![]()
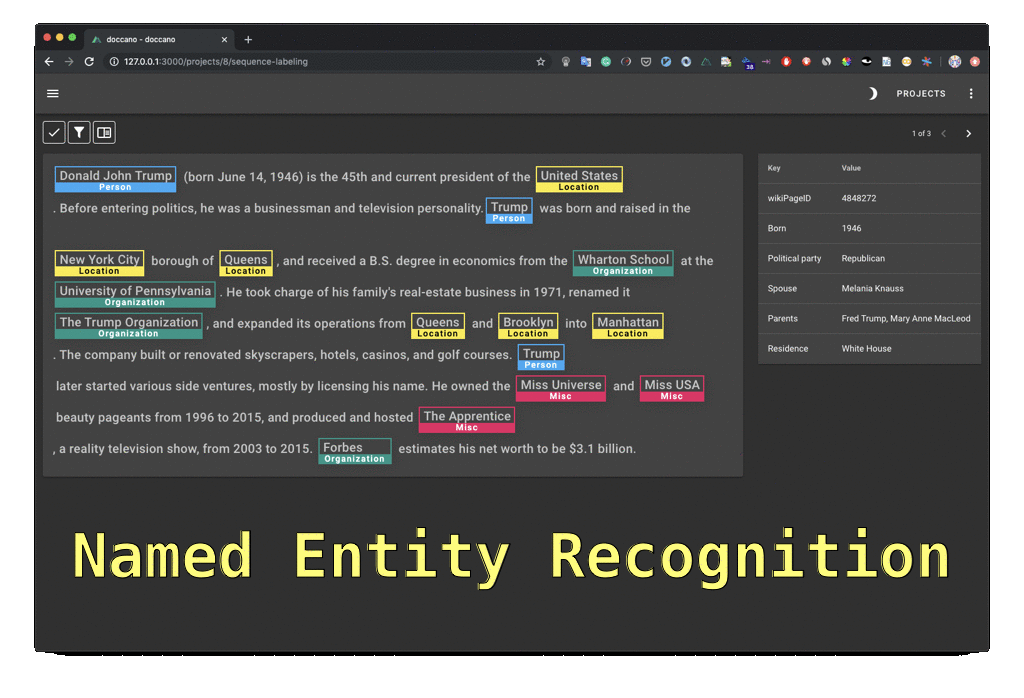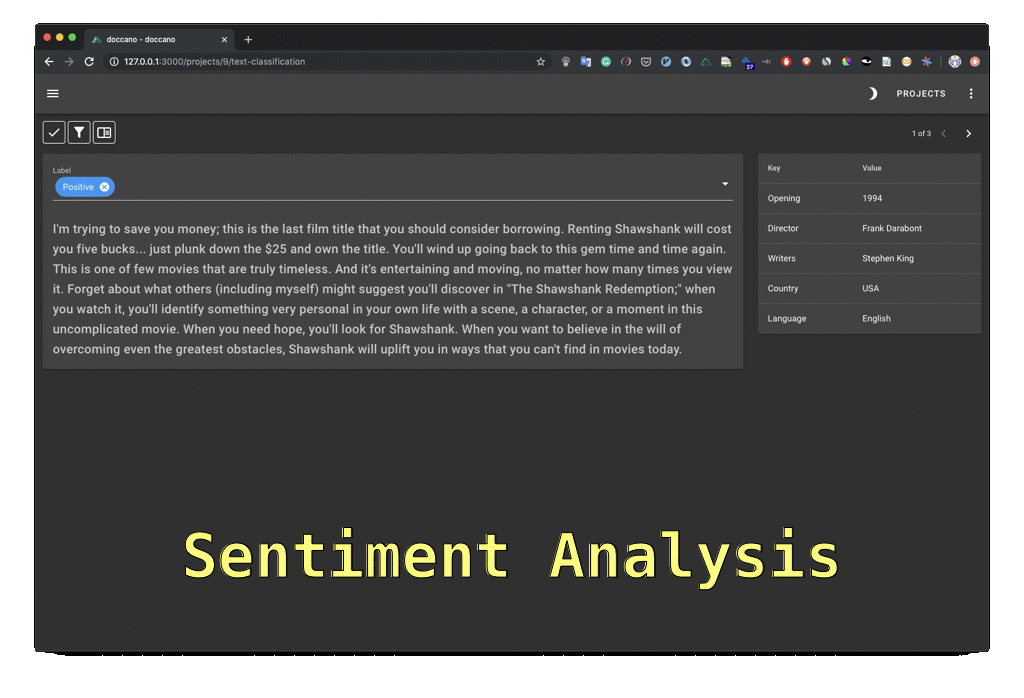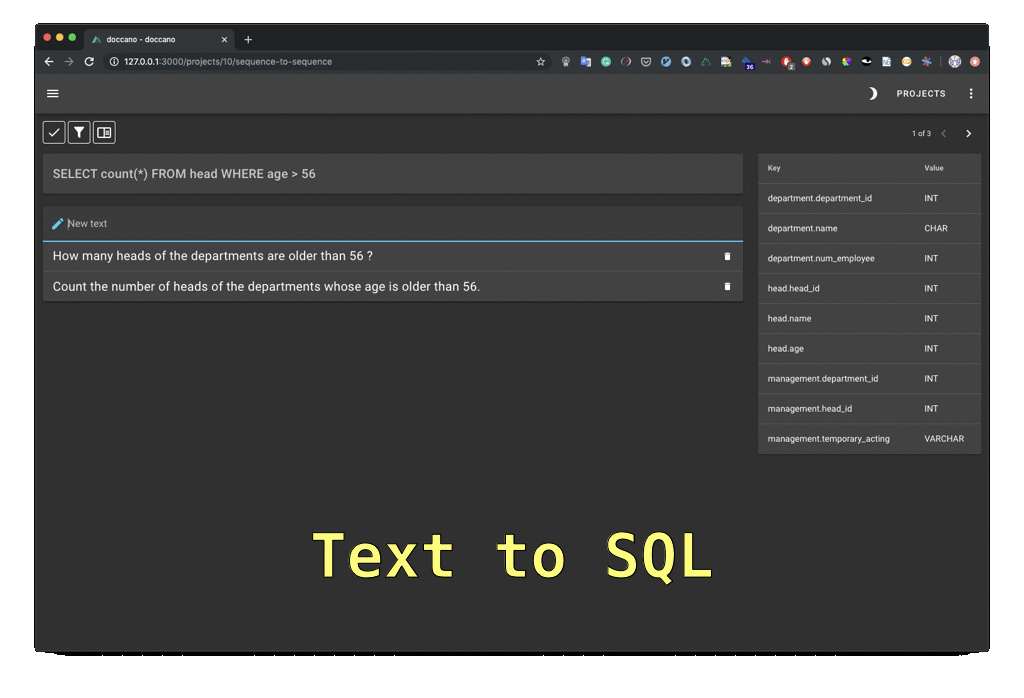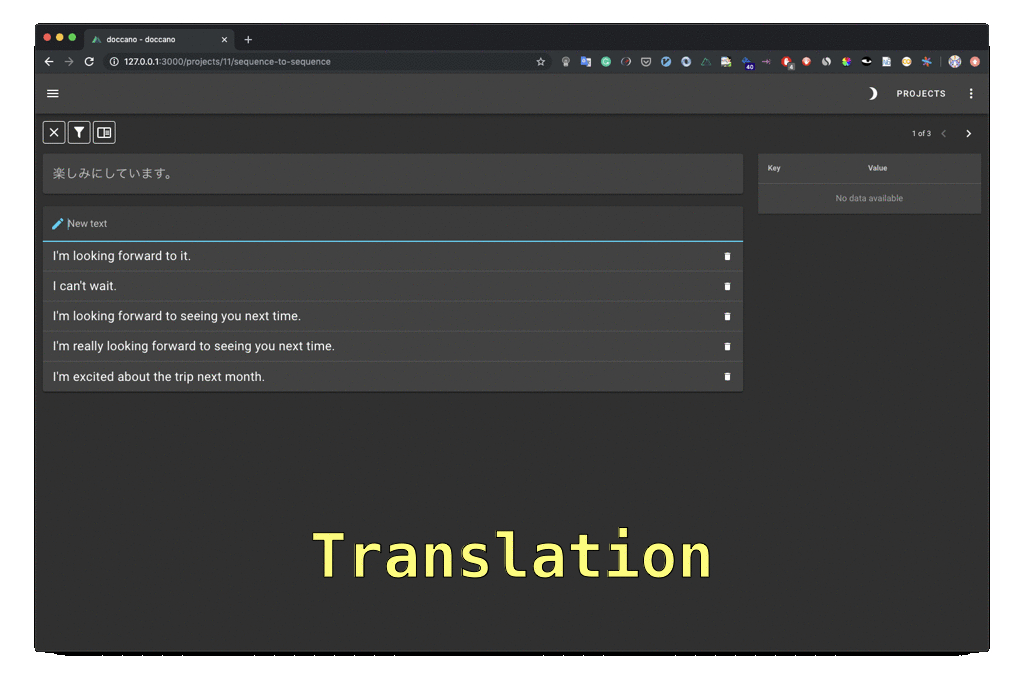
doccano is an open-source text annotation tool for humans. It provides annotation features for text classification, sequence labeling, and sequence to sequence tasks. You can create labeled data for sentiment analysis, named entity recognition, text summarization, and so on. Just create a project, upload data, and start annotating. You can build a dataset in hours.
Try the annotation demo.
Read the documentation at https://doccano.github.io/doccano/.
- Collaborative annotation
- Multi-language support
- Mobile support
- Emoji 😄 support
- Dark theme
- RESTful API
There are three options to run doccano:
- pip (Python 3.8+)
- Docker
- Docker Compose
To install doccano, run:
pip install doccanoBy default, SQLite 3 is used for the default database. If you want to use PostgreSQL, install the additional dependencies:
pip install 'doccano[postgresql]'and set the DATABASE_URL environment variable according to your PostgreSQL credentials:
DATABASE_URL="postgres://${POSTGRES_USER}:${POSTGRES_PASSWORD}@${POSTGRES_HOST}:${POSTGRES_PORT}/${POSTGRES_DB}?sslmode=disable"After installation, run the following commands:
# Initialize database.
doccano init
# Create a super user.
doccano createuser --username admin --password pass
# Start a web server.
doccano webserver --port 8000In another terminal, run the command:
# Start the task queue to handle file upload/download.
doccano taskGo to http://127.0.0.1:8000/.
As a one-time setup, create a Docker container as follows:
docker pull doccano/doccano
docker container create --name doccano \
-e "ADMIN_USERNAME=admin" \
-e "[email protected]" \
-e "ADMIN_PASSWORD=password" \
-v doccano-db:/data \
-p 8000:8000 doccano/doccanoNext, start doccano by running the container:
docker container start doccanoGo to http://127.0.0.1:8000/.
To stop the container, run docker container stop doccano -t 5. All data created in the container will persist across restarts.
If you want to use the latest features, specify the nightly tag:
docker pull doccano/doccano:nightlyYou need to install Git and clone the repository:
git clone https://github.com/doccano/doccano.git
cd doccanoNote for Windows developers: Be sure to configure git to correctly handle line endings or you may encounter status code 127 errors while running the services in future steps. Running with the git config options below will ensure your git directory correctly handles line endings.
git clone https://github.com/doccano/doccano.git --config core.autocrlf=inputThen, create an .env file with variables in the following format (see ./docker/.env.example):
# platform settings
ADMIN_USERNAME=admin
ADMIN_PASSWORD=password
[email protected]
# rabbit mq settings
RABBITMQ_DEFAULT_USER=doccano
RABBITMQ_DEFAULT_PASS=doccano
# database settings
POSTGRES_USER=doccano
POSTGRES_PASSWORD=doccano
POSTGRES_DB=doccano
After running the following command, access http://127.0.0.1/.
docker-compose -f docker/docker-compose.prod.yml --env-file .env up| Service | Button |
|---|---|
| AWS1 |  |
| Heroku |  |
See the documentation for details.
As with any software, doccano is under continuous development. If you have requests for features, please file an issue describing your request. Also, if you want to see work towards a specific feature, feel free to contribute by working towards it. The standard procedure is to fork the repository, add a feature, fix a bug, then file a pull request that your changes are to be merged into the main repository and included in the next release.
Here are some tips might be helpful. How to Contribute to Doccano Project
@misc{doccano,
title={{doccano}: Text Annotation Tool for Human},
url={https://github.com/doccano/doccano},
note={Software available from https://github.com/doccano/doccano},
author={
Hiroki Nakayama and
Takahiro Kubo and
Junya Kamura and
Yasufumi Taniguchi and
Xu Liang},
year={2018},
}For help and feedback, feel free to contact the author.
Footnotes
-
(1) EC2 KeyPair cannot be created automatically, so make sure you have an existing EC2 KeyPair in one region. Or create one yourself. (2) If you want to access doccano via HTTPS in AWS, here is an instruction. ↩

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")









































































































