
pip install rudalle==1.1.3
ruDALL-E Malevich (XL)
ruDALL-E Emojich (XL) (readme here)
ruDALL-E Surrealist (XL)
ruDALL-E Kandinsky (XXL) (soon)

Example usage ruDALL-E Malevich (XL) with 3.5GB vRAM!
Finetuning example
import ruclip
from rudalle.pipelines import generate_images, show, super_resolution, cherry_pick_by_ruclip
from rudalle import get_rudalle_model, get_tokenizer, get_vae, get_realesrgan
from rudalle.utils import seed_everything
# prepare models:
device = 'cuda'
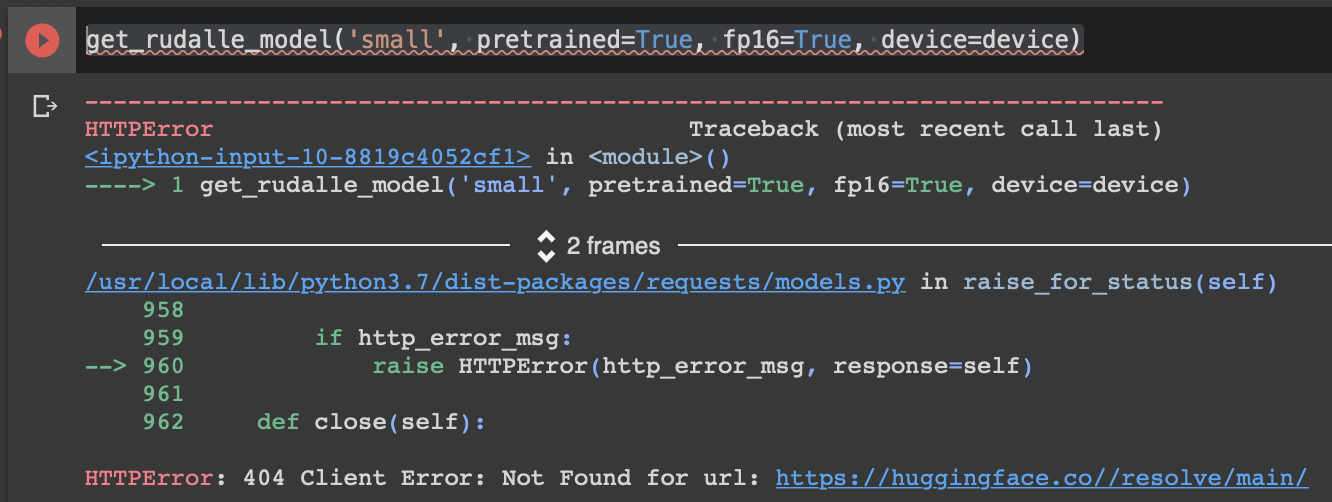
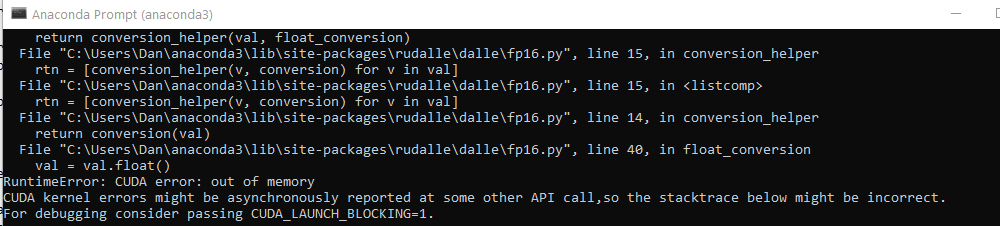
dalle = get_rudalle_model('Malevich', pretrained=True, fp16=True, device=device)
tokenizer = get_tokenizer()
vae = get_vae(dwt=True).to(device)
# pipeline utils:
realesrgan = get_realesrgan('x2', device=device)
clip, processor = ruclip.load('ruclip-vit-base-patch32-384', device=device)
clip_predictor = ruclip.Predictor(clip, processor, device, bs=8)
text = 'радуга на фоне ночного города'
seed_everything(42)
pil_images = []
scores = []
for top_k, top_p, images_num in [
(2048, 0.995, 24),
]:
_pil_images, _scores = generate_images(text, tokenizer, dalle, vae, top_k=top_k, images_num=images_num, bs=8, top_p=top_p)
pil_images += _pil_images
scores += _scores
show(pil_images, 6)
top_images, clip_scores = cherry_pick_by_ruclip(pil_images, text, clip_predictor, count=6)
show(top_images, 3)
sr_images = super_resolution(top_images, realesrgan)
show(sr_images, 3)
text, seed = 'красивая тян из аниме', 6955
see jupyters/ruDALLE-image-prompts-A100.ipynb
text, seed = 'Храм Василия Блаженного', 42
skyes = [red_sky, sunny_sky, cloudy_sky, night_sky]
Video generation example
Finetuning example
Aspect ratio images -->NEW<--

Request access: Here
роботы акварелью в стиле ван гога



FID = 15.4 (COCO Valid)
- @bes shared great idea and realization with IDWT for decoding images with higher quality 512x512! 😈💪 thanks a lot for your constructive advices, appreciate it
- @neverix thanks a lot for contributing for speed up of inference
- @Igor Pavlov trained model and prepared code with super-resolution
- @oriBetelgeuse thanks a lot for easy API of generation using image prompt
- @Alex Wortega created first FREE version colab notebook with fine-tuning ruDALL-E Malevich (XL) on sneakers domain 💪
- @Anton Lozhkov Integrated to Huggingface Spaces with Gradio, see here
![]()













![pre-commit-ci[bot] avatar](https://avatars.githubusercontent.com/in/68672?v=4 "pre-commit-ci[bot]")
























































































































































{kind=link}
{kind=link}
{kind=link}