deepinsight / insightface Goto Github PK
View Code? Open in Web Editor NEWState-of-the-art 2D and 3D Face Analysis Project
Home Page: https://insightface.ai
State-of-the-art 2D and 3D Face Analysis Project
Home Page: https://insightface.ai




































































































































































































































@nttstar when I run the code with three Titanx, but encounter crash, how should I solve it?
CUDA_VISIBLE_DEVICES='0,1,2' python -u train_softmax.py --network r50 --loss-type 2 --margin-m 0.35 --data-dir ../datasets/faces_ms1m_112x112 --prefix ../model-r50-amsoftmax
gpu num: 4
num_layers 50
image_size [112, 112]
num_classes 85164
Called with argument: Namespace(batch_size=512, beta=1000.0, beta_freeze=0, beta_min=5.0, c2c_threshold=0.0, center_alpha=0.5, center_scale=0.003, ckpt=1, coco_scale=8.676161173096705, ctx_num=4, data_dir='../datasets/faces_ms1m_112x112', easy_margin=0, emb_size=512, end_epoch=100000, gamma=0.12, image_channel=3, image_h=112, image_w=112, images_per_identity=0, incay=0.0, loss_type=2, lr=0.1, lr_steps='', margin=4, margin_m=0.35, margin_s=64.0, margin_verbose=0, max_steps=0, mom=0.9, network='r50', num_classes=85164, num_layers=50, output_c2c=0, patch='0_0_96_112_0', per_batch_size=128, power=1.0, prefix='../model-r50-amsoftmax', pretrained='', rand_mirror=1, rescale_threshold=0, retrain=False, scale=0.9993, target='lfw,cfp_ff,cfp_fp,agedb_30', triplet_alpha=0.3, triplet_bag_size=3600, triplet_max_ap=0.0, use_deformable=0, use_val=False, verbose=2000, version_input=1, version_output='E', version_se=0, version_unit=3, wd=0.0005)
init resnet 50
0 1 E 3
INFO:root:loading recordio ../datasets/faces_ms1m_112x112/train.rec...
header0 label [ 3804847. 3890011.]
id2range 85164
0 0
3804846
rand_mirror 1
(512,)
loading bin 1000
loading bin 2000
loading bin 3000
loading bin 4000
loading bin 5000
loading bin 6000
loading bin 7000
loading bin 8000
loading bin 9000
loading bin 10000
loading bin 11000
loading bin 12000
(12000L, 3L, 112L, 112L)
ver lfw
loading bin 1000
loading bin 2000
loading bin 3000
loading bin 4000
loading bin 5000
loading bin 6000
loading bin 7000
loading bin 8000
loading bin 9000
loading bin 10000
loading bin 11000
loading bin 12000
loading bin 13000
loading bin 14000
(14000L, 3L, 112L, 112L)
ver cfp_ff
loading bin 1000
loading bin 2000
loading bin 3000
loading bin 4000
loading bin 5000
loading bin 6000
loading bin 7000
loading bin 8000
loading bin 9000
loading bin 10000
loading bin 11000
loading bin 12000
loading bin 13000
loading bin 14000
(14000L, 3L, 112L, 112L)
ver cfp_fp
loading bin 1000
loading bin 2000
loading bin 3000
loading bin 4000
loading bin 5000
loading bin 6000
loading bin 7000
loading bin 8000
loading bin 9000
loading bin 10000
loading bin 11000
loading bin 12000
(12000L, 3L, 112L, 112L)
ver agedb_30
lr_steps [100000, 140000, 160000]
[14:06:14] /home/travis/build/dmlc/mxnet-distro/mxnet-build/dmlc-core/include/dmlc/logging.h:308: [14:06:14] src/storage/./pooled_storage_manager.h:107: cudaMalloc failed: out of memory
Stack trace returned 10 entries:
[bt] (0) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28e5ac) [0x7efbb96995ac]
[bt] (1) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28bb72f) [0x7efbbbcc672f]
[bt] (2) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28bf958) [0x7efbbbcca958]
[bt] (3) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23db5ad) [0x7efbbb7e65ad]
[bt] (4) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23e5684) [0x7efbbb7f0684]
[bt] (5) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23e661c) [0x7efbbb7f161c]
[bt] (6) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23eae98) [0x7efbbb7f5e98]
[bt] (7) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23f4e5a) [0x7efbbb7ffe5a]
[bt] (8) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23f5554) [0x7efbbb800554]
[bt] (9) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(MXExecutorSimpleBind+0x2250) [0x7efbbb76ef80]
Traceback (most recent call last):
File "train_softmax.py", line 873, in
main()
File "train_softmax.py", line 870, in main
train_net(args)
File "train_softmax.py", line 864, in train_net
epoch_end_callback = epoch_cb )
File "/usr/local/lib/python2.7/dist-packages/mxnet/module/base_module.py", line 460, in fit
for_training=True, force_rebind=force_rebind)
File "/usr/local/lib/python2.7/dist-packages/mxnet/module/module.py", line 428, in bind
state_names=self._state_names)
File "/usr/local/lib/python2.7/dist-packages/mxnet/module/executor_group.py", line 237, in init
self.bind_exec(data_shapes, label_shapes, shared_group)
File "/usr/local/lib/python2.7/dist-packages/mxnet/module/executor_group.py", line 333, in bind_exec
shared_group))
File "/usr/local/lib/python2.7/dist-packages/mxnet/module/executor_group.py", line 611, in _bind_ith_exec
shared_buffer=shared_data_arrays, **input_shapes)
File "/usr/local/lib/python2.7/dist-packages/mxnet/symbol/symbol.py", line 1494, in simple_bind
raise RuntimeError(error_msg)
RuntimeError: simple_bind error. Arguments:
data: (128, 3, 112, 112)
softmax_label: (128,)
[14:06:14] src/storage/./pooled_storage_manager.h:107: cudaMalloc failed: out of memory
Stack trace returned 10 entries:
[bt] (0) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28e5ac) [0x7efbb96995ac]
[bt] (1) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28bb72f) [0x7efbbbcc672f]
[bt] (2) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28bf958) [0x7efbbbcca958]
[bt] (3) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23db5ad) [0x7efbbb7e65ad]
[bt] (4) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23e5684) [0x7efbbb7f0684]
[bt] (5) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23e661c) [0x7efbbb7f161c]
[bt] (6) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23eae98) [0x7efbbb7f5e98]
[bt] (7) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23f4e5a) [0x7efbbb7ffe5a]
[bt] (8) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23f5554) [0x7efbbb800554]
[bt] (9) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(MXExecutorSimpleBind+0x2250) [0x7efbbb76ef80]
Thanks for your work,but the extra loss I do not know why you do this:
1 The extra loss is makes the l2 norm small,and you do this for hard sample mining?
2 In the code,the extra loss is used only when the loss is softmax or sphereface,why?The other loss can not use it?
I see you got very good accuracy on LFW, and it is better than @davidsandberg's.
How can I use your pretraind model with tensorflow as like @davidsandberg's?
Thanks.
Hi there, thanks for the great work, could you please provide the definition of different loss type. It would be many appreciated if the corresponding paper could be indicated.
Hello,
Ca you please give us/upload the 500+ overlap between facescrub identities and ms1m
also when can you upload the megface distractor noise list ?
Thanks,
Gsquared
Thanks for your amazing work! After reading your paper and some code in this project, i have some questions:
easy_margin? if args.easy_margin:
cond = mx.symbol.Activation(data=cos_t, act_type='relu')
#cond_v = cos_t - 0.4
#cond = mx.symbol.Activation(data=cond_v, act_type='relu')
else:
cond_v = cos_t - threshold
cond = mx.symbol.Activation(data=cond_v, act_type='relu')
It has been a long time that I want to try dropout and ReLU/PReLU after FC.
Thanks a lot, the result is conductive.
I have seen that the current top algorithm in the MegaFace challenge is iBug_DeepInsight, with an accuracy that corresponds with your latest update: 2018.02.13: We achieved state-of-the-art performance on MegaFace-Challenge-1, at 98.06
After reading your paper and the README in this repo, it seems to me that this accuracy is achieved using the cleaned/refined MegaFace dataset. Is this correct?
What is the accuracy you have got on Megaface for both verification, and identification, because through the published paper
ArcFace(m=0.5) Rank1@10^6: 83.27
VR@FAR10^6: 98.48
LResNet100E-IR@MS1M
Is there any problem with that?
can you share us the tool to convert from mxnet into caffe?
Hi,
In your paper, you used 3.8m images of Ms1m dataset. But in the clean list you provided, there is only 3.47m images. Could you please release the full clean list? Thank you!
Awesome work!
As I know, there are some overlapped identities between LFW and ms1m, does the clean list has removed the overlapped identities, this may affect the performance on LFW
What did you mean by sphereface? is it Asoftmax or L-Margin or Isoftmax ? because I think it's not same as Asoftmax ...
If yes did you test it and get similar behavior to the original one
Now I believe in order to achieve fairness, you should remove this repository, or at least remove this list of Megaface, because we are working hard to achieve a high result without taking the effort of other R&D guys, Companies...
Please respect my opinion, I appreciate your work and efforts, but day by day I think to do this thing because after 1 Month we will see all going to have the same result. This is in contrast to previous periods.
flake8 testing of https://github.com/deepinsight/insightface on Python 2.7.14
$ flake8 . --count --select=E901,E999,F821,F822,F823 --show-source --statistics
make_list(args)
^
1 F821 undefined name 'make_list'
There is a make_list() defined at:
Some questions need you guys to help answer, thanks in advance!
add fixed margin 44.
similarity transformation,
face_preprocess.py there are some commented code which looks like projective transform.test.py, I use the mtcnn crop the testing images, without resizing and fixed 44 margin. I am not sure if this is by design or I am wrong with the cropping steps -:)
mtcnn 5 landmarks
I have ran training to epoch 34, minibatch 1700 using code at https://github.com/deepinsight/insightface/tree/af4a4e8f5c47de08e9f069a6a5e65988b6e91888 with a few modification (adding memonger). Typical performance is
| LFW | CFP-FF | CFP-FP | AgeDB-30 |
|---|---|---|---|
| 99.817% | 99.771% | 94.257% | 98.000% |
Hi,
First congratulations on the great work you did. I am currently struggle on the Megaface Testing because it has so many duplicated images with Facescrub.
I am looking for the "remove_noises.py" you commented on the Readme.md, but it looks it's missing.
Thanks a lot for sharing your experiment code. I am planning to tinker Mobilenet model on Raspberry Pi. Would it be possible for you to share the model?
You have made a great work here. However, I believe that adding Angular Triplet Loss (https://github.com/KaleidoZhouYN/Angular-Triplet-Loss) will definitely improve the results on Megaface and LFW. Unfortunately, I do not have enough experience to implement it in MxNet. Hope someone will try it out soon.
Did you try this new loss? or willing to try it?
$ python2 -m flake8 --count --select=E901,E999,F821,F822,F823 --show-source --statistics
./src/data.py:1222:32: F821 undefined name 'idx2range'
print('idx2range', len(idx2range))
^
./src/data.py:1225:26: F821 undefined name 'path_root'
self.path_root = path_root
^
./src/data.py:1243:31: F821 undefined name 'per_batch_size'
self.identities = int(per_batch_size/self.images_per_identity)
^
./src/data.py:1250:96: F821 undefined name 'per_batch_size'
self.provide_data = [(data_name, (batch_size,) + data_shape), ('extra', (batch_size, per_batch_size))]
^
./src/data.py:1255:21: F821 undefined name 'per_batch_size'
while a<per_batch_size:
^
./src/data.py:1260:18: F821 undefined name 'per_batch_size'
c += per_batch_size
^
./src/data.py:1324:19: F821 undefined name 'faiss'
quantizer = faiss.IndexFlatL2(d) # the other index
^
./src/data.py:1325:15: F821 undefined name 'faiss'
index = faiss.IndexIVFFlat(quantizer, d, faiss_params[0], faiss.METRIC_L2)
^
./src/data.py:1325:65: F821 undefined name 'faiss'
index = faiss.IndexIVFFlat(quantizer, d, faiss_params[0], faiss.METRIC_L2)
^
./src/data.py:1348:13: F821 undefined name 'offline_reset'
offline_reset()
^
./src/data.py:1679:19: F821 undefined name 'faiss'
quantizer = faiss.IndexFlatL2(d) # the other index
^
./src/data.py:1680:15: F821 undefined name 'faiss'
index = faiss.IndexIVFFlat(quantizer, d, faiss_params[0], faiss.METRIC_L2)
^
./src/data.py:1680:65: F821 undefined name 'faiss'
index = faiss.IndexIVFFlat(quantizer, d, faiss_params[0], faiss.METRIC_L2)
^
./src/data/face2rec2.py:194:9: F821 undefined name 'make_list'
make_list(args)
^
Have a check at the mobilenet structure, and most of the weights are in the final FC layer:
pre_fc1_weight parameter size=25690112, shape=(512L, 50176L)
and looking at the code, the last pooling layer is omitted (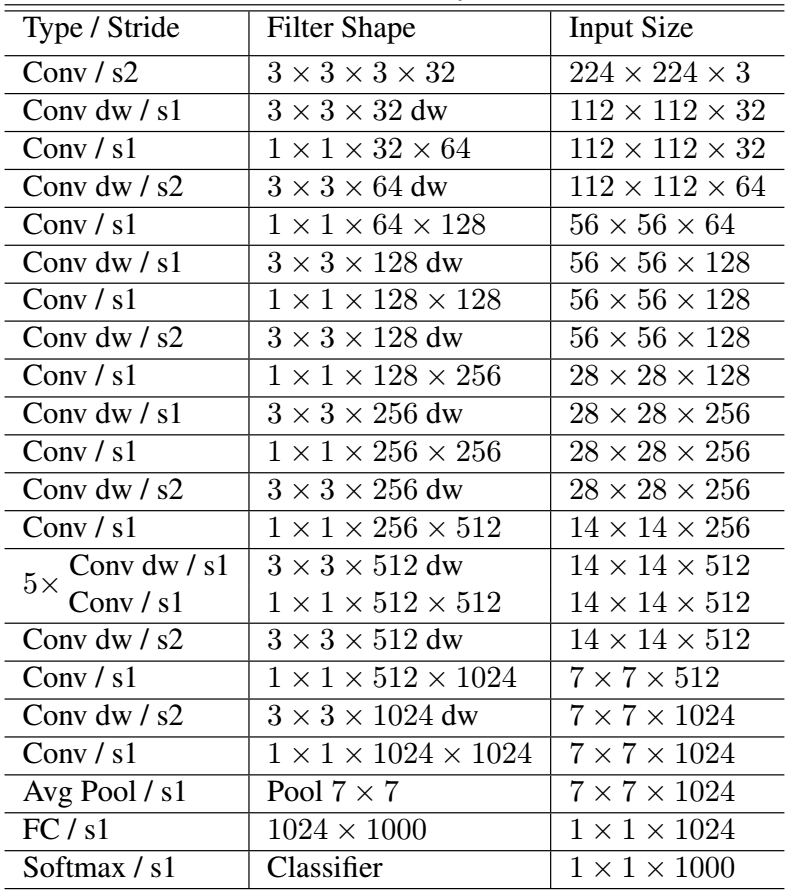 ).
).
insightface/src/symbols/fmobilenet.py
Lines 75 to 80 in f1cd542
Is this by design? Ignoring the last pooling layer leads to much larger model size -:(
Hi,
I have 2 questions related to the paper:
I have a doubt
Please look at the clean list provided by you, ms1m_clean_list.txt, in this list for the Freebase identity m.05lbbp which has one image 51.jpg
But in MsCeleb original database the Freebase identity m.05lbbp has 22 images with 51 name such as
51-FaceId-0.jpg 51-FaceId-11.jpg 51-FaceId-13.jpg 51-FaceId-15.jpg 51-FaceId-17.jpg 51-FaceId-19.jpg 51-FaceId-20.jpg 51-FaceId-2.jpg 51-FaceId-4.jpg 51-FaceId-6.jpg 51-FaceId-8.jpg 51-FaceId-10.jpg 51-FaceId-12.jpg 51-FaceId-14.jpg 51-FaceId-16.jpg 51-FaceId-18.jpg 51-FaceId-1.jpg 51-FaceId-21.jpg 51-FaceId-3.jpg 51-FaceId-5.jpg 51-FaceId-7.jpg 51-FaceId-9.jpg
can you please tell us how did you assign names to your images while generating images from MsCelebV1-Faces-Aligned.tsv while following the below format described by MsCeleb
File format: text files, each line is an image record containing 7 columns, delimited by TAB.
Column1: Freebase MID
Column2: ImageSearchRank
Column3: ImageURL
Column4: PageURL
Column5: FaceID
Column6: FaceRectangle_Base64Encoded (four floats, relative coordinates of UpperLeft and BottomRight corner)
Column7: FaceData_Base64Encoded
you can check the format at
https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
After going through the instructions for adding the dataset, and adding the dependency, and making sure I'm within the SRC file in the repository, I enter the following to run the model on MobileNet:
CUDA_VISIBLE_DEVICES='0,1,2,3' python -u train_softmax.py --network m1 --loss-type 4 --margin-m 0.5 --data-dir ../datasets/faces_ms1m_112x112 --prefix ../model-r100
But when I run that, I get the following output:
gpu num: 4
num_layers 1
image_size [112, 112]
num_classes 85164
Called with argument: Namespace(batch_size=512, beta=1000.0, beta_freeze=0, beta_min=5.0, c2c_mode=-10, c2c_threshold=0.0, center_alpha=0.5, center_scale=0.003, ckpt=1, coco_scale=8.676161173096705, ctx_num=4, data_dir='../datasets/faces_ms1m_112x112', easy_margin=0, emb_size=512, end_epoch=100000, gamma=0.12, image_channel=3, image_h=112, image_w=112, images_per_identity=0, incay=0.0, loss_type=4, lr=0.1, lr_steps='', margin=4, margin_m=0.5, margin_s=64.0, margin_verbose=0, max_steps=0, mom=0.9, network='m1', num_classes=85164, num_layers=1, output_c2c=0, patch='0_0_96_112_0', per_batch_size=128, power=1.0, prefix='../model-r100', pretrained='', rand_mirror=1, rescale_threshold=0, retrain=False, scale=0.9993, target='lfw,cfp_ff,cfp_fp,agedb_30', triplet_alpha=0.3, triplet_bag_size=3600, triplet_max_ap=0.0, use_deformable=0, use_val=False, verbose=2000, version_input=1, version_output='E', version_se=0, version_unit=3, wd=0.0005)
init mobilenet 1
(1, 'E', 3)
INFO:root:loading recordio ../datasets/faces_ms1m_112x112/train.rec...
header0 label [ 3804847. 3890011.]
id2range 85164
0 0
3804846
rand_mirror 1
(512,)
[20:17:39] src/engine/engine.cc:55: MXNet start using engine: ThreadedEnginePerDevice
loading bin 1000
loading bin 2000
loading bin 3000
loading bin 4000
loading bin 5000
loading bin 6000
loading bin 7000
loading bin 8000
loading bin 9000
loading bin 10000
loading bin 11000
loading bin 12000
(12000L, 3L, 112L, 112L)
ver lfw
loading bin 1000
loading bin 2000
loading bin 3000
loading bin 4000
loading bin 5000
loading bin 6000
loading bin 7000
loading bin 8000
loading bin 9000
loading bin 10000
loading bin 11000
loading bin 12000
loading bin 13000
loading bin 14000
(14000L, 3L, 112L, 112L)
ver cfp_ff
loading bin 1000
loading bin 2000
loading bin 3000
loading bin 4000
loading bin 5000
loading bin 6000
loading bin 7000
loading bin 8000
loading bin 9000
loading bin 10000
loading bin 11000
loading bin 12000
loading bin 13000
loading bin 14000
(14000L, 3L, 112L, 112L)
ver cfp_fp
loading bin 1000
loading bin 2000
loading bin 3000
loading bin 4000
loading bin 5000
loading bin 6000
loading bin 7000
loading bin 8000
loading bin 9000
loading bin 10000
loading bin 11000
loading bin 12000
(12000L, 3L, 112L, 112L)
ver agedb_30
lr_steps [100000, 140000, 160000]
[20:18:13] src/operator/././cudnn_algoreg-inl.h:107: Running performance tests to find the best convolution algorithm, this can take a while... (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
[20:18:16] /home/travis/build/dmlc/mxnet-distro/mxnet-build/dmlc-core/include/dmlc/logging.h:308: [20:18:16] src/storage/storage.cc:63: Check failed: e == cudaSuccess || e == cudaErrorCudartUnloading CUDA: invalid device ordinal
Stack trace returned 10 entries:
[bt] (0) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28e5ac) [0x7f08e94825ac]
[bt] (1) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28b98a6) [0x7f08ebaad8a6]
[bt] (2) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28bf94b) [0x7f08ebab394b]
[bt] (3) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23db5ad) [0x7f08eb5cf5ad]
[bt] (4) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23e5684) [0x7f08eb5d9684]
[bt] (5) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23e661c) [0x7f08eb5da61c]
[bt] (6) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23eae98) [0x7f08eb5dee98]
[bt] (7) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23f4e5a) [0x7f08eb5e8e5a]
[bt] (8) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23f5554) [0x7f08eb5e9554]
[bt] (9) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(MXExecutorSimpleBind+0x2250) [0x7f08eb557f80]
Traceback (most recent call last):
File "train_softmax.py", line 915, in <module>
main()
File "train_softmax.py", line 912, in main
train_net(args)
File "train_softmax.py", line 906, in train_net
epoch_end_callback = epoch_cb )
File "/usr/local/lib/python2.7/dist-packages/mxnet/module/base_module.py", line 460, in fit
for_training=True, force_rebind=force_rebind)
File "/usr/local/lib/python2.7/dist-packages/mxnet/module/module.py", line 428, in bind
state_names=self._state_names)
File "/usr/local/lib/python2.7/dist-packages/mxnet/module/executor_group.py", line 237, in __init__
self.bind_exec(data_shapes, label_shapes, shared_group)
File "/usr/local/lib/python2.7/dist-packages/mxnet/module/executor_group.py", line 333, in bind_exec
shared_group))
File "/usr/local/lib/python2.7/dist-packages/mxnet/module/executor_group.py", line 611, in _bind_ith_exec
shared_buffer=shared_data_arrays, **input_shapes)
File "/usr/local/lib/python2.7/dist-packages/mxnet/symbol/symbol.py", line 1494, in simple_bind
raise RuntimeError(error_msg)
RuntimeError: simple_bind error. Arguments:
data: (128, 3, 112, 112)
softmax_label: (128,)
[20:18:16] src/storage/storage.cc:63: Check failed: e == cudaSuccess || e == cudaErrorCudartUnloading CUDA: invalid device ordinal
Stack trace returned 10 entries:
[bt] (0) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28e5ac) [0x7f08e94825ac]
[bt] (1) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28b98a6) [0x7f08ebaad8a6]
[bt] (2) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x28bf94b) [0x7f08ebab394b]
[bt] (3) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23db5ad) [0x7f08eb5cf5ad]
[bt] (4) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23e5684) [0x7f08eb5d9684]
[bt] (5) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23e661c) [0x7f08eb5da61c]
[bt] (6) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23eae98) [0x7f08eb5dee98]
[bt] (7) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23f4e5a) [0x7f08eb5e8e5a]
[bt] (8) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(+0x23f5554) [0x7f08eb5e9554]
[bt] (9) /usr/local/lib/python2.7/dist-packages/mxnet/libmxnet.so(MXExecutorSimpleBind+0x2250) [0x7f08eb557f80]
Can you include more detail in the README about the specific requirements in terms of devices and CUDA requirements?
After several tries I could not get the detector to work. Can you add a pre-cropped example/image.
@nttstar What do you think of applying model compression techniques (e.g Model Distillation) to Arcnet model to reduce run time?
Thank you for the great work! I'm not quite familiar with mxnet framework so sorry for a stupid question. Can you tell me where the backpropagation is implemented in your code, please?
first,it is really appreciate for sharing your codes!Now, i want to know the time consuming!
For single cropped face image(112x112), total inference time is only 17ms on my testing server(Intel E5-2660 @ 2.00GHz, Tesla M40, LResNet34E-IR).
the inference time (17ms) is run CPU or GPU?
I think the codes here shows that you normalize each feature on the whole test dataset's features.
It is some tricks or I misunderstood the codes?
What do you mean by mobilenet v2 is it for mobile?
thanks for your sharing and which dataset do you used?
Just want to know the training time cost about the provided LResNet50E-IR model.
per the code in deploy/test.py:
parser.add_argument('--image-size', default='112,112', help='')it seems that the input should be cropped as square with width as 112, however the mtcnn output may be rectangle, I thought the detailed steps to run test.py are as below:
test.py and the script will do face alignment with mtcnnI am curious if my understanding is wrong, I thought the alignment before resizing should be more reliable?
Hi, from the paper and readme, it seems the mobilenet m1 == fmobilenet ==LMobileNetE , and curiors the performance of fmobilenetv2.
Thank you for your wonderful work, do you have plan to release the clean list, I want to use it with another alignment method
Traceback (most recent call last):
File "train_softmax.py", line 873, in
main()
File "train_softmax.py", line 870, in main
train_net(args)
File "train_softmax.py", line 593, in train_net
sym, arg_params, aux_params = get_symbol(args, arg_params, aux_params)
File "train_softmax.py", line 245, in get_symbol
fc7 = mx.sym.LSoftmax(data=embedding, label=gt_label, num_hidden=args.num_classes,
AttributeError: 'module' object has no attribute 'LSoftmax'
Hi dear author! Happy Chinese new year : )
In paper, you used Prelu as activation function in proposed residual block, but in fresnet.py, you seem to replaced prelu with relu, Am I right?If so, could you explain the reason?
Thanks!
can you share the landmarks annotations of vggface2 dataset?
Your performance of LResNet34E-IR converted caffemodel drop ~0.19 on LFW. I'm not familiar with mxnet. Can we convert mxnet model to caffe without lossing precision?
Dear:
Very impressive code release. Could you please share a working scrip to train and fine tune triplet loss with softmax?
Thanks
Hello, I want to know if has other tricks in your code besides your paper mentioned?
Hi,
Is it possible to share the dataset somewhere else?
Hi @nttstar , i notice that you use skimage SimilarityTransform method but not opencv estimateRigidTransform in face_preprocess.py. Is the first one can get a high face recogniton accuracy rate? Looking forward to your reply.
python align_facescrub.py --input-dir ~/face/megaface/facescrub/ --output-dir ./facescrub_align
Martin Henderson/Martin Henderson_40499
Rebecca Budig/Rebecca Budig_10788
Pamela Anderson/Pamela Anderson_2367
valid keys 3530
Creating networks and loading parameters
AttributeError: 'EasyDict' object has no attribute 'landmark'
Why do you select MXNET instead of tensorflow for this project?
What's the advantage of mxnet than tensorflow?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.