yesvods / blog Goto Github PK
View Code? Open in Web Editor NEWIndeed insight in Full Stack
Indeed insight in Full Stack



















































































































在react生态圈里面,组件的设计非常自由。因为react本身只提供组件渲染以及生命周期,至于用户交互、数据交互、组件状态之间的关系,并没有强关联。
long long age,人们对组件模式毫无感知,只知道input渲染一个输入框,设置value输入框就有这个值。自组件化盛行,便衍生出另外两种极端的设计模式。
顾名思义,就是会被父组件控制的组件,其状态完全决定于父组件。拿我们最熟悉的input组件来举个栗子。控制组件input会有一个value的参数,输入框内容决定于value,除非它变化了,不然输入框内容不会更改。
class input extends Component {
render(){
return (
<input type="text" value="i won't be change whatever you do" />
)
}
}
这样,无论用户如何输入,输入框内容都可以保持不变,当然我们可以监听用户输入事件来相应改变value:
class input extends Component {
render(){
return (
<input type="text" value={this.state.v} onChange={e => {
this.setState({v: e.target.value})
}}/>
)
}
}
与控制组件相反,非常自由,不会带有value属性,自我管理状态,通常非控制组件需要一个默认值defaultValue,自此之后,父组件对非控制组件状态再也无能为力。
class input extends Component {
render(){
return (
<input type="text" defaultValue="i will change to what you input" />
)
}
}
实际应用下,非控制组件用武之地非常少,一般用于状态与外界毫无交互关联时。
好了,上面都是废话,想要更详细了解控制、非控制组件,可以参考react官网文章下面才是有用的。
我们平时写HTML用的input组件都很灵活,比如:
<input value="可以当默认状态用啦">
还可以用js来改变状态,当然,就算用js直接改写状态,dom节点的value还是以前的那个。
inputDom.value = "我变了,js先动的手"
inputDom.value // "我变了,js先动的手"
inputDom.getAttribute('value') //"可以当默认状态用啦"
我们习惯于灵活地使用一个组件,也就是说,用户输入了,你得变。从网络上拿到数据了,你也要更新自己啊。灵活的组件模式,状态会被外部以及用户改变。
class input extends Component {
constructor(props){
//初始化时候你以为就不用工作了吗,变!
this.state = {v: props.value}
}
componentDidMount(){
this.count = 0;
setInterval(()=> {
//说不定要定时从外面拿点资料更新一下呢
this.setState({v: this.count++});
}, 2000)
}
componentWillReceiveProps(nextProps){
//喏,父组件要你变,你也得改变一下啊
this.setState({v: nextProps.value});
}
render(){
return (
<input type="text" value={this.state.v} onChange={e => {
//你看,用户输入也要改变状态啊,好累
this.setState({v: e.target.value})
}}/>
)
}
}这组件好强啊,什么场景都可以用。那有什么缺点吗,别跟我说prefect。
好吧,其实,有两个问题:
在很多场景,需要管理表单的状态,又不能限制组件的状态灵活度,一般会使用第三种设计模式来做表单组件。我们可以通过其他途径直接获得子组件的内部真实状态,通过context或者回调方法,让子组件主动上报自己的状态,父组件对状态做一个汇总。(真实组织信息传递形式周报,好像发现了什么)。
组件设计模式有三种:控制组件,非控制组件,混合控制组件。实际工作中,让所有react表单组件遵循第三种设计模式,可以很清晰设计出灵活通用的组件。并通过状态收集机制(排期到后面的文章),一套健壮的组件就出炉了。
第一篇介绍的是redux作为状态容器的核心**,由state初始化,到action被分发而改变状态。之后的扩展都是围绕核心**展开,也正得益于函数式编程等其他扩展,redux成为目前最流行的react状态管理框架。
redux里面,store实例拥有四个方法:getState,dispatch,subscribe,replaceReducer。
其中前两个是store的核心方法,分别用于获取状态以及改变状态。
subscribe用于订阅状态更改事件,每当store的状态改变后,订阅的函数就会被调用。
replaceReducer用于替换创建store的reducer,比如从页面A跳转到页面B后,仅仅需要替换reducer就可以让B页面使用所需的状态,在按需加载状态时候非常有用。
精简后的store创建代码非常简单:
function createStore(reducer, initialState){
let currentState = initialState;
return {
getState: () => currentState,
dispatch: action => {
currentState = reducer(currentState, action)
}
}
}reducer是一个简单的纯函数(currentState, action) => nextState
接收现在的状态以及action作为参数,根据action的类型以及信息,对state进行修改,返回最新的state。
比如一个动物园有猫和狗,现在需要添加一些猫猫狗狗:
function cat(state = [], action){
if(action.type === constant.ADD_CAT){
state.push(action.cat);
return state;
}else {
return state;
}
}
function dog(state = [], action){
if(action.type === constant.ADD_DOG){
state.push(action.dog);
return state;
}else {
return state;
}
}//添加Tom猫
dispatch({
type: constant.ADD_CAT,
cat: {
name: 'Tom'
}
});
//添加Jerry狗
dispatch({
type: constant.ADD_DOG,
dog: {
name: 'Jerry'
}
});之前提及到的是单一数据源原则,一个应用应该只有一个数据源(state),但是一个reducer会产生一个state,那怎么把猫狗两个reducer合成一个呢。redux提供了工具函数combineReducers,把多个reducre进行结合。我们可以编写多个reducer函数,每个函数只专注于自己的状态修改(比如cat函数,只专注于对cat这个状态的修改,不管dog的状态)。
而且,通过combineReducers合成一个reducer后,可以继续使用combineReducers把合成过的reducers进行再次合成,这样就非常方便地产生一个应用状态树,这也是为什么reducr仅仅需要一个数据源,便可以管理大型应用整个状态的原因。
比如:
//homeAnimals就成为一个reducers
const homeAnimals = combineReducers({cat, dog});// nextState:
// {
// cat: [{...}],
// dog: [{...}]
// }
const nextState = homeAnimals(state, action);更高层级的状态树:
cons zoo = combineReducers(homeAnimals, otherAnimals);// nextState:
// {
// homeAnimals: {...},
// otherAnimals: {...}
// }
const nextState = zoo(state, action);合成的reducerzoo就会产生更深嵌套的状态树。
作者:Dan Abramov
译者:Jogis
原文日期:2015/12/18
原文链接:http://facebook.github.io/react/blog/2015/12/18/react-components-elements-and-instances.html
很多React新手对Components以及他们的instances和elements之间的区别感到非常困惑,为什么要用三种不同的术语来代表那些被渲染在荧屏上的内容呢?
如果是刚入门React,那么你应该只是接触过一些组件类(component classes)以及实例(instances)。打比方,你可能通过class关键字声明了一个Button组件。这个程序运行时候,可能会有几个Button组件的实例(instances)运行在浏览器上,每一个实例会有各自的参数(properties)以及本地状态(state)。这种属于传统的面向对象UI编程。那么为什么会有元素(elements)出现呢?
在这种传统UI模式上,你需要负责创建和删除实例(instances)的子组件实例。如果一个Form的组件想要渲染一个Button子组件,需要实例化这个Button子组件,并且手动更新他们的内容。
class Form extends TraditionalObjectOrientedView {
render() {
// Read some data passed to the view
const { isSubmitted, buttonText } = this.attrs;
if (!isSubmitted && !this.button) {
// Form is not yet submitted. Create the button!
this.button = new Button({
children: buttonText,
color: 'blue'
});
this.el.appendChild(this.button.el);
}
if (this.button) {
// The button is visible. Update its text!
this.button.attrs.children = buttonText;
this.button.render();
}
if (isSubmitted && this.button) {
// Form was submitted. Destroy the button!
this.el.removeChild(this.button.el);
this.button.destroy();
}
if (isSubmitted && !this.message) {
// Form was submitted. Show the success message!
this.message = new Message({ text: 'Success!' });
this.el.appendChild(this.message.el);
}
}
}
这个只是伪代码,但是这个就是大概的形式。特别是当你用一些库(比如Backbone),去写一些需要保持数据同步的组件化组合的UI界面时候。
每一个组件实例需要保留它的DOM节点引用和子组件的实例,并且需要在合适时机去创建、更新、删除那些子组件实例。代码行数会随着组件的状态(state)数量,以平方几何级别增长。而且这样,组件需要直接访问它的子组件实例,使得这个组件以后非常难解耦。
于是,React又有什么不同呢?
React提出一种元素(elements)来解决这个问题。一个元素仅仅是一个纯的JSON对象,用于描述这个组件的实例或者是DOM节点(译者注:比如div)和组件所需要的参数。元素仅仅包括三个信息:组件类型(例如,Button)、组件参数(例如:color)和一些组件的子元素
一个元素(element)实际上并不等于组件的实例,更确切地说,它是一种方式,去告诉React在荧屏上渲染什么,你并不能调用元素的任何方法,它仅仅是一个不可修改的对象,这个对象带有两个字段:type: (string | ReactClass)和props: Object[1]
当一个元素的type是一个字符串,代表是一个type(译者注:比如div)类型的DOM,props对应的是这个DOM的属性。React就是根据这个规则来渲染,比如:
{
type: 'button',
props: {
className: 'button button-blue',
children: {
type: 'b',
children: 'OK!'
}
}
}
这个元素只是用一个纯的JSON对象,去代表下面的HTML:
<button class='button button-blue'>
<b>
OK!
</b>
</button>
需要注意的是,元素之间是怎么嵌套的。按照惯例,当我们想去创建一棵元素树(译者注:对,有点拗口),我们会定义一个或者多个子元素作为一个大的元素(容器元素)的children参数。
最重要的是,父子元素都只是一种描述符,并不是实际的实例(instances)。在他们被创建的时候,他们不会去引用任何被渲染在荧屏上的内容。你可以创建他们,然后把他们删掉,这并不会对荧屏渲染产生任何影响。
React元素是非常容易遍历的,不需要去解析,理所当然的是,他们比真实的DOM元素轻量很多————因为他们只是纯JSON对象。
然而,元素的type属性可能会是一个函数或者是一个类,代表这是一个React组件:
{
type: Button,
props: {
color: 'blue',
children: 'OK!'
}
}
这就是React的核心灵感!
一个描述另外一个组件的元素,依旧是一个元素,就像刚刚描述DON节点的元素那样。他们可以被嵌套(nexted)和相互混合(mixed)。
这种特性可以让你定义一个DangerButton组件,作为一个有特定Color属性值的Button组件,而不需要担心Button组件实际渲染成DOM的适合是button还是div,或者是其他:
const DangerButton = ({ children }) => ({
type: Button,
props: {
color: 'red',
children: children
}
});
在一个元素树里面,你可以混合配对DOM和组件元素:
const DeleteAccount = () => ({
type: 'div',
props: {
children: [{
type: 'p',
props: {
children: 'Are you sure?'
}
}, {
type: DangerButton,
props: {
children: 'Yep'
}
}, {
type: Button,
props: {
color: 'blue',
children: 'Cancel'
}
}]
});
或者可能你更喜欢JSX:
const DeleteAccount = () => (
<div>
<p>Are you sure?</p>
<DangerButton>Yep</DangerButton>
<Button color='blue'>Cancel</Button>
</div>
);
这种混合配对有利于保持组件的相互解耦关系,因为他们可以通过组合(componsition)独立地表达is-a()和has-a()的关系:
Button是一个附带特定参数的<button>DOMDangerButton是一个附带特定参数的ButtonDeleteAccount在一个<div>DOM里包含一个Button和一个DangerButton当React看到一个带有type属性的元素,而且这个type是个函数或者类,React就会去把相应的props给予元素,并且去获取元素返回的子元素。
当React看到这种元素:
{
type: Button,
props: {
color: 'blue',
children: 'OK!'
}
}
就会去获取Button要渲染的子元素,Button就会返回下面的元素:
{
type: 'button',
props: {
className: 'button button-blue',
children: {
type: 'b',
children: 'OK!'
}
}
}
React会不断重复这个过程,直到它获取这个页面所有组件潜在的DOM标签元素。
React就像一个孩子,会去问“什么是 Y”,然后你会回答“X 是 Y”。孩子重复这个过程直到他们弄清楚这个世界的每一个小的细节。
还记得上面提到的Form例子吗?它可以用React来写成下面形式:
const Form = ({ isSubmitted, buttonText }) => {
if (isSubmitted) {
// Form submitted! Return a message element.
return {
type: Message,
props: {
text: 'Success!'
}
};
}
// Form is still visible! Return a button element.
return {
type: Button,
props: {
children: buttonText,
color: 'blue'
}
};
};
就是这么简单!对于一个React组件,props会被作为输入内容,一个元素会被作为输出内容。
被组件返回的元素树可能包含描述DOM节点的子元素,和描述其他组件的子元素。这可以让你组合UI的独立部分,而不需要依赖他们内部的DOM结构。
React会替我们创建更新和删除实例,我们只需要通过组件返回的元素来描述这些示例,React会替我们管理好这些实例的操作。
在上面提到的例子里,Form,Message和Button都是React组件。他们都可以被写成函数形式,就像上面提到的,或者是写成继承React.Component的类的形式。这三种声明组件的方法结果几乎都是相同的:
// 1) As a function of props
// 1) 作为一个接收props参数的函数
const Button = ({ children, color }) => ({
type: 'button',
props: {
className: 'button button-' + color,
children: {
type: 'b',
props: {
children: children
}
}
}
});
// 2) Using the React.createClass() factory
// 2) 使用React.createClass()的工厂方法
const Button = React.createClass({
render() {
const { children, color } = this.props;
return {
type: 'button',
props: {
className: 'button button-' + color,
children: {
type: 'b',
props: {
children: children
}
}
}
};
}
});
// 3) As an ES6 class descending from React.Component
// 3) 作为一个ES6的类,去继承React.Component
class Button extends React.Component {
render() {
const { children, color } = this.props;
return {
type: 'button',
props: {
className: 'button button-' + color,
children: {
type: 'b',
props: {
children: children
}
}
}
};
}
}
当组件被定义为类,它会比起函数方法的定义强大一些。它可以存储一些本地状态(state)以及在相应DOM节点创建或者删除时候去执行一些自定义逻辑。
一个函数组件会没那么强大,但是会更简洁,而且可以通过一个render()就能表现得就像一个类组件一样。除非你需要一些只能用类才能提供的特性,否则我们鼓励你去使用函数组件来替代类组件。
然而,不管是函数组件或者类组件,基本来说,他们都属于React组件。他们都会以props作为输入内容,以元素作为输出内容
当你调用:
ReactDOM.render({
type: Form,
props: {
isSubmitted: false,
buttonText: 'OK!'
}
}, document.getElementById('root'));
React会提供那些props去问Form:“请你返回你的元素树”,然后他最终会使用简单的方式,去“精炼”出他对于你的组件树的理解:
// React: You told me this...
{
type: Form,
props: {
isSubmitted: false,
buttonText: 'OK!'
}
}
// React: ...And Form told me this...
{
type: Button,
props: {
children: 'OK!',
color: 'blue'
}
}
// React: ...and Button told me this! I guess I'm done.
{
type: 'button',
props: {
className: 'button button-blue',
children: {
type: 'b',
props: {
children: 'OK!'
}
}
}
}
这部分过程被React称作协调(reconciliation),在你调用ReactDOM.render()或者setState()的时候会被执行。在协调过程结束之前,React掌握DOM树的结果,再这之后,比如react-dom或者react-native的渲染器会应用最小必要变更集合来更新DOM节点(或者是React Native的特定平台视图)。
这个逐步精炼的过程也说明了为什么React应用如此容易优化。如果你的组件树一部分变得太庞大以至于React难以去高效访问,在相关参数没有变化的情况下,你可以告诉React去跳过这一步“精炼”以及跳过diff树的其中一部分。如果参数是不可修改的,计算出他们是否有变化会变得相当快。所以React和immutability结合起来会非常好,而且可以用最小的代价去获得最大的优化。
你可能发现这篇博客一开始谈论到很多关于组件和元素的内容,但是并没有太多关于实例的。事实上,比起大多数的面向对象UI框架,实例在React上显得并没有那么重要。
只有类组件可以拥有实例,而且你从来不需要直接创建他们:React会帮你做好。当存在父组件实例访问子组件实例的情况下,他们只是被用来做一些必要的动作(比如在一个表单域设置焦点),而且通常应该要避免这样做。
React为每一个类组件维护实例的创建,所以你可以以面向对象的方式,用方法和本地状态去编写组件,但是除此之外,实例在React的变成模型上并不是很重要,而且会被React自己管理好。
元素是一个纯的JSON对象,用于描述你想通过DOM节点或者其他组件在荧屏上展示的内容。元素可以在他们的参数里面包含其他元素。创建一个React元素代价非常小。一个元素一旦被创建,将不可更改。
一个组件可以用几种不同的方式去声明。可以是一个带有render()方法的类。作为另外一种选择,在简单的情况下,组件可以被定义为一个函数。在两种方式下,组件都是被传入的参数作为输入内容,以返回的元素作为输出内容。
如果有一个组件被调用,传入了一些参数作为输入,那是因为有一某个父组件返回了一个带有这个组件的type以及这些参数(到React上)。这就是为什么大家都认为参数流动方式只有一种:从父组件到子组件。
实例就是你在组件上调用this时候得到的东西,它对本地状态存储以及对响应生命周期事件非常有用。
函数组件根本没有实例,类组件拥有实例,但是你从来都不需要去直接创建一个组件实例——React会帮你管理好它。
最后,想要创建元素,使用React.createElement(),JSX或者一个元素工厂工具。不要在实际代码上把元素写成纯JSON对象——仅需要知道他们在React机制下面以纯JSON对象存在就好。
[1]. 出于安全考虑,所有React元素需要在对象下声明一个额外的$$typeof: Symbol.for(‘react.element’)字段。它在上面的例子被忽略了。这篇博客从头开始用行内对象来表示元素,来告知你底层运作的概念。但是,除非你要么添加$$typeof到元素上或者用React.createElement或JSX去修改上面的代码,否则那些代码并不能正常执行。
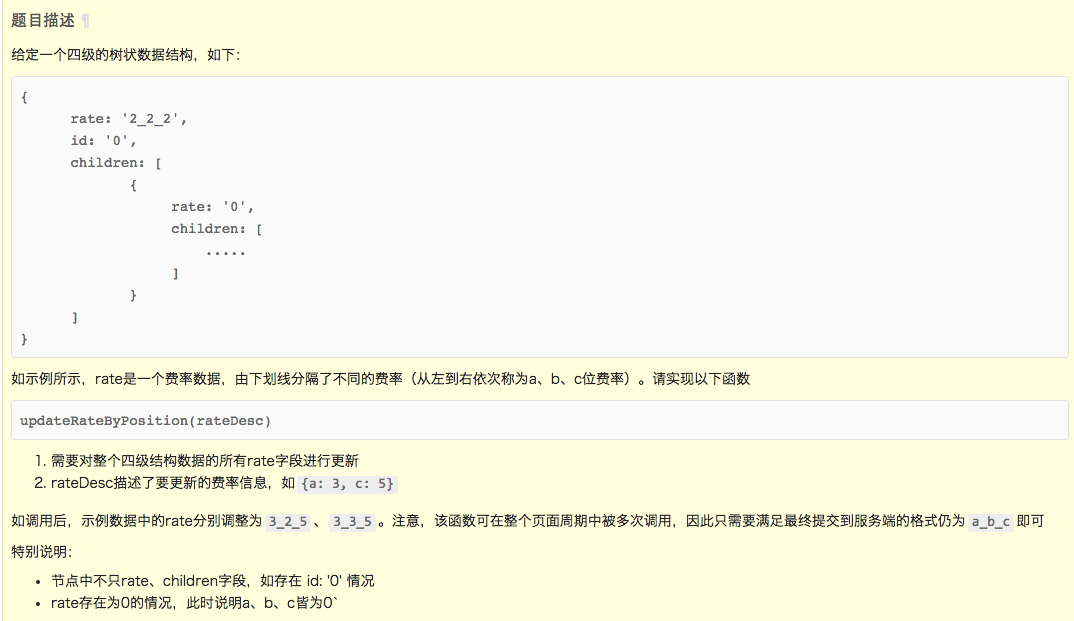
前一篇文章介绍了webpack以及安装方法,本文将会介绍webpack在单页面应用程序(Single Page Application)与多页面站点不同场合的用法。
跟其他模块加载器类似,webpack也是需要配置一个入口文件,比如是entry.js
有几种配置方式,下面来介绍一下直接把入口文件写在配置文件 webpack.config.js:
module.exports = {
entry: {
"entry":"./entry.js"
},
output: {
path: "build"
filename: "bundle.js"
}
}
通过命令行
> webpack
很便利地,webpack检测配置文件,读取模块入口与输出路径和文件名,将文件依赖整合成一个文件,输出到build/bundle.js
通过在HTML简单引入
<script src="./build/bundle.js"></script>
就可以在浏览器运行。
简单的SPA程序加载,包括:JS编译与加载、CSS编译与加载、图片加载与压缩、JS与CSS压缩。
Webpack提供了一套加载器机制,比如:css-loader、style-loader、url-loader等,用于将不同资源加载到js文件中,例如url-loader用于在js中加载png/jpg格式的图片文件,css/style loader 用于加载css文件,less-loader用于将less文件编译成css。
下面介绍一些常用的加载器(详细介绍在这里):
style+css+less加载Bootstrap less版本:
require('style!css!less!./bower_components/bootstrap/bootstrap.less');
style+css 加载一般样式文件:
require('style!css!./styles/main.css');
url 加载图片资源文件:
require('url!./images/logo.png');
json loader加载json格式文件:
require('json!./data.json');
js后缀的文件不需要使用加载器
require('./scripts/main.js');
coffee script加载
require('coffee!./scripts/main.coffee');
喜欢尝鲜的童鞋可以通过Babel loader体验ES6/7特性:
require('babel!./scripts/es6.js');
需要注意的是,避免用babel作为加载器加载所有node_module模块,会出现意外结果,而且大量加载情况下,加载时间很长。babel还可以用作reactjs jsx文件加载使用,详细请看。
刚刚介绍了行内加载资源的方式,如果有很多css或者图片资源需要加载,重复写加载器显得很笨拙,webpack提供另一种方式加载资源。
在配置文件添加配置:
module.exports = {
module: {
loaders: [
{test: /.css$/, loader: "style!css"},
{test: /.(png|jpg)$/, loader: "url-loader?limit=8192"}
]
}
}
其中test是正则表达式,对符合的文件名使用相应的加载器
/.css$/会匹配 xx.css文件,但是并不适用于xx.sass或者xx.css.zip文件
/.css/除了匹配xx.css也可以匹配xx.css.zip
加载器后可以加入?xx=yy传递参数,表示添加将xx设置为yy(跟http地址Query很像)
需要注意的是,使用加载器前需要使用
> npm i --save xxx-loader
安装相应加载器,并通过--save把依赖配置到package.json中,使用加载器并不需要使用require引入。
以上介绍的加载器,可以很方便使用webpack整合日常资源,如果认为webpack仅仅只能做这些,那就让您失望了。
可以看到,以上加载资源时候,都使用相对路径来描述路径,对于那些./app/src/scripts/main.js通过修改webpack配置文件,添加默认搜索路径后,显得更加优雅。
// webpack.config.js
var path = require("path")
module.exports = {
resolve: {
alias: {
js: path.join(__dirname, "./app/src/scripts")
}
}
}
require("js/main.js");
默认搜索路径配置
对于bower_components死忠们,前端开发少不了几个bower插件,使用gulp可以通过gulp-wiredep来动态把bower.json dependencies加载到指定HTML文件。
在webpack也有非常便利的导入方法:
首先,加入配置
module.exports = {
resolve: {
alias: {
js: path.join(__dirname, "src/scripts"),
src: path.join(__dirname, "src/scripts"),
styles: path.join(__dirname, "src/styles"),
img: path.join(__dirname, "src/img")
},
root: [
path.join(__dirname, "bower_components")
]
},
plugins: [
new webpack.ResolverPlugin(
new webpack.ResolverPlugin.DirectoryDescriptionFilePlugin(".bower.json", ["main"])
)
]
}
resolve.root 表示添加默认搜索路径,使用如下语法:
require("jquery");
webpack会在bower_components/jquery目录下进行查找CommandJS模块node_module/index.js、index.js
但是,因为Bower不属于CommandJS规范范畴,使用的是bower.json main属性指定项目入口文件
说到这里,大家就知道plugins里面那串东东是干嘛的啦
之后,我们就可以很方便在任何js文件里面引用jquery:
var jQuery = $ = require("jquery");
需要注意的是,require的并非jquery.js,而是bower_components目录下的文件夹名
webpack 不仅仅适用于SPA开发,对于多页面站点,webpack支持得很好,通过更改配置文件为多入口:
module.exports = {
entry: {
"entry":"./src/scripts/entry.js",
"swiperEffect":"./src/scripts/swiperEffect.js"
},
output: {
path: "build"
filename: "[name].bundle.js"
}
}
output设置里面,[name]代表entry的每一个键值,因此运行webpack时候,会输出对应的两个文件:
build/entry.bundle.js
build/swiperEffect.bundle.js
然后就可以在index.html和about.html两个页面分别引用啦
前端工程一项就是减少http请求,这表示需要把多个js合并成一个,但是,单个js文件过大会影响浏览器加载文件速度,由于现在浏览器并发http请求多达6个,可以利用这个特性,将可复用第三方资源库分离加载。
使用CommandJS规范的
//entry.js
require.ensure(["jquery", "imgScroll"], function(require){
var $ = require("jquery");
require("imgScroll");
$("#container").scroll({
XXX
})
})
通过require.ensure声明的文件,称作按需加载依赖,这些依赖会独立出来一个文件,待入口模块加载完,需要请求时候才会相继加载
再次编译webpack:
build/entry.bundle.js
build/swiperEffect.bundle.js
build/2.2.bundle.js
其中2.2.bundle.js就是jquery+imgScroll异步加载内容
可以看到2.2.bundle.js在entry.bundle.js加载完后进行异步加载。
除了简单运行webpack,还可以添加几个参数,方便部署文件处理。
输出js文件,经过uglify进行压缩:
> webpack -p
自动监听变化,动态运行webpack编译:
> webpack --watch
通常Dev阶段,使用--watch配合live-server就可以自动化开发繁琐的窗口切换与回车。
以上仅仅介绍了webpack前端开发最基本的用法,更多参数以及功能使用,参考官网
最近举行了一场盛大的前端算法大比拼,题目从真实业务场景中抽取出来,童鞋们纷纷摩拳擦掌展示自己算法基本功。题目如下:
真实场景里面,有7M左右的JSON数据需要统一更新费率,据说一开始处理这堆数据一次就得耗费20+秒。在浏览器场景下,这意味着这段时间UI渲染被阻塞,用户交互完全无响应。最后经过调整的算法,也需要1秒左右的执行时间,非常影响用户体验。
略懂浏览器动画的童鞋都知道,在浏览器一帧里面layout、合成、渲染占据了不少CPU时间,真实交给js进行运行的时间只有不到10ms。在如此大数据量处理的场景下要保持丝般顺滑的用户体验,算法必不可少,可见算法对于前端依旧非常重要。
鄙人也参加了大比拼,分享一下自己的小小心得,总结一下如何将7M数据处理从1000ms降到10ms以下。
从题目的数据结构可以看到,这是一个多叉树,第一时间联想到的是树的遍历。
借鉴函数式编程**,树的处理只需要三个步骤:
函数递归遍历
使用processor处理每一个树节点
葛优躺...
Talk is cheap, show me the code.
树的遍历:
function trav(tree, processor){
if(!tree.children) return;
for(var i in tree.children){
let node = tree.children[i];
processor(node);
if(item.children){
trav(item, process)
}
}
}处理器:
function processor(node){
//...预处理
let values = node.rate.split('_');
values[0] = '3';
values[1] = '5';
node.rate = values.join('_');
}好,大功告成,跑一下。。。43ms??!
不科学!这在浏览器特喵的已经卡了一会了。
肯定哪里有问题,先看一下树遍历。
result: 3ms
唔..只用了3ms,对于大量数据遍历这个时间也说得过去,不是性能瓶颈。
那就只有处理器出问题了,细看一下:
// node.rate.split('_')
result 10ms+
// values[0] = '3';
// values[1] = '5';
result 10ms+
// values.join('_');
result 10ms+出乎意料,在大量重复调用情况下,就算是一个普通的方法也会产生大量性能损耗。大家应该也听说过字符串处理是特别费性能的,处理不当就会产生不少问题。
从上面的运行可以看出,无论是字符串的分离或者合并,还是数组的赋值都会导致性能损耗。平时这么说早被人打死了,什么性能损耗,能跑就行。在真正性能瓶颈上,这些细节尤为关键。
实际上,我们只是需要根据现有费率+要修改费率组成出一个新费率。我们可以把这些操作做成
把多次写、赋值操作,改成一次低性能损耗的字符串合并。
好好好,你们要的code
//读取
function getValue(pos, raw, position, resMap){
if(position.indexOf(pos) === -1) return raw.charAt(pos * 2);
return resMap[pos];
}
//合并
function concat(raw, position, resMap){
let str = '';
str = str+getValue(0, raw, position, resMap)+'-'+getValue(1, raw, position, resMap)+'-'+getValue(2, raw, position, resMap);
return str;
}于是..最终的处理器代码应该是酱紫的:
trav(this.data, item => {
if(!item.rate) item.rate = '0_0_0';
item.rate = concat(item.rate, position, resMap);
});最终的最佳跑分结果是:
result: 6.666..ms
在处理字符串合并时候依然需要注意的是,不同的合并方式,系统调度是不一样的。
//产生3次变量调度, tmpVal = 'hehe', tmpVal2 = val1 + 'hehe', tmpVal3 = tmpVal2 + val2;
let str = val1 + ' hehe ' + val2 ;
//产生1次变量调度, tmpVal = 'hehe', tmpVal +=val1, tmpVal +=val2
let str = ' hehe ' + val1 + val2
随着前端项目越来越复杂(尤其是大型SPA),以及命名空间混乱,一系列模块加载器随之而生。
Javascript模块标准有:AMD 和 CommonJS
最有名的加载器有:RequireJS、SeaJS、Bowserify
那么,有人就会问,这么多模块加载器,为什么还要重复发明轮子?
童鞋们*安勿燥,下面为大家娓娓道来 Webpack的特性以及使用入门。
现有的模块加载器,不能很好适配大型项目(大型单页面应用程序)开发。开发这样一款加载器最大原因,就是为了代码分离以及静态资源模块化无缝接合。
尽管尝试去拓展现有的模块加载器,但最后发现不可能完成所有功能目标。
Webpack有两种依赖声明方式:同步与异步。异步方式,将依赖分割成多个节点,然后每个节点形成一个新的文件块。经过优化后的文件块树,会以一个个文件形式分发出去(仅仅打包成一个大文件形式是很低效的,详见)。
原生的Webpack只能处理JS文件,使用加载器插件,可以将其他资源专为JS资源。通过这种方式来加载,每一种资源都可以被Webpack看作是一个模块来加载。
Webpack内置一个智能加载模块,可以用于处理几乎所有的第三方库。它甚至可以解析依赖声明的表达式,比如 require("./templates" + name + ".jade")。Webpack会处理最常见的JS模块标准:CommonJS 和 AMD。
Webpack的最大特点,就是配套了非常丰富的插件系统。大部分内置特性功能都是基于这套插件系统。它可以让你根据需要自定义Webpack,将一般插件作为开源项目发布出去。
npm install -g webpack
项目中初始化Webpack
最优的方式就是,在项目中声明Webpack依赖。通过声明依赖,可以选择一个本地的Webpack版本,而不需要使用全局声明的版本。
添加一个npm 配置文件package.json:
npm init
然后需要回答一系列问题。如果希望把自己项目发布到npm上面,这些问题的回答非常重要。(如果不需要的话,一直回车就好啦)
安装webpack、添加依赖到package.json
npm install webpack --save-dev
其中--save-dev就是声明在开发阶段需要用到webpack,并且自动把webpack依赖写到package.json配置文件上面,生产环境就不需要安装(上生产环境时候,webpack已经把项目打包好啦,不需要它老人家出马了)
同步与异步加载,往往是指网络资源,像图片、样式、脚本等。本文探索在PCWeb下,同步&异步性能差距到底有多少?为何移动端的优秀方案到PCWeb,会造成性能问题?
我们只声明单一的静态脚本资源。
<script src="./react.js"><script>
使用简单脚本发起资源请求。
<script>
var s = document.createElement('script')
s.src="./react.js"
document.body.appendChild(s)
</script>
看到结果很惊诧,仅仅是一个不一样的加载方式,导致的是40ms与400ms的差异。那么,这段时间里面,浏览器到底去干啥了。
通过图示,说明了几个问题
同步加载,是否会受插件影响?
分析:
可以看到高优先级的资源,比部分插件脚本有更高执行优先级,浏览器会“尽可能快”地加载执行。
在插件环境下,加载会被各种插件干预,那么纯粹的异步(low)同步(high)在Webkit浏览器加载的差距是怎样的呢?我们通过切换至隐身模式,消除所有插件影响,注意需要将所有插件的”隐身可用“取消勾选。
在OSX环境下,Shift+CMD+N启用隐身模式,在某些情况有特别的妙用..
结论是:同步的高优先级获得优先系统调度,与异步加载有略微优势
PCWeb下,同步加载的特性,比起异步加载有非常大的优势。在某些场景下,还有一些"绝妙"的用法。
在大家的认知里,JSONP,往往是另外一种异步请求的方式,其主要优点是支持跨域数据请求。因此,JSONP往往是将一个Script节点动态插入document,随后浏览器会自动发起一个远程请求。
除了上述单一用法外,在PCWeb,JSONP具有非常巨大的性能&工程化价值。
通过【图说舌尖上的脚本】与【同步vs异步加载】了解到,PCWeb受限于插件环境,异步机制变得非常不吃香。异步发起的请求,无论是JSONP等资源加载,抑或XHR(fetch),都会被标记为低优先级。
我们来看一下,发起6个异步JSONP是怎样的情况:
<script>
function appendScript(src){
var s = document.createElement('script')
s.src = src
document.body.appendChild(s)
}
for(let i=0;i<6;i++){
appendScript(`./react.js?v=${i}`)
}
</script>
结果跟之前分析的异步请求别无二致,异步JSONP默默低下了头。
举个栗子,在实际PC场景,无论采用的是React Or Vue Or what ever. 我们都需要在渲染前加载一堆组件,数据+模板(JSX etc.)+组件方式,来实现渲染。我们在渲染页面前就需要加载一堆资源,有时候甚至可以达到2M之大!
这块大资源并没有错(有时候利用一块大资源,比起每次加载不一样非缓存资源性能还高),但是在浏览器加载这块大头时候,脚本的解析、编译、执行,也随着体积增长(特别是执行耗时)。当然,这也有一些办法可以减轻这些负担(未完,待续..)。然而,我们可以利用上面介绍到的同步JSONP优雅地减少页面加载时间!我们先来回顾一下部分原理:
因为主线程被阻碍了,后面的解析工作没有办法继续往下进行,
当遇到这种情况,WebKit会启动另外一个线程去遍历后面的HTML,
收集需要的资源URL,然后发送请求,这样就可以避免阻塞。
———— 《WebKit技术内幕》
我们把资源都看成一个大体积Bundle,在HTML解析到这个脚本时,由于无需下载(memory cached Or disk cached),接下来就是漫长的解析、编译、执行。但是,我们可不能让浏览器闲着,通过同步JSONP,在Bundle后面声明一堆以后渲染要用的页面数据。这样,浏览器主进程漫长的阻塞执行过程中,相关的数据已经被网络模块准备就绪,由于模块数据相对体积小,因此没有解析/编译/执行成本。
<script src="BigBundle.js"></script>
<script src="parallelData1.js"></script>
<script src="parallelData2.js"></script>
<script src="parallelData3.js"></script>
<script src="parallelData4.js"></script>
<script src="parallelData5.js"></script>
<script src="parallelData6.js"></script>
我们一直提到的是,在PCWeb页面初始化场景,异步加载都会面临性能问题。而上述的方案通过所有资源同步的方式实现,用最高优先级来渲染初始页。
在鄙人的某些业务场景下,真实用到同步加载Bundle,异步获取资源,首屏渲染时间惨不忍睹。仅仅通过资源JSONP同步化,还没做其他优化😕,首屏时间直接从2.1s,下降至1.4s😱。
Hyperapp是一个轻量级视图库,拥有完备的界面渲染、以及视图数据交互更新能力。专注于视图渲染的核心部分,使得它的体积非常轻巧,也使得它具备"无限可能"。在设计上并无涉及太多复杂场景,尤为适用于轻量级的移动开发场景。
Hyperapp仅关心状态渲染、调度生成后actions对象。在状态管理上,我们可以自主使用flux、redux,甚至无需使用任何状态管理库。
Hyperapp提供vnode生成辅助函数,但并不限制渲染模板的选择,我们可以自由选择类似JSX,甚至类VUE的模板语言。
在Hyperapp初始渲染之后,触发视图更新的唯一方式是,通过调用action变更状态,从而触发视图更新。这使得我们可以建立易于跟踪、健壮、可维性强的应用。
详细的分析,可以在源码注释仓库下看到,里面有hyperapp各个源码重要细节的分析。下面来介绍一下hyperapp源码有意思的地方:
专注于视图渲染&数据交互更新,在实现上也是恰到好处地实现这些功能。具备内置状态驱动的视图更新引擎、标准VNode四板斧、DOM-diff机制。在这点来说,hyperapp处于新生期,需要具备完善的生态,才可以发挥出强大的内核能力。
VNode四板斧:
// 基本的HTML标签都可以被抽象成如下形式:
// {
// nodeName,
// attributes,
// children,
// key
// }
// TextNode只有一个nodeValue,SVG也是比较特殊,所以在更新时候也会对这两种类型做特殊处理DOM-diff 原则:
// 1. 平级对比,非平级则认为是不一样的dom,直接铲平重建
// 2. 只更新同类型节点,非同类型一样铲平重建
// 3. 尽可能利用现有dom,免除额外的删除创建开销,只需要重新插入(appendChild or insertBefore)
// 4. index&key相同的vdom,对应的dom无需对比,直接复用,下一个!hyperapp在细看一些实现上,会觉得有些"不严谨",可能会被钻空子。比如:clone、get等函数实现,或者是Promise、Array的判断。
事实上,这些函数用于在有标准DOM结构的实现、自调用的源码上,作为判断能达到"刚刚好"的要求。既不会浪费性能体积,也不会导致出错。
function get(path, source) {
for (var i = 0; i < path.length; i++) {
source = source[path[i]]
}
return source
}
// const result = { winner: { name: 'Tony' } }
// get(['winner', 'name'], result) => Tony不必具备lodash get的兼容性,以最优形态抽象出适用于源码的函数,便是最好的。
说出来你可能不信,hyperapp仅有四个生命周期函数。
他们分别是:
oncreate(DOMElement)onupdate(DOMElement)onremove(DOMElement, action)ondestory(DOMElement)这使得hyperapp比较适用于轻交互场景,配合webpack的模板语法编译能力,可以实现非常轻量级的移动应用。
在列表渲染时候,hyperapp严格要求组件提供对应key属性。
如果没有对应的key,相当于默认每次渲染都是全新的列表,这会涉及到原有列表DOM的销毁、新列表DOM创建以及添加,大型列表上有可能会导致性能问题。
也正因为这个特性,使得在良好结构下,hyperapp的渲染性能表现不亚于现有主流渲染库。

Hyperapp虽然精巧,却完全支持SSR特性。在初次渲染时候,会将现有DOM结构转成vdom,当有行为触发数据变动时,高效进行dom-diff以更新现有视图。
大神,我在V2EX看到你发的《黑苹果完美攒机配置分享》帖,然后我参照你的配置也配了一台,现在在安装黑苹果时遇到了点问题,怀疑是EFI不正确导致,能分享一下你的EFI吗?
事情经过是这样的,某个阳光明媚的晚上,跟大多数人一样,在MacBook前静静地写着redux/flux“优美”的诗句。剧情急转直下:
└── constants
├── comA.js
├── comB.js
├── comC.js
├── comD.js
├── comE.js
└── index.js
index.js看起来是这样的:
import * from './a';
import * from './b';
...好像没什么不对劲,然后看了一下a.js和b.js..
//a.js
export const OPEN_SIDEBAR = "OPEN_SIDEBAR";
export const CLOSE_SIDEBAR = "CLOSE_SIDEBAR";
export const HIDE_ITEM = "HIDE_ITEM";
//b.js
export const TOGGLE_LIST = "TOGGLE_LIST";
export const CHANGE_WIDTH = "CHANGE_WIDTH";
export const HIDE_ITEM = "HIDE_ITEM";
。。
。。。
。。。。
喵的,不同组件的constant又写重复了。于是开始漫长的改constant之旅:
COMB_HIDE_ITEM慢着....
好像comC,comD,comE都有这个constant
咳咳,膝盖中箭的有木有,站出来!其实constant这个常量在react界最先被flux框架采用,再后来著名的redux(star数已经超过flux),也采用同样方式定义action与reducer之间的事件分发机制。引入constant,有效解决事件分发时,事件类型的一致性以及清晰逻辑性。
其实一直以来,业界津津乐道的是react的vm,flux/redux的状态管理机制,webpack开发技巧以及插件使用,react-router入门 etc.
constant如此重要的事件结构机制因为可将性太低,往往被大家忽略。其实,细心思考,不难发现,随着项目增大。constants目录将会随着数据处理事件迅速膨胀。大家一直维护着这个事件命名机制,身心疲惫有木有。
export KeyMirror({
ADD_TODO: null,
COMPLETE_TODO: null,
SET_VISIBILITY_FILTER: null
})
export const ADD_TODO = 'ADD_TODO'
export const COMPLETE_TODO = 'COMPLETE_TODO'
export const SET_VISIBILITY_FILTER = 'SET_VISIBILITY_FILTER'
引用redux文档的原话:
Types should typically be defined as string constants.
Once your app is large enough,
you may want to move them into a separate module.
看到刚刚LZ的经历,大家可以发现。其实,constant随着项目增大,独立出来的constants也会导致非常麻烦的维护问题。
类似constant-mirror、flux-constants的库都耐不住寂寞了,站出来声张正义。
但是,这些库其中一个致命共同点:
就一句话:
Fuck off constants.js
我们再也不需要去维护任何的与constant有关的文件,也不需要到处去找constants/comA.js、reducer/comA.js、action/comA.js一个个去改命名。
HIDE_ITEM和comB的HIDE_ITEM可不一样,自家用自家的,互不侵犯。npm install react-constant --save//ES5 version
var Constant = require('react-constant').Constant;
var constants = Constant('mynamespace');
//ES6 version
import { Constant } from 'react-constant';
let constants = Constant('mynamespace');<script src="dist/constant.min.js"></script>reducer.js
function reducer(state, action){
switch(action.type){
case constants.of('ON'):
//TODO
break;
case constants.of('OFF'):
//TODO
break;
default:
return state;
}
}action.js
function toggleLight(flag){
return {
type: constants.ON,
flag: flag
}
}我们通过分析主流浏览器Chrome,来了解一个脚本从无到有再到运行作用,到底经历了什么。以下将会用lodash为作为例子,浏览器的脚本生命周期。
在浏览器中,在HTML解析过程中,当解析到带有src的script标签,便会即刻调度网络模块队列,网络模块在有空余请求线程时,会即刻执行队列的请求。
举个栗子:
<script>
console.log("Hello Tmall")
</script>
<script src="lodash.js"></script>
浏览器会优先发起lodash.js的请求,而后执行console.log脚本。
了解TCP/IP协议的童鞋都知道,网络服务器存在慢启动机制,数据包会以递增方式发送至客户端(浏览器),一个500KB左右的lodash.js会被以十多个包送达:
也许有童鞋已经发现,为了极致的性能,Chrome在接收到首个数据包时,已经开始脚本的解析工作。
随后,脚本的一系列连贯的生命周期,最后会发出一个load事件,表明脚本已就绪。
总体看起来,脚本的确会阻塞后续HTML解析,一个完整生命周期大概是酱紫的。
那么,当多个脚本并行加载,时间序列是怎样的呢:脚本下载会并行发起,接收数据交替进行。而解析、编译、执行,会根据HTML声明顺序,串行进行
以react react-dom lodash并行加载为例,整个时序是酱紫的:
前端框架时代,为开发体验、效率与页面性能带来,非常大的革命。大家纷纷拿起一系列打包工具(webpack/parcel etc.),配合一系列加载器快速搭建起一个 SPA 页面。
SPA 应用带来的好处非常明显;
但是也带来一系列性能问题:
这些问题是使用 SPA 模式不可避免的,通过了解 SPA 加载运行过程,可以逐渐看清楚引起性能问题的根本原因,通过精细化应用加载,来解决这些问题。
比起一般的简单页面,SPA 最大的问题,就是在初始化之时引入大量框架方案脚本,这导致脚本体积随着项目发展体积愈发增大。
很多人会关注脚本的加载体积,通过一系列方案来提升缓存命中率,减少脚本请求次数。在网络环境较差的移动端,尽量减少请求时间意义很大。
但这不是银弹,移动设备对脚本的解析、编译、执行性能较差(脚本加载参考《图说舌尖上的脚本》),即便可以完全利用缓存,执行时间也是性能一大瓶颈。
性能优化原则:贫则独善其身,富则兼济天下。
随着项目不断发展,页面不断增加,源源不断的第三方组件&工具库加入到Bundle里面,良好的 SPA 架构可以保证大型 SPA 项目依旧保持极致的性能与体验。下面介绍一个优秀性能&体验 SPA 具备的特性:
快速启动应用,并行发起 Bundle 加载&拉取初始数据。相信大家已经发现了,SPA 初始化时候,不得不等待 bundle 返回并执行后,才会发起数据加载。
由于在移动设备上(即便有缓存)bundle 加载极为耗时,我们可以充分利用这段时间将数据进行预加载。这项特性,使得后面的优化起到更加明显的效果。
如下示例代码:
// app.js
Promise.all([load('bundle'), load('data')])利用异步加载方式,在路由注册时提供异步拉取组件的方法,仅在需要进入对应路由时,对应组件才会被加载进来。
route({
Home: () => import('@/coms/home'),
About: () => import('@/coms/about')
})在Home和About等路由里面,可能公用一套 UI 组件,若不将异步加载公用组件统一打包,每次加载 路由时,都会额外加载一套 UI 组件。通过将公用组件提取打包成Vendor,可以减少下次进入路由加载体积与时间。
BTW:在webpack < 4时,依旧需要手动维护异步加载组件公用组件。webpack4提供更丰富的异步组件抽离方案。
当首屏加载完毕后,设备&网络处于空闲状态,可以对其他路由组件进行预加载,以便提升页面切换性能。
预加载是一个非常繁琐的过程,我们可以设计一个极小启动器,在页面渲染后快速预加载后续组件:
// 所有包含Page的路由组件均会被预加载
boostraper.loadMatch('Page')
webpack4在 ESM tree shaking上做了极大优化,使得在引用工具库时候真正做到"按需打包",这要求无论是自己开发的工具库,抑或使用第三方工具库,打包&使用 ESM 版本非常必要。
根据 PWA 缓存策略,可以将访问的页面index.html缓存起来,下次打开时候优先利用缓存,再发起请求更新缓存。这使得 SPA 应用几乎不需要额外时间便可加载应用首屏文档流。
Skeleton PageSPA 首屏加载面临较长时间白屏,骨架图是一个完美的"缓兵之计"。在谷歌研究员的文章 中有提到,骨架图对用户体验有极大的提升:
需要注意的是,骨架图应尽量保持足够小巧与简单,以确保不会严重影响页面后续加载。
无论如何优化性能加载,在页面切换时候依旧需要获取页面数据,若处理不好,可能会在数据返回前有短暂的不友好"空白"。通过以下方式可以很好处理这个问题:
除了上述提到的 SPA 优化方案,Web 性能基础也是必备的基石(如域名收敛、合理文档结构)。性能优化本质是一个页面精细化监控运营的过程,也要求我们对 Web 加载的过程与逻辑有更多的思考与理解。
webpack 4 移除 CommonsChunkPlugin,取而代之的是两个新的配置项(optimization.splitChunks 和 optimization.runtimeChunk),下面介绍一下用法和机制。
webpack模式模式现在已经做了一些通用性优化,适用于多数使用者。
需要注意的是:默认模式只影响按需(on-demand)加载的代码块(chunk),因为改变初始代码块会影响声明在HTML的script标签。如果可以处理好这些(比如,从打包状态里面读取并动态生成script标签到HTML),你可以通过设置optimization.splitChunks.chunks: "all",应用这些优化模式到初始代码块(initial chunk)。
webpack根据下述条件自动进行代码块分割:
node_modules文件夹里面为了满足后面两个条件,webpack有可能受限于包的最大数量值,生成的代码体积往上增加。
我们来看一下一些例子:
// entry.js
import("./a");// a.js
import "react-dom";
// ...结果:webpack会创建一个包含react-dom的分离代码块。当import调用时候,这个代码块就会与./a代码被并行加载。
为什么会这样打包:
node_modules来的这样打包有什么好处呢?
对比起你的应用代码,react-dom可能不会经常变动。通过将它分割至另外一个代码块,这个代码块可以被独立缓存起来(假设你在用的是长期缓存策略:chunkhash,records,Cache-Control)
// entry.js
import("./a");
import("./b");// a.js
import "./helpers"; // helpers is 40kb in size
// ...// b.js
import "./helpers";
import "./more-helpers"; // more-helpers is also 40kb in size
// ...结果:webpack会创建一个包含./helpers的独立代码块,其他模块会依赖于它。在import被调用时候,这个代码块会跟原始的代码并行加载(译注:它会跟a.js和b.js并行加载)。
为什么会这样打包:
import)调用依赖(指的是a.js和b.js)helpers体积大于30kb这样打包有什么好处呢?
将helpers代码放在每一个依赖的块里,可能就意味着,用户重复会下载它两次。通过用一个独立的代码块分割,它只需要被下载一次。实际上,这只是一种折衷方案,因为我们为此需要付出额外的一次请求的代价。这就是为什么默认webpack将最小代码块分割体积设置成30kb(译注:太小体积的代码块被分割,可能还会因为额外的请求,拖慢加载性能)。
通过optimizations.splitChunks.chunks: "all",上面的策略也可以应用到初始代码块上(inital chunks)。代码代码块也会被多个入口共享&按需加载(译注:以往我们使用CommonsChunkPlugin最通常的目的)。
如果想要更深入控制这个按需分块的功能,这里提供很多选项来满足你的需求。
Disclaimer:不要在没有实践测量的情况下,尝试手动优化这些参数。默认模式是经过千挑万选的,可以用于满足最佳web性能的策略。
这项优化可以用于将模块分配到对应的Cache group。
默认模式会将所有来自node_modules的模块分配到一个叫vendors的缓存组;所有重复引用至少两次的代码,会被分配到default的缓存组。
一个模块可以被分配到多个缓存组,优化策略会将模块分配至跟高优先级别(priority)的缓存组,或者会分配至可以形成更大体积代码块的组里。
在满足下述所有条件时,那些从相同代码块和缓存组来的模块,会形成一个新的代码块(译注:比如,在满足条件下,一个vendoer可能会被分割成两个,以充分利用并行请求性能)。
有四个选项可以用于配置这些条件:
minSize(默认是30000):形成一个新代码块最小的体积minChunks(默认是1):在分割之前,这个代码块最小应该被引用的次数(译注:保证代码块复用性,默认配置的策略是不需要多次引用也可以被分割)maxInitialRequests(默认是3):一个入口最大的并行请求数maxAsyncRequests(默认是5):按需加载时候最大的并行请求数。要控制代码块的命名,可以用name参数来配置。
注意:当不同分割代码块被赋予相同名称时候,他们会被合并在一起。这个可以用于在:比如将那些多个入口/分割点的共享模块(vendor)合并在一起,不过不推荐这样做。这可能会导致加载额外的代码。
如果赋予一个神奇的值true,webpack会基于代码块和缓存组的key自动选择一个名称。除此之外,可以使用字符串或者函数作为参数值。
当一个名称匹配到相应的入口名称,这个入口会被移除。
通过chunks选项,可以配置控制webpack选择哪些代码块用于分割(译注:其他类型代码块按默认方式打包)。有3个可选的值:initial、async和all。webpack将会只对配置所对应的代码块应用这些策略。
reuseExistingChunk选项允许复用已经存在的代码块,而不是新建一个新的,需要在精确匹配到对应模块时候才会生效。
这个选项可以在每个缓存组(Cache Group)里面做配置。
test选项用于控制哪些模块被这个缓存组匹配到。原封不动传递出去的话,它默认会选择所有的模块。可以传递的值类型:RegExp、String和Function
通过这个选项,可以通过绝对资源路径(absolute modules resource path)或者代码块名称(chunk names)来匹配对应模块。当一个代码块名称(chunk name)被匹配到,这个代码块的所有模块都会被选中。
这是默认的配置:
splitChunks: {
chunks: "async",
minSize: 30000,
minChunks: 1,
maxAsyncRequests: 5,
maxInitialRequests: 3,
name: true,
cacheGroups: {
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true,
},
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10
}
}
}默认来说,缓存组会继承splitChunks的配置,但是test、priorty和reuseExistingChunk只能用于配置缓存组。
cacheGroups是一个对象,按上述介绍的键值对方式来配置即可,值代表对应的选项:
除此之外,所有上面列出的选择都是可以用在缓存组里的:chunks, minSize, minChunks, maxAsyncRequests, maxInitialRequests, name。
可以通过optimization.splitChunks.cacheGroups.default: false禁用default缓存组。
default缓存组的优先级(priotity)是负数,因此所有自定义缓存组都可以有比它更高优先级(译注:更高优先级的缓存组可以优先打包所选择的模块)(默认自定义缓存组优先级为0)
可以用一些例子来说明:
splitChunks: {
cacheGroups: {
commons: {
name: "commons",
chunks: "initial",
minChunks: 2
}
}
}这会创建一个commons代码块,这个代码块包含所有被其他入口(entrypoints)共享的代码。
注意:这可能会导致下载额外的代码。
splitChunks: {
cacheGroups: {
commons: {
test: /[\\/]node_modules[\\/]/,
name: "vendors",
chunks: "all"
}
}
}这会创建一个名为vendors的代码块,它会包含整个应用所有来自node_modules的代码。
注意:这可能会导致下载额外的代码。
通过optimization.runtimeChunk: true选项,webpack会添加一个只包含运行时(runtime)额外代码块到每一个入口。(译注:这个需要看场景使用,会导致每个入口都加载多一份运行时代码)
也许最近已经听说Chrome59将支持headless模式,PhantomJS核心开发者Vitaly表示自己将会失业了。
3年前,无头浏览器PhantomJS已经如火如荼出现了,紧跟着NightmareJS也成为一名巨星。无头浏览器带来巨大便利性:页面爬虫、自动化测试、WebAutomation...
用过PhantomJS的都知道,它的环境是运行在一个封闭的沙盒里面,在环境内外完全不可通信,包括API、变量、全局方法调用等。一个之前写的微信页面爬虫,实现内外通信的方式极其Hack,为了达到目的,不择手段,令人发指,看过的哥们都会蛋疼。
So, 很自然的,Chrome59版支持的特性,全部可以利用,简直不要太爽:
为了点亮技能树,我们需要以下配置:
大致来说,有那么个过程:
有各种脚本启动方式,本次我们使用termial参数方式来打开:
$ /Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary --headless --remote-debugging-port=9222在Dock中,一个黄色的东西就会被启动,但是他不会跳出来。
依旧有各种方式,我们先安装一个工具帮助我们来对黄色浏览器做点事情:
$ tnpm i -S chrome-remote-interface Pretty Simple,写一个index.js:
const CDP = require("chrome-remote-interface");
CDP(client => {
// extract domains
const { Network, Page } = client;
// setup handlers
Network.requestWillBeSent(params => {
console.log(params.request.url);
});
Page.loadEventFired(() => {
client.close();
});
// enable events then start!
Promise.all([Network.enable(), Page.enable()])
.then(() => {
return Page.navigate({ url: "https://github.com" });
})
.catch(err => {
console.error(err);
client.close();
});
}).on("error", err => {
// cannot connect to the remote endpoint
console.error(err);
});
AND run it:
$ node index.js结果会展示一堆url:
https://github.com/
https://assets-cdn.github.com/assets/frameworks-12d63ce1986bd7fdb5a3f4d944c920cfb75982c70bc7f75672f75dc7b0a5d7c3.css
https://assets-cdn.github.com/assets/github-2826bd4c6eb7572d3a3e9774d7efe010d8de09ea7e2a559fa4019baeacf43f83.css
https://assets-cdn.github.com/assets/site-f4fa6ace91e5f0fabb47e8405e5ecf6a9815949cd3958338f6578e626cd443d7.css
https://assets-cdn.github.com/images/modules/site/home-illo-conversation.svg
https://assets-cdn.github.com/images/modules/site/home-illo-chaos.svg
https://assets-cdn.github.com/images/modules/site/home-illo-business.svg
https://assets-cdn.github.com/images/modules/site/integrators/slackhq.png
https://assets-cdn.github.com/images/modules/site/integrators/zenhubio.png
https://assets-cdn.github.com/assets/compat-8a4318ffea09a0cdb8214b76cf2926b9f6a0ced318a317bed419db19214c690d.js
https://assets-cdn.github.com/static/fonts/roboto/roboto-medium.woff
...这次轮到演示一下如何操控DOM:
const CDP = require("chrome-remote-interface");
CDP(chrome => {
chrome.Page
.enable()
.then(() => {
return chrome.Page.navigate({ url: "https://github.com" });
})
.then(() => {
chrome.DOM.getDocument((error, params) => {
if (error) {
console.error(params);
return;
}
const options = {
nodeId: params.root.nodeId,
selector: "img"
};
chrome.DOM.querySelectorAll(options, (error, params) => {
if (error) {
console.error(params);
return;
}
params.nodeIds.forEach(nodeId => {
const options = {
nodeId: nodeId
};
chrome.DOM.getAttributes(options, (error, params) => {
if (error) {
console.error(params);
return;
}
console.log(params.attributes);
});
});
});
});
});
}).on("error", err => {
console.error(err);
});
最后会返回数组,看起来像酱紫:
[
[ 'src',
'https://assets-cdn.github.com/images/modules/site/home-illo-conversation.svg',
'alt',
'',
'width',
'360',
'class',
'd-block width-fit mx-auto' ]
[ 'src',
'https://assets-cdn.github.com/images/modules/site/home-illo-chaos.svg',
'alt',
'',
'class',
'd-block width-fit mx-auto' ]
[ 'src',
'https://assets-cdn.github.com/images/modules/site/home-illo-business.svg',
'alt',
'',
'class',
'd-block width-fit mx-auto mb-4' ]
...
]
chrome-remote-interface 提供一套完整的API用于利用全量Chrome特性,更多使用方法参考:https://github.com/cyrus-and/chrome-remote-interface
Chrome Headless特性,不仅仅革新了原有格局,而且提高开发效率,降低使用门槛,对于经常使用爬虫、自动化测试前端童鞋来说简直是巨大福音,对于新童鞋来说也是一个新潮的玩具。
提到 Gulp,不得不说到的是较早的 JS 项目自动化构建工具——Grunt。
前端开发过程中,特别是最近几年多了 CoffeeScript、Sass、Less 等一些预编译语言,很多代码每次写完需要手动到工作目录去编译才能执行。此外,项目预发布时候需要进行 js、css 文件合并、压缩、重命名等操作,实在是很繁琐。此前很多工程师使用的是 Makefile 构建项目,但是这要求需要一定Linux基础,而且编写配置文件会增大非常多工作量, Grunt 的出现,解放了前端工程师的双手=_=
Grunt 通过 CLI 配合配置文件 gruntfile.js 去完成自动化构建任务,社区有非常多的 Grunt 插件,比如 concat(合并文件)、 uglify(js压缩),只需要在 gruntfile.js 中配置好路径等一些参数,运行以下命令就可以自动执行。
grunt takeName
Gulp是一款 The streaming build system(流式构建系统),如果说 Grunt 是基于 gruntfile.js 任务执行器,Gulp 就是基于 NodeJS 的文件流任务执行器,比起 Grunt 有如下特点
Gulp 主要 API 为 gulp.src(使用glob模式匹配获得文件流集)、gulp.dest(输出gulp文件流集到指定路径,路径指定相对于gulpfile.js配置文件)、gulp.watch(监听glob模式匹配的文件集,有改动时执行相应gulp任务),如图:
译作管弦乐演奏家,大多数就是一个老头拿着个小棍的形象,就像这样:
一个npmjs模块,就是一个以最大并发方式去排序或执行一系列的任务。这些任务就是我们之后会用到的 Gulp 任务,比如说 css 命名的任务,里面包括css的浏览器前缀添加、合并、压缩等操作。orchestrator 通过实例化一个对象,在对象上调用 add 来添加特定命名的任务、添加任务时候可以声明任务依赖,比如:
var Orchestrator = require('orchestrator');
var orchestrator = new Orchestrator();
orchestrator.add('thing1', function(){
// do stuff
});
orchestrator.add('thing2', function(){
// do stuff
});
orchestrator.add('mytask', ['thing1','thing2'], function() {
// Do stuff
});
以上代码,添加了3个 Gulp 任务,mytask 任务依赖于 thing1 和 thing2 ,即必须执行完后面两个任务,mytask才能执行,通过任务依赖,很容易理清和构建任务时候的执行顺序。需要注意的是,在填写 do stuff 时候,要确保其返回一个 promise 或者是 event stream(最常用),比如一个简单的任务是这样定义的:
var map = require('map-stream');
orchestrator.add('thing4', function(){
var stream = map(function (args, cb) {
cb(null, args);
});
// do stream stuff
return stream;
});
或则是返回一个 promise:
var Q = require('q');
orchestrator.add('thing3', function(){
var deferred = Q.defer();
// do async stuff
setTimeout(function () {
deferred.resolve();
}, 1);
return deferred.promise;
});
orchestrator 调用 start 来执行特定名称的任务,可一次执行多个:
orchestrator.start('one', 'two');
以上两个是 orchestrator 最常用的用于实现 Gulp 的函数,除此之外,还有任务检测,任务暂停,任务事件监听,想详细了解可访问npmjs:https://www.npmjs.org/package/orchestrator
这是 Gulp 采用的一个虚拟文件系统,可以读取 glob 模式匹配到的文件并转成文件流,可以获取文件流并转成文件集。其中 vinyl-fs 使用 vinyl 虚拟文件描述类,来对 glob 匹配到的文件进行描述,所谓的描述,只是简单的文件名与路径,以及文件内容,可以说是一个文件的封装,可以看看 vinyl 是如何描述一个或一组文件的:
var File = require('vinyl');
var coffeeFile = new File({
cwd: "/",
base: "/test/",
path: "/test/file.coffee",
contents: new Buffer("test = 123")
});
除了 vinyl ,vinyl-fs 还需要依赖 glob-stream 读写文件流,如图:
大家可能有疑问,读写文件流,为什么不用 nodejs 内核的 steam 类来读写呢,*安勿燥,Gulp 既然是基于 nodejs 构建,最终自然也是依赖 nodejs 内核实现它的功能的。
只是,stream 类读取文件流只针对一个文件路径,glob-stream 就是实现从获取 glob 模式匹配文件集,到转换成文件路径,再到读取,还是有一段距离的。如图:
glob-stream 通过 minimatch 来进行 glob 模式匹配,通过其他路径模块,获得一组文件路径,然后就是 ordered-read-streams 发光发热时候啦,对这组文件路径一个个地读啊,然后就获得一组文件流啦。
好啦,终于分析完 Gulp 的实现,通过对其中模块的阅读,其实 Nodejs 模块有点像乐高积木,内核给出的就是最基本的积木啦,不过你可以无限次使用它们,来堆出一个个小的物体,通过小小的物体组合,来组成非常徇丽多姿的乐高作品啦~
当然,也是有一些 c++ 实现的nodejs模块,主要是用于一些需要高性能运算的地方,比如最常用的编码格式转换工具node-iconv。
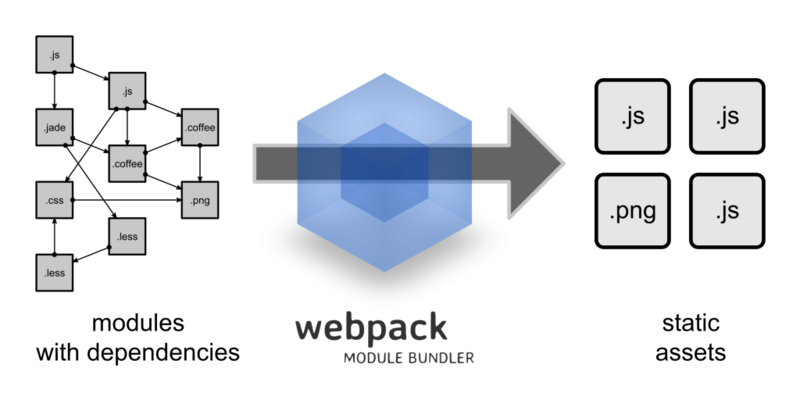
redux是可预测的JS应用状态容器。
现在有一个开关按钮组件ToggleButton,而按钮的on/off就是这个组件的状态。
一个应用里面会有大量的组件,而管理以及传递这些组件的状态,就成了非常繁琐的工作。redux使用一个非常简洁的思路,方便地提供不同层级组件的解耦式状态操作。
reudx本身是一个非常简单的流程概念,它仅仅是一个状态容器。如图:
APP或者说是Web/SPA,在组件化的应用中,会有着大量的组件层级关系,深嵌套的组件与浅层父组件进行数据交互,变得十分繁琐困难。而redux,站在一个服务级别的角度,可以毫无阻碍地(这个得益于react的context机制,后面会讲解)将应用的状态传递到每一个层级的组件中。一整个应用,得一管家,足矣。
使用redux过程中,只需要知晓这几个准则,就可以非常便捷地进行开发,少踩坑才是硬道理。
整个应用状态,都应该被存储在单一store的对象树中。
唯一可以修改状态的方式,就是发送(dispatch)一个动作(Action),这个动作以最小的数据,去描述发生了什么。
比如,用户想要从状态中删除一条TODO信息:
//Action
{
type: constant.REMOVE_TODO,
id: 'TODO_ID'
}非常简单,动作(Action)只需要一个type来描述这个动作类型,以及一个简单的id去表明要删那条信息。并不需要提供包含timestamp、data在内的一大堆信息。
纯函数(pure function)可被看成是一个状态机,在任何时候,只要有相同的输入,就会得到相同的输出:
//pure function
//add(1, 2) ===> 3
//add(1, 2) ===> 3
function add(a, b){
return a + b;
}
//impure function
//不纯函数,多次使用相同参数调用,可能会得出不同结果
//add(1) ===> 1
//add(1) ===> 2
var count = 0;
function add(n){
return count + n;
}这种修改状态的纯函数在redux里面被称作reducer,纯函数保障了状态的稳定性,不会因不同环境导致应用程序出现不同情况。而这也是redux内核的精髓(核心源码分析章节会讲解)。
以上是redux的一些介绍,下面就开始入门redux。实际上,redux使用起来非常简单,就以上面提到的图片进行介绍。
第一步,当然就是Action这个动作了,它可是唯一可以改变状态的途径,包括服务器来的推送以及用户操作,最终都需要转化为一个个Action。这种简单的方式解决了传统应用因为多种方式修改状态,而导致应用出现各种问题。
通过集中化对状态的修改,Action会按着严格的顺序一个个执行,因此应用并不会出现竞态的情况;Action仅仅是一个纯的JS对象,因此这个动作,可以被记录、序列化、存储以及以后通过一系列的“回放”来调试应用。
一个简单的添加TODO信息的动作:
{
type: constant.ADD_TODO,
msg: "下班回家收衣服"
}第二步,store可以被看作redux的最核心部分,一个小小的store,管理着整个应用的状态。其中包括:应用状态初始化、状态修改、注册状态变化监听器、替换应用状态。
当然,现在并不会涉及到这么多内容。store提供了一个方法#dispatch,这个就是用来发送一个动作,去修改store里面的状态,然后可以通过#getState方法来重新获得最新的状态:
//dispath above action
store.getState() // ===> {todo: []}
store.dispatch({
type: constant.ADD_TODO,
msg: "下班回家收衣服"
});
store.getState() // ===> {todo: ['下班回家收衣服']}然后返回的新状态,即将作为应用的状态通过props(在react应用里面)发送回APP。APP接收到新的props会对应用进行实时更新。这样就完成一个动作触发到应用更新的过程了。
刚有耳闻,这个reducer是用来修改状态的。再回顾上面的代码,在store.dispatch后发现store.getState调用返回的对象变了。
那应该是reducer做了手脚,顺带一提,reducer会接收两个参数:现在的状态state,被发送的动作Action
function todo(state = [], action){
if(action.type === constant.ADD_TODO){
//如果是添加TODO的动作,那就赶紧把TODO存起来
state.push(action.msg);
return state;
}else {
//其他动作的话,就不改状态啦,原样返回
return state;
}
}store通过读取reducer返回的内容,来作为新的状态,因此应用状态就更新了!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.