yvettelau / blog Goto Github PK
View Code? Open in Web Editor NEW【前端进阶】优质博文
【前端进阶】优质博文
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")




































































































































































































知其然知其所以然,首先了解三个概念:
1.什么是同步?
所谓同步,就是在发出一个"调用"时,在没有得到结果之前,该“调用”就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由“调用者”主动等待这个“调用”的结果。此调用执行完之前,阻塞之后的代码执行。
2.什么是异步?
"调用"在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在"调用"发出后,"被调用者"通过状态、通知来通知调用者,或通过回调函数处理这个调用。异步调用发出后,不影响后面代码的执行。
3.JavaScript 中为什么需要异步?
首先我们知道JavaScript是单线程的(即使新增了webworker,但是本质上JS还是单线程)。同步代码意味着什么呢?意味着有可能会阻塞,当我们有一个任务需要时间较长时,如果使用同步方式,那么就会阻塞之后的代码执行。而异步则不会,我们不会等待异步代码的之后,继续执行异步任务之后的代码。
概念了解完了,我们就要进入今天的正题了。首先大家思考一下:平时在工作中,主要使用了哪些异步解决方案,这些异步方案有什么优缺点?
异步最早的解决方案是回调函数,如事件的回调,setInterval/setTimeout中的回调。但是回调函数有一个很常见的问题,就是回调地狱的问题(稍后会举例说明);
为了解决回调地狱的问题,社区提出了Promise解决方案,ES6将其写进了语言标准。Promise一定程度上解决了回调地狱的问题,但是Promise也存在一些问题,如错误不能被try catch,而且使用Promise的链式调用,其实并没有从根本上解决回调地狱的问题,只是换了一种写法。
ES6中引入 Generator 函数,Generator是一种异步编程解决方案,Generator 函数是协程在 ES6 的实现,最大特点就是可以交出函数的执行权,Generator 函数可以看出是异步任务的容器,需要暂停的地方,都用yield语句注明。但是 Generator 使用起来较为复杂。
ES7又提出了新的异步解决方案:async/await,async是 Generator 函数的语法糖,async/await 使得异步代码看起来像同步代码,异步编程发展的目标就是让异步逻辑的代码看起来像同步一样。
回调函数 ---> Promise ---> Generator ---> async/await.
//node读取文件
fs.readFile(xxx, 'utf-8', function(err, data) {
//code
});回调函数的使用场景(包括但不限于):
回调函数的优点: 简单。
回调函数的缺点:
异步回调嵌套会导致代码难以维护,并且不方便统一处理错误,不能 try catch 和 回调地狱(如先读取A文本内容,再根据A文本内容读取B再根据B的内容读取C...)。
fs.readFile(A, 'utf-8', function(err, data) {
fs.readFile(B, 'utf-8', function(err, data) {
fs.readFile(C, 'utf-8', function(err, data) {
fs.readFile(D, 'utf-8', function(err, data) {
//....
});
});
});
});Promise 一定程度上解决了回调地狱的问题,Promise 最早由社区提出和实现,ES6 将其写进了语言标准,统一了用法,原生提供了Promise对象。
那么我们看看Promise是如何解决回调地狱问题的,仍然以上文的readFile 为例(先读取A文本内容,再根据A文本内容读取B再根据B的内容读取C)。
function read(url) {
return new Promise((resolve, reject) => {
fs.readFile(url, 'utf8', (err, data) => {
if(err) reject(err);
resolve(data);
});
});
}
read(A).then(data => {
return read(B);
}).then(data => {
return read(C);
}).then(data => {
return read(D);
}).catch(reason => {
console.log(reason);
});Promise 的优点:
缺点:
try catch假设有这样一个需求:读取A,B,C三个文件内容,都读取成功后,再输出最终的结果。在Promise之前,我们一般可以借助发布订阅模式去实现:
let pubsub = {
arry: [],
emit() {
this.arry.forEach(fn => fn());
},
on(fn) {
this.arry.push(fn);
}
}
let data = [];
pubsub.on(() => {
if(data.length === 3) {
console.log(data);
}
});
fs.readFile(A, 'utf-8', (err, value) => {
data.push(value);
pubsub.emit();
});
fs.readFile(B, 'utf-8', (err, value) => {
data.push(value);
pubsub.emit();
});
fs.readFile(C, 'utf-8', (err, value) => {
data.push(value);
pubsub.emit();
});Promise给我们提供了 Promise.all 的方法,对于这个需求,我们可以使用 Promise.all 来实现。
/**
* 将 fs.readFile 包装成promise接口
*/
function read(url) {
return new Promise((resolve, reject) => {
fs.readFile(url, 'utf8', (err, data) => {
if(err) reject(err);
resolve(data);
});
});
}
/**
* 使用 Promise
*
* 通过 Promise.all 可以实现多个异步并行执行,同一时刻获取最终结果的问题
*/
Promise.all([
read(A),
read(B),
read(C)
]).then(data => {
console.log(data);
}).catch(err => console.log(err));可执行代码可戳: https://github.com/YvetteLau/Blog/blob/master/JS/Async/index.js
Generator 函数是 ES6 提供的一种异步编程解决方案,整个 Generator 函数就是一个封装的异步任务,或者说是异步任务的容器。异步操作需要暂停的地方,都用 yield 语句注明。
Generator 函数一般配合 yield 或 Promise 使用。Generator函数返回的是迭代器。对生成器和迭代器不了解的同学,请自行补习下基础。下面我们看一下 Generator 的简单使用:
function* gen() {
let a = yield 111;
console.log(a);
let b = yield 222;
console.log(b);
let c = yield 333;
console.log(c);
let d = yield 444;
console.log(d);
}
let t = gen();
//next方法可以带一个参数,该参数就会被当作上一个yield表达式的返回值
t.next(1); //第一次调用next函数时,传递的参数无效
t.next(2); //a输出2;
t.next(3); //b输出3;
t.next(4); //c输出4;
t.next(5); //d输出5;为了让大家更好的理解上面代码是如何执行的,我画了一张图,分别对应每一次的next方法调用:
仍然以上文的 readFile (先读取A文本内容,再根据A文本内容读取B再根据B的内容读取C)为例,使用 Generator + co库来实现:
const fs = require('fs');
const co = require('co');
const bluebird = require('bluebird');
const readFile = bluebird.promisify(fs.readFile);
function* read() {
yield readFile(A, 'utf-8');
yield readFile(B, 'utf-8');
yield readFile(C, 'utf-8');
//....
}
co(read()).then(data => {
//code
}).catch(err => {
//code
});Generator的缺点大约不用我说了,除非是找虐,不然一般不会直接使用 Generator 来解决异步的(当然也不排除是因为我不熟练)~~~
不使用co库,如何实现?能否自己写一个最简的 my_co,有助于理解 async/await 的实现原理 ?请戳: https://github.com/YvetteLau/Blog/blob/master/JS/Async/generator.js
PS: 如果你还不太了解 Generator/yield,建议阅读ES6相关文档。
ES7中引入了 async/await 概念。async 其实是一个语法糖,它的实现就是将 Generator函数和自动执行器(co),包装在一个函数中。
async/await 的优点是代码清晰,不用像 Promise 写很多 then 链,就可以处理回调地狱的问题。并且错误可以被try catch。
仍然以上文的readFile (先读取A文本内容,再根据A文本内容读取B再根据B的内容读取C) 为例,使用 async/await 来实现:
const fs = require('fs');
const bluebird = require('bluebird');
const readFile = bluebird.promisify(fs.readFile);
async function read() {
await readFile(A, 'utf-8');
await readFile(B, 'utf-8');
await readFile(C, 'utf-8');
//code
}
read().then((data) => {
//code
}).catch(err => {
//code
});使用 async/await 实现此需求:读取A,B,C三个文件内容,都读取成功后,再输出最终的结果。
function read(url) {
return new Promise((resolve, reject) => {
fs.readFile(url, 'utf8', (err, data) => {
if(err) reject(err);
resolve(data);
});
});
}
async function readAsync() {
let data = await Promise.all([
read(A),
read(B),
read(C)
]);
return data;
}
readAsync().then(data => {
console.log(data);
});所以JS的异步发展史,可以认为是从 callback -> promise -> generator -> async/await。async/await 使得异步代码看起来像同步代码,异步编程发展的目标就是让异步逻辑的代码看起来像同步一样。
因本人水平有限,文中内容未必百分百正确,如有不对的地方,请给我留言,谢谢。
邀请你加入 Step-By-Step 项目
不积跬步无以至千里。 我是公众号【前端宇宙】作者刘小夕,我将和大家一起一步一个脚印,向前端专家迈进。
Step-By-Step
每个工作日我会发布一个前端相关的问题(目的是为了切实掌握相关的知识点),欢迎在 Issue 区留下你的答案。
节假日不会发布任何问题,希望大家能够利用节假日回顾一周所学。每周末我会进行一次汇总(整理出最优答案),以便大家回顾。
参考文章:
[2] ES6 Promise
[3] ES6 Generator
[4] ES6 async
[5] JavaScript异步编程
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。https://github.com/YvetteLau/Blog
关注小姐姐的公众号,加入交流群。
Step-By-Step (点击进入项目) 是我于
2019-05-20开始的一个项目,每个工作日发布一道面试题。每个周末我会仔细阅读大家的答案,整理最一份较优答案出来,因本人水平有限,有误的地方,大家及时指正。
如果想 加群 学习,关注公众号,添加我为好友,我拉你进群。
本周面试题一览:
XSS(Cross-Site Scripting,跨站脚本攻击)是一种代码注入攻击。攻击者在目标网站上注入恶意代码,当被攻击者登陆网站时就会执行这些恶意代码,这些脚本可以读取 cookie,session tokens,或者其它敏感的网站信息,对用户进行钓鱼欺诈,甚至发起蠕虫攻击等。
XSS 的本质是:恶意代码未经过滤,与网站正常的代码混在一起;浏览器无法分辨哪些脚本是可信的,导致恶意脚本被执行。由于直接在用户的终端执行,恶意代码能够直接获取用户的信息,利用这些信息冒充用户向网站发起攻击者定义的请求。
根据攻击的来源,XSS攻击可以分为存储型(持久性)、反射型(非持久型)和DOM型三种。下面我们来详细了解一下这三种XSS攻击:
1.1 反射型XSS
当用户点击一个恶意链接,或者提交一个表单,或者进入一个恶意网站时,注入脚本进入被攻击者的网站。Web服务器将注入脚本,比如一个错误信息,搜索结果等,未进行过滤直接返回到用户的浏览器上。
反射型 XSS 的攻击步骤:
URL,其中包含恶意代码。URL 时,网站服务端将恶意代码从 URL 中取出,拼接在 HTML 中返回给浏览器。反射型 XSS 漏洞常见于通过 URL 传递参数的功能,如网站搜索、跳转等。由于需要用户主动打开恶意的 URL 才能生效,攻击者往往会结合多种手段诱导用户点击。
POST 的内容也可以触发反射型 XSS,只不过其触发条件比较苛刻(需要构造表单提交页面,并引导用户点击),所以非常少见。
如果不希望被前端拿到cookie,后端可以设置 httpOnly (不过这不是 XSS攻击 的解决方案,只能降低受损范围)
如何防范反射型XSS攻击
对字符串进行编码。
对url的查询参数进行转义后再输出到页面。
app.get('/welcome', function(req, res) {
//对查询参数进行编码,避免反射型 XSS攻击
res.send(`${encodeURIComponent(req.query.type)}`);
});1.2 DOM 型 XSS
DOM 型 XSS 攻击,实际上就是前端 JavaScript 代码不够严谨,把不可信的内容插入到了页面。在使用 .innerHTML、.outerHTML、.appendChild、document.write()等API时要特别小心,不要把不可信的数据作为 HTML 插到页面上,尽量使用 .innerText、.textContent、.setAttribute() 等。
DOM 型 XSS 的攻击步骤:
如何防范 DOM 型 XSS 攻击
防范 DOM 型 XSS 攻击的核心就是对输入内容进行转义(DOM 中的内联事件监听器和链接跳转都能把字符串作为代码运行,需要对其内容进行检查)。
1.对于url链接(例如图片的src属性),那么直接使用 encodeURIComponent 来转义。
2.非url,我们可以这样进行编码:
function encodeHtml(str) {
return str.replace(/"/g, '"')
.replace(/'/g, ''')
.replace(/</g, '<')
.replace(/>/g, '>');
}DOM 型 XSS 攻击中,取出和执行恶意代码由浏览器端完成,属于前端 JavaScript 自身的安全漏洞。
1.3 存储型XSS
恶意脚本永久存储在目标服务器上。当浏览器请求数据时,脚本从服务器传回并执行,影响范围比反射型和DOM型XSS更大。存储型XSS攻击的原因仍然是没有做好数据过滤:前端提交数据至服务端时,没有做好过滤;服务端在接受到数据时,在存储之前,没有做过滤;前端从服务端请求到数据,没有过滤输出。
存储型 XSS 的攻击步骤:
这种攻击常见于带有用户保存数据的网站功能,如论坛发帖、商品评论、用户私信等。
如何防范存储型XSS攻击:
除了谨慎的转义,我们还需要其他一些手段来防范XSS攻击:
1.Content Security Policy
在服务端使用 HTTP的 Content-Security-Policy 头部来指定策略,或者在前端设置 meta 标签。
例如下面的配置只允许加载同域下的资源:
Content-Security-Policy: default-src 'self'<meta http-equiv="Content-Security-Policy" content="form-action 'self';">前端和服务端设置 CSP 的效果相同,但是meta无法使用report
严格的 CSP 在 XSS 的防范中可以起到以下的作用:
2.输入内容长度控制
对于不受信任的输入,都应该限定一个合理的长度。虽然无法完全防止 XSS 发生,但可以增加 XSS 攻击的难度。
3.输入内容限制
对于部分输入,可以限定不能包含特殊字符或者仅能输入数字等。
4.其他安全措施
屏幕并不是唯一的输出机制,比如说屏幕上看不见的元素(隐藏的元素),其中一些依然能够被读屏软件阅读出来(因为读屏软件依赖于可访问性树来阐述)。为了消除它们之间的歧义,我们将其归为三大类:
display 属性(不占据空间)display: none;HTML5 新增属性,相当于 display: none
<div hidden>
</div>position 和 盒模型 将元素移出可视区范围posoition 为 absolute 或 fixed,�通过设置 top、left 等值,将其移出可视区域。(可视区域不占位)position:absolute;
left: -99999px;position 为 relative,通过设置 top、left 等值,将其移出可视区域。(可视区域占位)position: relative;
left: -99999px;如希望其在可视区域不占位置,需同时设置 height: 0;
margin-left: -99999px;如果希望其在可视区域不占位,需同时设置 height: 0;
transform: scale(0);translateX, translateYtransform: translateX(-99999px);rotatetransform: rotateY(90deg);宽高为0,字体大小为0:
height: 0;
width: 0;
font-size: 0;宽高为0,超出隐藏:
height: 0;
width: 0;
overflow: hidden;opacity: 0;visibility属性visibility: hiddenz-index 属性position: relative;
z-index: -999;再设置一个层级较高的元素覆盖在此元素上。
clip-path: polygon(0 0, 0 0, 0 0, 0 0);读屏软件不可读,占据空间,可见。
<div aria-hidden="true">
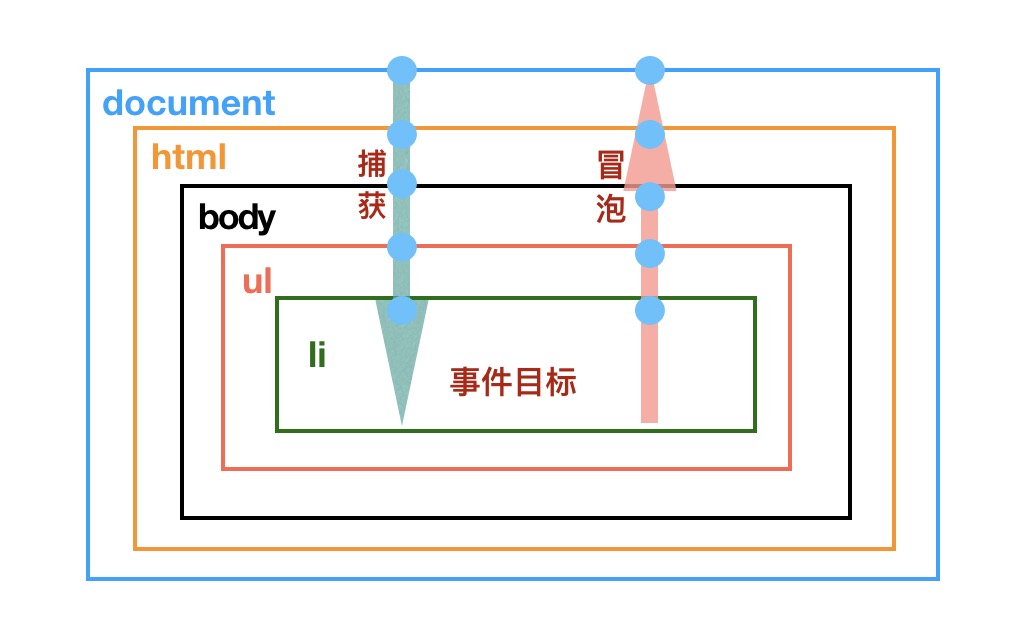
</div>在说浏览器事件代理机制原理之前,我们首先了解一下事件流的概念,早期浏览器,IE采用的是事件捕获事件流,而Netscape采用的则是事件冒泡。"DOM2级事件"把事件流分为三个阶段,捕获阶段、目标阶段、冒泡阶段。现代浏览器也都遵循此规范。
事件代理又称为事件委托,在祖先级 DOM 元素绑定一个事件,当触发子孙级DOM元素的事件时,利用事件冒泡的原理来触发绑定在祖先级 DOM 的事件。因为事件会从目标元素一层层冒泡至 document 对象。
添加到页面上的事件数量会影响页面的运行性能,如果添加的事件过多,会导致网页的性能下降。采用事件代理的方式,可以大大减少注册事件的个数。
事件代理的当时,某个子孙元素是动态增加的,不需要再次对其进行事件绑定。
不用担心某个注册了事件的DOM元素被移除后,可能无法回收其事件处理程序,我们只要把事件处理程序委托给更高层级的元素,就可以避免此问题。
允许给一个事件注册多个监听。
提供了一种更精细的手段控制 listener 的触发阶段(可以选择捕获或者是冒泡)。
对任何 DOM 元素都是有效的,而不仅仅是对 HTML 元素有效。
addEventListener 接受3个参数,分别是要处理的事件名、实现了 EventListener 接口的对象或者是一个函数、一个对象/一个布尔值。
target.addEventListener(type, listener[, options]);
target.addEventListener(type, listener[, useCapture]);options(对象) | 可选
capture: Boolean。true 表示在捕获阶段触发,false表示在冒泡阶段触发。默认是 false。
once:Boolean。true 表示listener 在添加之后最多只调用一次,listener 会在其被调用之后自动移除。默认是 false。
passive: Boolean。true 表示 listener 永远不会调用 preventDefault()。如果 listener 仍然调用了这个函数,客户端将会忽略它并抛出一个控制台警告。默认是 false。
useCapture(Boolean) | 可选
useCapture 默认为 false。表示冒泡阶段调用事件处理程序,若设置为 true,表示在捕获阶段调用事件处理程序。
如将页面中的所有click事件都代理到document上:
document.addEventListener('click', function (e) {
console.log(e.target);
/**
* 捕获阶段调用调用事件处理程序,eventPhase是 1;
* 处于目标,eventPhase是2
* 冒泡阶段调用事件处理程序,eventPhase是 3;
*/
console.log(e.eventPhase);
}, false);与 addEventListener 相对应的是 removeEventListener,用于移除事件监听。
setTimeout 只能保证延时或间隔不小于设定的时间。因为它实际上只是将回调添加到了宏任务队列中,但是如果主线程上有任务还没有执行完成,它必须要等待。
如果你对前面这句话不是非常理解,那么有必要了解一下 JS的运行机制。
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在"任务队列"(task queue)。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
如 setTimeout(()=>{callback();}, 1000) ,即表示在1s之后将 callback 放到宏任务队列中,当1s的时间到达时,如果主线程上有其它任务在执行,那么 callback 就必须要等待,另外 callback 的执行也需要时间,因此 setTimeout 的时间间隔是有误差的,它只能保证延时不小于设置的时间。
setTimeout 的误差我们只能减少执行多次的 setTimeout 的误差,例如倒计时功能。
倒计时的时间通常都是从服务端获取的。造成误差的原因:
1.没有考虑误差时间(函数执行的时间/其它代码的阻塞)
2.没有考虑浏览器的“休眠”
完全消除 setTimeout的误差是不可能的,但是我们减少 setTimeout 的误差。通过对下一次任务的调用时间进行修正,来减少误差。
let count = 0;
let countdown = 5000; //服务器返回的倒计时时间
let interval = 1000;
let startTime = new Date().getTime();
let timer = setTimeout(countDownStart, interval); //首次执行
//定时器测试
function countDownStart() {
count++;
const offset = new Date().getTime() - (startTime + count * 1000);
const nextInterval = interval - offset; //修正后的延时时间
if (nextInterval < 0) {
nextInterval = 0;
}
countdown -= interval;
console.log("误差:" + offset + "ms,下一次执行:" + nextInterval + "ms后,离活动开始还有:" + countdown + "ms");
if (countdown <= 0) {
clearTimeout(timer);
} else {
timer = setTimeout(countDownStart, nextInterval);
}
}如果当前页面是不可见的,那么倒计时会出现大于100ms的误差时间。因此在页面显示时,应该重新从服务端获取剩余时间进行倒计时。当然,为了更好的性能,当倒计时不可见(Tab页切换/倒计时内容不在可视区时),可以选择停止倒计时。
为此,我们可以监听 visibityChange 事件进行处理。
[2] https://www.ecma-international.org/ecma-262/6.0/#sec-completion-record-specification-type
[3] http://www.xuanfengge.com/js-realizes-precise-countdown.html
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。https://github.com/YvetteLau/Blog
关注公众号,加入技术交流群。
//?
if(a == 1 && a == 2 && a == 3) {
console.log(1);
}互联网寒冬之际,各大公司都缩减了HC,甚至是采取了“裁员”措施,在这样的大环境之下,想要获得一份更好的工作,必然需要付出更多的努力。
一年前,也许你搞清楚闭包,this,原型链,就能获得认可。但是现在,很显然是不行了。本文梳理出了一些面试中有一定难度的高频原生JS问题,部分知识点可能你之前从未关注过,或者看到了,却没有仔细研究,但是它们却非常重要。本文将以真实的面试题的形式来呈现知识点,大家在阅读时,建议不要先看我的答案,而是自己先思考一番。尽管,本文所有的答案,都是我在翻阅各种资料,思考并验证之后,才给出的(绝非复制粘贴而来)。但因水平有限,本人的答案未必是最优的,如果您有更好的答案,欢迎给我留言。
本文篇幅较长,但是满满的都是干货!并且还埋伏了可爱的表情包,希望小伙伴们能够坚持读完。
写文超级真诚的小姐姐祝愿大家都能找到心仪的工作。
如果你还没读过上篇【上篇和中篇并无依赖关系,您可以读过本文之后再阅读上篇】,可戳【面试篇】寒冬求职季之你必须要懂的原生JS(上)
小姐姐花了近百个小时才完成这篇文章,篇幅较长,希望大家阅读时多花点耐心,力求真正的掌握相关知识点。
异步最早的解决方案是回调函数,如事件的回调,setInterval/setTimeout中的回调。但是回调函数有一个很常见的问题,就是回调地狱的问题(稍后会举例说明);
为了解决回调地狱的问题,社区提出了Promise解决方案,ES6将其写进了语言标准。Promise解决了回调地狱的问题,但是Promise也存在一些问题,如错误不能被try catch,而且使用Promise的链式调用,其实并没有从根本上解决回调地狱的问题,只是换了一种写法。
ES6中引入 Generator 函数,Generator是一种异步编程解决方案,Generator 函数是协程在 ES6 的实现,最大特点就是可以交出函数的执行权,Generator 函数可以看出是异步任务的容器,需要暂停的地方,都用yield语句注明。但是 Generator 使用起来较为复杂。
ES7又提出了新的异步解决方案:async/await,async是 Generator 函数的语法糖,async/await 使得异步代码看起来像同步代码,异步编程发展的目标就是让异步逻辑的代码看起来像同步一样。
1.回调函数: callback
//node读取文件
fs.readFile(xxx, 'utf-8', function(err, data) {
//code
});回调函数的使用场景(包括但不限于):
异步回调嵌套会导致代码难以维护,并且不方便统一处理错误,不能try catch 和 回调地狱(如先读取A文本内容,再根据A文本内容读取B再根据B的内容读取C...)。
fs.readFile(A, 'utf-8', function(err, data) {
fs.readFile(B, 'utf-8', function(err, data) {
fs.readFile(C, 'utf-8', function(err, data) {
fs.readFile(D, 'utf-8', function(err, data) {
//....
});
});
});
});2.Promise
Promise 主要解决了回调地狱的问题,Promise 最早由社区提出和实现,ES6 将其写进了语言标准,统一了用法,原生提供了Promise对象。
那么我们看看Promise是如何解决回调地狱问题的,仍然以上文的readFile为例。
function read(url) {
return new Promise((resolve, reject) => {
fs.readFile(url, 'utf8', (err, data) => {
if(err) reject(err);
resolve(data);
});
});
}
read(A).then(data => {
return read(B);
}).then(data => {
return read(C);
}).then(data => {
return read(D);
}).catch(reason => {
console.log(reason);
});想要运行代码看效果,请戳(小姐姐使用的是VS的 Code Runner 执行代码): https://github.com/YvetteLau/Blog/blob/master/JS/Async/promise.js
思考一下在Promise之前,你是如何处理异步并发问题的,假设有这样一个需求:读取三个文件内容,都读取成功后,输出最终的结果。有了Promise之后,又如何处理呢?代码可戳: https://github.com/YvetteLau/Blog/blob/master/JS/Async/index.js
注: 可以使用 bluebird 将接口 promise化;
引申: Promise有哪些优点和问题呢?
3.Generator
Generator 函数是 ES6 提供的一种异步编程解决方案,整个 Generator 函数就是一个封装的异步任务,或者说是异步任务的容器。异步操作需要暂停的地方,都用 yield 语句注明。
Generator 函数一般配合 yield 或 Promise 使用。Generator函数返回的是迭代器。对生成器和迭代器不了解的同学,请自行补习下基础。下面我们看一下 Generator 的简单使用:
function* gen() {
let a = yield 111;
console.log(a);
let b = yield 222;
console.log(b);
let c = yield 333;
console.log(c);
let d = yield 444;
console.log(d);
}
let t = gen();
//next方法可以带一个参数,该参数就会被当作上一个yield表达式的返回值
t.next(1); //第一次调用next函数时,传递的参数无效
t.next(2); //a输出2;
t.next(3); //b输出2;
t.next(4); //c输出3;
t.next(5); //d输出3;为了让大家更好的理解上面代码是如何执行的,我画了一张图,分别对应每一次的next方法调用:
仍然以上文的readFile为例,使用 Generator + co库来实现:
const fs = require('fs');
const co = require('co');
const bluebird = require('bluebird');
const readFile = bluebird.promisify(fs.readFile);
function* read() {
yield readFile(A, 'utf-8');
yield readFile(B, 'utf-8');
yield readFile(C, 'utf-8');
//....
}
co(read()).then(data => {
//code
}).catch(err => {
//code
});不使用co库,如何实现?能否自己写一个最简的my_co?请戳: https://github.com/YvetteLau/Blog/blob/master/JS/Async/generator.js
PS: 如果你还不太了解 Generator/yield,建议阅读ES6相关文档。
4.async/await
ES7中引入了 async/await 概念。async其实是一个语法糖,它的实现就是将Generator函数和自动执行器(co),包装在一个函数中。
async/await 的优点是代码清晰,不用像 Promise 写很多 then 链,就可以处理回调地狱的问题。错误可以被try catch。
仍然以上文的readFile为例,使用 Generator + co库来实现:
const fs = require('fs');
const bluebird = require('bluebird');
const readFile = bluebird.promisify(fs.readFile);
async function read() {
await readFile(A, 'utf-8');
await readFile(B, 'utf-8');
await readFile(C, 'utf-8');
//code
}
read().then((data) => {
//code
}).catch(err => {
//code
});可执行代码,请戳:https://github.com/YvetteLau/Blog/blob/master/JS/Async/async.js
思考一下 async/await 如何处理异步并发问题的? https://github.com/YvetteLau/Blog/blob/master/JS/Async/index.js
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:说一说JS异步发展史
async/await 就是 Generator 的语法糖,使得异步操作变得更加方便。来张图对比一下:
async 函数就是将 Generator 函数的星号(*)替换成 async,将 yield 替换成await。
我们说 async 是 Generator 的语法糖,那么这个糖究竟甜在哪呢?
1)async函数内置执行器,函数调用之后,会自动执行,输出最后结果。而Generator需要调用next或者配合co模块使用。
2)更好的语义,async和await,比起星号和yield,语义更清楚了。async表示函数里有异步操作,await表示紧跟在后面的表达式需要等待结果。
3)更广的适用性。co模块约定,yield命令后面只能是 Thunk 函数或 Promise 对象,而async 函数的 await 命令后面,可以是 Promise 对象和原始类型的值。
4)返回值是Promise,async函数的返回值是 Promise 对象,Generator的返回值是 Iterator,Promise 对象使用起来更加方便。
async 函数的实现原理,就是将 Generator 函数和自动执行器,包装在一个函数里。
具体代码试下如下(和spawn的实现略有差异,个人觉得这样写更容易理解),如果你想知道如何一步步写出 my_co ,可戳: https://github.com/YvetteLau/Blog/blob/master/JS/Async/my_async.js
function my_co(it) {
return new Promise((resolve, reject) => {
function next(data) {
try {
var { value, done } = it.next(data);
}catch(e){
return reject(e);
}
if (!done) {
//done为true,表示迭代完成
//value 不一定是 Promise,可能是一个普通值。使用 Promise.resolve 进行包装。
Promise.resolve(value).then(val => {
next(val);
}, reject);
} else {
resolve(value);
}
}
next(); //执行一次next
});
}
function* test() {
yield new Promise((resolve, reject) => {
setTimeout(resolve, 100);
});
yield new Promise((resolve, reject) => {
// throw Error(1);
resolve(10)
});
yield 10;
return 1000;
}
my_co(test()).then(data => {
console.log(data); //输出1000
}).catch((err) => {
console.log('err: ', err);
});如果你有更好的答案或想法,欢迎在这题目对应的github下留言:谈谈对 async/await 的理解,async/await 的实现原理是什么?
try...catch 中。//下面两种写法都可以同时触发
//法一
async function f1() {
await Promise.all([
new Promise((resolve) => {
setTimeout(resolve, 600);
}),
new Promise((resolve) => {
setTimeout(resolve, 600);
})
])
}
//法二
async function f2() {
let fn1 = new Promise((resolve) => {
setTimeout(resolve, 800);
});
let fn2 = new Promise((resolve) => {
setTimeout(resolve, 800);
})
await fn1;
await fn2;
}/**
* 函数a内部运行了一个异步任务b()。当b()运行的时候,函数a()不会中断,而是继续执行。
* 等到b()运行结束,可能a()早就* 运行结束了,b()所在的上下文环境已经消失了。
* 如果b()或c()报错,错误堆栈将不包括a()。
*/
function b() {
return new Promise((resolve, reject) => {
setTimeout(resolve, 200)
});
}
function c() {
throw Error(10);
}
const a = () => {
b().then(() => c());
};
a();
/**
* 改成async函数
*/
const m = async () => {
await b();
c();
};
m();报错信息如下,可以看出 async 函数可以保留运行堆栈。
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:使用 async/await 需要注意什么?
在代码实现前,我们需要先了解 Promise.race 的特点:
Promise.race返回的仍然是一个Promise.
它的状态与第一个完成的Promise的状态相同。它可以是完成( resolves),也可以是失败(rejects),这要取决于第一个Promise是哪一种状态。
如果传入的参数是不可迭代的,那么将会抛出错误。
如果传的参数数组是空,那么返回的 promise 将永远等待。
如果迭代包含一个或多个非承诺值和/或已解决/拒绝的承诺,则 Promise.race 将解析为迭代中找到的第一个值。
Promise.race = function (promises) {
//promises 必须是一个可遍历的数据结构,否则抛错
return new Promise((resolve, reject) => {
if (typeof promises[Symbol.iterator] !== 'function') {
//真实不是这个错误
Promise.reject('args is not iteratable!');
}
if (promises.length === 0) {
return;
} else {
for (let i = 0; i < promises.length; i++) {
Promise.resolve(promises[i]).then((data) => {
resolve(data);
return;
}, (err) => {
reject(err);
return;
});
}
}
});
}测试代码:
//一直在等待态
Promise.race([]).then((data) => {
console.log('success ', data);
}, (err) => {
console.log('err ', err);
});
//抛错
Promise.race().then((data) => {
console.log('success ', data);
}, (err) => {
console.log('err ', err);
});
Promise.race([
new Promise((resolve, reject) => { setTimeout(() => { resolve(100) }, 1000) }),
new Promise((resolve, reject) => { setTimeout(() => { resolve(200) }, 200) }),
new Promise((resolve, reject) => { setTimeout(() => { reject(100) }, 100) })
]).then((data) => {
console.log(data);
}, (err) => {
console.log(err);
});引申: Promise.all/Promise.reject/Promise.resolve/Promise.prototype.finally/Promise.prototype.catch 的实现原理,如果还不太会,戳:Promise源码实现
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:如何实现 Promise.race?
一个对象如果要具备可被 for...of 循环调用的 Iterator 接口,就必须在其 Symbol.iterator 的属性上部署遍历器生成方法(或者原型链上的对象具有该方法)
PS: 遍历器对象根本特征就是具有next方法。每次调用next方法,都会返回一个代表当前成员的信息对象,具有value和done两个属性。
//如为对象添加Iterator 接口;
let obj = {
name: "Yvette",
age: 18,
job: 'engineer',
[Symbol.iterator]() {
const self = this;
const keys = Object.keys(self);
let index = 0;
return {
next() {
if (index < keys.length) {
return {
value: self[keys[index++]],
done: false
};
} else {
return { value: undefined, done: true };
}
}
};
}
};
for(let item of obj) {
console.log(item); //Yvette 18 engineer
}使用 Generator 函数(遍历器对象生成函数)简写 Symbol.iterator 方法,可以简写如下:
let obj = {
name: "Yvette",
age: 18,
job: 'engineer',
* [Symbol.iterator] () {
const self = this;
const keys = Object.keys(self);
for (let index = 0;index < keys.length; index++) {
yield self[keys[index]];//yield表达式仅能使用在 Generator 函数中
}
}
};原生具备 Iterator 接口的数据结构如下。
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:可遍历数据结构的有什么特点?
在 requestAnimationFrame 之前,我们主要使用 setTimeout/setInterval 来编写JS动画。
编写动画的关键是循环间隔的设置,一方面,循环间隔足够短,动画效果才能显得平滑流畅;另一方面,循环间隔还要足够长,才能确保浏览器有能力渲染产生的变化。
大部分的电脑显示器的刷新频率是60HZ,也就是每秒钟重绘60次。大多数浏览器都会对重绘操作加以限制,不超过显示器的重绘频率,因为即使超过那个频率用户体验也不会提升。因此,最平滑动画的最佳循环间隔是 1000ms / 60 ,约为16.7ms。
setTimeout/setInterval 有一个显著的缺陷在于时间是不精确的,setTimeout/setInterval 只能保证延时或间隔不小于设定的时间。因为它们实际上只是把任务添加到了任务队列中,但是如果前面的任务还没有执行完成,它们必须要等待。
requestAnimationFrame 才有的是系统时间间隔,保持最佳绘制效率,不会因为间隔时间过短,造成过度绘制,增加开销;也不会因为间隔时间太长,使用动画卡顿不流畅,让各种网页动画效果能够有一个统一的刷新机制,从而节省系统资源,提高系统性能,改善视觉效果。
综上所述,requestAnimationFrame 和 setTimeout/setInterval 在编写动画时相比,优点如下:
1.requestAnimationFrame 不需要设置时间,采用系统时间间隔,能达到最佳的动画效果。
2.requestAnimationFrame 会把每一帧中的所有DOM操作集中起来,在一次重绘或回流中就完成。
3.当 requestAnimationFrame() 运行在后台标签页或者隐藏的 <iframe> 里时,requestAnimationFrame() 会被暂停调用以提升性能和电池寿命(大多数浏览器中)。
requestAnimationFrame 使用(试试使用requestAnimationFrame写一个移动的小球,从A移动到B初):
function step(timestamp) {
//code...
window.requestAnimationFrame(step);
}
window.requestAnimationFrame(step);如果你有更好的答案或想法,欢迎在这题目对应的github下留言:requestAnimationFrame 和 setTimeout/setInterval 有什么区别?使用 requestAnimationFrame 有哪些好处?
类型转换的规则三言两语说不清,真想哇得一声哭出来~
JS中类型转换分为 强制类型转换 和 隐式类型转换 。
通过 Number()、parseInt()、parseFloat()、toString()、String()、Boolean(),进行强制类型转换。
逻辑运算符(&&、 ||、 !)、运算符(+、-、*、/)、关系操作符(>、 <、 <= 、>=)、相等运算符(==)或者 if/while 的条件,可能会进行隐式类型转换。
强制类型转换
1.Number() 将任意类型的参数转换为数值类型
规则如下:
NAN0X / 0x 开头的十六进制数字字符串,允许包含正负号),则将其转换为十进制NaNvalueOf() 方法,然后依据前面的规则转换返回的值。如果转换的结果是 NaN ,则调用对象的 toString() 方法,再次依照前面的规则转换返回的字符串值。部分内置对象调用默认的 valueOf 的行为:
| 对象 | 返回值 |
|---|---|
| Array | 数组本身(对象类型) |
| Boolean | 布尔值(原始类型) |
| Date | 从 UTC 1970 年 1 月 1 日午夜开始计算,到所封装的日期所经过的毫秒数 |
| Function | 函数本身(对象类型) |
| Number | 数字值(原始类型) |
| Object | 对象本身(对象类型) |
| String | 字符串值(原始类型) |
Number('0111'); //111
Number('0X11') //17
Number(null); //0
Number(''); //0
Number('1a'); //NaN
Number(-0X11);//-172.parseInt(param, radix)
如果第一个参数传入的是字符串类型:
如果第一个参数传入的Number类型:
如果第一个参数是 null 或者是 undefined,或者是一个对象类型:
如果第一个参数是数组:
1. 去数组的第一个元素,按照上面的规则进行解析
如果第一个参数是Symbol类型:
1. 抛出错误
如果指定radix参数,以radix为基数进行解析
parseInt('0111'); //111
parseInt(0111); //八进制数 73
parseInt('');//NaN
parseInt('0X11'); //17
parseInt('1a') //1
parseInt('a1'); //NaN
parseInt(['10aa','aaa']);//10
parseInt([]);//NaN; parseInt(undefined);parseFloat
规则和parseInt基本相同,接受一个Number类型或字符串,如果是字符串中,那么只有第一个小数点是有效的。
toString()
规则如下:
''[object Object]let arry = [];
let obj = {a:1};
let sym = Symbol(100);
let date = new Date();
let fn = function() {console.log('稳住,我们能赢!')}
let str = 'hello world';
console.log([].toString()); // ''
console.log([1, 2, 3, undefined, 5, 6].toString());//1,2,3,,5,6
console.log(arry.toString()); // 1,2,3
console.log(obj.toString()); // [object Object]
console.log(date.toString()); // Sun Apr 21 2019 16:11:39 GMT+0800 (CST)
console.log(fn.toString());// function () {console.log('稳住,我们能赢!')}
console.log(str.toString());// 'hello world'
console.log(sym.toString());// Symbol(100)
console.log(undefined.toString());// 抛错
console.log(null.toString());// 抛错String()
String() 的转换规则与 toString() 基本一致,最大的一点不同在于 null 和 undefined,使用 String 进行转换,null 和 undefined对应的是字符串 'null' 和 'undefined'
Boolean
除了 undefined、 null、 false、 ''、 0(包括 +0,-0)、 NaN 转换出来是false,其它都是true.
隐式类型转换
&& 、|| 、 ! 、 if/while 的条件判断
需要将数据转换成 Boolean 类型,转换规则同 Boolean 强制类型转换
运算符: + - * /
+ 号操作符,不仅可以用作数字相加,还可以用作字符串拼接。
仅当 + 号两边都是数字时,进行的是加法运算。如果两边都是字符串,直接拼接,无需进行隐式类型转换。
除了上面的情况外,如果操作数是对象、数值或者布尔值,则调用toString()方法取得字符串值(toString转换规则)。对于 undefined 和 null,分别调用String()显式转换为字符串,然后再进行拼接。
console.log({}+10); //[object Object]10
console.log([1, 2, 3, undefined, 5, 6] + 10);//1,2,3,,5,610-、*、/ 操作符针对的是运算,如果操作值之一不是数值,则被隐式调用Number()函数进行转换。如果其中有一个转换除了为NaN,结果为NaN.
关系操作符: ==、>、< 、<=、>=
> , < ,<= ,>=
注: NaN是非常特殊的值,它不和任何类型的值相等,包括它自己,同时它与任何类型的值比较大小时都返回false。
console.log(10 > {});//返回false.
/**
*{}.valueOf ---> {}
*{}.toString() ---> '[object Object]' ---> NaN
*NaN 和 任何类型比大小,都返回 false
*/相等操作符:
==
对象如何转换成原始数据类型
如果部署了 [Symbol.toPrimitive] 接口,那么调用此接口,若返回的不是基础数据类型,跑出错误。
如果没有部署 [Symbol.toPrimitive] 接口,那么先返回 valueOf() 的值,若返回的不是基础类型的值,再返回 toString() 的值,若返回的不是基础类型的值, 则抛出异常。
//先调用 valueOf, 后调用 toString
let obj = {
[Symbol.toPrimitive]() {
return 200;
},
valueOf() {
return 300;
},
toString() {
return 'Hello';
}
}
//如果 valueOf 返回的不是基本数据类型,则会调用 toString,
//如果 toString 返回的也不是基本数据类型,会抛出错误
console.log(obj + 200); //400如果你有更好的答案或想法,欢迎在这题目对应的github下留言:JS 类型转换的规则是什么?
HTML5则提出了 Web Worker 标准,表示js允许多线程,但是子线程完全受主线程控制并且不能操作dom,只有主线程可以操作dom,所以js本质上依然是单线程语言。
web worker就是在js单线程执行的基础上开启一个子线程,进行程序处理,而不影响主线程的执行,当子线程执行完之后再回到主线程上,在这个过程中不影响主线程的执行。子线程与主线程之间提供了数据交互的接口postMessage和onmessage,来进行数据发送和接收。
var worker = new Worker('./worker.js'); //创建一个子线程
worker.postMessage('Hello');
worker.onmessage = function (e) {
console.log(e.data); //Hi
worker.terminate(); //结束线程
};//worker.js
onmessage = function (e) {
console.log(e.data); //Hello
postMessage("Hi"); //向主进程发送消息
};仅是最简示例代码,项目中通常是将一些耗时较长的代码,放在子线程中运行。
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:简述下对 webWorker 的理解
ES6模块在编译时,就能确定模块的依赖关系,以及输入和输出的变量。
CommonJS 模块,运行时加载。
ES6 模块自动采用严格模式,无论模块头部是否写了 "use strict"; (严格模式有哪些限制?[//链接])
require 可以做动态加载,import 语句做不到,import 语句必须位于顶层作用域中。
ES6 模块中顶层的 this 指向 undefined,ommonJS 模块的顶层 this 指向当前模块。
CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
CommonJS 模块输出的是值的拷贝,也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。如:
//name.js
var name = 'William';
setTimeout(() => name = 'Yvette', 200);
module.exports = {
name
};
//index.js
const name = require('./name');
console.log(name); //William
setTimeout(() => console.log(name), 300); //William对比 ES6 模块看一下:
ES6 模块的运行机制与 CommonJS 不一样。JS 引擎对脚本静态分析的时候,遇到模块加载命令 import ,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。
//name.js
var name = 'William';
setTimeout(() => name = 'Yvette', 200);
export { name };
//index.js
import { name } from './name';
console.log(name); //William
setTimeout(() => console.log(name), 300); //Yvette如果你有更好的答案或想法,欢迎在这题目对应的github下留言:ES6模块和CommonJS模块的差异?
在说浏览器事件代理机制原理之前,我们首先了解一下事件流的概念,早期浏览器,IE采用的是事件捕获事件流,而Netscape采用的则是事件捕获。"DOM2级事件"把事件流分为三个阶段,捕获阶段、目标阶段、冒泡阶段。现代浏览器也都遵循此规范。
那么事件代理是什么呢?
事件代理又称为事件委托,在祖先级DOM元素绑定一个事件,当触发子孙级DOM元素的事件时,利用事件冒泡的原理来触发绑定在祖先级DOM的事件。因为事件会从目标元素一层层冒泡至document对象。
为什么要事件代理?
添加到页面上的事件数量会影响页面的运行性能,如果添加的事件过多,会导致网页的性能下降。采用事件代理的方式,可以大大减少注册事件的个数。
事件代理的当时,某个子孙元素是动态增加的,不需要再次对其进行事件绑定。
不用担心某个注册了事件的DOM元素被移除后,可能无法回收其事件处理程序,我们只要把事件处理程序委托给更高层级的元素,就可以避免此问题。
如将页面中的所有click事件都代理到document上:
addEventListener 接受3个参数,分别是要处理的事件名、处理事件程序的函数和一个布尔值。布尔值默认为false。表示冒泡阶段调用事件处理程序,若设置为true,表示在捕获阶段调用事件处理程序。
document.addEventListener('click', function (e) {
console.log(e.target);
/**
* 捕获阶段调用调用事件处理程序,eventPhase是 1;
* 处于目标,eventPhase是2
* 冒泡阶段调用事件处理程序,eventPhase是 1;
*/
console.log(e.eventPhase);
});如果你有更好的答案或想法,欢迎在这题目对应的github下留言:浏览器事件代理机制的原理是什么?
自定义 DOM 事件(不考虑IE9之前版本)
自定义事件有三种方法,一种是使用 new Event(), 另一种是 createEvent('CustomEvent') , 另一种是 new customEvent()
new Event()获取不到 event.detail
let btn = document.querySelector('#btn');
let ev = new Event('alert', {
bubbles: true, //事件是否冒泡;默认值false
cancelable: true, //事件能否被取消;默认值false
composed: false
});
btn.addEventListener('alert', function (event) {
console.log(event.bubbles); //true
console.log(event.cancelable); //true
console.log(event.detail); //undefined
}, false);
btn.dispatchEvent(ev);createEvent('CustomEvent') (DOM3)要创建自定义事件,可以调用 createEvent('CustomEvent'),返回的对象有 initCustomEvent 方法,接受以下四个参数:
let btn = document.querySelector('#btn');
let ev = btn.createEvent('CustomEvent');
ev.initCustomEvent('alert', true, true, 'button');
btn.addEventListener('alert', function (event) {
console.log(event.bubbles); //true
console.log(event.cancelable);//true
console.log(event.detail); //button
}, false);
btn.dispatchEvent(ev);new customEvent() (DOM4)使用起来比 createEvent('CustomEvent') 更加方便
var btn = document.querySelector('#btn');
/*
* 第一个参数是事件类型
* 第二个参数是一个对象
*/
var ev = new CustomEvent('alert', {
bubbles: 'true',
cancelable: 'true',
detail: 'button'
});
btn.addEventListener('alert', function (event) {
console.log(event.bubbles); //true
console.log(event.cancelable);//true
console.log(event.detail); //button
}, false);
btn.dispatchEvent(ev);自定义非 DOM 事件(观察者模式)
EventTarget类型有一个单独的属性handlers,用于存储事件处理程序(观察者)。
addHandler() 用于注册给定类型事件的事件处理程序;
fire() 用于触发一个事件;
removeHandler() 用于注销某个事件类型的事件处理程序。
function EventTarget(){
this.handlers = {};
}
EventTarget.prototype = {
constructor:EventTarget,
addHandler:function(type,handler){
if(typeof this.handlers[type] === "undefined"){
this.handlers[type] = [];
}
this.handlers[type].push(handler);
},
fire:function(event){
if(!event.target){
event.target = this;
}
if(this.handlers[event.type] instanceof Array){
const handlers = this.handlers[event.type];
handlers.forEach((handler)=>{
handler(event);
});
}
},
removeHandler:function(type,handler){
if(this.handlers[type] instanceof Array){
const handlers = this.handlers[type];
for(var i = 0,len = handlers.length; i < len; i++){
if(handlers[i] === handler){
break;
}
}
handlers.splice(i,1);
}
}
}
//使用
function handleMessage(event){
console.log(event.message);
}
//创建一个新对象
var target = new EventTarget();
//添加一个事件处理程序
target.addHandler("message", handleMessage);
//触发事件
target.fire({type:"message", message:"Hi"}); //Hi
//删除事件处理程序
target.removeHandler("message",handleMessage);
//再次触发事件,没有事件处理程序
target.fire({type:"message",message: "Hi"});如果你有更好的答案或想法,欢迎在这题目对应的github下留言:js如何自定义事件?
知其然知其所以然,在说跨域方法之前,我们先了解下什么叫跨域,浏览器有同源策略,只有当“协议”、“域名”、“端口号”都相同时,才能称之为是同源,其中有一个不同,即是跨域。
那么同源策略的作用是什么呢?同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。
那么我们又为什么需要跨域呢?一是前端和服务器分开部署,接口请求需要跨域,二是我们可能会加载其它网站的页面作为iframe内嵌。
跨域的方法有哪些?
常用的跨域方法
尽管浏览器有同源策略,但是 <script> 标签的 src 属性不会被同源策略所约束,可以获取任意服务器上的脚本并执行。jsonp 通过插入script标签的方式来实现跨域,参数只能通过url传入,仅能支持get请求。
实现原理:
Step1: 创建 callback 方法
Step2: 插入 script 标签
Step3: 后台接受到请求,解析前端传过去的 callback 方法,返回该方法的调用,并且数据作为参数传入该方法
Step4: 前端执行服务端返回的方法调用
下面代码仅为说明 jsonp 原理,项目中请使用成熟的库。分别看一下前端和服务端的简单实现:
//前端代码
function jsonp({url, params, cb}) {
return new Promise((resolve, reject) => {
//创建script标签
let script = document.createElement('script');
//将回调函数挂在 window 上
window[cb] = function(data) {
resolve(data);
//代码执行后,删除插入的script标签
document.body.removeChild(script);
}
//回调函数加在请求地址上
params = {...params, cb} //wb=b&cb=show
let arrs = [];
for(let key in params) {
arrs.push(`${key}=${params[key]}`);
}
script.src = `${url}?${arrs.join('&')}`;
document.body.appendChild(script);
});
}
//使用
function sayHi(data) {
console.log(data);
}
jsonp({
url: 'http://localhost:3000/say',
params: {
//code
},
cb: 'sayHi'
}).then(data => {
console.log(data);
});//express启动一个后台服务
let express = require('express');
let app = express();
app.get('/say', (req, res) => {
let {cb} = req.query; //获取传来的callback函数名,cb是key
res.send(`${cb}('Hello!')`);
});
app.listen(3000);从今天起,jsonp的原理就要了然于心啦~
jsonp 只能支持 get 请求,cors 可以支持多种请求。cors 并不需要前端做什么工作。
简单跨域请求:
只要服务器设置的Access-Control-Allow-Origin Header和请求来源匹配,浏览器就允许跨域
//简单跨域请求
app.use((req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', 'XXXX');
});带预检(Preflighted)的跨域请求
不满于简单跨域请求的,即是带预检的跨域请求。服务端需要设置 Access-Control-Allow-Origin (允许跨域资源请求的域) 、 Access-Control-Allow-Methods (允许的请求方法) 和 Access-Control-Allow-Headers (允许的请求头)
app.use((req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', 'XXX');
res.setHeader('Access-Control-Allow-Headers', 'XXX'); //允许返回的头
res.setHeader('Access-Control-Allow-Methods', 'XXX');//允许使用put方法请求接口
res.setHeader('Access-Control-Max-Age', 6); //预检的存活时间
if(req.method === "OPTIONS") {
res.end(); //如果method是OPTIONS,不做处理
}
});更多CORS的知识可以访问: HTTP访问控制(CORS)
使用nginx反向代理实现跨域,只需要修改nginx的配置即可解决跨域问题。
A网站向B网站请求某个接口时,向B网站发送一个请求,nginx根据配置文件接收这个请求,代替A网站向B网站来请求。
nginx拿到这个资源后再返回给A网站,以此来解决了跨域问题。
例如nginx的端口号为 8090,需要请求的服务器端口号为 3000。(localhost:8090 请求 localhost:3000/say)
nginx配置如下:
server {
listen 8090;
server_name localhost;
location / {
root /Users/liuyan35/Test/Study/CORS/1-jsonp;
index index.html index.htm;
}
location /say {
rewrite ^/say/(.*)$ /$1 break;
proxy_pass http://localhost:3000;
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
}
# others
}
Websocket 是 HTML5 的一个持久化的协议,它实现了浏览器与服务器的全双工通信,同时也是跨域的一种解决方案。
Websocket 不受同源策略影响,只要服务器端支持,无需任何配置就支持跨域。
前端页面在 8080 的端口。
let socket = new WebSocket('ws://localhost:3000'); //协议是ws
socket.onopen = function() {
socket.send('Hi,你好');
}
socket.onmessage = function(e) {
console.log(e.data)
}服务端 3000端口。可以看出websocket无需做跨域配置。
let WebSocket = require('ws');
let wss = new WebSocket.Server({port: 3000});
wss.on('connection', function(ws) {
ws.on('message', function(data) {
console.log(data); //接受到页面发来的消息'Hi,你好'
ws.send('Hi'); //向页面发送消息
});
});postMessage 通过用作前端页面之前的跨域,如父页面与iframe页面的跨域。window.postMessage方法,允许跨窗口通信,不论这两个窗口是否同源。
话说工作中两个页面之前需要通信的情况并不多,我本人工作中,仅使用过两次,一次是H5页面中发送postMessage信息,ReactNative的webview中接收此此消息,并作出相应处理。另一次是可轮播的页面,某个轮播页使用的是iframe页面,为了解决滑动的事件冲突,iframe页面中去监听手势,发送消息告诉父页面是否左滑和右滑。
子页面向父页面发消息
父页面
window.addEventListener('message', (e) => {
this.props.movePage(e.data);
}, false);子页面(iframe):
if(/*左滑*/) {
window.parent && window.parent.postMessage(-1, '*')
}else if(/*右滑*/){
window.parent && window.parent.postMessage(1, '*')
}父页面向子页面发消息
父页面:
let iframe = document.querySelector('#iframe');
iframe.onload = function() {
iframe.contentWindow.postMessage('hello', 'http://localhost:3002');
}子页面:
window.addEventListener('message', function(e) {
console.log(e.data);
e.source.postMessage('Hi', e.origin); //回消息
});node 中间件的跨域原理和nginx代理跨域,同源策略是浏览器的限制,服务端没有同源策略。
node中间件实现跨域的原理如下:
1.接受客户端请求
2.将请求 转发给服务器。
3.拿到服务器 响应 数据。
4.将 响应 转发给客户端。
不常用跨域方法
以下三种跨域方式很少用,如有兴趣,可自行查阅相关资料。
window.name + iframe
location.hash + iframe
document.domain (主域需相同)
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:跨域的方法有哪些?原理是什么?
<script> 的 defer 属性,HTML4 中新增
<script> 的 async 属性,HTML5 中新增
<script>标签打开defer属性,脚本就会异步加载。渲染引擎遇到这一行命令,就会开始下载外部脚本,但不会等它下载和执行,而是直接执行后面的命令。
defer 和 async 的区别在于: defer要等到整个页面在内存中正常渲染结束,才会执行;
async一旦下载完,渲染引擎就会中断渲染,执行这个脚本以后,再继续渲染。defer是“渲染完再执行”,async是“下载完就执行”。
如果有多个 defer 脚本,会按照它们在页面出现的顺序加载。
多个async脚本是不能保证加载顺序的。
function downloadJS() {
varelement = document.createElement("script");
element.src = "XXX.js";
document.body.appendChild(element);
}
//何时的时候,调用上述方法 如页面 onload 之后,
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:js异步加载的方式有哪些?
//?
if(a == 1 && a == 2 && a == 3) {
console.log(1);
}1.在类型转换的时候,我们知道了对象如何转换成原始数据类型。如果部署了 [Symbol.toPrimitive],那么返回的就是Symbol.toPrimitive的返回值。当然,我们也可以把此函数部署在valueOf或者是toString接口上,效果相同。
//利用闭包延长作用域的特性
let a = {
[Symbol.toPrimitive]: (function() {
let i = 1;
return function() {
return i++;
}
})()
}(1). 比较 a == 1 时,会调用 [Symbol.toPrimitive],此时 i 是 1,相等。
(2). 继续比较 a == 2,调用 [Symbol.toPrimitive],此时 i 是 2,相等。
(3). 继续比较 a == 3,调用 [Symbol.toPrimitive],此时 i 是 3,相等。
2.利用Object.definePropert在window/global上定义a属性,获取a属性时,会调用get.
let val = 1;
Object.defineProperty(window, 'a', {
get: function() {
return val++;
}
});3.利用数组的特性。
var a = [1,2,3];
a.join = a.shift;数组的 toString 方法返回一个字符串,该字符串由数组中的每个元素的 toString() 返回值经调用 join() 方法连接(由逗号隔开)组成。
因此,我们可以重新 join 方法。返回第一个元素,并将其删除。
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:下面代码a在什么情况中打印出1?
function Foo() {
getName = function() {console.log(1)};
return this;
}
Foo.getName = function() {console.log(2)};
Foo.prototype.getName = function() {console.log(3)};
var getName = function() {console.log(4)};
function getName() {console.log(5)};
Foo.getName();
getName();
Foo().getName();
getName();
new Foo.getName();
new Foo().getName();
new new Foo().getName();**说明:**一道经典的面试题,仅是为了帮助大家回顾一下知识点,加深理解,真实工作中,是不可能这样写代码的,否则,肯定会被打死的。
1.首先预编译阶段,变量声明与函数声明提升至其对应作用域的最顶端。
因此上面的代码编译后如下(函数声明的优先级先于变量声明):
function Foo() {
getName = function() {console.log(1)};
return this;
}
var getName;
function getName() {console.log(5)};
Foo.getName = function() {console.log(2)};
Foo.prototype.getName = function() {console.log(3)};
getName = function() {console.log(4)};2.Foo.getName();直接调用Foo上getName方法,输出2
3.getName();输出4,getName被重新赋值了
4.Foo().getName();执行Foo(),window的getName被重新赋值,返回this;浏览器环境中,非严格模式,this 指向 window,this.getName();输出为1.
如果是严格模式,this 指向 undefined,此处会抛出错误。
如果是node环境中,this 指向 global,node的全局变量并不挂在global上,因为global.getName对应的是undefined,不是一个function,会抛出错误。
5.getName();已经抛错的自然走不动这一步了;继续浏览器非严格模式;window.getName被重新赋过值,此时再调用,输出的是1
6.new Foo.getName();考察运算符优先级的知识,new 无参数列表,对应的优先级是18;成员访问操作符 . , 对应的优先级是 19。因此相当于是 new (Foo.getName)();new操作符会执行构造函数中的方法,因此此处输出为 2.
7.new Foo().getName();new 带参数列表,对应的优先级是19,和成员访问操作符.优先级相同。同级运算符,按照从左到右的顺序依次计算。new Foo()先初始化 Foo 的实例化对象,实例上没有getName方法,因此需要原型上去找,即找到了 Foo.prototype.getName,输出3
8.new new Foo().getName(); new 带参数列表,优先级19,因此相当于是 new (new Foo()).getName();先初始化 Foo 的实例化对象,然后将其原型上的 getName 函数作为构造函数再次 new ,输出3
因此最终结果如下:
Foo.getName(); //2
getName();//4
Foo().getName();//1
getName();//1
new Foo.getName();//2
new Foo().getName();//3
new new Foo().getName();//3如果你有更好的答案或想法,欢迎在这题目对应的github下留言:下面这段代码的输出是什么?
Object.definedProperty 的作用是劫持一个对象的属性,劫持属性的getter和setter方法,在对象的属性发生变化时进行特定的操作。而 Proxy 劫持的是整个对象。
Proxy 会返回一个代理对象,我们只需要操作新对象即可,而 Object.defineProperty 只能遍历对象属性直接修改。
Object.definedProperty 不支持数组,更准确的说是不支持数组的各种API,因为如果仅仅考虑arry[i] = value 这种情况,是可以劫持的,但是这种劫持意义不大。而 Proxy 可以支持数组的各种API。
尽管 Object.defineProperty 有诸多缺陷,但是其兼容性要好于 Proxy.
PS: Vue2.x 使用 Object.defineProperty 实现数据双向绑定,V3.0 则使用了 Proxy.
//拦截器
let obj = {};
let temp = 'Yvette';
Object.defineProperty(obj, 'name', {
get() {
console.log("读取成功");
return temp
},
set(value) {
console.log("设置成功");
temp = value;
}
});
obj.name = 'Chris';
console.log(obj.name);PS: Object.defineProperty 定义出来的属性,默认是不可枚举,不可更改,不可配置【无法delete】
我们可以看到 Proxy 会劫持整个对象,读取对象中的属性或者是修改属性值,那么就会被劫持。但是有点需要注意,复杂数据类型,监控的是引用地址,而不是值,如果引用地址没有改变,那么不会触发set。
let obj = {name: 'Yvette', hobbits: ['travel', 'reading'], info: {
age: 20,
job: 'engineer'
}};
let p = new Proxy(obj, {
get(target, key) { //第三个参数是 proxy, 一般不使用
console.log('读取成功');
return Reflect.get(target, key);
},
set(target, key, value) {
if(key === 'length') return true; //如果是数组长度的变化,返回。
console.log('设置成功');
return Reflect.set([target, key, value]);
}
});
p.name = 20; //设置成功
p.age = 20; //设置成功; 不需要事先定义此属性
p.hobbits.push('photography'); //读取成功;注意不会触发设置成功
p.info.age = 18; //读取成功;不会触发设置成功最后,我们再看下对于数组的劫持,Object.definedProperty 和 Proxy 的差别
Object.definedProperty 可以将数组的索引作为属性进行劫持,但是仅支持直接对 arry[i] 进行操作,不支持数组的API,非常鸡肋。
let arry = []
Object.defineProperty(arry, '0', {
get() {
console.log("读取成功");
return temp
},
set(value) {
console.log("设置成功");
temp = value;
}
});
arry[0] = 10; //触发设置成功
arry.push(10); //不能被劫持Proxy 可以监听到数组的变化,支持各种API。注意数组的变化触发get和set可能不止一次,如有需要,自行根据key值决定是否要进行处理。
let hobbits = ['travel', 'reading'];
let p = new Proxy(hobbits, {
get(target, key) {
// if(key === 'length') return true; //如果是数组长度的变化,返回。
console.log('读取成功');
return Reflect.get(target, key);
},
set(target, key, value) {
// if(key === 'length') return true; //如果是数组长度的变化,返回。
console.log('设置成功');
return Reflect.set([target, key, value]);
}
});
p.splice(0,1) //触发get和set,可以被劫持
p.push('photography');//触发get和set
p.slice(1); //触发get;因为 slice 是不会修改原数组的如果你有更好的答案或想法,欢迎在这题目对应的github下留言:实现双向绑定 Proxy 与 Object.defineProperty 相比优劣如何?
Object.is() 与比较操作符 ===、== 有什么区别?以下情况,Object.is认为是相等
两个值都是 undefined
两个值都是 null
两个值都是 true 或者都是 false
两个值是由相同个数的字符按照相同的顺序组成的字符串
两个值指向同一个对象
两个值都是数字并且
都是正零 +0
都是负零 -0
都是 NaN
都是除零和 NaN 外的其它同一个数字
Object.is() 类似于 ===,但是有一些细微差别,如下:
console.log(Object.is(NaN, NaN));//true
console.log(NaN === NaN);//false
console.log(Object.is(-0, +0)); //false
console.log(-0 === +0); //trueObject.is 和 ==差得远了, == 在类型不同时,需要进行类型转换,前文已经详细说明。
如果你有更好的答案或想法,欢迎在这题目对应的github下留言:Object.is() 与比较操作符 ===、== 有什么区别?
最后一道题留给大家回答,再写下去,篇幅实在太长。
针对这道题,后面会专门写一篇文章~
留下你的答案: 什么是事件循环?Node事件循环和JS事件循环的差异是什么?
关于浏览器的event-loop可以看我之前的文章:搞懂浏览器的EventLoop
关注小姐姐的公众号,加入技术交流群。
后续写作计划(写作顺序不定)
1.《寒冬求职季之你必须要懂的原生JS》(下)
2.《寒冬求职季之你必须要知道的CSS》
3.《寒冬求职季之你必须要懂的前端安全》
4.《寒冬求职季之你必须要懂的一些浏览器知识》
5.《寒冬求职季之你必须要知道的性能优化》
6.《寒冬求职季之你必须要懂的webpack原理》
针对React技术栈:
1.《寒冬求职季之你必须要懂的React》系列
2.《寒冬求职季之你必须要懂的ReactNative》系列
本文的写成耗费了非常多的时间,在这个过程中,我也学习到了很多知识,谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。
互联网寒冬之际,各大公司都缩减了HC,甚至是采取了“裁员”措施,在这样的大环境之下,想要获得一份更好的工作,必然需要付出更多的努力。
一年前,也许你搞清楚闭包,this,原型链,就能获得认可。但是现在,很显然是不行了。本文梳理出了一些面试中有一定难度的高频原生JS问题,部分知识点可能你之前从未关注过,或者看到了,却没有仔细研究,但是它们却非常重要。本文将以真实的面试题的形式来呈现知识点,大家在阅读时,建议不要先看我的答案,而是自己先思考一番。尽管,本文所有的答案,都是我在翻阅各种资料,思考并验证之后,才给出的(绝非复制粘贴而来)。但因水平有限,本人的答案未必是最优的,如果您有更好的答案,欢迎给我留言。
本文篇幅较长,但是满满的都是干货!并且还埋伏了可爱的表情包,希望小伙伴们能够坚持读完。
衷心的祝愿大家都能找到心仪的工作。
1. 原始类型有哪几种?null 是对象吗?原始数据类型和复杂数据类型存储有什么区别?
2. typeof 是否正确判断类型? instanceof呢? instanceof 的实现原理是什么?
首先 typeof 能够正确的判断基本数据类型,但是除了 null, typeof null输出的是对象。
但是对象来说,typeof 不能正确的判断其类型, typeof 一个函数可以输出 'function',而除此之外,输出的全是 object,这种情况下,我们无法准确的知道对象的类型。
instanceof可以准确的判断复杂数据类型,但是不能正确判断基本数据类型。(正确判断数据类型请戳:https://github.com/YvetteLau/Blog/blob/master/JS/data-type.js)
instanceof 是通过原型链判断的,A instanceof B, 在A的原型链中层层查找,是否有原型等于B.prototype,如果一直找到A的原型链的顶端(null;即Object.prototype.__proto__),仍然不等于B.prototype,那么返回false,否则返回true.
instanceof的实现代码:
// L instanceof R
function instance_of(L, R) {//L 表示左表达式,R 表示右表达式
var O = R.prototype;// 取 R 的显式原型
L = L.__proto__; // 取 L 的隐式原型
while (true) {
if (L === null) //已经找到顶层
return false;
if (O === L) //当 O 严格等于 L 时,返回 true
return true;
L = L.__proto__; //继续向上一层原型链查找
}
}3. for of , for in 和 forEach,map 的区别。
PS: Object.keys():返回给定对象所有可枚举属性的字符串数组。
关于forEach是否会改变原数组的问题,有些小伙伴提出了异议,为此我写了代码测试了下(注意数组项是复杂数据类型的情况)。
除了forEach之外,map等API,也有同样的问题。
let arry = [1, 2, 3, 4];
arry.forEach((item) => {
item *= 10;
});
console.log(arry); //[1, 2, 3, 4]
arry.forEach((item) => {
arry[1] = 10; //直接操作数组
});
console.log(arry); //[ 1, 10, 3, 4 ]
let arry2 = [
{ name: "Yve" },
{ age: 20 }
];
arry2.forEach((item) => {
item.name = 10;
});
console.log(arry2);//[ { name: 10 }, { age: 20, name: 10 } ]如还不了解 iterator 接口或 for...of, 请先阅读ES6文档: Iterator 和 for...of 循环
更多细节请戳: https://github.com/YvetteLau/Blog/blob/master/JS/for.js
4. 如何判断一个变量是不是数组?
arr.constructor === Array. (不准确,因为我们可以指定 obj.constructor = Array)function fn() {
console.log(Array.isArray(arguments)); //false; 因为arguments是类数组,但不是数组
console.log(Array.isArray([1,2,3,4])); //true
console.log(arguments instanceof Array); //fasle
console.log([1,2,3,4] instanceof Array); //true
console.log(Object.prototype.toString.call(arguments)); //[object Arguments]
console.log(Object.prototype.toString.call([1,2,3,4])); //[object Array]
console.log(arguments.constructor === Array); //false
arguments.constructor = Array;
console.log(arguments.constructor === Array); //true
console.log(Array.isArray(arguments)); //false
}
fn(1,2,3,4);5. 类数组和数组的区别是什么?
类数组:
1)拥有length属性,其它属性(索引)为非负整数(对象中的索引会被当做字符串来处理);
2)不具有数组所具有的方法;
类数组是一个普通对象,而真实的数组是Array类型。
常见的类数组有: 函数的参数 arugments, DOM 对象列表(比如通过 document.querySelectorAll 得到的列表), jQuery 对象 (比如 $("div")).
类数组可以转换为数组:
//第一种方法
Array.prototype.slice.call(arrayLike, start);
//第二种方法
[...arrayLike];
//第三种方法:
Array.from(arrayLike);PS: 任何定义了遍历器(Iterator)接口的对象,都可以用扩展运算符转为真正的数组。
Array.from方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象。
6. == 和 === 有什么区别?
=== 不需要进行类型转换,只有类型相同并且值相等时,才返回 true.
== 如果两者类型不同,首先需要进行类型转换。具体流程如下:
let person1 = {
age: 25
}
let person2 = person1;
person2.gae = 20;
console.log(person1 === person2); //true,注意复杂数据类型,比较的是引用地址思考:
[] == ![]
我们来分析一下: [] == ![] 是true还是false?
![] 引用类型转换成布尔值都是true,因此![]的是false7. ES6中的class和ES5的类有什么区别?
8. 数组的哪些API会改变原数组?
修改原数组的API有:
splice/reverse/fill/copyWithin/sort/push/pop/unshift/shift
不修改原数组的API有:
slice/map/forEach/every/filter/reduce/entries/find
注: 数组的每一项是简单数据类型,且未直接操作数组的情况下。
9. let、const 以及 var 的区别是什么?
10. 在JS中什么是变量提升?什么是暂时性死区?
变量提升就是变量在声明之前就可以使用,值为undefined。
在代码块内,使用 let/const 命令声明变量之前,该变量都是不可用的(会抛出错误)。这在语法上,称为“暂时性死区”。暂时性死区也意味着 typeof 不再是一个百分百安全的操作。
typeof x; // ReferenceError(暂时性死区,抛错)
let x;typeof y; // 值是undefined,不会报错暂时性死区的本质就是,只要一进入当前作用域,所要使用的变量就已经存在了,但是不可获取,只有等到声明变量的那一行代码出现,才可以获取和使用该变量。
11. 如何正确的判断this? 箭头函数的this是什么?
this的绑定规则有四种:默认绑定,隐式绑定,显式绑定,new绑定.
测试下是否已经成功Get了此知识点(浏览器执行环境):
var number = 5;
var obj = {
number: 3,
fn1: (function () {
var number;
this.number *= 2;
number = number * 2;
number = 3;
return function () {
var num = this.number;
this.number *= 2;
console.log(num);
number *= 3;
console.log(number);
}
})()
}
var fn1 = obj.fn1;
fn1.call(null);
obj.fn1();
console.log(window.number);如果this的知识点,您还不太懂,请戳: 嗨,你真的懂this吗?
12. 词法作用域和this的区别。
13. 谈谈你对JS执行上下文栈和作用域链的理解。
执行上下文就是当前 JavaScript 代码被解析和执行时所在环境, JS执行上下文栈可以认为是一个存储函数调用的栈结构,遵循先进后出的原则。
作用域链: 无论是 LHS 还是 RHS 查询,都会在当前的作用域开始查找,如果没有找到,就会向上级作用域继续查找目标标识符,每次上升一个作用域,一直到全局作用域为止。
题难不难?不难!继续挑战一下难!知道难,就更要继续了!
闭包是指有权访问另一个函数作用域中的变量的函数,创建闭包最常用的方式就是在一个函数内部创建另一个函数。
闭包的作用有:
15. call、apply有什么区别?call,aplly和bind的内部是如何实现的?
call 和 apply 的功能相同,区别在于传参的方式不一样:
fn.call(obj, arg1, arg2, ...),调用一个函数, 具有一个指定的this值和分别地提供的参数(参数的列表)。
fn.apply(obj, [argsArray]),调用一个函数,具有一个指定的this值,以及作为一个数组(或类数组对象)提供的参数。
call核心:
Function.prototype.call = function (context) {
/** 如果第一个参数传入的是 null 或者是 undefined, 那么指向this指向 window/global */
/** 如果第一个参数传入的不是null或者是undefined, 那么必须是一个对象 */
if (!context) {
//context为null或者是undefined
context = typeof window === 'undefined' ? global : window;
}
context.fn = this; //this指向的是当前的函数(Function的实例)
let args = [...arguments].slice(1);//获取除了this指向对象以外的参数, 空数组slice后返回的仍然是空数组
let result = context.fn(...args); //隐式绑定,当前函数的this指向了context.
delete context.fn;
return result;
}
//测试代码
var foo = {
name: 'Selina'
}
var name = 'Chirs';
function bar(job, age) {
console.log(this.name);
console.log(job, age);
}
bar.call(foo, 'programmer', 20);
// Selina programmer 20
bar.call(null, 'teacher', 25);
// 浏览器环境: Chirs teacher 25; node 环境: undefined teacher 25apply:
apply的实现和call很类似,但是需要注意他们的参数是不一样的,apply的第二个参数是数组或类数组.
Function.prototype.apply = function (context, rest) {
if (!context) {
//context为null或者是undefined时,设置默认值
context = typeof window === 'undefined' ? global : window;
}
context.fn = this;
let result;
if(rest === undefined || rest === null) {
//undefined 或者 是 null 不是 Iterator 对象,不能被 ...
result = context.fn(rest);
}else if(typeof rest === 'object') {
result = context.fn(...rest);
}
delete context.fn;
return result;
}
var foo = {
name: 'Selina'
}
var name = 'Chirs';
function bar(job, age) {
console.log(this.name);
console.log(job, age);
}
bar.apply(foo, ['programmer', 20]);
// Selina programmer 20
bar.apply(null, ['teacher', 25]);
// 浏览器环境: Chirs programmer 20; node 环境: undefined teacher 25bind
bind 和 call/apply 有一个很重要的区别,一个函数被 call/apply 的时候,会直接调用,但是 bind 会创建一个新函数。当这个新函数被调用时,bind() 的第一个参数将作为它运行时的 this,之后的一序列参数将会在传递的实参前传入作为它的参数。
Function.prototype.my_bind = function(context) {
if(typeof this !== "function"){
throw new TypeError("not a function");
}
let self = this;
let args = [...arguments].slice(1);
function Fn() {};
Fn.prototype = this.prototype;
let bound = function() {
let res = [...args, ...arguments]; //bind传递的参数和函数调用时传递的参数拼接
context = this instanceof Fn ? this : context || this;
return self.apply(context, res);
}
//原型链
bound.prototype = new Fn();
return bound;
}
var name = 'Jack';
function person(age, job, gender){
console.log(this.name , age, job, gender);
}
var Yve = {name : 'Yvette'};
let result = person.my_bind(Yve, 22, 'enginner')('female'); 16. new的原理是什么?通过new的方式创建对象和通过字面量创建有什么区别?
new:
function new(func) {
lat target = {};
target.__proto__ = func.prototype;
let res = func.call(target);
if (typeof(res) == "object" || typeof(res) == "function") {
return res;
}
return target;
}字面量创建对象,不会调用 Object构造函数, 简洁且性能更好;
new Object() 方式创建对象本质上是方法调用,涉及到在proto链中遍历该方法,当找到该方法后,又会生产方法调用必须的 堆栈信息,方法调用结束后,还要释放该堆栈,性能不如字面量的方式。
通过对象字面量定义对象时,不会调用Object构造函数。
17. 谈谈你对原型的理解?
在 JavaScript 中,每当定义一个对象(函数也是对象)时候,对象中都会包含一些预定义的属性。其中每个函数对象都有一个prototype 属性,这个属性指向函数的原型对象。使用原型对象的好处是所有对象实例共享它所包含的属性和方法。
18. 什么是原型链?【原型链解决的是什么问题?】
原型链解决的主要是继承问题。
每个对象拥有一个原型对象,通过 proto (读音: dunder proto) 指针指向其原型对象,并从中继承方法和属性,同时原型对象也可能拥有原型,这样一层一层,最终指向 null(Object.proptotype.__proto__ 指向的是null)。这种关系被称为原型链 (prototype chain),通过原型链一个对象可以拥有定义在其他对象中的属性和方法。
构造函数 Parent、Parent.prototype 和 实例 p 的关系如下:(p.__proto__ === Parent.prototype)
19. prototype 和
__proto__区别是什么?
prototype是构造函数的属性。
__proto__ 是每个实例都有的属性,可以访问 [[prototype]] 属性。
实例的__proto__ 与其构造函数的prototype指向的是同一个对象。
function Student(name) {
this.name = name;
}
Student.prototype.setAge = function(){
this.age=20;
}
let Jack = new Student('jack');
console.log(Jack.__proto__);
//console.log(Object.getPrototypeOf(Jack));;
console.log(Student.prototype);
console.log(Jack.__proto__ === Student.prototype);//true20. 使用ES5实现一个继承?
组合继承(最常用的继承方式)
function SuperType() {
this.name = name;
this.colors = ['red', 'blue', 'green'];
}
SuperType.prototype.sayName = function() {
console.log(this.name);
}
function SubType(name, age) {
SuperType.call(this, name);
this.age = age;
}
SubType.prototype = new SuperType();
SubType.prototype.constructor = SubType;
SubType.prototype.sayAge = function() {
console.log(this.age);
}其它继承方式实现,可以参考《JavaScript高级程序设计》
21. 什么是深拷贝?深拷贝和浅拷贝有什么区别?
浅拷贝是指只复制第一层对象,但是当对象的属性是引用类型时,实质复制的是其引用,当引用指向的值改变时也会跟着变化。
深拷贝复制变量值,对于非基本类型的变量,则递归至基本类型变量后,再复制。深拷贝后的对象与原来的对象是完全隔离的,互不影响,对一个对象的修改并不会影响另一个对象。
实现一个深拷贝:
function deepClone(obj) { //递归拷贝
if(obj === null) return null; //null 的情况
if(obj instanceof RegExp) return new RegExp(obj);
if(obj instanceof Date) return new Date(obj);
if(typeof obj !== 'object') {
//如果不是复杂数据类型,直接返回
return obj;
}
/**
* 如果obj是数组,那么 obj.constructor 是 [Function: Array]
* 如果obj是对象,那么 obj.constructor 是 [Function: Object]
*/
let t = new obj.constructor();
for(let key in obj) {
//如果 obj[key] 是复杂数据类型,递归
t[key] = deepClone(obj[key]);
}
return t;
}看不下去了?别人的送分题会成为你的送命题
防抖和节流的作用都是防止函数多次调用。区别在于,假设一个用户一直触发这个函数,且每次触发函数的间隔小于设置的时间,防抖的情况下只会调用一次,而节流的情况会每隔一定时间调用一次函数。
防抖(debounce): n秒内函数只会执行一次,如果n秒内高频事件再次被触发,则重新计算时间
function debounce(func, wait, immediate=true) {
let timeout, context, args;
// 延迟执行函数
const later = () => setTimeout(() => {
// 延迟函数执行完毕,清空定时器
timeout = null
// 延迟执行的情况下,函数会在延迟函数中执行
// 使用到之前缓存的参数和上下文
if (!immediate) {
func.apply(context, args);
context = args = null;
}
}, wait);
let debounced = function (...params) {
if (!timeout) {
timeout = later();
if (immediate) {
//立即执行
func.apply(this, params);
} else {
//闭包
context = this;
args = params;
}
} else {
clearTimeout(timeout);
timeout = later();
}
}
debounced.cancel = function () {
clearTimeout(timeout);
timeout = null;
};
return debounced;
};防抖的应用场景:
节流(throttle): 高频事件在规定时间内只会执行一次,执行一次后,只有大于设定的执行周期后才会执行第二次。
//underscore.js
function throttle(func, wait, options) {
var timeout, context, args, result;
var previous = 0;
if (!options) options = {};
var later = function () {
previous = options.leading === false ? 0 : Date.now() || new Date().getTime();
timeout = null;
result = func.apply(context, args);
if (!timeout) context = args = null;
};
var throttled = function () {
var now = Date.now() || new Date().getTime();
if (!previous && options.leading === false) previous = now;
var remaining = wait - (now - previous);
context = this;
args = arguments;
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
result = func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
// 判断是否设置了定时器和 trailing
timeout = setTimeout(later, remaining);
}
return result;
};
throttled.cancel = function () {
clearTimeout(timeout);
previous = 0;
timeout = context = args = null;
};
return throttled;
};函数节流的应用场景有:
23. 取数组的最大值(ES5、ES6)
// ES5 的写法
Math.max.apply(null, [14, 3, 77, 30]);
// ES6 的写法
Math.max(...[14, 3, 77, 30]);
// reduce
[14,3,77,30].reduce((accumulator, currentValue)=>{
return accumulator = accumulator > currentValue ? accumulator : currentValue
});24. ES6新的特性有哪些?
25. setTimeout倒计时为什么会出现误差?
setTimeout() 只是将事件插入了“任务队列”,必须等当前代码(执行栈)执行完,主线程才会去执行它指定的回调函数。要是当前代码消耗时间很长,也有可能要等很久,所以并没办法保证回调函数一定会在 setTimeout() 指定的时间执行。所以, setTimeout() 的第二个参数表示的是最少时间,并非是确切时间。
HTML5标准规定了 setTimeout() 的第二个参数的最小值不得小于4毫秒,如果低于这个值,则默认是4毫秒。在此之前。老版本的浏览器都将最短时间设为10毫秒。另外,对于那些DOM的变动(尤其是涉及页面重新渲染的部分),通常是间隔16毫秒执行。这时使用 requestAnimationFrame() 的效果要好于 setTimeout();
26. 为什么 0.1 + 0.2 != 0.3 ?
0.1 + 0.2 != 0.3 是因为在进制转换和进阶运算的过程中出现精度损失。
下面是详细解释:
JavaScript使用 Number 类型表示数字(整数和浮点数),使用64位表示一个数字。
图片说明:
计算机无法直接对十进制的数字进行运算, 需要先对照 IEEE 754 规范转换成二进制,然后对阶运算。
1.进制转换
0.1和0.2转换成二进制后会无限循环
0.1 -> 0.0001100110011001...(无限循环)
0.2 -> 0.0011001100110011...(无限循环)
但是由于IEEE 754尾数位数限制,需要将后面多余的位截掉,这样在进制之间的转换中精度已经损失。
2.对阶运算
由于指数位数不相同,运算时需要对阶运算 这部分也可能产生精度损失。
按照上面两步运算(包括两步的精度损失),最后的结果是
0.0100110011001100110011001100110011001100110011001100
结果转换成十进制之后就是 0.30000000000000004。
27. promise 有几种状态, Promise 有什么优缺点 ?
promise有三种状态: fulfilled, rejected, pending.
Promise 的优点:
Promise 的缺点:
28. Promise构造函数是同步还是异步执行,then中的方法呢 ?promise如何实现then处理 ?
Promise的构造函数是同步执行的。then中的方法是异步执行的。
promise的then实现,详见: Promise源码实现
29. Promise和setTimeout的区别 ?
Promise 是微任务,setTimeout 是宏任务,同一个事件循环中,promise总是先于 setTimeout 执行。
30. 如何实现 Promise.all ?
要实现 Promise.all,首先我们需要知道 Promise.all 的功能:
Promise.all = function (promises) {
return new Promise((resolve, reject) => {
let index = 0;
let result = [];
if (promises.length === 0) {
resolve(result);
} else {
setTimeout(() => {
function processValue(i, data) {
result[i] = data;
if (++index === promises.length) {
resolve(result);
}
}
for (let i = 0; i < promises.length; i++) {
//promises[i] 可能是普通值
Promise.resolve(promises[i]).then((data) => {
processValue(i, data);
}, (err) => {
reject(err);
return;
});
}
})
}
});
}如果想了解更多Promise的源码实现,可以参考我的另一篇文章:Promise的源码实现(完美符合Promise/A+规范)
31.如何实现 Promise.finally ?
不管成功还是失败,都会走到finally中,并且finally之后,还可以继续then。并且会将值原封不动的传递给后面的then.
Promise.prototype.finally = function (callback) {
return this.then((value) => {
return Promise.resolve(callback()).then(() => {
return value;
});
}, (err) => {
return Promise.resolve(callback()).then(() => {
throw err;
});
});
}32. 什么是函数柯里化?实现 sum(1)(2)(3) 返回结果是1,2,3之和
函数柯里化是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
function sum(a) {
return function(b) {
return function(c) {
return a+b+c;
}
}
}
console.log(sum(1)(2)(3)); // 6引申:实现一个curry函数,将普通函数进行柯里化:
function curry(fn, args = []) {
return function(){
let rest = [...args, ...arguments];
if (rest.length < fn.length) {
return curry.call(this,fn,rest);
}else{
return fn.apply(this,rest);
}
}
}
//test
function sum(a,b,c) {
return a+b+c;
}
let sumFn = curry(sum);
console.log(sumFn(1)(2)(3)); //6
console.log(sumFn(1)(2, 3)); //6如果您在面试中遇到了更多的原生JS问题,或者有一些本文未涉及到且有一定难度的JS知识,请给我留言。您的问题将会出现在后续文章中~
本文的写成耗费了非常多的时间,在这个过程中,我也学习到了很多知识,谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。https://github.com/YvetteLau/Blog
后续写作计划
1.《寒冬求职季之你必须要懂的原生JS》(中)(下)
2.《寒冬求职季之你必须要知道的CSS》
3.《寒冬求职季之你必须要懂的前端安全》
4.《寒冬求职季之你必须要懂的一些浏览器知识》
5.《寒冬求职季之你必须要知道的性能优化》
针对React技术栈:
1.《寒冬求职季之你必须要懂的React》系列
2.《寒冬求职季之你必须要懂的ReactNative》系列
欢迎关注小姐姐的微信公众号,加入技术交流群。
参考文章:
0.1 + 0.2 !== 0.3 此题答案大量使用了此篇文章的图文: https://juejin.im/post/5b90e00e6fb9a05cf9080dffvue-cli, create-react-app、react-native-cli 等都是非常优秀的脚手架,通过脚手架,我们可以快速初始化一个项目,无需自己从零开始一步步配置,有效提升开发体验。尽管这些脚手架非常优秀,但是未必是符合我们的实际应用的,我们可以定制一个属于自己的脚手架(或公司通用脚手架),来提升自己的开发效率。
脚手架的作用
在开始之前,我们需要明确自己的脚手架需要哪些功能。vue init template-name project-name 、create-react-app project-name。我们这次编写的脚手架(eos-cli)具备以下能力(脚手架的名字爱叫啥叫啥,我选用了Eos黎明女神):
eos init template-name project-name 根据远程模板,初始化一个项目(远程模板可配置)eos config set <key> <value> 修改配置信息eos config get [<key>] 查看配置信息eos --version 查看当前版本号eos -h大家可以自行扩展其它的 commander,本篇文章旨在教大家如何实现一个脚手架。
本项目完整代码请戳(建议先clone代码): https://github.com/YvetteLau/Blog/tree/master/eos-cli
效果展示
初始化一个项目
修改.eosrc文件,从 vuejs-template 下载模板
关于这些第三方库的说明,可以直接npm上查看相应的说明,此处不一一展开。
创建一个空项目(eos-cli),使用 npm init 进行初始化。
npm install babel-cli babel-env chalk commander download-git-repo ini inquirer log-symbols ora├── bin
│ └── www //可执行文件
├── dist
├── ... //生成文件
└── src
├── config.js //管理eos配置文件
├── index.js //主流程入口文件
├── init.js //init command
├── main.js //入口文件
└── utils
├── constants.js //定义常量
├── get.js //获取模板
└── rc.js //配置文件
├── .babelrc //babel配置文件
├── package.json
├── README.md开发使用了ES6语法,使用 babel 进行转义,
.bablerc
{
"presets": [
[
"env",
{
"targets": {
"node": "current"
}
}
]
]
}eos 命令node.js 内置了对命令行操作的支持,package.json 中的 bin 字段可以定义命令名和关联的执行文件。在 package.json 中添加 bin 字段
package.json
{
"name": "eos-cli",
"version": "1.0.0",
"description": "脚手架",
"main": "index.js",
"bin": {
"eos": "./bin/www"
},
"scripts": {
"compile": "babel src -d dist",
"watch": "npm run compile -- --watch"
}
}www 文件
行首加入一行 #!/usr/bin/env node 指定当前脚本由node.js进行解析
#! /usr/bin/env node
require('../dist/main.js');开发过程中为了方便调试,在当前的 eos-cli 目录下执行 npm link,将 eos 命令链接到全局环境。
npm run watch利用 commander 来处理命令行。
main
import program from 'commander';
import { VERSION } from './utils/constants';
import apply from './index';
import chalk from 'chalk';
/**
* eos commands
* - config
* - init
*/
let actionMap = {
init: {
description: 'generate a new project from a template',
usages: [
'eos init templateName projectName'
]
},
config: {
alias: 'cfg',
description: 'config .eosrc',
usages: [
'eos config set <k> <v>',
'eos config get <k>',
'eos config remove <k>'
]
},
//other commands
}
// 添加 init / config 命令
Object.keys(actionMap).forEach((action) => {
program.command(action)
.description(actionMap[action].description)
.alias(actionMap[action].alias) //别名
.action(() => {
switch (action) {
case 'config':
//配置
apply(action, ...process.argv.slice(3));
break;
case 'init':
apply(action, ...process.argv.slice(3));
break;
default:
break;
}
});
});
function help() {
console.log('\r\nUsage:');
Object.keys(actionMap).forEach((action) => {
actionMap[action].usages.forEach(usage => {
console.log(' - ' + usage);
});
});
console.log('\r');
}
program.usage('<command> [options]');
// eos -h
program.on('-h', help);
program.on('--help', help);
// eos -V VERSION 为 package.json 中的版本号
program.version(VERSION, '-V --version').parse(process.argv);
// eos 不带参数时
if (!process.argv.slice(2).length) {
program.outputHelp(make_green);
}
function make_green(txt) {
return chalk.green(txt);
}download-git-repo 支持从 Github、Gitlab 下载远程仓库到本地。
get.js
import { getAll } from './rc';
import downloadGit from 'download-git-repo';
export const downloadLocal = async (templateName, projectName) => {
let config = await getAll();
let api = `${config.registry}/${templateName}`;
return new Promise((resolve, reject) => {
//projectName 为下载到的本地目录
downloadGit(api, projectName, (err) => {
if (err) {
reject(err);
}
resolve();
});
});
}init 命令在用户执行 init 命令后,向用户提出问题,接收用户的输入并作出相应的处理。命令行交互利用 inquirer 来实现:
inquirer.prompt([
{
name: 'description',
message: 'Please enter the project description: '
},
{
name: 'author',
message: 'Please enter the author name: '
}
]).then((answer) => {
//...
});在用户输入之后,开始下载模板,这时候使用 ora 来提示用户正在下载模板,下载结束之后,也给出提示。
import ora from 'ora';
let loading = ora('downloading template ...');
loading.start();
//download
loading.succeed(); //或 loading.fail();init.js
import { downloadLocal } from './utils/get';
import ora from 'ora';
import inquirer from 'inquirer';
import fs from 'fs';
import chalk from 'chalk';
import symbol from 'log-symbols';
let init = async (templateName, projectName) => {
//项目不存在
if (!fs.existsSync(projectName)) {
//命令行交互
inquirer.prompt([
{
name: 'description',
message: 'Please enter the project description: '
},
{
name: 'author',
message: 'Please enter the author name: '
}
]).then(async (answer) => {
//下载模板 选择模板
//通过配置文件,获取模板信息
let loading = ora('downloading template ...');
loading.start();
downloadLocal(templateName, projectName).then(() => {
loading.succeed();
const fileName = `${projectName}/package.json`;
if(fs.existsSync(fileName)){
const data = fs.readFileSync(fileName).toString();
let json = JSON.parse(data);
json.name = projectName;
json.author = answer.author;
json.description = answer.description;
//修改项目文件夹中 package.json 文件
fs.writeFileSync(fileName, JSON.stringify(json, null, '\t'), 'utf-8');
console.log(symbol.success, chalk.green('Project initialization finished!'));
}
}, () => {
loading.fail();
});
});
}else {
//项目已经存在
console.log(symbol.error, chalk.red('The project already exists'));
}
}
module.exports = init;config 配置eos config set registry vuejs-templatesconfig 配置,支持我们使用其它仓库的模板,例如,我们可以使用 vuejs-templates 中的仓库作为模板。这样有一个好处:更新模板无需重新发布脚手架,使用者无需重新安装,并且可以自由选择下载目标。
config.js
// 管理 .eosrc 文件 (当前用户目录下)
import { get, set, getAll, remove } from './utils/rc';
let config = async (action, key, value) => {
switch (action) {
case 'get':
if (key) {
let result = await get(key);
console.log(result);
} else {
let obj = await getAll();
Object.keys(obj).forEach(key => {
console.log(`${key}=${obj[key]}`);
})
}
break;
case 'set':
set(key, value);
break;
case 'remove':
remove(key);
break;
default:
break;
}
}
module.exports = config;rc.js
.eosrc 文件的增删改查
import { RC, DEFAULTS } from './constants';
import { decode, encode } from 'ini';
import { promisify } from 'util';
import chalk from 'chalk';
import fs from 'fs';
const exits = promisify(fs.exists);
const readFile = promisify(fs.readFile);
const writeFile = promisify(fs.writeFile);
//RC 是配置文件
//DEFAULTS 是默认的配置
export const get = async (key) => {
const exit = await exits(RC);
let opts;
if (exit) {
opts = await readFile(RC, 'utf8');
opts = decode(opts);
return opts[key];
}
return '';
}
export const getAll = async () => {
const exit = await exits(RC);
let opts;
if (exit) {
opts = await readFile(RC, 'utf8');
opts = decode(opts);
return opts;
}
return {};
}
export const set = async (key, value) => {
const exit = await exits(RC);
let opts;
if (exit) {
opts = await readFile(RC, 'utf8');
opts = decode(opts);
if(!key) {
console.log(chalk.red(chalk.bold('Error:')), chalk.red('key is required'));
return;
}
if(!value) {
console.log(chalk.red(chalk.bold('Error:')), chalk.red('value is required'));
return;
}
Object.assign(opts, { [key]: value });
} else {
opts = Object.assign(DEFAULTS, { [key]: value });
}
await writeFile(RC, encode(opts), 'utf8');
}
export const remove = async (key) => {
const exit = await exits(RC);
let opts;
if (exit) {
opts = await readFile(RC, 'utf8');
opts = decode(opts);
delete opts[key];
await writeFile(RC, encode(opts), 'utf8');
}
}npm publish 将本脚手架发布至npm上。其它用户可以通过 npm install eos-cli -g 全局安装。
即可使用 eos 命令。
本项目完整代码请戳: https://github.com/YvetteLau/Blog/tree/master/eos-cli
编写本文,虽然花费了一定时间,但是在这个过程中,我也学习到了很多知识,谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。
https://github.com/YvetteLau/Blog
[1] 珠峰架构课(墙裂推荐)
[2] npm依赖文档(https://www.npmjs.com/package/download-git-repo)
关注公众号,加入技术交流群。
基本每个开发者都需要考虑逻辑复用的问题,否则你的项目中将充斥着大量的重复代码。那么 React 是怎么复用组件逻辑的呢?本文将一一介绍 React 复用组件逻辑的几种方法,希望你读完之后能够有所收获。如果你对这些内容已经非常清楚,那么略过本文即可。
我已尽量对文中的代码和内容进行了校验,但是因为自身知识水平限制,难免有错误,欢迎在评论区指正。
Mixins 事实上是 React.createClass 的产物了。当然,如果你曾经在低版本的 react 中使用过 Mixins,例如 react-timer-mixin, react-addons-pure-render-mixin,那么你可能知道,在 React 的新版本中我们其实还是可以使用 mixin,虽然 React.createClass 已经被移除了,但是仍然可以使用第三方库 create-react-class,来继续使用 mixin。甚至,ES6 写法的组件,也同样有方式去使用 mixin。当然啦,这不是本文讨论的重点,就不多做介绍了,如果你维护的老项目在升级的过程中遇到这类问题,可以与我探讨。
新的项目中基本不会出现 Mixins,但是如果你们公司还有一些老项目要维护,其中可能就应用了 Mixins,因此稍微花点时间,了解下 Mixins 的使用方法和原理,还是有必要的。倘若你完全没有这方面的需求,那么跳过本节亦是可以的。
React 15.3.0 版本中增加了 PureComponent。而在此之前,或者如果你使用的是 React.createClass 的方式创建组件,那么想要同样的功能,就是使用 react-addons-pure-render-mixin,例如:
//下面代码在新版React中可正常运行,因为现在已经无法使用 `React.createClass`,我就不使用 `React.createClass` 来写了。
const createReactClass = require('create-react-class');
const PureRenderMixin = require('react-addons-pure-render-mixin');
const MyDialog = createReactClass({
displayName: 'MyDialog',
mixins: [PureRenderMixin],
//other code
render() {
return (
<div>
{/* other code */}
</div>
)
}
});首先,需要注意,mixins 的值是一个数组,如果有多个 Mixins,那么只需要依次放在数组中即可,例如: mixins: [PureRenderMixin, TimerMixin]。
Mixins 的原理可以简单理解为将一个 mixin 对象上的方法增加到组件上。类似于 $.extend 方法,不过 React 还进行了一些其它的处理,例如:除了生命周期函数外,不同的 mixins 中是不允许有相同的属性的,并且也不能和组件中的属性和方法同名,否则会抛出异常。另外即使是生命周期函数,constructor 、render 和 shouldComponentUpdate 也是不允许重复的。
而如 compoentDidMount 的生命周期,会依次调用 Mixins,然后再调用组件中定义的 compoentDidMount。
例如,上面的 PureRenderMixin 提供的对象中,有一个 shouldComponentUpdate 方法,即是将这个方法增加到了 MyDialog 上,此时 MyDialog 中不能再定义 shouldComponentUpdate,否则会抛出异常。
//react-addons-pure-render-mixin 源码
var shallowEqual = require('fbjs/lib/shallowEqual');
module.exports = {
shouldComponentUpdate: function(nextProps, nextState) {
return (
!shallowEqual(this.props, nextProps) ||
!shallowEqual(this.state, nextState)
);
},
};Mixins 引入了隐式的依赖关系。
例如,每个 mixin 依赖于其他的 mixin,那么修改其中一个就可能破坏另一个。
Mixins 会导致名称冲突
如果两个 mixin 中存在同名方法,就会抛出异常。另外,假设你引入了一个第三方的 mixin,该 mixin 上的方法和你组件的方法名发生冲突,你就不得不对方法进行重命名。
Mixins 会导致越来越复杂
mixin 开始的时候是简单的,但是随着时间的推移,容易变得越来越复杂。例如,一个组件需要一些状态来跟踪鼠标悬停,为了保持逻辑的可重用性,将 handleMouseEnter()、handleMouseLeave() 和 isHovering() 提取到 HoverMixin() 中。
然后其他人可能需要实现一个提示框,他们不想复制 HoverMixin() 的逻辑,于是他们创建了一个使用 HoverMixin 的 TooltipMixin,TooltipMixin 在它的 componentDidUpdate 中读取 HoverMixin() 提供的 isHovering() 来决定显示或隐藏提示框。
几个月之后,有人想将提示框的方向设置为可配置的。为了避免代码重复,他们将 getTooltipOptions() 方法增加到了 TooltipMixin 中。结果过了段时间,你需要再同一个组件中显示多个提示框,提示框不再是悬停时显示了,或者一些其他的功能,你需要解耦 HoverMixin() 和 TooltipMixin 。另外,如果很多组件使用了某个 mixin,mixin 中新增的功能都会被添加到所有组件中,事实上很多组件完全不需要这些新功能。
渐渐地,封装的边界被侵蚀了,由于很难更改或移除现有的mixin,它们变得越来越抽象,直到没有人理解它们是如何工作的。
React 官方认为在 React 代码库中,Mixin 是不必要的,也是有问题的。推荐开发者使用高阶组件来进行组件逻辑的复用。
React 官方文档对 HOC 进行了如下的定义:高阶组件(HOC)是 React 中用于复用组件逻辑的一种高级技巧。HOC 自身不是 React API 的一部分,它是一种基于 React 的组合特性而形成的设计模式。
简而言之,高阶组件就是一个函数,它接受一个组件为参数,返回一个新组件。
高阶组件的定义形如下面这样:
//接受一个组件 WrappedComponent 作为参数,返回一个新组件 Proxy
function withXXX(WrappedComponent) {
return class Proxy extends React.Component {
render() {
return <WrappedComponent {...this.props}>
}
}
}开发项目时,当你发现不同的组件有相似的逻辑,或者发现自己在写重复代码的时候,这时候就需要考虑组件复用的问题了。
这里我以一个实际开发的例子来说明,近期各大APP都在适配暗黑模式,而暗黑模式下的背景色、字体颜色等等和正常模式肯定是不一样的。那么就需要监听暗黑模式开启关闭事件,每个UI组件都需要根据当前的模式来设置样式。
每个组件都去监听事件变化来 setState 肯定是不可能的,因为会造成多次渲染。
这里我们需要借助 context API 来做,我以新的 Context API 为例。如果使用老的 context API 实现该功能,需要使用发布订阅模式来做,最后利用 react-native / react-dom 提供的 unstable_batchedUpdates 来统一更新,避免多次渲染的问题(老的 context API 在值发生变化时,如果组件中 shouldComponentUpdate 返回了 false,那么它的子孙组件就不会重新渲染了)。
顺便多说一句,很多新的API出来的时候,不要急着在项目中使用,比如新的 Context API,如果你的 react 版本是 16.3.1, react-dom 版本是16.3.3,你会发现,当你的子组件是函数组件时,即使用 Context.Consumer 的形式时,你是能获取到 context 上的值,而你的组件是个类组件时,你根本拿不到 context 上的值。
同样的 React.forwardRef 在该版本食用时,某种情况下也有多次渲染的bug。都是血和泪的教训,不多说了,继续暗黑模式这个需求。
我的想法是将当前的模式(假设值为 light / dark)挂载到 context 上。其它组件直接从 context 上获取即可。不过我们知道的是,新版的 ContextAPI 函数组件和类组件,获取 context 的方法是不一致的。而且一个项目中有非常多的组件,每个组件都进行一次这样的操作,也是重复的工作量。于是,高阶组件就派上用场啦(PS:React16.8 版本中提供了 useContext 的 Hook,用起来很方便)
当然,这里我使用高阶组件还有一个原因,就是我们的项目中还包含老的 context API (不要问我为什么不直接重构下,牵扯的人员太多了,没法随便改),新老 context API 在一个项目中是可以共存的,不过我们不能在同一个组件中同时使用。所以如果一个组件中已经使用的旧的 context API,要想从新的 context API 上获取值,也需要使用高阶组件来处理它。
于是,我编写了一个 withColorTheme 的高阶组件的雏形(这里也可以认为 withColorTheme 是一个返回高阶组件的高阶函数):
import ThemeContext from './context';
function withColorTheme(options={}) {
return function(WrappedComponent) {
return class ProxyComponent extends React.Component {
static contextType = ThemeContext;
render() {
return (<WrappedComponent {...this.props} colortheme={this.context}/>)
}
}
}
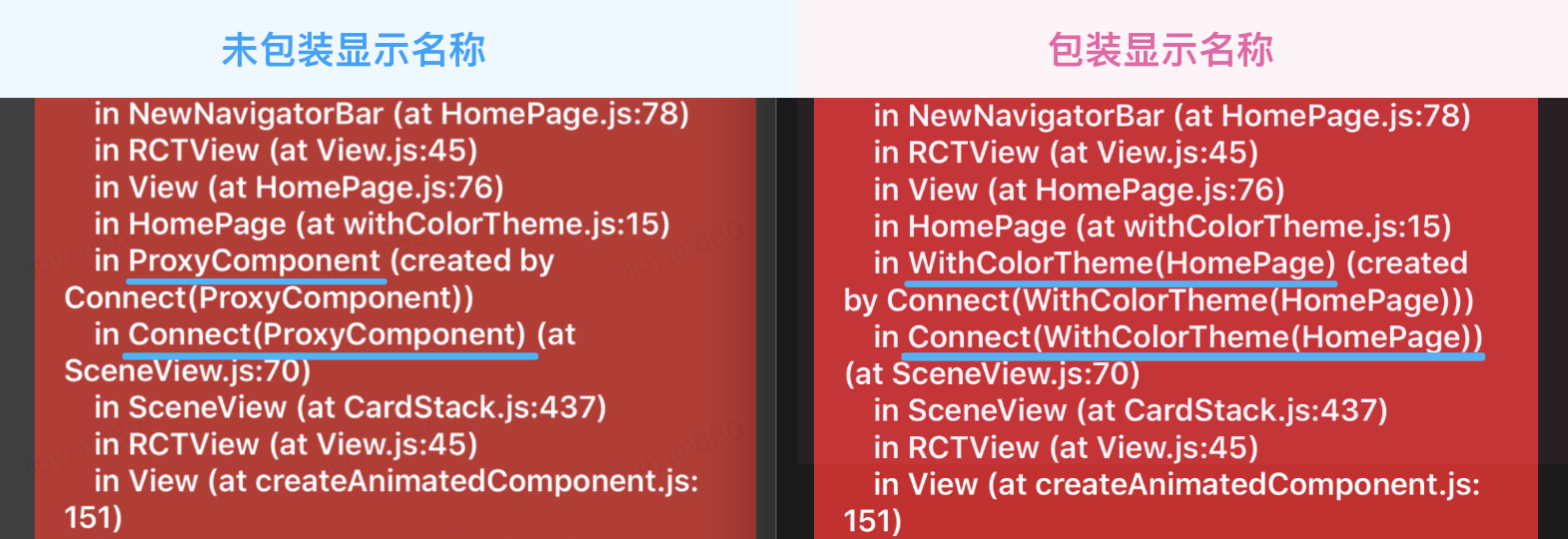
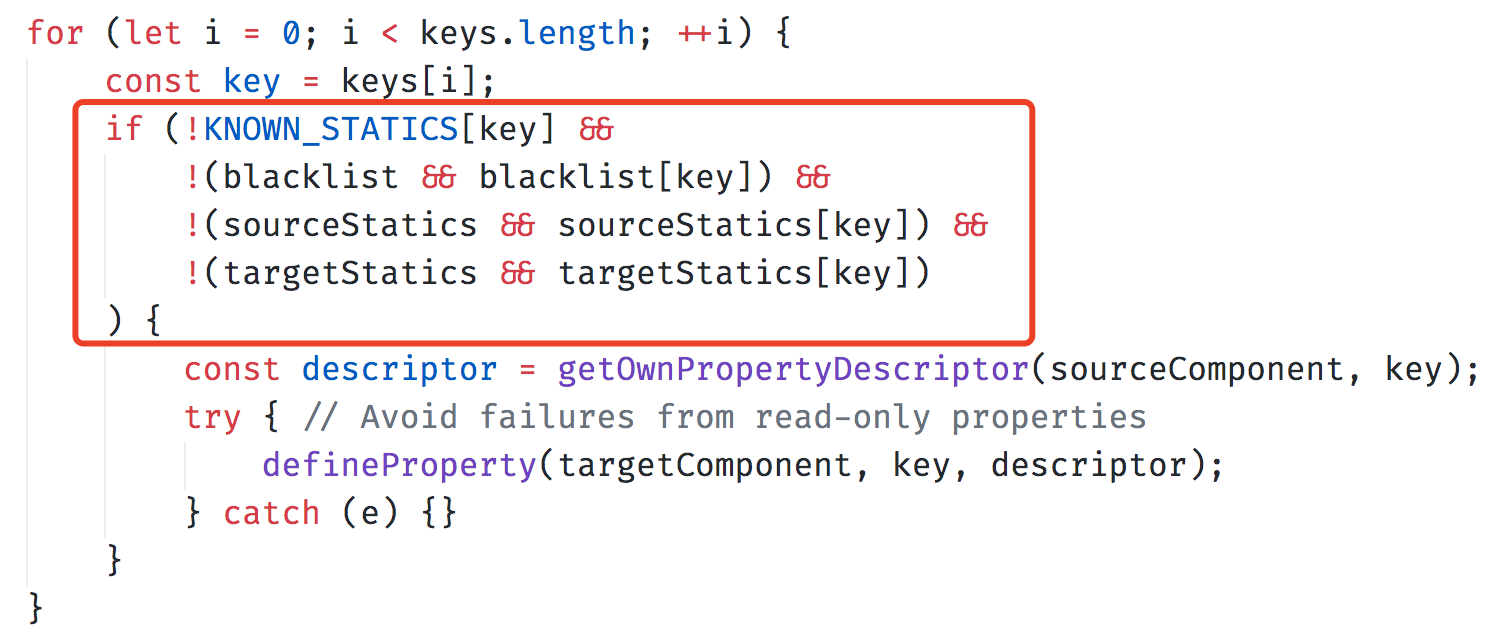
}上面这个雏形存在几个问题,首先,我们没有为 ProxyComponent 包装显示名称,因此,为其加上:
import ThemeContext from './context';
function withColorTheme(options={}) {
function(WrappedComponent) {
class ProxyComponent extends React.Component {
static contextType = ThemeContext;
render() {
return (<WrappedComponent {...this.props} colortheme={this.context}/>)
}
}
}
function getDisplayName(WrappedComponent) {
return WrappedComponent.displayName || WrappedComponent.name || 'Component';
}
const displayName = `WithColorTheme(${getDisplayName(WrappedComponent)})`;
ProxyComponent.displayName = displayName;
return ProxyComponent;
}我们来看一下,不包装显示名称和包装显示名称的区别:
React Developer Tools 中调试
ReactNative的红屏报错
众所周知,使用 HOC 包装组件,需要复制静态方法,如果你的 HOC 仅仅是某几个组件使用,没有静态方法需要拷贝,或者需要拷贝的静态方法是确定的,那么你手动处理一下也可以。
因为 withColorTheme 这个高阶组件,最终是要提供给很多业务使用的,无法限制别人的组件写法,因此这里我们必须将其写得通用一些。
hoist-non-react-statics 这个依赖可以帮助我们自动拷贝非 React 的静态方法,这里有一点需要注意,它只会帮助你拷贝非 React 的静态方法,而非被包装组件的所有静态方法。我第一次使用这个依赖的时候,没有仔细看,以为是将 WrappedComponent 上所有的静态方法都拷贝到 ProxyComponent。然后就遇到了 XXX.propsTypes.style undefined is not an object 的红屏报错(ReactNative调试)。因为我没有手动拷贝 propTypes,错误的以为 hoist-non-react-statics 会帮我处理了。
hoist-non-react-statics 的源码非常短,有兴趣的话,可以看一下,我当前使用的 3.3.2 版本。
因此,诸如 childContextTypes、contextType、contextTypes、defaultProps、displayName、getDefaultProps、getDerivedStateFromError、getDerivedStateFromProps
mixins、propTypes、type 等不会被拷贝,其实也比较容易理解,因为 ProxyComponent 中可能也需要设置这些,不能简单去覆盖。
import ThemeContext from './context';
import hoistNonReactStatics from 'hoist-non-react-statics';
function withColorTheme(options={}) {
function(WrappedComponent) {
class ProxyComponent extends React.Component {
static contextType = ThemeContext;
render() {
return (<WrappedComponent {...this.props} colortheme={this.context}/>)
}
}
}
function getDisplayName(WrappedComponent) {
return WrappedComponent.displayName || WrappedComponent.name || 'Component';
}
const displayName = `WithColorTheme(${getDisplayName(WrappedComponent)})`;
ProxyComponent.displayName = displayName;
ProxyComponent.WrappedComponent = WrappedComponent;
ProxyComponent.propTypes = WrappedComponent.propTypes;
//contextType contextTypes 和 childContextTypes 因为我这里不需要,就不拷贝了
return ProxyComponent;
}现在似乎差不多了,不过呢,HOC 还有一个问题,就是 ref 传递的问题。如果不经过任何处理,我们通过 ref 拿到的是 ProxyComponent 的实例,而不是原本想要获取的 WrappedComponent 的实例。
虽然我们已经用无关的 props 进行了透传,但是 key 和 ref 不是普通的 prop,React 会对它进行特别处理。
所以这里我们需要对 ref 特别处理一下。如果你的 reac-dom 是 16.4.2 或者你的 react-native 版本是 0.59.9 以上,那么可以放心的使用 React.forwardRef 进行 ref 转发,这样使用起来也是最方便的。
使用 React.forwardRef 转发
import ThemeContext from './context';
import hoistNonReactStatics from 'hoist-non-react-statics';
function withColorTheme(options={}) {
function(WrappedComponent) {
class ProxyComponent extends React.Component {
static contextType = ThemeContext;
render() {
const { forwardRef, ...wrapperProps } = this.props;
return <WrappedComponent {...wrapperProps} ref={forwardRef} colorTheme={ this.context } />
}
}
}
function getDisplayName(WrappedComponent) {
return WrappedComponent.displayName || WrappedComponent.name || 'Component';
}
const displayName = `WithColorTheme(${getDisplayName(WrappedComponent)})`;
ProxyComponent.displayName = displayName;
ProxyComponent.WrappedComponent = WrappedComponent;
ProxyComponent.propTypes = WrappedComponent.propTypes;
//contextType contextTypes 和 childContextTypes 因为我这里不需要,就不拷贝了
if (options.forwardRef) {
let forwarded = React.forwardRef((props, ref) => (
<ProxyComponent {...props} forwardRef={ref} />
));
forwarded.displayName = displayName;
forwarded.WrappedComponent = WrappedComponent;
forwarded.propTypes = WrappedComponent.propTypes;
return hoistNonReactStatics(forwarded, WrappedComponent);
} else {
return hoistNonReactStatics(ProxyComponent, WrappedComponent);
}
}假设,我们对 TextInput 进行了装饰,如 export default withColorTheme({forwardRef: true})(TextInput)。
使用: <TextInput ref={v => this.textInput = v}>
如果要获取 WrappedComponent 的实例,直接通过 this.textInput 即可,和未使用 withColorTheme 装饰前一样获取。
通过方法调用
getWrappedInstance
import ThemeContext from './context';
import hoistNonReactStatics from 'hoist-non-react-statics';
function withColorTheme(options={}) {
function(WrappedComponent) {
class ProxyComponent extends React.Component {
static contextType = ThemeContext;
getWrappedInstance = () => {
if (options.forwardRef) {
return this.wrappedInstance;
}
}
setWrappedInstance = (ref) => {
this.wrappedInstance = ref;
}
render() {
const { forwardRef, ...wrapperProps } = this.props;
let props = {
...this.props
};
if (options.forwardRef) {
props.ref = this.setWrappedInstance;
}
return <WrappedComponent {...props} colorTheme={ this.context } />
}
}
}
function getDisplayName(WrappedComponent) {
return WrappedComponent.displayName || WrappedComponent.name || 'Component';
}
const displayName = `WithColorTheme(${getDisplayName(WrappedComponent)})`;
ProxyComponent.displayName = displayName;
ProxyComponent.WrappedComponent = WrappedComponent;
ProxyComponent.propTypes = WrappedComponent.propTypes;
//contextType contextTypes 和 childContextTypes 因为我这里不需要,就不拷贝了
if (options.forwardRef) {
let forwarded = React.forwardRef((props, ref) => (
<ProxyComponent {...props} forwardRef={ref} />
));
forwarded.displayName = displayName;
forwarded.WrappedComponent = WrappedComponent;
forwarded.propTypes = WrappedComponent.propTypes;
return hoistNonReactStatics(forwarded, WrappedComponent);
} else {
return hoistNonReactStatics(ProxyComponent, WrappedComponent);
}
}同样的,我们对 TextInput 进行了装饰,如 export default withColorTheme({forwardRef: true})(TextInput)。
使用: <TextInput ref={v => this.textInput = v}>
如果要获取 WrappedComponent 的实例,那么需要通过 this.textInput.getWrappedInstance() 获取被包装组件 TextInput 的实例。
我先说一下,为什么我将它设计为下面这样:
function withColorTheme(options={}) {
function(WrappedComponent) {
}
}而不是像这样:
function withColorTheme(WrappedComponent, options={}) {
}主要是使用装饰器语法比较方便,而且很多业务中也使用了 react-redux:
@connect(mapStateToProps, mapDispatchToProps)
@withColorTheme()
export default class TextInput extends Component {
render() {}
}这样设计,可以不破坏原本的代码结构。否则的话,原本使用装饰器语法的业务改起来就有点麻烦。
回归到最大化可组合,看看官方文档怎么说:
像 connect(react-redux 提供) 函数返回的单参数 HOC 具有签名 Component => Component。输出类型与输入类型相同的函数很容易组合在一起。
// ... 你可以编写组合工具函数
// compose(f, g, h) 等同于 (...args) => f(g(h(...args)))
const enhance = compose(
// 这些都是单参数的 HOC
withRouter,
connect(commentSelector)
)
const EnhancedComponent = enhance(WrappedComponent)compose 的源码可以看下 redux 的实现,代码很短。
再复杂化一下就是:
withRouter(connect(commentSelector)(withColorTheme(options)(WrappedComponent)));我们的 enhance 可以编写为:
const enhance = compose(
withRouter,
connect(commentSelector),
withColorTheme(options)
)
const EnhancedComponent = enhance(WrappedComponent)如果我们是写成 XXX(WrappedComponent, options) 的形式的话,那么上面的代码将变成:
const EnhancedComponent = withRouter(connect(withColorTheme(WrappedComponent, options), commentSelector))试想一下,如果还有更多的 HOC 要使用,这个代码会变成什么样子?
约定
props 传递给被包裹的组件(HOC应透传与自身无关的 props)注意事项
render 方法中使用 HOCReact 的 diff 算法(称为协调)使用组件标识来确定它是应该更新现有子树还是将其丢弃并挂载新子树。 如果从 render 返回的组件与前一个渲染中的组件相同(===),则 React 通过将子树与新子树进行区分来递归更新子树。 如果它们不相等,则完全卸载前一个子树。
这不仅仅是性能问题 —— 重新挂载组件会导致该组件及其所有子组件的状态丢失。
如果在组件之外创建 HOC,这样一来组件只会创建一次。因此,每次 render 时都会是同一个组件。
Refs 不会被传递(需要额外处理)React 官方文档上有这样一段描述: HOC 不会修改传入的组件,也不会使用继承来复制其行为。相反,HOC 通过将组件包装在容器组件中来组成新组件。HOC 是纯函数,没有副作用。
因此呢,我觉得反向继承不是 React 推崇的方式,这里我们可以做一下了解,某些场景下也有可能会用到。
function withColor(WrappedComponent) {
class ProxyComponent extends WrappedComponent {
//注意 ProxyComponent 会覆盖 WrappedComponent 的同名函数,包括 state 和 props
render() {
//React.cloneElement(super.render(), { style: { color:'red' }})
return super.render();
}
}
return ProxyComponent;
}和上一节不同,反向继承不会增加组件的层级,并且也不会有静态属性拷贝和 refs 丢失的问题。可以利用它来做渲染劫持,不过我目前没有什么必须要使用反向继承的场景。
虽然它没有静态属性和 refs的问题,也不会增加层级,但是它也不是那么好用,会覆盖同名属性和方法这点就让人很无奈。另外虽然可以修改渲染结果,但是不好注入 props。
首先, render props 是指一种在 React 组件之间使用一个值为函数的 prop 共享代码的简单技术。
具有 render prop 的组件接受一个函数,该函数返回一个 React 元素并调用它而不是实现自己的渲染逻辑。
<Route
{...rest}
render={routeProps => (
<FadeIn>
<Component {...routeProps} />
</FadeIn>
)}
/>ReactNative 的开发者,其实 render props 的技术使用的很多,例如,FlatList 组件:
import React, {Component} from 'react';
import {
FlatList,
View,
Text,
TouchableHighlight
} from 'react-native';
class MyList extends Component {
data = [{ key: 1, title: 'Hello' }, { key: 2, title: 'World' }]
render() {
return (
<FlatList
style={{marginTop: 60}}
data={this.data}
renderItem={({ item, index }) => {
return (
<TouchableHighlight
onPress={() => { alert(item.title) }}
>
<Text>{item.title}</Text>
</TouchableHighlight>
)
}}
ListHeaderComponent={() => {
return (<Text>以下是一个List</Text>)
}}
ListFooterComponent={() => {
return <Text>没有更多数据</Text>
}}
/>
)
}
}例如: FlatList 的 renderItem、ListHeaderComponent 就是render prop。
注意,render prop 是因为模式才被称为 render prop ,你不一定要用名为 render 的 prop 来使用这种模式。render prop 是一个用于告知组件需要渲染什么内容的函数 prop。
其实,我们在封装组件的时候,也经常会应用到这个技术,例如我们封装一个轮播图组件,但是每个页面的样式是不一致的,我们可以提供一个基础样式,但是也要允许自定义,否则就没有通用价值了:
//提供一个 renderPage 的 prop
class Swiper extends React.PureComponent {
getPages() {
if(typeof renderPage === 'function') {
return this.props.renderPage(XX,XXX)
}
}
render() {
const pages = typeof renderPage === 'function' ? this.props.renderPage(XX,XXX) : XXXX;
return (
<View>
<Animated.View>
{pages}
</Animated.View>
</View>
)
}
}
Render Props和React.PureComponent一起使用时要小心
如果在 render 方法里创建函数,那么 render props,会抵消使用 React.PureComponent 带来的优势。因为浅比较 props 的时候总会得到 false,并且在这种情况下每一个 render 对于 render prop 将会生成一个新的值。
import React from 'react';
import { View } from 'react-native';
import Swiper from 'XXX';
class MySwiper extends React.Component {
render() {
return (
<Swiper
renderPage={(pageDate, pageIndex) => {
return (
<View></View>
)
}}
/>
)
}
}这里应该比较好理解,这样写,renderPage 每次都会生成一个新的值,很多 React 性能优化上也会提及到这一点。我们可以将 renderPage 的函数定义为实例方法,如下:
import React from 'react';
import { View } from 'react-native';
import Swiper from 'XXX';
class MySwiper extends React.Component {
renderPage(pageDate, pageIndex) {
return (
<View></View>
)
}
render() {
return (
<Swiper
renderPage={this.renderPage}
/>
)
}
}如果你无法静态定义 prop,则 <Swiper> 应该扩展 React.Component,因为也没有浅比较的必要了,就不要浪费时间去比较了。
Hook 是 React 16.8 的新增特性,它可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性。HOC 和 render props 虽然都可以
React 已经内置了一些 Hooks,如: useState、useEffect、useContext、useReducer、useCallback、useMemo、useRef 等 Hook,如果你还不清楚这些 Hook,那么可以优先阅读一下官方文档。
我们主要是将如何利用 Hooks 来进行组件逻辑复用。假设,我们有这样一个需求,在开发环境下,每次渲染时,打印出组件的 props。
import React, {useEffect} from 'react';
export default function useLogger(componentName,...params) {
useEffect(() => {
if(process.env.NODE_ENV === 'development') {
console.log(componentName, ...params);
}
});
}使用时:
import React, { useState } from 'react';
import useLogger from './useLogger';
export default function Counter(props) {
let [count, setCount] = useState(0);
useLogger('Counter', props);
return (
<div>
<button onClick={() => setCount(count + 1)}>+</button>
<p>{`${props.title}, ${count}`}</p>
</div>
)
}另外,官方文档自定义 Hook 章节也一步一步演示了如何利用 Hook 来进行逻辑复用。我因为版本限制,还没有在项目中应用 Hook ,虽然文档已经看过多次。读到这里,一般都会有一个疑问,那就是 Hook 是否会替代 render props 和 HOC,关于这一点,官方也给出了答案:
通常,render props 和高阶组件只渲染一个子节点。我们认为让 Hook 来服务这个使用场景更加简单。这两种模式仍有用武之地,例如,FlatList 组件的 renderItem 等属性,或者是 一个可见的容器组件或许会有它自己的 DOM 结构。但在大部分场景下,Hook 足够了,并且能够帮助减少嵌套。
HOC 最最最讨厌的一点就是层级嵌套了,如果项目是基于新版本进行开发,那么需要逻辑复用时,优先考虑 Hook,如果无法实现需求,那么再使用 render props 和 HOC 来解决。
不积跬步无以至千里。
Step-By-Step (点击进入项目) 是我于
2019-05-20开始的一个项目,每个工作日发布一道面试题。每个周末我会仔细阅读大家的答案,整理最一份较优答案出来,因本人水平有限,有误的地方,大家及时指正。
如果想 加群 学习,可以通过文末的公众号,添加我为好友。
本周面试题一览:
本周是继承专题,在开始之前,需要先了解构造函数、原型和原型链的相关知识。
构造函数和普通函数的区别仅在于调用它们的方式不同,任何函数,只要通过 new 操作符来调用,那它就可以作为构造函数;任何函数,如果不通过 new 操作符来调用,那么它就是一个普通函数。
实例拥有 constructor(构造函数) 属性,该属性返回创建实例对象的构造函数。
function Person(name, age) {
this.name = name;
this.age = age;
}
var Yvette = new Person('刘小夕', 20);
console.log(Yvette.constructor === Person); //true有一点需要说明的是,除了基本数据类型的 constructor 外( null 和 undefined 无 constructor 属性),constructor 属性是可以被重写的。因此检测对象类型时,instanceof 操作符比 contsrutor 更可靠一些。
function Person(name) {
this.name = name;
}
function SuperType() { }
var Yvette = new Person('刘小夕');
console.log(Yvette.constructor); //[Function: Person]
Yvette.constructor = SuperType;
console.log(Yvette.constructor); //[Function: SuperType]我们创建的每个函数都有 prototype 属性,这个属性指向函数的原型对象。原型对象的用途是包含可以由特定类型的所有实例共享的属性和方法。
在默认情况下,所有原型对象都会自动获得一个 constructor 属性,这个属性包含一个指向 prototype 属性所在函数的指针。
当调用构造函数创建一个新实例后,该实例的内部将包含一个指针,指向构造函数的原型对象(可以通过实例的 __proto__ 来访问构造函数的原型对象)。
function Person(name) {
this.name = name;
}
Person.prototype.sayName = function() {
console.log(this.name);
}
var person1 = new Person('刘小夕');
var person2 = new Person('前端小姐姐');
//构造函数原型对象上的方法和属性被实例共享
person1.sayName();
person1.sayName(); 实例.__proto__ === 构造函数.prototype
console.log(Object.prototype.__proto__ === null) //true
console.log(Object.__proto__ === Function.prototype) //true
console.log(Function.prototype.__proto__ === Object.prototype) //true简单回顾一下构造函数、原型和实例的关系:
每个构造函数都有一个原型对象,原型对象都包含一个指向构造函数的指针,而实例都包含一个可以执行原型对象的内部指针(可以通过 __proto 访问)。
假如我们让原型对象等于另一个类型的实例,那么此时原型对象包含一个指向另一个原型的指针,相应地,另一个原型中也包含着一个指向另一个构造函数的指针。加入另一个原型又是另一个类型的实例,那么上述关系仍然成立,如此层层递进,就构成了实例与原型的链条,这就是原型链的基本概念。
function SuperType() {
this.type = 'animal';
}
SuperType.prototype.getType = function() {
console.log(this.type);
}
function SubType() {
}
SubType.prototype = new SuperType();
SubType.prototype.sayHello = function() {
console.log('hello');
}
function SimType(name) {
this.name = name;
}
SimType.prototype = new SubType();
SimType.prototype.sayHi = function() {
console.log('hi');
}
var instance = new SimType('刘小夕');
instance.getType();一图胜万言:
调用 instance.getType() 会调用以下的搜索步骤:
instance 实例SimType.prototypeSubType.prototypeSuperType.prototype,找到了 getType 方法在找不到属性或方法的情况下,搜索过程总是要一环一环地前行到原型链的末端才会停下来。
所有引用类型都继承了 Object,这个继承也是通过原型链实现的。如果在 SuperType.prototype 还没有找到 getType,就会到 Object.prototype中找(图中少画了一环)。
原型链继承的基本**是利用原型让一个引用类型继承另一个引用类型的属性和方法。
如 SubType.prototype = new SuperType();
function SuperType() {
this.name = 'Yvette';
this.colors = ['pink', 'blue', 'green'];
}
SuperType.prototype.getName = function () {
return this.name;
}
function SubType() {
this.age = 22;
}
SubType.prototype = new SuperType();
SubType.prototype.getAge = function() {
return this.age;
}
SubType.prototype.constructor = SubType;
let instance1 = new SubType();
instance1.colors.push('yellow');
console.log(instance1.getName()); //'Yvette'
console.log(instance1.colors);//[ 'pink', 'blue', 'green', 'yellow' ]
let instance2 = new SubType();
console.log(instance2.colors);//[ 'pink', 'blue', 'green', 'yellow' ]可以看出 colors 属性会被所有的实例共享(instance1、instance2、...)。
缺点:
借用构造函数的技术,其基本**为:
在子类型的构造函数中调用超类型构造函数。
function SuperType(name) {
this.name = name;
this.colors = ['pink', 'blue', 'green'];
}
function SubType(name) {
SuperType.call(this, name);
}
let instance1 = new SubType('Yvette');
instance1.colors.push('yellow');
console.log(instance1.colors);//['pink', 'blue', 'green', yellow]
let instance2 = new SubType('Jack');
console.log(instance2.colors); //['pink', 'blue', 'green']优点:
缺点:
组合继承指的是将原型链和借用构造函数技术组合到一块,从而发挥二者之长的一种继承模式。基本思路:
使用原型链实现对原型属性和方法的继承,通过借用构造函数来实现对实例属性的继承,既通过在原型上定义方法来实现了函数复用,又保证了每个实例都有自己的属性。
function SuperType(name) {
this.name = name;
this.colors = ['pink', 'blue', 'green'];
}
SuperType.prototype.sayName = function () {
console.log(this.name);
}
function SuberType(name, age) {
SuperType.call(this, name);
this.age = age;
}
SuberType.prototype = new SuperType();
SuberType.prototype.constructor = SuberType;
SuberType.prototype.sayAge = function () {
console.log(this.age);
}
let instance1 = new SuberType('Yvette', 20);
instance1.colors.push('yellow');
console.log(instance1.colors); //[ 'pink', 'blue', 'green', 'yellow' ]
instance1.sayName(); //Yvette
let instance2 = new SuberType('Jack', 22);
console.log(instance2.colors); //[ 'pink', 'blue', 'green' ]
instance2.sayName();//Jack缺点:
优点:
原型继承的基本**:
借助原型可以基于已有的对象创建新对象,同时还不必因此创建自定义类型。
function object(o) {
function F() { }
F.prototype = o;
return new F();
}在 object() 函数内部,先穿甲一个临时性的构造函数,然后将传入的对象作为这个构造函数的原型,最后返回了这个临时类型的一个新实例,从本质上讲,object() 对传入的对象执行了一次浅拷贝。
ECMAScript5通过新增 Object.create()方法规范了原型式继承。这个方法接收两个参数:一个用作新对象原型的对象和(可选的)一个为新对象定义额外属性的对象(可以覆盖原型对象上的同名属性),在传入一个参数的情况下,Object.create() 和 object() 方法的行为相同。
var person = {
name: 'Yvette',
hobbies: ['reading', 'photography']
}
var person1 = Object.create(person);
person1.name = 'Jack';
person1.hobbies.push('coding');
var person2 = Object.create(person);
person2.name = 'Echo';
person2.hobbies.push('running');
console.log(person.hobbies);//[ 'reading', 'photography', 'coding', 'running' ]
console.log(person1.hobbies);//[ 'reading', 'photography', 'coding', 'running' ]在没有必要创建构造函数,仅让一个对象与另一个对象保持相似的情况下,原型式继承是可以胜任的。
缺点:
同原型链实现继承一样,包含引用类型值的属性会被所有实例共享。
寄生式继承是与原型式继承紧密相关的一种思路。寄生式继承的思路与寄生构造函数和工厂模式类似,即创建一个仅用于封装继承过程的函数,该函数在内部已某种方式来增强对象,最后再像真地是它做了所有工作一样返回对象。
function createAnother(original) {
var clone = object(original);//通过调用函数创建一个新对象
clone.sayHi = function () {//以某种方式增强这个对象
console.log('hi');
};
return clone;//返回这个对象
}
var person = {
name: 'Yvette',
hobbies: ['reading', 'photography']
};
var person2 = createAnother(person);
person2.sayHi(); //hi基于 person 返回了一个新对象 -—— person2,新对象不仅具有 person 的所有属性和方法,而且还有自己的 sayHi() 方法。在考虑对象而不是自定义类型和构造函数的情况下,寄生式继承也是一种有用的模式。
缺点:
所谓寄生组合式继承,即通过借用构造函数来继承属性,通过原型链的混成形式来继承方法,基本思路:
不必为了指定子类型的原型而调用超类型的构造函数,我们需要的仅是超类型原型的一个副本,本质上就是使用寄生式继承来继承超类型的原型,然后再将结果指定给子类型的原型。寄生组合式继承的基本模式如下所示:
function inheritPrototype(subType, superType) {
var prototype = object(superType.prototype); //创建对象
prototype.constructor = subType;//增强对象
subType.prototype = prototype;//指定对象
}constructor 属性至此,我们就可以通过调用 inheritPrototype 来替换为子类型原型赋值的语句:
function SuperType(name) {
this.name = name;
this.colors = ['pink', 'blue', 'green'];
}
//...code
function SuberType(name, age) {
SuperType.call(this, name);
this.age = age;
}
inheritPrototype(SuberType, SuperType);
//...code优点:
只调用了一次超类构造函数,效率更高。避免在SuberType.prototype上面创建不必要的、多余的属性,与其同时,原型链还能保持不变。
因此寄生组合继承是引用类型最理性的继承范式。
Class 可以通过extends关键字实现继承,如:
class SuperType {
constructor(age) {
this.age = age;
}
getAge() {
console.log(this.age);
}
}
class SubType extends SuperType {
constructor(age, name) {
super(age); // 调用父类的constructor(x, y)
this.name = name;
}
getName() {
console.log(this.name);
}
}
let instance = new SubType(22, '刘小夕');
instance.getAge(); //22对于ES6的 class 需要做以下几点说明:
console.log(typeof SuperType);//function
console.log(SuperType === SuperType.prototype.constructor); //trueObject.keys(SuperType.prototype);constructor 方法是类的默认方法,通过 new 命令生成对象实例时,自动调用该方法。一个类必须有constructor 方法,如果没有显式定义,一个空的 constructor 方法会被默认添加。
Class 不能像构造函数那样直接调用,会抛出错误。
使用 extends 关键字实现继承,有一点需要特别说明:
constructor 中调用 super 方法,否则新建实例时会报错。如果没有子类没有定义 constructor 方法,那么这个方法会被默认添加。在子类的构造函数中,只有调用 super 之后,才能使用 this关键字,否则报错。这是因为子类实例的构建,基于父类实例,只有super方法才能调用父类实例。class SubType extends SuperType {
constructor(...args) {
super(...args);
}
}[1] 珠峰架构课(墙裂推荐)
[2] CSS-清除浮动
[3] 详解JS函数柯里化
[4] JavaScript数组去重
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。 https://github.com/YvetteLau/Blog
关注公众号,加入技术交流群。
为什么会写这篇博文呢?
前段时间,和头条的小伙伴聊天问头条面试前端会问哪些问题,他称如果是他面试的话,event-loop肯定是要问的。那天聊了蛮多,event-loop算是给我留下了很深的印象。原因很简单,因为之前我从未深入了解过,如果是面试的时候,我遇到了这个问题,估计回答得肯定不如人意。
因此,最近我阅读了一些相关的文章,并细细梳理了一番,输出了本篇博文,希望能帮助大家搞懂浏览器的event-loop。后续会继续补充node中的event-loop。
JavaScript的运行机制:
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步
概括即是: 调用栈中的同步任务都执行完毕,栈内被清空了,就代表主线程空闲了,这个时候就会去任务队列中按照顺序读取一个任务放入到栈中执行。每次栈内被清空,都会去读取任务队列有没有任务,有就读取执行,一直循环读取-执行的操作
一个事件循环中有一个或者是多个任务队列
JavaScript中有两种异步任务:
宏任务: script(整体代码), setTimeout, setInterval, setImmediate, I/O, UI rendering
微任务: process.nextTick(Nodejs), Promises, Object.observe, MutationObserver;
主线程从"任务队列"中读取执行事件,这个过程是循环不断的,这个机制被称为事件循环。此机制具体如下:主线程会不断从任务队列中按顺序取任务执行,每执行完一个任务都会检查microtask队列是否为空(执行完一个任务的具体标志是函数执行栈为空),如果不为空则会一次性执行完所有microtask。然后再进入下一个循环去任务队列中取下一个任务执行。
详细说明:
执行进入microtask检查的的具体步骤如下:
需要注意的是:当前执行栈执行完毕时会立刻先处理所有微任务队列中的事件, 然后再去宏任务队列中取出一个事件。同一次事件循环中, 微任务永远在宏任务之前执行。
图示:
先看一个简单的示例:
setTimeout(()=>{
console.log("setTimeout1");
Promise.resolve().then(data => {
console.log(222);
});
});
setTimeout(()=>{
console.log("setTimeout2");
});
Promise.resolve().then(data=>{
console.log(111);
});思考一下, 运行结果是什么?
运行结果为:
111
setTimeout1
222
setTimeout2我们来看一下为什么?
我们来详细说明一下, JS引擎是如何执行这段代码的:
再思考一下下面代码的执行顺序:
console.log('script start');
setTimeout(function () {
console.log('setTimeout---0');
}, 0);
setTimeout(function () {
console.log('setTimeout---200');
setTimeout(function () {
console.log('inner-setTimeout---0');
});
Promise.resolve().then(function () {
console.log('promise5');
});
}, 200);
Promise.resolve().then(function () {
console.log('promise1');
}).then(function () {
console.log('promise2');
});
Promise.resolve().then(function () {
console.log('promise3');
});
console.log('script end');思考一下, 运行结果是什么?
运行结果为:
script start
script end
promise1
promise3
promise2
setTimeout---0
setTimeout---200
promise5
inner-setTimeout---0那么为什么?
我们来详细说明一下, JS引擎是如何执行这段代码的:
因为 JavaScript 是单线程的。单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。为了协调事件(event),用户交互(user interaction),脚本(script),渲染(rendering),网络(networking)等,用户代理(user agent)必须使用事件循环(event loops)。
最后有一点需要注意的是:本文介绍的是浏览器的Event-loop,因此在测试验证时,一定要使用浏览器环境进行测试验证,如果使用了node环境,那么结果不一定是如上所说。
最后,如果您觉得本篇博文给了您一点帮助或者启发,请帮忙点个Star吧~
欢迎关注小姐姐的微信公众号,加入技术交流群。
翻译:刘小夕
原文链接:https://devinduct.com/blogpost/36/javascript-proxy-and-its-benefits-let-s-create-an-api-wrapper
通常,当谈到JavaScript语言时,我们讨论的是ES6标准提供的新特性,本文也不例外。 我们将讨论JavaScript代理以及它们的作用,但在我们深入研究之前,我们先来看一下Proxy的定义是什么。
MDN上的定义是:代理对象是用于定义基本操作的自定义行为(例如,属性查找,赋值,枚举,函数调用等)。
换句话说,我们可以说代理对象是我们的目标对象的包装器,我们可以在其中操纵其属性并阻止对它的直接访问。 你可能会发现将它们应用到实际代码中很困难,我鼓励你仔细阅读这个概念,它可能会改变你的观点。
handler
包含陷阱(traps)的占位符对象。
traps
提供属性访问的方法。这类似于操作系统中捕获器的概念。
target
代理虚拟化的对象。(由代理对象包装和操作的实际对象)
在本文中,我将为 get 和 set 陷阱 提供简单的用例,考虑到最后,我们将看到如何使用它们并包含更复杂的功能,如API。
let p = new Proxy(target, handler);将目标和处理程序传递给Proxy构造函数,这样就创建了一个proxy对象。现在,让我们看看如何利用它。为了更清楚地看出Proxy的好处,首先,我们需要编写一些没有它的代码。
想象一下,我们有一个带有几个属性的用户对象,如果属性存在,我们想要打印用户信息,如果不存在,则抛出异常。在不使用代理对象时,判断属性值是否存在的代码也放在了打印用户信息的函数,即 printUser 中(这并不是我们所希望的),如下demo所示:
let user = {
name: 'John',
surname: 'Doe'
};
let printUser = (property) => {
let value = user[property];
if (!value) {
throw new Error(`The property [${property}] does not exist`);
} else {
console.log(`The user ${property} is ${value}`);
}
}
printUser('name'); // 输出: 'The user name is John'
printUser('email'); // 抛出错误: The property [email] does not exist通过查看上面的代码,你会发现:将条件和异常移到其他地方,而printUser中仅关注显示用户信息的实际逻辑会更好。这是我们可以使用代理对象的地方,让我们更新一下这个例子。
let user = {
name: 'John',
surname: 'Doe'
};
let proxy = new Proxy(user, {
get(target, property) {
let value = target[property];
if (!value) {
throw new Error(`The property [${property}] does not exist`);
}
return value;
}
});
let printUser = (property) => {
console.log(`The user ${property} is ${proxy[property]}`);
};
printUser('name'); // 输出: 'The user name is John'
printUser('email'); // 抛出错误: The property [email] does not exist在上面的示例中,我们包装了 user 对象,并设置了一个 get 方法。 此方法充当拦截器,在返回值之前,会首先对属性值进行检查,如果不存在,则抛出异常。
输出与第一种情况相同,但此时 printUser 函数专注于逻辑,只处理消息。
代理可能有用的另一个例子是属性值验证。在这种情况下,我们需要使用 set 方法,并在其中进行验证。例如,当我们需要确保目标类型时,这是一个非常有用的钩子。我们来看一下实际使用:
let user = new Proxy({}, {
set(target, property, value) {
if (property === 'name' && Object.prototype.toString.call(value) !== '[object String]') { // 确保是 string 类型
throw new Error(`The value for [${property}] must be a string`);
};
target[property] = value;
}
});
user.name = 1; // 抛出错误: The value for [name] must be a string这些是相当简单的用例,以下场景,proxy均可以派上用场:
现在是时候创建一个更复杂的用例了。
通过使用简单用例中的知识,我们可以创建一个API包装器,以便在我们的应用程序中使用。 当前只支持 get 和 post 请求,但它可以很容易地扩展。代码如下所示。
const api = new Proxy({}, {
get(target, key, context) {
return target[key] || ['get', 'post'].reduce((acc, key) => {
acc[key] = (config, data) => {
if (!config && !config.url || config.url === '') throw new Error('Url cannot be empty.');
let isPost = key === 'post';
if (isPost && !data) throw new Error('Please provide data in JSON format when using POST request.');
config.headers = isPost ? Object.assign(config.headers || {}, { 'content-type': 'application/json;chartset=utf8' }) :
config.headers;
return new Promise((resolve, reject) => {
let xhr = new XMLHttpRequest();
xhr.open(key, config.url);
if (config.headers) {
Object.keys(config.headers).forEach((header) => {
xhr.setRequestHeader(header, config.headers[header]);
});
}
xhr.onload = () => (xhr.status === 200 ? resolve : reject)(xhr);
xhr.onerror = () => reject(xhr);
xhr.send(isPost ? JSON.stringify(data) : null);
});
};
return acc;
}, target)[key];
},
set() {
throw new Error('API methods are readonly');
},
deleteProperty() {
throw new Error('API methods cannot be deleted!');
}
});让我们解释一下简单实现,set 和 deleteProperty。 我们添加了一个保护级别,并确保每当有人意外或无意地尝试为任何API属性设置新值时,都会抛出异常。
每次尝试删除属性时都会调用 deleteProperty 方法。可以确保没有人可以从我们的代理(即此处的 api)中删除任何属性,因为通常我们都不想丢失API方法。
get 在这里很有趣,它做了几件事。target 是一个空对象,get 方法将在第一次有人使用 api 时创建所有方法(如当前的 get 和 post请求),在 reduce 回调中,我们根据提供的配置执行API规范所需的验证和检查。在此示例中,我们不允许空URL和发布请求而不提供数据。这些检查可以扩展和修改,但重要的是我们只能在这一个地方集中处理。
reduce 仅在第一次API调用时完成,之后都会跳过整个 reduce 进程,get 只会执行默认行为并返回属性值,即API处理程序。每个处理程序返回一个Promise对象,负责创建请求并调用服务。
使用:
api.get({
url: 'my-url'
}).then((xhr) => {
alert('Success');
}, (xhr) => {
alert('Fail');
});delete api.get; //throw new Error('API methods cannot be deleted!'); 当您需要对数据进行更多控制时,代理可以派上用场。你可以根据受控规则扩展或拒绝对原始数据的访问,从而监视对象并确保正确行为。
如果您喜欢这篇文章,请关注我的公众号。可以在下面的评论部分中表达您的想法。
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。https://github.com/YvetteLau/Blog
function Foo() {
getName = function() {console.log(1)};
return this;
}
Foo.getName = function() {console.log(2)};
Foo.prototype.getName = function() {console.log(3)};
var getName = function() {console.log(4)};
function getName() {console.log(5)};
Foo.getName();
getName();
Foo().getName();
getName();
new Foo.getName();
new Foo().getName();
new new Foo().getName();随着互联网的发展,各种Web应用变得越来越复杂,满足了用户的各种需求的同时,各种网络安全问题也接踵而至。作为前端工程师的我们也逃不开这个问题,今天一起看一看Web前端有哪些安全问题以及我们如何去检测和防范这些问题。非前端的攻击本文不会讨论(如SQL注入,DDOS攻击等),毕竟后端也非本人擅长的领域。
QQ邮箱、新浪微博、YouTube、WordPress 和 百度 等知名网站都曾遭遇攻击,如果你从未有过安全方面的问题,不是因为你所开发的网站很安全,更大的可能是你的网站的流量非常低或者没有攻击的价值。
本文主要讨论以下几种攻击方式: XSS攻击、CSRF攻击、点击劫持以及URL跳转漏洞。
希望大家在阅读完本文之后,能够很好的回答以下几个面试题。
1.前端有哪些攻击方式?
2.什么是XSS攻击?XSS攻击有几种类型?如果防范XSS攻击?
3.什么是CSRF攻击?如何防范CSRF攻击
4.如何检测网站是否安全?
在开始之前,建议大家先clone代码,我为大家准备好了示例代码,并且写了详细的注释,大家可以对照代码来理解每一种攻击以及如何去防范攻击,毕竟看再多的文字,都不如实操。(Readme中详细得写了操作步骤):https://github.com/YvetteLau/Blog/tree/master/Security
XSS(Cross-Site Scripting,跨站脚本攻击)是一种代码注入攻击。攻击者在目标网站上注入恶意代码,当被攻击者登陆网站时就会执行这些恶意代码,这些脚本可以读取 cookie,session tokens,或者其它敏感的网站信息,对用户进行钓鱼欺诈,甚至发起蠕虫攻击等。
XSS 的本质是:恶意代码未经过滤,与网站正常的代码混在一起;浏览器无法分辨哪些脚本是可信的,导致恶意脚本被执行。由于直接在用户的终端执行,恶意代码能够直接获取用户的信息,利用这些信息冒充用户向网站发起攻击者定义的请求。
XSS分类
根据攻击的来源,XSS攻击可以分为存储型(持久性)、反射型(非持久型)和DOM型三种。下面我们来详细了解一下这三种XSS攻击:
1.1 反射型XSS
当用户点击一个恶意链接,或者提交一个表单,或者进入一个恶意网站时,注入脚本进入被攻击者的网站。Web服务器将注入脚本,比如一个错误信息,搜索结果等,未进行过滤直接返回到用户的浏览器上。
反射型 XSS 的攻击步骤:
URL,其中包含恶意代码。URL 时,网站服务端将恶意代码从 URL 中取出,拼接在 HTML 中返回给浏览器。反射型 XSS 漏洞常见于通过 URL 传递参数的功能,如网站搜索、跳转等。由于需要用户主动打开恶意的 URL 才能生效,攻击者往往会结合多种手段诱导用户点击。
POST 的内容也可以触发反射型 XSS,只不过其触发条件比较苛刻(需要构造表单提交页面,并引导用户点击),所以非常少见。
查看反射型攻击示例
请戳: https://github.com/YvetteLau/Blog/tree/master/Security
根据 README.md 的提示进行操作(真实情况下是需要诱导用户点击的,上述代码仅是用作演示)。
注意Chrome 和 Safari 能够检测到 url 上的xss攻击,将网页拦截掉,但是其它浏览器不行,如Firefox
如果不希望被前端拿到cookie,后端可以设置 httpOnly (不过这不是 XSS攻击 的解决方案,只能降低受损范围)
如何防范反射型XSS攻击
对字符串进行编码。
对url的查询参数进行转义后再输出到页面。
app.get('/welcome', function(req, res) {
//对查询参数进行编码,避免反射型 XSS攻击
res.send(`${encodeURIComponent(req.query.type)}`);
});1.2 DOM 型 XSS
DOM 型 XSS 攻击,实际上就是前端 JavaScript 代码不够严谨,把不可信的内容插入到了页面。在使用 .innerHTML、.outerHTML、.appendChild、document.write()等API时要特别小心,不要把不可信的数据作为 HTML 插到页面上,尽量使用 .innerText、.textContent、.setAttribute() 等。
DOM 型 XSS 的攻击步骤:
如何防范 DOM 型 XSS 攻击
防范 DOM 型 XSS 攻击的核心就是对输入内容进行转义(DOM 中的内联事件监听器和链接跳转都能把字符串作为代码运行,需要对其内容进行检查)。
1.对于url链接(例如图片的src属性),那么直接使用 encodeURIComponent 来转义。
2.非url,我们可以这样进行编码:
function encodeHtml(str) {
return str.replace(/"/g, '"')
.replace(/'/g, ''')
.replace(/</g, '<')
.replace(/>/g, '>');
}DOM 型 XSS 攻击中,取出和执行恶意代码由浏览器端完成,属于前端 JavaScript 自身的安全漏洞。
查看DOM型XSS攻击示例(根据readme提示查看)
请戳: https://github.com/YvetteLau/Blog/tree/master/Security
1.3 存储型XSS
恶意脚本永久存储在目标服务器上。当浏览器请求数据时,脚本从服务器传回并执行,影响范围比反射型和DOM型XSS更大。存储型XSS攻击的原因仍然是没有做好数据过滤:前端提交数据至服务端时,没有做好过滤;服务端在接受到数据时,在存储之前,没有做过滤;前端从服务端请求到数据,没有过滤输出。
存储型 XSS 的攻击步骤:
这种攻击常见于带有用户保存数据的网站功能,如论坛发帖、商品评论、用户私信等。
如何防范存储型XSS攻击:
查看存储型XSS攻击示例(根据Readme提示查看)
请戳: https://github.com/YvetteLau/Blog/tree/master/Security
除了谨慎的转义,我们还需要其他一些手段来防范XSS攻击:
1.Content Security Policy
在服务端使用 HTTP的 Content-Security-Policy 头部来指定策略,或者在前端设置 meta 标签。
例如下面的配置只允许加载同域下的资源:
Content-Security-Policy: default-src 'self'<meta http-equiv="Content-Security-Policy" content="form-action 'self';">前端和服务端设置 CSP 的效果相同,但是meta无法使用report
更多的设置可以查看 Content-Security-Policy
严格的 CSP 在 XSS 的防范中可以起到以下的作用:
2.输入内容长度控制
对于不受信任的输入,都应该限定一个合理的长度。虽然无法完全防止 XSS 发生,但可以增加 XSS 攻击的难度。
3.输入内容限制
对于部分输入,可以限定不能包含特殊字符或者仅能输入数字等。
4.其他安全措施
1.5 XSS 检测
读到这儿,相信大家已经知道了什么是XSS攻击,XSS攻击的类型,以及如何去防范XSS攻击。但是有一个非常重要的问题是:我们如何去检测XSS攻击,怎么知道自己的页面是否存在XSS漏洞?
很多大公司,都有专门的安全部门负责这个工作,但是如果没有安全部门,作为开发者本身,该如何去检测呢?
1.使用通用 XSS 攻击字串手动检测 XSS 漏洞
如: jaVasCript:/*-/*`/*\`/*'/*"/**/(/* */oNcliCk=alert() )//%0D%0A%0d%0a//</stYle/</titLe/</teXtarEa/</scRipt/--!>\x3csVg/<sVg/oNloAd=alert()//>\x3e
能够检测到存在于 HTML 属性、HTML 文字内容、HTML 注释、跳转链接、内联 JavaScript 字符串、内联 CSS 样式表等多种上下文中的 XSS 漏洞,也能检测 eval()、setTimeout()、setInterval()、Function()、innerHTML、document.write() 等 DOM 型 XSS 漏洞,并且能绕过一些 XSS 过滤器。
<img src=1 onerror=alert(1)>
2.使用第三方工具进行扫描(详见最后一个章节)
CSRF(Cross-site request forgery)跨站请求伪造:攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
典型的CSRF攻击流程:
一图胜千言:
CSRF的特点
1.攻击通常在第三方网站发起,如图上的站点B,站点A无法防止攻击发生。
2.攻击利用受害者在被攻击网站的登录凭证,冒充受害者提交操作;并不会去获取cookie信息(cookie有同源策略)
3.跨站请求可以用各种方式:图片URL、超链接、CORS、Form提交等等(来源不明的链接,不要点击)
运行代码,更直观了解一下
用户 loki 银行存款 10W。
用户 yvette 银行存款 1000。
我们来看看 yvette 如何通过 CSRF 攻击,将 loki 的钱偷偷转到自己的账户中,并根据提示,查看如何去防御CSRF攻击。
请戳: https://github.com/YvetteLau/Blog/tree/master/Security [根据readme中的CSRF部分进行操作]
1. 添加验证码(体验不好)
验证码能够防御CSRF攻击,但是我们不可能每一次交互都需要验证码,否则用户的体验会非常差,但是我们可以在转账,交易等操作时,增加验证码,确保我们的账户安全。
2. 判断请求的来源:检测Referer(并不安全,Referer可以被更改)
`Referer` 可以作为一种辅助手段,来判断请求的来源是否是安全的,但是鉴于 `Referer` 本身是可以被修改的,因为不能仅依赖于 `Referer`
3. 使用Token(主流)
CSRF攻击之所以能够成功,是因为服务器误把攻击者发送的请求当成了用户自己的请求。那么我们可以要求所有的用户请求都携带一个CSRF攻击者无法获取到的Token。服务器通过校验请求是否携带正确的Token,来把正常的请求和攻击的请求区分开。跟验证码类似,只是用户无感知。
- 服务端给用户生成一个token,加密后传递给用户
- 用户在提交请求时,需要携带这个token
- 服务端验证token是否正确
4. Samesite Cookie属性
为了从源头上解决这个问题,Google起草了一份草案来改进HTTP协议,为Set-Cookie响应头新增Samesite属性,它用来标明这个 Cookie是个“同站 Cookie”,同站Cookie只能作为第一方Cookie,不能作为第三方Cookie,Samesite 有两个属性值,分别是 Strict 和 Lax。
部署简单,并能有效防御CSRF攻击,但是存在兼容性问题。
Samesite=Strict
Samesite=Strict 被称为是严格模式,表明这个 Cookie 在任何情况都不可能作为第三方的 Cookie,有能力阻止所有CSRF攻击。此时,我们在B站点下发起对A站点的任何请求,A站点的 Cookie 都不会包含在cookie请求头中。
**Samesite=Lax**
`Samesite=Lax` 被称为是宽松模式,与 Strict 相比,放宽了限制,允许发送安全 HTTP 方法带上 Cookie,如 `Get` / `OPTIONS` 、`HEAD` 请求.
但是不安全 HTTP 方法,如: `POST`, `PUT`, `DELETE` 请求时,不能作为第三方链接的 Cookie
为了更好的防御CSRF攻击,我们可以组合使用以上防御手段。
点击劫持是指在一个Web页面中隐藏了一个透明的iframe,用外层假页面诱导用户点击,实际上是在隐藏的frame上触发了点击事件进行一些用户不知情的操作。
iframe 中1. frame busting
Frame busting
if ( top.location != window.location ){
top.location = window.location
}需要注意的是: HTML5中iframe的 sandbox 属性、IE中iframe的security 属性等,都可以限制iframe页面中的JavaScript脚本执行,从而可以使得 frame busting 失效。
2. X-Frame-Options
X-FRAME-OPTIONS是微软提出的一个http头,专门用来防御利用iframe嵌套的点击劫持攻击。并且在IE8、Firefox3.6、Chrome4以上的版本均能很好的支持。
可以设置为以下值:
DENY: 拒绝任何域加载
SAMEORIGIN: 允许同源域下加载
ALLOW-FROM: 可以定义允许frame加载的页面地址
URL 跳转漏洞是指后台服务器在告知浏览器跳转时,未对客户端传入的重定向地址进行合法性校验,导致用户浏览器跳转到钓鱼页面的一种漏洞。
URL跳转一般有以下几种实现方式
Header头跳转
Javascript跳转
META标签跳转
URL跳转漏洞防御
之所以会出现跳转 URL 漏洞,就是因为服务端没有对客户端传递的跳转地址进行合法性校验,所以,预防这种攻击的方式,就是对客户端传递过来的跳转 URL 进行校验。
1.referer的限制
如果确定传递URL参数进入的来源,我们可以通过该方式实现安全限制,保证该URL的有效性,避免恶意用户自己生成跳转链接
2.加入有效性验证Token
保证所有生成的链接都是来自于可信域,通过在生成的链接里加入用户不可控的token对生成的链接进行校验,可以避免用户生成自己的恶意链接从而被利用。
上面我们介绍了几种常见的前端安全漏洞,也了解一些防范措施,那么我们如何发现自己网站的安全问题呢?没有安全部门的公司可以考虑下面几款开源扫码工具:
Arachni是基于Ruby的开源,功能全面,高性能的漏洞扫描框架,Arachni提供简单快捷的扫描方式,只需要输入目标网站的网址即可开始扫描。它可以通过分析在扫描过程中获得的信息,来评估漏洞识别的准确性和避免误判。
Arachni默认集成大量的检测工具,可以实施 代码注入、CSRF、文件包含检测、SQL注入、命令行注入、路径遍历等各种攻击。
同时,它还提供了各种插件,可以实现表单爆破、HTTP爆破、防火墙探测等功能。
针对大型网站,该工具支持会话保持、浏览器集群、快照等功能,帮助用户更好实施渗透测试。
Mozilla HTTP Observatory,是Mozilla最近发布的一款名为Observatory的网站安全分析工具,意在鼓励开发者和系统管理员增强自己网站的安全配置。用法非常简单:输入网站URL,即可访问并分析网站HTTP标头,随后可针对网站安全性提供数字形式的分数和字母代表的安全级别。
检查的主要范围包括:
W3af是一个基于Python的Web应用安全扫描器。可帮助开发人员,有助于开发人员和测试人员识别Web应用程序中的漏洞。
扫描器能够识别200多个漏洞,包括跨站点脚本、SQL注入和操作系统命令。
参考文章:
[1] https://github.com/0xsobky/HackVault/wiki/Unleashing-an-Ultimate-XSS-Polyglot
[2] https://tech.meituan.com/2018/10/11/fe-security-csrf.html
[3] https://zhuanlan.zhihu.com/p/25486768?group_id=820705780520079360
[4] https://mp.weixin.qq.com/s/up35Zd8EmEfDVnvxOX9EmA
[5] https://juejin.im/post/5b4e0c936fb9a04fcf59cb79
[6] https://juejin.im/post/5c8a33dcf265da2dc538fc7d
[7] https://github.com/OWASP/CheatSheetSeries
关注小姐姐的公众号,加入技术交流群。
后续写作计划(写作顺序不定)
1.《寒冬求职季之你必须要懂的原生JS》(下)
2.《寒冬求职季之你必须要知道的CSS》
3.《寒冬求职季之你必须要懂的一些浏览器知识》
4.《寒冬求职季之你必须要知道的性能优化》
5.《寒冬求职季之你必须要懂的webpack原理》
针对React技术栈:
1.《寒冬求职季之你必须要懂的React》系列
2.《寒冬求职季之你必须要懂的ReactNative》系列
编写本文,虽然花费了很多时间,但是在这个过程中,我也学习到了很多知识,谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。https://github.com/YvetteLau/Blog
Step-By-Step (点击进入项目) 是我于
2019-05-20开始的一个项目,每个工作日发布一道面试题。每个周末我会仔细阅读大家的答案,整理最一份较优答案出来,因本人水平有限,有误的地方,大家及时指正。
如果想 加群 学习,可以通过文末的公众号,添加我为好友。
本周面试题一览:
闭包是指有权访问另一个函数作用域中的变量的函数,创建闭包最常用的方式就是在一个函数内部创建另一个函数。
function foo() {
var a = 2;
return function fn() {
console.log(a);
}
}
let func = foo();
func(); //输出2闭包使得函数可以继续访问定义时的词法作用域。拜 fn 所赐,在 foo() 执行后,foo 内部作用域不会被销毁。
无论通过何种手段将内部函数传递到所在的词法作用域之外,它都会持有对原始定义作用域的引用,无论在何处执行这个函数都会使用闭包。如:
function foo() {
var a = 2;
function inner() {
console.log(a);
}
outer(inner);
}
function outer(fn){
fn(); //闭包
}
foo();能够访问函数定义时所在的词法作用域(阻止其被回收)。
私有化变量
function base() {
let x = 10; //私有变量
return {
getX: function() {
return x;
}
}
}
let obj = base();
console.log(obj.getX()); //10var a = [];
for (var i = 0; i < 10; i++) {
a[i] = (function(j){
return function () {
console.log(j);
}
})(i);
}
a[6](); // 6function coolModule() {
let name = 'Yvette';
let age = 20;
function sayName() {
console.log(name);
}
function sayAge() {
console.log(age);
}
return {
sayName,
sayAge
}
}
let info = coolModule();
info.sayName(); //'Yvette'模块模式具有两个必备的条件(来自《你不知道的JavaScript》)
闭包会导致函数的变量一直保存在内存中,过多的闭包可能会导致内存泄漏
在实现 Promise.all 方法之前,我们首先要知道 Promise.all 的功能和特点,因为在清楚了 Promise.all 功能和特点的情况下,我们才能进一步去写实现。
Promise.all(iterable) 返回一个新的 Promise 实例。此实例在 iterable 参数内所有的 promise 都 fulfilled 或者参数中不包含 promise 时,状态变成 fulfilled;如果参数中 promise 有一个失败rejected,此实例回调失败,失败原因的是第一个失败 promise 的返回结果。
let p = Promise.all([p1, p2, p3]);p的状态由 p1,p2,p3决定,分成以下;两种情况:
(1)只有p1、p2、p3的状态都变成 fulfilled,p的状态才会变成 fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p的回调函数。
(2)只要p1、p2、p3之中有一个被 rejected,p的状态就变成 rejected,此时第一个被reject的实例的返回值,会传递给p的回调函数。
Promise.all 的返回值是一个 promise 实例
Promise.all 会 同步 返回一个已完成状态的 promisePromise.all 会 异步 返回一个已完成状态的 promisePromise.all 返回一个 处理中(pending) 状态的 promise.Promise.all 返回的 promise 的状态
Promise.all 返回的 promise 异步地变为完成。promise 失败,Promise.all 异步地将失败的那个结果给失败状态的回调函数,而不管其它 promise 是否完成Promise.all 返回的 promise 的完成状态的结果都是一个数组Promise.all = function (promises) {
return new Promise((resolve, reject) => {
//Array.from 将可迭代对象转换成数组
promises = Array.from(promises);
if (promises.length === 0) {
resolve([]);
} else {
let result = [];
let index = 0;
for (let i = 0; i < promises.length; i++ ) {
//考虑到 i 可能是 thenable 对象也可能是普通值
Promise.resolve(promises[i]).then(data => {
result[i] = data;
if (++index === promises.length) {
//所有的 promises 状态都是 fulfilled,promise.all返回的实例才变成 fulfilled 态
resolve(result);
}
}, err => {
reject(err);
return;
});
}
}
});
}<script> 标签中增加 async(html5) 或者 defer(html4) 属性,脚本就会异步加载。<script src="../XXX.js" defer></script>defer 和 async 的区别在于:
defer 要等到整个页面在内存中正常渲染结束(DOM 结构完全生成,以及其他脚本执行完成),在window.onload 之前执行;async 一旦下载完,渲染引擎就会中断渲染,执行这个脚本以后,再继续渲染。defer 脚本,会按照它们在页面出现的顺序加载async 脚本不能保证加载顺序script 标签动态创建的 script ,设置 src 并不会开始下载,而是要添加到文档中,JS文件才会开始下载。
let script = document.createElement('script');
script.src = 'XXX.js';
// 添加到html文件中才会开始下载
document.body.append(script);let xhr = new XMLHttpRequest();
xhr.open("get", "js/xxx.js",true);
xhr.send();
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
eval(xhr.responseText);
}
}ES6 为数组实例新增了 flat 方法,用于将嵌套的数组“拉平”,变成一维的数组。该方法返回一个新数组,对原数组没有影响。
flat 默认只会 “拉平” 一层,如果想要 “拉平” 多层的嵌套数组,需要给 flat 传递一个整数,表示想要拉平的层数。
function flattenDeep(arr, deepLength) {
return arr.flat(deepLength);
}
console.log(flattenDeep([1, [2, [3, [4]], 5]], 3));当传递的整数大于数组嵌套的层数时,会将数组拉平为一维数组,JS能表示的最大数字为 Math.pow(2, 53) - 1,因此我们可以这样定义 flattenDeep 函数
function flattenDeep(arr) {
//当然,大多时候我们并不会有这么多层级的嵌套
return arr.flat(Math.pow(2,53) - 1);
}
console.log(flattenDeep([1, [2, [3, [4]], 5]]));function flattenDeep(arr){
return arr.reduce((acc, val) => Array.isArray(val) ? acc.concat(flattenDeep(val)) : acc.concat(val), []);
}
console.log(flattenDeep([1, [2, [3, [4]], 5]]));function flattenDeep(input) {
const stack = [...input];
const res = [];
while (stack.length) {
// 使用 pop 从 stack 中取出并移除值
const next = stack.pop();
if (Array.isArray(next)) {
// 使用 push 送回内层数组中的元素,不会改动原始输入 original input
stack.push(...next);
} else {
res.push(next);
}
}
// 使用 reverse 恢复原数组的顺序
return res.reverse();
}
console.log(flattenDeep([1, [2, [3, [4]], 5]]));ES6 规定,默认的 Iterator 接口部署在数据结构的 Symbol.iterator 属性,换个角度,也可以认为,一个数据结构只要具有 Symbol.iterator 属性(Symbol.iterator 方法对应的是遍历器生成函数,返回的是一个遍历器对象),那么就可以其认为是可迭代的。
Symbol.iterator 属性,Symbol.iterator() 返回的是一个遍历器对象for ... of 进行循环let arry = [1, 2, 3, 4];
let iter = arry[Symbol.iterator]();
console.log(iter.next()); //{ value: 1, done: false }
console.log(iter.next()); //{ value: 2, done: false }
console.log(iter.next()); //{ value: 3, done: false }Iterator 接口的数据结构:上面我们说,一个对象只有具有正确的 Symbol.iterator 属性,那么其就是可迭代的,因此,我们可以通过给对象新增 Symbol.iterator 使其可迭代。
let obj = {
name: "Yvette",
age: 18,
job: 'engineer',
*[Symbol.iterator]() {
const self = this;
const keys = Object.keys(self);
for (let index = 0; index < keys.length; index++) {
yield self[keys[index]];//yield表达式仅能使用在 Generator 函数中
}
}
};
for (var key of obj) {
console.log(key); //Yvette 18 engineer
}[1] 珠峰架构课(墙裂推荐)
[1] MDN Promise.all
[2] Promise
[3] Iterator
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。 https://github.com/YvetteLau/Blog
关注公众号,加入技术交流群。
this关键字是JavaScript中最复杂的机制之一,是一个特别的关键字,被自动定义在所有函数的作用域中,但是相信很多JavaScript开发者并不是非常清楚它究竟指向的是什么。听说你很懂this,是真的吗?
请先回答第一个问题:如何准确判断this指向的是什么?【面试的高频问题】
——————————————————————————————————————————————
【图片来源于网络,侵删】
再看一道题,控制台打印出来的值是什么?【浏览器运行环境】
var number = 5;
var obj = {
number: 3,
fn1: (function () {
var number;
this.number *= 2;
number = number * 2;
number = 3;
return function () {
var num = this.number;
this.number *= 2;
console.log(num);
number *= 3;
console.log(number);
}
})()
}
var fn1 = obj.fn1;
fn1.call(null);
obj.fn1();
console.log(window.number);如果你思考出来的结果,与在浏览中执行结果相同,并且每一步的依据都非常清楚,那么,你可以选择继续往下阅读,或者关闭本网页,愉快得去玩耍。如果你有一部分是靠蒙的,或者对自己的答案并不那么确定,那么请继续往下阅读。
毕竟花一两个小时的时间,把this彻底搞明白,是一件很值得事情,不是吗?
本文将细致得讲解this的绑定规则,并在最后剖析前文两道题。
首先,我们为什么要学习this?
不管出于什么目的,我们都需要把this这个知识点整的明明白白的。
OK,Let's go!
言归正传,this是什么?首先记住this不是指向自身!this 就是一个指针,指向调用函数的对象。这句话我们都知道,但是很多时候,我们未必能够准确判断出this究竟指向的是什么?这就好像我们听过很多道理 却依然过不好这一生。今天咱们不探讨如何过好一生的问题,但是呢,希望阅读完下面的内容之后,你能够一眼就看出this指向的是什么。
为了能够一眼看出this指向的是什么,我们首先需要知道this的绑定规则有哪些?
上面的名词,你也许听过,也许没听过,但是今天之后,请牢牢记住。我们将依次来进行解析。
默认绑定,在不能应用其它绑定规则时使用的默认规则,通常是独立函数调用。
function sayHi(){
console.log('Hello,', this.name);
}
var name = 'YvetteLau';
sayHi();在调用Hi()时,应用了默认绑定,this指向全局对象(非严格模式下),严格模式下,this指向undefined,undefined上没有this对象,会抛出错误。
上面的代码,如果在浏览器环境中运行,那么结果就是 Hello,YvetteLau
但是如果在node环境中运行,结果就是 Hello,undefined.这是因为node中name并不是挂在全局对象上的。
本文中,如不特殊说明,默认为浏览器环境执行结果。
函数的调用是在某个对象上触发的,即调用位置上存在上下文对象。典型的形式为 XXX.fun().我们来看一段代码:
function sayHi(){
console.log('Hello,', this.name);
}
var person = {
name: 'YvetteLau',
sayHi: sayHi
}
var name = 'Wiliam';
person.sayHi();
打印的结果是 Hello,YvetteLau.
sayHi函数声明在外部,严格来说并不属于person,但是在调用sayHi时,调用位置会使用person的上下文来引用函数,隐式绑定会把函数调用中的this(即此例sayHi函数中的this)绑定到这个上下文对象(即此例中的person)
需要注意的是:对象属性链中只有最后一层会影响到调用位置。
function sayHi(){
console.log('Hello,', this.name);
}
var person2 = {
name: 'Christina',
sayHi: sayHi
}
var person1 = {
name: 'YvetteLau',
friend: person2
}
person1.friend.sayHi();
结果是:Hello, Christina.
因为只有最后一层会确定this指向的是什么,不管有多少层,在判断this的时候,我们只关注最后一层,即此处的friend。
隐式绑定有一个大陷阱,绑定很容易丢失(或者说容易给我们造成误导,我们以为this指向的是什么,但是实际上并非如此).
function sayHi(){
console.log('Hello,', this.name);
}
var person = {
name: 'YvetteLau',
sayHi: sayHi
}
var name = 'Wiliam';
var Hi = person.sayHi;
Hi();结果是: Hello,Wiliam.
这是为什么呢,Hi直接指向了sayHi的引用,在调用的时候,跟person没有半毛钱的关系,针对此类问题,我建议大家只需牢牢继续这个格式:XXX.fn();fn()前如果什么都没有,那么肯定不是隐式绑定,但是也不一定就是默认绑定,这里有点小疑问,我们后来会说到。
除了上面这种丢失之外,隐式绑定的丢失是发生在回调函数中(事件回调也是其中一种),我们来看下面一个例子:
function sayHi(){
console.log('Hello,', this.name);
}
var person1 = {
name: 'YvetteLau',
sayHi: function(){
setTimeout(function(){
console.log('Hello,',this.name);
})
}
}
var person2 = {
name: 'Christina',
sayHi: sayHi
}
var name='Wiliam';
person1.sayHi();
setTimeout(person2.sayHi,100);
setTimeout(function(){
person2.sayHi();
},200);结果为:
Hello, Wiliam
Hello, Wiliam
Hello, Christina第一条输出很容易理解,setTimeout的回调函数中,this使用的是默认绑定,非严格模式下,执行的是全局对象
第二条输出是不是有点迷惑了?说好XXX.fun()的时候,fun中的this指向的是XXX呢,为什么这次却不是这样了!Why?
其实这里我们可以这样理解: setTimeout(fn,delay){ fn(); },相当于是将person2.sayHi赋值给了一个变量,最后执行了变量,这个时候,sayHi中的this显然和person2就没有关系了。
第三条虽然也是在setTimeout的回调中,但是我们可以看出,这是执行的是person2.sayHi()使用的是隐式绑定,因此这是this指向的是person2,跟当前的作用域没有任何关系。
读到这里,也许你已经有点疲倦了,但是答应我,别放弃,好吗?再坚持一下,就可以掌握这个知识点了。

显式绑定比较好理解,就是通过call,apply,bind的方式,显式的指定this所指向的对象。(注意:《你不知道的Javascript》中将bind单独作为了硬绑定讲解了)
call,apply和bind的第一个参数,就是对应函数的this所指向的对象。call和apply的作用一样,只是传参方式不同。call和apply都会执行对应的函数,而bind方法不会。
function sayHi(){
console.log('Hello,', this.name);
}
var person = {
name: 'YvetteLau',
sayHi: sayHi
}
var name = 'Wiliam';
var Hi = person.sayHi;
Hi.call(person); //Hi.apply(person)输出的结果为: Hello, YvetteLau. 因为使用硬绑定明确将this绑定在了person上。
那么,使用了硬绑定,是不是意味着不会出现隐式绑定所遇到的绑定丢失呢?显然不是这样的,不信,继续往下看。
function sayHi(){
console.log('Hello,', this.name);
}
var person = {
name: 'YvetteLau',
sayHi: sayHi
}
var name = 'Wiliam';
var Hi = function(fn) {
fn();
}
Hi.call(person, person.sayHi); 输出的结果是 Hello, Wiliam. 原因很简单,Hi.call(person, person.sayHi)的确是将this绑定到Hi中的this了。但是在执行fn的时候,相当于直接调用了sayHi方法(记住: person.sayHi已经被赋值给fn了,隐式绑定也丢了),没有指定this的值,对应的是默认绑定。
现在,我们希望绑定不会丢失,要怎么做?很简单,调用fn的时候,也给它硬绑定。
function sayHi(){
console.log('Hello,', this.name);
}
var person = {
name: 'YvetteLau',
sayHi: sayHi
}
var name = 'Wiliam';
var Hi = function(fn) {
fn.call(this);
}
Hi.call(person, person.sayHi);此时,输出的结果为: Hello, YvetteLau,因为person被绑定到Hi函数中的this上,fn又将这个对象绑定给了sayHi的函数。这时,sayHi中的this指向的就是person对象。
至此,革命已经快胜利了,我们来看最后一种绑定规则: new 绑定。
javaScript和C++不一样,并没有类,在javaScript中,构造函数只是使用new操作符时被调用的函数,这些函数和普通的函数并没有什么不同,它不属于某个类,也不可能实例化出一个类。任何一个函数都可以使用new来调用,因此其实并不存在构造函数,而只有对于函数的“构造调用”。
使用new来调用函数,会自动执行下面的操作:
因此,我们使用new来调用函数的时候,就会新对象绑定到这个函数的this上。
function sayHi(name){
this.name = name;
}
var Hi = new sayHi('Yevtte');
console.log('Hello,', Hi.name);输出结果为 Hello, Yevtte, 原因是因为在var Hi = new sayHi('Yevtte');这一步,会将sayHi中的this绑定到Hi对象上。
我们知道了this有四种绑定规则,但是如果同时应用了多种规则,怎么办?
显然,我们需要了解哪一种绑定方式的优先级更高,这四种绑定的优先级为:
new绑定 > 显式绑定 > 隐式绑定 > 默认绑定
这个规则时如何得到的,大家如果有兴趣,可以自己写个demo去测试,或者记住上面的结论即可。
凡事都有例外,this的规则也是这样。
如果我们将null或者是undefined作为this的绑定对象传入call、apply或者是bind,这些值在调用时会被忽略,实际应用的是默认绑定规则。
var foo = {
name: 'Selina'
}
var name = 'Chirs';
function bar() {
console.log(this.name);
}
bar.call(null); //Chirs 输出的结果是 Chirs,因为这时实际应用的是默认绑定规则。
箭头函数是ES6中新增的,它和普通函数有一些区别,箭头函数没有自己的this,它的this继承于外层代码库中的this。箭头函数在使用时,需要注意以下几点:
(1)函数体内的this对象,继承的是外层代码块的this。
(2)不可以当作构造函数,也就是说,不可以使用new命令,否则会抛出一个错误。
(3)不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
(4)不可以使用yield命令,因此箭头函数不能用作 Generator 函数。
(5)箭头函数没有自己的this,所以不能用call()、apply()、bind()这些方法去改变this的指向.
OK,我们来看看箭头函数的this是什么?
var obj = {
hi: function(){
console.log(this);
return ()=>{
console.log(this);
}
},
sayHi: function(){
return function() {
console.log(this);
return ()=>{
console.log(this);
}
}
},
say: ()=>{
console.log(this);
}
}
let hi = obj.hi(); //输出obj对象
hi(); //输出obj对象
let sayHi = obj.sayHi();
let fun1 = sayHi(); //输出window
fun1(); //输出window
obj.say(); //输出window那么这是为什么呢?如果大家说箭头函数中的this是定义时所在的对象,这样的结果显示不是大家预期的,按照这个定义,say中的this应该是obj才对。
我们来分析一下上面的执行结果:
依旧是前面的代码。我们来看看箭头函数中的this真的是静态的吗?
我要说:非也
var obj = {
hi: function(){
console.log(this);
return ()=>{
console.log(this);
}
},
sayHi: function(){
return function() {
console.log(this);
return ()=>{
console.log(this);
}
}
},
say: ()=>{
console.log(this);
}
}
let sayHi = obj.sayHi();
let fun1 = sayHi(); //输出window
fun1(); //输出window
let fun2 = sayHi.bind(obj)();//输出obj
fun2(); //输出obj可以看出,fun1和fun2对应的是同样的箭头函数,但是this的输出结果是不一样的。
所以,请大家牢牢记住一点: 箭头函数没有自己的this,箭头函数中的this继承于外层代码库中的this.
关于this的规则,至此,就告一段落了,但是想要一眼就能看出this所绑定的对象,还需要不断的训练。
我们来回顾一下,最初的问题。
1. 如何准确判断this指向的是什么?
2. 执行过程解析
var number = 5;
var obj = {
number: 3,
fn: (function () {
var number;
this.number *= 2;
number = number * 2;
number = 3;
return function () {
var num = this.number;
this.number *= 2;
console.log(num);
number *= 3;
console.log(number);
}
})()
}
var myFun = obj.fn;
myFun.call(null);
obj.fn();
console.log(window.number);
我们来分析一下,这段代码的执行过程。
window.number * = 2; //window.number的值是10(var number定义的全局变量是挂在window上的)
number = number * 2; //number的值是NaN;注意我们这边定义了一个number,但是没有赋值,number的值是undefined;Number(undefined)->NaN
number = 3; //number的值为3fn: function(){
var num = this.number;
this.number *= 2;
console.log(num);
number *= 3;
console.log(number);
}执行时:
var num = this.number; //num=10; 此时this指向的是window
this.number * = 2; //window.number = 20
console.log(num); //输出结果为10
number *= 3; //number=9; 这个number对应的闭包中的number;闭包中的number的是3
console.log(number); //输出的结果是9var num = this.number;//num = 3;此时this指向的是obj
this.number *= 2; //obj.number = 6;
console.log(num); //输出结果为3;
number *= 3; //number=27;这个number对应的闭包中的number;闭包中的number的此时是9
console.log(number);//输出的结果是27因此组中结果为:
10
9
3
27
20严格模式下结果,大家根据今天所学,自己分析,巩固一下知识点。
最后,恭喜坚持读完的小伙伴们,你们成功get到了this这个知识点,但是想要完全掌握,还是要多回顾和练习。如果你有不错的this练习题,欢迎在评论区留言哦,大家一起进步!
谢谢您花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,那么不要吝啬你的赞和Star哦,您的肯定是我前进的最大动力。
欢迎关注小姐姐的微信公众号,加入技术交流群。
原文地址: https://dev.to/sayanide/best-github-repos-for-web-developers-9id

手头有大量的资源📚总是一件很棒的事。
作为一个码农,我们需要专注于功能和最佳实践,而不是一遍遍地编写样板代码。消除无用功,投入时间学习使用正确的工具或者懂得使用有用的资源可以极大的帮助我们节省时间。
通过本篇文章,我们将会了解一些能够极大的帮助我们提升 WEB 开发技能的 GitHub 库,这些库也会帮助你编写更好的代码。
这个库是一个很棒的地方,可以让你随时了解 Node 世界,并在使用时了解最佳实践。拥有 40k Star 和 133 位贡献者,这个库几乎每天都有更新。
该库对排名较高 Node.js 的最佳实践进行了总结和整理,包括 Node.js + Docker 最佳实践。目前拥有超过80多种最佳实践,风格指南和结构建议等。
一些常见的最佳做法包括:
点击跳转到仓库
HTML5 Boilerplate 是一个专业的前端模板,用于构建快速、健壮和适应性强的 Web 应用程序或者网站。
该项目是多年迭代开发和社区知识的产物。它没有强加特定的开发理念或者框架,所以你可按照自己的方式自由地构建代码。
包括像如下的预定义功能:
CSS 助手类根据你想要用的内容以及使用方法,将所需文件复制粘贴到你的工程目录里即可。这样就为你提供了一个配置好的模板,从而加快了开发速度。
点击跳转到仓库
掌握一个新框架的核心概念和意识形态并不是一件令人沮丧的事情。
如果你没有正确理解这个概念的话,你需要阅读文档,运行示例代码,拆解示例应用程序并将其重新组合在一起,在本地安装 CLI 等等,它需要花费太多的经历,令人沮丧。
RealWorld 允许你选择任何前端(React,Angular2 等)和任何后端(Node , Django 等),并将它们集成在一起以查看应用程序的真实示例。
由于这些实现和技术栈相关,它们显然不能混用,但它们仍然遵循相同的功能和UX规范。
一些常用集成实例:
你可以在仓库中找到无穷无尽的示例。尽情去寻找吧!
点击跳转到仓库
这是一系列深入研究 JavaScript 语言核心机制的书籍。
所有的书籍均为免费,你可以随时在线阅读。
作者建议阅读的顺序为:
点击跳转到仓库
这是 Airbnb 提供的非常精确和专业的风格指南。
本指南将通过深入基础知识和代码片段来帮助你由深入浅地理解 JavaScript。
本指南涉及的一些热门内容如下:
点击跳转到仓库
Storybook 是 UI 组件的开发环境,它允许你浏览组件库,查看每个组件的不同状态,以及交互地开发和测试组件。
Storybook 在 app 之外运行,这允许你独立开发 UI 组件,提高组件的重用性、测试性和开发速度。你可以快速构建,而不必担心应用程序特定的依赖关系。
它附带了一个 CLI 和一些代码示例,供你熟悉 Storybook.
点击跳转到仓库
Front-End-Checklist 是一个详尽的列表,列出了在网站或者 HTML 页面投入使用前所需要具备或者测试的所有元素。
它是一个基于前端 Web 开发的仓库,更关注性能、安全性和 SEO 等。
Front-End-Checklist 中的所有项目对于大多数工程都是必须的,但其中有些元素可以省略。
包括:
点击跳转到仓库
这篇文章的令该来源于 Tech Sapien 和他所有令人惊叹的工作。库中的图片📷 也是取自同一处。
上面提到的所有的库并不是唯一可用的资源,除此之外我敢肯定还有大量的令人惊叹的项目。这些是其中一些我觉得很有用的资源,同时我自己也经常沉浸其中。
不要忘了给这些库点 Star🌟。以感谢所有出色的贡献者,感谢他们为我们创造了如此有用的资源✌🏼
原文地址: https://dev.to/sayanide/best-github-repos-for-web-developers-9id
最后:
如果有翻译的不对的地方,请多多指正,希望有所帮助。
PS E:\mywockspace\Blog-master\eos-cli> npm link
[email protected] postinstall E:\mywockspace\Blog-master\eos-cli
eos config set
'eos' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! [email protected] postinstall: eos config set
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] postinstall script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
npm ERR! C:\Users\zwhu\AppData\Roaming\npm-cache_logs\2019-08-27T01_40_58_198Z-debug.log
PS E:\mywockspace\Blog-master\eos-cli>
翻译:刘小夕
原文链接:https://dmitripavlutin.com/7-architectural-attributes-of-a-reliable-react-component/
原文的篇幅非常长,不过内容太过于吸引我,还是忍不住要翻译出来。此篇文章对编写可重用和可维护的React组件非常有帮助。但因为篇幅实在太长,我对文章进行了分割,本篇文章重点阐述 封装。因本人水平有限,文中部分翻译可能不够准确,如果您有更好的想法,欢迎在评论区指出。
更多文章可戳: https://github.com/YvetteLau/Blog
———————————————我是一条分割线————————————————
一个封装组件提供
props控制其行为而不是暴露其内部结构。
耦合是决定组件之间依赖程度的系统特性。根据组件的依赖程度,可区分两种耦合类型:
当应用程序组件对其他组件知之甚少或一无所知时,就会发生松耦合。
当应用程序组件知道彼此的许多详细信息时,就会发生紧耦合。
松耦合是我们设计应用结构和组件之间关系的目标。
松耦合应用(封装组件)
松耦合会带来以下好处:
相反,紧耦合的系统会失去上面描述的好处。主要缺点是很难修改高度依赖于其他组件的组件。即使是一处修改,也可能导致一系列的依赖组件需要修改。
紧耦合应用(组件无封装)
封装 或 信息隐藏 是如何设计组件的基本原则,也是松耦合的关键。
封装良好的组件隐藏其内部结构,并提供一组属性来控制其行为。
隐藏内部结构是必要的。其他组件没必要知道或也不依赖组件的内部结构或实现细节。
React 组件可能是函数组件或类组件、定义实例方法、设置 ref、拥有 state 或使用生命周期方法。这些实现细节被封装在组件内部,其他组件不应该知道这些细节。
隐藏内部结构的组件彼此之间的依赖性较小,而降低依赖度会带来松耦合的好处。
细节隐藏是隔离组件的关键。此时,你需要一种组件通信的方法:props。porps 是组件的输入。
建议 prop 的类型为基本数据(例如,string 、 number 、boolean):
<Message text="Hello world!" modal={false} />;必要时,使用复杂的数据结构,如对象或数组:
<MoviesList items={['Batman Begins', 'Blade Runner']} />prop 可以是一个事件处理函数和异步函数:
<input type="text" onChange={handleChange} />prop 甚至可以是一个组件构造函数。组件可以处理其他组件的实例化:
function If({ component: Component, condition }) {
return condition ? <Component /> : null;
}
<If condition={false} component={LazyComponent} /> 为了避免破坏封装,请注意通过 props 传递的内容。给子组件设置 props 的父组件不应该暴露其内部结构的任何细节。例如,使用 props 传输整个组件实例或 refs 都是一个不好的做法。
访问全局变量同样也会对封装产生负面影响。
组件的实例和状态对象是封装在组件内部的实现细节。因此,将状态管理的父组件实例传递给子组件会破坏封装。
我们来研究一下这种情况。
一个简单的应用程序显示一个数字和两个按钮。第一个按钮增加数值,第二个按钮减少数值:
这个应用由两个组件组成:<App> 和 <Controls>.
number 是 <App> 的 state 对象,<App> 负责 将这个数字渲染到页面。
// 问题: 封装被破坏
class App extends Component {
constructor(props) {
super(props);
this.state = { number: 0 };
}
render() {
return (
<div className="app">
<span className="number">{this.state.number}</span>
<Controls parent={this} />
</div>
);
}
}<Controls> 负责渲染按钮,并为其设置事件处理函数,当用户点击按钮时,父组件的状态将会被更新:number 加1或者减1((updateNumber()方法`)
// 问题: 使用父组件的内部结构
class Controls extends Component {
render() {
return (
<div className="controls">
<button onClick={() => this.updateNumber(+1)}>
Increase
</button>
<button onClick={() => this.updateNumber(-1)}>
Decrease
</button>
</div>
);
}
updateNumber(toAdd) {
this.props.parent.setState(prevState => ({
number: prevState.number + toAdd
}));
}
}当前的实现有什么问题?
第一个问题是: <App> 的封装被破坏,因为它的内部结构在应用中传递。<App> 错误地允许 <Controls> 直接去修改其 state。
第二个问题是: 子组件 Controls 知道了太多父组件 <App> 的内部细节,它可以访问父组件的实例,知道父组件是一个有状态组件,知道父组件的 state 对象的细节(知道 number 是父组件 state 的属性),并且知道怎么去更新父组件的 state.
一个麻烦的结果是: <Controls> 将很难测试和重用。对 <App> 结构的细微修改会导致需要对 <Controls> 进行修改(对于更大的应用程序,也会导致类似耦合的组件需要修改)。
解决方案是设计一个方便的通信接口,考虑到松耦合和封装。让我们改进两个组件的结构和属性,以便恢复封装。
只有组件本身应该知道它的状态结构。<App> 的状态管理应该从 <Controls>(updateNumber()方法)移到正确的位置:即 <App> 组件中。
<App> 被修改为 <Controls> 设置属性 onIncrease 和 onDecrease。这些是更新 <App> 状态的回调函数:
// 解决: 恢复封装
class App extends Component {
constructor(props) {
super(props);
this.state = { number: 0 };
}
render() {
return (
<div className="app">
<span className="number">{this.state.number}</span>
<Controls
onIncrease={() => this.updateNumber(+1)}
onDecrease={() => this.updateNumber(-1)}
/>
</div>
);
}
updateNumber(toAdd) {
this.setState(prevState => ({
number: prevState.number + toAdd
}));
}
}现在,<Controls> 接收用于增加和减少数值的回调,注意解耦和封装恢复时:<Controls> 不再需要访问父组件实例。也不会直接去修改父组件的状态。
而且,<Controls> 被修改为了一个函数式组件:
// 解决方案: 使用回调函数去更新父组件的状态
function Controls({ onIncrease, onDecrease }) {
return (
<div className="controls">
<button onClick={onIncrease}>Increase</button>
<button onClick={onDecrease}>Decrease</button>
</div>
);
}<App> 组件的封装已经恢复,状态由其本身管理,也应该如此。
此外,<Controls> 不在依赖 <App> 的实现细节,onIncrease 和 onDecrease 在按钮被点击的时候调用,<Controls> 不知道(也不应该知道)这些回调的内部实现。
<Controls> 组件的可重用性和可测试性显著增加。
<Controls> 的复用变得很容易,因为它除了需要回调,没有其它依赖。测试也变得简单,只需验证单击按钮时,回调是否执行。
最后谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。https://github.com/YvetteLau/Blog
Step-By-Step (点击进入项目) 是我于
2019-05-20开始的一个项目,每个工作日发布一道面试题。每个周末我会仔细阅读大家的答案,整理最一份较优答案出来,因本人水平有限,有误的地方,大家及时指正。
如果想 加群 学习,扫码 二维码 (点击查看),添加我为好友,验证信息为加入组织,我拉你进群。
本周面试题一览:
节流函数的作用是规定一个单位时间,在这个单位时间内最多只能触发一次函数执行,如果这个单位时间内多次触发函数,只能有一次生效。
举例说明:小明的妈妈和小明约定好,如果小明在周考中取得满分,那么当月可以带他去游乐场玩,但是一个月最多只能去一次。
这其实就是一个节流的例子,在一个月的时间内,去游乐场最多只能触发一次。即使这个时间周期内,小明取得多次满分。
1.按钮点击事件
2.拖拽事件
3.onScoll
4.计算鼠标移动的距离(mousemove)
利用时间戳实现
function throttle (func, delay) {
var lastTime = 0;
function throttled() {
var context = this;
var args = arguments;
var nowTime = Date.now();
if(nowTime > lastTime + delay) {
func.apply(context, args);
lastTime = nowTime;
}
}
//防抖函数最终返回的是一个函数
return throttled;
}利用定时器实现
function throttle(func, delay) {
var timeout = null;
function throttled() {
var context = this;
var args = arguments;
if(!timeout) {
timeout = setTimeout(()=>{
func.apply(context, args);
clearTimeout(timeout);
timeout=null
}, delay);
}
}
return throttled;
}时间戳和定时器的方式都没有考虑最后一次执行的问题,比如有个按钮点击事件,设置的间隔时间是1S,在第0.5S,1.8S,2.2S点击,那么只有0.5S和1.8S的两次点击能够触发函数执行,而最后一次的2.2S会被忽略。
组合实现,允许设置第一次或者最后一次是否触发函数执行
function throttle (func, wait, options) {
var timeout, context, args, result;
var previous = 0;
if (!options) options = {};
var later = function () {
previous = options.leading === false ? 0 : Date.now() || new Date().getTime();
timeout = null;
result = func.apply(context, args);
if (!timeout) context = args = null;
};
var throttled = function () {
var now = Date.now() || new Date().getTime();
if (!previous && options.leading === false) previous = now;
var remaining = wait - (now - previous);
context = this;
args = arguments;
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
result = func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
// 判断是否设置了定时器和 trailing
timeout = setTimeout(later, remaining);
}
return result;
};
throttled.cancel = function () {
clearTimeout(timeout);
previous = 0;
timeout = context = args = null;
};
return throttled;
}使用很简单:
btn.onclick = throttle(handle, 1000, {leading:true, trailing: true});在开始说明JS上下文栈和作用域之前,我们先说明下JS上下文以及作用域的概念。
执行上下文就是当前 JavaScript 代码被解析和执行时所在环境的抽象概念, JavaScript 中运行任何的代码都是在执行上下文中运行。
执行上下文类型分为:
执行上下文创建过程中,需要做以下几件事:
作用域负责收集和维护由所有声明的标识符(变量)组成的一系列查询,并实施一套非常严格的规则,确定当前执行的代码对这些标识符的访问权限。—— 摘录自《你不知道的JavaScript》(上卷)
作用域有两种工作模型:词法作用域和动态作用域,JS采用的是词法作用域工作模型,词法作用域意味着作用域是由书写代码时变量和函数声明的位置决定的。(with 和 eval 能够修改词法作用域,但是不推荐使用,对此不做特别说明)
作用域分为:
执行栈,也叫做调用栈,具有 LIFO (后进先出) 结构,用于存储在代码执行期间创建的所有执行上下文。
规则如下:
以一段代码具体说明:
function fun3() {
console.log('fun3')
}
function fun2() {
fun3();
}
function fun1() {
fun2();
}
fun1();Global Execution Context (即全局执行上下文)首先入栈,过程如下:
伪代码:
//全局执行上下文首先入栈
ECStack.push(globalContext);
//执行fun1();
ECStack.push(<fun1> functionContext);
//fun1中又调用了fun2;
ECStack.push(<fun2> functionContext);
//fun2中又调用了fun3;
ECStack.push(<fun3> functionContext);
//fun3执行完毕
ECStack.pop();
//fun2执行完毕
ECStack.pop();
//fun1执行完毕
ECStack.pop();
//javascript继续顺序执行下面的代码,但ECStack底部始终有一个 全局上下文(globalContext);作用域链就是从当前作用域开始一层一层向上寻找某个变量,直到找到全局作用域还是没找到,就宣布放弃。这种一层一层的关系,就是作用域链。
如:
var a = 10;
function fn1() {
var b = 20;
console.log(fn2)
function fn2() {
a = 20
}
return fn2;
}
fn1()();fn2作用域链 = [fn2作用域, fn1作用域,全局作用域]
BFC 是 Block Formatting Context 的缩写,即块格式化上下文。我们来看一下CSS2.1规范中对 BFC 的说明。
Floats, absolutely positioned elements, block containers (such as inline-blocks, table-cells, and table-captions) that are not block boxes, and block boxes with 'overflow' other than 'visible' (except when that value has been propagated to the viewport) establish new block formatting contexts for their contents.
浮动、绝对定位的元素、非块级盒子的块容器(如inline-blocks、table-cells 和 table-captions),以及
overflow的值不为visible(该值已传播到视区时除外)为其内容建立新的块格式上下文。
因此,如果想要深入的理解BFC,我们需要了解以下两个概念:
1.Box
2.Formatting Context
Box 是 CSS 布局的对象和基本单位,页面是由若干个Box组成的。
元素的类型 和 display 属性,决定了这个 Box 的类型。不同类型的 Box 会参与不同的 Formatting Context。
Formatting Context 是页面的一块渲染区域,并且有一套渲染规则,决定了其子元素将如何定位,以及和其它元素的关系和相互作用。
Formatting Context 有 BFC (Block formatting context),IFC (Inline formatting context),FFC (Flex formatting context) 和 GFC (Grid formatting context)。FFC 和 GFC 为 CC3 中新增。
margin 属性决定。属于同一个BFC的两个相邻Box的margin会发生重叠【符合合并原则的margin合并后是使用大的margin】1.防止 margin 重叠
<style>
.a{
height: 100px;
width: 100px;
margin: 50px;
background: pink;
}
</style>
<body>
<div class="a"></div>
<div class="a"></div>
</body>两个div直接的 margin 是50px,发生了 margin 的重叠。
根据BFC规则,同一个BFC内的两个两个相邻Box的
margin会发生重叠,因此我们可以在div外面再嵌套一层容器,并且触发该容器生成一个 BFC,这样<div class="a"></div>就会属于两个 BFC,自然也就不会再发生margin重叠
<style>
.a{
height: 100px;
width: 100px;
margin: 50px;
background: pink;
}
.container{
overflow: auto; /*触发生成BFC*/
}
</style>
<body>
<div class="container">
<div class="a"></div>
</div>
<div class="a"></div>
</body>2.清除内部浮动
<style>
.a{
height: 100px;
width: 100px;
margin: 10px;
background: pink;
float: left;
}
.container{
width: 120px;
border: 2px solid black;
}
</style>
<body>
<div class="container">
<div class="a"></div>
</div>
</body>container 的高度没有被撑开,如果我们希望 container 的高度能够包含浮动元素,那么可以创建一个新的 BFC,因为根据 BFC 的规则,计算 BFC 的高度时,浮动元素也参与计算。
<style>
.a{
height: 100px;
width: 100px;
margin: 10px;
background: pink;
float: left;
}
.container{
width: 120px;
display: inline-block;/*触发生成BFC*/
border: 2px solid black;
}
</style>3.自适应多栏布局
<style>
body{
width: 500px;
}
.a{
height: 150px;
width: 100px;
background: pink;
float: left;
}
.b{
height: 200px;
background: blue;
}
</style>
<body>
<div class="a"></div>
<div class="b"></div>
</body> 根据规则,BFC的区域不会与float box重叠。因此,可以触发生成一个新的BFC,如下:
<style>
.b{
height: 200px;
overflow: hidden; /*触发生成BFC*/
background: blue;
}
</style>| 声明方式 | 变量提升 | 暂时性死区 | 重复声明 | 块作用域有效 | 初始值 | 重新赋值 |
|---|---|---|---|---|---|---|
| var | 会 | 不存在 | 允许 | 不是 | 非必须 | 允许 |
| let | 不会 | 存在 | 不允许 | 是 | 非必须 | 允许 |
| const | 不会 | 存在 | 不允许 | 是 | 必须 | 不允许 |
a = 10;
var a; //正常a = 10;
let a; //ReferenceErrorlet a = 10;
var a = 20;
//抛出异常:SyntaxError: Identifier 'a' has already been declaredconst a;//SyntaxError: Missing initializer in const declaration这里有一个非常重要的点即是:复杂数据类型,存储在栈中的是堆内存的地址,存在栈中的这个地址是不变的,但是存在堆中的值是可以变得。有没有相当常量指针/指针常量~
const a = 20;
const b = {
age: 18,
star: 500
}一图胜万言,如下图所示,不变的是栈内存中 a 存储的 20,和 b 中存储的 0x0012ff21(瞎编的一个数字)。而 {age: 18, star: 200} 是可变的。思考下如果想希望一个对象是不可变的,应该用什么方法?
{
let a = 10;
const b = 20;
var c = 30;
}
console.log(a); //ReferenceError
console.log(b); //ReferenceError
console.log(c); //30在 let/const 之前,最早学习JS的时候,也曾被下面这个问题困扰:
期望: a[0]() 输出 0 , a[1]() 输出 1 , a[2]() 输出 2 , ...
var a = [];
for (var i = 0; i < 10; i++) {
a[i] = function () {
console.log(i);
};
}
a[6](); // 10虽然后来知道了为什么,但是想要得到自己需要的结果,还得整个闭包,我...我做错了什么,要这么对我...
var a = [];
for (var i = 0; i < 10; i++) {
a[i] = (function(j){
return function () {
console.log(j);
}
})(i)
}
a[6](); // 6有了 let 之后,终于不要这么麻烦了。
var a = [];
for (let i = 0; i < 10; i++) {
a[i] = function () {
console.log(i);
};
}
a[6](); // 6美滋滋,有没有~
美是美了,但是总得问自己为什么吧~
var i 为什么输出的是 10,这是因为 i 在全局范围内都是有效的,相当于只有一个变量 i,等执行到 a[6]() 的时候,这个 i 的值是什么?请大声说出来。
再看 let , 我们说 let 声明的变量仅在块级作用域内有效,变量i是let声明的,当前的 i 只在本轮循环有效,所以每一次循环的 i 其实都是一个新的变量。有兴趣的小伙伴可以查看 babel 编译后的代码。
var a = 10;
console.log(window.a);//10只要块级作用域内存在let命令,它所声明的变量就“绑定”(binding)这个区域,不再受外部的影响。
var a = 10;
if (true) {
a = 20; // ReferenceError
let a;
}在代码块内,使用 let/const 命令声明变量之前,该变量都是不可用的,也就意味着 typeof 不再是一个百分百安全的操作。
console.log(typeof b);//undefined
console.log(a); //ReferenceError
let a = 10;深拷贝和浅拷贝是针对复杂数据类型来说的。
深拷贝复制变量值,对于非基本类型的变量,则递归至基本类型变量后,再复制。 深拷贝后的对象与原来的对象是完全隔离的,互不影响,对一个对象的修改并不会影响另一个对象。
浅拷贝是会将对象的每个属性进行依次复制,但是当对象的属性值是引用类型时,实质复制的是其引用,当引用指向的值改变时也会跟着变化。
可以使用 for in、 Object.assign、 扩展运算符 ... 、Array.prototype.slice()、Array.prototype.concat() 等,例如:
let obj = {
name: 'Yvette',
age: 18,
hobbies: ['reading', 'photography']
}
let obj2 = Object.assign({}, obj);
let obj3 = {...obj};
obj.name = 'Jack';
obj.hobbies.push('coding');
console.log(obj);//{ name: 'Jack', age: 18,hobbies: [ 'reading', 'photography', 'coding' ] }
console.log(obj2);//{ name: 'Yvette', age: 18,hobbies: [ 'reading', 'photography', 'coding' ] }
console.log(obj3);//{ name: 'Yvette', age: 18,hobbies: [ 'reading', 'photography', 'coding' ] }可以看出浅拷贝只最第一层属性进行了拷贝,当第一层的属性值是基本数据类型时,新的对象和原对象互不影响,但是如果第一层的属性值是复杂数据类型,那么新对象和原对象的属性值其指向的是同一块内存地址。来看一下使用 for in 实现浅拷贝。
let obj = {
name: 'Yvette',
age: 18,
hobbies: ['reading', 'photography']
}
let newObj = {};
for(let key in obj){
newObj[key] = obj[key];
//这一步不需要多说吧,复杂数据类型栈中存的是对应的地址,因此赋值操作,相当于两个属性值指向同一个内存空间
}
console.log(newObj);
//{ name: 'Yvette', age: 18, hobbies: [ 'reading', 'photography' ] }
obj.age = 20;
obj.hobbies.pop();
console.log(newObj);
//{ name: 'Yvette', age: 18, hobbies: [ 'reading' ] }1.深拷贝最简单的实现是:
JSON.parse(JSON.stringify(obj))
let obj = {
name: 'Yvette',
age: 18,
hobbies: ['reading', 'photography']
}
let newObj = JSON.parse(JSON.stringify(obj));//newObj和obj互不影响
obj.hobbies.push('coding');
console.log(newObj);//{ name: 'Yvette', age: 18, hobbies: [ 'reading', 'photography' ] }JSON.parse(JSON.stringify(obj)) 是最简单的实现方式,但是有一点缺陷:
1.对象的属性值是函数时,无法拷贝。
let obj = {
name: 'Yvette',
age: 18,
hobbies: ['reading', 'photography'],
sayHi: function() {
console.log(sayHi);
}
}
let newObj = JSON.parse(JSON.stringify(obj));
console.log(newObj);//{ name: 'Yvette', age: 18, hobbies: [ 'reading', 'photography' ] }2.原型链上的属性无法获取
function Super() {
}
Super.prototype.location = 'NanJing';
function Child(name, age, hobbies) {
this.name = name;
this.age = age;
}
Child.prototype = new Super();
let obj = new Child('Yvette', 18);
console.log(obj.location); //NanJing
let newObj = JSON.parse(JSON.stringify(obj));
console.log(newObj);//{ name: 'Yvette', age: 18}
console.log(newObj.location);//undefined;原型链上的属性无法获取3.不能正确的处理 Date 类型的数据
4.不能处理 RegExp
5.会忽略 symbol
6.会忽略 undefined
let obj = {
time: new Date(),
reg: /\d{3}/,
sym: Symbol(10),
name: undefined
}
let obj2 = JSON.parse(JSON.stringify(obj));
console.log(obj2); //{ time: '2019-06-02T08:16:44.625Z', reg: {} }2.实现一个 deepClone 函数
RegExp 或者 Date 类型,返回对应类型function deepClone(obj) { //递归拷贝
if(obj instanceof RegExp) return new RegExp(obj);
if(obj instanceof Date) return new Date(obj);
if(obj === null || typeof obj !== 'object') {
//如果不是复杂数据类型,直接返回
return obj;
}
/**
* 如果obj是数组,那么 obj.constructor 是 [Function: Array]
* 如果obj是对象,那么 obj.constructor 是 [Function: Object]
*/
let t = new obj.constructor();
for(let key in obj) {
//如果 obj[key] 是复杂数据类型,递归
if(obj.hasOwnProperty(key)){//是否是自身的属性
t[key] = deepClone(obj[key]);
}
}
return t;
}测试:
function Super() {
}
Super.prototype.location = 'NanJing';
function Child(name, age, hobbies) {
this.name = name;
this.age = age;
this.hobbies = hobbies;
}
Child.prototype = new Super();
let obj = new Child('Yvette', 18, ['reading', 'photography']);
obj.sayHi = function () {
console.log('hi');
}
console.log(obj.location); //NanJing
let newObj = deepClone(obj);
console.log(newObj);//
console.log(newObj.location);//NanJing 可以获取到原型链上的属性
newObj.sayHi();//hi 函数属性拷贝正常[1] https://www.ecma-international.org/ecma-262/6.0/#sec-completion-record-specification-type
[2] 【译】理解 Javascript 执行上下文和执行栈
[3] https://css-tricks.com/debouncing-throttling-explained-examples/
[5] https://www.cnblogs.com/coco1s/p/4017544.html
[6] https://www.cnblogs.com/wangfupeng1988/p/4000798.html
[7] https://www.w3.org/TR/2011/REC-CSS2-20110607/visuren.html#block-boxes
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。https://github.com/YvetteLau/Blog
关注公众号,加入技术交流群。
不积跬步无以至千里。
Step-By-Step (点击进入项目) 是我于 2019-05-20 开始的一个项目,项目愿景:一步一个脚印,量变引起质变。
Step-By-Step 仅会在工作日发布面试题,主要考虑到部分小伙伴平时工作较为繁忙,或周末有出游计划。每个周末我会仔细阅读大家的答案,整理最一份较优答案出来,因本人水平有限,有误的地方,大家及时指正。参与答题的小伙伴,可以对比自己的回答。
答题不是目的,不希望大家仅仅是简单的搜索答案,复制粘贴到issue下。更多的是希望大家及时查漏补缺 / 巩固相关知识。
已经过去的一周中,大家回答的都非常认真,希望小伙伴们能够一如既往的坚持。同样也欢迎更多的小伙伴一起参与进来,如果想 加群学习,扫码二维码 (点击查看),添加我为好友,验证信息为加入组织,我拉你进群。
如果用一句话说明 this 的指向,那么即是: 谁调用它,this 就指向谁。
但是仅通过这句话,我们很多时候并不能准确判断 this 的指向。因此我们需要借助一些规则去帮助自己:
this 的指向可以按照以下顺序判断:
浏览器环境:无论是否在严格模式下,在全局执行环境中(在任何函数体外部)this 都指向全局对象 window;
node 环境:无论是否在严格模式下,在全局执行环境中(在任何函数体外部),this 都是空对象 {};
new 绑定如果是 new 绑定,并且构造函数中没有返回 function 或者是 object,那么 this 指向这个新对象。如下:
构造函数返回值不是 function 或 object。
function Super(age) {
this.age = age;
}
let instance = new Super('26');
console.log(instance.age); //26构造函数返回值是 function 或 object,这种情况下 this 指向的是返回的对象。
function Super(age) {
this.age = age;
let obj = {a: '2'};
return obj;
}
let instance = new Super('hello');
console.log(instance.age); //undefined你可以想知道为什么会这样?我们来看一下 new 的实现原理:
[[原型]] 连接。function new(func) {
let target = {};
target.__proto__ = func.prototype;
let res = func.call(target);
//排除 null 的情况
if (res && typeof(res) == "object" || typeof(res) == "function") {
return res;
}
return target;
}function info(){
console.log(this.age);
}
var person = {
age: 20,
info
}
var age = 28;
var info = person.info;
info.call(person); //20
info.apply(person); //20
info.bind(person)(); //20这里同样需要注意一种特殊情况,如果 call,apply 或者 bind 传入的第一个参数值是 undefined 或者 null,严格模式下 this 的值为传入的值 null /undefined。非严格模式下,实际应用的默认绑定规则,this 指向全局对象(node环境为global,浏览器环境为window)
function info(){
//node环境中:非严格模式 global,严格模式为null
//浏览器环境中:非严格模式 window,严格模式为null
console.log(this);
console.log(this.age);
}
var person = {
age: 20,
info
}
var age = 28;
var info = person.info;
//严格模式抛出错误;
//非严格模式,node下输出undefined(因为全局的age不会挂在 global 上)
//非严格模式。浏览器环境下输出 28(因为全局的age会挂在 window 上)
info.call(null);xxx.fn()function info(){
console.log(this.age);
}
var person = {
age: 20,
info
}
var age = 28;
person.info(); //20;执行的是隐式绑定非严格模式: node环境,执行全局对象 global,浏览器环境,执行全局对象 window。
严格模式:执行 undefined
function info(){
console.log(this.age);
}
var age = 28;
//严格模式;抛错
//非严格模式,node下输出 undefined(因为全局的age不会挂在 global 上)
//非严格模式。浏览器环境下输出 28(因为全局的age会挂在 window 上)
//严格模式抛出,因为 this 此时是 undefined
info(); 箭头函数没有自己的this,继承外层上下文绑定的this。
let obj = {
age: 20,
info: function() {
return () => {
console.log(this.age); //this继承的是外层上下文绑定的this
}
}
}
let person = {age: 28};
let info = obj.info();
info(); //20
let info2 = obj.info.call(person);
info2(); //28ES10新增了一种基本数据类型:BigInt
复杂数据类型只有一种: Object
null 不是一个对象,尽管 typeof null 输出的是 object,这是一个历史遗留问题,JS 的最初版本中使用的是 32 位系统,为了性能考虑使用低位存储变量的类型信息,000 开头代表是对象,null 表示为全零,所以将它错误的判断为 object 。
基本数据类型存储在栈中。
复杂数据类型存储在堆中,栈中存储的变量,是指向堆中的引用地址。
let b = {
age: 10
}
let a = b;
a.age = 20;
console.log(a); //{ age: 20 }函数传参都是按值传递(栈中的存储的内容):基本数据类型,拷贝的是值;复杂数据类型,拷贝的是引用地址
//基本数据类型
let b = 10
function change(info) {
info=20;
}
//info=b;基本数据类型,拷贝的是值得副本,二者互不干扰
change(b);
console.log(b);//10//复杂数据类型
let b = {
age: 10
}
function change(info) {
info.age = 20;
}
//info=b;根据第三条差异,可以看出,拷贝的是地址的引用,修改互相影响。
change(b);
console.log(b);//{ age: 20 }语义化意味着顾名思义,HTML5的语义化指的是合理正确的使用语义化的标签来创建页面结构,如 header,footer,nav,从标签上即可以直观的知道这个标签的作用,而不是滥用div。
<aside> 的内容可用作文章的侧栏。例如使用这些可视化标签,构建下面的页面结构:
对于早期不支持 HTML5 的浏览器,如IE8及更早之前的版本,我们可以引入 html5shiv 来支持。
== 操作符在左右数据类型不一致时,会先进行隐式转换。
a == 1 && a == 2 && a == 3 的值意味着其不可能是基本数据类型。因为如果 a 是 null 或者是 undefined bool类型,都不可能返回true。
因此可以推测 a 是复杂数据类型,JS 中复杂数据类型只有 object,回忆一下,Object 转换为原始类型会调用什么方法?
如果部署了 [Symbol.toPrimitive] 接口,那么调用此接口,若返回的不是基本数据类型,抛出错误。
如果没有部署 [Symbol.toPrimitive] 接口,那么根据要转换的类型,先调用 valueOf / toString
hint 是 default 时,调用顺序为:valueOf >>> toString,即valueOf 返回的不是基本数据类型,才会继续调用 toString,如果toString 返回的还不是基本数据类型,那么抛出错误。hint 是 string(Date对象的hint默认是string) ,调用顺序为:toString >>> valueOf,即toString 返回的不是基本数据类型,才会继续调用 valueOf,如果valueOf 返回的还不是基本数据类型,那么抛出错误。hint 是 number,调用顺序为: valueOf >>> toStringvar obj = {
[Symbol.toPrimitive](hint) {
console.log(hint);
return 10;
},
valueOf() {
console.log('valueOf');
return 20;
},
toString() {
console.log('toString');
return 'hello';
}
}
console.log(obj + 'yvette'); //default
//如果没有部署 [Symbol.toPrimitive]接口,调用顺序为`valueOf` >>> `toString`
console.log(obj == 'yvette'); //default
//如果没有部署 [Symbol.toPrimitive]接口,调用顺序为`valueOf` >>> `toString`
console.log(obj * 10);//number
//如果没有部署 [Symbol.toPrimitive]接口,调用顺序为`valueOf` >>> `toString`
console.log(Number(obj));//number
//如果没有部署 [Symbol.toPrimitive]接口,调用顺序为`valueOf` >>> `toString`
console.log(String(obj));//string
//如果没有部署 [Symbol.toPrimitive]接口,调用顺序为`toString` >>> `valueOf`那么对于这道题,只要 [Symbol.toPrimitive] 接口,第一次返回的值是 1,然后递增,即成功成立。
let a = {
[Symbol.toPrimitive]: (function(hint) {
let i = 1;
//闭包的特性之一:i 不会被回收
return function() {
return i++;
}
})()
}
console.log(a == 1 && a == 2 && a == 3); //true调用 valueOf 接口的情况:
let a = {
valueOf: (function() {
let i = 1;
//闭包的特性之一:i 不会被回收
return function() {
return i++;
}
})()
}
console.log(a == 1 && a == 2 && a == 3); //true另外,除了i自增的方法外,还可以利用 正则,如下
let a = {
reg: /\d/g,
valueOf () {
return this.reg.exec(123)[0]
}
}
console.log(a == 1 && a == 2 && a == 3); //true调用 toString 接口的情况,不再做说明。
使用 Object.defineProperty 定义的属性,在获取属性时,会调用 get 方法。利用这个特性,我们在 window 对象上定义 a 属性,如下:
let i = 1;
Object.defineProperty(window, 'a', {
get: function() {
return i++;
}
});
console.log(a == 1 && a == 2 && a == 3); //trueES6 新增了 Proxy ,此处我们同样可以利用 Proxy 去实现,如下:
let a = new Proxy({}, {
i: 1,
get: function () {
return () => this.i++;
}
});
console.log(a == 1 && a == 2 && a == 3); // truetoString 接口默认调用数组的 join 方法,重写数组的 join 方法。let a = [1, 2, 3];
a.join = a.shift;
console.log(a == 1 && a == 2 && a == 3); //truewith 关键字我本人对 with 向来是敬而远之的。不过 with 的确也是此题方法之一:
let i = 0;
with ({
get a() {
return ++i;
}
}) {
console.log(a == 1 && a == 2 && a == 3); //true
}防抖函数的作用就是控制函数在一定时间内的执行次数。防抖意味着N秒内函数只会被执行一次,如果N秒内再次被触发,则重新计算延迟时间。
举例说明:小思最近在减肥,但是她非常贪吃。为此,与其男朋友约定好,如果10天不吃零食,就可以购买一个包(不要问为什么是包,因为包治百病)。但是如果中间吃了一次零食,那么就要重新计算时间,直到小思坚持10天没有吃零食,才能购买一个包。所以,管不住嘴的小思,没有机会买包(悲伤的故事)...这就是防抖。
不管吃没吃零食,每10天买一个包,中间想买包,忍着,等到第十天的时候再买,这种情况是节流。如何控制女朋友的消费,各位攻城狮们,get到了吗?防抖可比节流有效多了!
immediate 为 true 时,表示开始会立即触发一次。
immediate 为 false 时,表示最后一次一定会触发。
loadsh 中的 debounce 的第三个参数 option ,提供了 leading 和 trailing 两个参数。
function debounce(func, wait, immediate=true) {
let timeout, context, args;
// 延迟执行函数
const later = () => setTimeout(() => {
// 延迟函数执行完毕,清空定时器
timeout = null
// 延迟执行的情况下,函数会在延迟函数中执行
// 使用到之前缓存的参数和上下文
if (!immediate) {
func.apply(context, args);
context = args = null;
}
}, wait);
let debounced = function (...params) {
if (!timeout) {
timeout = later();
if (immediate) {
//立即执行
func.apply(this, params);
} else {
//闭包
context = this;
args = params;
}
} else {
clearTimeout(timeout);
timeout = later();
}
}
debounced.cancel = function () {
clearTimeout(timeout);
timeout = null;
};
return debounced;
};参考文章:
[1] https://www.ecma-international.org/ecma-262/6.0/#sec-completion-record-specification-type
[2] 嗨,你真的懂this吗?
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。https://github.com/YvetteLau/Blog
关注公众号,加入交流群。
不积跬步无以至千里。
Step-By-Step (点击进入项目) 是我于
2019-05-20开始的一个项目,每个工作日发布一道面试题。每个周末我会仔细阅读大家的答案,整理最一份较优答案出来,因本人水平有限,有误的地方,大家及时指正。
如果想 加群 学习,可以通过文末的公众号,添加我为好友。
本周面试题一览:
JSON.stringifyJSON.stringify([, replacer [, space]) 方法是将一个JavaScript值(对象或者数组)转换为一个 JSON字符串。此处模拟实现,不考虑可选的第二个参数 replacer 和第三个参数 space,如果对这两个参数的作用还不了解,建议阅读 MDN 文档。
JSON.stringify()将值转换成对应的JSON格式:
基本数据类型:
undefined)"false"/"true"NaN 和 Infinity)转换之后是字符串类型的数值undefined"null"NaN 和 Infinity 转换之后是字符串 "null"如果是函数类型
undefined如果是对象类型(非函数)
如果有 toJSON() 方法,那么序列化 toJSON() 的返回值。
如果是一个数组
undefined、任意的函数以及 symbol,转换成字符串 "null"如果是 RegExp 对象。
返回 {} (类型是 string)
如果是 Date 对象,返回 Date 的 toJSON 字符串值
如果是普通对象;
undefined、任意的函数以及 symbol 值,忽略。symbol 为属性键的属性都会被完全忽略掉。对包含循环引用的对象(对象之间相互引用,形成无限循环)执行此方法,会抛出错误。
模拟实现
function jsonStringify(data) {
let dataType = typeof data;
if (dataType !== 'object') {
let result = data;
//data 可能是 string/number/null/undefined/boolean
if (Number.isNaN(data) || data === Infinity) {
//NaN 和 Infinity 序列化返回 "null"
result = "null";
} else if (dataType === 'function' || dataType === 'undefined' || dataType === 'symbol') {
//function 、undefined 、symbol 序列化返回 undefined
return undefined;
} else if (dataType === 'string') {
result = '"' + data + '"';
}
//boolean 返回 String()
return String(result);
} else if (dataType === 'object') {
if (data === null) {
return "null";
} else if (data.toJSON && typeof data.toJSON === 'function') {
return jsonStringify(data.toJSON());
} else if (data instanceof Array) {
let result = [];
//如果是数组
//toJSON 方法可以存在于原型链中
data.forEach((item, index) => {
if (typeof item === 'undefined' || typeof item === 'function' || typeof item === 'symbol') {
result[index] = "null";
} else {
result[index] = jsonStringify(item);
}
});
result = "[" + result + "]";
return result.replace(/'/g, '"');
} else {
//普通对象
/**
* 循环引用抛错(暂未检测,循环引用时,堆栈溢出)
* symbol key 忽略
* undefined、函数、symbol 为属性值,被忽略
*/
let result = [];
Object.keys(data).forEach((item, index) => {
if (typeof item !== 'symbol') {
//key 如果是symbol对象,忽略
if (data[item] !== undefined && typeof data[item] !== 'function'
&& typeof data[item] !== 'symbol') {
//键值如果是 undefined、函数、symbol 为属性值,忽略
result.push('"' + item + '"' + ":" + jsonStringify(data[item]));
}
}
});
return ("{" + result + "}").replace(/'/g, '"');
}
}
}测试代码:
let sym = Symbol(10);
console.log(jsonStringify(sym) === JSON.stringify(sym));
let nul = null;
console.log(jsonStringify(nul) === JSON.stringify(nul));
let und = undefined;
console.log(jsonStringify(undefined) === JSON.stringify(undefined));
let boo = false;
console.log(jsonStringify(boo) === JSON.stringify(boo));
let nan = NaN;
console.log(jsonStringify(nan) === JSON.stringify(nan));
let inf = Infinity;
console.log(jsonStringify(Infinity) === JSON.stringify(Infinity));
let str = "hello";
console.log(jsonStringify(str) === JSON.stringify(str));
let reg = new RegExp("\w");
console.log(jsonStringify(reg) === JSON.stringify(reg));
let date = new Date();
console.log(jsonStringify(date) === JSON.stringify(date));
let obj = {
name: '刘小夕',
age: 22,
hobbie: ['coding', 'writing'],
date: new Date(),
unq: Symbol(10),
sayHello: function () {
console.log("hello")
},
more: {
brother: 'Star',
age: 20,
hobbie: [null],
info: {
money: undefined,
job: null,
others: []
}
}
}
console.log(jsonStringify(obj) === JSON.stringify(obj));
function SuperType(name, age) {
this.name = name;
this.age = age;
}
let per = new SuperType('小姐姐', 20);
console.log(jsonStringify(per) === JSON.stringify(per));
function SubType(info) {
this.info = info;
}
SubType.prototype.toJSON = function () {
return {
name: '钱钱钱',
mount: 'many',
say: function () {
console.log('我偏不说!');
},
more: null,
reg: new RegExp("\w")
}
}
let sub = new SubType('hi');
console.log(jsonStringify(sub) === JSON.stringify(sub));
let map = new Map();
map.set('name', '小姐姐');
console.log(jsonStringify(map) === JSON.stringify(map));
let set = new Set([1, 2, 3, 4, 5, 1, 2, 3]);
console.log(jsonStringify(set) === JSON.stringify(set));JSON.parseJSON.parse(JSON.parse(text[, reviver]) 方法用来解析JSON字符串,构造由字符串描述的JavaScript值或对象。提供可选的reviver函数用以在返回之前对所得到的对象执行变换。此处模拟实现,不考虑可选的第二个参数 reviver ,如果对这个参数的作用还不了解,建议阅读 MDN 文档。
最简单,最直观的方式就是调用 eval
var json = '{"name":"小姐姐", "age":20}';
var obj = eval("(" + json + ")"); // obj 就是 json 反序列化之后得到的对象直接调用 eval 存在 XSS 漏洞,数据中可能不是 json 数据,而是可执行的 JavaScript 代码。因此,在调用 eval 之前,需要对数据进行校验。
var rx_one = /^[\],:{}\s]*$/;
var rx_two = /\\(?:["\\\/bfnrt]|u[0-9a-fA-F]{4})/g;
var rx_three = /"[^"\\\n\r]*"|true|false|null|-?\d+(?:\.\d*)?(?:[eE][+\-]?\d+)?/g;
var rx_four = /(?:^|:|,)(?:\s*\[)+/g;
if (
rx_one.test(
json
.replace(rx_two, "@")
.replace(rx_three, "]")
.replace(rx_four, "")
)
) {
var obj = eval("(" +json + ")");
}JSON 是 JS 的子集,可以直接交给 eval 运行。
new FunctionFunction 与 eval 有相同的字符串参数特性。
var json = '{"name":"小姐姐", "age":20}';
var obj = (new Function('return ' + json))();观察者模式定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知,并自动更新。观察者模式属于行为型模式,行为型模式关注的是对象之间的通讯,观察者模式就是观察者和被观察者之间的通讯。
观察者(Observer)直接订阅(Subscribe)主题(Subject),而当主题被激活的时候,会触发(Fire Event)观察者里的事件。
//有一家猎人工会,其中每个猎人都具有发布任务(publish),订阅任务(subscribe)的功能
//他们都有一个订阅列表来记录谁订阅了自己
//定义一个猎人类
//包括姓名,级别,订阅列表
function Hunter(name, level){
this.name = name
this.level = level
this.list = []
}
Hunter.prototype.publish = function (money){
console.log(this.level + '猎人' + this.name + '寻求帮助')
this.list.forEach(function(item, index){
item(money)
})
}
Hunter.prototype.subscribe = function (targrt, fn){
console.log(this.level + '猎人' + this.name + '订阅了' + targrt.name)
targrt.list.push(fn)
}
//猎人工会走来了几个猎人
let hunterMing = new Hunter('小明', '黄金')
let hunterJin = new Hunter('小金', '白银')
let hunterZhang = new Hunter('小张', '黄金')
let hunterPeter = new Hunter('Peter', '青铜')
//Peter等级较低,可能需要帮助,所以小明,小金,小张都订阅了Peter
hunterMing.subscribe(hunterPeter, function(money){
console.log('小明表示:' + (money > 200 ? '' : '暂时很忙,不能') + '给予帮助')
});
hunterJin.subscribe(hunterPeter, function(){
console.log('小金表示:给予帮助')
});
hunterZhang.subscribe(hunterPeter, function(){
console.log('小张表示:给予帮助')
});
//Peter遇到困难,赏金198寻求帮助
hunterPeter.publish(198);
//猎人们(观察者)关联他们感兴趣的猎人(目标对象),如Peter,当Peter有困难时,会自动通知给他们(观察者)父元素 .container
子元素 .box
flex 布局/* 无需知道被居中元素的宽高 */
.container {
display: flex;
align-items: center;
justify-content: center;
}设置父元素的 text-align 和 line-height = height
.container {
height: 100px;
line-height: 100px;
text-align: center;
}absolute + transform/* 无需知道被居中元素的宽高 */
/* 设置父元素非 `static` 定位 */
.container {
position: relative;
}
/* 子元素绝对定位,使用 translate的好处是无需知道子元素的宽高 */
/* 如果知道宽高,也可以使用 margin 设置 */
.box {
position: absolute;
left: -50%;
top: -50%;
transform: translate(-50%, -50%);
}grid 布局/* 无需知道被居中元素的宽高 */
.container {
display: grid;
}
.box {
justify-self: center;
align-self: center;
}margin:auto/* 无需知道被居中元素的宽高 */
.box {
position: absolute;
left: 0;
top: 0;
right: 0;
bottom: 0;
margin: auto;
}
.container {
position: relative;
}CommonJS 模块有哪些差异?CommonJS 模块是运行时加载,ES6模块是编译时输出接口。CommonJS 加载的是一个对象,该对象只有在脚本运行完才会生成。CommonJS 模块输出的是一个值的拷贝,ES6模块输出的是值的引用。- `CommonJS` 输出的是一个值的拷贝(注意基本数据类型/复杂数据类型)
- ES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
CommonJS 模块输出的是值的拷贝。
模块输出的值是基本数据类型,模块内部的变化就影响不到这个值。
//name.js
let name = 'William';
setTimeout(() => { name = 'Yvette'; }, 300);
module.exports = name;
//index.js
const name = require('./name');
console.log(name); //William
//name.js 模块加载后,它的内部变化就影响不到 name
//name 是一个基本数据类型。将其复制出一份之后,二者之间互不影响。
setTimeout(() => console.log(name), 500); //William模块输出的值是复杂数据类型
//name.js
let name = 'William';
setTimeout(() => { name = 'Yvette'; }, 300);
module.exports = { name };
//index.js
const { name } = require('./name');
console.log(name); //William
//name 是一个原始类型的值,会被缓存。
setTimeout(() => console.log(name), 500); //William模块输出的是对象:
//name.js
let name = 'William';
let hobbies = ['coding'];
setTimeout(() => {
name = 'Yvette';
hobbies.push('reading');
}, 300);
module.exports = { name, hobbies };
//index.js
const { name, hobbies } = require('./name');
console.log(name); //William
console.log(hobbies); //['coding']
/*
* name 的值没有受到影响,因为 {name: name} 属性值 name 存的是个字符串
* 300ms后 name 变量重新赋值,但是不会影响 {name: name}
*
* hobbies 的值会被影响,因为 {hobbies: hobbies} 属性值 hobbies 中存的是
* 数组的堆内存地址,因此当 hobbies 对象的值被改变时,存在栈内存中的地址并
没有发生变化,因此 hoobies 对象值的改变会影响 {hobbies: hobbies}
* xx = { name, hobbies } 也因此改变 (复杂数据类型,拷贝的栈内存中存的地址)
*/
setTimeout(() => {
console.log(name);//William
console.log(hobbies);//['coding', 'reading']
}, 500);ES6 模块的运行机制与 CommonJS 不一样。JS 引擎对脚本静态分析的时候,遇到模块加载命令 import ,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。
//name.js
let name = 'William';
setTimeout(() => { name = 'Yvette'; hobbies.push('writing'); }, 300);
export { name };
export var hobbies = ['coding'];
//index.js
import { name, hobbies } from './name';
console.log(name, hobbies); //William ["coding"]
//name 和 hobbie 都会被模块内部的变化所影响
setTimeout(() => {
console.log(name, hobbies); //Yvette ["coding", "writing"]
}, 500); //YvetteES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。因此上面的例子也很容易理解。
那么 export default 导出是什么情况呢?
//name.js
let name = 'William';
let hobbies = ['coding']
setTimeout(() => { name = 'Yvette'; hobbies.push('writing'); }, 300);
export default { name, hobbies };
//index.js
import info from './name';
console.log(info.name, info.hobbies); //William ["coding"]
//name 不会被模块内部的变化所影响
//hobbie 会被模块内部的变化所影响
setTimeout(() => {
console.log(info.name, info.hobbies); //William ["coding", "writing"]
}, 500); //Yvette一起看一下为什么。
export default 可以理解为将变量赋值给 default,最后导出 default (仅是方便理解,不代表最终的实现,如果对这块感兴趣,可以阅读 webpack 编译出来的代码)。
基础类型变量 name, 赋值给 default 之后,只读引用与 default 关联,此时原变量 name 的任何修改都与 default 无关。
复杂数据类型变量 hobbies,赋值给 default之后,只读引用与 default 关联,default 和 hobbies 中存储的是同一个对象的堆内存地址,当这个对象的值发生改变时,此时 default 的值也会发生变化。
"use strict";import 语句做不到,import 语句必须位于顶层作用域中。import name from './name';
name = 'Star'; //抛错[1] 珠峰架构课(墙裂推荐)
[2] JSON.parse三种实现方式
[3] ES6 文档
[4] JSON-js
[5] CommonJS模块和ES6模块的区别
[6] 发布订阅模式与观察者模式
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。 https://github.com/YvetteLau/Blog
关注公众号,加入技术交流群。
今年来,各大公司都缩减了HC,甚至是采取了“裁员”措施,在这样的大环境之下,想要获得一份更好的工作,必然需要付出更多的努力。
本文挑选了20到大厂面试题,大家在阅读时,建议不要先看我的答案,而是自己先思考一番。尽管,本文所有的答案,都是我在翻阅各种资料,思考并验证之后,才给出的。但因水平有限,本人的答案未必是最优的,如果您有更好的答案,欢迎给我留言。
本文篇幅较长,希望小伙伴们能够坚持读完,如果想加入交流群,可以通过文末的公众号添加我为好友。
new 的实现原理:
function _new() {
let target = {}; //创建的新对象
//第一个参数是构造函数
let [constructor, ...args] = [...arguments];
//执行[[原型]]连接;target 是 constructor 的实例
target.__proto__ = constructor.prototype;
//执行构造函数,将属性或方法添加到创建的空对象上
let result = constructor.apply(target, args);
if (result && (typeof (result) == "object" || typeof (result) == "function")) {
//如果构造函数执行的结构返回的是一个对象,那么返回这个对象
return result;
}
//如果构造函数返回的不是一个对象,返回创建的新对象
return target;
}如果用一句话说明 this 的指向,那么即是: 谁调用它,this 就指向谁。
但是仅通过这句话,我们很多时候并不能准确判断 this 的指向。因此我们需要借助一些规则去帮助自己:
this 的指向可以按照以下顺序判断:
浏览器环境:无论是否在严格模式下,在全局执行环境中(在任何函数体外部)this 都指向全局对象 window;
node 环境:无论是否在严格模式下,在全局执行环境中(在任何函数体外部),this 都是空对象 {};
new 绑定如果是 new 绑定,并且构造函数中没有返回 function 或者是 object,那么 this 指向这个新对象。如下:
构造函数返回值不是 function 或 object。
new Super()返回的是 this 对象。
function Super(age) {
this.age = age;
}
let instance = new Super('26');
console.log(instance.age); //26构造函数返回值是 function 或 object,
new Super()是返回的是Super种返回的对象。
function Super(age) {
this.age = age;
let obj = {a: '2'};
return obj;
}
let instance = new Super('hello');
console.log(instance);//{ a: '2' }
console.log(instance.age); //undefinedfunction info(){
console.log(this.age);
}
var person = {
age: 20,
info
}
var age = 28;
var info = person.info;
info.call(person); //20
info.apply(person); //20
info.bind(person)(); //20这里同样需要注意一种特殊情况,如果 call,apply 或者 bind 传入的第一个参数值是 undefined 或者 null,严格模式下 this 的值为传入的值 null /undefined。非严格模式下,实际应用的默认绑定规则,this 指向全局对象(node环境为global,浏览器环境为window)
function info(){
//node环境中:非严格模式 global,严格模式为null
//浏览器环境中:非严格模式 window,严格模式为null
console.log(this);
console.log(this.age);
}
var person = {
age: 20,
info
}
var age = 28;
var info = person.info;
//严格模式抛出错误;
//非严格模式,node下输出undefined(因为全局的age不会挂在 global 上)
//非严格模式。浏览器环境下输出 28(因为全局的age会挂在 window 上)
info.call(null);xxx.fn()function info(){
console.log(this.age);
}
var person = {
age: 20,
info
}
var age = 28;
person.info(); //20;执行的是隐式绑定非严格模式: node环境,执行全局对象 global,浏览器环境,执行全局对象 window。
严格模式:执行 undefined
function info(){
console.log(this.age);
}
var age = 28;
//严格模式;抛错
//非严格模式,node下输出 undefined(因为全局的age不会挂在 global 上)
//非严格模式。浏览器环境下输出 28(因为全局的age会挂在 window 上)
//严格模式抛出,因为 this 此时是 undefined
info(); 箭头函数没有自己的this,继承外层上下文绑定的this。
let obj = {
age: 20,
info: function() {
return () => {
console.log(this.age); //this继承的是外层上下文绑定的this
}
}
}
let person = {age: 28};
let info = obj.info();
info(); //20
let info2 = obj.info.call(person);
info2(); //28深拷贝和浅拷贝是针对复杂数据类型来说的,浅拷贝只拷贝一层,而深拷贝是层层拷贝。
深拷贝复制变量值,对于非基本类型的变量,则递归至基本类型变量后,再复制。 深拷贝后的对象与原来的对象是完全隔离的,互不影响,对一个对象的修改并不会影响另一个对象。
浅拷贝是会将对象的每个属性进行依次复制,但是当对象的属性值是引用类型时,实质复制的是其引用,当引用指向的值改变时也会跟着变化。
可以使用 for in、 Object.assign、 扩展运算符 ... 、Array.prototype.slice()、Array.prototype.concat() 等,例如:
let obj = {
name: 'Yvette',
age: 18,
hobbies: ['reading', 'photography']
}
let obj2 = Object.assign({}, obj);
let obj3 = {...obj};
obj.name = 'Jack';
obj.hobbies.push('coding');
console.log(obj);//{ name: 'Jack', age: 18,hobbies: [ 'reading', 'photography', 'coding' ] }
console.log(obj2);//{ name: 'Yvette', age: 18,hobbies: [ 'reading', 'photography', 'coding' ] }
console.log(obj3);//{ name: 'Yvette', age: 18,hobbies: [ 'reading', 'photography', 'coding' ] }可以看出浅拷贝只最第一层属性进行了拷贝,当第一层的属性值是基本数据类型时,新的对象和原对象互不影响,但是如果第一层的属性值是复杂数据类型,那么新对象和原对象的属性值其指向的是同一块内存地址。
1.深拷贝最简单的实现是:
JSON.parse(JSON.stringify(obj))
JSON.parse(JSON.stringify(obj)) 是最简单的实现方式,但是有一些缺陷:
2.实现一个 deepClone 函数
RegExp 或者 Date 类型,返回对应类型function deepClone(obj, hash = new WeakMap()) { //递归拷贝
if (obj instanceof RegExp) return new RegExp(obj);
if (obj instanceof Date) return new Date(obj);
if (obj === null || typeof obj !== 'object') {
//如果不是复杂数据类型,直接返回
return obj;
}
if (hash.has(obj)) {
return hash.get(obj);
}
/**
* 如果obj是数组,那么 obj.constructor 是 [Function: Array]
* 如果obj是对象,那么 obj.constructor 是 [Function: Object]
*/
let t = new obj.constructor();
hash.set(obj, t);
for (let key in obj) {
//递归
if (obj.hasOwnProperty(key)) {//是否是自身的属性
t[key] = deepClone(obj[key], hash);
}
}
return t;
}call 和 apply 的功能相同,都是改变 this 的执行,并立即执行函数。区别在于传参方式不同。
func.call(thisArg, arg1, arg2, ...):第一个参数是 this 指向的对象,其它参数依次传入。
func.apply(thisArg, [argsArray]):第一个参数是 this 指向的对象,第二个参数是数组或类数组。
一起思考一下,如何模拟实现 call ?
首先,我们知道,函数都可以调用 call,说明 call 是函数原型上的方法,所有的实例都可以调用。即: Function.prototype.call。
call 方法中获取调用call()函数window / global(非严格模式)call 的第一个参数是 this 指向的对象,根据隐式绑定的规则,我们知道 obj.foo(), foo() 中的 this 指向 obj;因此我们可以这样调用函数 thisArgs.func(...args)Function.prototype.call = function() {
let [thisArg, ...args] = [...arguments];
if (!thisArg) {
//context为null或者是undefined
thisArg = typeof window === 'undefined' ? global : window;
}
//this的指向的是当前函数 func (func.call)
thisArg.func = this;
//执行函数
let result = thisArg.func(...args);
delete thisArg.func; //thisArg上并没有 func 属性,因此需要移除
return result;
}bind 的实现思路和 call 一致,仅参数处理略有差别。如下:
Function.prototype.apply = function(thisArg, rest) {
let result; //函数返回结果
if (!thisArg) {
//context为null或者是undefined
thisArg = typeof window === 'undefined' ? global : window;
}
//this的指向的是当前函数 func (func.call)
thisArg.func = this;
if(!rest) {
//第二个参数为 null / undefined
result = thisArg.func();
}else {
result = thisArg.func(...rest);
}
delete thisArg.func; //thisArg上并没有 func 属性,因此需要移除
return result;
}在开始之前,我们首先需要搞清楚函数柯里化的概念。
函数柯里化是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
const curry = (fn, ...args) =>
args.length < fn.length
//参数长度不足时,重新柯里化该函数,等待接受新参数
? (...arguments) => curry(fn, ...args, ...arguments)
//参数长度满足时,执行函数
: fn(...args);function sumFn(a, b, c) {
return a + b + c;
}
var sum = curry(sumFn);
console.log(sum(2)(3)(5));//10
console.log(sum(2, 3, 5));//10
console.log(sum(2)(3, 5));//10
console.log(sum(2, 3)(5));//10函数柯里化的主要作用:
- 利用隐式类型转换
== 操作符在左右数据类型不一致时,会先进行隐式转换。
a == 1 && a == 2 && a == 3 的值意味着其不可能是基本数据类型。因为如果 a 是 null 或者是 undefined bool类型,都不可能返回true。
因此可以推测 a 是复杂数据类型,JS 中复杂数据类型只有 object,回忆一下,Object 转换为原始类型会调用什么方法?
如果部署了 [Symbol.toPrimitive] 接口,那么调用此接口,若返回的不是基本数据类型,抛出错误。
如果没有部署 [Symbol.toPrimitive] 接口,那么根据要转换的类型,先调用 valueOf / toString
hint 是 default 时,调用顺序为:valueOf >>> toString,即valueOf 返回的不是基本数据类型,才会继续调用 valueOf,如果toString 返回的还不是基本数据类型,那么抛出错误。hint 是 string(Date对象的hint默认是string) ,调用顺序为:toString >>> valueOf,即toString 返回的不是基本数据类型,才会继续调用 valueOf,如果valueOf 返回的还不是基本数据类型,那么抛出错误。hint 是 number,调用顺序为: valueOf >>> toString//部署 [Symbol.toPrimitive] / valueOf/ toString 皆可
//一次返回1,2,3 即可。
let a = {
[Symbol.toPrimitive]: (function(hint) {
let i = 1;
//闭包的特性之一:i 不会被回收
return function() {
return i++;
}
})()
}
- 利用数据劫持(Proxy/Object.definedProperty)
let i = 1;
let a = new Proxy({}, {
i: 1,
get: function () {
return () => this.i++;
}
});
- 数组的
toString接口默认调用数组的join方法,重新join方法
let a = [1, 2, 3];
a.join = a.shift;Box 是 CSS 布局的对象和基本单位,页面是由若干个Box组成的。
元素的类型 和 display 属性,决定了这个 Box 的类型。不同类型的 Box 会参与不同的 Formatting Context。
Formatting Context
Formatting Context 是页面的一块渲染区域,并且有一套渲染规则,决定了其子元素将如何定位,以及和其它元素的关系和相互作用。
Formatting Context 有 BFC (Block formatting context),IFC (Inline formatting context),FFC (Flex formatting context) 和 GFC (Grid formatting context)。FFC 和 GFC 为 CC3 中新增。
margin 属性决定。属于同一个BFC的两个相邻Box的margin会发生重叠【符合合并原则的margin合并后是使用大的margin】如何创建BFC
BFC 的应用
margin 会发生重叠,触发生成两个BFC,即不会重叠)
<script>标签中增加async(html5) 或者defer(html4) 属性,脚本就会异步加载。
<script src="../XXX.js" defer></script>defer 和 async 的区别在于:
defer 要等到整个页面在内存中正常渲染结束(DOM 结构完全生成,以及其他脚本执行完成),在window.onload 之前执行;async 一旦下载完,渲染引擎就会中断渲染,执行这个脚本以后,再继续渲染。defer 脚本,会按照它们在页面出现的顺序加载async 脚本不能保证加载顺序动态创建
script标签
动态创建的 script ,设置 src 并不会开始下载,而是要添加到文档中,JS文件才会开始下载。
let script = document.createElement('script');
script.src = 'XXX.js';
// 添加到html文件中才会开始下载
document.body.append(script);XHR 异步加载JS
let xhr = new XMLHttpRequest();
xhr.open("get", "js/xxx.js",true);
xhr.send();
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
eval(xhr.responseText);
}
}ES5 有 6 种方式可以实现继承,分别为:
原型链继承的基本**是利用原型让一个引用类型继承另一个引用类型的属性和方法。
function SuperType() {
this.name = 'Yvette';
this.colors = ['pink', 'blue', 'green'];
}
SuperType.prototype.getName = function () {
return this.name;
}
function SubType() {
this.age = 22;
}
SubType.prototype = new SuperType();
SubType.prototype.getAge = function() {
return this.age;
}
SubType.prototype.constructor = SubType;
let instance1 = new SubType();
instance1.colors.push('yellow');
console.log(instance1.getName()); //'Yvette'
console.log(instance1.colors);//[ 'pink', 'blue', 'green', 'yellow' ]
let instance2 = new SubType();
console.log(instance2.colors);//[ 'pink', 'blue', 'green', 'yellow' ]缺点:
借用构造函数的技术,其基本**为:
在子类型的构造函数中调用超类型构造函数。
function SuperType(name) {
this.name = name;
this.colors = ['pink', 'blue', 'green'];
}
function SubType(name) {
SuperType.call(this, name);
}
let instance1 = new SubType('Yvette');
instance1.colors.push('yellow');
console.log(instance1.colors);//['pink', 'blue', 'green', yellow]
let instance2 = new SubType('Jack');
console.log(instance2.colors); //['pink', 'blue', 'green']优点:
缺点:
组合继承指的是将原型链和借用构造函数技术组合到一块,从而发挥二者之长的一种继承模式。基本思路:
使用原型链实现对原型属性和方法的继承,通过借用构造函数来实现对实例属性的继承,既通过在原型上定义方法来实现了函数复用,又保证了每个实例都有自己的属性。
function SuperType(name) {
this.name = name;
this.colors = ['pink', 'blue', 'green'];
}
SuperType.prototype.sayName = function () {
console.log(this.name);
}
function SuberType(name, age) {
SuperType.call(this, name);
this.age = age;
}
SuberType.prototype = new SuperType();
SuberType.prototype.constructor = SuberType;
SuberType.prototype.sayAge = function () {
console.log(this.age);
}
let instance1 = new SuberType('Yvette', 20);
instance1.colors.push('yellow');
console.log(instance1.colors); //[ 'pink', 'blue', 'green', 'yellow' ]
instance1.sayName(); //Yvette
let instance2 = new SuberType('Jack', 22);
console.log(instance2.colors); //[ 'pink', 'blue', 'green' ]
instance2.sayName();//Jack缺点:
优点:
原型继承的基本**:
借助原型可以基于已有的对象创建新对象,同时还不必因此创建自定义类型。
function object(o) {
function F() { }
F.prototype = o;
return new F();
}在 object() 函数内部,先穿甲一个临时性的构造函数,然后将传入的对象作为这个构造函数的原型,最后返回了这个临时类型的一个新实例,从本质上讲,object() 对传入的对象执行了一次浅拷贝。
ECMAScript5通过新增 Object.create()方法规范了原型式继承。这个方法接收两个参数:一个用作新对象原型的对象和(可选的)一个为新对象定义额外属性的对象(可以覆盖原型对象上的同名属性),在传入一个参数的情况下,Object.create() 和 object() 方法的行为相同。
var person = {
name: 'Yvette',
hobbies: ['reading', 'photography']
}
var person1 = Object.create(person);
person1.name = 'Jack';
person1.hobbies.push('coding');
var person2 = Object.create(person);
person2.name = 'Echo';
person2.hobbies.push('running');
console.log(person.hobbies);//[ 'reading', 'photography', 'coding', 'running' ]
console.log(person1.hobbies);//[ 'reading', 'photography', 'coding', 'running' ]在没有必要创建构造函数,仅让一个对象与另一个对象保持相似的情况下,原型式继承是可以胜任的。
缺点:
同原型链实现继承一样,包含引用类型值的属性会被所有实例共享。
寄生式继承是与原型式继承紧密相关的一种思路。寄生式继承的思路与寄生构造函数和工厂模式类似,即创建一个仅用于封装继承过程的函数,该函数在内部已某种方式来增强对象,最后再像真地是它做了所有工作一样返回对象。
function createAnother(original) {
var clone = object(original);//通过调用函数创建一个新对象
clone.sayHi = function () {//以某种方式增强这个对象
console.log('hi');
};
return clone;//返回这个对象
}
var person = {
name: 'Yvette',
hobbies: ['reading', 'photography']
};
var person2 = createAnother(person);
person2.sayHi(); //hi基于 person 返回了一个新对象 -—— person2,新对象不仅具有 person 的所有属性和方法,而且还有自己的 sayHi() 方法。在考虑对象而不是自定义类型和构造函数的情况下,寄生式继承也是一种有用的模式。
缺点:
所谓寄生组合式继承,即通过借用构造函数来继承属性,通过原型链的混成形式来继承方法,基本思路:
不必为了指定子类型的原型而调用超类型的构造函数,我们需要的仅是超类型原型的一个副本,本质上就是使用寄生式继承来继承超类型的原型,然后再将结果指定给子类型的原型。寄生组合式继承的基本模式如下所示:
function inheritPrototype(subType, superType) {
var prototype = object(superType.prototype); //创建对象
prototype.constructor = subType;//增强对象
subType.prototype = prototype;//指定对象
}constructor 属性至此,我们就可以通过调用 inheritPrototype 来替换为子类型原型赋值的语句:
function SuperType(name) {
this.name = name;
this.colors = ['pink', 'blue', 'green'];
}
//...code
function SuberType(name, age) {
SuperType.call(this, name);
this.age = age;
}
SuberType.prototype = new SuperType();
inheritPrototype(SuberType, SuperType);
//...code优点:
只调用了一次超类构造函数,效率更高。避免在SuberType.prototype上面创建不必要的、多余的属性,与其同时,原型链还能保持不变。
因此寄生组合继承是引用类型最理性的继承范式。
隐藏类型
屏幕并不是唯一的输出机制,比如说屏幕上看不见的元素(隐藏的元素),其中一些依然能够被读屏软件阅读出来(因为读屏软件依赖于可访问性树来阐述)。为了消除它们之间的歧义,我们将其归为三大类:
完全隐藏
display 属性display: none;HTML5 新增属性,相当于 display: none
<div hidden>
</div>视觉上的隐藏
position 和 盒模型 将元素移出可视区范围posoition 为 absolute 或 fixed,�通过设置 top、left 等值,将其移出可视区域。position:absolute;
left: -99999px;position 为 relative,通过设置 top、left 等值,将其移出可视区域。position: relative;
left: -99999px;
height: 0margin-left: -99999px;
height: 0;transform: scale(0);
height: 0;translateX, translateYtransform: translateX(-99999px);
height: 0rotatetransform: rotateY(90deg);height: 0;
width: 0;
font-size: 0;height: 0;
width: 0;
overflow: hidden;opacity: 0;visibility属性visibility: hidden;z-index 属性position: relative;
z-index: -999;再设置一个层级较高的元素覆盖在此元素上。
clip-path: polygon(0 0, 0 0, 0 0, 0 0);语义上的隐藏
读屏软件不可读,占据空间,可见。
<div aria-hidden="true">
</div>| 声明方式 | 变量提升 | 暂时性死区 | 重复声明 | 块作用域有效 | 初始值 | 重新赋值 |
|---|---|---|---|---|---|---|
| var | 会 | 不存在 | 允许 | 不是 | 非必须 | 允许 |
| let | 不会 | 存在 | 不允许 | 是 | 非必须 | 允许 |
| const | 不会 | 存在 | 不允许 | 是 | 必须 | 不允许 |
1.let/const 定义的变量不会出现变量提升,而 var 定义的变量会提升。
2.相同作用域中,let 和 const 不允许重复声明,var 允许重复声明。
3.const 声明变量时必须设置初始值
4.const 声明一个只读的常量,这个常量不可改变。
这里有一个非常重要的点即是:在JS中,复杂数据类型,存储在栈中的是堆内存的地址,存在栈中的这个地址是不变的,但是存在堆中的值是可以变得。有没有相当常量指针/指针常量~
const a = 20;
const b = {
age: 18,
star: 500
}一图胜万言,如下图所示,不变的是栈内存中 a 存储的 20,和 b 中存储的 0x0012ff21(瞎编的一个数字)。而 {age: 18, star: 200} 是可变的。
在开始说明JS上下文栈和作用域之前,我们先说明下JS上下文以及作用域的概念。
执行上下文就是当前 JavaScript 代码被解析和执行时所在环境的抽象概念, JavaScript 中运行任何的代码都是在执行上下文中运行。
执行上下文类型分为:
执行上下文创建过程中,需要做以下几件事:
作用域负责收集和维护由所有声明的标识符(变量)组成的一系列查询,并实施一套非常严格的规则,确定当前执行的代码对这些标识符的访问权限。—— 摘录自《你不知道的JavaScript》(上卷)
作用域有两种工作模型:词法作用域和动态作用域,JS采用的是词法作用域工作模型,词法作用域意味着作用域是由书写代码时变量和函数声明的位置决定的。(with 和 eval 能够修改词法作用域,但是不推荐使用,对此不做特别说明)
作用域分为:
执行栈,也叫做调用栈,具有 LIFO (后进先出) 结构,用于存储在代码执行期间创建的所有执行上下文。
规则如下:
以一段代码具体说明:
function fun3() {
console.log('fun3')
}
function fun2() {
fun3();
}
function fun1() {
fun2();
}
fun1();Global Execution Context (即全局执行上下文)首先入栈,过程如下:
伪代码:
//全局执行上下文首先入栈
ECStack.push(globalContext);
//执行fun1();
ECStack.push(<fun1> functionContext);
//fun1中又调用了fun2;
ECStack.push(<fun2> functionContext);
//fun2中又调用了fun3;
ECStack.push(<fun3> functionContext);
//fun3执行完毕
ECStack.pop();
//fun2执行完毕
ECStack.pop();
//fun1执行完毕
ECStack.pop();
//javascript继续顺序执行下面的代码,但ECStack底部始终有一个 全局上下文(globalContext);作用域链就是从当前作用域开始一层一层向上寻找某个变量,直到找到全局作用域还是没找到,就宣布放弃。这种一层一层的关系,就是作用域链。
如:
var a = 10;
function fn1() {
var b = 20;
console.log(fn2)
function fn2() {
a = 20
}
return fn2;
}
fn1()();fn2作用域链 = [fn2作用域, fn1作用域,全局作用域]
防抖函数的作用
防抖函数的作用就是控制函数在一定时间内的执行次数。防抖意味着N秒内函数只会被执行一次,如果N秒内再次被触发,则重新计算延迟时间。
举例说明: 小思最近在减肥,但是她非常吃吃零食。为此,与其男朋友约定好,如果10天不吃零食,就可以购买一个包(不要问为什么是包,因为包治百病)。但是如果中间吃了一次零食,那么就要重新计算时间,直到小思坚持10天没有吃零食,才能购买一个包。所以,管不住嘴的小思,没有机会买包(悲伤的故事)... 这就是 防抖。
防抖函数实现
timer 是 null,调用 later(),若 immediate 为true,那么立即调用 func.apply(this, params);如果 immediate 为 false,那么过 wait 之后,调用 func.apply(this, params)timer 已经重置为 null(即 setTimeout 的倒计时结束),那么流程与第一次触发时一样,若 timer 不为 null(即 setTimeout 的倒计时未结束),那么清空定时器,重新开始计时。function debounce(func, wait, immediate = true) {
let timeout, result;
// 延迟执行函数
const later = (context, args) => setTimeout(() => {
timeout = null;// 倒计时结束
if (!immediate) {
//执行回调
result = func.apply(context, args);
context = args = null;
}
}, wait);
let debounced = function (...params) {
if (!timeout) {
timeout = later(this, params);
if (immediate) {
//立即执行
result = func.apply(this, params);
}
} else {
clearTimeout(timeout);
//函数在每个等待时延的结束被调用
timeout = later(this, params);
}
return result;
}
//提供在外部清空定时器的方法
debounced.cancel = function () {
clearTimeout(timer);
timer = null;
};
return debounced;
};immediate 为 true 时,表示函数在每个等待时延的开始被调用。immediate 为 false 时,表示函数在每个等待时延的结束被调用。
防抖的应用场景
节流函数的作用
节流函数的作用是规定一个单位时间,在这个单位时间内最多只能触发一次函数执行,如果这个单位时间内多次触发函数,只能有一次生效。
节流函数实现
function throttle(func, wait, options = {}) {
var timeout, context, args, result;
var previous = 0;
var later = function () {
previous = options.leading === false ? 0 : (Date.now() || new Date().getTime());
timeout = null;
result = func.apply(context, args);
if (!timeout) context = args = null;
};
var throttled = function () {
var now = Date.now() || new Date().getTime();
if (!previous && options.leading === false) previous = now;
//remaining 为距离下次执行 func 的时间
//remaining > wait,表示客户端系统时间被调整过
var remaining = wait - (now - previous);
context = this;
args = arguments;
//remaining 小于等于0,表示事件触发的间隔时间大于设置的 wait
if (remaining <= 0 || remaining > wait) {
if (timeout) {
//清空定时器
clearTimeout(timeout);
timeout = null;
}
//重置 previous
previous = now;
//执行函数
result = func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
timeout = setTimeout(later, remaining);
}
return result;
};
throttled.cancel = function () {
clearTimeout(timeout);
previous = 0;
timeout = context = args = null;
};
return throttled;
}禁用第一次首先执行,传递 {leading: false} ;想禁用最后一次执行,传递 {trailing: false}
节流的应用场景
《JavaScript高级程序设计》:
闭包是指有权访问另一个函数作用域中的变量的函数
《JavaScript权威指南》:
从技术的角度讲,所有的JavaScript函数都是闭包:它们都是对象,它们都关联到作用域链。
《你不知道的JavaScript》
当函数可以记住并访问所在的词法作用域时,就产生了闭包,即使函数是在当前词法作用域之外执行。
function foo() {
var a = 2;
return function fn() {
console.log(a);
}
}
let func = foo();
func(); //输出2闭包使得函数可以继续访问定义时的词法作用域。拜 fn 所赐,在 foo() 执行后,foo 内部作用域不会被销毁。
能够访问函数定义时所在的词法作用域(阻止其被回收)。
私有化变量
function base() {
let x = 10; //私有变量
return {
getX: function() {
return x;
}
}
}
let obj = base();
console.log(obj.getX()); //10var a = [];
for (var i = 0; i < 10; i++) {
a[i] = (function(j){
return function () {
console.log(j);
}
})(i);
}
a[6](); // 6function coolModule() {
let name = 'Yvette';
let age = 20;
function sayName() {
console.log(name);
}
function sayAge() {
console.log(age);
}
return {
sayName,
sayAge
}
}
let info = coolModule();
info.sayName(); //'Yvette'模块模式具有两个必备的条件(来自《你不知道的JavaScript》)
在实现 Promise.all 方法之前,我们首先要知道 Promise.all 的功能和特点,因为在清楚了 Promise.all 功能和特点的情况下,我们才能进一步去写实现。
Promise.all 功能
Promise.all(iterable) 返回一个新的 Promise 实例。此实例在 iterable 参数内所有的 promise 都 fulfilled 或者参数中不包含 promise 时,状态变成 fulfilled;如果参数中 promise 有一个失败rejected,此实例回调失败,失败原因的是第一个失败 promise 的返回结果。
let p = Promise.all([p1, p2, p3]);p的状态由 p1,p2,p3决定,分成以下;两种情况:
(1)只有p1、p2、p3的状态都变成 fulfilled,p的状态才会变成 fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p的回调函数。
(2)只要p1、p2、p3之中有一个被 rejected,p的状态就变成 rejected,此时第一个被reject的实例的返回值,会传递给p的回调函数。
Promise.all 的特点
Promise.all 的返回值是一个 promise 实例
Promise.all 会 同步 返回一个已完成状态的 promisePromise.all 会 异步 返回一个已完成状态的 promisePromise.all 返回一个 处理中(pending) 状态的 promise.Promise.all 返回的 promise 的状态
Promise.all 返回的 promise 异步地变为完成。promise 失败,Promise.all 异步地将失败的那个结果给失败状态的回调函数,而不管其它 promise 是否完成Promise.all 返回的 promise 的完成状态的结果都是一个数组Promise.all 实现
Promise.all = function (promises) {
//promises 是可迭代对象,省略参数合法性检查
return new Promise((resolve, reject) => {
//Array.from 将可迭代对象转换成数组
promises = Array.from(promises);
if (promises.length === 0) {
resolve([]);
} else {
let result = [];
let index = 0;
for (let i = 0; i < promises.length; i++ ) {
//考虑到 i 可能是 thenable 对象也可能是普通值
Promise.resolve(promises[i]).then(data => {
result[i] = data;
if (++index === promises.length) {
//所有的 promises 状态都是 fulfilled,promise.all返回的实例才变成 fulfilled 态
resolve(result);
}
}, err => {
reject(err);
return;
});
}
}
});
}例如:
flattenDeep([1, [2, [3, [4]], 5]]); //[1, 2, 3, 4, 5]利用 Array.prototype.flat
ES6 为数组实例新增了 flat 方法,用于将嵌套的数组“拉平”,变成一维的数组。该方法返回一个新数组,对原数组没有影响。
flat 默认只会 “拉平” 一层,如果想要 “拉平” 多层的嵌套数组,需要给 flat 传递一个整数,表示想要拉平的层数。
function flattenDeep(arr, deepLength) {
return arr.flat(deepLength);
}
console.log(flattenDeep([1, [2, [3, [4]], 5]], 3));当传递的整数大于数组嵌套的层数时,会将数组拉平为一维数组,JS能表示的最大数字为 Math.pow(2, 53) - 1,因此我们可以这样定义 flattenDeep 函数
function flattenDeep(arr) {
//当然,大多时候我们并不会有这么多层级的嵌套
return arr.flat(Math.pow(2,53) - 1);
}
console.log(flattenDeep([1, [2, [3, [4]], 5]]));利用 reduce 和 concat
function flattenDeep(arr){
return arr.reduce((acc, val) => Array.isArray(val) ? acc.concat(flattenDeep(val)) : acc.concat(val), []);
}
console.log(flattenDeep([1, [2, [3, [4]], 5]]));使用 stack 无限反嵌套多层嵌套数组
function flattenDeep(input) {
const stack = [...input];
const res = [];
while (stack.length) {
// 使用 pop 从 stack 中取出并移除值
const next = stack.pop();
if (Array.isArray(next)) {
// 使用 push 送回内层数组中的元素,不会改动原始输入 original input
stack.push(...next);
} else {
res.push(next);
}
}
// 使用 reverse 恢复原数组的顺序
return res.reverse();
}
console.log(flattenDeep([1, [2, [3, [4]], 5]]));例如:
uniq([1, 2, 3, 5, 3, 2]);//[1, 2, 3, 5]法1: 利用ES6新增数据类型
Set
Set类似于数组,但是成员的值都是唯一的,没有重复的值。
function uniq(arry) {
return [...new Set(arry)];
}法2: 利用
indexOf
function uniq(arry) {
var result = [];
for (var i = 0; i < arry.length; i++) {
if (result.indexOf(arry[i]) === -1) {
//如 result 中没有 arry[i],则添加到数组中
result.push(arry[i])
}
}
return result;
}法3: 利用
includes
function uniq(arry) {
var result = [];
for (var i = 0; i < arry.length; i++) {
if (!result.includes(arry[i])) {
//如 result 中没有 arry[i],则添加到数组中
result.push(arry[i])
}
}
return result;
}法4:利用
reduce
function uniq(arry) {
return arry.reduce((prev, cur) => prev.includes(cur) ? prev : [...prev, cur], []);
}法5:利用
Map
function uniq(arry) {
let map = new Map();
let result = new Array();
for (let i = 0; i < arry.length; i++) {
if (map.has(arry[i])) {
map.set(arry[i], true);
} else {
map.set(arry[i], false);
result.push(arry[i]);
}
}
return result;
}ES6 规定,默认的 Iterator 接口部署在数据结构的 Symbol.iterator 属性,换个角度,也可以认为,一个数据结构只要具有 Symbol.iterator 属性(Symbol.iterator 方法对应的是遍历器生成函数,返回的是一个遍历器对象),那么就可以其认为是可迭代的。
Symbol.iterator 属性,Symbol.iterator() 返回的是一个遍历器对象for ... of 进行循环Array.from 转换为数组let arry = [1, 2, 3, 4];
let iter = arry[Symbol.iterator]();
console.log(iter.next()); //{ value: 1, done: false }
console.log(iter.next()); //{ value: 2, done: false }
console.log(iter.next()); //{ value: 3, done: false }Iterator 接口的数据结构:尽管浏览器有同源策略,但是 <script> 标签的 src 属性不会被同源策略所约束,可以获取任意服务器上的脚本并执行。jsonp 通过插入 script 标签的方式来实现跨域,参数只能通过 url 传入,仅能支持 get 请求。
实现原理:
jsonp源码实现
function jsonp({url, params, callback}) {
return new Promise((resolve, reject) => {
//创建script标签
let script = document.createElement('script');
//将回调函数挂在 window 上
window[callback] = function(data) {
resolve(data);
//代码执行后,删除插入的script标签
document.body.removeChild(script);
}
//回调函数加在请求地址上
params = {...params, callback} //wb=b&callback=show
let arrs = [];
for(let key in params) {
arrs.push(`${key}=${params[key]}`);
}
script.src = `${url}?${arrs.join('&')}`;
document.body.appendChild(script);
});
}使用:
function show(data) {
console.log(data);
}
jsonp({
url: 'http://localhost:3000/show',
params: {
//code
},
callback: 'show'
}).then(data => {
console.log(data);
});服务端代码(node):
//express启动一个后台服务
let express = require('express');
let app = express();
app.get('/show', (req, res) => {
let {callback} = req.query; //获取传来的callback函数名,callback是key
res.send(`${callback}('Hello!')`);
});
app.listen(3000);[1] 珠峰架构课(墙裂推荐)
[2] [JavaScript高级程序设计第六章]
[3] Step-By-Step】高频面试题深入解析 / 周刊01
[4] Step-By-Step】高频面试题深入解析 / 周刊02
[5] Step-By-Step】高频面试题深入解析 / 周刊03
[6] Step-By-Step】高频面试题深入解析 / 周刊04
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。 https://github.com/YvetteLau/Blog
关注公众号,加入技术交流群。
翻译:刘小夕
原文链接:https://dmitripavlutin.com/7-architectural-attributes-of-a-reliable-react-component/
原文的篇幅非常长,不过内容太过于吸引我,还是忍不住要翻译出来。此篇文章对编写可重用和可维护的React组件非常有帮助。但因为篇幅实在太长,我不得不进行了分割,本篇文章重点阐述 SRP,即单一职责原则。
————————————我是一条分割线————————————
我喜欢React组件式开发方式。你可以将复杂的用户界面分割为一个个组件,利用组件的可重用性和抽象的DOM操作。
基于组件的开发是高效的:一个复杂的系统是由专门的、易于管理的组件构建的。然而,只有设计良好的组件才能确保组合和复用的好处。
尽管应用程序很复杂,但为了满足最后期限和意外变化的需求,你必须不断地走在架构正确性的细线上。你必须将组件分离为专注于单个任务,并经过良好测试。
不幸的是,遵循错误的路径总是更加容易:编写具有许多职责的大型组件、紧密耦合组件、忘记单元测试。这些增加了技术债务,使得修改现有功能或创建新功能变得越来越困难。
编写React应用程序时,我经常问自己:
幸运的是,可靠的组件具有共同的特性。让我们来研究这7个有用的标准(本文只阐述 SRP,剩余准则正在途中),并将其详细到案例研究中。
当一个组件只有一个改变的原因时,它有一个单一的职责。
编写React组件时要考虑的基本准则是单一职责原则。单一职责原则(缩写:SRP)要求组件有一个且只有一个变更的原因。
组件的职责可以是呈现列表,或者显示日期选择器,或者发出 HTTP 请求,或者绘制图表,或者延迟加载图像等。你的组件应该只选择一个职责并实现它。当你修改组件实现其职责的方式(例如,更改渲染的列表的数量限制),它有一个更改的原因。
为什么只有一个理由可以改变很重要?因为这样组件的修改隔离并且受控。单一职责原则制了组件的大小,使其集中在一件事情上。集中在一件事情上的组件便于编码、修改、重用和测试。
下面我们来举几个例子
实例1:一个组件获取远程数据,相应地,当获取逻辑更改时,它有一个更改的原因。
发生变化的原因是:
示例2:表组件将数据数组映射到行组件列表,因此在映射逻辑更改时有一个原因需要更改。
发生变化的原因是:
你的组件有很多职责吗?如果答案是“是”,则按每个单独的职责将组件分成若干块。
如果您发现SRP有点模糊,请阅读本文。
在项目早期阶段编写的单元将经常更改,直到达到发布阶段。这些更改通常要求组件在隔离状态下易于修改:这也是 SRP 的目标。
当一个组件有多个职责时,就会发生一个常见的问题。乍一看,这种做法似乎是无害的,并且工作量较少:
props 和 callbacks这种幼稚的结构在开始时很容易编码。但是随着应用程序的增加和变得复杂,在以后的修改中会出现困难。同时实现多个职责的组件有许多更改的原因。现在出现的主要问题是:出于某种原因更改组件会无意中影响同一组件实现的其它职责。
不要关闭电灯开关,因为它同样作用于电梯。
这种设计很脆弱。意外的副作用是很难预测和控制的。
例如,<ChartAndForm> 同时有两个职责,绘制图表,并处理为该图表提供数据的表单。<ChartandForm> 就会有两个更改原因:绘制图表和处理表单。
当你更改表单字段(例如,将 <input> 修改为 <select> 时,你无意中中断图表的渲染。此外,图表实现是不可重用的,因为它与表单细节耦合在一起。
解决多重责任问题需要将 <ChartAndForm> 分割为两个组件:<Chart> 和<Form>。每个组件只有一个职责:绘制图表或处理表单。组件之间的通信是通过props 实现。
多重责任问题的最坏情况是所谓的上帝组件(上帝对象的类比)。上帝组件倾向于了解并做所有事情。你可能会看到它名为 <Application>、<Manager> 、<Bigcontainer> 或 <Page>,代码超过500行。
在组合的帮助下使其符合SRP,从而分解上帝组件。(组合(composition)是一种通过将各组件联合在一起以创建更大组件的方式。组合是 React 的核心。)
设想一个组件向一个专门的服务器发出 HTTP 请求,以获取当前天气。成功获取数据时,该组件使用响应来展示天气信息:
import axios from 'axios';
// 问题: 一个组件有多个职责
class Weather extends Component {
constructor(props) {
super(props);
this.state = { temperature: 'N/A', windSpeed: 'N/A' };
}
render() {
const { temperature, windSpeed } = this.state;
return (
<div className="weather">
<div>Temperature: {temperature}°C</div>
<div>Wind: {windSpeed}km/h</div>
</div>
);
}
componentDidMount() {
axios.get('http://weather.com/api').then(function (response) {
const { current } = response.data;
this.setState({
temperature: current.temperature,
windSpeed: current.windSpeed
})
});
}
}在处理类似的情况时,问问自己:是否必须将组件拆分为更小的组件?通过确定组件可能会如何根据其职责进行更改,可以最好地回答这个问题。
这个天气组件有两个改变原因:
componentDidMount() 中的 fetch 逻辑:服务器URL或响应格式可能会改变。
render() 中的天气展示:组件显示天气的方式可以多次更改。
解决方案是将 <Weather> 分为两个组件:每个组件只有一个职责。命名为 <WeatherFetch> 和 <WeatherInfo>。
<WeatherFetch> 组件负责获取天气、提取响应数据并将其保存到 state 中。它改变原因只有一个就是获取数据逻辑改变。
import axios from 'axios';
// 解决措施: 组件只有一个职责就是请求数据
class WeatherFetch extends Component {
constructor(props) {
super(props);
this.state = { temperature: 'N/A', windSpeed: 'N/A' };
}
render() {
const { temperature, windSpeed } = this.state;
return (
<WeatherInfo temperature={temperature} windSpeed={windSpeed} />
);
}
componentDidMount() {
axios.get('http://weather.com/api').then(function (response) {
const { current } = response.data;
this.setState({
temperature: current.temperature,
windSpeed: current.windSpeed
});
});
}
}这种结构有什么好处?
例如,你想要使用 async/await 语法来替代 promise 去服务器获取响应。更改原因:修改获取逻辑
// 改变原因: 使用 async/await 语法
class WeatherFetch extends Component {
// ..... //
async componentDidMount() {
const response = await axios.get('http://weather.com/api');
const { current } = response.data;
this.setState({
temperature: current.temperature,
windSpeed: current.windSpeed
});
}
}因为 <WeatherFetch> 只有一个更改原因:修改 fetch 逻辑,所以对该组件的任何修改都是隔离的。使用 async/await 不会直接影响天气的显示。
<WeatherFetch> 渲染 <WeatherInfo>。后者只负责显示天气,改变原因只可能是视觉显示改变。
// 解决方案: 组件只有一个职责,就是显示天气
function WeatherInfo({ temperature, windSpeed }) {
return (
<div className="weather">
<div>Temperature: {temperature}°C</div>
<div>Wind: {windSpeed} km/h</div>
</div>
);
}让我们更改<WeatherInfo>,如不显示 “wind:0 km/h” 而是显示 “wind:calm”。这就是天气视觉显示发生变化的原因:
// 改变原因: 无风时的显示
function WeatherInfo({ temperature, windSpeed }) {
const windInfo = windSpeed === 0 ? 'calm' : `${windSpeed} km/h`;
return (
<div className="weather">
<div>Temperature: {temperature}°C</div>
<div>Wind: {windInfo}</div>
</div>
);
}同样,对 <WeatherInfo> 的修改是隔离的,不会影响 <WeatherFetch> 组件。
<WeatherFetch> 和 <WeatherInfo> 有各自的职责。一种组件的变化对另一种组件的影响很小。这就是单一职责原则的作用:修改隔离,对系统的其他组件产生影响很轻微并且可预测。
按职责使用分块组件的组合并不总是有助于遵循单一责任原则。另外一种有效实践是高阶组件(缩写为 HOC)
高阶组件是一个接受一个组件并返回一个新组件的函数。
HOC 的一个常见用法是为封装的组件增加新属性或修改现有的属性值。这种技术称为属性代理:
function withNewFunctionality(WrappedComponent) {
return class NewFunctionality extends Component {
render() {
const newProp = 'Value';
const propsProxy = {
...this.props,
// 修改现有属性:
ownProp: this.props.ownProp + ' was modified',
// 增加新属性:
newProp
};
return <WrappedComponent {...propsProxy} />;
}
}
}
const MyNewComponent = withNewFunctionality(MyComponent);你还可以通过控制输入组件的渲染过程从而控制渲染结果。这种 HOC 技术被称为渲染劫持:
function withModifiedChildren(WrappedComponent) {
return class ModifiedChildren extends WrappedComponent {
render() {
const rootElement = super.render();
const newChildren = [
...rootElement.props.children,
// 插入一个元素
<div>New child</div>
];
return cloneElement(
rootElement,
rootElement.props,
newChildren
);
}
}
}
const MyNewComponent = withModifiedChildren(MyComponent);如果您想深入了解HOCS实践,我建议您阅读“深入响应高阶组件”。
让我们通过一个例子来看看HOC的属性代理技术如何帮助分离职责。
组件 <PersistentForm> 由 input 输入框和按钮 save to storage 组成。更改输入值后,点击 save to storage 按钮将其写入到 localStorage 中。
input 的状态在 handlechange(event) 方法中更新。点击按钮,值将保存到本地存储,在 handleclick() 中处理:
class PersistentForm extends Component {
constructor(props) {
super(props);
this.state = { inputValue: localStorage.getItem('inputValue') };
this.handleChange = this.handleChange.bind(this);
this.handleClick = this.handleClick.bind(this);
}
render() {
const { inputValue } = this.state;
return (
<div className="persistent-form">
<input type="text" value={inputValue}
onChange={this.handleChange} />
<button onClick={this.handleClick}>Save to storage</button>
</div>
);
}
handleChange(event) {
this.setState({
inputValue: event.target.value
});
}
handleClick() {
localStorage.setItem('inputValue', this.state.inputValue);
}
}遗憾的是: <PersistentForm> 有2个职责:管理表单字段;将输入只保存中 localStorage。
让我们重构一下 <PersistentForm> 组件,使其只有一个职责:展示表单字段和附加的事件处理程序。它不应该知道如何直接使用存储:
class PersistentForm extends Component {
constructor(props) {
super(props);
this.state = { inputValue: props.initialValue };
this.handleChange = this.handleChange.bind(this);
this.handleClick = this.handleClick.bind(this);
}
render() {
const { inputValue } = this.state;
return (
<div className="persistent-form">
<input type="text" value={inputValue}
onChange={this.handleChange} />
<button onClick={this.handleClick}>Save to storage</button>
</div>
);
}
handleChange(event) {
this.setState({
inputValue: event.target.value
});
}
handleClick() {
this.props.saveValue(this.state.inputValue);
}
}组件从属性初始值接收存储的输入值,并使用属性函数 saveValue(newValue) 来保存输入值。这些props 由使用属性代理技术的 withpersistence() HOC提供。
现在 <PersistentForm> 符合 SRP。更改的唯一原因是修改表单字段。
查询和保存到本地存储的职责由 withPersistence() HOC承担:
function withPersistence(storageKey, storage) {
return function (WrappedComponent) {
return class PersistentComponent extends Component {
constructor(props) {
super(props);
this.state = { initialValue: storage.getItem(storageKey) };
}
render() {
return (
<WrappedComponent
initialValue={this.state.initialValue}
saveValue={this.saveValue}
{...this.props}
/>
);
}
saveValue(value) {
storage.setItem(storageKey, value);
}
}
}
}withPersistence()是一个 HOC,其职责是持久的。它不知道有关表单域的任何详细信息。它只聚焦一个工作:为传入的组件提供 initialValue 字符串和 saveValue() 函数。
将 <PersistentForm> 和 withpersistence() 一起使用可以创建一个新组件<LocalStoragePersistentForm>。它与本地存储相连,可以在应用程序中使用:
const LocalStoragePersistentForm
= withPersistence('key', localStorage)(PersistentForm);
const instance = <LocalStoragePersistentForm />;只要 <PersistentForm> 正确使用 initialValue 和 saveValue()属性,对该组件的任何修改都不能破坏 withPersistence() 保存到存储的逻辑。
反之亦然:只要 withPersistence() 提供正确的 initialValue 和 saveValue(),对 HOC 的任何修改都不能破坏处理表单字段的方式。
SRP的效率再次显现出来:修改隔离,从而减少对系统其他部分的影响。
此外,代码的可重用性也会增加。你可以将任何其他表单 <MyOtherForm> 连接到本地存储:
const LocalStorageMyOtherForm
= withPersistence('key', localStorage)(MyOtherForm);
const instance = <LocalStorageMyOtherForm />;你可以轻松地将存储类型更改为 session storage:
const SessionStoragePersistentForm
= withPersistence('key', sessionStorage)(PersistentForm);
const instance = <SessionStoragePersistentForm />;初始版本 <PersistentForm> 没有隔离修改和可重用性好处,因为它错误地具有多个职责。
在不好分块组合的情况下,属性代理和渲染劫持的 HOC 技术可以使得组件只有一个职责。
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。 https://github.com/YvetteLau/Blog
已在1群/2群的小伙伴们不要加~~~
直接运行点击页面“+”|“-”按钮代码会报错redux-logger.js:1 Uncaught TypeError: r is not a function
去掉reduxLogger运行正常
很多时候,我们在进行移动端开发时,都是先在PC端使用手机模拟器进行调试,没有问题后,我们才会在手机端的浏览器进行测试,这个时候,如果没有出现问题,皆大欢喜。但是一旦出现问题,我们就很难解决,因为缺乏可视化的界面。不似在PC端,我们能直观的去改变样式,或者是进行断点调试。有时,在移动端我们不得不借助于alert来调试,但是这样的调试方法效率极其低下,很多时候,都是靠经验,或者是靠排除法。甚至,我们不得不归结为是浏览器的实现问题。
那么,有什么什么方法,能够让我们调试移动端的适配的时候,像调试PC端一样直观呢?本文旨在为你提供移动端的调试方法,希望能够为你打开新的一扇门。
本文会给出三种真机调试方法,你可以选择自己最喜欢的一款~
简单说明一下每一种方式的优缺点:
第一种: chrome真机调试,有一个很大的局限性就是,只能调试手机端的chrome浏览器,对于UC,QQ这些浏览器均不适用,因此在调试兼容问题时,帮助不大,但是最大的优点是: 简单快捷。
第二种: weinre调试方式,安装和适用不复杂,适用于全平台的调试,即任何手机的任何浏览器皆可以调试,不过需要手机和电脑在同一个网段下。
第三种:spy-debugger,安装稍微复杂一点,spy-debugger集成了weinre,不过还增加了抓包工具,使用最为方便。
下面我们开始具体介绍如何使用这三种调试方法:
手机端下载好chrome浏览器,使用USB连接到PC,打开手机的USB调试模式。
然后在PC端打开chrome浏览器,在地址栏输入: chrome://inspect. 勾选"discovery usb device"。然后在手机端浏览网页,就可以看到如下的页面,点击inspect,进行调试。(鉴于我的工作电脑是加了域的,因为并不能使用这个方式,如果有和我一样情况的童鞋,可以考虑使用另外两种调试方式)
Weinre(WebInspector Remote)是一款基于Web Inspector(Webkit)的远程调试工具,借助于网络,可以在PC上直接调试运行在移动设备上的远程页面。
本地服务器: 可以使用http-server、tomcat等,也可以使用编译器集成的服务
weinre安装
全局安装: npm install –g weinre
局部安装: npm install weinre
启动: weinre --httpPort 8090 --boundHost -all-
如果是局部安装的话,需要在前面加上 node_modules/.bin/
相信前端的童鞋都会用npm包管理工具,对于这个工具,我就不展开了,如果没有安装npm的,自行安装。
weinew启动参数说明:
8080端口使用情况较多,所以我选择了指定8090端口。
启动了weinre之后,我们在浏览器中输入localhost:8090.显示如下界面,表示已经启动成功。
点击debug client user interface,进入调试页面。
当前的targets中内容为空。
现在,我们需要做另外一点操作,在我们要调试的页面中,增加一个脚本。
<script src="http://localhost:8090/target/target-script-min.js#anonymous"></script>记住将localhost换成你的IP地址.
然后,我们在本地启动一个服务器,可以是IDE集成的服务器,或者是http-server,我使用的是http-server.启动之后,我们在手机端访问要调试的网页。然后就会发现targets下面增加了记录。
这时,我们就可以点击Elements进行调试。
修改样式时,会在手机端即时生效,并且也可以查看控制台信息,唯一一点就是,不能进行断点调试。
最后,在调试结束之后,别忘记删除嵌入的script。
除了这种方法之后,还介绍了在手机端保存一段Js代码,在需要调试某个页面时,点击执行JS,但是现在浏览器为了安全起见,已经不再支持此方法。默认的方法是搜索,而非执行,所以不可取。
最后,再介绍一下spy-debugger方法。用这个方法,我们不再需要自己增加和删除脚本。
Spy-debugger内部集成了weinre,通过代理的方式拦截所有html自动注入weinre所需的js代码。简化了weinre需要给每个调试的页面添加js代码。spy-debugger原理是拦截所有html页面请求注入weinre所需要的js代码。让页面调试更加方便。
特性:
Spydebugger安装与使用
安装: 全局安装 npm install –g spy-debugger
启动: spy-debugger
设置手机的HTTP代理
代理的地址为 PC的IP地址 ,代理的端口为spy-debugger的启动端口(默认端口为:9888)默认端口是 9888。
如果要指定端口: spy-debugger –p 8888
Android设置步骤:设置 - WLAN - 长按选中网络 - 修改网络 - 高级 - 代理设置 - 手动
iOS设置代理步骤:设置 - 无线局域网 - 选中网络 - HTTP代理手动
手机安装证书(node-mitmproxy CA根证书)
第一步:生成证书:
生成CA根证书,根证书生成在 /Users/XXX/node-mitmproxy/ 目录下(Mac)。
spy-debugger initCA第二步:安装证书:
把node-mitmproxy文件夹下的 node-mitmproxy.ca.crt 传到手机上,点击安装即可。
Spy-debugger启动界面,同样,在手机端刷新页面之后,targets中会有记录
以我曾经做的京东游戏的页面展示一下效果,当我们在手机上选中一个元素时,可以在电脑上看到相应的信息,这样我们就可以看出有可能是什么样式不兼容导致了UI的异常了,同样,还可以在控制台中看到JS的log信息,对于移动端调试来说非常有帮助。
]
总结:
最后,谢谢阅读。如果本篇博文给您带来了一点启发或者是帮助,请帮忙点个Star吧,非常感谢~
欢迎关注小姐姐的微信公众号,加入技术交流群。
React16.3.0开始,生命周期进行了一些变化。本文主要介绍React16.3.0之后的生命周期。
16版本之前的react组件的生命周期相信大家已经很熟悉。16版本的react对组件的生命周期函数进行了一些修改,下面进行详细说明。
创建期:
运行时:
props发生变化时
state发生变化时
卸载时
componentWillUnmount()
创建期:
或者如下生命周期:
注意: getDerivedStateFromProps/getSnapshotBeforeUpdate 和 componentWillMount/componentWillReceiveProps/componentWillUpdate 如果同时存在,React会在控制台给出警告信息,且仅执行 getDerivedStateFromProps/getSnapshotBeforeUpdate 【[email protected]】
运行时:
props发生变化时
或者如下生命周期:
state发生变化时
或者如下生命周期:
销毁时
componentWillUnmount()
新的生命周期图示:
constructor生命周期,如不需要,可缺省。通常会在 constructor 方法中初始化 state 和绑定事件处理程序。
但是,如果写了constructor,那么必须在其中调用super(props);否则可能会引起报错。
如:
class Base extends Component {
constructor(props) {
super(); //应该为 super(props);
}
state = {
name: this.props.name
}
//....code
}
抛出异常: Uncaught TypeError: Cannot read property 'name' of undefined.
同样,如果定义了context,在state中需要使用this.context去获取context上的内容,则需要super(props, context);
不过,如果你缺省constructor,那么在state中,可以放心的使用 this.props 或者是 this.context,不会引起报错。
class Base extends Component {
state = {
name: this.props.name,
color: this.context.color
}
//....code
}
初始化的state同样可以在constructor中定义。如果需要给方法绑定this,那么统一在constructor中进行。
当组件的state需要根据props来改变的时候可调用此方法。这个方法是在 render() 前会被执行,每次触发render前,都会触发此方法。
该方法有两个参数props和state; 返回值为state对象, 不需要返回整体state,把需要改变的state返回即可。如果不需要,可以返回null.
class Base extends Component {
state = {
age: 20
}
static getDerivedStateFromProps(props, state) {
return {
age: 50
}
}
render() {
// 50
return (
<div>{this.state.age}</div>
)
}
}这个方法允许组件基于 props 的变更来更新其内部状态,以这种方式获得的组件状态被称为派生状态。应该谨慎使用派生状态,可能会引入潜在的错误
React组件中必须要提供的方法。当state或者props任一数据有更新时都会执行。
render() 是一个纯函数,因此,不要在其中执行setState诸如此类的操作。render必须有一个返回值,返回的数据类型可以有:
注意不要在render中调用setState
componentDidMount()方法是在组件加载完后立即执行,也就是当该组件相关的dom节点插入到dom树中时。该方法在组件生命中只执行一次。
一般情况,我们会在这里setState(),或者进行接口请求,设置订阅等。
class Base extends Component {
state = {
age: 20
}
componentDidMount() {
this.fetchDate();
}
render() {
return (
<div>{this.state.age}</div>
)
}
//other code
}在渲染新的props或state前,shouldComponentUpdate被调用,默认返回true。forceUpdate()时不会调用此方法。
如果shouldComponentUpdate()返回false,那么getSnapshotBeforeUpdate,render和componentDidUpdate不会被调用。
此生命周期主要用于优化性能。
在render()的输出被渲染到DOM之前被调用。使组件能够在它们被更改之前捕获当前值(如滚动位置)。这个生命周期返回的任何值都将作为第三个参数传递给componentDidUpdate().
在更新发生后调用 componentDidUpdate()。当组件更新时,将此作为一个机会来操作DOM。如将当前的props与以前的props进行比较(例如,如果props没有改变,则可能不需要网络请求。
如果组件使用 getSnapshotBeforeUpdate(),则它返回的值将作为第三个“快照”参数传递给 componentDidUpdate()。否则,这个参数是undefined。
在组件被卸载并销毁之前立即被调用。在此方法中执行任何必要的清理,例如使定时器无效,取消网络请求或清理在componentDidMount()中创建的任何监听。
最后,说明一点:
componentWillMount,componentWillReceiveProps,componentWillUpdate这三个生命周期在React未来版本中会被废弃。
而UNSAFE_componentWillUpdate,UNSAFE_componentWillReceiveProps,UNSAFE_componentWillUpdate 未来版本中仍可继续使用。
初始化阶段(父组件和子组件):
运行阶段:父组件props/state更新
子组件的shouldComponentUpdate返回false,则子组件其后的生命周期都不在进行,但是父组件的生命周期继续执行。
卸载阶段: 卸载父组件
参考:
欢迎关注小姐姐的微信公众号,加入技术交流群。
webpack 核心概念:
webpack流程:
webpack启动后会从 Entry 里配置的 Module 开始递归解析 Entry 依赖的所有Module.每找到一个Module,就会根据配置的Loader去找出对应的转换规则,对Module进行转换后,再解析出当前的Module依赖的Module.这些模块会以Entry为单位进行分组,一个Entry和其所有依赖的Module被分到一个组也就是一个Chunk。最好Webpack会把所有Chunk转换成文件输出。在整个流程中Webpack会在恰当的时机执行Plugin里定义的逻辑。
下面我们开始从零开始配置一个支持打包图片,CSS,LESS,SASS,支持ES6/ES7和JSX语法,并对代码进行压缩的webpack配置.
1. 最简webpack配置
首先初始化npm和安装webpack的依赖:
npm init -y
npm install --save-dev webpack webpack-cli配置 webpack.config.js 文件如下:
const path = require('path');
module.exports = {
entry: path.resolve(__dirname, 'src/index.js'),
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js',
publicPath: '/'
}
}说明: publicPath 上线时配置的是cdn的地址。
使用命令进行打包:
webpack --mode production也可以将其配置到 package.json 中的 scripts 字段.
入口文件为 src/index.js, 打包输出到 dist/bundle.js.
2. 使用模板 html
html-webpack-plugin 可以指定template模板文件,将会在output目录下,生成html文件,并引入打包后的js.
安装依赖:
npm install --save-dev html-webpack-plugin在 webpack.config.js 增加 plugins 配置:
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
//...other code
plugins: [
new HtmlWebpackPlugin({
template: path.resolve(__dirname, 'src/index.html')
})
]
}HtmlWebpackPlugin 还有一些其它的参数,如title(html的title),minify(是否要压缩),filename(dist中生成的html的文件名)等
3. 配置 webpack-dev-server
webpack-dev-server提供了一个简单的Web服务器和实时热更新的能力
安装依赖:
npm install --save-dev webpack-dev-server在 webpack.config.js 增加 devServer 配置:
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
//...other code
devServer: {
contentBase: './dist',
port: '8080',
host: 'localhost'
}
}在 package.json 的 scripts 字段中增加:
webpack-dev-server --mode development之后,我们就可以通过 npm run dev , 来启动服务。
更多 webpack-dev-server 的知识,请访问: https://webpack.js.org/configuration/dev-server/
4. 支持加载css文件
通过使用不同的 style-loader 和 css-loader, 可以将 css 文件转换成JS文件类型。
安装依赖:
npm install --save-dev style-loader css-loader在 webpack.config.js 中增加 loader 的配置。
module.exports = {
//other code
module: {
rules: [
{
test: /\.css/,
use: ['style-loader', 'css-loader'],
exclude: /node_modules/,
include: path.resolve(__dirname, 'src')
}
]
}
}loader 可以配置以下参数:
如果需要给loader传参,那么可以使用use+loader的方式,如:
module.exports = {
//other code
module: {
rules: [
{
use: [{
loader: 'style-loader',
options: {
insertAt: 'top'
}
},
'css-loader'
],
//....
}
]
}
} 5. 支持加载图片
如果希望图片存放在单独的目录下,那么需要指定outputPath
安装依赖:
npm install --save-dev url-loader file-loader在 webpack.config.js 中增加 loader 的配置(增加在 module.rules 的数组中)。
module.exports = {
//other code
module: {
rules: [
{
test: /\.(gif|jpg|png|bmp|eot|woff|woff2|ttf|svg)/,
use: [
{
loader: 'url-loader',
options: {
limit: 8192,
outputPath: 'images'
}
}
]
}
]
}
} 6.支持编译less和sass
有些前端同事可能习惯于使用less或者是sass编写css,那么也需要在 webpack 中进行配置。
安装对应的依赖:
npm install --save-dev less less-loader
npm install --save-dev node-sass sass-loader在 webpack.config.js 中增加 loader 的配置(module.rules 数组中)。
module.exports = {
//other code
module: {
rules: [
{
test: /\.less/,
use: ['style-loader', 'css-loader', 'less-loader'],
exclude: /node_modules/,
include: path.resolve(__dirname, 'src')
},
{
test: /\.scss/,
use: ['style-loader', 'css-loader', 'sass-loader'],
exclude: /node_modules/,
include: path.resolve(__dirname, 'src')
}
]
}
} 7.支持转义 ES6/ES7/JSX
ES6/ES7/JSX 转义需要 Babel 的依赖,支持装饰器。
npm install --save-dev @babel/core babel-loader @babel/preset-env @babel/preset-react @babel/plugin-proposal-decorators @babel/plugin-proposal-object-rest-spread在 webpack.config.js 中增加 loader 的配置(module.rules 数组中)。
module.exports = {
//other code
module: {
rules: [
{
test: /\.jsx?$/,
use: [
{
loader: 'babel-loader',
options: {
presets: ['@babel/preset-env', '@babel/react'],
plugins: [
[require("@babel/plugin-proposal-decorators"), { "legacy": true }]
]
}
}
],
include: path.resolve(__dirname, 'src'),
exclude: /node_modules/
},
]
}
}8.压缩JS文件
安装依赖:
npm install --save-dev uglifyjs-webpack-plugin
npm install --save-dev optimize-css-assets-webpack-plugin在 webpack.config.js 中增加 optimization 的配置
const UglifyWebpackPlugin = require('uglifyjs-webpack-plugin');
module.exports = {
//other code
optimization: {
minimizer: [
new UglifyWebpackPlugin({
parallel: 4
})
]
}
}9.分离CSS(如果CSS文件较大的话)
因为CSS的下载和JS可以并行,当一个HTML文件很大的时候,可以把CSS单独提取出来加载
npm install --save-dev mini-css-extract-plugin在 webpack.config.js 中增加 plugins 的配置,并且将 'style-loader' 修改为 { loader: MiniCssExtractPlugin.loader}。
CSS打包在单独目录,那么配置filename。
const MiniCssExtractPlugin = require('mini-css-extract-plugin');
module.exports = {
//other code
module: {
rules: [
{
test: /\.css/,
use: [{ loader: MiniCssExtractPlugin.loader}, 'css-loader'],
exclude: /node_modules/,
include: path.resolve(__dirname, 'src')
},
{
test: /\.less/,
use: [{ loader: MiniCssExtractPlugin.loader }, 'css-loader', 'less-loader'],
exclude: /node_modules/,
include: path.resolve(__dirname, 'src')
},
{
test: /\.scss/,
use: [{ loader: MiniCssExtractPlugin.loader }, 'css-loader', 'sass-loader'],
exclude: /node_modules/,
include: path.resolve(__dirname, 'src')
},
]
},
plugins: [
new MiniCssExtractPlugin({
filename: 'css/[name].css'
})
]
}10.压缩CSS文件
安装依赖:
npm install --save-dev optimize-css-assets-webpack-plugin在 webpack.config.js 中的 optimization 中增加配置
const OptimizeCssAssetsWebpackPlugin = require('optimize-css-assets-webpack-plugin');
module.exports = {
//other code
optimization: {
minimizer: [
new OptimizeCssAssetsWebpackPlugin()
]
}
}11.打包前先清空输出目录
npm install --save-dev clean-webpack-plugin在 webpack.config.js 中增加 plugins 的配置
const CleanWebpackPlugin = require('clean-webpack-plugin');
module.exports = {
//other code
plugins: [
new CleanWebpackPlugin()
]
}至此,webpack配置已经基本能满足需求。
完整webpack.config.js和package.json文件
webpack.config.js文件:
const path = require('path');
const htmlWebpackPlugin = require('html-webpack-plugin');
const UglifyWebpackPlugin = require('uglifyjs-webpack-plugin');
const MiniCssExtractPlugin = require('mini-css-extract-plugin');
const CleanWebpackPlugin = require('clean-webpack-plugin');
const OptimizeCssAssetsWebpackPlugin = require('optimize-css-assets-webpack-plugin');
module.exports = {
entry: path.resolve(__dirname, 'src/index.js'),
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js',
publicPath: '/'
},
devServer: {
contentBase: './dist',
port: '8080',
host: 'localhost'
},
module: {
rules: [
{
test: /\.jsx?$/,
use: [
{
loader: 'babel-loader',
options: {
presets: ['@babel/preset-env', '@babel/react'],
plugins: [
[require("@babel/plugin-proposal-decorators"), { "legacy": true }]
]
}
}
],
include: path.resolve(__dirname, 'src'),
exclude: /node_modules/
},
{
test: /\.css/,
use: [{ loader: MiniCssExtractPlugin.loader}, 'css-loader'],
exclude: /node_modules/,
include: path.resolve(__dirname, 'src')
},
{
test: /\.less/,
use: [{ loader: MiniCssExtractPlugin.loader }, 'css-loader', 'less-loader'],
exclude: /node_modules/,
include: path.resolve(__dirname, 'src')
},
{
test: /\.scss/,
use: [{ loader: MiniCssExtractPlugin.loader }, 'css-loader', 'sass-loader'],
exclude: /node_modules/,
include: path.resolve(__dirname, 'src')
},
{
test: /\.(gif|jpg|png|bmp|eot|woff|woff2|ttf|svg)/,
use: [
{
loader: 'url-loader',
options: {
limit: 1024,
outputPath: 'images'
}
}
]
}
]
},
optimization: {
minimizer: [
new UglifyWebpackPlugin({
parallel: 4
}),
new OptimizeCssAssetsWebpackPlugin()
]
},
plugins: [
new htmlWebpackPlugin({
template: path.resolve(__dirname, 'src/index.html'),
}),
new MiniCssExtractPlugin({
filename: 'css/[name].css'
}),
new CleanWebpackPlugin()
]
}package.json文件:
{
"name": "webpk",
"version": "1.0.0",
"description": "",
"main": "webpack.config.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "webpack --mode production",
"dev": "webpack-dev-server --mode development"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"@babel/core": "^7.4.0",
"@babel/plugin-proposal-decorators": "^7.4.0",
"@babel/plugin-proposal-object-rest-spread": "^7.4.0",
"@babel/preset-env": "^7.4.1",
"@babel/preset-react": "^7.0.0",
"babel-loader": "^8.0.5",
"clean-webpack-plugin": "^2.0.1",
"css-loader": "^2.1.1",
"file-loader": "^3.0.1",
"html-webpack-plugin": "^3.2.0",
"less": "^3.9.0",
"less-loader": "^4.1.0",
"mini-css-extract-plugin": "^0.5.0",
"node-sass": "^4.11.0",
"optimize-css-assets-webpack-plugin": "^5.0.1",
"sass-loader": "^7.1.0",
"style-loader": "^0.23.1",
"uglifyjs-webpack-plugin": "^2.1.2",
"url-loader": "^1.1.2",
"webpack": "^4.29.6",
"webpack-cli": "^3.3.0",
"webpack-dev-server": "^3.2.1"
},
"dependencies": {
"react": "^16.8.4",
"react-dom": "^16.8.4",
"react-redux": "^6.0.1",
"redux": "^4.0.1"
}
}更多loader和plugin的参数可以参考:
https://www.webpackjs.com/loaders/
https://www.webpackjs.com/plugins/
如果你有其它的webpack配置需求,欢迎留言~
欢迎关注小姐姐的微信公众号,加入技术交流群。
你确定 typeof === ‘object’ || typeof === 'function' 的都是复杂类型吗?
翻译: 刘小夕
原文链接:https://css-tricks.com/understanding-the-almighty-reducer/
有一些小伙伴,对JavaScript的 reduce 方法还不够理解,我们来看下面两段代码:
const nums = [1, 2, 3];
let value = 0;
for (let i = 0; i < nums.length; i++) {
value += nums[i];
}const nums = [1, 2, 3];
const value = nums.reduce((ac, next) => ac + next, 0);这两段代码在功能上是等价的,都是数组中所有数字的总和,但是它们之间有一些理念差异。让我们先研究一下 reducer,因为它们功能强大,而且在编程中很重要。有成百上千篇关于 reducer 的文章,最后我会链接我喜欢的文章。
reducer 是什么要理解 reducer 的第一点也是最重要的一点是它永远返回一个值,这个值可以是数字、字符串、数组或对象,但它始终只能是一个。reducer 对于很多场景都很适用,但是它们对于将一种逻辑应用到一组值中并最终得到一个单一结果的情况特别适用。
另外需要说明:reducer 本质上不会改变你的初始值;相反,它们会返回一些其他的东西。
让我们回顾一下第一个例子,这样你就可以看到这里发生了什么,一起看一下下面的gif:
观看gif也许对我们所有帮助,不过还是要回归代码:
const nums = [1, 2, 3];
let value = 0;
for (let i = 0; i < nums.length; i++) {
value += nums[i];
}数组 nums ([1,2,3]) ,数组中的每个数字的第一个值将被添加到 value (0)。我们遍历数组并将其每一项添加到 value。
让我们尝试一下不同的方法来实现此功能:
const nums = [1, 2, 3];
const initialValue = 0;
const reducer = function (acc, item) {
return acc + item;
}
const total = nums.reduce(reducer, initialValue);现在我们有了相同的数组,但这次我们不会改变初始值(即前段代码中的 value)。这里,我们有一个仅在开始时使用的初始值。接下来,我们可以创建一个函数,它接受一个累加器(acc)和一个项(item)。累加器是在上一次调用中返回的累积值(或者是 initialValue),是下一个回调的输入值。在这个例子中,你可以把它想象成一个滚下一座山的雪球,当它以每一个吃过的值的大小增长时,它会吃掉它路径中的每个值。
我们将使用 .reduce() 来接收这个函数并从初始值开始。可以使用箭头函数简写:
const nums = [1, 2, 3];
const initialValue = 0;
const reducer = (acc, item) => {
return acc + item;
}
const total = nums.reduce(reducer, initialValue);进一步缩短代码长度,我们知道箭头函数,在没有 {} 时,默认 return;
const nums = [1, 2, 3];
const initialValue = 0;
const reducer = (acc, item) => acc + item;
const total = nums.reduce(reducer, initialValue);现在我们可以在调用它的地方应用这个函数,也可以直接设置初始值,如下:
const nums = [1, 2, 3];
const total = nums.reduce((acc, item) => acc + item, 0);累加器可能是一个令人生畏的术语,所以当我们在回调调用上应用逻辑时,你可以将它想象成数组的当前状态。
如果不清楚发生了什么,让我们记录下每次迭代的情况。reduce 使用的回调函数将针对数组中的每个项运行。下面的演示将有助于更清楚地说明这一点。我使用了一个不同的数组([1,3,6]),因为数字与索引相同可能会令人困惑。
const nums = [1, 3, 6];
const reducer4 = function (acc, item) {
console.log(`Acc: ${acc}, Item: ${item}, Return value: ${acc + item}`);
return acc + item;
}
const total4 = nums.reduce(reducer4, 0);当我们执行这段代码时,我们会在控制台看到以下输出:
Acc: 0, Item: 1, Return value: 1
Acc: 1, Item: 3, Return value: 4
Acc: 4, Item: 6, Return value: 10下面是一个更直观的分解:
acc)从初始值(initialValue):0 开始的item是1,所以返回值是1(0+1=1)acc),item (数组的第二项)是3item 是6既然我们已经掌握了这一点,那么让我们来看看 reducer 可以做的一些常见和有用的事情。
假设您有一个数字数组,并且希望返回一个报告这些数字在数组中出现的次数的对象。请注意,这同样适用于字符串。
const nums = [3, 5, 6, 82, 1, 4, 3, 5, 82];
const result = nums.reduce((tally, amt) => {
tally[amt] ? tally[amt]++ : tally[amt] = 1;
return tally;
}, {});
console.log(result);
//{ '1': 1, '3': 2, '4': 1, '5': 2, '6': 1, '82': 2 }最初,我们有一个数组和将要放入其中的对象。在 reducer 中,我们首先判断这个item是否存在于累加器中,如果是存在,加1。如果不存在,添加这一项并设置为1。最后,请返回每一项出现的次数。然后,我们运行reduce函数,同时传递 reducer 和初始值。
假设我们有一个数组,我们希望基于一组条件创建一个对象。reduce 在这里非常适用!现在,我们希望从数组中任意一个数字项创建一个对象,并同时显示该数字的奇数和偶数版本。
const nums = [3, 5, 6, 82, 1, 4, 3, 5, 82];
// we're going to make an object from an even and odd
// version of each instance of a number
const result = nums.reduce((acc, item) => {
acc[item] = {
odd: item % 2 ? item : item - 1,
even: item % 2 ? item + 1 : item
}
return acc;
}, {});
console.log(result);控制台输出结果:
{ '1': { odd: 1, even: 2 },
'3': { odd: 3, even: 4 },
'4': { odd: 3, even: 4 },
'5': { odd: 5, even: 6 },
'6': { odd: 5, even: 6 },
'82': { odd: 81, even: 82 }
}当我们遍历数组中的每一项时,我们为偶数和奇数创建一个属性,并且基于一个带模数运算符的内联条件,我们要么存储该数字,要么将其递增1。模算符非常适合这样做,因为它可以快速检查偶数或奇数 —— 如果它可以被2整除,它是偶数,如果不是,它是奇数。
在顶部,我提到了其他一些便利的文章,这些文章有助于更熟悉 reducer 的作用。以下是我的最爱:
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。 https://github.com/YvetteLau/Blog
Promise是前端面试中的高频问题,我作为面试官的时候,问Promise的概率超过90%,据我所知,大多数公司,都会问一些关于Promise的问题。如果你能根据PromiseA+的规范,写出符合规范的源码,那么我想,对于面试中的Promise相关的问题,都能够给出比较完美的答案。
我的建议是,对照规范多写几次实现,也许第一遍的时候,是改了多次,才能通过测试,那么需要反复的写,我已经将Promise的源码实现写了不下七遍。
/**
* 1. new Promise时,需要传递一个 executor 执行器,执行器立刻执行
* 2. executor 接受两个参数,分别是 resolve 和 reject
* 3. promise 只能从 pending 到 rejected, 或者从 pending 到 fulfilled
* 4. promise 的状态一旦确认,就不会再改变
* 5. promise 都有 then 方法,then 接收两个参数,分别是 promise 成功的回调 onFulfilled,
* 和 promise 失败的回调 onRejected
* 6. 如果调用 then 时,promise已经成功,则执行 onFulfilled,并将promise的值作为参数传递进去。
* 如果promise已经失败,那么执行 onRejected, 并将 promise 失败的原因作为参数传递进去。
* 如果promise的状态是pending,需要将onFulfilled和onRejected函数存放起来,等待状态确定后,再依次将对应的函数执行(发布订阅)
* 7. then 的参数 onFulfilled 和 onRejected 可以缺省
* 8. promise 可以then多次,promise 的then 方法返回一个 promise
* 9. 如果 then 返回的是一个结果,那么就会把这个结果作为参数,传递给下一个then的成功的回调(onFulfilled)
* 10. 如果 then 中抛出了异常,那么就会把这个异常作为参数,传递给下一个then的失败的回调(onRejected)
* 11.如果 then 返回的是一个promise,那么需要等这个promise,那么会等这个promise执行完,promise如果成功,
* 就走下一个then的成功,如果失败,就走下一个then的失败
*/
const PENDING = 'pending';
const FULFILLED = 'fulfilled';
const REJECTED = 'rejected';
function Promise(executor) {
let self = this;
self.status = PENDING;
self.onFulfilled = [];//成功的回调
self.onRejected = []; //失败的回调
//PromiseA+ 2.1
function resolve(value) {
if (self.status === PENDING) {
self.status = FULFILLED;
self.value = value;
self.onFulfilled.forEach(fn => fn());//PromiseA+ 2.2.6.1
}
}
function reject(reason) {
if (self.status === PENDING) {
self.status = REJECTED;
self.reason = reason;
self.onRejected.forEach(fn => fn());//PromiseA+ 2.2.6.2
}
}
try {
executor(resolve, reject);
} catch (e) {
reject(e);
}
}
Promise.prototype.then = function (onFulfilled, onRejected) {
//PromiseA+ 2.2.1 / PromiseA+ 2.2.5 / PromiseA+ 2.2.7.3 / PromiseA+ 2.2.7.4
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : value => value;
onRejected = typeof onRejected === 'function' ? onRejected : reason => { throw reason };
let self = this;
//PromiseA+ 2.2.7
let promise2 = new Promise((resolve, reject) => {
if (self.status === FULFILLED) {
//PromiseA+ 2.2.2
//PromiseA+ 2.2.4 --- setTimeout
setTimeout(() => {
try {
//PromiseA+ 2.2.7.1
let x = onFulfilled(self.value);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
//PromiseA+ 2.2.7.2
reject(e);
}
});
} else if (self.status === REJECTED) {
//PromiseA+ 2.2.3
setTimeout(() => {
try {
let x = onRejected(self.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
});
} else if (self.status === PENDING) {
self.onFulfilled.push(() => {
setTimeout(() => {
try {
let x = onFulfilled(self.value);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
});
});
self.onRejected.push(() => {
setTimeout(() => {
try {
let x = onRejected(self.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
});
});
}
});
return promise2;
}
function resolvePromise(promise2, x, resolve, reject) {
let self = this;
//PromiseA+ 2.3.1
if (promise2 === x) {
reject(new TypeError('Chaining cycle'));
}
if (x && typeof x === 'object' || typeof x === 'function') {
let used; //PromiseA+2.3.3.3.3 只能调用一次
try {
let then = x.then;
if (typeof then === 'function') {
//PromiseA+2.3.3
then.call(x, (y) => {
//PromiseA+2.3.3.1
if (used) return;
used = true;
resolvePromise(promise2, y, resolve, reject);
}, (r) => {
//PromiseA+2.3.3.2
if (used) return;
used = true;
reject(r);
});
}else{
//PromiseA+2.3.3.4
if (used) return;
used = true;
resolve(x);
}
} catch (e) {
//PromiseA+ 2.3.3.2
if (used) return;
used = true;
reject(e);
}
} else {
//PromiseA+ 2.3.3.4
resolve(x);
}
}
module.exports = Promise;有专门的测试脚本可以测试所编写的代码是否符合PromiseA+的规范。
首先,在promise实现的代码中,增加以下代码:
Promise.defer = Promise.deferred = function () {
let dfd = {};
dfd.promise = new Promise((resolve, reject) => {
dfd.resolve = resolve;
dfd.reject = reject;
});
return dfd;
}安装测试脚本:
npm install -g promises-aplus-tests如果当前的promise源码的文件名为promise.js
那么在对应的目录执行以下命令:
promises-aplus-tests promise.jspromises-aplus-tests**有872条测试用例。以上代码,可以完美通过所有用例。
对上面的代码实现做一点简要说明(其它一些内容注释中已经写得很清楚):
onFulfilled 和 onFulfilled的调用需要放在setTimeout,因为规范中表示: onFulfilled or onRejected must not be called until the execution context stack contains only platform code。使用setTimeout只是模拟异步,原生Promise并非是这样实现的。
在 resolvePromise 的函数中,为何需要usedd这个flag,同样是因为规范中明确表示: If both resolvePromise and rejectPromise are called, or multiple calls to the same argument are made, the first call takes precedence, and any further calls are ignored. 因此我们需要这样的flag来确保只会执行一次。
self.onFulfilled 和 self.onRejected 中存储了成功的回调和失败的回调,根据规范2.6显示,当promise从pending态改变的时候,需要按照顺序去指定then对应的回调。
PS: 下面是我翻译的规范,供参考
术语
要求
Promise 必须处于以下三个状态之一: pending, fulfilled 或者是 rejected
2.1.1.1 可以变成 fulfilled 或者是 rejected
2.1.2.1 不会变成其它状态
2.1.2.2 必须有一个value值
2.1.3.1 不会变成其它状态
2.1.3.2 必须有一个promise被reject的reason
概括即是:promise的状态只能从pending变成fulfilled,或者从pending变成rejected.promise成功,有成功的value.promise失败的话,有失败的原因
promise必须提供一个then方法,来访问最终的结果
promise的then方法接收两个参数
promise.then(onFulfilled, onRejected)2.2.1.1 onFulfilled 必须是函数类型
2.2.1.2 onRejected 必须是函数类型
2.2.2.1 必须在promise变成 fulfilled 时,调用 onFulfilled,参数是promise的value
2.2.2.2 在promise的状态不是 fulfilled 之前,不能调用
2.2.2.3 onFulfilled 只能被调用一次
2.2.3.1 必须在promise变成 rejected 时,调用 onRejected,参数是promise的reason
2.2.3.2 在promise的状态不是 rejected 之前,不能调用
2.2.3.3 onRejected 只能被调用一次
2.2.6.1 如果promise变成了 fulfilled态,所有的onFulfilled回调都需要按照then的顺序执行
2.2.6.2 如果promise变成了 rejected态,所有的onRejected回调都需要按照then的顺序执行
promise2 = promise1.then(onFulfilled, onRejected);2.2.7.1 onFulfilled 或 onRejected 执行的结果为x,调用 resolvePromise
2.2.7.2 如果 onFulfilled 或者 onRejected 执行时抛出异常e,promise2需要被reject
2.2.7.3 如果 onFulfilled 不是一个函数,promise2 以promise1的值fulfilled
2.2.7.4 如果 onRejected 不是一个函数,promise2 以promise1的reason rejected
resolvePromise(promise2, x, resolve, reject)
2.3.2.1 如果x是pending态,那么promise必须要在pending,直到 x 变成 fulfilled or rejected.
2.3.2.2 如果 x 被 fulfilled, fulfill promise with the same value.
2.3.2.3 如果 x 被 rejected, reject promise with the same reason.
2.3.3.1 let then = x.then.
2.3.3.2 如果 x.then 这步出错,那么 reject promise with e as the reason..
2.3.3.3 如果 then 是一个函数,then.call(x, resolvePromiseFn, rejectPromise)
2.3.3.3.1 resolvePromiseFn 的 入参是 y, 执行 resolvePromise(promise2, y, resolve, reject);
2.3.3.3.2 rejectPromise 的 入参是 r, reject promise with r.
2.3.3.3.3 如果 resolvePromise 和 rejectPromise 都调用了,那么第一个调用优先,后面的调用忽略。
2.3.3.3.4 如果调用then抛出异常e
2.3.3.3.4.1 如果 resolvePromise 或 rejectPromise 已经被调用,那么忽略
2.3.3.3.4.3 否则,reject promise with e as the reason
2.3.3.4 如果 then 不是一个function. fulfill promise with x.
虽然上述的promise源码已经符合PromiseA+的规范,但是原生的Promise还提供了一些其他方法,如:
下面具体说一下每个方法的实现:
Promise.resolve
Promise.resolve(value) 返回一个以给定值解析后的Promise 对象.
Promise.resolve = function (param) {
if (param instanceof Promise) {
return param;
}
return new Promise((resolve, reject) => {
if (param && param.then && typeof param.then === 'function') {
setTimeout(() => {
param.then(resolve, reject);
});
} else {
resolve(param);
}
});
}thenable对象的执行加 setTimeout的原因是根据原生Promise对象执行的结果推断的,如下的测试代码,原生的执行结果为: 20 400 30;为了同样的执行顺序,增加了setTimeout延时。
测试代码:
let p = Promise.resolve(20);
p.then((data) => {
console.log(data);
});
let p2 = Promise.resolve({
then: function(resolve, reject) {
resolve(30);
}
});
p2.then((data)=> {
console.log(data)
});
let p3 = Promise.resolve(new Promise((resolve, reject) => {
resolve(400)
}));
p3.then((data) => {
console.log(data)
});Promise.reject
Promise.reject方法和Promise.resolve不同,Promise.reject()方法的参数,会原封不动地作为reject的理由,变成后续方法的参数。
Promise.reject = function (reason) {
return new Promise((resolve, reject) => {
reject(reason);
});
}Promise.prototype.catch
Promise.prototype.catch 用于指定出错时的回调,是特殊的then方法,catch之后,可以继续 .then
Promise.prototype.catch = function (onRejected) {
return this.then(null, onRejected);
}Promise.prototype.finally
不管成功还是失败,都会走到finally中,并且finally之后,还可以继续then。并且会将值原封不动的传递给后面的then.
Promise.prototype.finally = function (callback) {
return this.then((value) => {
return Promise.resolve(callback()).then(() => {
return value;
});
}, (err) => {
return Promise.resolve(callback()).then(() => {
throw err;
});
});
}Promise.all
Promise.all(promises) 返回一个promise对象
Promise.all = function (promises) {
return new Promise((resolve, reject) => {
let index = 0;
let result = [];
if (promises.length === 0) {
resolve(result);
} else {
function processValue(i, data) {
result[i] = data;
if (++index === promises.length) {
resolve(result);
}
}
for (let i = 0; i < promises.length; i++) {
//promises[i] 可能是普通值
Promise.resolve(promises[i]).then((data) => {
processValue(i, data);
}, (err) => {
reject(err);
return;
});
}
}
});
}
测试代码:
var promise1 = new Promise((resolve, reject) => {
resolve(3);
})
var promise2 = 42;
var promise3 = new Promise(function(resolve, reject) {
setTimeout(resolve, 100, 'foo');
});
Promise.all([promise1, promise2, promise3]).then(function(values) {
console.log(values); //[3, 42, 'foo']
},(err)=>{
console.log(err)
});
var p = Promise.all([]); // will be immediately resolved
var p2 = Promise.all([1337, "hi"]); // non-promise values will be ignored, but the evaluation will be done asynchronously
console.log(p);
console.log(p2)
setTimeout(function(){
console.log('the stack is now empty');
console.log(p2);
});Promise.race
Promise.race函数返回一个 Promise,它将与第一个传递的 promise 相同的完成方式被完成。它可以是完成( resolves),也可以是失败(rejects),这要取决于第一个完成的方式是两个中的哪个。
如果传的参数数组是空,则返回的 promise 将永远等待。
如果迭代包含一个或多个非承诺值和/或已解决/拒绝的承诺,则 Promise.race 将解析为迭代中找到的第一个值。
Promise.race = function (promises) {
return new Promise((resolve, reject) => {
if (promises.length === 0) {
return;
} else {
for (let i = 0; i < promises.length; i++) {
Promise.resolve(promises[i]).then((data) => {
resolve(data);
return;
}, (err) => {
reject(err);
return;
});
}
}
});
}测试代码:
Promise.race([
new Promise((resolve, reject) => { setTimeout(() => { resolve(100) }, 1000) }),
undefined,
new Promise((resolve, reject) => { setTimeout(() => { reject(100) }, 100) })
]).then((data) => {
console.log('success ', data);
}, (err) => {
console.log('err ',err);
});
Promise.race([
new Promise((resolve, reject) => { setTimeout(() => { resolve(100) }, 1000) }),
new Promise((resolve, reject) => { setTimeout(() => { resolve(200) }, 200) }),
new Promise((resolve, reject) => { setTimeout(() => { reject(100) }, 100) })
]).then((data) => {
console.log(data);
}, (err) => {
console.log(err);
});欢迎关注小姐姐的微信公众号,加入技术交流群。
其实使用 typeof 加上 Object.prototype.toString.call() 就可以正确判断类型。前者用于判断是原始类型还是引用类型,后者用于精确判断。
Step-By-Step (点击进入项目) 是我于
2019-05-20开始的一个项目,每个工作日发布一道面试题。每个周末我会仔细阅读大家的答案,整理最一份较优答案出来,因本人水平有限,有误的地方,大家及时指正。
如果想 加群 学习,可以通过文末的公众号,添加我为好友。
本周面试题一览:
在实现 Promise.race 方法之前,我们首先要知道 Promise.race 的功能和特点,因为在清楚了 Promise.race 功能和特点的情况下,我们才能进一步去写实现。
Promise.race(iterable) 返回一个 promise,一旦 iterable 中的一个 promise 状态是 fulfilled / rejected ,那么 Promise.race 返回的 promise 状态是 fulfilled / rejected.
let p = Promise.race([p1, p2, p3]);只要p1、p2、p3之中有一个实例率先改变状态,p的状态就跟着改变。那个率先改变的 Promise 实例的返回值,就传递给 p 的回调函数。
Promise.race 的返回值是一个 promise 实例
Promise.race 返回的 promise 永远是 pending 态promise,Promise.race 会返回一个处理中(pending)的 promiseiterable 包含一个或多个非 promise 值或已经解决的promise,则 Promise.race 将解析为 iterable 中找到的第一个值。Promise.race = function (promises) {
//promises传入的是可迭代对象(省略参数合法性判断)
promises = Array.from(promises);//将可迭代对象转换为数组
return new Promise((resolve, reject) => {
if (promises.length === 0) {
//空的可迭代对象;
//用于在pending态
} else {
for (let i = 0; i < promises.length; i++) {
Promise.resolve(promises[i]).then((data) => {
resolve(data);
}).catch((reason) => {
reject(reason);
})
}
}
});
}尽管浏览器有同源策略,但是 <script> 标签的 src 属性不会被同源策略所约束,可以获取任意服务器上的脚本并执行。jsonp 通过插入 script 标签的方式来实现跨域,参数只能通过 url 传入,仅能支持 get 请求。
function jsonp({url, params, callback}) {
return new Promise((resolve, reject) => {
//创建script标签
let script = document.createElement('script');
//将回调函数挂在 window 上
window[callback] = function(data) {
resolve(data);
//代码执行后,删除插入的script标签
document.body.removeChild(script);
}
//回调函数加在请求地址上
params = {...params, callback} //wb=b&callback=show
let arrs = [];
for(let key in params) {
arrs.push(`${key}=${params[key]}`);
}
script.src = `${url}?${arrs.join('&')}`;
document.body.appendChild(script);
});
}使用:
function show(data) {
console.log(data);
}
jsonp({
url: 'http://localhost:3000/show',
params: {
//code
},
callback: 'show'
}).then(data => {
console.log(data);
});服务端代码(node):
//express启动一个后台服务
let express = require('express');
let app = express();
app.get('/show', (req, res) => {
let {callback} = req.query; //获取传来的callback函数名,callback是key
res.send(`${callback}('Hello!')`);
});
app.listen(3000);SetSet类似于数组,但是成员的值都是唯一的,没有重复的值。
function uniq(arry) {
return [...new Set(arry)];
}indexOffunction uniq(arry) {
var result = [];
for (var i = 0; i < arry.length; i++) {
if (result.indexOf(arry[i]) === -1) {
//如 result 中没有 arry[i],则添加到数组中
result.push(arry[i])
}
}
return result;
}includesfunction uniq(arry) {
var result = [];
for (var i = 0; i < arry.length; i++) {
if (!result.includes(arry[i])) {
//如 result 中没有 arry[i],则添加到数组中
result.push(arry[i])
}
}
return result;
}reducefunction uniq(arry) {
return arry.reduce((prev, cur) => prev.includes(cur) ? prev : [...prev, cur], []);
}Mapfunction uniq(arry) {
let map = new Map();
let result = new Array();
for (let i = 0; i < arry.length; i++) {
if (map.has(arry[i])) {
map.set(arry[i], true);
} else {
map.set(arry[i], false);
result.push(arry[i]);
}
}
return result;
}当容器的高度为auto,且容器的内容中有浮动(float为left或right)的元素,在这种情况下,容器的高度不能自动伸长以适应内容的高度,使得内容溢出到容器外面而影响(甚至破坏)布局的现象。这个现象叫浮动溢出,为了防止这个现象的出现而进行的CSS处理,就叫CSS清除浮动。
<style>
.inner {
width: 100px;
height: 100px;
float: left;
}
</style>
<div class='outer'>
<div class='inner'></div>
<div class='inner'></div>
<div class='inner'></div>
</div>clear 属性在 <div class='outer'> 内创建一个空元素,对其设置 clear: both; 的样式。
clear 属性 + 伪元素.outer:after{
content: '';
display: block;
clear: both;
visibility: hidden;
height: 0;
}IE8以上和非IE浏览器才支持:after,如果想要支持IE6、7,需要给 outer 元素,设置样式 zoom: 1;
根据 BFC 的规则,计算 BFC 的高度时,浮动元素也参与计算。因此清除浮动,只需要触发一个BFC即可。
可以使用以下方法来触发BFC
如:
.outer {
overflow: hidden;
}注意使用 display: inline-block 会产生间隙。
在开始之前,我们首先需要搞清楚函数柯里化的概念。
函数柯里化是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
const currying = (fn, ...args) =>
args.length < fn.length
//参数长度不足时,重新柯里化该函数,等待接受新参数
? (...arguments) => currying(fn, ...args, ...arguments)
//参数长度满足时,执行函数
: fn(...args);function sumFn(a, b, c) {
return a + b + c;
}
var sum = currying(sumFn);
console.log(sum(2)(3)(5));//10
console.log(sum(2, 3, 5));//10
console.log(sum(2)(3, 5));//10
console.log(sum(2, 3)(5));//10函数柯里化的主要作用:
[1] 珠峰架构课(墙裂推荐)
[2] CSS-清除浮动
[3] 详解JS函数柯里化
[4] JavaScript数组去重
谢谢各位小伙伴愿意花费宝贵的时间阅读本文,如果本文给了您一点帮助或者是启发,请不要吝啬你的赞和Star,您的肯定是我前进的最大动力。 https://github.com/YvetteLau/Blog
关注公众号,加入技术交流群。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.