-
🌱 I’m currently focusing on Mobile and Web Vulnerabilities Research
-
📝 I regularly write articles on My Blog
-
💬 Ask me about Hacking and Bug Hunting
-
📫 How to reach me: [email protected]
-
🔑 My GPG public key is:
56F7 1F31 9CC6 5DB7

ChatGPT in command line with OpenAI API (gpt-3.5-turbo/gpt-4/gpt-4-32k)
Home Page: https://platform.openai.com/docs/introduction
License: GNU General Public License v2.0
🌱 I’m currently focusing on Mobile and Web Vulnerabilities Research
📝 I regularly write articles on My Blog
💬 Ask me about Hacking and Bug Hunting
📫 How to reach me: [email protected]
🔑 My GPG public key is: 56F7 1F31 9CC6 5DB7













































































































输入python gptcli.py -p https://gpt.pawan.krd/backend-api/conversation,报错:
(chatgpt) G:\[Notes]\chatgpt-demo\gptcli>python gptcli.py -p https://gpt.pawan.krd/backend-api/conversation
Loading key from G:[Notes]\chatgpt-demo\gptcli\.key
Using proxy: https://gpt.pawan.krd/backend-api/conversation
Attach response in prompt: False
Stream mode: True
�[1;33mInput:�[0m hello?
C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\connector.py:899: RuntimeWarning: An HTTPS request is being
sent through an HTTPS proxy. This support for TLS in TLS is known to be disabled in the stdlib asyncio. This is why
you'll probably see an error in the log below.
It is possible to enable it via monkeypatching under Python 3.7 or higher. For more details, see:
* https://bugs.python.org/issue37179
* https://github.com/python/cpython/pull/28073
You can temporarily patch this as follows:
* https://docs.aiohttp.org/en/stable/client_advanced.html#proxy-support
* https://github.com/aio-libs/aiohttp/discussions/6044
_, proto = await self._create_proxy_connection(req, traces, timeout)
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
Traceback (most recent call last):
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\openai\api_requestor.py", line 587, in arequest_raw
result = await session.request(**request_kwargs)
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\client.py", line 536, in _request
conn = await self._connector.connect(
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\connector.py", line 540, in connect
proto = await self._create_connection(req, traces, timeout)
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\connector.py", line 899, in _create_connection
_, proto = await self._create_proxy_connection(req, traces, timeout)
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\connector.py", line 1288, in _create_proxy_connection
raise ClientHttpProxyError(
aiohttp.client_exceptions.ClientHttpProxyError: 400, message='Bad Request', url=URL('https://gpt.pawan.krd/backend-api/conversation')
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "G:\[Notes]\chatgpt-demo\gptcli\gptcli.py", line 161, in <module>
answer = asyncio.run(query_openai_stream(data))
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\runners.py", line 44, in run
return loop.run_until_complete(main)
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\base_events.py", line 641, in run_until_complete
return future.result()
File "G:\[Notes]\chatgpt-demo\gptcli\gptcli.py", line 52, in query_openai_stream
async for part in await openai.ChatCompletion.acreate(
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\openai\api_resources\chat_completion.py", line 45, in acreate
return await super().acreate(*args, **kwargs)
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\openai\api_resources\abstract\engine_api_resource.py", line 217, in acreate
response, _, api_key = await requestor.arequest(
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\openai\api_requestor.py", line 300, in arequest
result = await self.arequest_raw(
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\openai\api_requestor.py", line 604, in arequest_raw
raise error.APIConnectionError("Error communicating with OpenAI") from e
openai.error.APIConnectionError: Error communicating with OpenAI
Exception ignored in: <function _ProactorBasePipeTransport.__del__ at 0x000002AC05F29A20>
Traceback (most recent call last):
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\proactor_events.py", line 116, in __del__
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\proactor_events.py", line 108, in close
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\base_events.py", line 745, in call_soon
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\base_events.py", line 510, in _check_closed
RuntimeError: Event loop is closed
(chatgpt) G:\[Notes]\chatgpt-demo\gptcli>输入python gptcli.py -r,报错:
(chatgpt) G:\[Notes]\chatgpt-demo\gptcli>python gptcli.py -r
Loading key from G:[Notes]\chatgpt-demo\gptcli\.key
Attach response in prompt: True
Stream mode: True
�[1;33mInput:�[0m
�[1;33mInput:�[0m Hello?
Traceback (most recent call last):
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\connector.py", line 980, in _wrap_create_connection
return await self._loop.create_connection(*args, **kwargs) # type: ignore[return-value] # noqa
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\base_events.py", line 1055, in create_connection
raise exceptions[0]
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\base_events.py", line 1040, in create_connection
sock = await self._connect_sock(
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\base_events.py", line 954, in _connect_sock
await self.sock_connect(sock, address)
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\proactor_events.py", line 704, in sock_connect
return await self._proactor.connect(sock, address)
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\windows_events.py", line 812, in _poll
value = callback(transferred, key, ov)
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\windows_events.py", line 599, in finish_connect
ov.getresult()
OSError: [WinError 121] 信号灯超时时间已到
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\openai\api_requestor.py", line 587, in arequest_raw
result = await session.request(**request_kwargs)
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\client.py", line 536, in _request
conn = await self._connector.connect(
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\connector.py", line 540, in connect
proto = await self._create_connection(req, traces, timeout)
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\connector.py", line 901, in _create_connection
_, proto = await self._create_direct_connection(req, traces, timeout)
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\connector.py", line 1206, in _create_direct_connection
raise last_exc
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\connector.py", line 1175, in _create_direct_connection
transp, proto = await self._wrap_create_connection(
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\aiohttp\connector.py", line 988, in _wrap_create_connection
raise client_error(req.connection_key, exc) from exc
aiohttp.client_exceptions.ClientConnectorError: Cannot connect to host api.openai.com:443 ssl:default [信号灯超时时间已 到]
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "G:\[Notes]\chatgpt-demo\gptcli\gptcli.py", line 161, in <module>
answer = asyncio.run(query_openai_stream(data))
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\runners.py", line 44, in run
return loop.run_until_complete(main)
File "C:\Users\li\.conda\envs\chatgpt\lib\asyncio\base_events.py", line 641, in run_until_complete
return future.result()
File "G:\[Notes]\chatgpt-demo\gptcli\gptcli.py", line 52, in query_openai_stream
async for part in await openai.ChatCompletion.acreate(
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\openai\api_resources\chat_completion.py", line 45, in acreate
return await super().acreate(*args, **kwargs)
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\openai\api_resources\abstract\engine_api_resource.py", line 217, in acreate
response, _, api_key = await requestor.arequest(
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\openai\api_requestor.py", line 300, in arequest
result = await self.arequest_raw(
File "C:\Users\li\.conda\envs\chatgpt\lib\site-packages\openai\api_requestor.py", line 604, in arequest_raw
raise error.APIConnectionError("Error communicating with OpenAI") from e
openai.error.APIConnectionError: Error communicating with OpenAI难不成要挂代理才能用?😂
A low priority idea.
There is a slight delay between the use of tokens and when it shows up on the usage page: https://platform.openai.com/account/usage
It would be good to know the tokens required to send a query and/or the tokens used for a query.
Some ideas:
OpenAI do provide some information on the way token usage should be estimated, or can be called from the API:
https://platform.openai.com/docs/guides/chat/introduction#:~:text=it%27s%20more%20difficult%20to%20count%20how%20many%20tokens
Can't immediately see pricing information via the API, however they are published here: https://openai.com/pricing
I made absolutely sure my local directory was updated to the latest version. I have GPT Pro, and it works fine with gpt-3.5-turbo, but when the config is set to gpt-4 or gpt-4-32k, it says the model does not exist.


Hi!
Is it possible to save the current conversation session to some file using logging or f.write? That would be cool, that's what's missing in chat.openai.com
something like
filename = (date)+generate_random_string(10)
with open(f"{filename}.txt", "w") as f:
while true:
f.write(prompt)
f.write(message)

refer document:
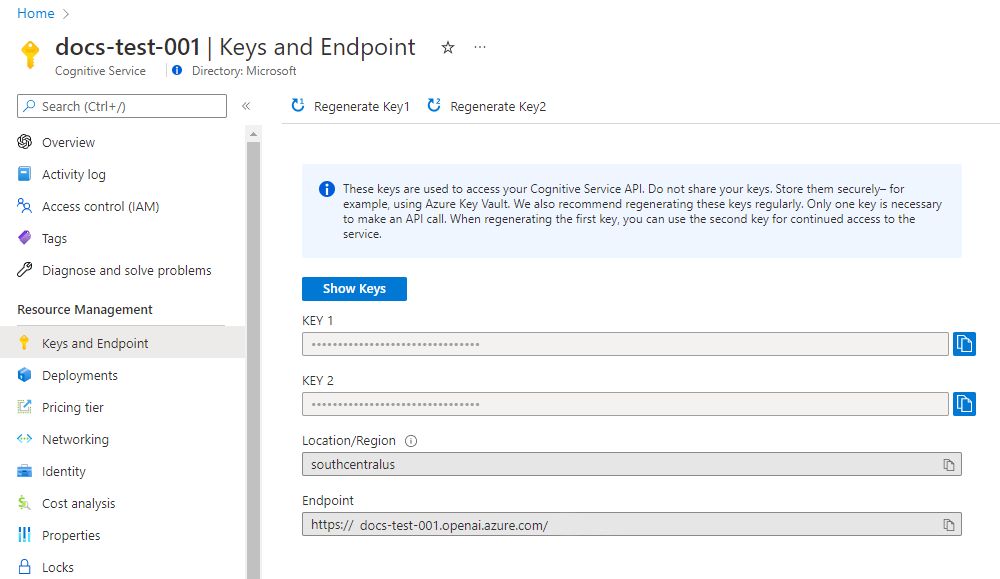
ENDPOINT and API-KEY| Variable name | Value |
|---|---|
| ENDPOINT | This value can be found in the Keys & Endpoint section when examining your resource from the Azure portal. Alternatively, you can find the value in the Azure AI Studio > Playground > Code View. An example endpoint is: https://docs-test-001.openai.azure.com/. |
| API-KEY | This value can be found in the Keys & Endpoint section when examining your resource from the Azure portal. You can use either KEY1 or KEY2. |
#Note: The openai-python library support for Azure OpenAI is in preview.
import os
import openai
openai.api_type = "azure"
openai.api_base = os.getenv("AZURE_OPENAI_ENDPOINT")
openai.api_version = "2023-05-15"
openai.api_key = os.getenv("AZURE_OPENAI_KEY")
response = openai.ChatCompletion.create(
engine="gpt-35-turbo", # engine = "deployment_name".
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure Cognitive Services support this too?"}
]
)
print(response)
print(response['choices'][0]['message']['content'])
系统:macOS
电脑:MacBookair M1芯片
在M2 macmini上也会出现这样的情况:

缺少pysocks依赖,少个依赖就不提pr了,安装依赖后解决报错。

Hello, 我是windows 10, python 3.7.8.
Traceback (most recent call last):
File "gptcli.py", line 10, in
from rich.markdown import Markdown, MarkdownIt
ImportError: cannot import name 'MarkdownIt' from 'rich.markdown'
When presenting ChatGPT a piece of code to refactor it, GPT answers back the refactored code inside a black colored block. It looks fine but If i were to copy the code and paste it in a text editor or IDE, it will look something like this:
if __name__ ==
"__main__":
main()
Not only it breaks it down in three rows when it should be only one two but also it will be filled with blank spaces everywhere. Editing/cleaning it takes a lot of time.
EDIT:
Using Gnome terminal version 0.54.2 +GNUTLS

环境:mac
终端:iterm2, zsh
I have trouble installing gptcli because the pyreadline3 dependency gives me error, since in my environment I’m not allowed to compile binaries.
Can you make the pyreadline3 lib optional, or replace it with a pure python lib?
Thanks
比如我想问一段代码的含义,中间包含了几个回车,当前的程序检测到一次回车就会当做一个问题进行询问。

I am trying to run gptcli on windows 11.
Here is the error I am facing
(venv) PS D:\experiments\gptcli-main\gptcli-main> python .\gptcli.py -c .\config.json
Loading config from: .\config.json
openai.api_key=sk-mEkw*****
openai.api_base=https://chat.pppan.net/v1
openai.api_type=open_ai
openai.api_version=None
openai.api_organization=None
Proxy: socks5://localhost:1080
Context level: ContextLevel.FULL
Stream mode: True
gptcli> hello
Traceback (most recent call last):
File "D:\experiments\gptcli-main\gptcli-main\gptcli.py", line 252, in query_openai_stream
response = openai.ChatCompletion.create(
File "D:\experiments\gptcli-main\gptcli-main\venv\lib\site-packages\openai\lib\_old_api.py", line 39, in __call__
raise APIRemovedInV1(symbol=self._symbol)
openai.lib._old_api.APIRemovedInV1:
You tried to access openai.ChatCompletion, but this is no longer supported in openai>=1.0.0 - see the README at https://github.com/openai/openai-python for the API.
You can run `openai migrate` to automatically upgrade your codebase to use the 1.0.0 interface.
Alternatively, you can pin your installation to the old version, e.g. `pip install openai==0.28`
A detailed migration guide is available here: https://github.com/openai/openai-python/discussions/742
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\experiments\gptcli-main\gptcli-main\gptcli.py", line 420, in <module>
main()
File "D:\experiments\gptcli-main\gptcli-main\gptcli.py", line 417, in main
app.cmdloop()
File "D:\experiments\gptcli-main\gptcli-main\venv\lib\site-packages\cmd2\cmd2.py", line 5285, in cmdloop
self._cmdloop()
File "D:\experiments\gptcli-main\gptcli-main\venv\lib\site-packages\cmd2\cmd2.py", line 3142, in _cmdloop
stop = self.onecmd_plus_hooks(line)
File "D:\experiments\gptcli-main\gptcli-main\gptcli.py", line 131, in onecmd_plus_hooks
self.handle_input(line)
File "D:\experiments\gptcli-main\gptcli-main\gptcli.py", line 163, in handle_input
answer = self.query_openai_stream(self.messages)
File "D:\experiments\gptcli-main\gptcli-main\gptcli.py", line 272, in query_openai_stream
except openai.error.OpenAIError as e:
AttributeError: module 'openai' has no attribute 'error'
Let me know if any more information is required from my side.
Base gptcli. ChatGPT UI in window & mac with open api (gpt-3.5/gpt-4) and generate chat files. https://github.com/xhunmon/GPT-UI.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.