![]()
![]()

The official documentation for PyMDE is available at www.pymde.org.
This repository accompanies the monograph Minimum-Distortion Embedding.
PyMDE is a Python library for computing vector embeddings for finite sets of items, such as images, biological cells, nodes in a network, or any other abstract object.
What sets PyMDE apart from other embedding libraries is that it provides a simple but general framework for embedding, called Minimum-Distortion Embedding (MDE). With MDE, it is easy to recreate well-known embeddings and to create new ones, tailored to your particular application.
PyMDE is competitive in runtime with more specialized embedding methods. With a GPU, it can be even faster.
PyMDE can be enjoyed by beginners and experts alike. It can be used to:
- visualize datasets, small or large;
- generate feature vectors for supervised learning;
- compress high-dimensional vector data;
- draw graphs (in up to orders of magnitude less time than packages like NetworkX);
- create custom embeddings, with custom objective functions and constraints (such as having uncorrelated feature columns);
- and more.
PyMDE is very young software, under active development. If you run into issues, or have any feedback, please reach out by filing a Github issue.
This README gives a very brief overview of PyMDE. Make sure to read the official documentation at www.pymde.org, which has in-depth tutorials and API documentation.
PyMDE is available on the Python Package Index, and on Conda Forge.
To install with pip, use
pip install pymde
Alternatively, to install with conda, use
conda install -c pytorch -c conda-forge pymde
PyMDE has the following requirements:
- Python >= 3.7
- numpy >= 1.17.5
- scipy
- torch >= 1.7.1
- torchvision >= 0.8.2
- pynndescent
- requests
Getting started with PyMDE is easy. For embeddings that work out-of-the box, we provide two main functions:
pymde.preserve_neighborswhich preserves the local structure of original data, and
pymde.preserve_distanceswhich preserves pairwise distances or dissimilarity scores in the original data.
Arguments. The input to these functions is the original data, represented
either as a data matrix in which each row is a feature vector, or as a
(possibly sparse) graph encoding pairwise distances. The embedding dimension is
specified by the embedding_dim keyword argument, which is 2 by default.
Return value. The return value is an MDE object. Calling the embed()
method on this object returns an embedding, which is a matrix
(torch.Tensor) in which each row is an embedding vector. For example, if the
original input is a data matrix of shape (n_items, n_features), then the
embedding matrix has shape (n_items, embeddimg_dim).
We give examples of using these functions below.
The following code produces an embedding of the MNIST dataset (images of
handwritten digits), in a fashion similar to LargeVis, t-SNE, UMAP, and other
neighborhood-based embeddings. The original data is a matrix of shape (70000, 784), with each row representing an image.
import pymde
mnist = pymde.datasets.MNIST()
embedding = pymde.preserve_neighbors(mnist.data, verbose=True).embed()
pymde.plot(embedding, color_by=mnist.attributes['digits'])
Unlike most other embedding methods, PyMDE can compute embeddings that satisfy constraints. For example:
embedding = pymde.preserve_neighbors(mnist.data, constraint=pymde.Standardized(), verbose=True).embed()
pymde.plot(embedding, color_by=mnist.attributes['digits'])
The standardization constraint enforces the embedding vectors to be centered and have uncorrelated features.
The function pymde.preserve_distances is useful when you're more interested
in preserving the gross global structure instead of local structure.
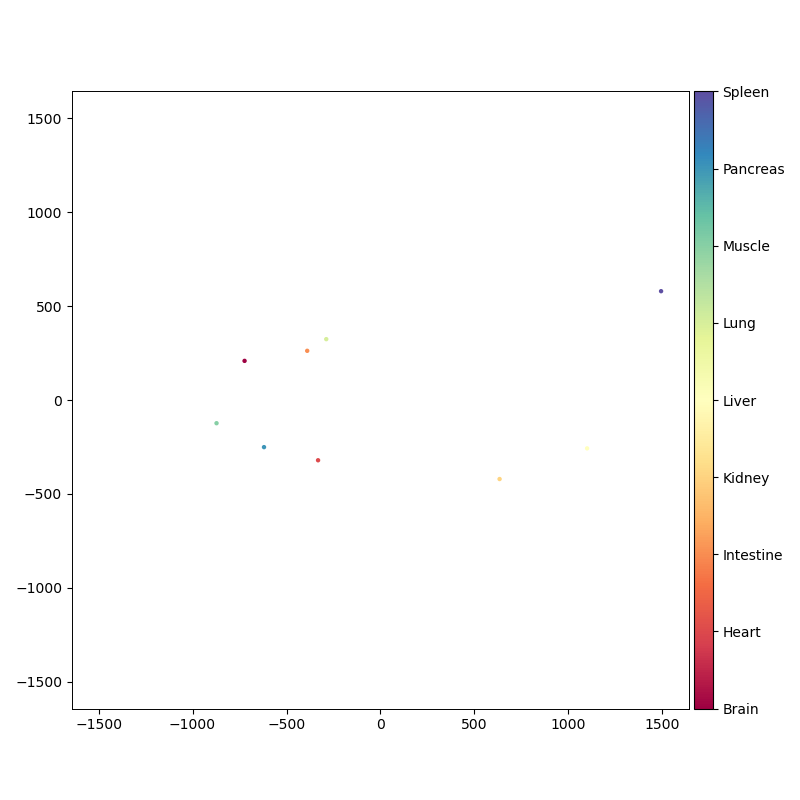
Here's an example that produces an embedding of an academic coauthorship network, from Google Scholar. The original data is a sparse graph on roughly 40,000 authors, with an edge between authors who have collaborated on at least one paper.
import pymde
google_scholar = pymde.datasets.google_scholar()
embedding = pymde.preserve_distances(google_scholar.data, verbose=True).embed()
pymde.plot(embedding, color_by=google_scholar.attributes['coauthors'], color_map='viridis', background_color='black')
More collaborative authors are colored brighter, and are near the center of the embedding.
We have several example notebooks that show how to use PyMDE on real (and synthetic) datasets.
To cite our work, please use the following BibTex entry.
@article{agrawal2021minimum,
author = {Agrawal, Akshay and Ali, Alnur and Boyd, Stephen},
title = {Minimum-Distortion Embedding},
journal = {arXiv},
year = {2021},
}
PyMDE was designed and developed by Akshay Agrawal.