esi-neuroscience / syncopy Goto Github PK
View Code? Open in Web Editor NEWSystems Neuroscience Computing in Python: user-friendly analysis of large-scale electrophysiology data
License: BSD 3-Clause "New" or "Revised" License
Systems Neuroscience Computing in Python: user-friendly analysis of large-scale electrophysiology data
License: BSD 3-Clause "New" or "Revised" License
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")












































In FieldTrip channel labels are accessed via the label field. Users might get the impression that our channels don't have labels, since objects do not have a .label property.
Conversely, users might expect that .channel actually accesses the underlying data by-channel, e.g.,
>>> data.channel[0]
array([-37.6199, -49.1482, -60.0665, ..., -59.6986, -52.9486, -45.1072],
dtype=float32)In addition to a timelockanalysis method for computing averages (compare #180), the following methods are needed (named after their respective FieldTrip prototypes):
statistics/freqdescriptives
statistics/freqgrandaverageSee fieldtrip functions here:
Not really a problem per se, more like a missing feature? Please elaborate
Support parallel processing of multiple Syncopy objects could be realized in a relatively straight-forward fashion via using a bag.map([obj for obj in data]) construction in unwrap_cfg
Not really a problem per se, more like a missing feature? Please elaborate
Right now we use a custom-tailored snippet relying on np.searchsorted to match user-queried values with a target NumPy array in 8 different places across five files (testing routines not included). We should really standardize this using a routine such as
values, idx = best_match(source, selection, span=True, tol=None, squash_duplicates=True)
# span -> allow `toilim`/`foilim` like selections
# tol -> if provided, ensures values in selection do not deviate further than `tol` from source, e.g.,
if tol is not None:
assert np.all([np.all((np.abs(source - value)) < tol) for value in selection])
# squash_duplicates:
# source = [0, 1, 2, 3]
# selection = [0.4, 1., 1.2, 1.9]
# -> values = [0, 1, 2], idx = [0, 1, 2]
# Algorithm:
issorted = True # do not perform O(n) potentially unnecessary sort ops!
if np.diff(source).min() < 0:
issorted = False
orig = source.copy()
idx_orig = np.argsort(orig)
source = orig[idx_orig]
if span:
idx = np.intersect1d(np.where(source >= selection[0])[0], np.where(source <= selection[1])[0])
else:
idx = np.searchsorted(source, selection, side="left")
leftNbrs = np.abs(selection - source[np.maximum(idx - 1, np.zeros(idx.shape, dtype=np.intp))])
rightNbrs = np.abs(selection - source[np.minimum(idx, np.full(idx.shape, source.size - 1, dtype=np.intp))])
shiftLeft = ((idx == source.size) | (leftNbrs < rightNbrs))
idx[shiftLeft] -= 1
if squash_duplicates: # account for potentially unsorted selections (and thus `idx`)
_, xdi = np.unique(idx, return_index=True)
idx = idx[np.sort(xdi)]
if not issorted:
idx_sort = idx_orig[idx]
return orig[idx_sort], idx_sort
else:
return source[idx], idx
# Test with:
# 1:
source = np.arange(10)
selection = np.array([ 1.9, 9. , 1. , -0.4, 1.2, 0.2, 9.5])
# 2:
source = np.random.choice(source, size=source.size, replace=False)
# 3:
selection.sort()
# 4:
selection = [1.5, 5.9]As not all future data classes will have a data property we remove explicit dataset properties (BaseData.data) from BaseData and move it further down the hierarchy. This requires removing all explicit references in
BaseData.__init__BaseData.__del__BaseData.mode.setterBaseData.tagBaseData.containerBaseData.clearBaseData.copyIssue #3 depends on this functionality.
The tests for the data_parser function currently only operate on AnalogData. This should be extended to all data classes.
Is your feature request related to a problem? Please elaborate.
As it stands right now, the VirtualData class is a piece of working but borderline useless code that requires a plethora of workarounds in multiple places throughout the code. It is very questionable, whether our VirutalData is ever going to be used "in the wild" so keeping it around seems like a lot of unnecessary work.
Do you have a solution in mind? Please elaborate
We should remove VirtualData from the package. If we find ourselves to ever need the same or related functionality, we can still go back and salvage the code.
@joschaschmiedt Any objections?
@pantaray, I tried to fined tests for a
ComputationalRoutinewith multiple positional arguments. Do they exist? If not should I open an issue?Currently, we do not test that. However, multiple positional arguments are a mandatory requirement for all time-frequency methods (which was actually the reason for me to re-visit
in-gridandsi-gridin the first place ;) ). So, as soon as TF-stuff is operational, we will automatically test this functionality. However, if you want to have explicit tests for multiple positional args ofComputationalRoutine, I'm def. open for it (of course, those tests will be more artificial in nature, but might make debugging easier).
Ideally I think we should have an explicit test for that (for the unlikely case that the TF implementation changes). Let's have an issue for that.
Originally posted by @joschaschmiedt in #38 (comment)
Currently, using multiple positional arguments in a computeFunction of a ComputationalRoutine instance is supported but so far completely untested. While time-frequency analysis methods make use of this functionality and thus testing mtmconvol and wavelet automatically tests the handling of multiple positional args in a computeFunction, we should probably include explicit tests for this (very crucial) functionality in the package for
two reasons: (a) interweaving these tests w/TF tests makes debugging unnecessarily hard and (b) as @joschaschmiedt rightly points out, in the unlikely event the TF implementation changes, the functionality tests silently disappear without notice.
Is your feature request related to a problem? Please elaborate.
When working with large dask LocalCluster objects (large = many local workers), it can happen, that multiple workers try to access the same session token due to mystery behavior of the blake2b hash algorithm triggering very weird cascade of ImportError exceptions.
Do you have a solution in mind? Please elaborate
We should consider using the Python interpreter's process ID to generate session IDs instead of (pseudo-random) hashes. This would also simplify debugging of parallel processing setups.
Additional context
PIDs might cause some headaches under Windows, though...
Is your feature request related to a problem? Please elaborate.
Currently, it is not possible for parallel workers spawned by ComputationalRoutine to determine which trial-(channel-)chunk they're currently processing. This will probably be necessary for some more elaborate computeFunctions (that might also require inter-worker communication).
Do you have a solution in mind? Please elaborate
We should incorporate a new mandatory keyword for computeFunctions: following dask's map_blocks array method, we should consider implementing a block_info keyword (following dask's nomenclature): block_info will be a dictionary providing references to the current chunk-index and respective trial number. Adhering to dask's naming scheme should make the keyword quite self-explaining to developers familiar with dask arrays.
Not really a problem per se, more like a missing feature? Please elaborate
De-trending is currently not supported by freqanalysis. We should support polyremoval and polyorder keywords. Leverage detrend option of stft for this.
To ensure proper functionality of Syncopy w/o a functional dask installation, a new testing environment without dask should be added to the current test setup.
Is your feature request related to a problem? Please elaborate.
The input argument unfolding in ComputationalRoutine is currently very gullible:
self.argv[ak] = [arg] * numTrialsThis can go horribly wrong. As per @joschaschmiedt we should explicitly check for supported argument types before fanning out arg across (a potentially huge number of) workers here...
To allow visual inspection, basic visualization tools are needed. At least simple plotting of AnalogData and SpectralData trials (w/smart streaming from disk to not spill GBs of data into memory) is required.
Two promising candidates to handle the heavy lifting for us are
ipywidgets using WebGL. Development seems to have stopped or at least slowed down (last release > 1yr ago). Here is a blog post by iPyVolume's lead developer.Adapt/extend/test SpectralData to handle time-frequency data
In order to avoid confusion, our wording concerning I/O should be consistent. We should go through all documentation and make sure that
We want to support by-trial variations in time-/frequency-selections, i.e., things like
select = {"trials": [5, 1, 4], "toi": [[0, 3, 1], [0, 1, 2], [3]]}FieldTrip supports similar functionality in some cases (e.g., by-trial toilims in ft_redefinetrial).
To adequately represent the result of averaging or pairwise connectivity analyses, a new class structure is needed. Similar to the already existing (abstract and concrete) classes, the following inheritance tree needs to be implemented:
graph TD
BaseData-->AnalogData;
BaseData-->SpectralData;
BaseData-->StatisticalData;
ABC-->StatisticalData;
AnalogData-->TimelockData;
StatisticalData-->|+avg +var +cov +dof|TimelockData
SpectralData-->FreqDescriptivesData;
StatisticalData-->|+avg +var +cov +dof| FreqDescriptivesData;
StatisticalData-->|+chan1 +chan2| ConnectivityData;
ConnectivityData-->|+freq| SpectralConnectivityData;
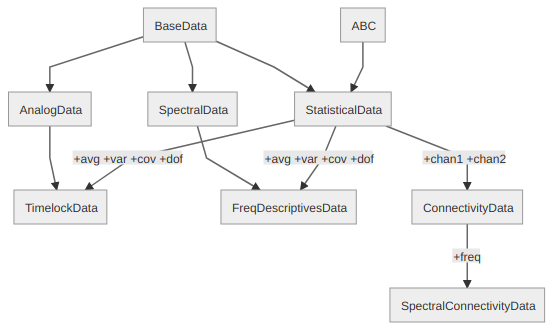
where StatisticalData is an (at the moment) empty abstract class. All other classes are instantiable and provide (at least) the following attributes (inheritance as indicated by above diagram):
TimelockData.avg
TimelockData.var
TimelockData.cov
TimelockData.dat
ConnectivityData.chan1
ConnectivityData.chan2
SpectralConnectivityData.freqMulti-process spawning for testing is currently broken on Windows
Is your feature request related to a problem? Please elaborate.
We currently theoretically support object creation using memory-mapped NumPy arrays. This functionality is (a) not working everywhere (spy.save may or may not crash w/memory maps) (b) barely tested and (c) results in lots and lots of if-else constructs (particularly in ComputationalRoutine and friends) to account for differences in HDF containers and memory maps. It seems questionable, whether memory-map support is a feature that is worth jumping through so many hoops at this point (also considering the terrible performance of memory maps w/GPFS).
Do you have a solution in mind? Please elaborate
We should remove memory map support from Syncopy entirely. If people really want to use memmaps, we can re-include support in a coordinated and clean manner later. At this point, we're sitting on lots of barely functional/untested legacy code.
@joschaschmiedt Any objections?
Do we want/need to archive Syncopy ("archive" as in "preserve a given snapshot of its source code for 10+ years even when git/GitHub may not be existing/relevant any more")? If yes, Software Heritage might be a good place to look into.
Is your feature request related to a problem? Please elaborate.
Currently, unwrap_cfg and consequently unwrap_select as well as detect_parallel_client assume that the decorated function only accepts a single Syncopy object (very creatively called data) as input object. This was a sane assumption so far, but overlay-plotting already needs to process multiple input objects (statistics and connectivity will very likely require this functionality too).
Do you have a solution in mind? Please elaborate
Extend unwrap_cfg to allow data to be a list of Syncopy objects. This way code modifications should be minimally invasive and backward compatible.
Describe the bug
After seven months of testing/running Syncopy, copy_trial is still completely unused. We should remove the routine and the corresponding tests to avoid any unintentional side-effects downstream.
A glossary for terms such as "metafunction", etc. might be useful. See
https://www.sphinx-doc.org/en/master/usage/restructuredtext/directives.html#glossary-directive
Is your feature request related to a problem? Please elaborate.
Our file headers, specifically the part
# Last modified by: Stefan Fuertinger [[email protected]]
# Last modification time: <2020-04-27 13:47:34>reliably trigger merge conflicts. Since Syncopy will most likely be installed in the site-packages directory of the respective Python installation/environment it is running in, these headers will very likely be invisible to most users anyway. We should consider removing the headers altogether, since git/GitHub provide this functionality anyway.
Do you have a solution in mind? Please elaborate
Remove headers from all files in package.
Prepare wavelet code to be compatible w/ComputationalRoutine.
Leverage new complex wavelets in SciPy v. 14.+
We might consider adding default community health files (e.g., CONTRIBUTING.md, SUPPORT.md etc.) to the root of a public repository called .github that is owned by the esi-neuroscience organization.
Inspired by ft_checkdata, it may be useful to have a checkdata method for all data classes, which checks whether all necessary properties are filled with sensible values, e.g. whether the avg, var, dof arrays of TimelockData have matching shapes.
Not really a problem per se, more like a missing feature? Please elaborate
Right now, we can't select single trials/channels/freqs etc. using their respective number or string label, i.e., to select the first trial of an AnalogData object, one has to use:
In [6]: spy.selectdata(data, trials=[0])
100% |██████████████████████████████████████| 1/1 [00:00<00:00]
Out[6]:
Syncopy AnalogData object with fields
cfg : dictionary with keys ''
channel : [560] element <class 'numpy.ndarray'>
container : None
data : 1 trials of length 1341.0 defined on [1341 x 560] float32 Dataset of size 2.86 MB
dimord : 2 element list
filename : /Users/pantaray/.spy/spy_0ebf_7589cb16.analog
mode : r+
sampleinfo : [1 x 2] element <class 'numpy.ndarray'>
samplerate : 1000.0
tag : None
time : 1 element list
trialinfo : [1 x 1] element <class 'numpy.ndarray'>
trials : 1 element iterable
Use `.log` to see object historywhile things like this explode:
In [4]: spy.selectdata(data, trials=0)
SyNCoPy encountered an error in
/Applications/anaconda/envs/syncopy/lib/python3.8/site-packages/IPython/core/interactiveshell.py, line 3331 in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
--------------------------------------------------------------------------------
Abbreviated traceback:
<ipython-input-4-5594eaf38e86>, line 1 in <module>
spy.selectdata(data, trials=0)
/Users/pantaray/Documents/job/SyNCoPy/Codes/syncopy-repo/syncopy/shared/kwarg_decorators.py, line 205 in wrapper_cfg
return func(data, *args, **kwords)
/Users/pantaray/Documents/job/SyNCoPy/Codes/syncopy-repo/syncopy/shared/kwarg_decorators.py, line 410 in parallel_client_detector
return func(data, *args, **kwargs)
/Users/pantaray/Documents/job/SyNCoPy/Codes/syncopy-repo/syncopy/datatype/methods/selectdata.py, line 261 in selectdata
data._selection = {"trials": trials,
/Users/pantaray/Documents/job/SyNCoPy/Codes/syncopy-repo/syncopy/datatype/base_data.py, line 445 in _selection
self._selector = Selector(self, select)
Use `import traceback; import sys; traceback.print_tb(sys.last_traceback)` for full error traceback.
SPYTypeError: Wrong type of select: trials: expected array_like found intSelecting single elements via one-component lists is not very intuitive - we should probably support scalar/string selections.
Describe the bug
We still have a lingering examples sub-package in Syncopy -the codes in there are at best very opaque and barely legible and at worst obsolete and broken. Since we started a separate syncopy-examples repository specifically intended to contain "Example analysis scripts and Jupyter notebooks illustrating how to use Syncopy for large-scale electrophysiology data processing" we should remove the barely functional examples sub-package from the main code repo.
We should decide how we want to normalize power:
We currently do not test in-place selection w/freqanalysis - this should be addressed w/one or two test-cases.
In general, we might want to consider cooking up a template for writing tests for Syncopy meta-functions to have all our analysis routines undergo standardized functional-/unit-/regression-testing.
syncopy.io.utils.startInfoDict into documentation<dataclass>_infoDictPropertiesIs your feature request related to a problem? Please elaborate.
The color of SPYWarning messages is too dim - make it more "orange-ish" so that warnings are better readable on both bright and dark backgrounds.
Describe the bug
Currently, it's possible to perform selections a la toi = [0, 10, 3, 5, 3, 3, 3, 3, 0, 0, 10, 15] which correctly re-shuffles and appends time-points. However, the resulting object's time property is completely (borderline catastrophically) wrong.
For situations like this, we could introduce a hidden _time attribute and extend the time property as follows:
@property
def time(self):
"""list(float): trigger-relative time axes of each trial """
if self._time is not None:
return self._time
if self.samplerate is not None and self.sampleinfo is not None:
return [(np.arange(0, stop - start) + self._t0[tk]) / self.samplerate \
for tk, (start, stop) in enumerate(self.sampleinfo)]
@time.setter
def time(timearr):
# Ensure consistency of input array
nSamples = self.trials[0].shape[self.dimord.index("time")]
try:
array_parser(timearr, varname="time", dimensions=(len(self.trials), nSamples),
hasinf=False, hasnan=False)
except Exception as exc:
raise exc
self._time = np.array(timearr)Note All trial-getters can stay as they are, since they rely on sampleinfo which (at least for trial-getting purposes) basically encodes the by-trial sample counts.
Note further This issue's significance has been promoted w/new time-frequency objects (that may very well originate from things like toi = [-0.1, 0.1, 0.3, 0.4])
Create a crontab job to pull our GitHub repo to GitLab.
For storing the output of timelockanalysis we need a subclass of StatisticalData. Fieldtrip's ft_timelockanalysis outputs the following shapes:
avgFIC =
struct with fields:
time: [1×900 double]
label: {149×1 cell}
elec: [1×1 struct]
grad: [1×1 struct]
avg: [149×900 double]
var: [149×900 double]
dof: [149×900 double]
dimord: 'chan_time'
cov: [149×149 double]
cfg: [1×1 struct]
the cov field is optional. With cfg.keeptrials = 'yes' the output looks like this:
avgFIC =
struct with fields:
time: [1×900 double]
label: {149×1 cell}
elec: [1×1 struct]
grad: [1×1 struct]
sampleinfo: [77×2 double]
trial: [77×149×900 double]
trialinfo: [77×1 double]
dimord: 'rpt_chan_time'
cov: [77×149×149 double]
cfg: [1×1 struct]
A convenience method for checking two Syncopy objects for equality would be quite useful. Ideally, we want something like
>>> obj1 = spy.AnalogData(...)
>>> obj2 = obj1.copy(deep=True)
>>> obj1 == obj2
TrueThe equality operator needs be smart enough to check for identical sample-rates, data hashes, trial info etc.
NEO can read a big variety of electrophysiology data formats into Python. We should consider support for NEO as a property set method of BaseData.
The lazy loading may also be interesting to look at.
More relevant: look into NWB support
Is your feature request related to a problem? Please elaborate.
Currently we're using GitLab CI hosted on ESI premises for testing, docs and deployment. We should consider using free alternatives on GitHub as well.
Do you have a solution in mind? Please elaborate
Windows support would be nice but is not a requirement. Popular candidates for evaluation are
See https://github.com/ligurio/awesome-ci for a comprehensive overview.
Not really a problem per se, more like a missing feature? Please elaborate
We need a method to convert a DiscreteData object into an AnalogData object (e.g., to perform spectral analysis on spikes/saccades). Implement a new function in datatype/data_methods.py
to_analog(samplerate=..., peak_value=1, dtype=float32, filename=None)where samplerate denotes the desired sample-rate of the constructed AnalogData object, peak_value means the "on"-value of events (e.g., construct a binary time-series of the form 00001000100) and filename can be optionally provided to circumvent creation of a tmp object and directly write to a user-defined location.
Explore what's the deal with padding trials when using dpss windowing functions.
We should standardize warning messages across Syncopy. Instead of each method printing its own variant of a warning, use a template instead.
Necessary for selectdata support (and potential concurrent processing capabilities).
cf #47 (review)
If I understand the code correctly the wrapper also supports multiple positional
dataarguments, i.e.result = func(cfg, data1, data2, data3)I did not see any documentation or tests for this use case. Is that right?
A bug preventing empty indexing arrays to be processed correctly by h5py triggered exceptions in ComputationalRoutine (specifically in compute_sequential but also in the unwrap_io decorator fueled by compute_parallel). A temporary workaround has been built in - as soon as h5py version 2.10 is available via conda this workaround should be removed.
As of this writing, no pre-built wheels of version 2.10 are available for linux in pip, thus requiring manual compilation of the 2.10-sources against an existing libhdf5.so + headers - which is really not worth the trouble just for directly handling empty indexing arrays (which themselves are most likely the product of erroneous data selections anyway...)
The bandwidth parameter of the dpss windows (NW) in mtmfft is not yet well defined. This should be clarified.
In Fieldtrip, the 'csd' is computed in the freqanalysis function. We should probably do the same.
Fieldtrip's ft_freqanalysis supports the computation of both power-spectra and cross-spectral densities with
cfg.output = 'powandcsd' % return the power and the cross-spectrawhich then requires
cfg.channelcmb = Mx2 cell-array with selection of channel pairs (default = {'all' 'all'}),
see FT_CHANNELCOMBINATION for details(see http://www.fieldtriptoolbox.org/reference/ft_freqanalysis/).
We should make decision on how we compute the cross-spectral densities necessary for spectral connectivity methods. See also #3
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.