cvxgrp / pymde Goto Github PK
View Code? Open in Web Editor NEWMinimum-distortion embedding with PyTorch
Home Page: https://pymde.org
License: Apache License 2.0
Minimum-distortion embedding with PyTorch
Home Page: https://pymde.org
License: Apache License 2.0
I install the pymde in PyCharm,for the beginning example with MNIST.
I use pymde.plot(embedding, color_by=mnist.attributes['digits']),but I can't see the visualization result.
I don't kown where I am wrong,can you help me?
Here is my code:
import pymde
import torchvision
mnist = pymde.datasets.MNIST()
embedding = pymde.preserve_neighbors(mnist.data, verbose=True).embed(verbose=True)
print('embedding shape === ',embedding.shape)
pymde.plot(embedding, color_by=mnist.attributes['digits'])Hi,
Many thanks for making available this nice package!
I have a windows machine with Python 3.6.5 and install pymde-0.1.11, torch-1.9.0, torchvision-0.10.0
To produce a 3D embedding, I used this commands:
embedding= pymde.preserve_neighbors(input_data, embedding_dim= intrinsic_dim, attractive_penalty=
pymde.penalties.Log1p, repulsive_penalty= pymde.penalties.Log,
constraint= pymde.Standardized(), n_neighbors= 5, repulsive_fraction=
0.5, init= 'random', device= 'cpu')
projected_data= embedding.embed(max_iter= 350, memory_size= 20)
which produced the warning message shown below. Will this warning affect the quality of the projection?
C:\Temp\Python\Python3.6.5\lib\site-packages\pymde\constraints.py:182: UserWarning: torch.symeig is deprecated in favor of torch.linalg.eigh and will be removed in a future PyTorch release.
The default behavior has changed from using the upper triangular portion of the matrix by default to using the lower triangular portion.
L, _ = torch.symeig(A, upper=upper)
should be replaced with
L = torch.linalg.eigvalsh(A, UPLO='U' if upper else 'L')
and
L, V = torch.symeig(A, eigenvectors=True)
should be replaced with
L, V = torch.linalg.eigh(A, UPLO='U' if upper else 'L') (Triggered internally at ..\aten\src\ATen\native\BatchLinearAlgebra.cpp:2500.)
lmbda, Q = torch.symeig(X.T @ X, eigenvectors=True)
C:\Temp\Python\Python3.6.5\lib\site-packages\torch_tensor.py:575: UserWarning: floor_divide is deprecated, and will be removed in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values.
To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor'). (Triggered internally at ..\aten\src\ATen\native\BinaryOps.cpp:467.)
return torch.floor_divide(self, other)
Thanks,
Ivan
Hello,
Running pymde.preserve_neighbors does not always produce the same set of edges as stored in mde.edges.
Here is a MWE:
import pymde
import torch
n_examples=15 # Note results become reproducible with n_examples=14
embedding_dim = 2
original_dim = 128
X = torch.rand((n_examples,original_dim))
collect = []
for i in range(5):
mde = pymde.preserve_neighbors(X,embedding_dim=embedding_dim)
collect.append(mde.edges)
if i > 0:
print(f"Trial {i} matches trial {i-1}")
print((torch.sort(collect[i],0).values == torch.sort(collect[i-1],0).values).all())
print()This prints:
Trial 1 matches trial 0
tensor(False)
Trial 2 matches trial 1
tensor(False)
Trial 3 matches trial 2
tensor(False)
Trial 4 matches trial 3
tensor(False)Note per the comment above, if I switch to n_examples = 14, I get that all elements of collect are identical.
I haven't been able to fully trace the issue, but did note that the neighbors variable defined here is consistent on each trial, so my best guess is there is something strange happening in the Graph class here.
I noticed a typo in the example in the MDE>Distortion functions>Losses section of the documentation (https://pymde.org/mde/index.html#losses) . The second line of the example reads f = pymde.losses.Quadratic(weights), when it should read f = pymde.losses.Quadratic(deviations).
I'm happy to fix this by forking the repo and submitting a pull request. Is that ok? Should I go ahead and do the same if I notice any other small errors?
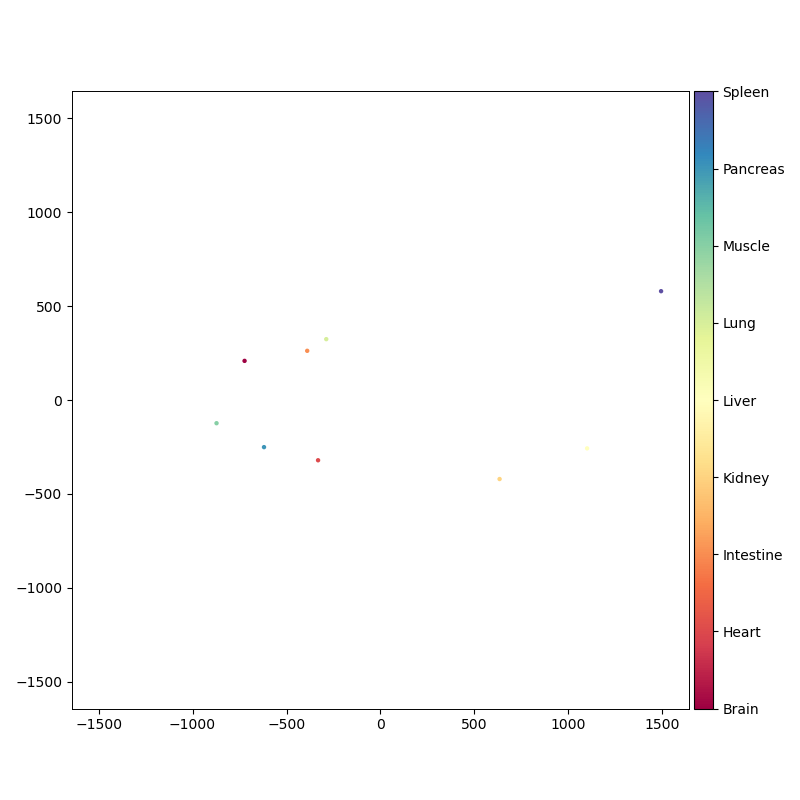
First off, cool package! I've noticed that when I supply categorical arrays to "color_by" I still end up with a continuous color bar in my figure. I'm using pymde version 0.1.2 with python 3.9.7, pandas 1.3.4, and numpy 1.20.3. Hardware is an M1 MacBook Pro. I've checked that I'm actually using variables which are categorical, but otherwise haven't been able to figure out why I always get a smooth color bar. From perusing the code it looks like if the object I use for "color_by" is discrete, I should automatically get a discrete colorbar, right? All of my data are stored as a pandas dataframe, which I have been coercing into numpy objects.
Code snippet:
print(plotframe.head())
embedding = pymde.preserve_distances(plotframe.T.to_numpy(), embedding_dim=2, verbose=True).embed()
test = np.array(plotframe.columns)
print(np.issubdtype(test.dtype, np.object_))
pymde.plot(embedding, color_by=test, marker_size=10)
plt.tight_layout()
plt.savefig("MDE_test")
plt.close('all')
Output:
Liver Brain Pancreas ... Spleen Kidney Muscle
0 10.809978 6.798201 5.420175 ... 11.332651 13.995842 2.141489
1 14.133262 8.006512 0.000000 ... 10.533630 11.486465 0.000000
2 11.177152 3.051282 5.471645 ... 12.835654 8.657145 2.040094
3 12.226920 3.475457 0.000000 ... 9.413930 8.958743 1.973367
4 9.611370 0.000000 0.000000 ... 6.384823 4.735076 0.000000
[5 rows x 9 columns]
Feb 21 10:54:16 AM: Computing 36 distances
True
I am trying to explore the code and getting some incompatibility with python version 3.9 and/or my version of numpy 1.19.3
The trace:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-2-fab5524ebb5d> in <module>
----> 1 import pymde
/usr/local/lib/python3.9/site-packages/pymde/__init__.py in <module>
5 from pymde.constraints import Centered, Anchored, Standardized
6
----> 7 from pymde import datasets
8
9 from pymde.preprocess.graph import Graph
/usr/local/lib/python3.9/site-packages/pymde/datasets.py in <module>
16
17 import numpy as np
---> 18 from pymde.preprocess.graph import Graph
19 from pymde.problem import LOGGER
20 import scipy.sparse as sp
/usr/local/lib/python3.9/site-packages/pymde/preprocess/__init__.py in <module>
3 from pymde.preprocess.preprocess import scale
4
----> 5 from pymde.preprocess.generic import distances, k_nearest_neighbors
6
7 from . import graph
/usr/local/lib/python3.9/site-packages/pymde/preprocess/generic.py in <module>
3 import torch
4
----> 5 from pymde.preprocess import data_matrix
6 from pymde.preprocess import graph
7
/usr/local/lib/python3.9/site-packages/pymde/preprocess/data_matrix.py in <module>
4
5 from pymde import problem
----> 6 from pymde.preprocess.graph import Graph
7 from pymde.preprocess.preprocess import sample_edges
8 from pymde import util
/usr/local/lib/python3.9/site-packages/pymde/preprocess/graph.py in <module>
9 from pymde import problem
10 from pymde.functions import penalties, losses
---> 11 from pymde.preprocess import _graph
12
13
pymde/preprocess/_graph.pyx in init pymde.preprocess._graph()
ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject
Hello, is it possible to use preserve_neighbors with pre-computed k-nearest neighbors data in the distance-matrix-like form used by the likes of UMAP and t-SNE? In this format, the indices and distances are stored as separate matrices of shape n_objects, n_neighbors. The element (i, j) in the index matrix is the index of the jth nearest neighbor of i, and the equivalent element in the distance matrix is the distance between those two objects.
I (think) I can work out how to manually convert that into the edges/weights form used by pymde.Graph (various acts of melting and raveling), but I don't get the results I expect compared to passing the data directly. I think that's because when preprocess.generic.k_nearest_neighbors is called, for the graph code path, graph.k_nearest_neighbors has graph_distances=True. So another way to put it is: is there a way to pass a Graph so that it is interpreted as a distance matrix? This would be helpful because calculating the k-nearest neighbors is usually the slowest part of this sort of dimensionality reduction method.
SolverError: Function evaluation returned NaN.
mde2 = pymde.preserve_neighbors(
scrna_wilk.data,
embedding_dim=3,
constraint=pymde.Standardized(),
repulsive_fraction=1.0,
verbose=True,
)
embedding2 = mde2.embed(verbose=True)
This code produces the following output:-
SolverError Traceback (most recent call last)
in
6 verbose=True,
7 )
----> 8 embedding2 = mde2.embed(verbose=True)
~/.local/lib/python3.8/site-packages/pymde/problem.py in embed(self, X, eps, max_iter, memory_size, verbose, print_every, snapshot_every)
494 )
495 else:
--> 496 X_star, solve_stats = optim.lbfgs(
497 X=X,
498 constraint=self.constraint,
~/.local/lib/python3.8/site-packages/pymde/optim.py in lbfgs(X, objective_fn, constraint, eps, max_iter, memory_size, use_line_search, use_cached_loss, verbose, print_every, snapshot_every, logger)
129 norm_X = X.norm(p="fro")
130 X.requires_grad_(True)
--> 131 opt.step(value_and_grad)
132 X.requires_grad_(False)
133
/apps/easybuild/1.0/software/PyTorch/1.6.0/lib/python3.8/site-packages/torch/autograd/grad_mode.py in decorate_context(*args, **kwargs)
13 def decorate_context(*args, **kwargs):
14 with self:
---> 15 return func(*args, **kwargs)
16 return decorate_context
17
~/.local/lib/python3.8/site-packages/pymde/lbfgs.py in step(self, closure)
514 closure, x, t, d, self._project_callback)
515
--> 516 loss, flat_grad, t, ls_func_evals = _strong_wolfe(
517 obj_func, x_init, t, d, loss, flat_grad, gtd)
518 self._cached_loss = torch.tensor(loss, device=flat_grad.device)
~/.local/lib/python3.8/site-packages/pymde/lbfgs.py in _strong_wolfe(obj_func, x, t, d, f, g, gtd, c1, c2, tolerance_change, max_ls)
71 torch.isnan(g_new).any() or
72 torch.isinf(g_new).any()):
---> 73 raise SolverError("Function evaluation returned NaN.")
74 ls_func_evals = 1
75 gtd_new = g_new.dot(d)
SolverError: Function evaluation returned NaN.
For extremely big problems (problems too large to fit in RAM/GPU memory), the stochastic solve method from chapter 6 of the monograph is useful. This has already been implemented.
This is a tracking issue, for exposing the stochastic solve method to the public API.
Hey all,
I'm having trouble running preserve_distances on mnist because pymde tries to allocate 1000Gb of RAM. Is that to be expected? Thanks
Mar 22 10:57:27 PM: Sampling 50000000 edges
Mar 22 10:57:32 PM: Computing 50000000 distances
RuntimeError: [enforce fail at CPUAllocator.cpp:67] . DefaultCPUAllocator: can't allocate memory: you tried to allocate 156800000000 bytes. Error code 12 (Cannot allocate memory)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-17-f2ac8e7c8297> in <module>
----> 1 z = pymde.preserve_distances(X_train, verbose=True).embed()
~/anaconda3/envs/tfumap/lib/python3.7/site-packages/pymde/recipes.py in preserve_distances(data, embedding_dim, loss, constraint, max_distances, device, verbose)
106
107 graph = preprocess.generic.distances(
--> 108 data, retain_fraction=retain_fraction, verbose=verbose
109 )
110 edges = graph.edges.to(device)
~/anaconda3/envs/tfumap/lib/python3.7/site-packages/pymde/preprocess/generic.py in distances(data, retain_fraction, verbose)
50 if _is_data_matrix(data):
51 return data_matrix.distances(
---> 52 data, retain_fraction=retain_fraction, verbose=verbose
53 )
54 else:
~/anaconda3/envs/tfumap/lib/python3.7/site-packages/pymde/preprocess/data_matrix.py in distances(data, retain_fraction, verbose)
79 # and/or the number of features is large.
80 delta = (
---> 81 (data[edges[:, 0]] - data[edges[:, 1]])
82 .pow(2)
83 .sum(dim=1)
RuntimeError: [enforce fail at CPUAllocator.cpp:67] . DefaultCPUAllocator: can't allocate memory: you tried to allocate 156800000000 bytes. Error code 12 (Cannot allocate memory)
Hi, really interesting package with some great features. It'd be really handy if it were able to use objects constructed using igraph
Hi @akshayka ! Thank you for your beautiful work and this wonderful library.
I wonder if it is possible to use pyMDE with distances or affinities matrices as input. I'm working on a topological data analysis library and would very much like to include some pyMDE wrappers for graph layout and visualization.
For example, would it be possible to start the pymde with only pairwise distances and/or k-nearest-neighbor distances or affinities? How much change on the current code would be needed to do so? Do you think it would be better to try to implement this on a separate library with calls to pyMDE internals?
Thanks! :)
for example if I have a dataframe shape of (50,1000), 50 samples with time series length of 1000 each
The Datasets functionality is partially dependent on the requests package through torchvision.datasets. However, torchvision doesn't consider that to be essential functionality, so requests is not an explicit dependency. This leads users who create a minimal environment, e.g.
conda create -n foo -c conda-forge pymdeto encounter a ModuleNotFound error when trying an example like
import pymde
mnist = pymde.datasets.MNIST()Not a huge deal, but if following suit with torchvision and not including requests as an explicit dependency, it might be nice to give users a heads up in the documentation.
My code is following:
pymde.seed(0)
mde = pymde.preserve_neighbors(
matrix[: 1001], # matrix[: 1000]
embedding_dim=2,
init='random',
device='cpu',
constraint=pymde.Centered(),
verbose=self.verbose
)
embeddings = mde.embed(verbose=self.verbose)
embeddings = embeddings.cpu().numpy()When I use the first 1,000 samples from the input matrix I get a very different results then using one sample more (1,001).
Here is the log:
Feb 21 07:21:55 PM: Computing 5-nearest neighbors, with max_distance=None
Feb 21 07:21:55 PM: Exact nearest neighbors by brute force
Feb 21 07:21:55 PM: Your dataset appears to contain duplicated items (rows); when embedding, you should typically have unique items.
Feb 21 07:21:55 PM: The following items have duplicates [261 262 264 385 394 490 521 542 547 592 715]
Feb 21 07:21:55 PM: Fitting a centered embedding into R^2, for a graph with 1001 items and 9562 edges.
Feb 21 07:21:55 PM: `embed` method parameters: eps=1.0e-05, max_iter=300, memory_size=10
Feb 21 07:21:55 PM: iteration 000 | distortion 0.773313 | residual norm 0.0166138 | step length 30.3 | percent change 1.09275
Feb 21 07:21:55 PM: iteration 030 | distortion 0.372009 | residual norm 0.00494183 | step length 1 | percent change 5.72445
Feb 21 07:21:55 PM: iteration 060 | distortion 0.305200 | residual norm 0.00271112 | step length 1 | percent change 3.55324
Feb 21 07:21:56 PM: iteration 090 | distortion 0.284056 | residual norm 0.00196794 | step length 1 | percent change 2.22588
Feb 21 07:21:56 PM: iteration 120 | distortion 0.277153 | residual norm 0.000870837 | step length 1 | percent change 0.436913
Feb 21 07:21:56 PM: iteration 150 | distortion 0.275639 | residual norm 0.00086974 | step length 1 | percent change 1.04672
Feb 21 07:21:56 PM: iteration 180 | distortion 0.272377 | residual norm 0.00140454 | step length 1 | percent change 1.2704
Feb 21 07:21:56 PM: iteration 210 | distortion 0.269552 | residual norm 0.000706442 | step length 1 | percent change 0.560233
Feb 21 07:21:56 PM: iteration 240 | distortion 0.267543 | residual norm 0.00103134 | step length 1 | percent change 0.558733
Feb 21 07:21:56 PM: iteration 270 | distortion 0.265752 | residual norm 0.000605354 | step length 1 | percent change 0.259163
Feb 21 07:21:56 PM: iteration 299 | distortion 0.265053 | residual norm 0.000348569 | step length 1 | percent change 0.0578442
Feb 21 07:21:56 PM: Finished fitting in 0.660 seconds and 300 iterations.
Feb 21 07:21:56 PM: average distortion 0.265 | residual norm 3.5e-04
And here the output embeddings:


Is this an expected behaviour? I thought adding one sample should not makes as much difference.
Thank you for helping me out!
Thank you for an excellent package!
I am working with very large single cell datasets, attempting to embed various latent spaces generated from these data using pymde. Data sizes are commonly (30M, 30) or larger (currently up to 60M,30 and growing). I've been using a single-cell recipe from scVI, which is:
mde = pymde.preserve_neighbors(
data,
embedding_dim=2,
constraint=pymde.Standardized(),
repulsive_fraction=0.7,
verbose=verbose,
device=device,
n_neighbors=15,
)
The preserve_neighbors API runs out of memory using default parameters (for both CPU and Cuda devices). As noted in the docs, using init="random" improves this somewhat, but it still OOMs with approx 10% of our full dataset on a GPU with 24GiB of RAM.
I was wondering if you could provide further advice on approaches to embedding extremely large matrices.
Thank you.
The quadratic initialization takes the most time for a dataset with 150k observations and 15 nearest neighbors. Is it possible to use the GPU for this?
PyTorch has support for both CUDA-backed COO matrices and lobpcg. See sparse supported linear algebra operations.
Using following example on my dataset:
embedding = pymde.preserve_neighbors(tensor_df_x, embedding_dim=2, verbose=True).embed()
pymde.plot(embedding, color_by=df_train['intent'])
Getting following error:
ValueError: ('Adjacency matrices must not contain self edges; the following nodes were found to have self edges: ', array([ 34, 44, 110, 120, 153, 171, 181]))
The dataset is https://drive.google.com/file/d/1bHi3hmfFRUE_wwqoTyHuUhd7LrdC4Pag/view?usp=sharing
index -1 is out of bounds for axis 0 with size 0 (This error causes the graph that I want to display to not appear)
Heya! I think the command on the Installation page is currently
conda install -c pytorch conda-forge pymde
but the channel should be immediately after the -c flag (and should prioritize the PyTorch channel)
conda install -c pytorch -c conda-forge pymde
Otherwise it fails with the following message:
guille@guille-mbp ~> conda install -c pytorch conda-forge pymde (pymde)
Collecting package metadata (current_repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Collecting package metadata (repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
PackagesNotFoundError: The following packages are not available from current channels:
- pymde
- conda-forge
Current channels:
- https://conda.anaconda.org/pytorch/osx-64
- https://conda.anaconda.org/pytorch/noarch
- https://repo.anaconda.com/pkgs/main/osx-64
- https://repo.anaconda.com/pkgs/main/noarch
- https://repo.anaconda.com/pkgs/r/osx-64
- https://repo.anaconda.com/pkgs/r/noarch
To search for alternate channels that may provide the conda package you're
looking for, navigate to
https://anaconda.org
and use the search bar at the top of the page.
Thanks!
Hallo, have recently looked into this cool library, and wanted to do some embedding.
But have trouble running the updating embeddings notebook.
https://github.com/cvxgrp/pymde/blob/main/examples/updating_an_existing_embedding.ipynb
When I do this step:
incremental_mde = pymde.preserve_neighbors(
mnist.data,
constraint=anchor_constraint,
init='random',
verbose=False)
I get the this error:

Am running on a clean environment.
Reproduced the error in this 10 lines colab file: https://colab.research.google.com/drive/1Fq4u8Z85Xmpz1Z3YKem7jA2ONfGouAiA?usp=sharing
Hope you can help.
Kind regards
Chapter 7 of the monograph has some synthetic numerical examples, for the optimization subroutine. We should add Github notebooks to reproduce them.
This is a super cool package! It would be great to see it directly used in Scanpy
I made an issue there describing a bit about the feature request. It seems pretty straightforward to implement given that you have recipe functions already. I'm not sure how much work it would be to directly use the neighbors graph created by scanpy.pp.neighbors (also uses Pynndescent)
Running in Jupyter notebook. Importing TSNE (from sklearn.manifold import TSNE) prior to pyMDE (import pymde) is causing the kernel to die when I try to use pyMDE (for example (mnist = pymde.datasets.MNIST())
The same is true in reverse, i.e. TSNE also kills kernel if the pyMDE is imported before TSNE
from sklearn.manifold import TSNE
import pymde
mnist = pymde.datasets.MNIST()
embedding = pymde.preserve_neighbors(mnist.data).embed()Library versions:
pymde - 0.1.15
scikit-learn - 1.1.1
The package has a license but lacks a license file. Could this please be added?
Without a license file, this precludes making a Conda Forge build of the package (which I am interested in helping with).
Hi, I am trying to install pymde on a MacBook Air with an M1 chip. I have tried both in a virtual environment and globally.
System Version: macOS 12.0.1
Kernel Version: Darwin 21.1.0
/usr/bin/python3 --version
Python 3.8.2
However, I am always facing the same issue.
ERROR: Command errored out with exit status 1:
command: /Library/Developer/CommandLineTools/usr/bin/python3 -u -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'/private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-install-h05etips/llvmlite_698138ee5d98423b8959abdddb1d07cd/setup.py'"'"'; __file__='"'"'/private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-install-h05etips/llvmlite_698138ee5d98423b8959abdddb1d07cd/setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-record-veev5qpz/install-record.txt --single-version-externally-managed --user --prefix= --compile --install-headers /Users/eleonoravercesi/Library/Python/3.8/include/python3.8/llvmlite
cwd: /private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-install-h05etips/llvmlite_698138ee5d98423b8959abdddb1d07cd/
Complete output (14 lines):
running install
running build
got version from file /private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-install-h05etips/llvmlite_698138ee5d98423b8959abdddb1d07cd/llvmlite/_version.py {'version': '0.37.0', 'full': 'd77dc1bcdb5af040c549f4d1ceeb4db7c8d08718'}
running build_ext
/Library/Developer/CommandLineTools/usr/bin/python3 /private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-install-h05etips/llvmlite_698138ee5d98423b8959abdddb1d07cd/ffi/build.py
LLVM version... Traceback (most recent call last):
File "/private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-install-h05etips/llvmlite_698138ee5d98423b8959abdddb1d07cd/ffi/build.py", line 220, in <module>
main()
File "/private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-install-h05etips/llvmlite_698138ee5d98423b8959abdddb1d07cd/ffi/build.py", line 214, in main
main_posix('osx', '.dylib')
File "/private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-install-h05etips/llvmlite_698138ee5d98423b8959abdddb1d07cd/ffi/build.py", line 134, in main_posix
raise RuntimeError(msg) from None
RuntimeError: Could not find a `llvm-config` binary. There are a number of reasons this could occur, please see: https://llvmlite.readthedocs.io/en/latest/admin-guide/install.html#using-pip for help.
error: command '/Library/Developer/CommandLineTools/usr/bin/python3' failed with exit status 1
----------------------------------------
ERROR: Command errored out with exit status 1: /Library/Developer/CommandLineTools/usr/bin/python3 -u -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'/private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-install-h05etips/llvmlite_698138ee5d98423b8959abdddb1d07cd/setup.py'"'"'; __file__='"'"'/private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-install-h05etips/llvmlite_698138ee5d98423b8959abdddb1d07cd/setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /private/var/folders/y_/5kkrlhbj2v1bch8snxxws28c0000gn/T/pip-record-veev5qpz/install-record.txt --single-version-externally-managed --user --prefix= --compile --install-headers /Users/eleonoravercesi/Library/Python/3.8/include/python3.8/llvmlite Check the logs for full command output.
Thank you!
Thanks so much for this awesome tool! I feel like I might be missing something obvious, but I can't find a way in the API to set a random seed, such that the projections are reproducible for sharing or publication. If this is possible, could you please point me to it?
Implement a method for incrementally embedding, i.e., for adding new points to an existing embedding, as described in chapter 2, section 4.2 of the monograph.
All the necessary pieces are already implemented; they just need to be assembled together.
Hi - thanks for developing pyMDE!
I am trying to create an embedding like tSNE or UMAP, but with additional bias on the embedded space. For example, I have single-cell RNA-seq data and would like to embed according to cell-cell similarity as usual. In addition, each cell (sample) has an attribute, for example "age", and I would like to bias the embedding to place larger values of the attribute further from the center.
Is there a mechanism to create a distortion function that operates on the absolute positions in the target space? I understand that constraints allow you to pin datapoints to specific absolute positions, but I want a more flexible bias rather than pinning points precisely. Any help appreciated!
The quality of an embedding in PyMDE is judged by the collection of of Euclidean distances between pairs of embedding distances.
Euclidean distance is natural for visualization, since it is the distance that humans use in the real world. It is also closely related to the standardization constraint (which puts an upper bound on the sum of squared Euclidean distances between embedding vectors).
There is nothing in the underlying optimization algorithm or code that requires the distances to be Euclidean, and the code could easily be extended to support other distances.
If this is something that you actively want, please react with a 👍 on this post.
Is there a reason why the library doesn't offer a scikit-learn compatbile API? A class that can work via the fit_transform() API?
Hi, I've seen this work by Intel: https://github.com/intel/scikit-learn-intelex and curious if anyone has looked into how it may compare / if it can be used as a speed up for nndescent? There is an example notebook here showing the speedup on a toy example: https://www.kaggle.com/kppetrov/fast-knn-using-scikit-learn-intelex-for-mnist - i believe there are also additional hooks for GPU methods: https://intel.github.io/scikit-learn-intelex/gpu.html
Hi, thank you for an incredible package! I am interested in visualizing decision boundaries of my high dimensional data as viewed in a lower dimension. In order to do this, I plan to take my high dim data and embed to 2D, and then find an invertible transform that goes from the extents of my 2D data back to the high dimensional data s.t. I can apply my function for discovering the likelihood on the equivalent high dim data.
Is it possible to invert the MDE transform in order to achieve this? For instance, I would have some 2D data that has been embedded w/ MDE and I'd like to map a grid to the extents of this 2D data, then find the equivalent high-dim representation of the grid points w/ the invertible MDE transform?
Any help appreciated! Thanks so much!
I would like to use the Standardized() constraint, but every time I get a following error:
~/Documents/school/repsys/repsys/evaluators.py in _compute_embeddings(self, matrix, max_samples, **kwargs)
39 pymde.seed(self.seed)
40 mde = pymde.preserve_neighbors(matrix, init='random', constraint=pymde.Standardized(), verbose=self.verbose, **kwargs)
---> 41 embeddings = mde.embed(verbose=self.verbose, max_iter=400)
42 embeddings = embeddings.cpu().numpy()
43
~/opt/miniconda3/envs/repsys/lib/python3.7/site-packages/pymde/problem.py in embed(self, X, eps, max_iter, memory_size, verbose, print_every, snapshot_every)
506 print_every=print_every,
507 snapshot_every=snapshot_every,
--> 508 logger=LOGGER,
509 )
510
~/opt/miniconda3/envs/repsys/lib/python3.7/site-packages/pymde/optim.py in lbfgs(X, objective_fn, constraint, eps, max_iter, memory_size, use_line_search, use_cached_loss, verbose, print_every, snapshot_every, logger)
129 norm_X = X.norm(p="fro")
130 X.requires_grad_(True)
--> 131 opt.step(value_and_grad)
132 X.requires_grad_(False)
133
~/opt/miniconda3/envs/repsys/lib/python3.7/site-packages/torch/optim/optimizer.py in wrapper(*args, **kwargs)
86 profile_name = "Optimizer.step#{}.step".format(obj.__class__.__name__)
87 with torch.autograd.profiler.record_function(profile_name):
---> 88 return func(*args, **kwargs)
89 return wrapper
90
~/opt/miniconda3/envs/repsys/lib/python3.7/site-packages/torch/autograd/grad_mode.py in decorate_context(*args, **kwargs)
26 def decorate_context(*args, **kwargs):
27 with self.__class__():
---> 28 return func(*args, **kwargs)
29 return cast(F, decorate_context)
30
~/opt/miniconda3/envs/repsys/lib/python3.7/site-packages/pymde/lbfgs.py in step(self, closure)
518
519 loss, flat_grad, t, ls_func_evals = _strong_wolfe(
--> 520 obj_func, x_init, t, d, loss, flat_grad, gtd)
521 self._cached_loss = torch.tensor(loss, device=flat_grad.device)
522 self._add_grad(t, d)
~/opt/miniconda3/envs/repsys/lib/python3.7/site-packages/pymde/lbfgs.py in _strong_wolfe(obj_func, x, t, d, f, g, gtd, c1, c2, tolerance_change, max_ls)
70 raise SolverError("Function evaluation returned NaN.")
71 elif np.isinf(f_new).any():
---> 72 raise SolverError("Function evaluation returned inf.")
73 elif torch.isnan(g_new).any():
74 raise SolverError("Gradient evaluation returned NaN.")
SolverError: Function evaluation returned inf.
I tried different configurations of the preserve_neighbors function, but still getting the same error. After removing this constraint, everything works just fine. I also tried Centered() constraint, which works as well.
My implementation is:
pymde.seed(0)
mde = pymde.preserve_neighbors(matrix, init='random', constraint=pymde.Centered(), verbose=True)
embeddings = mde.embed(verbose=True, max_iter=400)
embeddings = embeddings.cpu().numpy()I install the pymde in PyCharm,for the beginning example with MNIST.
I use pymde.plot(embedding, color_by=mnist.attributes['digits']),but I can't see the visualization result.
I don't kown where I am wrong,can you help me?
Here is my code:
`import pymde
import torchvision
mnist = pymde.datasets.MNIST()
#Next, we embed
embedding = pymde.preserve_neighbors(mnist.data, verbose=True).embed(verbose=True)
print('embedding shape === ',embedding.shape)
pymde.plot(embedding, color_by=mnist.attributes['digits'])`
Hi, how could we use pymde to implement default embeddings like UMAP?
Hi.
I have had some on and off luck with using pymde. I am trying the embedding on a dataset of images and the way I have been working on my experiment is as follows:
The experiment works great when i use images from 2 folders (2list.npy). But when I increase the number of images (3list.npy, 10list.npy), the code gets stuck at "Computing quadratic initialization".
In the google drive link below, you will find the following:
The code in the notebook is self explanatory. To duplicate the issue, first use "2list.npy", which should run successfully. Then try "3list.npy" and "10list.npy", which should get stuck at "Computing quadratic initialization".
https://drive.google.com/file/d/17kktp6W1Lq_7PjxCiEQBEAk_u-kbDLEN/view?usp=sharing
Hi, this is an interesting library :) I have one question, does pymde handle missing data?
For example, for data of shape (n_items, n_features) as input into pymde.preserve_neighbors(data), some n_features may be nan.
It is in principle possible to have multiple constraint sets, so long as the constraints are on mutually exclusive subsets of the items.
For example, for n=1000 items, the vectors of items 0, ..., 99 could be anchored in place, while the submatrix of the embedding for items 100, ..., 999 could constrained to be standardized.
Hi, many thanks for the wonderful package. I have observed that I get segmentation fault errors when using PyTorch 2.0 and pymde. Everything works fine with PyTorch 1.13.1. Would it be possible to pin torch accordingly?
Is there an easy way to use constraint=Standardized() with target standard deviation set to some value sigma instead of 1? Or would I need to define my own class by copying the _Standardized() code and modifying the standard deviation there?
It would be awesome to build PyMDE on Conda Forge.
I would appreciate some help with this, since I don't have experience uploading to Conda Forge.
@mfansler, if you're still interested in helping, that would be much appreciated.
When installing the package using peotry on a device that does not have cuda installed I get the error:
Unable to find installation candidates for nvidia-cudnn-cu11
since the package works on CPU as well is it possible to fix this install issue so that i don't have to have a gpu enabled device to install the package.
Hi Akshay,
I was trying to fit my data to a pymde.datasets object and plot the embedding with the following code:
# convert 30 features to torch.tensor
print('data shape: ' + str(latent_vector.iloc[:,:-1].shape))
data = torch.tensor(latent_vector.iloc[:,:-1].values)
print(type(data))
# convert target to attributes dictionary
print('target shape: ' + str(latent_vector.iloc[:,-1:].shape))
attributes = {'predictions': latent_vector.iloc[:,-1:].values}
print(type(attributes))
# create pyMDE object from data and attributes
dataset = pymde.datasets.Dataset(data, attributes)
print(type(dataset))
print(type(dataset.data))
print(type(dataset.attributes))
# embedding
mde = pymde.preserve_neighbors(dataset.data, verbose=True)
embedding = mde.embed(verbose=True)
# visualize the embedding
pymde.plot(embedding, color_by=dataset.attributes['predictions'])
print:
data shape: (1286810, 30)
<class 'torch.Tensor'>
target shape: (1286810, 1)
<class 'dict'>
<class 'pymde.datasets.Dataset'>
<class 'torch.Tensor'>
<class 'dict'>
Mar 25 12:17:28 PM: Computing 15-nearest neighbors, with max_distance=None
Thu Mar 25 12:17:28 2021 Building RP forest with 32 trees
Thu Mar 25 12:17:36 2021 NN descent for 20 iterations
1 / 20
2 / 20
Stopping threshold met -- exiting after 2 iterations
Mar 25 12:18:04 PM: Computing quadratic initialization.
Mar 26 10:18:36 AM: Fitting a centered embedding into R^2, for a graph with 1286810 items and 23259581 edges.
Mar 26 10:18:36 AM: `embed` method parameters: eps=1.0e-05, max_iter=300, memory_size=10
Mar 26 10:18:42 AM: iteration 000 | distortion 2.465605 | residual norm 0.889904 | step length 0.00157404 | percent change 8.72897e-05
Mar 26 10:20:09 AM: iteration 030 | distortion 0.208646 | residual norm 0.000285891 | step length 1 | percent change 5.24053
Mar 26 10:21:41 AM: iteration 060 | distortion 0.099533 | residual norm 0.000107316 | step length 1 | percent change 1.34718
Mar 26 10:23:11 AM: iteration 090 | distortion 0.076901 | residual norm 8.17378e-05 | step length 1 | percent change 0.672268
Mar 26 10:24:42 AM: iteration 120 | distortion 0.066920 | residual norm 6.65433e-05 | step length 1 | percent change 0.450777
Mar 26 10:26:10 AM: iteration 150 | distortion 0.060995 | residual norm 5.49753e-05 | step length 1 | percent change 0.325744
Mar 26 10:27:37 AM: iteration 180 | distortion 0.057445 | residual norm 4.82097e-05 | step length 1 | percent change 0.255452
Mar 26 10:29:05 AM: iteration 210 | distortion 0.054821 | residual norm 4.50138e-05 | step length 1 | percent change 0.183081
Mar 26 10:30:33 AM: iteration 240 | distortion 0.052996 | residual norm 3.57502e-05 | step length 1 | percent change 0.162585
Mar 26 10:32:01 AM: iteration 270 | distortion 0.051759 | residual norm 3.04045e-05 | step length 1 | percent change 0.115733
Mar 26 10:33:27 AM: iteration 299 | distortion 0.050823 | residual norm 2.29072e-05 | step length 1 | percent change 0.139809
Mar 26 10:33:27 AM: Finished fitting in 890.999 seconds and 300 iterations.
Mar 26 10:33:27 AM: average distortion 0.0508 | residual norm 2.3e-05
I encountered the following problem:
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
<ipython-input-118-a135ee68ae95> in <module>
20
21 # visualize the embedding
---> 22 pymde.plot(embedding, color_by=dataset.attributes['predictions'])
~\Anaconda3\envs\vame\lib\site-packages\pymde\experiment_utils.py in plot(X, color_by, color_map, colors, edges, axis_limits, background_color, marker_size, figsize_inches, savepath)
504 background_color=background_color,
505 s=marker_size,
--> 506 figsize=figsize_inches,
507 )
508
~\Anaconda3\envs\vame\lib\site-packages\pymde\experiment_utils.py in _plot(X, color_by, edges, s, figsize, colors, cmap, lim, background_color, title, tight, savepath)
357 edgecolor=[],
358 cmap=cmap,
--> 359 alpha=1.0,
360 )
361 elif colors is not None:
~\Anaconda3\envs\vame\lib\site-packages\matplotlib\__init__.py in inner(ax, data, *args, **kwargs)
1445 def inner(ax, *args, data=None, **kwargs):
1446 if data is None:
-> 1447 return func(ax, *map(sanitize_sequence, args), **kwargs)
1448
1449 bound = new_sig.bind(ax, *args, **kwargs)
~\Anaconda3\envs\vame\lib\site-packages\matplotlib\cbook\deprecation.py in wrapper(*inner_args, **inner_kwargs)
409 else deprecation_addendum,
410 **kwargs)
--> 411 return func(*inner_args, **inner_kwargs)
412
413 return wrapper
~\Anaconda3\envs\vame\lib\site-packages\matplotlib\axes\_axes.py in scatter(self, x, y, s, c, marker, cmap, norm, vmin, vmax, alpha, linewidths, verts, edgecolors, plotnonfinite, **kwargs)
4451 self._parse_scatter_color_args(
4452 c, edgecolors, kwargs, x.size,
-> 4453 get_next_color_func=self._get_patches_for_fill.get_next_color)
4454
4455 if plotnonfinite and colors is None:
~\Anaconda3\envs\vame\lib\site-packages\matplotlib\axes\_axes.py in _parse_scatter_color_args(c, edgecolors, kwargs, xsize, get_next_color_func)
4250 isinstance(c, str)
4251 or (np.iterable(c) and len(c) > 0
-> 4252 and isinstance(cbook.safe_first_element(c), str)))
4253
4254 def invalid_shape_exception(csize, xsize):
~\Anaconda3\envs\vame\lib\site-packages\matplotlib\cbook\__init__.py in safe_first_element(obj)
1669 raise RuntimeError("matplotlib does not support generators "
1670 "as input")
-> 1671 return next(iter(obj))
1672
1673
NotImplementedError: multi-dimensional sub-views are not implemented
It seems like the color_by=dataset.attributes['predictions'] is the problem, as I can plot the embedding without coloring, althouth there is not much to see:
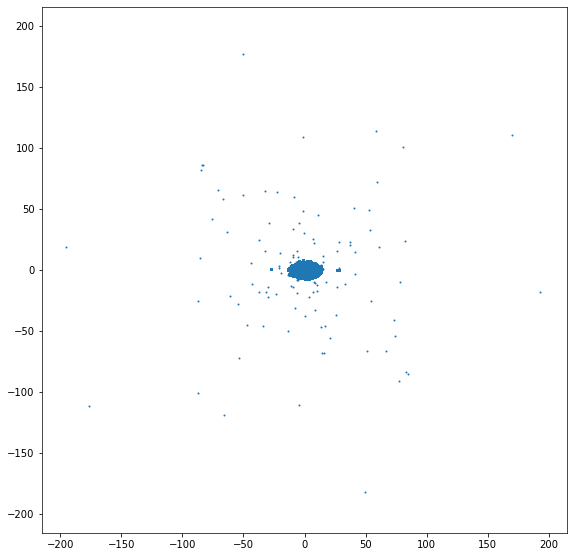
This is how the umap embedding looked like from import umap:

Do you have a hunch of what I am missing?
Last side note: mde.device shows that my GPU is not detected (or at least not engaged) device(type='cpu') and the embedding took 22 hours, any idea on that?
Thanks in advance!
Hi.
I'm interested in using PyMDE for some embedding problem. In the training data the method seems to work fine, but I've been trying to use the function of incremental embedding in order to embed new points and I obtain the following error:
This is a part of my code:
g1 = pymde.Graph(adj)
embedding = pymde.preserve_neighbors(g1).embed()
pymde.plot(embedding)
# To add new points into the embedding
anchor_constraint = pymde.Anchored(
anchors = torch.arange(n_train),
values = embedding,
)
incremental_mde = pymde.preserve_neighbors(
g1,
constraint = anchor_constraint,
init='random',
verbose=True)
incremental_mde.embed()When performing incremental_mde.embed() appears the following error:
_SolverError: Function evaluation returned NaN.
File "C:\Users\bioimag\AppData\Local\Temp/ipykernel_17984/3089993745.py", line 12, in
incremental_mde.embed()
File "C:\Users\bioimag\anaconda3\envs\embeds03\lib\site-packages\pymde\problem.py", line 496, in embed
X_star, solve_stats = optim.lbfgs(
File "C:\Users\bioimag\anaconda3\envs\embeds03\lib\site-packages\pymde\optim.py", line 131, in lbfgs
opt.step(value_and_grad)
File "C:\Users\bioimag\anaconda3\envs\embeds03\lib\site-packages\torch\optim\optimizer.py", line 89, in wrapper
return func(*args, **kwargs)
File "C:\Users\bioimag\anaconda3\envs\embeds03\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Users\bioimag\anaconda3\envs\embeds03\lib\site-packages\pymde\lbfgs.py", line 519, in step
loss, flat_grad, t, ls_func_evals = _strong_wolfe(
File "C:\Users\bioimag\anaconda3\envs\embeds03\lib\site-packages\pymde\lbfgs.py", line 70, in _strong_wolfe
raise SolverError("Function evaluation returned NaN.")
SolverError: Function evaluation returned NaN_.
I saw a similar issue (#9), so I downgraded the pytorch version to the 1.8 version, but it still doesn't work.
Thank you in advance for your help.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.