![]()
This repository is inspired and built on the CARLA library. CARLA is a python library to benchmark counterfactual explanation and recourse models. It comes out-of-the box with commonly used datasets and various machine learning models. Designed with extensibility in mind: Easily include your own counterfactual methods, new machine learning models or other datasets. Find extensive documentation here! Our arXiv paper can be found here.
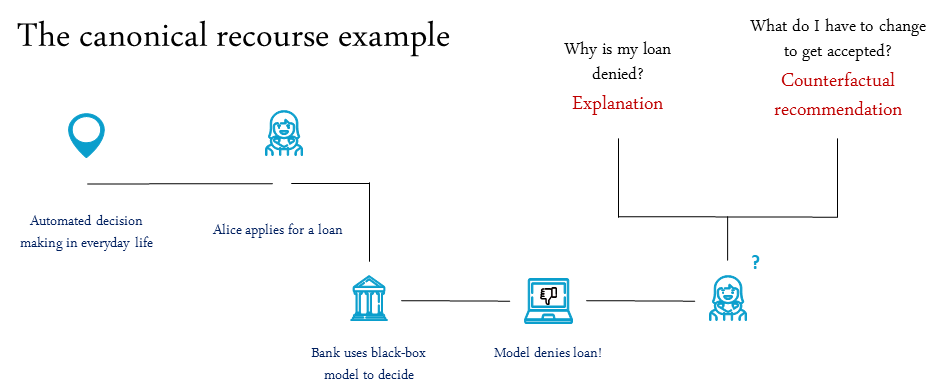
What is algorithmic recourse? As machine learning (ML) models are increasingly being deployed in high-stakes applications, there has been growing interest in providing recourse to individuals adversely impacted by model predictions (e.g., below we depict the canonical recourse example for an applicant whose loan has been denied). This library provides a starting point for researchers and practitioners alike, who wish to understand the inner workings of various counterfactual explanation and recourse methods and their underlying assumptions that went into the design of these methods.
- Getting Started (notebook): Source
- Causal Recourse (notebook): Source
- Plotting (notebook): Source
- Benchmarking (notebook): Source
- Adding your own Data: Source
- Adding your own ML-Model: Source
- Adding your own Recourse Method: Source 1 Source 2
| Name | Source |
|---|---|
| Adult | Source |
| COMPASS | Source |
| Give Me Some Credit (Credit) | Source |
| German Credit | Source |
| Mortgage | |
| TwoMoon |
| Model | Description | Tensorflow | Pytorch | Sklearn | XGBoost |
|---|---|---|---|---|---|
| MLP (ANN) | Multi-Layered Perceptron (Artificial Neural Network) with 2 hidden layers and ReLU activation function. | X | X | ||
| LR | Linear Model with no hidden layer and no activation function. | X | X | ||
| RandomForest | Tree Ensemble Model. | X | X |
The framework a counterfactual method currently works with is dependent on its underlying implementation. It is planned to make all recourse methods available for all ML frameworks . The latest state can be found here:
| Recourse Method | Paper | Tensorflow | Pytorch | SKlearn | XGBoost |
|---|---|---|---|---|---|
| CCHVAE | Source | X | |||
| Contrastive Explanations Method (CEM) | Source | X | |||
| Counterfactual Latent Uncertainty Explanations (CLUE) | Source | X | |||
| CRUDS | Source | X | |||
| Diverse Counterfactual Explanations (DiCE) | Source | X | X | ||
| Feasible and Actionable Counterfactual Explanations (FACE) | Source | X | X | ||
| FeatureTweak | Source | X | X | ||
| FOCUS | Source | X | X | ||
| Growing Spheres (GS) | Source | X | X | ||
| Mace | Source | X | |||
| Revise | Source | X | |||
| Wachter | Source | X |
python3.7pip
Using python directly or within activated virtual environment:
pip install -U pip setuptools wheel
pip install -r requirements-dev.txt
pip install -e .from data.catalog import DataCatalog
from evaluation import Benchmark
import evaluation.catalog as evaluation_catalog
from models.catalog import ModelCatalog
from random import seed
from recourse_methods import GrowingSpheres
RANDOM_SEED = 54321
seed(RANDOM_SEED) # set the random seed so that the random permutations can be reproduced again
# load a catalog dataset
data_name = "adult"
dataset = DataCatalog(data_name)
# load artificial neural network from catalog
model = ModelCatalog(dataset, "mlp", "tensorflow")
# get factuals from the data to generate counterfactual examples
factuals = (dataset.raw).sample(n=10, random_state=RANDOM_SEED)
# load a recourse model and pass black box model
gs = GrowingSpheres(model)
# generate counterfactual examples
counterfactuals = gs.get_counterfactuals(factuals)
# Generate Benchmark for recourse method, model and data
benchmark = Benchmark(model, gs, factuals)
evaluation_measures = [
evaluation_catalog.YNN(benchmark.mlmodel, {"y": 5, "cf_label": 1}),
evaluation_catalog.Distance(benchmark.mlmodel),
evaluation_catalog.SuccessRate(),
evaluation_catalog.Redundancy(benchmark.mlmodel, {"cf_label": 1}),
evaluation_catalog.ConstraintViolation(benchmark.mlmodel),
evaluation_catalog.AvgTime({"time": benchmark.timer}),
]
df_benchmark = benchmark.run_benchmark(evaluation_measures)This interface displays the results from running the CARLA library with a range of datasets, models and recourse methods.
cd .\live_site
pip install -r .\requirements.txt
python .\server.pyRead more from here to learn about the amendment of the live site tool.
Before running the command below, clear out all former computations from the results.csv file. Ensure to maintain the header (first line) of the csv file, and only delete the computation result.
python .\run_experiment.pyblack .\Contributions of any kind are very much welcome! Take a look at the To-Do issues section to see what things we are currently working on. If you have an idea for a new feature or a bug you want to fix, please follow look at the subsections below.
- Branch off of
mainfor all feature work and bug fixes, and create a "feature branch". Prefix the feature branch name with your name. The branch name should be in snake case and it should be short and descriptive. E.g.abu/readme_update
-
Commits should be atomic (guideline: the commit is self-contained; a reviewer could make sense of it even if they viewed the commit diff in isolation)
-
Commit messages and PR names are descriptive and written in imperative tense. With commit messages, they should include if they are a feature or a fix. E.g. "feat: create user REST endpoints", or "fix: remove typo in readme". From the example in the previous sentence, pay attention to the imperative tense used.
-
PRs can contain multiple commits, they do not need to be squashed together before merging as long as each commit is atomic.
- Expand the existing repository of available recourse methods to include new recourse methods.
- Minimum Observables - https://arxiv.org/abs/1907.04135
- ClaPROAR - https://arxiv.org/abs/2308.08187
- Gravitational Generator - https://arxiv.org/abs/2308.08187
- Greedy - https://arxiv.org/abs/2103.08951
- PROBE - https://arxiv.org/abs/2203.06768
- Extend the existing frontend design to incorporate new interactive features.
- Revamp the entire library to a newer python version.
- Refactor existing methods to utilize a singular backend type.
- Improve documentation in the repo ReadMe file.
- Include flowcharts to display the connection between the files in the repo.
- Include explanations for each folder in the repo.



