This is a GitHub Action originally built to overcome the 14-day limitation of GitHub's built-in traffic statistics.
Run this daily to collect potentially valuable data.
According to the motto: a data snapshot each day keeps the doctor away 🍎
See this Action in Marketplace.
High-level method description:
- This GitHub Action runs once per day. Each run yields a snapshot of repository traffic statistics (influenced by the past 14 days). Snapshots are persisted via git.
- Each run performs data analysis on all individual snapshots and generates a report from the aggregate — covering an arbitrarily long time frame.
Looking for a quick start? Follow the simple tutorial in the Wiki.
Demo 1:
Demo 2:
For more use cases (and their setup), see "Used by" section below.
- The report is generated in two document formats: HTML and PDF.
- The HTML report resembles how GitHub renders Markdown and is meant to be exposed via GitHub pages.
- Charts are based on Altair/Vega.
- The PDF report contains vector graphics.
- Data updates, aggregation results, and report files are stored in the git repository that you install this Action in: this Action commits changes to a special branch. No cloud storage or database needed. As a result, you have complete and transparent history for data updates and reports, with clear commit messages, in a single place.
- The observed repository (the one to build the report for) can be different from the repository you install this Action in.
- The HTML report can be served right away via GitHub pages (that is how the demo above works).
- Careful data analysis: there are a number of traps (example) when aggregating data based on what the GitHub Traffic API returns. This project tries to not fall for them. One goal of this project is to perform advanced analysis where possible.
- Traffic stats:
- Unique and total views per day
- Unique and total clones per day
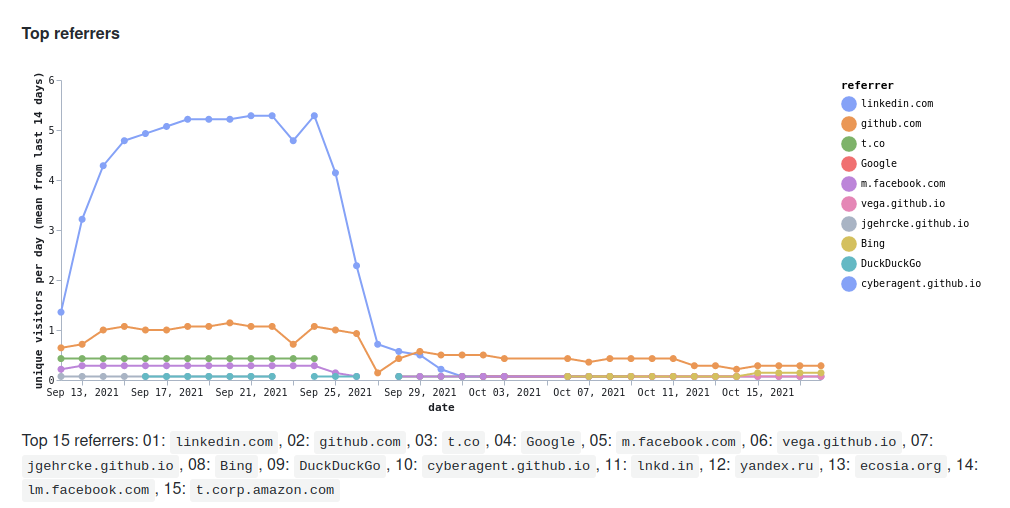
- Top referrers (where people come from when they land in your repository)
- Top paths (what people like to look at in your repository)
- Evolution of stargazers
- Evolution of forks
This walks on the shoulders of giants:
- Pandoc for rendering HTML from Markdown.
- Altair and Vega-Lite for visualization.
- Pandas for data analysis.
- The CPython ecosystem which has always been fun for me to build software in.
Naming is hard :-). Let's define two concepts and their names:
- The stats repository is the repository to fetch stats for and to generate the report for.
- The data repository is the repository to store data and report files in. This is also the repository where this Action runs in.
Let me know if you can think of better names.
These two repositories can be the same. But they don't have to be :-).
That is, you can for example set up this Action in a private repository but have it observe a public repository.
This section contains brief instructions for a scenario where the data repository is different from the stats repository.
For a more detailed walkthrough (showing how to greate a personal access token, and also which git commands to use) please follow the Tutorial in the wiki.
Example scenario:
- stats repository:
bob/nice-project - data repository:
bob/private-ghrs-data-repo
Create a GitHub Actions workflow file in the data repository (in the example this is the repo bob/private-ghrs-data-repo). Example path: .github/workflows/repostats-for-nice-project.yml.
Example workflow file content with code comments:
on:
schedule:
# Run this once per day, towards the end of the day for keeping the most
# recent data point most meaningful (hours are interpreted in UTC).
- cron: "0 23 * * *"
workflow_dispatch: # Allow for running this manually.
jobs:
j1:
name: repostats-for-nice-project
runs-on: ubuntu-latest
steps:
- name: run-ghrs
uses: jgehrcke/github-repo-stats@RELEASE
with:
# Define the stats repository (the repo to fetch
# stats for and to generate the report for).
# Remove the parameter when the stats repository
# and the data repository are the same.
repository: bob/nice-project
# Set a GitHub API token that can read the GitHub
# repository traffic API for the stats repository,
# and that can push commits to the data repository
# (which this workflow file lives in, to store data
# and the report files).
ghtoken: ${{ secrets.ghrs_github_api_token }}
Note: the recommended way to run this Action is on a schedule, once per day. Really.
Note: defining ghtoken: ${{ secrets.ghrs_github_api_token }} is required. In the data repository (where the action is executed) you need to have a secret defined, with the name GHRS_GITHUB_API_TOKEN (of course you can change the name in both places).
The content of the secret needs to be an API token that has the repo scope. Follow the tutorial for precise instructions.
In the workflow file you can set various configuration parameters. They
are specified and documented in the action.yml file (the reference). Here
is a quick description, for convenience:
ghtoken: GitHub API token for reading the GitHub repository traffic API for the stats repo, and for pushing commits to the data repo. Required.repository: Repository spec (<owner-or-org>/<reponame>) for the repository to fetch statistics for. Default:${{ github.repository }}(the repo this Action runs in).databranch: Branch to push data to (in the data repo). Default:github-repo-statsghpagesprefix: Set this if the data branch in the data repo is exposed via GitHub pages. Must not end with a slash. Example:https://jgehrcke.github.io/ghrs-testDefault: none
It is recommended that you create the data branch and delete all files from that branch before setting this Action up in your repository, so that this data branch appears as a tidy environment. You can of course remove files from that branch at any other point in time, too.
The GitHub Actions workflow specification language allows for defining a matrix of different job configurations through the jobs.<job_id>.strategy.matrix directive.
This can be used for efficiently tracking multiple stats repositories from within the same data repository.
Example workflow file:
name: fetch-repository-stats
concurrency: fetch-repository-stats
on:
schedule:
- cron: "0 23 * * *"
workflow_dispatch:
jobs:
run-ghrs-with-matrix:
name: repostats-for-nice-projects
runs-on: ubuntu-latest
strategy:
matrix:
# The repositories to generate reports for.
statsRepo: ['bob/nice-project', 'alice/also-nice-project']
# Do not cancel&fail all remaining jobs upon first job failure.
fail-fast: false
# Help avoid commit conflicts. Note(JP): this should not be
# necessary anymore, feedback appreciated
max-parallel: 1
steps:
- name: run-ghrs
uses: jgehrcke/github-repo-stats@RELEASE
with:
repository: ${{ matrix.statsRepo }}
ghtoken: ${{ secrets.ghrs_github_api_token }}Here is how to run bats-based checks from within a checkout:
$ git clone https://github.com/jgehrcke/github-repo-stats
$ cd github-repo-stats/
$ make clitests
...
1..5
ok 1 analyze.py: snapshots: some, vcagg: yes, stars: some, forks: none
ok 2 analyze.py: snapshots: some, vcagg: yes, stars: none, forks: some
ok 3 analyze.py: snapshots: some, vcagg: yes, stars: some, forks: some
ok 4 analyze.py: snapshots: some, vcagg: no, stars: some, forks: some
ok 5 analyze.py + pdf.py: snapshots: some, vcagg: no, stars: some, forks: some$ make lint
...
All done! ✨ 🍰 ✨
...Set environment variables, example:
export GITHUB_REPOSITORY=jgehrcke/ghrs-test
export GITHUB_WORKFLOW="localtesting"
export INPUT_DATABRANCH=databranch-test
export INPUT_GHTOKEN="c***1"
export INPUT_REPOSITORY=jgehrcke/covid-19-germany-gae
export INPUT_GHPAGESPREFIX="none"
export GHRS_FILES_ROOT_PATH="/home/jp/dev/github-repo-stats"
export GHRS_TESTING="true"(for an up-to-date list of required env vars see .github/workflows/prs.yml)
Run in empty directory. Example:
cd /tmp/ghrstest
rm -rf .* *; bash /home/jp/dev/github-repo-stats/entrypoint.shA few rather randomly picked use cases:
- https://github.com/idurar/erp-crm/tree/github-repo-stats/idurar/idurar-erp-crm
- https://github.com/awslabs/aws-security-analytics-bootstrap/tree/github-repo-stats/awslabs/aws-security-analytics-bootstrap
- https://github.com/centerofci/mathesar/tree/github-repo-stats/centerofci/mathesar
- https://github.com/carbon-design-system/carbon/tree/github-repo-stats/carbon-design-system/carbon
- https://github.com/Pythagora-io/pythagora/tree/github-repo-stats/Pythagora-io/pythagora
- https://github.com/ignite-hq/cli/tree/github-repo-stats/ignite-hq/cli
- https://github.com/tom-doerr/github_repo_stats_data/tree/master/tom-doerr
- https://github.com/ethyca/fides-stats/tree/main/ethyca/fides
- https://github.com/dylansdaniels/hnn_tracking_test/tree/main/jonescompneurolab/hnn
- https://github.com/idaholab/repository-statistics/tree/main/idaholab
- https://github.com/Declipsonator/Tweaks-Stats/tree/main/Declipsonator/Meteor-Tweaks