高度由高往低搜索,搜索时如果dp[i]不是初始状态我们直接返回即可,不会出现死循环
'''
n=len(arr)
dp=[0]*n
res=0
def dfs(idx):
if dp[idx]!=0:return
dp[idx]=1
i=idx-1
while i>=0:
if idx-i>d or arr[i]>=arr[idx]:break
dfs(i)
dp[idx]=max(dp[i]+1,dp[idx])
i-=1
i=idx+1
while i<n:
if i-idx>d or arr[i]>=arr[idx]:break
dfs(i)
dp[idx]=max(dp[i]+1,dp[idx])
i+=1
for i in range(n):
dfs(i)
for i in range(n):
res=max(dp[i],res)
return res1361 验证二叉树
二叉树上有 n 个节点,按从 0 到 n - 1 编号,其中节点 i 的两个子节点分别是 leftChild[i] 和 rightChild[i]。 只有 所有 节点能够形成且 只 形成 一颗 有效的二叉树时,返回 true;否则返回 false。 如果节点 i 没有左子节点,那么 leftChild[i] 就等于 -1。右子节点也符合该规则。 注意:节点没有值,本问题中仅仅使用节点编号。
示例
输入:n = 4, leftChild = [1,-1,3,-1], rightChild = [2,-1,-1,-1]
输出:true
输入:n = 4, leftChild = [1,-1,3,-1], rightChild = [2,3,-1,-1]
输出:false
代码
class Solution:
def validateBinaryTreeNodes(self, n: int, leftChild: List[int], rightChild: List[int]) -> bool:
'''
并查集
每次对左右子树结点进行检查,看左右子树和父节点是否在同一个集合中,如果是,存在环,返回False
如果不是,则把子节点加入父节点的集合中
最后检查整个图的联通分量个数,因为存在整个图不连通的情况
'''
p=[i for i in range(n)]
def find(x):
while p[x]!=x:x=p[x]
return x
for i in range(n):
pa=find(i)
if leftChild[i]!=-1:
pl=find(leftChild[i])
if pl==pa:return False
p[leftChild[i]]=i
if rightChild[i]!=-1:
pr=find(rightChild[i])
if pr==pa:return False
p[rightChild[i]]=i
c=0
for i in range(n):
if p[i]==i:c+=1
return c==1