aws / amazon-documentdb-jdbc-driver Goto Github PK
View Code? Open in Web Editor NEWAmazon DocumentDB JDBC driver to connect from BI tools and execute SQL Queries
License: Apache License 2.0
Amazon DocumentDB JDBC driver to connect from BI tools and execute SQL Queries
License: Apache License 2.0






![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")
















The signature of the AWS DocumentDB connector file you uploaded has expired. As a result, I am currently using the command -DDisableVerifyConnectorPluginSignature=true forcefully. I believe, as much as you do, that this is not an ideal solution.
I kindly request you to promptly update the signature on the intact taco file. I implore you to save me from this situation.
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
A clear and concise description of what you want to happen.
A clear and concise description of any alternative solutions or features you've considered.
Add any other context or screenshots about the feature request here.
DocumentDbQueryMappingService original exceptions can be hidden on call to getExceptionMessages(e) - for example, if it throws a null pointer exception, hiding the original exception. This should be adjusted to ensure that the original error is preserved, and other error handling should be investigated to look for similar issues.Add full support for PreparedStatment where parameter values are prepared with a SQL statement with replaceable parameter placeholders.
Refer to Oracle documentation
Statements work, but you need to provide the values in-line with the SQL statement.
None.
org.jkiss.dbeaver.model.sql.DBSQLException: SQL Error: Unsupported SQL syntax 'SELECT "key", "val" FROM test_table where val <> val'. Please refer to the list of the supported features.
at org.jkiss.dbeaver.model.impl.jdbc.exec.JDBCStatementImpl.executeStatement(JDBCStatementImpl.java:133)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.executeStatement(SQLQueryJob.java:582)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.lambda$1(SQLQueryJob.java:491)
at org.jkiss.dbeaver.model.exec.DBExecUtils.tryExecuteRecover(DBExecUtils.java:173)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.executeSingleQuery(SQLQueryJob.java:498)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.extractData(SQLQueryJob.java:924)
at org.jkiss.dbeaver.ui.editors.sql.SQLEditor$QueryResultsContainer.readData(SQLEditor.java:3805)
at org.jkiss.dbeaver.ui.controls.resultset.ResultSetJobDataRead.lambda$0(ResultSetJobDataRead.java:123)
at org.jkiss.dbeaver.model.exec.DBExecUtils.tryExecuteRecover(DBExecUtils.java:173)
at org.jkiss.dbeaver.ui.controls.resultset.ResultSetJobDataRead.run(ResultSetJobDataRead.java:121)
at org.jkiss.dbeaver.ui.controls.resultset.ResultSetViewer$ResultSetDataPumpJob.run(ResultSetViewer.java:5073)
at org.jkiss.dbeaver.model.runtime.AbstractJob.run(AbstractJob.java:105)
at org.eclipse.core.internal.jobs.Worker.run(Worker.java:63)
Caused by: java.sql.SQLFeatureNotSupportedException: Unsupported SQL syntax 'SELECT "key", "val"FROM test_table where val <> val'. Please refer to the list of the supported features.
at software.amazon.documentdb.jdbc.common.utilities.SqlError.createSQLFeatureNotSupportedException(SqlError.java:220)
at software.amazon.documentdb.jdbc.query.DocumentDbQueryMappingService.get(DocumentDbQueryMappingService.java:161)
at software.amazon.documentdb.jdbc.DocumentDbQueryExecutor.runQuery(DocumentDbQueryExecutor.java:172)
at software.amazon.documentdb.jdbc.DocumentDbQueryExecutor.executeQuery(DocumentDbQueryExecutor.java:125)
at software.amazon.documentdb.jdbc.DocumentDbStatement.executeQuery(DocumentDbStatement.java:98)
at software.amazon.documentdb.jdbc.common.Statement.execute(Statement.java:107)
at org.jkiss.dbeaver.model.impl.jdbc.exec.JDBCStatementImpl.execute(JDBCStatementImpl.java:329)
at org.jkiss.dbeaver.model.impl.jdbc.exec.JDBCStatementImpl.lambda$0(JDBCStatementImpl.java:131)
at org.jkiss.dbeaver.utils.SecurityManagerUtils.wrapDriverActions(SecurityManagerUtils.java:96)
at org.jkiss.dbeaver.model.impl.jdbc.exec.JDBCStatementImpl.executeStatement(JDBCStatementImpl.java:131)
... 12 more
This has been noted in Known Issues but we were hoping to increase the priority of this issue as it is preventing some queries from running that are important to our development of a connector using this driver.
SELECT TIME '20:17:40' FROM collectionConversion between the source type (Integer) and the target type (Date) is not supported.Conversion between the source type (Integer) and the target type (Date) is not supported.
java.sql.SQLException: Conversion between the source type (Integer) and the target type (Date) is not supported.
at software.amazon.documentdb.jdbc.common.utilities.SqlError.createSQLException(SqlError.java:191)
at software.amazon.documentdb.jdbc.DocumentDbAbstractResultSet.getValue(DocumentDbAbstractResultSet.java:173)
at software.amazon.documentdb.jdbc.DocumentDbAbstractResultSet.getDate(DocumentDbAbstractResultSet.java:317)
at software.amazon.documentdb.jdbc.DocumentDbAbstractResultSet.getTime(DocumentDbAbstractResultSet.java:335)
at software.amazon.documentdb.jdbc.DocumentDbAbstractResultSet.getTime(DocumentDbAbstractResultSet.java:249)
Caused by: org.apache.commons.beanutils.ConversionException: Default conversion to java.sql.Date failed.
at org.apache.commons.beanutils.converters.AbstractConverter.handleMissing(AbstractConverter.java:314)
at org.apache.commons.beanutils.converters.AbstractConverter.handleError(AbstractConverter.java:269)
at org.apache.commons.beanutils.converters.AbstractConverter.convert(AbstractConverter.java:177)
at software.amazon.documentdb.jdbc.DocumentDbAbstractResultSet.getValue(DocumentDbAbstractResultSet.java:171
Created projection stages of pipeline.
Pipeline stages added: {$project: {'EXPR$0': {"$literal": 73060000}, _id: 0}}
Query 1926e6b5-33f4-4e5a-84a3-a2cfdcfaedc6: Took 2057 ms to translate query.
Sending command '{"aggregate": "collection", "pipeline": [{"$project": {"EXPR$0": {"$literal": 73060000}, "_id": 0}}], "cursor": {"batchSize": 2000}, "$db": "resultDatabase", "lsid": {"id": {"$binary": {"base64": "qpsgQdszQWOv3kr6DfGdVQ==", "subType": "04"}}}}' with request id 46 to database resultDatabase on connection [connectionId{localValue:9, serverValue:10}] to server localhost:55921
Execution of command with request id 46 completed successfully in 13.97 ms on connection [connectionId{localValue:9, serverValue:10}] to server localhost:55921
Query 1926e6b5-33f4-4e5a-84a3-a2cfdcfaedc6: Took 36 ms to execute query and retrieve first batch of results.
Query 1926e6b5-33f4-4e5a-84a3-a2cfdcfaedc6: Executed on collection collection with following pipeline operations: [{"$project": {"EXPR$0": {"$literal": 73060000}, "_id": 0}}]
Converting 'Integer' value '73060000' to type 'java.sql.Date'
IntegerConverter cannot handle conversion to 'java.sql.Date'
Conversion threw ConversionException: IntegerConverter cannot handle conversion to 'java.sql.Date'
IntegerConverter cannot handle conversion to 'java.sql.Date'
Conversion between the source type (Integer) and the target type (Date) is not supported.
I am trying to run logstash pipeline which requires to get input (data from DocumentDB 'Mongo') and output to elasicSearch.
input {
jdbc{
jdbc_driver_library => ""
jdbc_driver_class => "software.amazon.documentdb.jdbc.DocumentDbMain"
jdbc_connection_string => "jdbc:documentdb://user:[email protected]/testDB?tlsAllowInvalidHostnames=true&tlsCAFile=rds-combined-ca-bundle.pem>
jdbc_user => ""
jdbc_password => ""
statement => "select * FROM `products` where `id` = 10"
}
}
filter {}
output{
stdout { codec => rubydebug { metadata=> true } }
elasticsearch {
action => "update"
doc_as_upsert => true
index => "logstash-products-index"
hosts => ["localhost:9200"]
user => ""
password => ""
}
}
Get product from DocumentDB and add to ElasticSearch.
When the pipeline is run, it fails and throws error.
[ERROR] 2022-12-19 14:52:25.217 [Ruby-0-Thread-17: :1] javapipeline - Worker loop initialization error {:pipeline_id=>"main", :error=>"Must only be called before "cook()"", :exception=>Java::JavaLang::IllegalStateException, :stacktrace=>"org.codehaus.janino.SimpleCompiler.assertUncooked(org/codehaus/janino/SimpleCompiler.java:526)\norg.codehaus.janino.SimpleCompiler.cook(org/codehaus/janino/SimpleCompiler.java:252)\norg.codehaus.janino.SimpleCompiler.compileToClassLoader(org/codehaus/janino/SimpleCompiler.java:517)\norg.codehaus.janino.SimpleCompiler.cook(org/codehaus/janino/SimpleCompiler.java:241)\norg.codehaus.janino.SimpleCompiler.cook(org/codehaus/janino/SimpleCompiler.java:219)\norg.codehaus.commons.compiler.Cookable.cook(org/codehaus/commons/compiler/Cookable.java:79)\norg.codehaus.commons.compiler.Cookable.cook(org/codehaus/commons/compiler/Cookable.java:74)\norg.logstash.config.ir.compiler.ComputeStepSyntaxElement.lambda$compile$0(org/logstash/config/ir/compiler/ComputeStepSyntaxElement.java:150)\njava.util.concurrent.ConcurrentHashMap.computeIfAbsent(java/util/concurrent/ConcurrentHashMap.java:1708)\norg.logstash.config.ir.compiler.ComputeStepSyntaxElement.compile(org/logstash/config/ir/compiler/ComputeStepSyntaxElement.java:140)\norg.logstash.config.ir.compiler.ComputeStepSyntaxElement.instantiate(org/logstash/config/ir/compiler/ComputeStepSyntaxElement.java:124)\norg.logstash.config.ir.compiler.DatasetCompiler.terminalOutputDataset(org/logstash/config/ir/compiler/DatasetCompiler.java:212)\norg.logstash.config.ir.CompiledPipeline$CompiledExecution.compileOutputs(org/logstash/config/ir/CompiledPipeline.java:414)\norg.logstash.config.ir.CompiledPipeline$CompiledExecution.(org/logstash/config/ir/CompiledPipeline.java:379)\norg.logstash.config.ir.CompiledPipeline$CompiledUnorderedExecution.(org/logstash/config/ir/CompiledPipeline.java:337)\norg.logstash.config.ir.CompiledPipeline.buildExecution(org/logstash/config/ir/CompiledPipeline.java:156)\norg.logstash.execution.WorkerLoop.(org/logstash/execution/WorkerLoop.java:67)\njdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)\njdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(jdk/internal/reflect/NativeConstructorAccessorImpl.java:77)\njdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(jdk/internal/reflect/DelegatingConstructorAccessorImpl.java:45)\njava.lang.reflect.Constructor.newInstanceWithCaller(java/lang/reflect/Constructor.java:499)\njava.lang.reflect.Constructor.newInstance(java/lang/reflect/Constructor.java:480)\norg.jruby.javasupport.JavaConstructor.newInstanceDirect(org/jruby/javasupport/JavaConstructor.java:237)\norg.jruby.RubyClass.new(org/jruby/RubyClass.java:911)\norg.jruby.RubyClass$INVOKER$i$newInstance.call(org/jruby/RubyClass$INVOKER$i$newInstance.gen)\nusr.share.logstash.logstash_minus_core.lib.logstash.java_pipeline.init_worker_loop(/usr/share/logstash/logstash-core/lib/logstash/java_pipeline.rb:580)\nusr.share.logstash.logstash_minus_core.lib.logstash.java_pipeline.start_workers(/usr/share/logstash/logstash-core/lib/logstash/java_pipeline.rb:286)\norg.jruby.RubyProc.call(org/jruby/RubyProc.java:309)\njava.lang.Thread.run(java/lang/Thread.java:833)", :thread=>"#<Thread:0x2c74eb8e sleep>"}
N/A
select c1, coalesce(c1, {ts '1899-12-28 00:00:00'}) as c2
from
(
select CAST(NULL as TIMESTAMP) as c1
from sales.emp
)
group by c1 1899-12-28 00:00:00
Exception thrown:
cannot convert TIMESTAMP literal to class java.math.BigDecimal java.lang.AssertionError: cannot convert TIMESTAMP literal to class java.math.BigDecimal
cannot convert TIMESTAMP literal to class java.math.BigDecimal
java.lang.AssertionError: cannot convert TIMESTAMP literal to class java.math.BigDecimal
at org.apache.calcite.rex.RexLiteral.getValueAs(RexLiteral.java:1143)
at org.apache.calcite.rel.rules.ProjectAggregateMergeRule$1.visitCall(ProjectAggregateMergeRule.java:111)
at org.apache.calcite.rel.rules.ProjectAggregateMergeRule$1.visitCall(ProjectAggregateMergeRule.java:91)
at org.apache.calcite.rex.RexCall.accept(RexCall.java:189)
at org.apache.calcite.rex.RexVisitor.visitList(RexVisitor.java:63)
at org.apache.calcite.rex.RexVisitor.visitList(RexVisitor.java:71)
at org.apache.calcite.rel.rules.ProjectAggregateMergeRule.onMatch(ProjectAggregateMergeRule.java:132)
at org.apache.calcite.plan.AbstractRelOptPlanner.fireRule(AbstractRelOptPlanner.java:337)
at org.apache.calcite.plan.hep.HepPlanner.applyRule(HepPlanner.java:556)
at org.apache.calcite.plan.hep.HepPlanner.applyRules(HepPlanner.java:420)
at org.apache.calcite.plan.hep.HepPlanner.executeRuleInstance(HepPlanner.java:243)
at org.apache.calcite.plan.hep.HepInstruction$RuleInstance$State.execute(HepInstruction.java:178)
at org.apache.calcite.plan.hep.HepPlanner.lambda$executeProgram$0(HepPlanner.java:211)
at com.google.common.collect.ImmutableList.forEach(ImmutableList.java:405)
at org.apache.calcite.plan.hep.HepPlanner.executeProgram(HepPlanner.java:210)
at org.apache.calcite.plan.hep.HepProgram$State.execute(HepProgram.java:118)
at org.apache.calcite.plan.hep.HepPlanner.executeProgram(HepPlanner.java:205)
at org.apache.calcite.plan.hep.HepPlanner.findBestExp(HepPlanner.java:191)
at org.apache.calcite.test.RelOptFixture.checkPlanning(RelOptFixture.java:378)
at org.apache.calcite.test.RelOptFixture.check(RelOptFixture.java:330)
at org.apache.calcite.test.RelOptFixture.checkUnchanged(RelOptFixture.java:322)
at org.apache.calcite.test.RelOptRulesTest.testProjectAggregateMergeNonNumericLiteral(RelOptRulesTest.java:4810)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:77)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:568)
at org.junit.platform.commons.util.ReflectionUtils.invokeMethod(ReflectionUtils.java:725)
at org.junit.jupiter.engine.execution.MethodInvocation.proceed(MethodInvocation.java:60)
at org.junit.jupiter.engine.execution.InvocationInterceptorChain$ValidatingInvocation.proceed(InvocationInterceptorChain.java:131)
at org.junit.jupiter.engine.extension.TimeoutInvocation.proceed(TimeoutInvocation.java:46)
at org.junit.jupiter.engine.extension.TimeoutExtension.intercept(TimeoutExtension.java:149)
at org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestableMethod(TimeoutExtension.java:140)
at org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestMethod(TimeoutExtension.java:84)
at org.junit.jupiter.engine.execution.ExecutableInvoker$ReflectiveInterceptorCall.lambda$ofVoidMethod$0(ExecutableInvoker.java:115)
at org.junit.jupiter.engine.execution.ExecutableInvoker.lambda$invoke$0(ExecutableInvoker.java:105)
at org.junit.jupiter.engine.execution.InvocationInterceptorChain$InterceptedInvocation.proceed(InvocationInterceptorChain.java:106)
at org.junit.jupiter.engine.execution.InvocationInterceptorChain.proceed(InvocationInterceptorChain.java:64)
at org.junit.jupiter.engine.execution.InvocationInterceptorChain.chainAndInvoke(InvocationInterceptorChain.java:45)
at org.junit.jupiter.engine.execution.InvocationInterceptorChain.invoke(InvocationInterceptorChain.java:37)
at org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java:104)
at org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java:98)
at org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.lambda$invokeTestMethod$7(TestMethodTestDescriptor.java:214)
at org.junit.platform.engine.support.hierarchical.ThrowableCollector.execute(ThrowableCollector.java:73)
at org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.invokeTestMethod(TestMethodTestDescriptor.java:210)
at org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.execute(TestMethodTestDescriptor.java:135)
at org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.execute(TestMethodTestDescriptor.java:66)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.lambda$executeRecursively$6(NodeTestTask.java:151)
at org.junit.platform.engine.support.hierarchical.ThrowableCollector.execute(ThrowableCollector.java:73)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.lambda$executeRecursively$8(NodeTestTask.java:141)
at org.junit.platform.engine.support.hierarchical.Node.around(Node.java:137)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.lambda$executeRecursively$9(NodeTestTask.java:139)
at org.junit.platform.engine.support.hierarchical.ThrowableCollector.execute(ThrowableCollector.java:73)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.executeRecursively(NodeTestTask.java:138)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.execute(NodeTestTask.java:95)
at org.junit.platform.engine.support.hierarchical.ForkJoinPoolHierarchicalTestExecutorService$ExclusiveTask.compute(ForkJoinPoolHierarchicalTestExecutorService.java:185)
at org.junit.platform.engine.support.hierarchical.ForkJoinPoolHierarchicalTestExecutorService.invokeAll(ForkJoinPoolHierarchicalTestExecutorService.java:129)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.lambda$executeRecursively$6(NodeTestTask.java:155)
at org.junit.platform.engine.support.hierarchical.ThrowableCollector.execute(ThrowableCollector.java:73)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.lambda$executeRecursively$8(NodeTestTask.java:141)
at org.junit.platform.engine.support.hierarchical.Node.around(Node.java:137)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.lambda$executeRecursively$9(NodeTestTask.java:139)
at org.junit.platform.engine.support.hierarchical.ThrowableCollector.execute(ThrowableCollector.java:73)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.executeRecursively(NodeTestTask.java:138)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.execute(NodeTestTask.java:95)
at org.junit.platform.engine.support.hierarchical.ForkJoinPoolHierarchicalTestExecutorService$ExclusiveTask.compute(ForkJoinPoolHierarchicalTestExecutorService.java:185)
at org.junit.platform.engine.support.hierarchical.ForkJoinPoolHierarchicalTestExecutorService.invokeAll(ForkJoinPoolHierarchicalTestExecutorService.java:129)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.lambda$executeRecursively$6(NodeTestTask.java:155)
at org.junit.platform.engine.support.hierarchical.ThrowableCollector.execute(ThrowableCollector.java:73)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.lambda$executeRecursively$8(NodeTestTask.java:141)
at org.junit.platform.engine.support.hierarchical.Node.around(Node.java:137)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.lambda$executeRecursively$9(NodeTestTask.java:139)
at org.junit.platform.engine.support.hierarchical.ThrowableCollector.execute(ThrowableCollector.java:73)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.executeRecursively(NodeTestTask.java:138)
at org.junit.platform.engine.support.hierarchical.NodeTestTask.execute(NodeTestTask.java:95)
at org.junit.platform.engine.support.hierarchical.ForkJoinPoolHierarchicalTestExecutorService$ExclusiveTask.compute(ForkJoinPoolHierarchicalTestExecutorService.java:185)
at java.base/java.util.concurrent.RecursiveAction.exec(RecursiveAction.java:194)
at java.base/java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:373)
at java.base/java.util.concurrent.ForkJoinPool$WorkQueue.topLevelExec(ForkJoinPool.java:1182)
at java.base/java.util.concurrent.ForkJoinPool.scan(ForkJoinPool.java:1655)
at java.base/java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1622)
at java.base/java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:165)
This issue resolution is in progress as of the creation of this issue.
The Pull Requests will notify you of new versions for Calcite dependency. You'll need to check to see if the issue and PR are merged into that version. On release of the fix from Calcite, update the dependency version for Calcite.
E.g. if fixed version is 1.34.0
implementation group: 'org.apache.calcite', name: 'calcite-core', version: '1.34.0'
n/a
n/a
NULLVARCHARAggregation is always used even in queries where find() would have been sufficient.
In general, find() is often faster than using the aggregation framework and always makes use of indexes. The $match stage for aggregation can only use an index to filter documents if it occurs at the beginning of a pipeline which is not always the case.
There is already some work in place in the Calcite adapter to determine a filter and projection document for a possible find() operation but these values are not used. If the query does not require additional operations that are only supported in the aggregation framework then the query execution should be done using find().
Just curious -- I'm sure it's a decent chunk of work but I have a usecase for this, and if I'm capable of implementing it, I may give it a shot.
1.2.2N/AWindows 11 x64Java 17@Test
fun `create direct Calcite schema with DocumentDB adapter`() {
val mongoURI = "mongodb://root:Password123#@localhost:27017/sample?authSource=admin"
val documentDBURI = "jdbc:documentdb://root:Password123%23@localhost:27017/sample?tls=false"
val connectionProps =
DocumentDbConnectionProperties.getPropertiesFromConnectionString(documentDBURI)
val metadataSchema =
DocumentDbDatabaseSchemaMetadata.get(connectionProps, "sample", MongoClients.create(mongoURI))
val calciteSchema =
DocumentDbSchemaFactory.create(metadataSchema, connectionProps)
val calciteConn = DriverManager.getConnection("jdbc:calcite:").unwrap(CalciteConnection::class.java)
calciteConn.rootSchema.add("sample", calciteSchema)
val query = """
SELECT * FROM "sample"."album"
"""
val rs = calciteConn.createStatement().executeQuery(query)
while (rs.next()) {
val md = rs.metaData
for (i in 1..md.columnCount) {
println(md.getColumnName(i) + ": " + rs.getObject(i))
}
}
}The rows are printed out in the while() loop (which works when querying using the JDBC driver bundled in the project, sample below)
@Test
fun `test Amazon DocumentDB Calcite adapter with Mongo`() {
val conn = DriverManager.getConnection(testDatabaseConfigProvider.mongoDocumentDB)
val query = """
SELECT
artist.*,
album.*
FROM sample.artist
INNER JOIN sample.album AS album
ON album.artist_id = artist.artist__id
"""
val rs = conn.createStatement().executeQuery(query)
while (rs.next()) {
val md = rs.metaData
for (i in 1..md.columnCount) {
println(md.getColumnName(i) + ": " + rs.getObject(i))
}
println("---")
}
}2022-04-25 15:55:34,132 INFO [sof.ama.doc.jdb.met.DocumentDbMetadataService] (Test worker) Successfully retrieved metadata schema _default in 35 ms.
2022-04-25 15:55:34,223 INFO [sof.ama.doc.jdb.DocumentDbQueryExecutor] (Test worker) Query 1c85e3e0-042b-4faf-8856-9fe3b90158b6: Beginning translation of query.
2022-04-25 15:55:34,897 INFO [sof.ama.doc.jdb.cal.ada.DocumentDbProject] (Test worker) Created projection stages of pipeline.
2022-04-25 15:55:34,968 INFO [sof.ama.doc.jdb.DocumentDbQueryExecutor] (Test worker) Query 1c85e3e0-042b-4faf-8856-9fe3b90158b6: Took 745 ms to translate query.
2022-04-25 15:55:34,974 INFO [sof.ama.doc.jdb.DocumentDbQueryExecutor] (Test worker) Query 1c85e3e0-042b-4faf-8856-9fe3b90158b6: Took 6 ms to execute query and retrieve first batch of results.
artist__id: 1.0
name: AC/DC
album__id: 1.0
artist_id: 1.0
title: Back In Black
---
artist__id: 1.0
name: AC/DC
album__id: 2.0
artist_id: 1.0
title: High VoltageIt runs successfully but nothing is printed. It looks like something happens, I can see the metadata introspection and projection running in the logs:
2022-04-25 15:49:09,203 INFO [sof.ama.doc.jdb.met.DocumentDbMetadataService] (Test worker) Successfully retrieved metadata schema sample in 91 ms.
2022-04-25 15:49:09,928 INFO [sof.ama.doc.jdb.cal.ada.DocumentDbProject] (Test worker) Created projection stages of pipeline.Full logs below
2022-04-25 15:49:09,106 INFO [org.mon.dri.client] (Test worker) MongoClient with metadata {"driver": {"name": "mongo-java-driver|sync", "version": "4.6.0"}, "os": {"type": "Windows", "name": "Windows 10", "architecture": "amd64", "version": "10.0"}, "platform": "Java/Eclipse Adoptium/17.0.1+12"} created with settings MongoClientSettings{readPreference=primary, writeConcern=WriteConcern{w=null, wTimeout=null ms, journal=null}, retryWrites=true, retryReads=true, readConcern=ReadConcern{level=null}, credential=MongoCredential{mechanism=null, userName='root', source='admin', password=<hidden>, mechanismProperties=<hidden>}, streamFactoryFactory=null, commandListeners=[], codecRegistry=ProvidersCodecRegistry{codecProviders=[ValueCodecProvider{}, BsonValueCodecProvider{}, DBRefCodecProvider{}, DBObjectCodecProvider{}, DocumentCodecProvider{}, IterableCodecProvider{}, MapCodecProvider{}, GeoJsonCodecProvider{}, GridFSFileCodecProvider{}, Jsr310CodecProvider{}, JsonObjectCodecProvider{}, BsonCodecProvider{}, EnumCodecProvider{}, com.mongodb.Jep395RecordCodecProvider@538c90bf]}, clusterSettings={hosts=[localhost:27017], srvServiceName=mongodb, mode=SINGLE, requiredClusterType=UNKNOWN, requiredReplicaSetName='null', serverSelector='null', clusterListeners='[]', serverSelectionTimeout='30000 ms', localThreshold='30000 ms'}, socketSettings=SocketSettings{connectTimeoutMS=10000, readTimeoutMS=0, receiveBufferSize=0, sendBufferSize=0}, heartbeatSocketSettings=SocketSettings{connectTimeoutMS=10000, readTimeoutMS=10000, receiveBufferSize=0, sendBufferSize=0}, connectionPoolSettings=ConnectionPoolSettings{maxSize=100, minSize=0, maxWaitTimeMS=120000, maxConnectionLifeTimeMS=0, maxConnectionIdleTimeMS=0, maintenanceInitialDelayMS=0, maintenanceFrequencyMS=60000, connectionPoolListeners=[], maxConnecting=2}, serverSettings=ServerSettings{heartbeatFrequencyMS=10000, minHeartbeatFrequencyMS=500, serverListeners='[]', serverMonitorListeners='[]'}, sslSettings=SslSettings{enabled=false, invalidHostNameAllowed=false, context=null}, applicationName='null', compressorList=[], uuidRepresentation=UNSPECIFIED, serverApi=null, autoEncryptionSettings=null, contextProvider=null}
2022-04-25 15:49:09,124 INFO [org.mon.dri.connection] (cluster-rtt-ClusterId{value='6266fb35ab0b6c505e955715', description='null'}-localhost:27017) Opened connection [connectionId{localValue:2, serverValue:223}] to localhost:27017
2022-04-25 15:49:09,124 INFO [org.mon.dri.connection] (cluster-ClusterId{value='6266fb35ab0b6c505e955715', description='null'}-localhost:27017) Opened connection [connectionId{localValue:1, serverValue:222}] to localhost:27017
2022-04-25 15:49:09,125 INFO [org.mon.dri.cluster] (cluster-ClusterId{value='6266fb35ab0b6c505e955715', description='null'}-localhost:27017) Monitor thread successfully connected to server with description ServerDescription{address=localhost:27017, type=STANDALONE, state=CONNECTED, ok=true, minWireVersion=0, maxWireVersion=13, maxDocumentSize=16777216, logicalSessionTimeoutMinutes=30, roundTripTimeNanos=52593400}
2022-04-25 15:49:09,191 INFO [org.mon.dri.connection] (Test worker) Opened connection [connectionId{localValue:3, serverValue:224}] to localhost:27017
2022-04-25 15:49:09,203 INFO [sof.ama.doc.jdb.met.DocumentDbMetadataService] (Test worker) Successfully retrieved metadata schema sample in 91 ms.
2022-04-25 15:49:09,928 INFO [sof.ama.doc.jdb.cal.ada.DocumentDbProject] (Test worker) Created projection stages of pipeline. var metaData = connection.getMetaData();
String catalogPattern = null;
String schemaPattern = "database";
String tablePattern = "table\\_name";
ResultSet tables = metaData.getTables(catalogPattern, schemaPattern, tablePattern);
if (tables.size() < 1) {
// Unexpected result
}
| Pattern | Regex Equivalent |
|---|---|
\_ |
[_] |
\% |
[%] |
\\ |
[\\] |
_ |
. |
% |
.* |
Change convertPatternToRegex() to handle escaped special characters (_and%`).
Steps to reproduce:
within ec2 instance in VPC
With TACO and jdbc in tableau connect to Amazon documentDB
Expected behaviour:
Overview of tables in schema
Actual behaviour:
Table list is not displayed
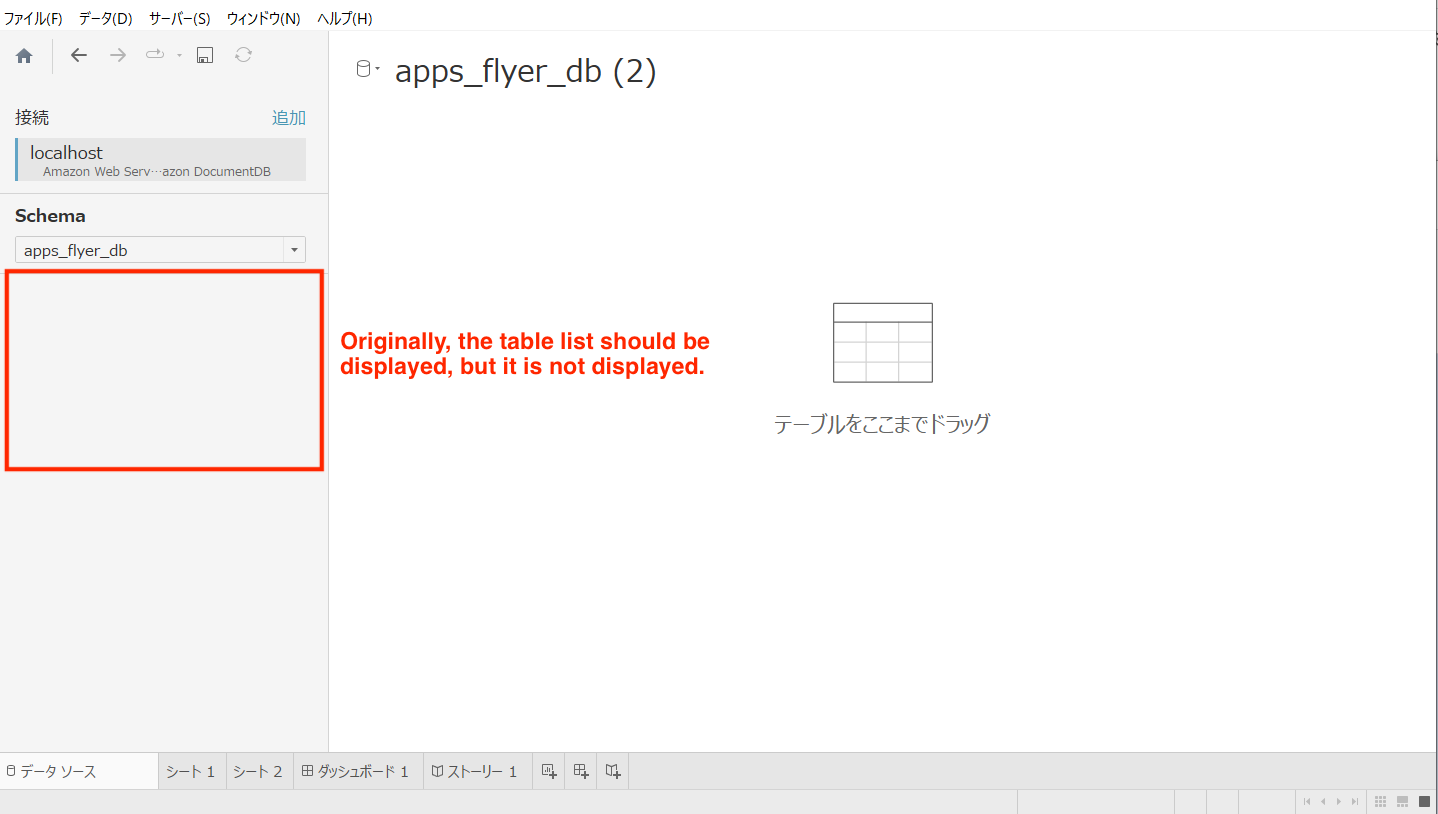
Error message/stack trace:
No error message
Any other details that can be helpful:
there is no problem with MAC PC.
plugin-version='1.14.0.0'plugin-version='1.13.0.0'N/A
N/A
The REVERSE_OPERATORS in DocumentDbRules are defined in a way that returns unexpected results.
Ex. For a column val [1, 2, 3] select val from int_table where 2 >= val should return [1, 2]
Currently, the driver reverses the operator >= to be '$lt' which is the same as select val from int_table where val < 2 which returns [1]
The correct reverse operator is '$lte' which should return [1, 2].
This should be a very quick fix, I made the change locally myself and it looks like this: Reverse Operator Change
you might want to switch to https://github.com/mwiede/jsch
It's maintained and features more secure algorithms.
replace dependency com.jcraft:jsch with com.github.mwiede:jsch
Steps to reproduce:
(within ec2 instance in VPC!!)
With TACO in tableau connect to documentDB
Expected behaviour:
Overview of tables in schema
Actual behaviour:
No overview at all.
Error message/stack trace:
An error occurred while communicating with the data source
Bad Connection: Tableau could not connect to the data source.
Error Code: 81B3934F
An error occurred while communicating with data source 'paydayService'
Any other details that can be helpful:
Used the jdbc driver with dbeaver, connection and creation of schema (and tables) was successful
Walking through the logs gives me no greater insight in what the issue is.
Same goes for tableau logs themselves (running in DEBUG mode)
Yes. Not being able to connect to mongoDB instance.
Currently it is not possible to authenticate in a mongo instance due DocumentDB JDBC driver not expose the auth database.
This is useful because tools like SchemaCrawler provide a uniform interface for getting schema information from JDBC datasources, but one of the requirements is a minimal implementation of getTypeInfo()
If this isn't too huge of a lift, maybe I can attempt a PR here if someone could give some hints on what the implementation should be?
@Test
fun `test SchemaCrawler`() {
val dataSource = DocumentDbDataSource().apply {
hostname = "localhost:27017"
database = "sample"
user = "root"
}
val options = SchemaCrawlerOptionsBuilder.newSchemaCrawlerOptions()
// Create a default TypeMap
val retrievalOptions = SchemaRetrievalOptionsBuilder.builder()
.withTypeMap(TypeMap())
.toOptions()
val catalog = SchemaCrawlerUtility.getCatalog(dataSource.connection, retrievalOptions,
options, schemacrawler.tools.options.Config())
println(catalog.tables)
}Caused by: java.sql.SQLFeatureNotSupportedException
at software.amazon.documentdb.jdbc.DocumentDbDatabaseMetaData.getTypeInfo(DocumentDbDatabaseMetaData.java:650)
at schemacrawler.crawl.DataTypeRetriever.retrieveSystemColumnDataTypesFromMetadata(DataTypeRetriever.java:179)
at schemacrawler.crawl.DataTypeRetriever.retrieveSystemColumnDataTypes(DataTypeRetriever.java:84)
at schemacrawler.crawl.RetrievalStopWatch.lambda$time$0(RetrievalStopWatch.java:105)
at us.fatehi.utility.StopWatch.time(StopWatch.java:142)
at schemacrawler.crawl.RetrievalStopWatch.time(RetrievalStopWatch.java:100)
at schemacrawler.crawl.RetrievalStopWatch.time(RetrievalStopWatch.java:72)
at schemacrawler.crawl.SchemaCrawler.crawlColumnDataTypes(SchemaCrawler.java:201)
at schemacrawler.crawl.SchemaCrawler.crawl(SchemaCrawler.java:143)I'd like to be able to save the detected schema locally. The schema information could then be restored later without needing another schema detection.
There are some collections that we work with that are very large and we may need to sample many or all of the documents. Minimizing the number of times that we do schema detection is important.
Hooks in the driver for:
None
At this point I'm most curious about the feasibility of this feature. Is it possible? How big of a change would this require?
C:\Program Files\Tableau\DriversC:\Users\[user]\Documents\My Tableau Repository\ConnectorsAn error occurred while communicating with Amazon DocumentDB by Amazon Web Services
There was a problem while running the connector plugin. Reinstall the plugin or contact the plugin provider.
Note that you might need to make local configuration changes to resolve the error.
Error Code:14D18B1F
Package signature verification failed during connection creation.
Connector Class: documentdbjdbc, Version: 1.14.0.0
An error occurred while communicating with Amazon DocumentDB by Amazon Web Services
There was a problem while running the connector plugin. Reinstall the plugin or contact the plugin provider.
Note that you might need to make local configuration changes to resolve the error.
Error Code:14D18B1F
Package signature verification failed during connection creation.
Connector Class: documentdbjdbc, Version: 1.14.0.0

Where to get it from?
A small refactoring improvement is possible when using loading the certificate:
#263
try (InputStream inputStream = getTlsCAFileInputStream()) {
if (inputStream != null) {
final X509Certificate certificate = (X509Certificate) CertificateFactory
.getInstance("X.509")
.generateCertificate(inputStream);
final SSLContext sslContext = SSLFactory.builder()
.withTrustMaterial(certificate)
.build()
.getSslContext();
builder.context(sslContext);
}
}
At the following place:
It is a small refactoring but this can be refactored to the following snippet:
try (InputStream inputStream = getTlsCAFileInputStream()) {
if (inputStream != null) {
final SSLContext sslContext = SSLFactory.builder()
.withTrustMaterial(CertificateUtils.loadCertificate(inputStream))
.build()
.getSslContext();
builder.context(sslContext);
}
}
None.
C:\Program Files\Tableau\DriversC:\Users\[user]\Documents\My Tableau Repository\ConnectorsAn error occurred while communicating with Amazon DocumentDB by Amazon Web Services
Bad Connection: Tableau could not connect to the data source.
Error Code: FAB9A2C5
Value expected to be of type DOCUMENT is of unexpected type NULL
Unable to connect to the Amazon DocumentDB by Amazon Web Services server "indivupad.cluster-REDACTED.us-east-1.docdb.amazonaws.com". Check that the server is running and that you have access privileges to the requested database.
Connector Class: documentdbjdbc, Version: 1.14.0.0
2022-02-14 12:12:53.680 +0100 (,,,,10,17) grpc-default-executor-7 : ERROR com.tableau.connect.util.GrpcServiceHelper - Failed in constructProtocol.
shadow.org.bson.BsonInvalidOperationException: Value expected to be of type DOCUMENT is of unexpected type NULL
at shadow.org.bson.BsonValue.throwIfInvalidType(BsonValue.java:419) ~[?:?]
at shadow.org.bson.BsonValue.asDocument(BsonValue.java:47) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processDocumentsInArray(DocumentDbTableSchemaGenerator.java:540) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processArray(DocumentDbTableSchemaGenerator.java:405) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processComplexTypes(DocumentDbTableSchemaGenerator.java:562) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processDocument(DocumentDbTableSchemaGenerator.java:188) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processDocumentsInArray(DocumentDbTableSchemaGenerator.java:540) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processArray(DocumentDbTableSchemaGenerator.java:405) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processComplexTypes(DocumentDbTableSchemaGenerator.java:562) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processDocument(DocumentDbTableSchemaGenerator.java:188) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processComplexTypes(DocumentDbTableSchemaGenerator.java:557) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processDocument(DocumentDbTableSchemaGenerator.java:188) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processComplexTypes(DocumentDbTableSchemaGenerator.java:557) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.processDocument(DocumentDbTableSchemaGenerator.java:188) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbTableSchemaGenerator.generate(DocumentDbTableSchemaGenerator.java:80) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbMetadataService.getCollectionMetadataDirect(DocumentDbMetadataService.java:404) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbMetadataService.getNewDatabaseMetadata(DocumentDbMetadataService.java:354) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbMetadataService.get(DocumentDbMetadataService.java:128) ~[?:?]
at software.amazon.documentdb.jdbc.metadata.DocumentDbDatabaseSchemaMetadata.get(DocumentDbDatabaseSchemaMetadata.java:114) ~[?:?]
at software.amazon.documentdb.jdbc.DocumentDbConnection.setMetadata(DocumentDbConnection.java:234) ~[?:?]
at software.amazon.documentdb.jdbc.DocumentDbConnection.ensureDatabaseMetadata(DocumentDbConnection.java:229) ~[?:?]
at software.amazon.documentdb.jdbc.DocumentDbConnection.getMetaData(DocumentDbConnection.java:208) ~[?:?]
at com.tableausoftware.jdbc.JDBCProtocolImpl.getDriverName(JDBCProtocolImpl.java:1037) ~[jdbcserver.jar:20214.0.17]
at com.tableau.connect.service.ProtocolService.constructProtocol(ProtocolService.java:61) ~[jdbcserver.jar:20214.0.17]
at com.tableau.connect.grpc.GrpcProtocolService.lambda$constructProtocol$0(GrpcProtocolService.java:63) ~[jdbcserver.jar:20214.0.17]
at com.tableau.connect.grpc.GrpcProtocolService.wrap(GrpcProtocolService.java:289) ~[jdbcserver.jar:20214.0.17]
at com.tableau.connect.grpc.GrpcProtocolService.constructProtocol(GrpcProtocolService.java:62) ~[jdbcserver.jar:20214.0.17]
at com.tableau.connect.generated.ProtocolServiceGrpc$MethodHandlers.invoke(ProtocolServiceGrpc.java:1492) ~[jdbcserver.jar:20214.0.17]
at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:180) ~[jdbcserver.jar:20214.0.17]
at io.grpc.PartialForwardingServerCallListener.onHalfClose(PartialForwardingServerCallListener.java:35) ~[jdbcserver.jar:20214.0.17]
at io.grpc.ForwardingServerCallListener.onHalfClose(ForwardingServerCallListener.java:23) ~[jdbcserver.jar:20214.0.17]
at io.grpc.ForwardingServerCallListener$SimpleForwardingServerCallListener.onHalfClose(ForwardingServerCallListener.java:40) ~[jdbcserver.jar:20214.0.17]
at io.grpc.Contexts$ContextualizedServerCallListener.onHalfClose(Contexts.java:86) ~[jdbcserver.jar:20214.0.17]
at io.grpc.internal.ServerCallImpl$ServerStreamListenerImpl.halfClosed(ServerCallImpl.java:331) ~[jdbcserver.jar:20214.0.17]
at io.grpc.internal.ServerImpl$JumpToApplicationThreadServerStreamListener$1HalfClosed.runInContext(ServerImpl.java:814) ~[jdbcserver.jar:20214.0.17]
at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37) ~[jdbcserver.jar:20214.0.17]
at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:123) ~[jdbcserver.jar:20214.0.17]
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) ~[?:?]
Steps to reproduce:
(within ec2 instance in VPC!!)
Download jdbc and taco.
Place files in designated folders.
Open up tableau.
Fill in wizard.
Try to connect.
Expected behaviour:
A successful connection with documentDB
Actual behaviour:
No successful connection with documentDB
Error message/stack trace:
Invalid username or password.
Error Code: 28911C50
Invalid username or password or user is not authorized on database 'paydayService'. Please check your settings. Authorization failed for user 'masterUser' on database 'admin' with mechanism 'SCRAM-SHA-1'. Please check username, password, database and authorization for the user.
Invalid username or password.
Connector Class: documentdbjdbc, Version: 1.14.0.0
Any other details that can be helpful:
Tried to connect by using studio 3T. Was successful.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.