zp1112 / blog Goto Github PK
View Code? Open in Web Editor NEW地址
Home Page: http://issue.suzper.com/
地址
Home Page: http://issue.suzper.com/





































原生Promise,拥有基本的then方法,并且在new一个Promise的时候传入一个函数,该函数的参数有resolve和reject(暂时不讨论),我们知道,在定义一个Promise的时候,js执行栈会先执行promise里面传入的这个函数,然后把resolve传给他,并注册一些then函数,再最终执行resolve的时候再把then注册的回调函数依次执行,类似于观察者模式,这也算为什么考察事件循环时,
new Promise((res, rej) => {
console.log(111); // 这里的打印正是在当前栈同步执行了这个回调函数。
setTimeout(() => console.log(222), 2000);
})
console.log(333)
会打印出
// 111 333 2秒后打印222根据上面的分析,我们写一个简单的能实现then功能的promise
function MyPromise(fn) {
const callbacks = []; // 存储then注册的回调函数
let value = null; // 当前最新resolve的值
this.then = function(callback) {
callbacks.push(callback); // 注册回调
return this; // 返回promise,用于链式
}
function resolve(newValue) {
value = newValue;
callbacks.forEach(function (callback) {
callback(value); // 依次执行回调
})
}
fn(resolve);
}
const p1 = new MyPromise(resolve => setTimeout(() => resolve(111), 1000)).then(data => console.log(data)); // 一秒后打印111但是我们发现当promise传入的是同步方法的时候,即立即resolve的时候,then来不及注册回调,这是由于事件循环导致的,同步方法顺序执行,因此需要将resolve函数的执行回调放到当前任务队列的最后,保证then注册完了所有回调函数
// 改造resolve
function resolve(newValue) {
value = newValue;
setTimeout(() => {
callbacks.forEach(function (callback) {
callback(value);
})
}, 0);
}
const p2 = new MyPromise(resolve => resolve(111)).then(data => console.log(data)); // 立即打印111
setTimeout(() => p2.then(data => console.log(data)), 0) // 打印不出data,是因为resolve已经结束了,在异步操作成功之前注册的回调都会执行,但是在Promise异步操作成功这之后调用的then注册的回调就再也不会执行了解决上述问题,可以在promise内部加入状态,就是pending、fulfilled、rejected(先不讲),如果处于pending状态,可以then注册回调函数,如果已经resolve成功,状态改为fulfilled,此时再再then里面注册的回调函数,直接使用最新的当前值value
function MyPromise(fn) {
const callbacks = [];
let value = null;
let state = 'pending';
this.then = function(callback) {
if (state === 'pending') {
callbacks.push(callback);
} else if (state === 'fulfilled') {
callback(value);
}
return this;
}
function resolve(newValue) {
state = 'fulfilled';
value = newValue;
setTimeout(() => {
callbacks.forEach(function (callback) {
callback(value);
})
}, 0);
}
fn(resolve);
}
// 都测试一下
const p1 = new MyPromise(resolve => setTimeout(() => resolve(111), 1000)).then(data => console.log(data));
setTimeout(() => p1.then(data => console.log(data)), 0) // 1秒后正常打印出111 111
const p2 = new MyPromise(resolve => resolve(111)).then(data => console.log(data));
setTimeout(() => p2.then(data => console.log(data)), 0) // 正常打印出111 111上述解决了异步和同步操作的问题,以及状态机制。
那么我们知道原生的promise的then里面可以返回一个promise,实现多个promise的链式调用,链式Promise是指在当前promise达到fulfilled状态后,即开始进行下一个promise(后邻promise)。那么我们如何衔接当前promise和后邻promise呢?由于目前的设计then里面都是普通回调函数,执行后返回的值直接调用resolve赋值给value,那么如果then注册了一个promise,就会在这个promise里面执行resolve,需要等待这个promise的异步操作,并将新的promise的值resolve传递给第一个promise的value。
promise1().then(promise2)promise1的resolve执行后,then回调函数执行,这个then函数需要负责把回调函数的值提到当层,便于给后面的回调函数使用,因此如果then传入的是一个promise2,需要想办法把promise2里层的resolve值拿到新层promise,那么最简单的办法就是在then里面返回一个新层promise,用新层的resolve,来截获promise2的resolve值。才能传递给后面的promise3使用,形象的来说就是你多个promise链式调用,需要每次使用一个新的promise来进行衔接。才能达到数据在各个promise之间游走。
让我们看看如何改造:
function MyPromise(fn) {
const callbacks = [];
let value = null;
let state = 'pending';
this.then = function(callback) {
return new MyPromise(resolve => {
if (state === 'pending') {
callbacks.push({
callback,
resolve
});
return;
} else if (state === 'fulfilled') {
resolve(callback(value));
return;
}
})
}
function resolve(newValue) {
if (newValue && (typeof newValue === 'object' || typeof newValue === 'function')) {
var then = newValue.then;
if (typeof then === 'function') {
then.call(newValue, resolve);
return;
}
}
state = 'fulfilled';
value = newValue;
setTimeout(() => {
callbacks.forEach(function (callback) {
callback.resolve(callback.callback ? callback.callback(value) : value);
})
}, 0);
}
fn(resolve);
}
const p3 = new MyPromise(resolve => setTimeout(() => resolve(111), 1000)).then(data => {
console.log(data)
return new MyPromise(resolve => setTimeout(() => resolve(222), 1000))
})
.then().then(data => {
console.log(data)
return new MyPromise(resolve => resolve(333)).then(data1 => {
console.log(data1)
})
});
// 正常打印
111
222
333总的来说前面几步都比较好理解,关于如何注册回调函数,如何在resolve的时候执行注册的回调函数,promise里面的then函数仅仅是注册了后续需要执行的代码,真正的执行是在resolve方法里面执行的。再根据原生promise的一些特性,逐个进行分析,实现一些功能。boom!!!!
raycaster通过鼠标位置拾取鼠标所在的物体。
onDocumentMouseOver: function (event) {
const mouse = new THREE.Vector2();
mouse.x = (event.clientX / this.width) * 2 - 1;
mouse.y = - (event.clientY / this.height) * 2 + 1;
this.raycaster.setFromCamera(mouse, this.camera);
let intersects = this.raycaster.intersectObjects(this.scene.children, true);
}得到的intersects可能有多个,根据场景中的物体深度排序,但是有时候会出现两个物体重叠的时候,可能我们需要使用renderOrder来将两个物体进行先后渲染,比如物体A和物体B,假设物体B的renderOrder为2,物体A的renderOrder为1,那么我们会先看到物体B,假设渲染代码如下:
cubeA.material.depthTest = false;
cubeA.renderOrder = 1;
scene.add(cubeA);
cubeB.material.depthTest = false;
cubeB.renderOrder = 2;
scene.add(cubeB);以上代码物体B的renderOrder虽然比物体A的大,但是后加入场景,因此raycaster射线击中反馈的数组中还是按照正常的场景进行深度计算,而与renderOrder顺序无关。那么有一种办法可以解决你想用raycaster拾取到renderOrder最大的重叠物体,很简单,将拾取到的物体数组按照renderOrder排个序,然后取intersects[0]即可。
花了一天时间,看了很多文章,大体上是理解了react的render机制,以及不可变数据在render机制中起到的作用。
安装一个工具可以检测组件是否发生了不必要的渲染。如果发生了不必要的组件渲染,控制台会精确定位并且打印出那些状态触发了不必要的渲染。然后针对性的进行优化,简直是神器啊。
npm i -D why-did-you-update在index.js加
if (process.env.NOED_ENV !== 'production') {
const { whyDidYouUpdate } = require('why-did-you-update');
whyDidYouUpdate(React);
}class App extends component {
constructor(props) {
super(props);
this.state = {
count: 0,
user: {
name: 'zp'
}
}
}
handleClick = () => {
this.setState({
count: 0
});
}
render() {
return (
<div>
<div onClick={this.handleClick}>点击我</div>
<div>{this.state.count}</div>
</div>
);
}
}保存文件,打开页面,点击点击我,会发现控制台打印出了一个console,提示这个render是不必要的render,count并没有改变,但是组件却重新渲染了。

PureComponent是react自带的继承了component的类,但是在组件re-render的时候加了一层判断,浅比较新的状态和旧的状态是否一致,如果新旧状态的引用不一致,则比较第一层状态值是否改变,上面的例子中count为第一层,值没有改变,所以不重新渲染。
class App extends PureComponent {
// ...代码
}为什么说是浅比较,那是因为假设我现在改更新的是user里面的name属性,name我们看看即便加了purecomponent,是否还会发生不必要的渲染呢。
修改handleClick
handleClick = () => {
this.setState({
user: {
name: 'zp'
}
});
}此时页面console,依然打印出不必要渲染,告知这里的不必要渲染造成的原因是user的引用改变了。
由于purecomponent只比较第一层,所以第二层的user下面的值{name: 'zp'}是个引用。引用改变了,值就不一样了,就会触发re-render。相当于

deepEquals = (obj1, obj2) => {
if (obj1 === obj2) {
return true;
}
for (const key of Object.keys(obj2)) {
if (obj1.hasOwnProperty(key) && obj1[key] === obj2[key]) {
return true;
}
}
return false;
}
shouldComponentUpdate = (nextProps, nextState) => {
return !this.deepEquals(this.state, nextState) || !this.deepEquals(this.props, nextProps);
}手写shouldComponentUpdate和加purecomponent的效果是一样的,只能浅比较。
所以purecomponent解决了浅层次的dom渲染优化,但是对于结构更加复杂的嵌套的数据结构,还是会发生不必要的渲染。
网上很火的数据结构immutable.js,似乎很好的解决了这个问题,让我们看看如何简单的使用immutable.js改造上面的例子
首先本地安装immutable.js。
npm i --save immutable这里我们先把state改造一下,使用immutable的API改造handleClick,最后render里面的dom渲染再使用API改造一下
this.state = {
data: Immutable.fromJS({
count: 0,
user: {
name: 'zp'
}
})
}
handleClick = () => {
this.setState((d) => {
return {
data: d.data.updateIn(['user', 'name'], () => 'zp') // 这里改变了user里面的name,深层改变
}
})
}
render() {
const data = this.state.data;
return (
<div>
<div onClick={this.handleClick}>点击我</div>
<div>{data.get('count')}</div>
<div>{data.getIn(['user', 'name'])}</div>
</div>
);
}保存刷新页面,点击,会发现并没有多余的render。cool!
我觉得这样看来,immutable.js真的很强大很诱人,看到没有浪费的render,这让有强迫症的开发人员感到很舒服,但是网上看到immutable.js的弊端也有些,
如果不用ImmutableJS ,那么就要尽量避免使用复杂的结构,最好扁平化数据结构,但是。。。。那是不可能的!!所以,你们看着办吧。
我只想说,虽然我现在的项目并没有使用react,甚至我也没用过ImmutableJS ,但是我对react的爱是不变的,我会保持学习,一直进步。。。。嘿,小哥,招前端吗?
实现效果如下
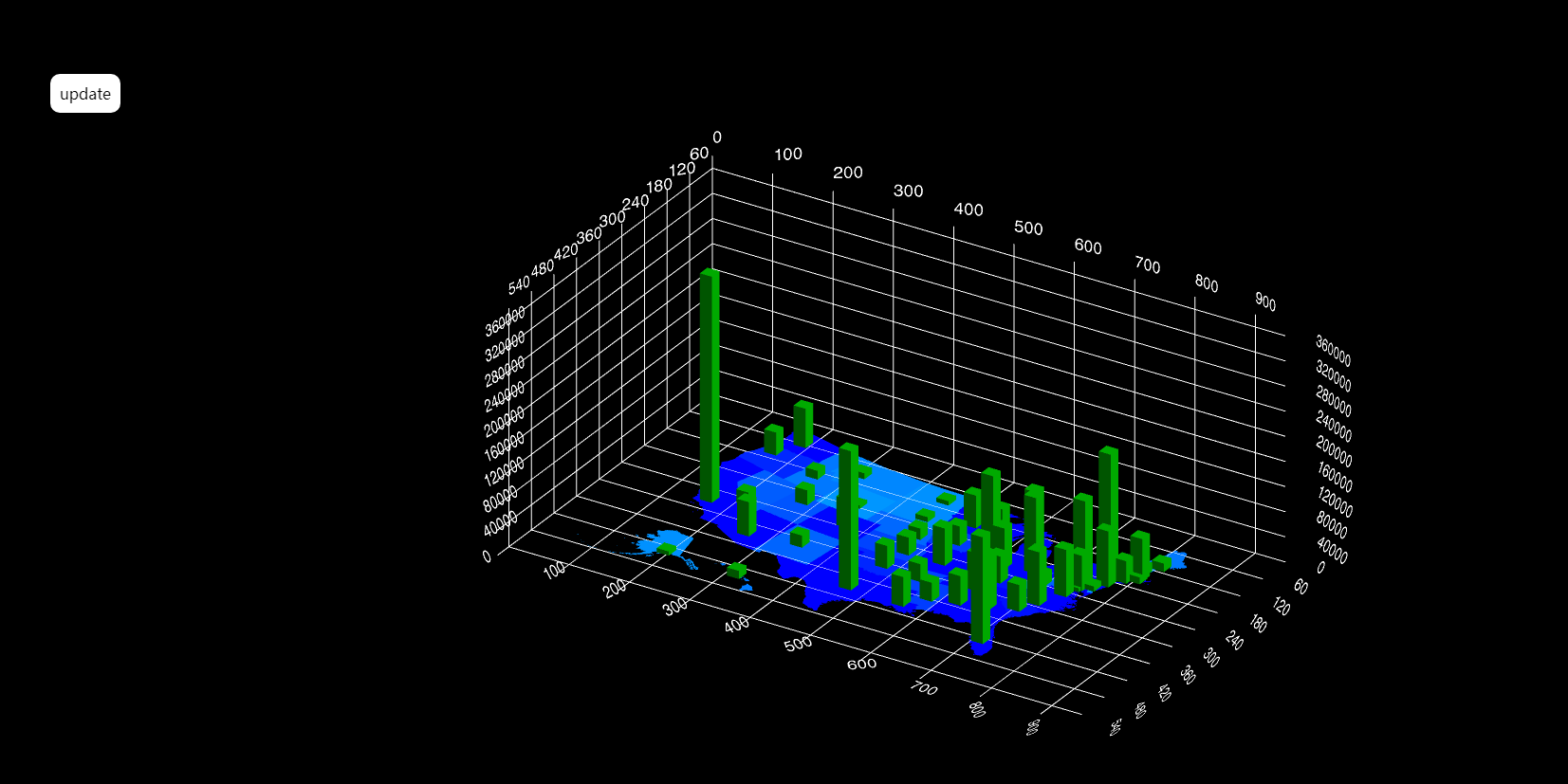
点击update按钮切换
<script src="https://d3js.org/d3.v4.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/topojson/1.6.20/topojson.min.js"></script>
<script src="https://threejs.org/build/three.js"></script>
<script src="https://threejs.org/examples/js/controls/OrbitControls.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/gsap/1.18.0/TweenMax.min.js"></script>
<script src="./SVGLoader.js"></script>
<script src="//d3js.org/queue.v1.min.js"></script>const width = window.innerWidth;
const height = window.innerHeight;
const scene = new THREE.Scene(); //创建场景
scene.background = new THREE.Color( 0x000000 );
// 添加平视相机,比较美观
function orthCamera(){
camera = new THREE.OrthographicCamera(window.innerWidth/-1.5,window.innerWidth/1.5,
window.innerHeight/1.5,window.innerHeight/-1.5,100,10000);
camera.position.set(500,500, 800);//设置相机坐标
camera.lookAt({x: 0, y: 0, z: 0});//让相机指向场景中心
}
orthCamera();
// 渲染
const renderer = new THREE.WebGLRenderer({antialias : true}); //创建渲染器(并设置抗锯齿属性)
renderer.setSize(width, height); //设置渲染器的大小
document.body.appendChild(renderer.domElement); //添加渲染器的DOM元素到body中
// 加入控制器
const controls = new THREE.OrbitControls( camera, renderer.domElement );
controls.screenSpacePanning = true;
function animate(time) {
requestAnimationFrame( animate );
renderer.render( scene, camera );
}
animate();至此已经创建好了场景空间,接下来要做的就是添加物体。
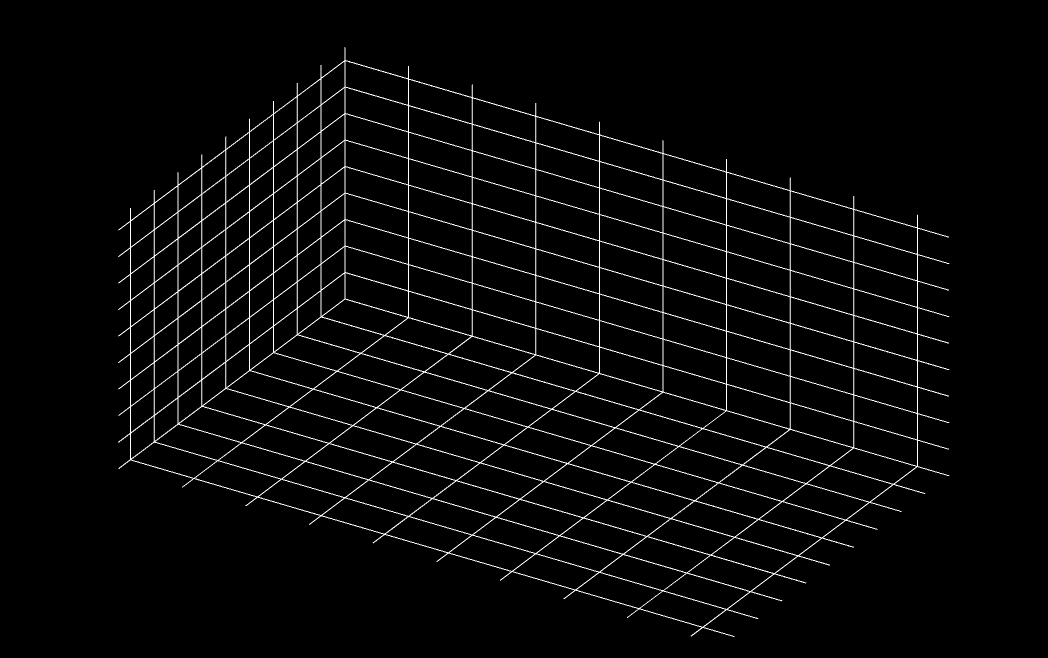
坐标轴分为三个面,六个坐标刻度,每个面两个刻度,相对的刻度相同
const geometryLeft = new THREE.Geometry(); //创建geometry
geometryLeft.vertices.push(new THREE.Vector3(0, 0 ,0)); //添加顶点
geometryLeft.vertices.push(new THREE.Vector3(19*50, 0, 0));
const geometryLeft1 = new THREE.Geometry(); //创建geometry
geometryLeft1.vertices.push(new THREE.Vector3(0, 0 ,0)); //添加顶点
geometryLeft1.vertices.push(new THREE.Vector3(19*30, 0, 0));
for(let i=0;i<10;i++){
//var mesh = new THREE.Mesh(geometry, material);
const line1 = new THREE.Line(geometryLeft, new THREE.LineBasicMaterial({color:0xffffff})); //利用geometry和material创建line
line1.position.z = i*60; //设置line的位置
scene.add(line1); //将line添加到场景中
const line11 = new THREE.Line(geometryLeft1, new THREE.LineBasicMaterial({color:0xffffff}));
line11.position.x = i*100;
line11.rotation.y = -Math.PI/2; //绕y轴旋转90度
scene.add(line11);
}
const geometryBack = new THREE.Geometry(); //创建geometry
geometryBack.vertices.push(new THREE.Vector3(0, 0 ,0)); //添加顶点
geometryBack.vertices.push(new THREE.Vector3(0, 0, 19*30));
const geometryBack1 = new THREE.Geometry(); //创建geometry
geometryBack1.vertices.push(new THREE.Vector3(0, 0 ,0)); //添加顶点
geometryBack1.vertices.push(new THREE.Vector3(0, 0, 19*20));
for(let i=0;i<10;i++){
//var mesh = new THREE.Mesh(geometry, material);
const line2 = new THREE.Line(geometryBack, new THREE.LineBasicMaterial({color:0xffffff})); //利用geometry和material创建line
line2.position.y = i*40; //设置line的位置
scene.add(line2); //将line添加到场景中
const line22 = new THREE.Line(geometryBack1, new THREE.LineBasicMaterial({color:0xffffff}));
line22.position.z = i*60;
line22.rotation.x = -Math.PI/2; //绕y轴旋转90度
scene.add(line22);
}
const geometryBottom = new THREE.Geometry(); //创建geometry
geometryBottom.vertices.push(new THREE.Vector3(0, 0 ,0)); //添加顶点
geometryBottom.vertices.push(new THREE.Vector3(19*50, 0, 0));
const geometryBottom1 = new THREE.Geometry(); //创建geometry
geometryBottom1.vertices.push(new THREE.Vector3(0, 0 ,0)); //添加顶点
geometryBottom1.vertices.push(new THREE.Vector3(19*20, 0, 0));
for(let i=0;i<10;i++){
//var mesh = new THREE.Mesh(geometry, material);
const line3 = new THREE.Line(geometryBottom, new THREE.LineBasicMaterial({color:0xffffff})); //利用geometry和material创建line
line3.position.y = i*40; //设置line的位置
scene.add(line3); //将line添加到场景中
const line33 = new THREE.Line(geometryBottom1, new THREE.LineBasicMaterial({color:0xffffff}));
line33.position.x = i*100;
line33.rotation.z = Math.PI/2; //绕y轴旋转90度
scene.add(line33);
}
const dirLight = new THREE.DirectionalLight(0xffffff, 1);
dirLight.position.set(100, 100, 50);
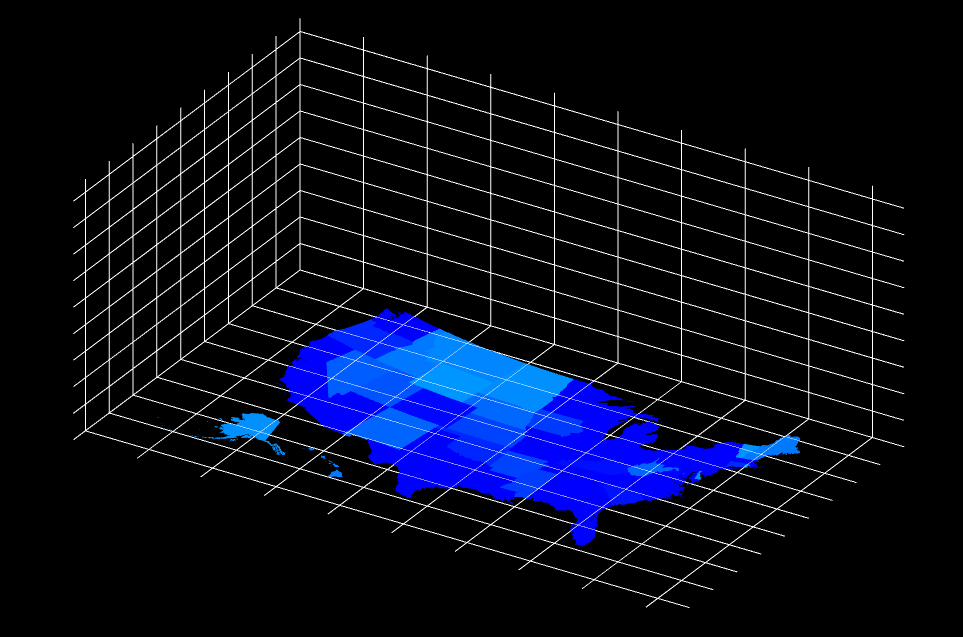
scene.add(dirLight);得到效果
由于坐标轴刻度的y轴将用于柱形图的高度,因此需要根据实际数据推算domain,所以需要放在数据加载后在执行,因此先加载地图数据.
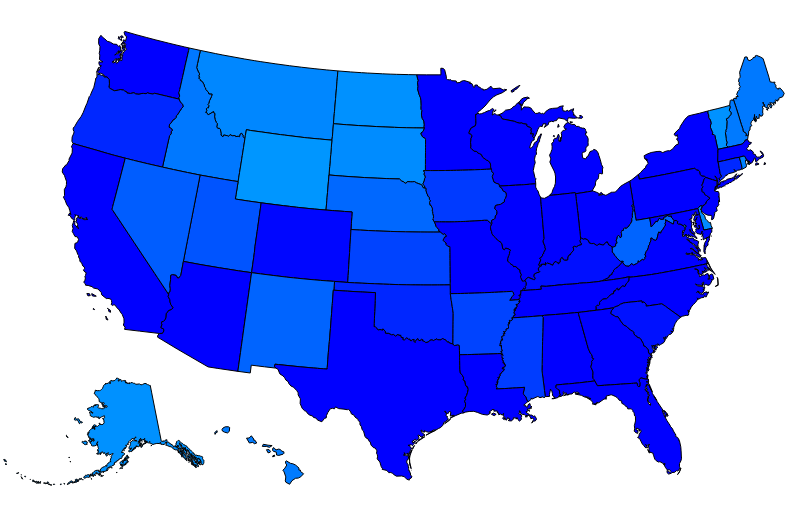
d3提供了geoPath方法可以渲染世界地图,threejs提供了svgLoader加载svg,将svg数据转换成threejs的shape平面
这个地图svg目前是通过在另一个文件使用d3画的,然后在浏览器中将生成的svgcopy下来保存成文件待使用。
const svgloader = new THREE.SVGLoader();
svgloader.load( './usasvg.svg', function ( paths ) {
const group = new THREE.Group();
const len = paths.length;
for ( let i = 0; i < len; i ++ ) {
const path = paths[ i ];
const material = new THREE.MeshBasicMaterial( {
color: path.color,
side: THREE.DoubleSide,
depthWrite: false
} );
const shapes = path.toShapes( true );
for ( let j = 0; j < shapes.length; j ++ ) {
const shape = shapes[ j ];
const geometry = new THREE.ShapeBufferGeometry( shape );
const mesh = new THREE.Mesh( geometry, material );
group.add( mesh );
}
}
group.rotation.x = Math.PI / 2; // 将xy平面上的地图翻转到xz平面
scene.add( group );
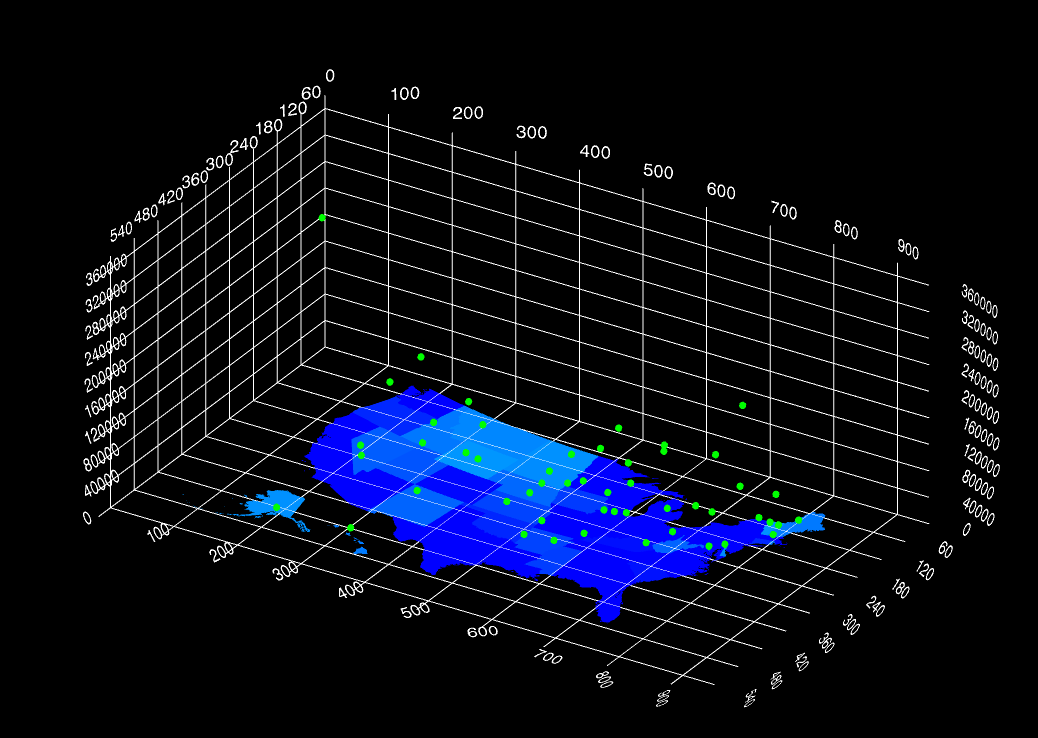
} );得到效果:
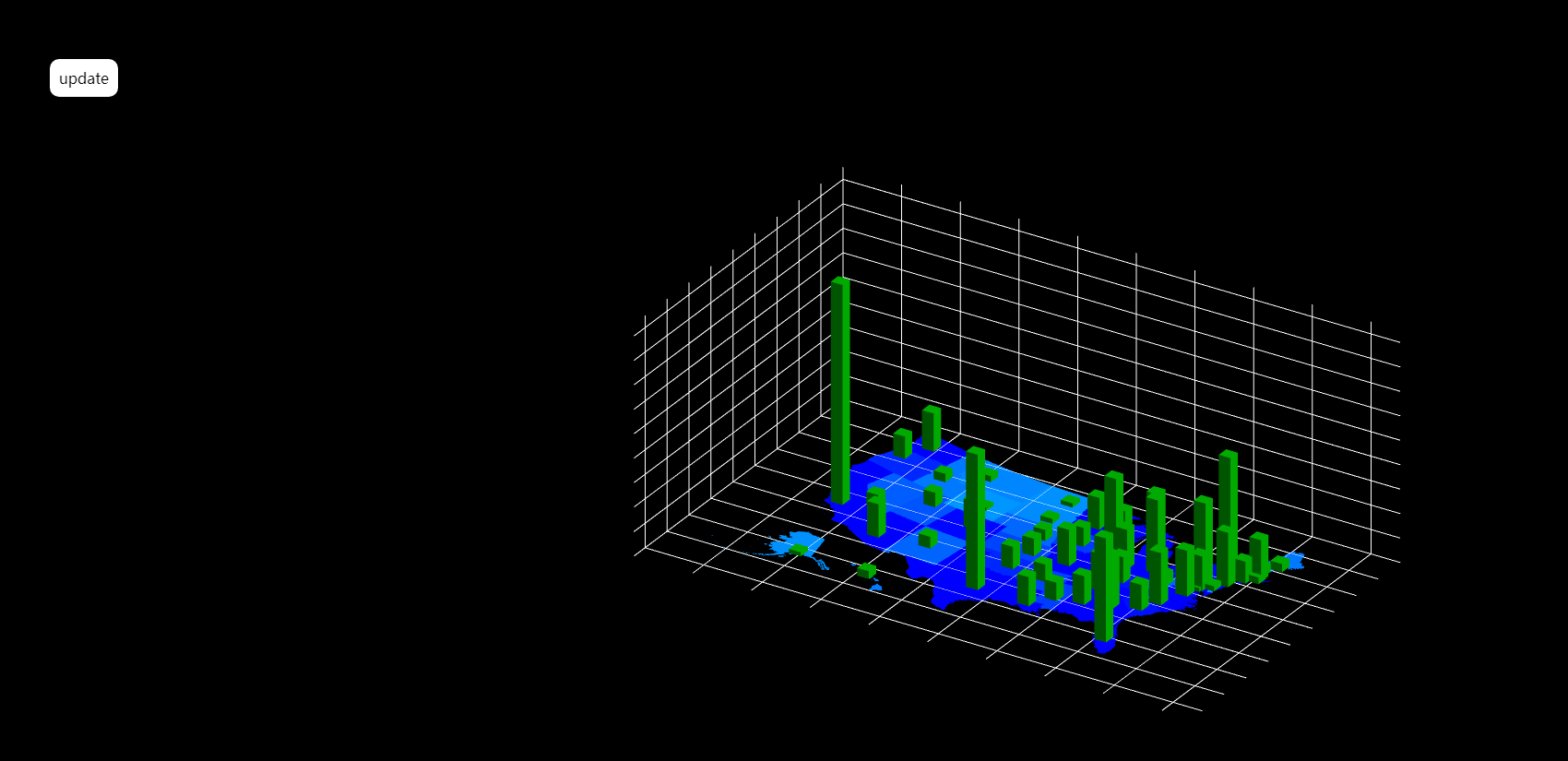
定义几个变量,用于存储object
const scaleHeight = d3.scaleLinear(); // y轴方向的比例尺
const bars = []; // 柱状体
const spheres = []; // 散点开始加载地图数据,这里的地图和数据都要和之前使用d3生成svg并渲染成shape的那个数据一样.
在body里面添加一个按钮update,用于动态变换柱形图和散点图形态。
<div id="update">update</div>const projection = d3.geoAlbersUsa().scale(1000);
const path = d3.geoPath().projection(projection);
queue().defer(d3.json, "./us.json").defer(d3.json, "./us-centroid.json").await(ready);
function ready(error, data, centroids) {
const features = topojson.feature(data, data.objects.states).features;
const centroidsFeatures = centroids.features;
const len = centroidsFeatures.length;
// 在此处决定比例尺的domain
scaleHeight.domain([0, Math.max(...centroidsFeatures.map(row => row.properties.population)) / 10000]).range([0, 360])
renderBars();
renderSpheres();
const update = document.getElementById('update');
update.addEventListener('click', handleUpdateClick, false);
var curType = 'sphere';
function renderBars() {
for (var i = 0; i < len; i ++) {
var centroid = path.centroid(centroidsFeatures[i]),
x = centroid[0],
y = centroid[1];
var barGeometry = new THREE.BoxGeometry(20, 2, 20);
// 此处的boxGeometry生成的box的y轴会随着高度正负伸长,所以需要矩阵转换来矫正一下,使得y是其一半的数值
barGeometry .applyMatrix(new THREE.Matrix4().makeTranslation(0,1, y));
var barMaterial = new THREE.MeshPhongMaterial({
color: 0x00ff00
});
// 数值比较大,我们除以10000
var barHeight = Math.floor(centroidsFeatures[i].properties.population / 10000 );
bar = new THREE.Mesh(barGeometry , barMaterial);
bar.position.x = x;
bar.barHeight= barHeight;
bar.customType = 'bar';
bar.customValue = Math.floor(centroidsFeatures[i].properties.population);
scene.add(bar);
bars.push(bar);
}
// 使用TweenMax动画库实现动画
for (var i = 0; i < bars.length; i++) {
var tween = new TweenMax.to(bars[i].scale, 1, {
ease: Elastic.easeOut.config(1, 1),
y: scaleHeight(bars[i].cubeHeight / 2)
});
}
}
function renderSpheres() {
for (var i = 0; i < len; i ++) {
var centroid = path.centroid(centroidsFeatures[i]),
x = centroid[0],
y = centroid[1];
var sphereGeometry = new THREE.SphereGeometry(5);
sphereGeometry.applyMatrix(new THREE.Matrix4().makeTranslation(0,1, y));
var sphereMaterial = new THREE.MeshBasicMaterial({
color: 0x00ff00
});
var sphereHeight = Math.floor(centroidsFeatures[i].properties.population / 10000 );
sphere = new THREE.Mesh(sphereGeometry, sphereMaterial);
sphere.position.x = x;
sphere.sphereHeight= sphereHeight;
sphere.customType = 'sphere';
sphere.customValue = Math.floor(centroidsFeatures[i].properties.population);
sphere.visible = false;
scene.add(sphere);
spheres.push(sphere);
}
for (var i = 0; i < spheres.length; i++) {
new TweenMax.to(spheres[i].position, 1, {
ease: Elastic.easeOut.config(1, 1),
y: scaleHeight(spheres[i].sphereHeight)
});
}
}
function showSpheres(i) {
curType = 'sphere';
new TweenMax.to(bars[i].scale, 1, {
ease: Elastic.easeOut.config(1, 1),
y: 1
});
cubes[i].visible = false;
spheres[i].visible = true;
new TweenMax.to(spheres[i].position, 1, {
ease: Elastic.easeOut.config(1, 1),
y: scaleHeight(spheres[i].barHeight)
});
}
function showBars(i) {
curType = 'bar';
new TweenMax.to(spheres[i].position, 1, {
ease: Elastic.easeOut.config(1, 1),
y: 1
});
spheres[i].visible = false;
cubes[i].visible = true;
new TweenMax.to(bars[i].scale, 1, {
ease: Elastic.easeOut.config(1, 1),
y: scaleHeight(bars[i].barHeight/ 2)
});
}
handleUpdateClick();
function handleUpdateClick() {
if (curType === 'bar') {
for (var i = 0; i < cubes.length; i++) {
showSpheres(i);
// var tween = new TweenMax.to(bars[i].scale, 1, {
// // ease: Elastic.easeOut.config(1, 1),
// y: 1,
// onComplete: showSpheres,
// onCompleteParams:[i]
// });
}
} else {
for (var i = 0; i < spheres.length; i++) {
showBars(i)
// var tween1 = new TweenMax.to(spheres[i].position, 1, {
// // ease: Elastic.easeOut.config(1, 1),
// y: 0,
// onComplete: showBars,
// onCompleteParams:[i]
// });
}
}
}
}得到效果:
threejs里面使用THREE.FontLoader加载threejs格式的字体,在官网可以下载。
function createText() {
const textLoader = new THREE.FontLoader();
textLoader.load(
'https://threejs.org/examples/fonts/helvetiker_regular.typeface.json',
function (font) {
// left top text
const options = {
size: 18,
height: 0,
font, // “引用js字体必须换成英文”
bevelThickness: 1,
bevelSize: 1,
bevelSegments: 1,
curveSegments: 50,
steps: 1
}
function createText(positions, n = 10) {
for(let i=0;i<n;i++){
// 使用TextBufferGeometry比TextGeometry快
const textLeftTop = new THREE.TextBufferGeometry(positions.text ? positions.text(i) : JSON.stringify(i * positions.n), options);
const textMeshLeftTop = new THREE.Mesh(textLeftTop, new THREE.MeshBasicMaterial());
textMeshLeftTop.position.x = typeof positions.x === 'function' ? positions.x(i) : positions.x;
textMeshLeftTop.position.y = typeof positions.y === 'function' ? positions.y(i) : positions.y;
textMeshLeftTop.position.z = typeof positions.z === 'function' ? positions.z(i) : positions.z;
textGroup.push(textMeshLeftTop);
scene.add(textMeshLeftTop);
}
}
createText({
n: 60,
x: 0,
y: 400,
z: function(i) {
return i * 60
}
});
createText({
text: function(i) {
return JSON.stringify(Math.floor(scaleHeight.invert(i * 40) * 1000));
},
n: 40,
x: 0,
y: function(i) {
return i * 40
},
z: 600
});
createText({
n: 100,
x: function(i) {
return i * 100
},
y: 0,
z: 600
});
createText({
n: 100,
x: function(i) {
return i * 100
},
y: 400,
z: 0
});
createText({
text: function(i) {
return JSON.stringify(Math.floor(scaleHeight.invert(i * 40) * 1000));
},
n: 40,
x: 1000,
y: function(i) {
return i * 40
},
z: 0
});
createText({
n: 60,
x: 1000,
y: 0,
z: function(i) {
return i * 60
}
});
}
);
}
createText的调用需要放到计算出scaleHeight的domain的时候调用,但是放那里调用会使得图形渲染产生卡顿,暂时还没想到好的办法。
createText();得到效果:
test
组件初始化函数,用于初始化状态,包括继承props和初始化state,所以没有必要在constructor里面执行setState,不会触发重新渲染,除非是异步的。
constructor(props) {
super(props);
this.state = {
val: 0
}
}
render() {
console.log(33333);
return ({this.state.val})
}组件即将渲染,在整个生命周期里面只会加载一次,在componentWillMount里面执行setState,不会触发重新渲染,除非是异步的。
componentWillMount() {
setTimeout(() => this.setState({
val: 999
}), 2000)
}
// 先打印33333
// 2s后打印33333
componentWillMount() {
this.setState({
val: 999
}
}
// 打印一次33333组件执行渲染,将虚拟dom渲染到真实dom。在这里不能执行setState,否则会触发循环。除非使用PureComponent,但是也会出现warning,而且在多层嵌套的对象改变的时候依然会死循环,因为PureComponent只是浅比较。
render渲染完毕后到这一步,通常在这里面可以用于获取服务器一些数据,改变state状态,会触发重新render,当然到底触不触发还取决于改变的值和shouldComponentUpdate。
当prop改变的时候触发,在这里面不能改变props,否则会陷入死循环!!,除非增加判断条件,避免陷入死循环。在这里面执行setState,会触发shouldComponentUpdate
当prop或state改变时触发,返回值是true的话会触发重新render,false不触发。在这里面不能执行setState,否则会陷入死循环!!
当props和state改变时,触发shouldComponentUpdate,如果返回false,则不会走到componentWillUpdate,如果返回true,则会触发componentWillUpdate
组件卸载的时候调用这个函数,可以在这里做一些定时器的销毁等操作。
由于setState是异步更新的,所以当你执行setState的时候在当前事件循环中不能立即使用改变后的state
this.state = { test: 'hello' }
...
this.setState({
test: 'world'
})
console.log(this.state.test) // hello如何使之可以立即使用呢
this.setState({
test: 'world'
}, () => console.log(this.state.test)) // world由于setState的批量更新机制,react利用事务来实现队列,在一个调用栈中的setState都会推到队列里面(哇,不懂),会发生如下情况
handleClick() {
this.setState({
val: this.state.val + 1
});
//第一次输出
console.log(this.state.val);
this.setState({
val: this.state.val + 1
});
//第二次输出
console.log(this.state.val);
setTimeout(()=>{
this.setState({val: this.state.val + 1});
//第三次输出
console.log(this.state.val);
this.setState({
val: this.state.val + 1
});
//第四次输出
console.log(this.state.val);
}, 0);
}
render() {
console.log(2333333); // 打印出来查看render次数
return ({this.state.val})
}控制台打印出
0
0
2333333 // 两次setState批量更新后的render 得到state.val == 1
2333333 // 第三次setState立即更新
2
2333333 // 第四次setState立即更新
3为何会这样呢,请看setState详解
本系列用于记录此次开发中后台项目中遇到的奇葩、诡异、魔法的坑。使用的依赖版本为:
"antd": "3.7.0",
"react": "^16.4.1",
"react-dom": "^16.2.0",
"react-redux": "^5.0.7",
"react-router": "^4.2.0",
"react-router-dom": "^4.2.2",坑:在使用该组件的时候,下拉数据异步获取,那么,初始值无效
以下代码是一个通用的下拉组件,作为form.getFieldDecorator函数包装的控件。
export default class ProductClasses extends React.PureComponent {
constructor(props) {
super(props);
this.state = {
productClasses: [],
};
}
async componentDidMount() {
const result = await queryListTree();
this.setState({
productClasses: result.data,
})
}
render() {
const { productClasses } = this.state;
const { labelInValue, prop, form } = this.props;
return <TreeSelect
defaultValue={form.getFieldsValue([prop])[prop]}
onChange={(e) => form.setFieldsValue({
[prop]: e,
})}
labelInValue={labelInValue}
placeholder="请选择产品类型"
dropdownStyle={{maxHeight: 300}}
allowClear
style={{ width: 200 }}
>
{makeTreeDom(productClasses)}
</TreeSelect>
}
}以上代码并不能在赋予初始值的时候正常显示初始值,必须使用一个三元运算符,将return改为如下才能生效
return productClasses.length ? (
<TreeSelect
defaultValue={form.getFieldsValue([prop])[prop]}
onChange={(e) => form.setFieldsValue({
[prop]: e,
})}
labelInValue={labelInValue}
placeholder="请选择产品类型"
dropdownStyle={{maxHeight: 300}}
allowClear
style={{ width: 200 }}
>
{makeTreeDom(productClasses)}
</TreeSelect>
) : null调试的时候经常需要打印一些log来查看,这时候直接展开function,在return之前加console似乎比较繁琐,可以写一个装饰器log来装饰这个func,使之在return之前打印结果。
function log(target, name, descriptor) {
var oldValue = descriptor.value;
descriptor.value = function () {
const res = oldValue.apply(null, arguments);
console.log(`Calling "${name}" and return `, res);
return res;
};
return descriptor;
}
class App extends React.Component {
@log
add() {
return 3;
}
componentDidMount() {
this.add()
}
render() {
return 111;
}
}类似于高阶组件的写法,装饰器需要传参数的时候再包裹一层函数
const setTitle = (title) => (WrappedComponent) => {
return class extends React.Component {
componentDidMount() {
document.title = title
}
render() {
return <WrappedComponent {...this.props} />
}
}
}
@setTitle('Profile Page')
class App extends React.Component {
render() {
return 111;
}
}redux提供connect可以使用装饰器写法
@connect(() => {
return {
count: state.count
}
},
(dispatch) => {
increcement: () => dispatch(increcementAction())
})
class App extends React.Component{
...
}继折腾了一宿没折腾好react-ssr,被react16和react-router4折磨半死后,毅然决定选择尝试Nextjs。
关于nextjs的大多教程,在这里
next中使用less,需要配置next.config.js使用相应的plugin,否则会报错。教程中说使用next-less
const withLess = require('@zeit/next-less')
module.exports = withLess()如你所愿,报错了,
.bezierEasingMixin();Inline JavaScript is not enabled. Is it set in your options?这是less3的一个bug,需要配置option,修改next.config.js
const withLess = require('@zeit/next-less')
module.exports = withLess({
cssModules: true, // 在项目中使用cssModule
lessLoaderOptions: {
javascriptEnabled: true //
},
})nextjs把css都打包到一个文件下,会存在命名冲突,而使用css module可以实现scope效果
此时,可以正常使用less和css module了。
pages/_app.js引入antd的样式 import "antd/dist/antd.less";,如你所愿,报错了,因为antd没有使用css module,我们在spa项目中配置webpack的时候通常是配置两种less-loader,一种是include src,一种是exclude node_module
然而查看next-less的源码,发现并没有做这种处理,因此需要手动修改next-less,将下面这部分复制,添加到
// 省略....
// 将此处的cssModules删除,添加一个参数antdLessLoaderOptions, 传参时将cssModules放到antdLessLoaderOptions和lessLoaderOptions里面
const {
cssLoaderOptions,
lessLoaderOptions = {},
antdLessLoaderOptions = {}
} = nextConfig
// 省略.....
options.defaultLoaders.less = cssLoaderConfig(config, extractCSSPlugin, {
cssModules: lessLoaderOptions.cssModules,
cssLoaderOptions,
dev,
isServer,
loaders: [
{
loader: 'less-loader',
options: lessLoaderOptions
}
]
})
config.module.rules.push({
test: /\.less$/,
exclude: [/node_modules/], // 处理非antd的less
use: options.defaultLoaders.less
})
// 添加一个less-loader
options.defaultLoaders.less = cssLoaderConfig(config, extractCSSPlugin, {
cssModules: antdLessLoaderOptions.cssModules,
cssLoaderOptions,
dev,
isServer,
loaders: [
{
loader: 'less-loader',
options: antdLessLoaderOptions
}
]
})
config.module.rules.push({
test: /\.less$/,
include: [/node_module/], // 专门处理antd的less和node_module其他的库的less
use: options.defaultLoaders.less
})修改next.config.js
const withLess = require('@zeit/next-less')
module.exports = withLess({
cssLoaderOptions: {
localIdentName: '[local]_[hash:base64:5]', // 此处是为了可以使生成的css module可辨识
},
lessLoaderOptions: {
cssModules: true,
javascriptEnabled: true
},
antdLessLoaderOptions: {
javascriptEnabled: true
}
})。。。。。。。。。。。。。。分界线。。。。。。。。。。。。。。
开发过程中发现了一个问题,就是cssmodule里面定义的css属性,会被antd的样式覆盖,原因很简单,由于在_app.js引入antd.less的时候在引入RootContainer之后,因此会覆盖,解决方法自然是将antd.less放在container组件之前引入。放在import最顶部即可
import "antd/dist/antd.less";
import RootContainer from '../components/RootContainer';boom!!!大功告成。
在伟大的js中,高阶函数通俗的讲指的是一个参数为函数,且return返回值也是函数的函数,即:
const gjfunc = (func) => () => func(); // 定义一个高阶函数
const usegjfunc = gjfunc(() => {console.log(111)}) 调用高阶函数返回一个函数
usegjfunc(); // 使用这个函数哇偶,好简单,高阶函数著名的应用就是柯里化.
const curry = (func, args) => {
let len = func.length;
args = args || [];
return (...arg) => {
args.push(...arg);
if (args.length == len) {
return func( ...args);
} else {
return curry(func,args);
}
}
}
curry((a, b) => a + b)(1)(2); // 3
const func1 = curry((a, b) => a + b); // 返回一个函数
const func2 = func1(1); // 返回一个函数
const func3 = func2(2); // 返回一个结果高阶组件的概念通俗的讲就是一个参数为组件,返回值也是一个组件的函数,
wrapperCom = wrapperFunc(wrappedComp);高阶组件 = 高阶函数(组件)
import React, { PureComponent } from 'react';
const WrapperFunc = (WrappedComp) =>
class WrapperFunc extends PureComponent {
constructor(props) {
super(props);
this.state = {
count: 0
}
}
render() {
return (
<WrappedComp data = {this.state} {...this.props} />
)}
}
class wrappedComp extends PureComponent {
render() {
return(
<div>
{this.props.data.count}
</div>
)}
}
export const WrapperComp = WrapperFunc(wrappedComp);这里的高阶函数WrapperFunc将wrappedComp组件包裹了一层,处理后再返回新的组件,实现了传入data属性来方便被包裹组件获得count公共状态,后面使用WrapperFunc包裹的任何组件都可以具备这个count。
那么如果我们想要定制count咋办呢,可以将count作为WrapperFunc函数的第二个参数,实现WrapperFunc(wrappedComp, 1)的功能,但是我们参考柯里化,可以使用更佳优雅的格式,将高阶函数再高阶一层,就变成了WrapperFunc(1)(wrappedComp),即WrapperFunc高阶函数,传入count=1作为参数,返回一个高阶函数,传入wrappedComp组件作为参数,返回包裹后的高阶组件。
import React, { Component, PureComponent } from 'react';
const WrapperFunc = (count) => (WrappedComp) =>
class WrapperFunc extends PureComponent {
constructor(props) {
super(props);
this.state = {
count
}
}
render() {
return (
<WrappedComp data = {this.state} {...this.props} />
)}
}
class wrappedComp extends PureComponent {
render() {
return(
<div>
{this.props.data.count}
</div>
)}
}
export const WrapperComp = WrapperFunc(1)(wrappedComp);
export const WrapperComp1 = WrapperFunc(2)(wrappedComp);用过react-redux的都知道,使用方式是这样滴:
<Provider store={store}>
<App />
</Provider>
// app.js
class App extend PureComponent {
// ...
]
export default connect(mapStateToProp,mapDispatchToProp)(App);
// 其中mapStateToProp,mapDispatchToProp两个函数分别实现了蒋store里面的state和dispatch转换成组件props里面的属性。Provider 最核心的一点就是实现了store的向下传递,使用了React提供的API getChildContext方法和childContextText声明
import React, { Component } from 'react';
import PropTypes from 'prop-types';
export default class Provider extends Component {
getChildContext() {
return {
store: this.props.store
};
}
render() {
return this.props.children;
}
}
Provider.childContextTypes = {
store: PropTypes.object
}import React, { Component, PureComponent } from 'react';
import PropTypes from 'prop-types';
export default function connect(mapStateToProp, mapDispatchToProp) {
return function(Comp) {
class WrapperFunc extends PureComponent {
constructor(props) {
super(props);
this.state = {}
}
componentDidMount() {
this.setState({
...this.state,
...mapStateToProp(this.context.store.getState()),
...mapDispatchToProp(this.context.store.dispatch)
})
}
render() {
return (
<Comp {...this.state}/>
)
}
}
WrapperFunc.contextTypes = {
store: PropTypes.object
}
return WrapperFunc;
}
}这里的关键步骤是将context里面的store里的state和dispatch传递给mapStateToProp, mapDispatchToProp这两个函数,这两个函数分别需要返回组件需要的状态和action,然后作为Comp组件的props传递下去。因此组件Comp就能在props中拿到store里面所需的东西。Boom!!!
####使用自己的connect和Provider
import React from 'react';
import ReactDOM from 'react-dom';
import Provider from './provider';
import { createStore } from 'redux';
import App from './App';
import testStore from './testStore';
if (process.env.NOED_ENV !== 'production') {
const { whyDidYouUpdate } = require('why-did-you-update');
whyDidYouUpdate(React);
}
const store = createStore(testStore);
ReactDOM.render(<Provider store={store}><App /></Provider>, document.getElementById('root'));App.js
import connect from './connect';
class App extends PureComponent {
render() {
return (
<div>
{this.props.connectCount}
</div>
);
}
}
export default connect((state) =>({ connectCount: state.count }), (dispatch) => console.log(333, dispatch))(App);大功告成,不知道该说啥,觉得自己对react的理解又通透了一些,开心~推荐图书《React进阶之路》
用 issue 写博客的话,是不是别人也可以写
微信授权分为四大步骤
前端获取。用户进入A站,
一、redrect到授权页,带上回调页面A,用户点击允许授权
二、回到A页面,带上获取到的code
三、使用code请求获取accesstoken和openid
四、使用accesstoken和openid获取用户信息
后端获取。用户进入A站,请求login接口
一、login接口redrect到授权页,回调接口getAccesstoken,允许授权
二、回到getAccesstoken接口,带上获取到的code
三、使用code请求获取accesstoken和openid
四、使用accesstoken和openid获取用户信息
五、种下cookie,返回到页面A
// auth.js
var req = require('request');
/* 微信登陆 */
var AppID = 'xxx';
var AppSecret = 'xxxxxx';
module.exports = [{
method: 'GET',
path: '/wx_login',
handler: async (request, h) => {
// 第一步:用户同意授权,获取code
var router = 'get_wx_access_token';
// 这是编码后的地址
var return_uri = 'http%3A%2F%2Fwww.test.com%2F'+router;
var scope = 'snsapi_userinfo';
// 授权页,回调地址get_wx_access_token
return h.redirect('https://open.weixin.qq.com/connect/oauth2/authorize?appid='+AppID+'&redirect_uri='+return_uri+'&response_type=code&scope='+scope+'&state=STATE#wechat_redirect');
}
}, {
method: 'GET',
path: '/get_wx_access_token',
handler: async (request, h) => {
// 第二步:通过code换取网页授权access_token
var code = request.query.code;
req.get(
{
url:'https://api.weixin.qq.com/sns/oauth2/access_token?appid='+AppID+'&secret='+AppSecret+'&code='+code+'&grant_type=authorization_code',
},
function(error, response, body){
if(response.statusCode == 200){
// 第三步:拉取用户信息(需scope为 snsapi_userinfo)
var data = JSON.parse(body);
var access_token = data.access_token;
var openid = data.openid;
req.get(
{
url:'https://api.weixin.qq.com/sns/userinfo?access_token='+access_token+'&openid='+openid+'&lang=zh_CN',
},
function(error, response, body){
if(response.statusCode == 200){
// 第四步:根据获取的用户信息进行对应操作
var userinfo = JSON.parse(body);
// 可以由此创建一个帐户
h.response(userinfo.nickname)
}else{
console.log(response.statusCode);
}
}
);
}else{
console.log(response.statusCode);
}
}
);
}
}];redux是通用的一套用于项目中统一管理全局状态的框架,这个状态state贯穿整个应用,全局共享,那么就少不了需要使用约定的统一的规范的动作actions来进行state的更新操作reducers。
全局唯一的共享的state,其实就是一个对象,这个对象里面的属性将来需要在应用中的多个甚至每个页面都要用到并进行更新操作。
const initialState = {
count: 0
}当多个页面多个组件都需要在各处进行共享state的操作的时候,如果各自随意修改state,就会变得很混乱,你不知道那个组件在何时何地修改了state,因此,需要一套约定的规范来进行更新state操作,redux提出使用action动作来触发,action相当于一个个钥匙,分发给各个组件,当你需要修改state的时候,只需要dispatch对应的action,这些action收集起来最终去触发对应的reducer执行最终的state更新操作。传给reducer的action始终只能是一个对象,对象中必须要有一个能描述操作的type用于让reducer针对type做对应的处理。
reducer就是最终要更新state的函数,参数为传入的state和action,会对不同action.type做出不同操作的函数,在没有任何操作情况下,我们返回初始的initialState。
export default function counter(state = initialState, action) {
const count = state.count
switch (action.type) {
case 'increase':
return { count: count + 1 }
default:
return state
}
}以上的这个reducer处理increase的时候返回了一个新state,而不是在原来的state上直接修改,为什么要这么做呢?有三点原因,但是让我们先上一大大大大大。。。段示例代码:
import React from 'react';
import ReactDOM from 'react-dom';
import { Provider } from 'react-redux';
import thunk from 'redux-thunk';
import { createStore, applyMiddleware, compose } from 'redux';
import App from './App';
import reducers from './reducers/index';
let store;
if(!(window.__REDUX_DEVTOOLS_EXTENSION__ || window.__REDUX_DEVTOOLS_EXTENSION__)){
store = createStore(
reducers,
applyMiddleware(thunk)
);
}else{
store = createStore(
reducers,
compose(applyMiddleware(thunk), window.__REDUX_DEVTOOLS_EXTENSION__ && window.__REDUX_DEVTOOLS_EXTENSION__()) //插件调试,未安装会报错
);
}
if (process.env.NODE_ENV !== 'production') {
const { whyDidYouUpdate } = require('why-did-you-update');
whyDidYouUpdate(React);
}
// react和redux的结合产生了react-redux
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>, document.getElementById('root')
);./reducers/index
import { combineReducers } from 'redux';
// 两个分开的reducer,将来可以根据项目需求进行state状态的细分,比如user相关的state,和app相关的state等分开使得state也组件化, 最终通过combineReducers进行组合成最终的大state,这里只是简单的示例。
function counter(state = { count: 0 }, action) {
const count = state.count;
switch (action.type) {
case 'increase':
state.count += 1;
return state;
default:
return state;
}
}
user(state = { username: 'candy' }, action) {
switch (action.type) {
case 'changename':
return { username: action.name }
default:
return state
}
}
export default combineReducers({
todoApp,
user
});App.js
import React, { PureComponent } from 'react';
import { connect } from 'react-redux';
class App extends PureComponent {
render() {
const { count, onIncreaseClick, onChangeUserClick, username } = this.props
return (
<div>
<span>{count}</span>
<button onClick={onIncreaseClick}>Increase</button>
<span>{username}</span>
<button onClick={onChangeUserClick}>ChangeUser</button>
</div>
)
}
}
function mapStateToProps(state) {
return {
count: state.todoApp.count,
username: state.user.username
}
}
const increaseAction = { type: 'increase' };
const changeUserClickAction = { type: 'changename', name: 'zp' };
function mapDispatchToProps(dispatch) {
return {
onIncreaseClick: () => dispatch(increaseAction),
onChangeUserClick: () => dispatch(changeUserClickAction)
}
}
export default connect(mapStateToProps, mapDispatchToProps)(App);
针对这个例子我们来看一下不修改state的三大理由:

正确的是直接返回一个新的对象{ count: state.count += 1 }
比如一个复杂state为如下所示,那么我们可以将其reducer拆分成分别处理count和user的两个,最后通过combineReducers合并。这样在返回副本的时候比较简单,可以直接{count: 2}这种单层的对象。
const state = {
count: {
sum: 0
},
user: {
username: 'candy'
}
}简单的数据往往一层两层的对象,对于一层对象的改变,也可以使用
object.assign({}, state, {
count: {sum: 2}
})但是程序往往是复杂类型的,单层的对象无法满足业务需求的时候,就会出现嵌套很深的对象,这时候Object.assign()就不起作用了,因为Object.assign()只是浅拷贝。。。对于全是可枚举的属性的对象,可以使用如下方法
const newState = JSON.parse(JSON.stringify(state)); // 深拷贝
newState.count.sum = 3;
return newState;或者使用lodash的cloneDeep
const newState = cloneDeep(state);
newState.visibilityFilter.b.d = action.filter;
return newState;每种方案各有优劣,需要视项目情况而定,选择最适合最清晰的方式,才能高效高性能的进行开发!!!boom!!!
Proxy意思为“代理”,即在访问对象之前建立一道“拦截”,任何访问该对象的操作之前都会通过这道“拦截”,即执行Proxy里面定义的方法。
基本用法
let pro = new Proxy(target,handler);这里不讲proxy的原理,只讲proxy在我们实际项目中可以利用到的地方。
图片的加载需要一定的时间,我们常常希望在图片加载成功之前显示一个占位图,那么可以使用proxy在html渲染图片的时候通过替换src来实现,因为html渲染图片img标签的时候实际是在执行一个get操作,因此可以使用proxy来实现
function proxyImg(img, loadingImg, realImg) {
const vImg = new Image();
let hasLoad = false;
vImg.src = realImg;
vImg.onload = function() {
Reflect.set(img, 'src', realImg);
hasLoad = true;
}
return new Proxy(img, {
get(obj, prop) {
if(prop === 'src' && !hasLoad) {
return loadingImg;
} else {
return obj[prop];
}
}
})
}
// 使用
const img = new Image();
document.body.appendChild(proxyImg(img, './loading.gif', './xx.png'))项目中常常要遇到这样一个场景
const obj = {};
if(!obj.style) { obj.style = {} }
else {
obj.style.left = '200px';
obj.style.top = '100px';
}每次都要多一个是否存在属性,不存在则初始化一个空对象,否则会报错can not assign to an undefined的错误,那么我们使用proxy来创建一个空对象,并拦截get操作,即可实现
const EmptyObject = function () {
return new Proxy({}, {
get: (target, property) => {
if (!(property in target)) {
target[property] = {};// 将判断为空的放在拦截器里面
}
return target[property];
}
})
};
// 使用
const obj = EmptyObject();
obj.test.test1 = 0;
console.log(888, obj)Proxy的应用非常多,在实际项目中要经常动脑,思考有没有可以借助Proxy实现的一些场景,来方便我们的编码。
不想写~~~自己搜。。
判断一个对象是否是一个类的实例可以使用a instanceof b,instanceof 运算符用来检测 constructor.prototype 是否存在于参数 object 的原型链上,即只要a顺着__proto__能找到某个__proto__等于b的prototype的都能返回true
实现一个instanceof
function instanceof(A, B) {
const O = B.prototype;
let A = A.__proto__ ;
while(true) {
if (A === null) return false; // 直到找到null
if (A === O) return true;
A = A.__proto__; // 顺着往上找
}
}根据上述特性,可以实现一个new函数,模拟new语法
function mynew (Class, options) {
const obj = {};
Class.call(obj, options);
obj.__proto__ = Class.prototype;
return obj;
}
function Person(name) {
this.name = name;
}
Person.prototype.sayhi = function(){console.log(this.name)}
const p1 = mynew(Person, 'candy');
p1.sayhi() // candy继承的原理在于子类为了继承父类的原型方法,需要将子类的prototype 合并父类的prototype 再新增自己的一些原型方法,同时,由于Person1.prototype = Person.prototype的行为会导致constructor丢失,所以需要手动添加,指向构造函数本身,为了继承父类的属性,需要在子类的构造函数即子类函数中,调用一遍父类的构造函数,从把父类的属性挂到子类的实例对象上,如果子类和父类的属性有重复,则使用子类的属性覆盖。因此可以得到如下继承方式。
function Person1(name) {
this.super(name)
// Person.call(this, name); 或者使用call执行
}
// Object.create将Person1.prototype.__proto__指向Person.prototype,并添加constructor为Person1
Person1.prototype = Object.create(Person.prototype, {
constructor: {
value: Person1,
enumerable: false,
writable: true,
configurable: true
}
})
// prototype上添加super方法,用于执行一次Person
Person1.prototype.super = Person;
let person1 = new Person1('candy');
console.log(person1.name); // candy原型链继承的精髓在于,让原型对象(子类原型对象)等于另一个类型(父类)的实例
每个构造函数都有一个原型对象,原型对象都包含一个指向构造函数想指针(constructor),而实例对象都包含一个指向原型对象的内部指针(proto)。如果让原型对象等于另一个类型的实例,此时的原型对象将包含一个指向另一个原型的指针(proto),另一个原型也包含着一个指向另一个构造函数的指针(constructor)。假如另一个原型又是另一个类型的实例……这就构成了实例与原型的链条。
首先明白中间件的基本**就是一个数据流的**,就像一个restful接口,在请求到达之前先经过一层或者多层的预处理即拦截处理完最终再交给下面的执行器。我们就redux中间件的例子来说一下。
先盗一张图

redux中间件middleware是用于增强store.dispatch的,比如我们dispatch任何action的时候,都想把这个action打印出来,那么我们不需要在每个reducer里面或者修改dispatch来达到目的,我们只需要写一个中间件,中间件将这个action先处理完后,再交给下一个中间件处理,最终交给原生的dispatch处理。
那么如何写这个中间件的思路呢,首先,我们最终的目的地是dispatch(action),假设dispatch长这样
let dispatch = (action) => {
console.log(333, action)
}那么我们先写个中间函数是这样的格式
const cons = (next) => action => {
console.log(111);
next(action);
}这里的next就是原生的dispatch函数, 我们重新定义dispatch = cons(dispatch),那么执行dispatch(action)的时候就会先执行打印,再执行原生的dispatch了。
假设我现在还想写一个中间件,
const cons2 = (next) => action => {
console.log(222);
next(action);
}此时我们重新定义dispatch = cons2(cons(dispatch)),就会先执行cons2的打印在执行cons的打印,通俗的讲下来,完整代码是这样的:
// 类比原生dispatch
let dispatch = (action) => {
console.log(333, action)
}
// 中间件1
const cons = (next) => action => {
console.log(111);
next(action);
}
// 中间件2
const cons2 = (next) => action => {
console.log(222);
next(action);
}
// 增强的dispatch
dispatch = cons2(cons(dispatch))
// 调用增强的dispatch
dispatch({key: 2}) // 222,111,333 数据action的流向是cons2->cons->dispatch使用applyMiddleware的方式是
const store = createStore(reducers, applyMiddleware(thunk));applyMiddleware源码核心部分
export default function applyMiddleware(...middlewares) {
return (next) => (reducer, initialState) => {
const store = next(reducer, initialState);
const middlewareAPI = {
// 这里的getState也保证了每次的middlewares使用的store.state是最新状态的state
getState: store.getState,
// 这里使用闭包使得每次执行middlewares的dispatch都是当前最新的,即middleware2拿到的dispatch是经过middleware1增强后的dispatch。
dispatch: (action) => dispatch(action)
}
const chain = middlewares.map(middleware => middleware(middlewareAPI));// 将最新的state和dispatch传入中间件,使得中间件可以获取最新的状态和dispatch。
const dispatch = compose(...chain)(store.dispatch) // compose是redux提供的一个函数实现上述从f(),g(),h()到f(g(h(dispatch)))的过程。具体实现自行百度。。。懒得写了。
return {
...store,
dispatch // 最终将得到的增强的dispatch,覆盖了原生的store里面的dispatch。
}
}
}以上分析,为了使得中间件可以获取最新的状态和dispatch,每个middleware有多包裹了一层闭包,从原来的
middleware = next => action => {}
// 变成了
middleware = ({dispatch, getState}) => next => action => {}
// 因此applyMiddleware中将其执行一次后再进行compose组合由于原生的dispatch只接受一个对象形式的action,不接受其他action,而且原生dispatch是同步模式,Action 发出以后,Reducer 立即算出 State。Action 发出以后,过一段时间再执行 Reducer,这就是异步。因此当我们需要在action里面执行一些异步操作的时候,就需要先处理这个异步的步骤,这时候中间件就派上用场了,redux-thunk中间件实现了这个功能。
使用方式
function fetchData() {
return (dispatch, getState) => {
setTimeout(() => {
dispatch({type: 'test', text: 'haha'});
}, 1000);
}
} 从这个使用方式可以很轻松的推测出redux-thunk的实现思路
const thunk = ({dispatch, getState}) =>(next) => action => {
if (typeof action === 'function') { // 异步函数
return action(dispatch, getState); // 注意此处的dispatch是最新的dispatch,进入循环
}
next(action);
}当然thunk和的applyMiddleware源码更加复杂,但是核心就是这么些,弄懂了核心,boom!
其实感觉这个中间件描述起来晦涩难懂,好难描述,不过既然都提上日程了,不写也得咬着牙写了。。
目前写博客是使用hexo部署,好处在于可以定制博客风格,没有设计感的人就别说定制了,定制了也很丑,只好用模板。要使用图片什么的还得上传到图床然后粘贴,写好了还得部署。还是挺麻烦的,比较适合写那种深入理解的文章。自从多说那个很丑的评论系统关闭了以后,大家纷纷替换了disqus评论系统,好像要翻墙?还得,注册才能评论?总之各种不方便。
另外一个记笔记的是印象笔记,他的优点先不说了,最大的缺点是,笔记太零散,回头找的时候已经找不到当初的那个知识点了。
还尝试了一个在线文档编辑,石墨文档,讲真这玩意还不错,但是也存在一个毛病,就是知识多了,文件创建多了,就找不到知识点了、、、
作为程序员,大多数人写博客,一方面想要让自己的博客精美,一方面又想让自己的博客得到传播,好成为大佬一样的网红前端,噗。。。
但是我们在平时工作或者阅读的时候,经常会遇到一些有意思的问题,和有意思的知识点,这时候想要即兴写一篇总结和笔记,又不想过段时间找不到。那么github的issues可以派上用场了,
优点:
图片直接上传,使用github的静态服务
支持markdown
github自带issues评论系统,还都是gay界各路大佬,可以共同审查博客中暴露的问题,帮助进步。
labels等同于是博客的tag标签,明显
projects等同于是博客的分类,整洁
issues列表就是博客归档,一目了然
那么我就从零开始使用github issues搭建属于自己的博客吧。
第一步,新建一个仓库
可以命名为blog或者自己喜欢的名字。

第二步,新建project
这里的project可以类比分类,将来你写好的issue可以拖到某个你已经创建的分类下面。比如新建了github专题的,以后有关github的文章都可以拖到这里。

第三步,新建issue
在右侧点击label的标志,可以选择已创建的一些label,或者当场创建label,需要注意label太散也不好,久了也会造成知识太零碎的情况。

选择一个project,提交后这个issue就会分类到这个project下面

然后点击提交issue试试
结果
最后你会在issues列表里面看到很舒服的一条issue
进入projects的github专题,你会看到你还没创建子类,任务卡,相当于大专题里的小专题吧。

那么我们就新建一个,命名为_github博客搭建_
然后点击右上角的add cards,将新创建的一个issue拖到新建的github博客搭建这个类目下面

这个以后找文章就方便多了。其实各种各样的工具都是为了我们能够更好地做到碎片知识积累和查找。其实也避免不了知识多了分类零散的问题,最本质的还是要自己自觉地维护好知识点的分类。
最后一步,创建主页



然后访问你的域名,就可以看到你的readme啦。
最近遇到一个需求是后端给了两个数据a和b,a是0.5,b是1,要画出a和b的比例为1:2,也就是0.5/1=1/2,那么如何将小数转换成分数呢。
以下假设都是保留两位小数的情况。反正几位小数就乘以10的n次方先得到整数就好了。
function transform(a, b) {
let fenzi = parseInt(a.toFixed(2) * 100, 10); // 分子
let fenmu = parseInt(b.toFixed(2) * 100, 10); // 分母
let min = Math.min(fenzi, fenmu); // 较小的
for (let i = min; i > 1; i --) {
if (!(fenzi % i) && !(fenmu % i)) {
fenzi = fenzi / i;
fenmu = fenmu / i;
min = Math.min(fenzi, fenmu);
}
}
return `${fenzi}:${fenmu}`;
}测试
transform(35, 15); // 7:3
transform(0.35, 0.15); // 7:3
transform(0.35, 30); //7:600当场景中的两个模型在同一个像素生成的渲染结果对应到一个相同的深度值时,渲染器就不知道该使用哪个模型的渲染结果了,或者说,不知道哪个面在前,哪个面在后,于是便开始“胡作非为”,这次让这个面在前面,下次让那个面在前面,于是模型的重叠部位便不停的闪烁起来。这便是Z-Fighting问题。原文链接

地图texture平面和栅格的深度相同,导致栅格线若隐若现,一会栅格线在上面一会平面在上面。

带边框的立方体紧挨的时候,边框重叠导致边框模糊。

使用方法1,将地图平面往下平移一个像素,就可以解决问题
rect.position.y = -1;但是没法解决第二个问题,紧挨着的立方体无法使用平移或者渲染顺序来解决。
缓冲的级别越多,冲突的概率相应的也就越低,所以,我们可以使用一个精度更高的z缓冲,来代替原有的Z缓冲。对于这个方法,threejs官网已经提供了一个例子webgl_camera_logarithmicdepthbuffer。不过,官网的例子为了演示效果,写得比较复杂,实际上只需要将logarithmicDepthBuffer参数设为true即可:
var renderer = new THREE.WebGLRenderer({ logarithmicDepthBuffer: true });得到较好的效果

今天遇到一个需求是,给出两个色值假设#269f42到#2fcb53,然后进行n等分。实现这样的效果

起始色值和终止色值由ui给出,然后数据数量(n)不是固定的,因此需要实现颜色的n等分。
// 实现十六进制转十进制,color可以是#fff或#ffffff格式
const hexToDec = (color) => {
if (!(/^#[0-9a-fA-F]{3,6}$/.test(color))) {
throw new Error('color十六进制格式不正确');
}
color = color.replace('#', '');
const hex = color.length == 3 ? color.replace(/(\w)/g, "$1$1,") : color.replace(/(\w{2})/g, "$1,");
return hex.substr(0, hex.length - 1).split(',').map(row => parseInt(row, 16));
}
// 实现十进制转十六进制
const decToHex = (arr) => {
return arr.map(row => parseInt(row, 10).toString(16)).join('');
}
// 实现等分
const divideColor = (from, to, n) => {
const fromArr = hexToDec(from);
const toArr = hexToDec(to);
const gaps = [];
const res = [];
fromArr.forEach((row, i) => {
gaps.push(parseInt((toArr[i] - row) / n, 10));
})
for (let j = 0; j < n; j++) {
res.push(`#${decToHex(fromArr.map((row, i) => `${row + gaps[i] * j}`))}`);
}
return res;
}
divideColor('#269f42', '#2fcb53', 10);
// ["#269f42", "#26a343", "#27a745", "#28ac47", "#29b048", "#2ab54a", "#2bb94c", "#2cbd4d", "#2dc24f", "#2ec651"]简单粗暴点的
sudo apt-get install nginx默认位置:
/usr/sbin/nginx:主程序
/etc/nginx:存放配置文件
默认使用/etc/nginx/conf.d/*.conf的配置,以后写nginx代理都放在conf.d目录下面。
/usr/share/nginx:存放静态文件
/var/log/nginx:存放日志
简单粗暴,cd /etc/nginx/conf.d/
cd /etc/nginx/conf.d/
vi docs.conf
server {
listen 80;
server_name docs.icodin.cn;
rewrite ^(.*) https://$server_name$1 permanent; // 自动从http跳转到https
}
server{
listen 443 ssl; // 端口出来443还可以是其他端口,访问时加上端口号即可,同时开启ssl
server_name docs.icodin.cn; // 可以使用localhost也可以使用自己的域名,记得将dns记录指向你的服务器ip
charset utf-8;
client_max_body_size 75M;
ssl_certificate /etc/nginx/conf.d/candy.crt; // 等会会生成的证书
ssl_certificate_key /etc/nginx/conf.d/candy.key;
ssl_ciphers ALL:!DH:!EXPORT:!RC4:+HIGH:!MEDIUM:!LOW:!aNULL:!eNULL;
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 5m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
location / {
root /home/ubuntu/web/docs/; // 将你的静态文件放在这个目录,默认渲染index.html或者index.htm
}
}简单粗暴,在/etc/nginx/conf.d目录下面执行,反正遇到permission deny啥的直接加sudo就好了。
openssl genrsa -des3 -out candy.key 1024 // 生成私钥
openssl req -new -key candy.key -out candy.csr // 生成证书签名请求
openssl rsa -in candy.key-out candy.key // 移除私钥的密码
openssl x509 -req -days 365 -in candy.csr -signkey candy.key -out candy.crt // 生成证书
ls
candy.crt candy.csr candy.key将你的静态页面上传或者github拉取(ssh啥的自己配),反正各种自己的方式把你的静态文件放到刚刚配置的nginx里面的root文件夹里,/home/ubuntu/web/,比如我将docs项目放到了web文件下。
还是记一下吧(ssh啥的)
ssh-keygen
cat ~/.ssh/id_rsa.pub
复制粘贴到github的sshkey配置里面ok,最后一步,执行
nginx -s reload浏览器打开 https://docs.icodin.cn (或者你自己配的域名,或者直接ip访问),boom!大功告成。可算是放到一起了,不用再这里谷歌一下怎么生存自签名,哪里谷歌一下怎么配置nginx的ssl了,毕竟老是记不得的。。
早些时候想知道人家开源的github上面的这俩badge是咋来的,大概知道是个代码编译成功,并测试通过,且展示测试代码覆盖率的东东,绿绿的看起来感觉很舒服很放心。

那么我们如何让自己的小代码也可以带上这看起来高大上,其实也没啥的东西呢。
首先我们的源码需要包含一些测试代码,并需要配置一些生成覆盖率的玩意。不想多说,随着tdd/bdd的流行,开源项目,不仅仅只是意味着贡献了一个开源项目,想要获得大家的信任和使用,对自己的源码就要有高要求,所以需要加测试,要把每一个函数都测试到(即代码覆盖率),让别人相信我的代码没有任何问题。而目前比较流行的测试栈一般为macha+istanbul+chai或者ava+istanbul+nyc等各种组合。
具体如何对源码进行测试并生成报告,可以参考这篇文章
Travish CI的意思是持续集成,在团队开发中,每个成员每天都会随时随地的进行代码的提交,如何防止提交的代码没有通过测试就成功提交,如何使得每次提交都能让每个成员得知,Travish CI让每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽快地发现集成错误。
测试不通过的代码不能部署,配置了持续集成后,代码提交到服务器上,就可以自动跑测试,测试通过后,就可以部署到服务器上了。且Travis脚本可以做很多事情,可以模拟生产环境,进行项目的打包和其他编译操作,如果编译或者打包不通过,将无法成功提交到服务器,这里将要说的实际就是github服务器。
首先在项目根目录下添加.travis.yml文件
language: node_js
repo_token: COVERALLS.IO_TOKEN
node_js:
- '7'
cache:
directories:
- node_modules
script: npm run nyc这里表示当push代码到github的时候,travis会自执行了测试命令npm run nyc。
"nyc": "nyc ava -vs && nyc report --reporter=html",npm run nyc执行了测试代码并生成测试报告.
到travis CI的官网,打开想要实施自动持续部署的项目。

然后执行git的push操作,就能发现,travis该repo下已经开始自动部署测试了。可以看到控制台日志。

并且会发现,标题那里,出现了你想要的这玩意

点击这个badge,选择md格式,复制这个链接到你的项目的readme开头

再试这提交一次,你会发现,你的readme就多了这个绿色的表示passing的
本地安装coveralls工具
npm i -D coverallsscript里面添加一句coveralls命令
"coverage": "node ./node_modules/istanbul/lib/cli.js cover ./node_modules/mocha/bin/_mocha -- --compilers js:babel-core/register --reporter mochawesome -R spec --timeout 5000 --recursive",
"coveralls": "npm run-script coverage && node ./node_modules/coveralls/bin/coveralls.js < coverage/lcov.info"npm run coveralls`执行了代码覆盖率生成,并且将生成的数据发送到coveralls官网的服务器,关联到自己的对应的仓库。
然后在travis.yml末尾添加两句
after_script: npm run coveralls
env:
global:
secure: 你的coveralls token加密后的这里说一下这个secure怎么来的,首先到coveralls官网,使用github登陆,在ADD REPOS里面选择该repo

完了在repos里面该仓库下就能找到token

在项目根目录下新建.coveralls.yml,复制
service_name: travis-pro
repo_token: 你的token由于这个token不要暴露在代码中,我们先在.gitignore里面把这个文件ignore掉,然后安装travis将token加密一下,具体方法是,
ruby -v # 确保安装了ruby
gem install travis
# 注意: 在项目根目录下执行
travis encrypt COVERALLS_TOKE=你的token就能得到很长的一段secure。
同时在界面底部找到badge图标,拿到md格式,粘贴到readme开头

然后提交代码,看到travis自动执行了两个脚本,一个是测试脚本,一个是代码覆盖率生成脚本,最后看到的界面是
travis:

coveralls:

webpack打包的第三方模块过大,导致最后压缩打包的dist很大,首屏加载的时候,需要等待的时间会比较长,一种有效的解决方法是将臃肿的第三方包使用cdn引入,
这么做可以将我们的压力分给其他服务器点,减轻自身的服务器压力。
使用方式
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/vue.js"></script>
<script src="//cdn.bootcss.com/vue-router/3.0.1/vue-router.min.js"></script>
<script src="//unpkg.com/vuex"></script>这时候你会发现,这段代码放在head里面,没有任何问题,开发也正常,但是发布到生产环境的时候,发现不是生产环境的vue,把 vue.js 换成 vue.min.js。
这是一个更小的构建,可以带来比开发环境下更快的速度体验。这时候会手动把vue换成
<script src="//cdn.jsdelivr.net/npm/vue"></script>然而,你会发现,开发环境下又没法进行调试。
于是Vue.js API文档上网查了下,发现了一个vue全局apiVue.config.devtool = true,
该配置用于使vue生产环境版本开启调试模式。于是你在代码中引入
if (process.env.NODE_ENV === 'development') {
Vue.config.devtool = true;
}然而,你发现,根本没有用,依然没有打开调试模式啊,最后,我找到了了原因,需要将vue的引入放在body后面而不是head里面
<body>
<div id="app">
</div>
<script src="//cdn.jsdelivr.net/npm/vue"></script>
<script src="//cdn.bootcss.com/vue-router/3.0.1/vue-router.min.js"></script>
<script src="//unpkg.com/vuex"></script>
</body>真的是很笨,半天才知道是这么回事。
今天被问到一个问题,假设页面只有一个按钮(仅仅只有一个,很简单的元素),有两种方式改变这个按钮上面的文字,一个是使用vue的数据绑定,另一个是使用jquery操作dom,问哪种方法性能更好。
首先,jquery和vue的差别在于,vue是先监听绑定数据,然后通知watcher,将变化放映到虚拟dom,然后操作真实dom,jquery是直接操作dom。
很多时候手工优化dom确实会比virtual dom效率高,对于比较简单的dom结构用手工优化没有问题,但当页面结构很庞大,结构很复杂时,手工优化会花去大量时间,而且可维护性也不高,不能保证每个人都有手工优化的能力。至此,virtual dom的解决方案应运而生,virtual dom很多时候都不是最优的操作,但它具有普适性,在效率、可维护性之间达平衡。解析vue2.0的diff算法
所以,对于dom操作频繁,不需要动画效果,就使用vue.js,对于dom操作不频繁,但又需要复杂的动画效果,就使用jquery。
大头来了,接下来我会一步一步实现简单意义上理解的vue状态更新原理,主要从数据,监听器,订阅者三个方面入手,目的不在于实现复杂可靠的mvvm框架,只是用于方便理解vue的双向数据绑定原理。
首先,定义一个数据源,该数据后续会被Obsever劫持,拦截它的get和set操作,并在get的时候添加订阅者,set的时候通知订阅者。定义一个全局的target,用于表示当前将要推入的订阅者,在get的时候推入调度器数组deps。注意这个data将作为全局共享的数据源。
新建一个文件mvvm.js
const data = {
key: 1,
user: {
name: 'candy'
}
}
// 定义一个全局的订阅者,表示当前将要推入的订阅者。将来就是那个watcher的实例
let target = null;定义一个Observer监听器,将data劫持,拦截get和set。
function Observer(data) {
this.data = data;
this.walk(data); // 遍历第一层属性
}
Observer.prototype = {
walk: function(data) {
for (const key of Object.keys(data)) {
this.convert(key, data[key]); // 劫持转化第一层属性
}
},
convert: function(key, val) {
this.defineReactive(this.data, key, val);
},
defineReactive: function(data, key, val) {
let childObj = observe(val); // 监听子属性
Object.defineProperty(data, key, {
configurable: false,
enumerable: true,
get: function() {
console.log('哈哈,拦截到了get')
return val;
},
set: function(newVal) {
if (newVal === val) return;
val = newVal;
console.log('哈哈,拦截到了set')
}
})
}
}尝试给data读取和改变属性值,
data.key; //哈哈,拦截到了get
data.key = 111; //哈哈,拦截到了set由于数据可能是多层嵌套的,所以需要遍历里面的属性和子属性,改造如下。
// 添加一个辅助函数
function observe(value) {
if (!value || typeof value !== 'object') {
return;
}
return new Observer(value);
};
Observer.prototype = {
// .....省略
defineReactive: function(data, key, val) {
let childObj = observe(val); // 监听子属性
Object.defineProperty(data, key, {
configurable: false,
enumerable: true,
get: function() {
console.log('哈哈,拦截到了get')
return val;
},
set: function(newVal) {
if (newVal === val) return;
val = newVal;
console.log('哈哈,拦截到了set')
childObj = observe(newVal); // 监听新的子属性
}
})
}
}尝试给data读取和改变属性值,
data.user.name; //哈哈,拦截到了get
data.user.name = 'candy'; //哈哈,拦截到了set拦截功能做到了,再改造一下使之具有订阅和发布功能。
// 定义一个全局的调度器deps
const deps = [];
Observer.prototype = {
// ...省略
defineReactive: function(data, key, val) {
let childObj = observe(val); // 监听子属性
Object.defineProperty(data, key, {
configurable: false,
enumerable: true,
get: function() {
if (target) {
deps.push(target); // 若当前注册了target订阅者,将其推入到deps调度器中
}
return val;
},
set: function(newVal) {
if (newVal === val) return;
val = newVal;
childObj = observe(newVal); // 监听新的子属性
deps.forEach(target => target.update()); // 该属性改变时,遍历调度器,将变化发布给订阅者。
}
})
}
}上述代码实现了监听器,监听了数据属性的getter和setter,便于订阅和通知发布。
上述代码中的target即是订阅者watcher实例,定义一个Watcher
function Watcher(vm, exp, cb) {
this.cb = cb; // 订阅者监听到发布者发布的变化后,调用的回调,也是我们最终的目的,这个回调可以用于dom更新等后续操作。
this.exp = exp; // 表达式,比如要获取data.user.name,就传入'user.name',获取data.key就传入'key'
this.vm = vm; // 传入的数据源
this.value = this.get(); // 获取数据源的数据,触发get事件,将this推入deps,实现订阅
}
watcher.prototype = {
update: function() {
this.run(); // update方法用于接收发布,执行run方法,并调用回调
},
run: function() {
const value = this.get(); // 获取最新值
const oldVal = this.value; // 取出旧值
if (value !== oldVal) {
this.value = value; // 保存新值
this.cb.call(this, value, oldVal); // 执行回调
}
},
get: function() {
target = this; // 准备把自身推入deps
const val = this.parseGetter(this.exp).call(this, this.vm); // parseGetter用于解析表达式
target = null;
return val;
},
parseGetter: function(exp) {
if (/[^\w.$]/.test(exp)) return;
const exps = exp.split('.'); // 点操作符获取属性值
return function(obj) {
// obj是传入被改造过的数据源
for (const item of exps) {
if (!obj) return;
obj = obj[item]; // 真正执行了被改造过的数据源的get
}
return obj;
}
}
}见证奇迹的时刻到了,初始化几个Wathcer,定义callback函数
function callback(val, oldVal) {
// 回调函数中获取到新值
console.log(val, oldVal);
}
const watch = new watcher(data, 'key', callback);
data.key = 111;
const watch2 = new watcher(data, 'value', callback);
data.user= {
sex: 2
};boom !!! 可以看到控制台打出新值和旧值,成功监听了data的属性变化,并利用这个监听执行了绑定的回调。
虽然在此次的理解中没有涉及到dom上的双向绑定,但是已经到回调那一步了,接下来就是那个回调咋写的问题了,vue中定义了compile编译器,解析类似这种{{data.key}}和其他指令的约定格式,使之成为一个个订阅者。每种dom结构对应有自己各自的回调函数,当监听到数据变化时,要做的就是在回调函数中把新值反映到dom中。
加油,fighting!!
查询了html2canvas的issue,发现原因是因为字体设置了 font-variant: tabular-nums,于是在代码中查找该属性,并没有,然而在浏览器中查找到了该属性,原来是antd的样式里面有这个设置,至于font-variant是干啥的,字体研究太深奥了,不管他。
在body中设置font-variant为normal就ok了,同时也解决了字符错位问题。
由于传入的width和height使用了clientWidth取值,默认是取整的,因此白边的产生就是实际元素多出来的小数点。使用target.getBoundingClientRect().width.toFixed(2)替换clientWidth,因为元素默认保留后两位,所以fixed2,但是还有问题,因为这样得到的不是数值,是字符串,无法生效,因此在前面加个+使之变成数字即可。
在项目开发的时候常常会遇到有的功能,比如在线视频和语音等需要上https才能使用和测试,因此需要我们的开发环境也具备https,即便是不安全的证书也可以试用。那么我们就看看如何配置本地https环境。
vue-cli构建
使用vue-cli搭建的项目,没有https,那么我们打开/build/dev-server.js文件,里面是一个express写的服务器。加入以下代码:
const https = require('https');
const fs = require('fs');
var privateKey = fs.readFileSync(path.join(__dirname, './cert/private.pem'), 'utf8');
var certificate = fs.readFileSync(path.join(__dirname, './cert/file.crt'), 'utf8');
var credentials = {key: privateKey, cert: certificate};在const port = process.env.PORT || config.dev.port;后面添加一行,在此之前在config/index.js文件中的dev对象里面加入httpsPort: process.env.PORT || 8084`
const httpsPort = process.env.httpsPort || config.dev.httpsPort;
``
再在server = app.listen(port);后面加入这几行代码开启https服务。
```js
server = app.listen(port);
var httpsServer = https.createServer(credentials, app);
httpsServer.listen(httpsPort, function() {
console.log('HTTPS Server is running on: https://localhost:%s', httpsPort);
});生成本地证书
在build目录下新建一个目录cert。
openssl genrsa 1024 > /build/cert/private.pem openssl req -new -key /build/cert/private.pem -out csr.pemopenssl x509 -req -days 365 -in csr.pem -signkey /build/cert/private.pem -out /build/cert/file.crt我们知道react或者是其他用于写单页应用的框架都是组件化的概念,每个路由每个页面就是一个个大组件,webpack在打包的时候,将所有的文件都打包进一个bundle里面,但是我们往往在a页面的时候不需要加载b页面的东西,理想情况下,用户访问一个页面时,该页面应该只需要加载自己使用到的代码,为了提高性能,webpack支持代码分片,将js代码打包到多个文件中按需加载。
按需加载的方式有两种,一个是 webpack提供的require.ensure(),一个是 ES6提案的import()
下面我们写一个asyncComponent异步加载方法,分别使用这两种方式实现。其实是写了一个高阶组件,高阶组件的理解可以看这篇文章。
webpack提供了require.ensure(),webpack 在编译时,会静态地解析代码中的 require.ensure(),同时将模块添加到一个分开的 chunk 当中。这个新的 chunk 会被 webpack 通过 jsonp 来按需加载。
// asyncCmponent.js
import React, { Component } from 'react';
export default function asyncComponent (importFunc) {
return class App extends Component {
constructor(props) {
super(props);
this.state = {
component: null
}
};
componentDidMount = () => {
importFunc().then(mod => {
this.setState({
component: mod.default || mod
})
});
}
render = () => {
const C = this.state.component;
return (
C ? <C {...this.props} /> : null
)
}
}
}调用
import asyncCmponent from './asyncCmponent.js';
const App = asyncCmponent(() => require.ensure([], (require) => require('./App')));
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById('root')
);打开浏览器,可以看到除了bundle.js还多了个1.js,且bundle的体积被拆分出来了。
es6中我们知道import是用于加载使用export命令定义的模块,import和require的区别在于import是在静态解析阶段执行的,所以它是一个模块之中最早执行的,而require是动态加载的,运行时加载模块,import命令无法取代require的动态加载功能。require到底加载哪一个模块,只有运行时才知道。import命令做不到这一点。因此,有一个提案,建议引入import()函数,完成动态加载。详情请看《es6入门》
import()函数返回的是一个promise。
// 只需修改componentDidMount部分
componentDidMount = () => {
importFunc().then(mod => {
this.setState({
component: mod.default || mod
})
})
}调用
const App = asyncCmponent(() => import('./App')));打开浏览器,可以看到同样的效果。boom!!!
要求:该连线必须从球体的边缘出发
已知:球体在三维空间中的半径,球体中心坐标
实现方案:
效果:

代码:
var sourcePosition3D = new THREE.Vector3(0, 0, 0);
var targetPosition3D = new THREE.Vector3(0, 0, 0);
sourcePosition3D.copy(sourceSphere.sphere.position); // 球心坐标
targetPosition3D.copy(targetSphere.sphere.position);
var sourcePoint = HelperMethods.get2DCoords(sourcePosition3D, camera, this.width, this.height);
var targetPoint = HelperMethods.get2DCoords(targetPosition3D, camera, this.width, this.height);
const sourced = sourceSphere.sphere.position.distanceTo(camera.position) // 视角到球心的距离
const sourceRadius = HelperMethods.computeProjectedRadius(camera.fov, sourced, sourceSphere.sphere.geometry.parameters.radius * sourceSphere.sphere.scale.x, this.width, this.height);
const targetd = targetSphere.sphere.position.distanceTo(camera.position)
const targetRadius = HelperMethods.computeProjectedRadius(camera.fov, targetd, targetSphere.sphere.geometry.parameters.radius * targetSphere.sphere.scale.x, this.width, this.height);
const tan = (targetPoint.y - sourcePoint.y) / (targetPoint.x - sourcePoint.x);
const deg = Math.atan(tan);
const diffx = targetPoint.x - sourcePoint.x;
const diffy = targetPoint.y - sourcePoint.y;
diffx > 0 ? sourcePoint.x = sourcePoint.x + sourceRadius * Math.abs(Math.cos(deg)) : sourcePoint.x = sourcePoint.x - sourceRadius * Math.abs(Math.cos(deg));
diffy > 0 ? sourcePoint.y = sourcePoint.y + sourceRadius * Math.abs(Math.sin(deg)) : sourcePoint.y = sourcePoint.y - sourceRadius * Math.abs(Math.sin(deg));
const tan1 = (sourcePoint.y - targetPoint.y) / (sourcePoint.x - targetPoint.x);
const deg1 = Math.atan(tan1);
const diffx1 = targetPoint.x - sourcePoint.x;
const diffy1 = targetPoint.y - sourcePoint.y;
diffx1 > 0 ? targetPoint.x = targetPoint.x - targetRadius * Math.abs(Math.cos(deg1)) : targetPoint.x = targetPoint.x + targetRadius * Math.abs(Math.cos(deg1));
diffy1 > 0 ? targetPoint.y = targetPoint.y - targetRadius * Math.abs(Math.sin(deg1)) : targetPoint.y = targetPoint.y + targetRadius * Math.abs(Math.sin(deg1));关键方法 computeProjectedRadius
computeProjectedRadius: function(fovy, d, r, width, height) {
var fov;
fov = fovy / 2 * Math.PI / 180.0;
// zoom = r / R = d / D = d / height / (2 * Math.tan(fov)) = d * 2 * Math.tan(fov) / height;
// so R = r / (d * 2 * Math.tan(fov) / height)
return r / (Math.tan(fov) * d * 2 / height); // Right
}关键在于一个比例问题,参考这张图

其中 zoom = d / D
D:相机与屏幕所在平面的距离,
d:相机与元素A的距离
在球体上体现为,d为相机到球心的距离,D可以通过H和fov视野角度求出,所以 zoom = d / D = r / R
无意中看到你这这个文档,很棒
Originally posted by @xiaohongzhou in #3 (comment)
今天来梳理一下commonjs和AMD和CMD三种模块加载规范。
commonjs是nodejs在服务器端的模块规范,很多的后端语言比如python和java都有模块的概念,而nodejs作为js语法,也需要实现一套模块加载器,才能更好地作为服务端语言。
使用方式
// a.js
console.log(444);
const privateVar = 'haha';
module.exports = {
name: 'candy',
sex: 1
}
// main.js
const a = require('./a.js'); // 444
console.log(a.name); // candy以上代码可以看到,一个单独的文件就是一个模块,模块的内部变量无法被外部知道,除非定义为global变量,或者通过接口方式暴露出来。使用module.exports输出,使用require加载,es6中可以使用export输出,使用import加载,require和import的区别在于require是运行时加载执行模块,而import是编译时加载并执行。
可以看到,以上require是同步的代码,所以需要先加载好了模块,才能进行模块接口的调用,而这在浏览器端是无法适用的,因为浏览器端的js是从服务器端获取,他的加载速度取决于网络环境等多种因素,而服务器端的js直接从硬盘加载。因此AMD和CMD浏览器端模块规范应运而生。
AMD(Asynchronous Module Definition)异步模块定义,它采用异步方式加载模块,模块的加载不影响它后面语句的运行。所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会运行。这种加载方式解决了浏览器端的两个问题
使用方式
// a.js
define(['./b.js'], function(b) {
return {
name: 'candy',
sex: 1
}
})
// index.html
<script>
require(['./a.js'], function(a) {
console.log(a.name);
}); // 444 candy
</script>define的工厂方法factory,是模块初始化要执行的函数或对象。如果为函数,它应该只被执行一次,它的参数是前面依赖数组加载的顺序得到的模块,如果数组为空,参数默认为require,exports,module。如果是对象,此对象应该为模块的输出值。这里的a.name的使用和a模块的加载是异步的,因此不会阻塞浏览器。
requirejs使用模块的方式也是require,但是这个require和commonjs的不一样的,它是异步的。
CMD(Common Module Definition)通用模块定义,它和requirejs都是为了解决浏览器端模块加载,但是区别在于模块的加载机制和加载时机上的不同,AMD是依赖关系前置,在定义模块的时候就要声明其依赖的模块,并且执行模块;CMD是按需加载依赖就近,只有在用到某个模块的时候才会去执行
// CMD
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
var b = require('./b') // 依赖可以就近书写,cmd在静态解析的时候将工厂函数toString,正则匹配到require,然后将依赖加载,在使用的时候执行
b.doSomething()
})
// AMD
define(['./a', './b'], function(a, b) { // 依赖前置,在静态解析的时候就已经执行。
a.doSomething()
b.doSomething()
})
// b.js
define(function(require, exports, module) {
console.log(888)
exports.bdata = 2;
});
// a.js
define(function(require, exports, module) {
const b = require('./b'); // 此处不会打印888因为没有使用b
b.bdata; // 此处会打印888,因为使用了b的接口
exports.adata = 1;
});
// index.html
seajs.use(['a.js'], function(my){
var star= my.adata;
console.log(star); //1
});CMD中的工厂函数,它只是define函数的一个参数,并不会被直接执行,而是会在需要的时候由专门的函数来调用生成接口。所以, 一个模块文件被浏览器下载下来后,并不会直接运行我们的模块定义代码,而是会首先执行一个define函数,这个函数会取得模块定义的源代码(通过函数的toString()函数来取得源代码),然后利用正则匹配找到依赖的模块(匹配require("dep.js")这样的字符串),然后加载依赖的模块,最后发射一个自定义事件complete,通知当前模块, 模块已经加载完成,此时,当前模块的就会调用与complete事件绑定的回调函数,完成与这个模块相关的任务,比如resolve与这个模块加载绑定的Promise。
作者:知乎用户
链接:https://www.zhihu.com/question/21308647/answer/118271737
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
boom!!!
使用webpack,最直观的可以看到打包后的结果是webpack将所有文件整合生成了一个bundle.js文件,然后往html文件里面一塞,就完事了。这么神奇,那么探索的入口就在于这个bundle.js(也没有别的入口了。。。)
由于浏览器没法直接执行CommonJS规范的模块,而webpack通过对js代码的解析和抽象,将入口文件转换成立即执行函数,将依赖模块包裹成函数,实现了模块化编程。
我们查看bundle的源码可以发现它是一个立即执行函数,这个函数的参数是modules,即webpack经过某种神力(其实是js代码解析工具,将js代码抽象成语法树(AST),然后深度遍历出一个模块依赖关系对象)整理出来的一个模块数组。数组的每个元素,都是一个函数,函数参数是module, exports, webpack_require。这个函数包裹的函数体就是每个模块的代码,其中参数module和exports是webpack自己实现的一套模块机制,类似于commonjs原理,这里使用webpack的模块机制将市面上各种AMD,CMD,commonjs等模块加载机制统一成webpack的这套机制。
webpack_require是webpack核心的模块加载函数,它通过模块id(遍历生成的),找到对应模块,执行并将模块的导出对象,变成module模块的exports对象的属性。其中这个module就是新创建的模块,如果该模块已创建过了,则使用缓存installedModule。
经过以上简单分析,可以得到如下简单的代码:
(function(modules){
function webpack_require(moduleId) {
// 缓存模块
const installedModule = {};
if (installedModule[moduleId]) {
return installedModule[moduleId].exports;
}
// 新建模块
const module = {
id: moduleId,
exports: {}
}
// 调用模块函数,执行里面的源码,将到处对象挂载到新建模块的exports上面,内部依赖递归调用
// webpack_require函数
modules[moduleId].call(module.exports, module, module.exports, webpack_require);
// 加入缓存
installedModule[moduleId] = module;
// 返回导出对象
return module.exports;
}
return webpack_require(0); // 执行入口文件,modules数组的第一个元素
})([function(module, exports, webpack_require) {
// 0 app.js入口文件
console.log(333)
const moduleA = webpack_require(1); // 执行依赖文件,modules数组的第二个元素
const b = moduleA.a * 2;
console.log(b);
}, function(module, exports, webpack_require) {
// 1 a.js
let a = 1;
function aa() {
console.log(111)
};
module.exports = {
a,
aa
}
}])boom!!!,执行一下这段代码,可以看到正常打出333 2,执行了入口文件并执行了依赖文件。
其中 a.js和app.js都被一个函数包裹起来了,这个函数实现了将模块源码里面的commonjs语法或者其他模块加载语法导出的属性(commonjs原生支持,其他语法用相应的loader解析),转换成参数module和exports上面的属性导出。
function(module, exports, webpack_require) {
// 模块代码
}那么代码分割,按需引入的模块是如何加载的呢,自然不能使用直接call执行函数了,webpack中定义了专门的方法,webpack_require.e函数将代码通过script标签的形式动态加载,加载完成后,调用回调函数webpackJsonp执行模块代码。模拟了类似jsonp原理。
理解到这先。。。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
