整理平时个人的一些观点、想法💡。具体见 issues
jiacai2050 / ideas Goto Github PK
View Code? Open in Web Editor NEWThink more
Home Page: https://github.com/jiacai2050/ideas/issues
Think more
Home Page: https://github.com/jiacai2050/ideas/issues
整理平时个人的一些观点、想法💡。具体见 issues
































job.waitForCompletion()
job.submit()
jobSubmitter.submitJobInternal(job, cluster)
submitJobInternal() 做了五件事:
splitSize = computeSplitSize(blockSize, minSize, maxSize);
computeSplitSize = Max(minSize, Min(maxSize, blockSize))
mapreduce.input.fileinputformat.split.maxsize 默认 Long.MAX
mapreduce.input.fileinputformat.split.minsize 默认 1
blockSize 默认 128
mapreduce.job.dir 等于 job staging dir + job_id
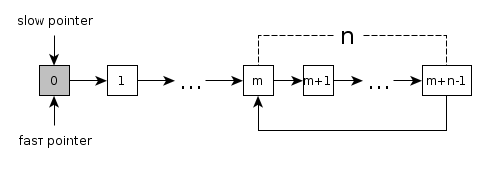
在解决图相关的问题时, 如果能够把点与点、边与边之间的关系的拓扑图画出来,对解决问题往往有很大的帮助。
效果和这个类似:
参考资料:
map, filter 这两个函数的功能是 reduce 函数功能的子集,为什么大多数 fp 里面还要多这两个函数。
下面举个例子,reduce能到,但是map做不到的(这也就证明了reduce 比 map 功能强大)
对一个只包含数字list,要求只对该list遍历一次,返回两个list,一个只包含偶数,一个只包含奇数:
Clojure 代码
(reduce
(fn [l i]
(if (= 0 (rem i 2))
(list
(cons i (first l))
(first (rest l)))
(list
(first l)
(cons i (first (rest l))))))
'(() ())
(range 0 10))
结果
((8 6 4 2 0) (9 7 5 3 1))
map 没法一次做到

https://www.j3e.de/linux/convmv/man/
http://superuser.com/questions/239810/setting-utf8-as-default-character-encoding-in-windows-7
https://msdn.microsoft.com/en-us/library/windows/desktop/dd317748(v=vs.85).aspx
http://www.zhihu.com/question/25253698
http://unicodebook.readthedocs.org/en/latest/operating_systems.html
https://en.wikipedia.org/wiki/Filename
https://docs.oracle.com/javase/8/docs/technotes/guides/intl/encoding.doc.html
http://www.programmershare.com/3062349/
https://support.apple.com/kb/DL355?viewlocale=en_US&locale=en_US
设计一个最优算法来查找一n个元素数组中的最大值和最小值,已知一种需要比较2n次的方法,请给一个更优的算法。请特别注意优化时间复杂度的常数。给出该算法最坏情况下的比较次数和该算法的步骤描述。(不用写代码,不给出比较次数的不得分)
http://stackoverflow.com/a/20558123/2163429
This is a question I had during an interview and I found the answer with a small hint from the interviewer which was "How do you compare two numbers?" (it really helped).
Here is the explanation:
Lets say I have 100 numbers (you can easily replace it by n but it work better for the example if n is an even number). What I do is that I split it into 50 lists of 2 numbers. For each couple I make one comparison and I'm done (which makes 50 comparisons by now) then I just have to find the minimum of the minimums (which is 49 comparisons) and the maximum of the maximums (which is 49 comparisons as well) such that we have to make 49+49+50=148 comparisons. We're done !
Remark: to find the minimum we proceed as follow (in pseudo code):
n=myList.size();
min=myList[0];
for (int i(1);i<n-1;i++)
{
if (min>myList[i]) min=myList[i];
}
return min;
And we find it in (n-1) comparisons. The code is almost the same for maximum.
(define (f return)
(return 2)
3)
(display (f (lambda (x) x))) ; displays 3
(display (call-with-current-continuation f)) ; displays 2
Reading from a disk is very slow compared to accessing (real) memory. In addition, it is common to read the same part of a disk several times during relatively short periods of time. For example, one might first read an e-mail message, then read the letter into an editor when replying to it, then make the mail program read it again when copying it to a folder. Or, consider how often the command ls might be run on a system with many users. By reading the information from disk only once and then keeping it in memory until no longer needed, one can speed up all but the first read. This is called disk buffering, and the memory used for the purpose is called the buffer cache.
Since memory is, unfortunately, a finite, nay, scarce resource, the buffer cache usually cannot be big enough (it can't hold all the data one ever wants to use). When the cache fills up, the data that has been unused for the longest time is discarded and the memory thus freed is used for the new data.
Disk buffering works for writes as well. On the one hand, data that is written is often soon read again (e.g., a source code file is saved to a file, then read by the compiler), so putting data that is written in the cache is a good idea. On the other hand, by only putting the data into the cache, not writing it to disk at once, the program that writes runs quicker. The writes can then be done in the background, without slowing down the other programs.
Most operating systems have buffer caches (although they might be called something else), but not all of them work according to the above principles. Some are write-through: the data is written to disk at once (it is kept in the cache as well, of course). The cache is called write-back if the writes are done at a later time. Write-back is more efficient than write-through, but also a bit more prone to errors: if the machine crashes, or the power is cut at a bad moment, or the floppy is removed from the disk drive before the data in the cache waiting to be written gets written, the changes in the cache are usually lost. This might even mean that the filesystem (if there is one) is not in full working order, perhaps because the unwritten data held important changes to the bookkeeping information.
Because of this, you should never turn off the power without using a proper shutdown procedure or remove a floppy from the disk drive until it has been unmounted (if it was mounted) or after whatever program is using it has signaled that it is finished and the floppy drive light doesn't shine anymore. The sync command flushes the buffer, i.e., forces all unwritten data to be written to disk, and can be used when one wants to be sure that everything is safely written. In traditional UNIX systems, there is a program called update running in the background which does a sync every 30 seconds, so it is usually not necessary to use sync. Linux has an additional daemon, bdflush, which does a more imperfect sync more frequently to avoid the sudden freeze due to heavy disk I/O that sync sometimes causes.
参考:
参考问题:
自己博客的总结:
The first bit of advice
When specifying a collection of data, use abstract class for datatypes, and extended classes for variants.
public abstract class NumD {
@Override
public String toString() {
return "new " + getClass().getName() + "()";
}
}
public class Zero extends NumD {}
public class OneMoreThan extends NumD {
private NumD preprocessor;
public OneMoreThan(NumD preprocessor) {
this.preprocessor = preprocessor;
}
@Override
public String toString() {
return "new " + getClass().getName() + "(" + preprocessor + ")";
}
}
虽然现在网络上有很多不如人意的地方,但好的方面更多,比如总有网友能发现不同的内幕,从而可以引发更深入的思考。
比如就在前两天,又有网友发现了前苏联在芯片方面落败的内幕了。
历史已经证明,在芯片方面,前苏联完败于美国,由此网友提出这样一个问题。
沿着这个问题,网友开始寻根问底了。
其实说起来,在芯片方面,前苏联的起步优势比美国要大。
前苏联之所以有起步优势,是因为有美英等国科学家的帮助。
结果前苏联搞出的第一台电脑比美国要强多了。
但在关键的一着棋上,前苏联走岔了,他们着力于军用,而没有考虑民用。
更何况,还有赫氏的指示。
这个决定在前苏联的科研人员中,有广泛的支持者基础。
而前苏联的科研人员是有私心的。
明知道前方是死胡同,也只能先顾眼下。
在这一点上,其实美国当初也遇到了这样的问题,但他们避开了。
美国的芯片科研界必须为市场和普通消费者服务。
于是美国人们最先拥有了晶体管收音机。
一年就卖了十万台。
这样一来,晶体管的研究算是在美国站稳脚根,并且站上风口了。
于是就因为这一步,美国在芯片方面开始慢慢与前苏联拉开距离了。
不过前苏联的科研人员也不在乎这个,因为发工资的人不同。
事实上,前苏联方面也不是没有能人,比如勃氏。
心意是好的,但没想到事与愿违。
由此前苏联的芯片科研人员走上了一条歪门邪道的路。
甚至出现了这样荒唐的事情。
而且前苏联的芯片行业存在一个致命的问题,这个问题还是无解的。
美国的芯片是有着足够应用场景的,而苏联缺乏这方面的条件,因为消费能力不足。
于是前苏联又走上了另一条路。
这样一来,就出现了这样一个黑色幽默。
当然,前苏联科研人员也不是没想过办法,比如三进制电脑。
可是研发出来后,没人用,于是最后也只能束之高阁。
说到底,造成这一切的差别就是市场,美国有这个,而前苏联没有这个。
是否有市场,这个差别就太大了,比大多数人想象的还要大。
而在是否尊重市场这个问题上,背后还是那个根本性问题:是否尊重人的本身需求。
只有消费者能自由选择了,市场才是有活力的。
研究者才能自由的去思考,才能有更多的创新思维。
技术才能更快被催熟,因为大多数人的需要,就是最强劲的动力。
这才是一个社会一个时代最正确的方向。
顺其自然,不去强求,尊重人们本身的需求,那一切技术都是大有可为的。
我相信,前苏联在芯片方面的落败历史,应该能给现在的我们一切启发,从而让我们可以少走一些弯路,也少做一些无用功。
毕竟芯片是很耗钱的事,能够尊重客观规律,能够少交一些学费,都是对历史对后人的最好交待。
以上就是我今天的一些思考,与朋友们分享一下。
https://syntopikon.substack.com/p/an-interview-with-mickey-petersen
An interview with Mickey Petersen, author of Mastering Emacs
Who are you, and what do you do?
I'm Mickey Petersen. I live in London, UK.
I'm a professional software developer, and I have been programming since I was around 10 years old. I did not have friends or family who knew much about computing, so I had to learn everything myself, from scratch.
How did you get interested in that in the first place?
I cut my teeth programming C in Turbo C for DOS and moved on to Delphi for Windows some years later, whilst at the same time trying to get a grip on this fairly new-fangled thing called Linux. Back then you had to go through all manner of hoops to even get it: I think I got mine from a CD that a friend of a family member had. It would've been far too large for my meagre 33.6k dialup modem connection to even attempt to download it from the web.
It was a Red Hat distro and I distinctly remember spending an eternity printing out the manual – as I would otherwise not be able to even *install* Linux, as I knew nothing about it – and then a long time figuring out how to install and use it. FVWM95 was the window manager, meant to look like Windows 95, and it was a great experience "running Linux" and using tools that would never work on DOS or Windows at the time. Back then Linux was the 'cool' thing and Windows and DOS.... not so much!
I tried programming C on Linux, and I remember trying Emacs back then. It had this funky green colour scheme; pretty sure it was a Red Hat X Resources thing at the time. But I could be wrong. Nevertheless, my flirtation with Emacs did not last. At the time it was just another tool in a succession of editors I experimented with. I probably settled on a graphical one that shipped with Red Hat as it had, you know, things like region selection and syntax highlighting enabled by default. Emacs could of course *do* both, but they weren't enabled by default back then.
Along the way I experimented with all manner of packages, window managers, and more. They took ages to compile, but back then – as a kid/teen – you had oodles of time, so it didn't really matter. But it laid the foundation for my interest in Linux and much more.
Many years later I would, during my time in uni, pick up Emacs. That time it stuck. I was a member of my university's computer science society, and the Dewey decimal tribunes who held court and sway in that society, were keen to let all and sundry know that Real Hackers Used Vim. Not Emacs; not ed(1), kate, or any other editor; just Vim. I never did buy into groupthink – and certainly not from someone scarcely older than myself – so I went with Emacs, as I'd at least played around with it many years before.
At the time I did not really know what you could, or could not, do with Emacs. I mostly navigated with arrow keys, a handful of key bindings, and the menu bar. I went with XEmacs, as it was generally ahead of GNU Emacs in the early noughties. As my coursework in uni involved a never-ending succession of LaTeX and various common and obscure programming languages, Emacs was a great choice. It had syntax highlighting for almost any language you could think of, and although I did not know about some of the more obvious features (comint, shells, etc.) I at least had a tool capable of running on all major platforms and with a consistent experience.
XEmacs had its downsides, though. It was falling behind and had its own way of doing things that was not entirely compatible with GNU Emacs. I eventually moved to GNU Emacs when, I think, Emacs 22 came out.
At some point during my time with Emacs back then, a light bulb went on in my mind – something that I know now, having written and taught people Emacs for many years, is a frequent occurrence – that I finally understood enough about Emacs to not feel lost. I could look up commands and keys; install and edit code; and even write some elisp!
I'd begun experimenting with Org mode, so I started a file called blogideas.org (blogs were all the rage back then!) to capture all the things I knew and I wish others did too. That would then morph into Mastering Emacs.
Since graduating uni, I've been a professional developer. I build bespoke software for clients around the world — with Emacs as my trusty editor, of course!
What resources would you recommend for people that are interested in what you do?
For programming? Gosh, there's too much. Back in the day it was actually really hard to learn programming as you'd need books, the web/internet, or know someone who knows a bit about it. Today, it's infinitely easier to get started — though I think it's equally hard sticking to it, and becoming proficient!
I found your work through Mastering Emacs, a phenomenal site – and book (written in Emacs, of course) – that helped me design my Emacs workflow (more so as a writer than a developer). Emacs can be intimidating for first-time users. Why should they choose it over another text editor?
Thank you! I'm glad you like both. That was exactly why I started the site.
Well, you're a writer using Emacs, and I think that is interesting.
I firmly believe that a significant proportion of Mastering Emacs readers are not professional "techies" (be it system administrators, developers, testers, etc.) but either tech-adjacent or work in fields where they are expected to have some technical proficiency in their field – a dab of Fortran or Python here, a pinch of LaTeX there – and use Emacs primarily as a tool to connect disparate areas of their work that other, non-Emacs users cannot easily mimic. Editing code is easy; there's myriad editors, including Emacs of course, that can do this. But there aren't many tools to track bibliography, your agenda, email, notes, and writing. But Emacs can easily do all of that, and much more.
Some Emacs users learn it because it's a "tax" they have to pay to work in certain academic circles or commercial environments where it's the only one available, or widely used. Something my cohort in University discovered when our lecturers would hand-wave away questions like "What should we use for editing Prolog?" with "Emacs."
So I think that people should learn Emacs if they want greater control – or freedom (also in the FOSS sense) – to mould their environment and tools to their liking. Not everyone does; if you dislike tinkering and tweaking, then Emacs is harder to sell. But to those of us who have had to use an application only to find that its keyboard shortcuts get in the way (or are missing altogether); or that one key that you use that does not work in some modal dialogues; or the frustration when you have to multi-task between umpteen tools – we find comfort in Emacs, because we are imbued with a tool capable of adapting itself to our needs. Emacs is a crucible.
What are some areas where Emacs could improve, either for longtime users or for newcomers?
Hm, this is a good question.
Emacs is written and designed for people who already know Emacs. That's not so great if you don't know Emacs; but it sure is if you do. Emacs opts to replace a low skill-ceiling (and anaemic key bindings and features) with a very high one (exceptionally powerful key bindings, programmability, etc.), because if you persevere then you'll eventually learn enough to benefit from an editor that does not hamstring its users.
But that simile applies to a range of things: no matter how many books, videos or power tools you buy, you won't become a master cabinet maker overnight. It takes skill and practice. It's just that we associate "text editor" with, well... notepad. Emacs is much more than just that.
Emacs is already much friendlier than it used to be. Better defaults; more sensible inclusions that ship with Emacs. Emacs 29 adds tree-sitter and Eglot, two tools of great import to coders, that should further reduce the friction for someone keen to experiment with Emacs without having to spend a weekend learning how to set it up.
The hardest thing for newcomers – and I say this as someone who did not think to do this myself as a newbie – is to read the manual. It's right there on the splash screen, or conveniently located in the help menu. But all too many "experts" recommend you hide the splash screen, and turn off the tool and menu bar. I fell victim to that advice when I was new also. It was terrible advice. Why hide something that helps you learn and explore?
Many suggest changing the key bindings or Emacs's unique vocabulary, but I think it's window dressing, and it won't alter the learning curve much, if at all.
So my suggestion is this: alter the tutorial (C-h t) so it's interactive, prettier, and more detailed. It should neatly segue into other areas important parts of Emacs. There's a wide range of users: prose writers; note takers; coders; command line hackers; etc. Emacs is more than capable of this interactivity, and yet the tutorial makes no use of it. Emacs should be a bit more firm in its advice to newbies.
What are some of the Emacs specific workflows that help you get your work done (packages, changes from defaults, etc.)?
For me it's the ability to program Emacs when I need to. I had to write some e-mail filters – sieves, as they're known – for an e-mail server. That was tedious as I had to test that they worked; what emails they'd affect (lest I screw up badly and ransack my emails); and then against particular e-mails to make sure the filter works properly for that particular e-mail.
I wrote a handful of lines of code that glues various parts of Emacs together to do this. I press a button and Emacs connects to the remote server with TRAMP and calls the program it needs to call, and then displays the result in an Emacs buffer.
So that's the most important one: adaptation to changing requirements.
I use mostly stock Emacs key bindings, with a handful of changes to make certain things more bearable. M-o instead of C-x o; C-x C-k to kill the current buffer; F1 opens M-x shell; and a handful of other minor things.
For productivity-related stuff I use Helm a lot for specific tasks. I can call up a Mastering Emacs customer using Helm and find their sales details. Great for when people forget their email or need to change something. It's a great completion framework. I also use IDO for files and buffers and Selectrum for general-purpose completion.
Besides Emacs, what tools & gear do you use (hardware, software, or anything else that comes to mind)?
I use a ZSA Moonlander Mark 1. It's one of those fancy 'mechanical' keyboards. It's quite nice. It's programmable and extensible, and it's more comfortable than normal keyboards. I used a MS Ergonomic keyboard for about 20 years and I'd literally wear them out in about 2 years.
I occasionally do some computer gaming. So I tend to overbuy every couple of years so I don't have to care about upgrading much for the next several years. So my primary workstation is an uber-high-specced desktop (that also doubles as a space heater) with a 39" ultrawide monitor. The monitor I love. I used to used dual monitors, but... eh. This is way better. One enormous Emacs frame that I can easily split into multiple windows.
Besides the tools, what habits & routines help you finish your work?
I rarely finish my work. Unless someone's paying me, that is!
I am a habitual starter-of-projects, finisher-of-few. Half-baked, half-inventions is how I generally term the stuff I do. I tend to build something out until I'm satisfied I've sated whatever silly intellectual curiosity I have, and then I drop it like a rock, as it's rarely perfect enough for me to release.
My projects folder is full of these things.
How do you relax or take a break?
I set my own working hours, as I generally work on my terms. For clients my work is a case of agreeing the scope of what needs doing, and then I get on with it. But it's unlikely to follow a 9-5 schedule, per se. So when I want a break, I get up and walk around. Living in London affords me the ability to do all manner of cultural stuff, if that is what I feel like.
I've realised the key to my happiness is small bouts of things that bring me joy: a cup of coffee; a nice walk; it's the little things. I also adore cooking and do it daily with my girlfriend. We both enjoy food and cooking.
Whose work inspires or motivates you, or that you admire?
Hm, you know, it's a good question. I self-motivate, I think, mostly. I know it's common for people to look upon the works of others for inspiration, and I think that is probably true of me as well. But it's more of an ethereal thing for me: it's a range of things – concepts, ideas – that drive me, and less so any particular person. So when I sit down and half-invent something, it's because of that.
Interviews, writing, and video.
| Browser or Runtime | JavaScript Engine |
|---|---|
| Mozilla | Spidermonkey |
| Chrome | V8 |
| Safari | JavaScriptCore |
| IE and Edge | Chakra |
| PhantomJS | JavaScriptCore |
| HTMLUnit | Rhino |
| TrifleJS | V8 |
| Node.js | V8 |
| Io.js | V8 |
| Java 8 | Nashorn |
任务自检相关表
create table self_check_new_rules (
job_name varchar(100),
rule_id int primary key auto_increment,
rule_name varchar(200),
db_type varchar(100),
db_name varchar(100),
table_name varchar(100),
definition varchar(100),
where_condition varchar(100),
group_by varchar(100),
compare varchar(50),
op varchar(10),
range_min double,
range_max double
)
# view
select `r`.`job_name` AS `job_name`,`r`.`rule_id` AS `rule_id`,`r`.`rule_name` AS `rule_name`,`m`.`db_type` AS `db_type`,`m`.`db_name` AS `db_name`,`m`.`table_name` AS `table_name`,`m`.`definition` AS `definition`,`m`.`where_condition` AS `where_condition`,`m`.`group_by` AS `group_by`,`m`.`compare` AS `compare`,`r`.`op` AS `op`,`r`.`range_min` AS `range_min`,`r`.`range_max` AS `range_max` from (`self_check_metric` `m` join `self_check_rule` `r` on((`r`.`left_metric_name` = `m`.`metric_name`))) where (left(`m`.`metric_name`,6) = 'yester')
abstract class Tree
case class Sum(l: Tree, r: Tree) extends Tree
case class Val(n: String) extends Tree
case class Const(v: Int) extends Tree
type Environment = String => Int
def eval(t: Tree, env: Environment):Int = t match {
case Sum(l, r) => eval(l, env) + eval(r, env)
case Val(n) => env(n)
case Const(v) => v
}
val exp = Sum(Val("x"), Sum(Val("y"), Const(4)))
println("x + (y + 4) = " + eval(exp, {case "x" => 1 case "y" => 2}))
object Timer {
def oncePerSecond(cb: () => Unit) = {
while (true) {
cb()
Thread sleep 1000
}
}
def main(arg: Array[String]) = {
oncePerSecond(() => {
println("time flies...")
})
}
}
参考:
((if (= 0 n)
5
(lambda (x) (+ x 7)))
6)
上面的程序是合法的 Scheme 程序,但是这里有很严重的问题, 显然,我们不能(5 6) 这样进行过程调用
ML、Haskell 允许你进行 infer types,
Java 则强制你显式指定类型
这就是这三类语言本质的区别
总结下他们之间的关系,并且总结出 python 、nodejs、java 中如何正确处理它们之间的编码
# 将 py 文件中的 \t 替换为四个空格
find . -name '*.py' -exec sed -i 's/\t/ /g' {} +
find ~/logs/ -type f -mtime +3 -name \*.log -delete
$ java -cp ~/bin/clojure-1.8.0.jar:. clojure.main <src>.clj
main.java
/**
* Copyright (c) Rich Hickey. All rights reserved.
* The use and distribution terms for this software are covered by the
* Eclipse Public License 1.0 (http://opensource.org/licenses/eclipse-1.0.php)
* which can be found in the file epl-v10.html at the root of this distribution.
* By using this software in any fashion, you are agreeing to be bound by
* the terms of this license.
* You must not remove this notice, or any other, from this software.
**/
package clojure;
import clojure.lang.Symbol;
import clojure.lang.Var;
import clojure.lang.RT;
public class main{
final static private Symbol CLOJURE_MAIN = Symbol.intern("clojure.main");
final static private Var REQUIRE = RT.var("clojure.core", "require");
final static private Var LEGACY_REPL = RT.var("clojure.main", "legacy-repl");
final static private Var LEGACY_SCRIPT = RT.var("clojure.main", "legacy-script");
final static private Var MAIN = RT.var("clojure.main", "main");
public static void legacy_repl(String[] args) {
REQUIRE.invoke(CLOJURE_MAIN);
LEGACY_REPL.invoke(RT.seq(args));
}
public static void legacy_script(String[] args) {
REQUIRE.invoke(CLOJURE_MAIN);
LEGACY_SCRIPT.invoke(RT.seq(args));
}
public static void main(String[] args) {
REQUIRE.invoke(CLOJURE_MAIN);
MAIN.applyTo(RT.seq(args));
}
}
| 应用市场 | 网址 |
|---|---|
| 苹果 | http://www.apple.com/cn/itunes/charts/free-apps/ |
| 小米 | http://app.mi.com/topList |
| 豌豆荚 | http://www.wandoujia.com/top/app |
| 安卓市场 | http://apk.hiapk.com/apps |
初步的想法是 python 写一个爬虫,定期去获取数据,数据主要包括两方面:
只包含应用数据,不获取游戏。
| Collector | Function | Recommended for | How to enable |
|---|---|---|---|
| Serial Collector | Uses single thread for both minor and major collections. Simplest. | Single processor machines | -XX:+UseSerialGC |
| Parallel Collector (Throughput Collector) | Uses multiple threads for minor collection. | Multi processor machines/enterprise class applications | -XX:+UseParallelGC. To enable Major parallel collection,add -XX:+UseParallelOldGC |
| CMS Collector (Concurrent Mark and Sweep Collector) | Mostly performs GC simultaneously along with Application | Applications that cannot tolerate longer GC pause times | -XX:+UseConcMarkSweepGC |
| G1 Collector | Strives to collect from Heap regions that have the most garbage | Most enterprise class applications. Through testing required before implementing. | –XX:+UseG1GC |

jstat -gcutil <pid>jmap -heap <pid>在求知的过程中,我们经常会要面对这样,那样的诱惑。
以读书为例,一部经典的好教材,想要把它读通,搞明白,弄扎实,除了在读的过程中理解作者想要描述
的字面意思以外,往往还需要通过作大量的相关习题及实验来建立起更为扎实,深刻的认识,而捧着厚厚
的一本书,人类心理潜在的占有本能又往往会驱使着自己以最快的速度将这部教材拿下,满足自己的成
就感,于是在没有外人监督,没有外力监控的情况下,很容易演变为一开始的时候读书,作题皆顾,随
着时间的推移,自己开始不能抗拒快速读完书本的诱惑,于是作题的频率越来越低,最终在快速攻克目标
的指导原则下,书读完了,习题却没有作几道。在读的过程中,在每个阅读的局部阶段,对作者想要传递
的意思似乎都搞明白了,但真的把书本一合,要求你对某一小节,某一大章,乃至全书作一个总结性的回
顾,往往就觉得很多想法,很多话,似乎就在嘴边,就在脑子里,却就是不能以流畅的方式表达而出。真
要让你用书上讲述的知识解决一些实际问题,却往往感觉无从下手。究其根源,实际上还是学习过程作得
还不够扎实。
在我们的阅读范畴中,有很多图书,是不值得精读的,特别是资讯性质的图书,资料,(尤以互联网上的
信息为甚),制作这些信息源的作者,出于快速传播其信息的需要,往往会在制作过程中对资讯进行适当
的处理,以降低受众理解消化的门坎。
对于这类资讯,在阅读它们的过程中,能够增加我们的见识,却不能增进我们的理解力,因为在开始阅读
之前,我们的理解力就已经与这些资讯的制作者相当了。(资讯的源制作人在其专业的领域当然有着超出
常人的理解力,但在他制作资讯的过程中,已经试图通过各种手段,降低理解资讯所需的理解力了,否
则,阅读一份资讯类的报纸还需要一个普通人经过一两天的思考才能完成的话,这些资讯制作机构也就早
早关门大吉了)。
而一本经典的好教材,其定位与资讯类读物则大不一样了,通俗来说,读资讯类读物,是为了知道发生了
什么,而读经典的教材类读物,则是为了知道在发生的事情背后蕴藏的机理。再换句话说,经典教材的
目的是为了提升人的理解力,而资讯类读物,则是为了让人长见识。
想要通过读经典教材的过程来提升自己的理解力,就好比要通过读书的过程,将作者身上所具备的,而在
读之前自己身上还未具备的某些能力,特质,吸收过来。不同的知识背景,不同的知识结构,不同的
知识基础,甚至不同的文化背景都注定了要想让自己通过读一本书获得跟作者在这本书所述及的内容
上相近的理解力,不会是件容易的事情。大量的思考,习题,实验,乃至于查找相关资料辨伪存真,相互
印证,都是重要的手段。一本好的教材,也许只有500页,但为了将其读通,读透,进而提升自己在这
本书所述范畴的理解力,你需要作的习题,需要查的资料,需要写的笔记和读书报告,可能会远大于这个
页数。如果在读这类书的过程中,只是满足于在快速阅读中理解自己目光所触的书本范围内容,恐怕,读
完了整本书,你都还未必能体会到作者真正想要传达内容的十分之一,个人在理解力上的增益也就很有限
了。
所以,对于阅读经典教材,我会试着采用如下的方法:
关键是连续,我本人不主张那种"这周看100页,下周休一周,再过一周再看几页"的这种不均匀的阅读
方式,现代社会里,我们接触到的事物,需要处理的事情都是非常繁多的,而个体的处理能力,记忆能力
是有限的,所以,如果阅读一本书的间隙太长,很可能你读到第150页的内容时,会发现自己已经淡忘了
前面的很多内容,这种淡忘在阅读过程中肯定在所难免,但是不规律,不连续的阅读引起的淡忘效果要明
显得多。 一股作气的策略,在读书过程中也适用。
早就有古人说过"学而不思则罔",长时间的阅读,却不去花时间思考why and how?会让自己退化为一个
知识存储机器,达不到提升理解力的效果了。对书本上的东西,如果只是人云亦云,所掌握的往往浮于表
象,只有真正经过自己深入思考,推敲的,才能更有效的纳入自己的知识体系。
曾经有过一段时间,我很排斥作题,觉得作题实在是一种应试教育的弊端,但多年之后,经历过一些认
知,学习上的困境,也走过一些弯路之后,我现在的体会是,作题是一种很有效的巩固所学,扎实所学的
方式。只不过,传统的应试教育过分强调作题本身在功利方面的回报,容易激发起人的心理反弹,以致于
个体一旦获得自由学习的环境以后,会倾向于排斥这种方式了。
有很多时候,我们在读书的过程中,感觉自己已经明白了作者所说的某句话,某个意思了,而实际上却未
必如此。不同的背景,不同的知识结构,注定了读者与作者经常会在相同的某个描述上存在理解偏差。作
者实际想阐明的意图是a,他用来阐明意图a的描述是B,而读者在读完描述B以后所建立起来的初始理解
则可能是c,c与a可能存在交集,也可能不存在交集。不通过作题,仅仅思考,是很难确立自己对作者的
主要意图的理解是不是存在偏差。而通过作题,往往能发现自己在理解上的偏差和盲点,让自己对描
述B的理解更接近于作者想要表达的原始意图a了。
个人觉得,阶段性地作读书笔记,有那么几分"跳出画外看画"的感觉,不停地阅读,思考,作题,会让
自己一直纠缠于书本,教材的细节,而适时地跳出来,作一个小结,会有助于自己廓清方向,梳理思路,
不囿于一书一时,另一方面,还能起到巩固所学的目的。至于查找资料,互为印证,因为现在的精力实在
是有限,也跟自己的惰性有关,现在自己读书的过程中,作得还很不够,(个人感觉,作学术研究的话,
查找资料,互为印证是必要条件,而仅仅是求知的话,则不那么紧迫。)但是上面所述的四点,自己在阅
读经典教材类的图书的过程中还是基本在一直坚持的。
最后引用法国学者Pascal曾经说过的一句话作为此贴的结尾吧:
"读得太快或太慢,都一无所获。"
原文:
https://groups.google.com/forum/#!msg/pongba/IKCLYgHYipg/5bPGjyS6jIYJ
记住,一个被拒绝并不代表永远。一年内你还可以重新应聘,失败是成功之母。
只在计算机上练习
不做行为面试题演练
用心回顾以往的项目和精力,然后准备一些小故事。
不做模拟面试训练
不要纸上谈兵
试图死记硬背答案
不大声说出你的解题思路
过于仓促
代码不够严谨
不做测试
修改错误漫不经心
轻言放弃
面试题如果不难怎么能体现求职者的水平呢。迎难而上还是轻言放弃?态度很重要。碰到棘手问题不要慌张,也不要轻言放弃。
https://lillianli.substack.com/p/let-the-bullets-fly-for-a-while
以下文字为 Google 翻译
上个月,在研究滴滴时,我离开了几天。但这是一个日子感觉像是几年的时代,尤其是在**科技领域。在滴滴全球在纳斯达克进行44 亿美元的 IPO后仅几天,他们的应用程序就在**网络安全局 (CAC) 的要求下从在线商店下架。引用的原因是违反个人数据收集。
我觉得**监管者从不睡觉,而不是资本。过去九个月,蚂蚁集团IPO被撤,社区团购玩家因价格倾销被罚款,阿里巴巴因反垄断被罚款,美团也因反垄断被罚款。就像奥普拉抛出汽车一样,每个科技巨头似乎都受到了召唤。
那么,为什么监管机构会介入呢?
在我看来,全球需要重新平衡国家、科技公司和消费者之间的权力。这需要更多的监管干预。特别是对于**来说,作为一个发展**家意味着它比其他国家有更多的监管需求和方法。
技术平台对民族国家的合法性构成重大挑战。1它们正在成为事实上的机构,而不仅仅是提供对公民生活至关重要的公用事业2而是设定社会运作的游戏规则。Facebook 为全球三分之一的人口制定了内容审核政策。Twitter 和其他人取消了这位美国前总统的平台,将他降低为不受欢迎的数字角色。这些是强大的私人实体,既是垄断又是公共产品,但消费者福利并不是他们议程的核心部分。立法者的意识逐渐增强,这就是为什么三大洲的政府正在重新评估科技巨头对其公民的影响和影响力。技术冲击是全球性的。
作为一个制度框架不完善的发展**家,**在技术监管方面还有一些额外的问题需要解决。如果我们以美国和欧洲的监管体系为基准,**在基本法律的制定和实施方面是滞后的。**的反垄断法于 2007 年首次通过,比美国1890 年的_谢尔曼法案_、1914 年的_克莱顿法案和__联邦贸易委员会法案晚近一个世纪_ 1914 年。同样值得注意的是,阿里巴巴成立于 1999 年,腾讯成立于 1998 年,百度成立于 2000 年——所有这些都领先于反垄断法。法律本身还不够,国家市场监督管理总局(SAMR)于 2018 年 4 月成立,全面覆盖执法。
**法律和监管机构需要迎头赶上,才能与既定的西方做法相提并论。这就是为什么每次监管事件的细节都相当平凡——无论是广发银行的价格倾销,还是美团和阿里巴巴的“二选一”,还是围绕敏感数据的国家安全问题;这些在西方大多是公开的案件,但在**却是新闻。部分原因是它以前没有发生过,这是由于缺乏政治意愿和伴随的法律机构。我想指出,监管应该被认为是正常的,而不仅限于科技公司。贵州茅台(**领先的白酒制造商)、顺丰物流和混凝土公司都受到审查或被罚款。消费技术平台具有网络效应,这通常意味着边际回报增加,但也更倾向于创造垄断。相对于实体公司,它们遵循一套不同的经济规则。
但是,如果**不将美国和欧洲作为默认的监管基准会怎样。正如我之前在“当我谈论**科技时我在谈论什么”中所写的:
贯穿**科技的一个关键主题是,作为一个制度不发达的发展**家,科技不是在增强现有制度,而是在创造它们。
在**,老公共机构与新兴数字机构之间存在共生关系。滴滴为黑色出租车清理灰色市场,美团和饿了么充当事实上的餐厅检查员。各内容平台代表当事人进行内容审核。政府是务实的。在**碎片化的威权治理结构中,能够引入并保持易读性的代理人留了下来。
随着这些混合治理结构经历高速增长,应该监管什么以及如何监管并不明显。尽管没有蓝图,但我称之为“让子弹飞一会儿”的监管节奏。
让子弹飞一会儿
要充分了解**,需要观看一部名为《让子弹飞》的精彩黑暗电影。自 2010 年上映以来,关于封建制鹅镇一个强盗变身假总督的故事已成为**网络空间模因的主要内容。它充斥着关于**权力、金钱和合法性的规则和界限的各种说法,它是一块文化试金石。
[
《让子弹飞》三兄弟电影截图
在关键的场景中——令人眼花缭乱的战斗,什么都不清楚——下属问强盗总督该怎么做。不可避免地,他以臭名昭著的台词“让子弹飞一会儿”作为回应。意思是,让混乱运行;谁知道哪些问题在没有干预的情况下自行解决,或者潮流何时会转向。在不确定性期间,不作为是一种资产。过早地调用事情会关闭可能性。
撇开我对**互联网表情包的喜爱不谈,这种说法引起了监管机构和经济学家的共鸣。当他们被要求描述**的监管方法时,这一直是谈话中最喜欢的标语。宏观经济理论3也证实了这一点,当市场经历高度的未来不确定性(如新兴市场的情况)且监管机构没有足够的监管工具时,偏向于不作为是一种主导策略。
***“摸着石头过河”的口号捕捉到了驾驭勇敢新世界所需的微妙实用主义。部分原因是信息不完善,部分原因是对采取的监管方法缺乏共识,**监管机构历来采取“先观察后行动”的做法。
在保护社会和消费者利益的同时,允许增长和创新形成一个微妙的平衡。监管机构并不总是正确的。在 2000 年代初期的移动电信价格战中,它们太软了。在 2015 年代的 P2P 借贷期间,他们行动太晚了。在共享经济时代,人们在ofo的存款在法规制定之前就已经丢失了。每次他们从以前的经验中学习,提高他们的监督能力并在下一轮改进。每一次都是创新先于监管的模式,其临界点是消费者福利的恶化4 。结果是这些公司活了下来,但发生了变化——陆金所,著名的 P2P 贷方之一也是由于监管方面的担忧,他们在 2018 年搁置了 IPO 计划。他们成功地将自己更名为企业贷方,并于 2020 年 11 月在纳斯达克上市。蚂蚁集团正在重组,但允许继续经营。
所以我认为这里的实际问题不是科技公司为何面临监管,因为**科技历史表明这种情况总会发生。问题应该是:为什么是现在?可以分为以下几个原因:
科技平台已转向价值提取而非创新以促进增长——随着**互联网用户整体增长的放缓以及大多数已经数字化的大市场,科技巨头必须专注于增加现有用户的支出以实现增长。COVID-19 巩固了平台在人们生活中的地位,但用户感到了压力。人们对价格歧视做法(滴滴和其他平台将对相同产品的老客户收取更高的价格)、工人面临的严格条件以及平台税商必须支付流量和关注他们的商品感到不满。当馅饼的大小变得固定时,每个玩家都会切换到提取模式,消费者会受到影响。
重新平衡以实现更具创新性的生态系统——“十四五”规划中的技术目标雄心勃勃。人工智能、量子计算、半导体和基因研究——未来的技术增长驱动力将不是电子商务,而是深度技术。王丹的观察**未来的重点是制造业、经济增长和实体经济。我不会说现有的科技巨头扼杀了创新,但我不确定它们有多大帮助。阿里巴巴和腾讯之间的影子战争占据了大量的空气和资金。数据在封闭的花园中被分割。**新创企业的数量每年都在下降。当大型科技公司不进行创新而是复制或收购竞争对手时,生态系统就会受到影响。
监管机构背后的额外政治影响力——**监管机构并非铁板一块。围绕**科技的叙述经常被提炼成个人,而在**,它实际上是对系统以及这些系统中伴随的竞争派系的叙述。很明显,权力转移已经发生,改革背后有决心。是杰克的讲话还是监管者觉得他们在微信中的抖音和淘宝链接需要观看?无论哪种方式,如果围绕滴滴数据调查的评论有任何依据,监管机构都会得到**群众的支持。
这对**科技的未来意味着什么?
我对长期持乐观态度,但对短期持谨慎态度。监管的目的不是扼杀创新,而是重新划定私营公司可以运营以实现利润最大化的界限。死公司对任何人有什么用?尤其是当它处理像现代公用事业这样重要的事情时。话虽这么说,但监管执法工作积压了很长时间。**科技公司必须解决他们的技术债务和收费问题,因为他们知道 CAC 和 SAMR 正在密切关注。子弹停止了飞行,行动开始了。
我实际上从我对该主题的研究中获得了更多材料(包括 SAMR、CAC 和其他在职权范围内的细分,对未来海外上市的潜在影响),并且很乐意分享并为高级订阅者提供 Q&A 线程在**特色圈社区。当您在那里时,也为本月的产品演练投票!目前的赢家是快手,但仅以微弱优势领先。
我终于完成了社区团购深潜!明天会发出去。<3
https://lillianli.substack.com/p/china-semiconductors-and-the-push
本文分两部分深入探讨**半导体供应链。它最初是对**半导体(制造半导体所需的设备)的利基研究,但已经发展到涵盖更广泛的生态系统。第 1 部分将讨论更广泛的生态系统,以及**为何迫切要求独立。第 2 部分将揭示**在此背景下的角色、不同的**参与者是谁,以及他们各自的发展轨迹。
这是一个非常复杂的行业,每个领域和角度都有大量文献,这篇文章来自各种专家和来源。我尽可能多地尝试将它们联系起来。如果我遗漏了你,请在Twitter 上给我留言,我会尽快给你链接。
非常感谢mule 、Dylan 、Chris 、Jon和Dan Wang 。
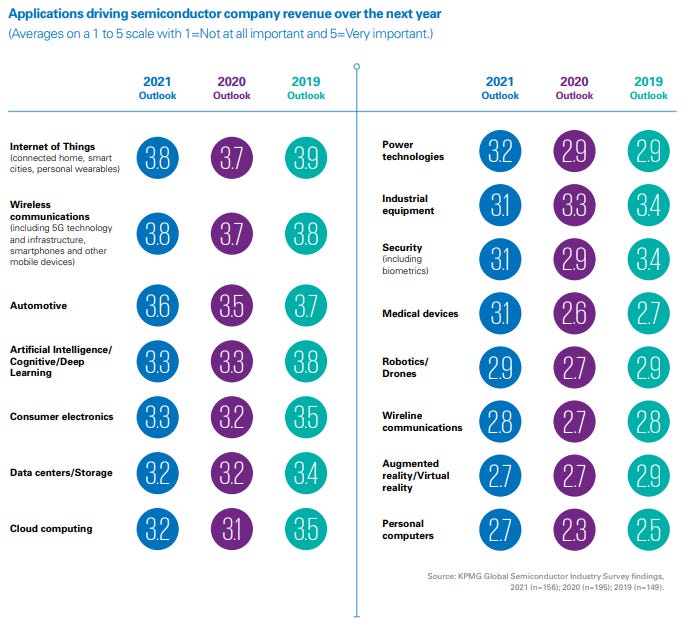
芯片成本正在上升。能参加比赛的球员越来越少。市场的周期性正在减弱。AI / 5G 的需求即将出现激增。**在当地供需方面存在很大的不匹配。
工人必须拥有生产资料。这是马克思主义的基础,它变成了共产主义,变成了社会主义。对此,洒上一些**特色,你就有了全球增长最快的大市场的基础。难怪**正在追求技术独立。总的来说,他们在这方面做得非常出色,也许在半导体领域除外。所有现代科技的关键是什么?半导体。
COVID-19 的出现使全球许多供应链都需要冗余。然而,**对内部集成电路(IC)制造能力的推动并不是什么新鲜事。在可追溯到 70 年代的每 5 年计划 (5YP) 中,即使名义上也提到了这一点。不过这一次其实不一样。第十四个五年计划是第一个强调_完全_自力更生,并建议在本地建立一个近端对端的链条。这也是**第一次在全国范围内处于足够强大的地位来资助这一尝试,也是第一次将其视为国家安全问题。
**半导体供应链是一个相当复杂的东西。要理解它,首先需要了解它如何融入全球供应链,并了解激励**独立的供需动态(包括半导体和一般技术)。一旦确定了这些背景,我们就可以了解**供应链的具体情况及其未来前景。
作为**特色的读者,您可能对科技感兴趣。您也可能已经对半导体有了不错的了解。对于外行,我在今年早些时候写了一篇关于半导体的介绍性帖子:
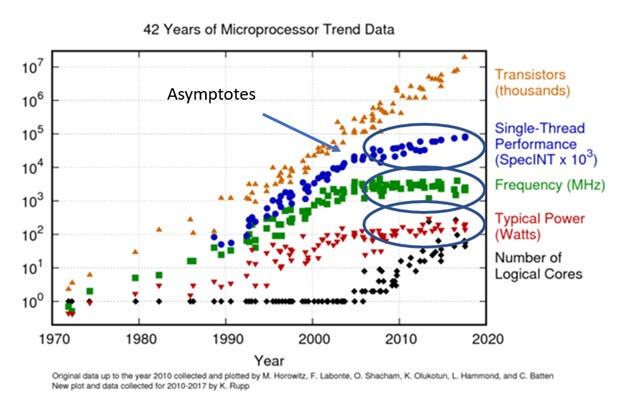
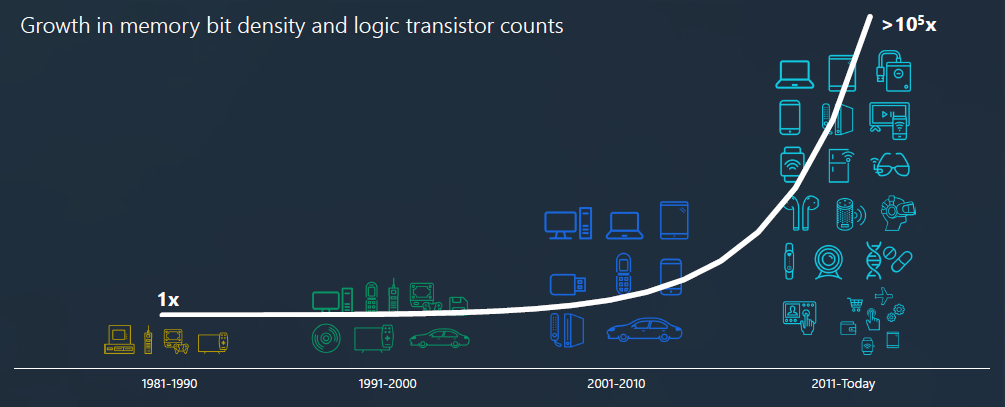
TL; DR 是半导体是构成集成电路构建块的微小导电材料 - 基本上为所有依靠电力运行的东西提供动力的小芯片。迄今为止,游戏的名称一直是“将更多组件塞进集成电路中”。这是摩尔定律:IC 上的晶体管数量大约每两年翻一番。众所周知,摩尔定律现在已经死了。
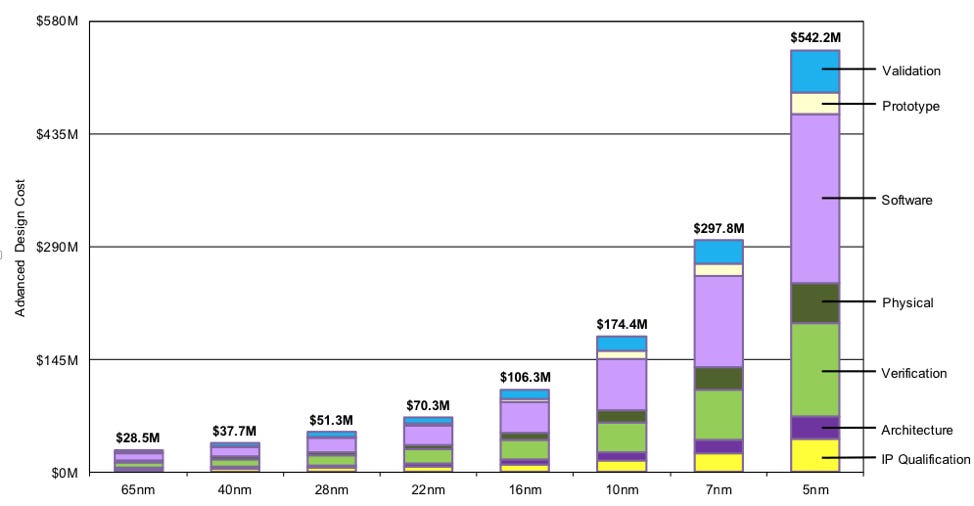
我们可以每隔几年将每个芯片的晶体管数量翻一番的想法导致公司认为这种增长是理所当然的。预计优化将发生在芯片尺寸级别,而不是代码或工艺级别。正如我们将看到的那样,物理学限制了芯片的持续缩小,以至于必须越来越多地从工艺改进、封装和软件中获得更好的性能。所有这些都使芯片生产成本成倍增加(图 1)。
[
图 1:按工艺节点增加的生产成本(SemiEngineering ,2020 年)
[
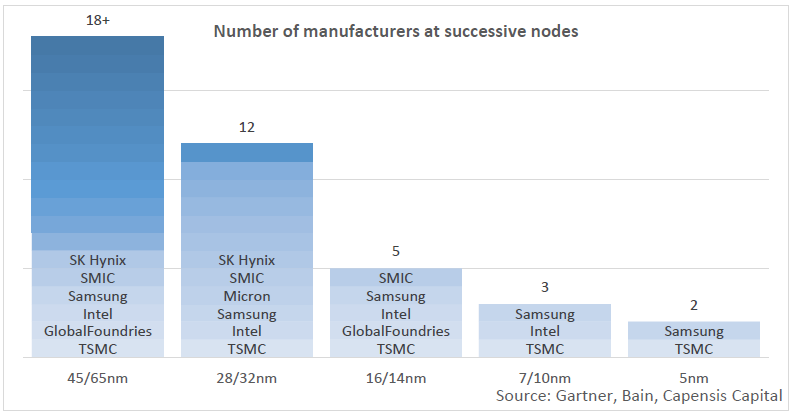
图 2:在前沿制造芯片变得越来越难( Capensis Capital 3Q2020 Letter)
从历史上看,芯片行业一直是高度周期性的。制造商不得不应对技术的指数级改进、管理一些人类已知的最复杂的工程以及极高的研发成本。在过去,所有这些都结合在一起,形成了繁荣与萧条的过山车。芯片制造商不得不努力计算开发代工厂所需的时间,因为新芯片(称为工艺节点1 )问世时交货时间长、供应限制和需求激增。由于“前沿”芯片——真正的小芯片,比如<7nm——比几年前的“落后”芯片更难生产,这加剧了这种情况。由于这些限制,供应链的许多要素将在不同时间达到高峰和低谷。
[
图 3: 2021 年 6 月Besi投资者介绍。
多年来,高资本支出、周期性投资和极端流程复杂性的三重奏导致了该行业的整合。现在很少有公司拥有知识产权、人才、生态系统或资金来竞争。另一方面,在过去五年中,需求激增。AI/ML、物联网、5G 和许多其他首字母缩写词技术流行语的承诺已经开始脱颖而出。
供给侧整合和需求侧爆炸的结合导致行业动态从过去的周期性转变。然而,更重要的是,尺寸的物理极限(芯片缩小)几乎受到了影响。这在很大程度上是摩尔定律被认为正在消亡的原因。换个说法:这不是你祖父的半导体产业。
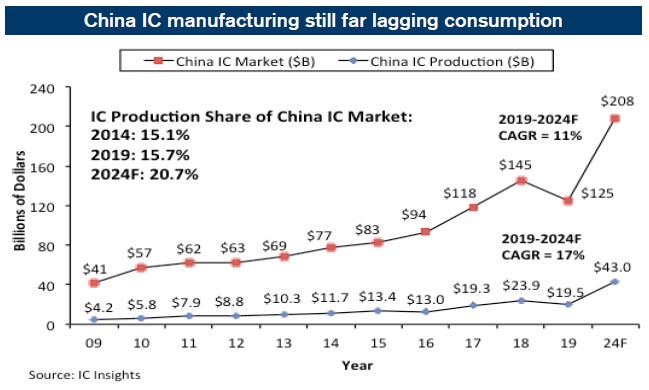
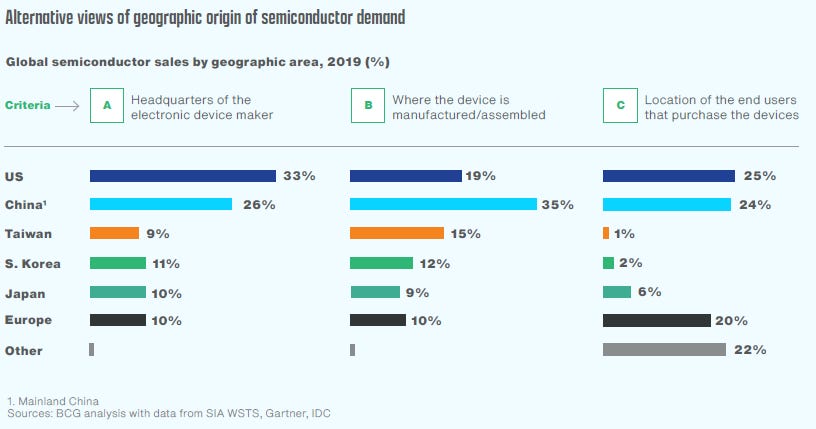
正是在这个新的行业中,全球垄断者控制了所有供应,**创造了大约3100 亿美元的需求。2020 年全球芯片销售总额为4400 亿美元。表面上看,**拥有全球 70% 的需求,但其中大约一半是经过包装和组装后从**出口到世界其他地区的。这就是为什么**如此热衷于技术独立的原因。他们在当地的供需方面长期存在不匹配,他们在依赖半导体的技术领域争夺世界领先地位,而芯片是美国(制造芯片制造的大部分设备)对他们的公认瓶颈。
[
图 4:Randy Abrams,瑞士信贷(2020 年)
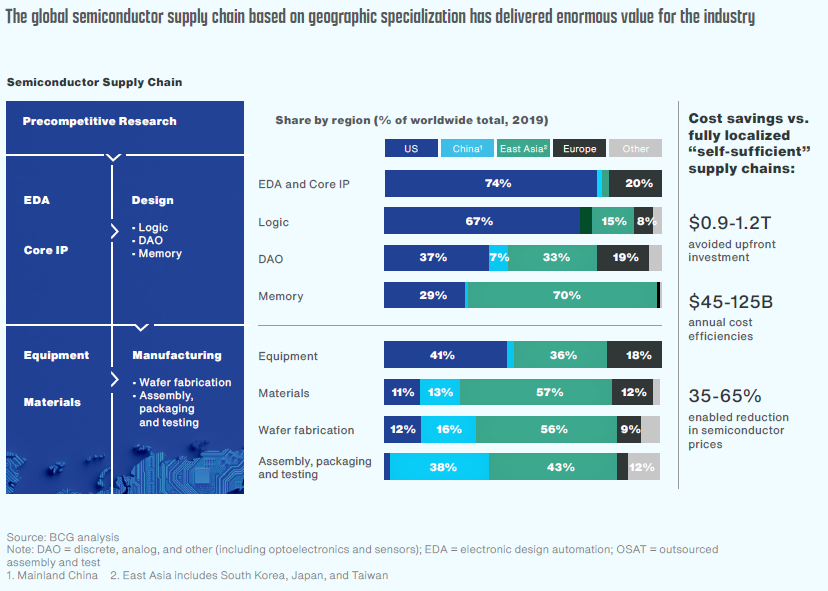
**在包装、设计和落后制造方面的能力不断增强,现在正在争取领先的独立性。本文的重点不是对整个全球供应链进行细致入微的全面了解。为此,我推荐BCG/SIA和德勤的这些报告。然而,如果不了解整个行业,就很难了解**在该行业中的作用。因此,如有必要,我将借鉴更全面的概述。
这篇文章(第 1 部分)的重点是更深入地研究_**_试图从中获得独立,以及他们_为什么_想要独立。第 2 部分将深入探讨**的主要参与者是_谁,他们期望__如何_进步,以及_何时_可以预期他们与当前领先的垄断者竞争。
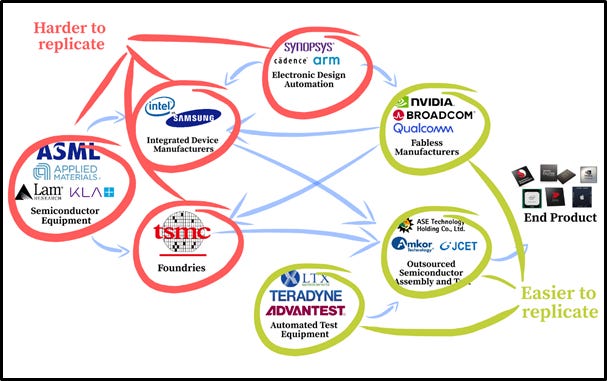
**试图破坏的“什么”。供应链归结为少数几家拥有巨大成本、人才生态系统和复杂知识产权的垄断企业。细微差别,有不同类型的芯片:大型(模拟)、中型(内存)和小型(逻辑)。**正试图在这三个方面都具有竞争力。这三者都有不同的进入门槛。**将难以与离消费者最远的供应链部分竞争,而与离消费者更近的部分竞争将变得更具竞争力,这需要较少的极端专业知识。
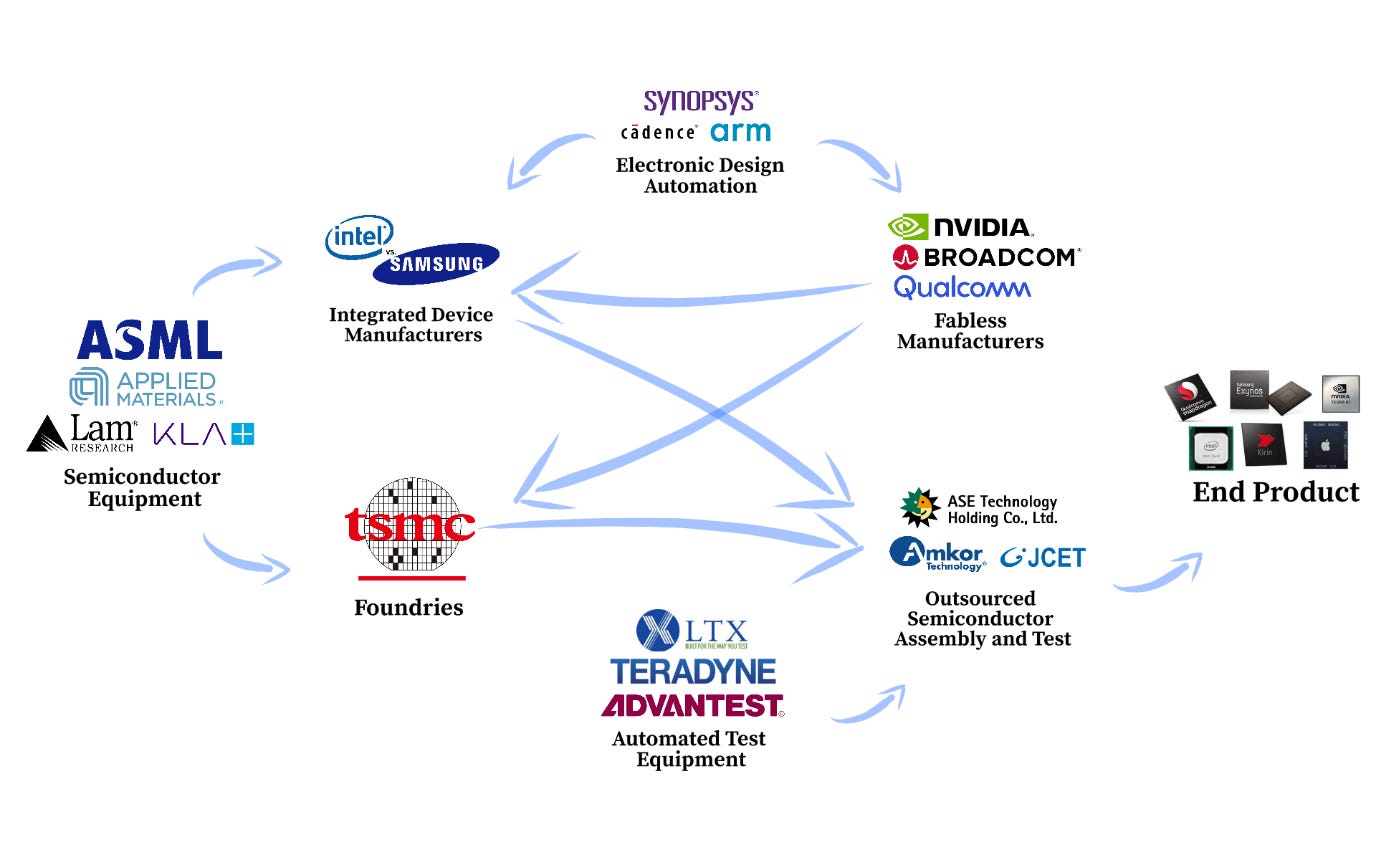
那么,今天的行业是什么样的呢?半导体公司分为五类:
电子设计自动化 (EDA)
芯片设计(Fabless 制造商)
制造厂(集成设备制造商和代工厂)
设备(“半导体”)
外包半导体组装和测试 (OSAT)
这是我为画一点图片而制作的小图形。
[
图5:全球逻辑芯片半导体供应链(Vineyard Holdings )
简而言之,设计用于智能手机、汽车和笔记本电脑的芯片的人(“无晶圆厂制造商”)是在 EDA 软件上完成的。如果他们可以设计和制造芯片,他们就被称为集成设备制造商。三星和英特尔是这里的两大巨头。
如果他们不能自己制造芯片(大多数人不能),那么他们就会将设计发送给可以的人。这些是代工厂,其中最重要的是台积电(TSMC)。我建议对那些感兴趣的人深入了解铸造厂的组成。
任何能够制造芯片的人都只能这样做,因为他们从少数供应商那里购买了超精密的设备。这种设备被称为 semicap,是 Semiconductor Capital Equipment 的缩写。代工厂将设备与专业材料和工艺专业知识相结合,然后弹出芯片。
该芯片仍需组装、测试和封装。由于这是与制造不同的能力,代工厂将这部分过程外包给专门从事该过程的人员。这是 OSAT 工作人员。他们依赖一组不同的供应商来提供测试设备。一旦芯片设计、制造、测试、封装和组装完毕,就可以使用了。
由于许多节点的——字面上是原子的——大小,处理它们的公司已经在他们的领域开发了不可复制的专业知识。在许多情况下,几个不合适的原子会导致整个产品无法使用。例如,ASML 的极紫外光刻 (EUV) 机器所需的镜子被抛光到小于一个原子厚度的光滑度。换个角度来看,如果镜子有德国那么大,最高的“山”只有 1 毫米高。这是**试图颠覆的行业。
流程节点(芯片)有多种尺寸,适用于一系列用例:
**大节点(>180nm)**通常是模拟的。通常,它们用于接收非二进制输入并将其转换为二进制(例如 EV 中的传感器如何“看到”道路并将该信息传播到系统的其余部分)。
**中等节点(28nm-180nm)**是多数逻辑节点。它们是大多数人在想到芯片时想到的节点——它们是处理过程计算的节点,比如 CPU 和 GPU。
**小节点(10nm 到 22nm)**分别在内存和逻辑之间以 80/20 的比例分割。大多数内存芯片是支持 NAND(SSD 中的永久存储)和DRAM (笔记本电脑用来保持所有 Chrome 标签页打开的临时存储)的芯片。
许多流行语技术都依赖于前沿节点。“领先”在技术上是指从台积电承诺的 1 纳米节点到 iPhone 8 中的 10 纳米节点。但实际上,目前规模化生产的最先进节点是支持 5G 的 iPhone 12 中的 5 纳米节点。
大规模部署 5G 的最低要求是 5nm 节点,因此它们的生产支持 AI 进步、5G 和大部分数据中心发展。关于计算是在“边缘”(数据的来源;不要与“前沿”一词混淆)还是在云中进行,还有一个完整的争论。无论哪种方式,领先的芯片都将成为构建这种基础设施的铁锹。
每种类型的节点都由具有特定专业知识的特定生产者主导。由于模拟芯片(大型)更容易制造,因此该领域公司的竞争优势来自其产品的广度、营销渠道的覆盖范围以及规模衍生的成本优势。德州仪器(是的,计算器公司)是领先的模拟生产商。
至于中型节点,这些主要用于存储芯片。全球有三个占主导地位的内存厂商。美国的美光,韩国的 SK 海力士和三星。内存产品完全商品化。从单位经济学的角度来看,它们也是一些最糟糕的产品——公司对最终用户的了解很少(创建更短的订单周期),并且过去在成本方面展开了激烈的竞争。因为存储芯片需要电容器(小电荷存储器)和晶体管(打开或关闭开关的小网关),所以它们比仅晶体管逻辑芯片具有更高的尺寸限制。内存芯片在物理上几乎被限制在 >10nm。我建议阅读Andrew Rosenblum 的2020 年第三季度投资者信函在这里进行更深入的了解。总结是,内存生产商增加供应的唯一方法是通过从半导体供应商那里购买更多设备并培训更多员工来管理生产线2来增加新的生产线。
[
图 6:我们正在全面打击半导体发展的规模限制。这是摩尔定律的消亡(mule ,2020)
上面概述的整个供应链,包括无晶圆厂设计师、代工厂、OSAT 团队,主要是逻辑芯片的供应链。作为计算的基础设施,这些芯片是**产业最大的焦点,也是最难复制的。_笼统地说,_这是给你的另一张照片。
[
图5(再次,但不同):全球逻辑芯片半导体供应链(Vineyard Holdings )
下面的图 7 和图 8 分别显示了半导体的区域需求和供应。请注意**的需求有多大,而除了 OSAT 之外,它们的供应量有多大。我们稍后会谈到这一点,但现在快速说明一下——**在制造领域的 16% 市场份额实际上主要是半导体制造国际公司 (SMIC)。有传言称,中芯国际在最好的情况下正在生产一些7nm 节点(主要是用于加密货币挖掘的 ASIC ),但在规模上它们仍处于 14nm 及以上。通常,公司不会跳过一个工艺节点,通常是从 14 纳米到 10 纳米,再到 7 纳米。在看到美国制裁对华为的影响后,中芯国际似乎有意从 14nm跃升至 7nm 。
[
图 7:按地区划分的半导体需求,BCG/SIA (2021 年)
[
图 8:按地理和方面划分的半导体供应,BCG/SIA (2021 年)
迄今为止,**在提供廉价劳动力方面表现出色,但在发展技术和关键步骤的能力方面并不那么出色。他们较低的劳动力成本使他们能够在组装和包装方面很好地竞争,这些过程虽然复杂,但远不如半导体生产或制造。
他们也在设计领域成长。随着公司开始需要更多专用芯片,通用芯片正面临威胁。苹果、谷歌、亚马逊、阿里巴巴、腾讯和许多其他家喻户晓的公司都开始制造自己的芯片,特别是因为代工厂使外包设计变得如此容易。
Cadence Design System 是领先的设计软件供应商之一,与 Synopsys 一起在市场上处于准双头垄断地位。下面的图 9 是它们在**的增长情况。这种增长的含义是,**对设计软件的需求量比 Cadence 服务的其他地区更快。骡子在 Cadence 的 20 年第三季度财报电话会议上 发表了一篇很好的文章,进一步解释了这一点。
[
图 9:Cadence 财务业绩(2020-2021 年)
然而,**和**公民所寻求的技术独立性不会在已经制造的芯片上找到,甚至在设计用于制造的芯片时也不会。**实现技术独立的唯一途径是工人拥有生产资料。**需要代工厂。
但铸造厂需要设备、工艺、庞大的人才库、客户和大量的专业知识。虽然金钱在创造这些方面有很长的路要走,但有些东西是金钱买不到的。每个设备制造商都在数十年的周期和整合中积累了开发特定设备(和维护)堆栈的专业知识。为了真正的独立,**需要自给自足,不仅要生产铸造厂,还要生产铸造厂所依赖的设备。否则,阻塞点只会向链条的上游移动。
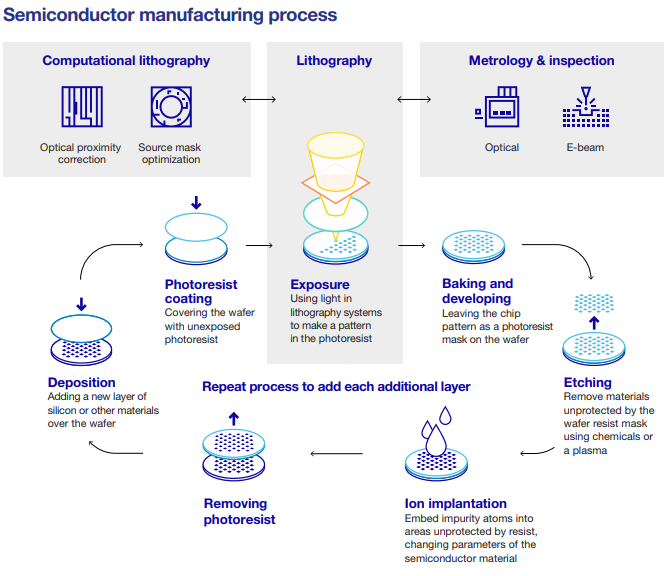
到目前为止,我一直避免详细介绍芯片的实际制造过程。这有点超出本文的范围,但这里是英飞凌的 13 分钟视频。如果您有进一步的兴趣,ASML在他们的网站上有很好的解释。平均而言,制造厂大约有 500 多台机器,芯片制造过程中大约有 1000 多个步骤。因为半导体芯片是人类曾经处理过的最小的事情之一,所以即使是微小的灰尘,它们也可能会被毁掉。大多数晶圆厂都竭尽全力避免这种情况,在空气通风上花费了大量资金。平均晶圆厂比医院的大多数手术室“清洁”约 100-1000 倍。
在高层次上,现代芯片是“小摩天大楼”(ASML 的类比,不是我的)。它们是硅晶片,首先涂有光刻胶,这是一种光敏聚合物,在曝光时会溶解。芯片经过数百次曝光循环,将未曝光的光刻胶烘烤以显影图案,并蚀刻掉不受光刻胶保护的材料,然后最终去除光刻胶并加工晶片。
[
图 10:前端半导体制造工艺(ASML 年度报告,2020)
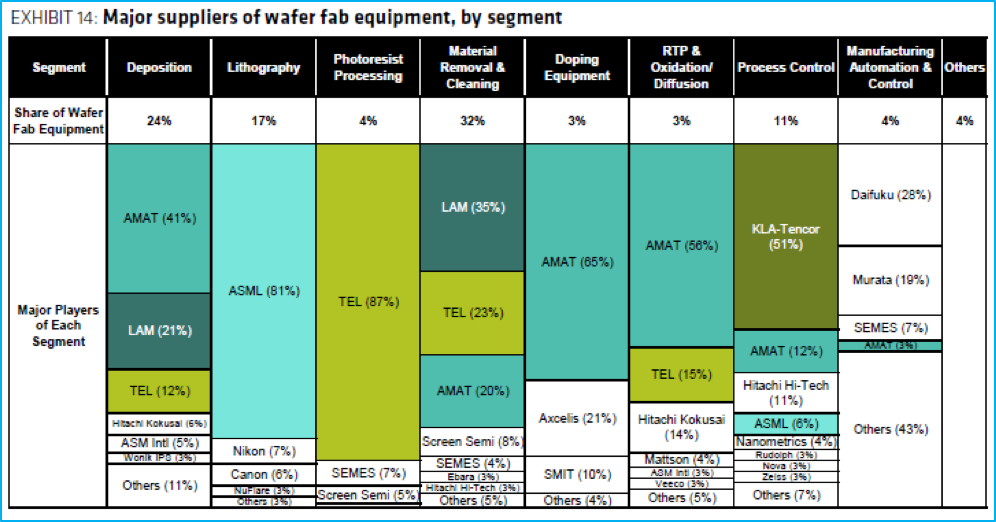
下面的图 11 显示了某些公司在半导体股领域的主导地位。Applied Materials (AMAT)、Lam Research (LAM)、ASML、Tokyo Electron (TEL) 和 KLA-Tencor 是值得注意的主要参与者。在这五个中,只有东京电子和 ASML 在美国以外。
在这两者中,ASML独一无二的 180 吨 EUV 机器是制造任何尖端产品的关键推动力。每年大约生产 25 台这样的机器,其中大部分供应给台积电,每台机器的成本约为 1.3 亿美元。迄今为止,部分是因为他们对美国零部件的依赖,部分是因为地缘政治,部分是因为他们与美国主导的供应链其他部分的关系,ASML 已被禁止向中芯国际和其他**代工厂出售 EUV 机器。
[
图 11:Gartner 和 Bernstein 分析(2019 年)
我上面描述的大部分是 semicap 的“前端”。“中端”和“后端”多为先进封装(晶圆级)和传统封装。这主要是 KLA-Tencor、Teradyne 和 FormFactor 的领域。它涉及用于测量、包装、组装和测试的设备。我向有兴趣的人推荐mule关于高级封装的文章和Christopher Seifel的行业概述。
对于关于开发链每个阶段的相对成本的(过时的)讨论,我推荐gwern关于摩尔定律的讨论,以及Brown和Linden 的这篇研究论文。每个先进制造厂的成本估计在 5 到150 亿美元之间,并且每 4 年左右翻一番。
**要发展独立的供应链,就必须规避这种对半导体的依赖。单独发展代工厂很难,但同时在全球范围内应对一系列边缘垄断者是一项非常艰巨的任务。既然我们知道_**_想要颠覆什么,那么让我们来看看_为什么_。
**此举的“原因”。它归结为市场需求和战略重点的结合。**不想依赖世界其他地区,对芯片有大量需求(现在和未来),尤其是随着人工智能发展的增长。
**进口的芯片比石油还多。
正如我们稍后将看到的,他们还明确表示,他们希望在人工智能和工业自动化领域引领世界。这使得半导体不仅是国际紧张局势加剧的最大瓶颈,也是实现技术增长目标的最大制约因素。
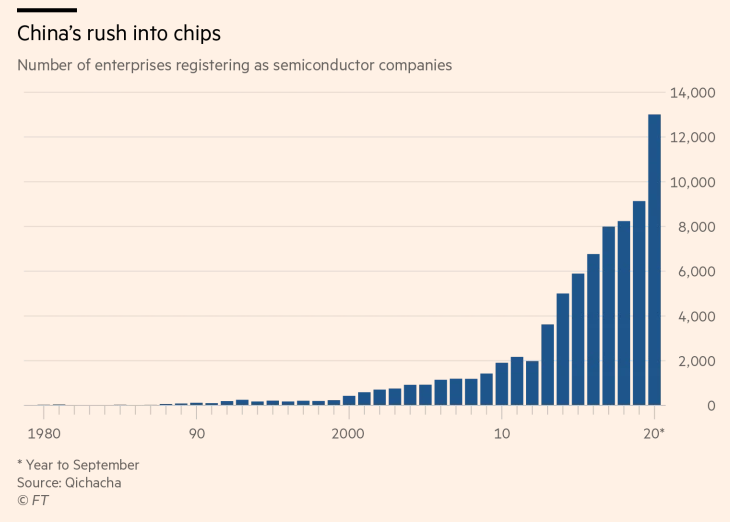
正因为如此,半导体制造已成为国家重点。在过去十年中,注册为半导体公司的公司数量增长了 700% 以上(图 12)。国家和私人机构都在投入资金来建立这种能力。这不仅仅是**驱动的行政命令。在华盛顿禁止华为使用 Cadence & Synopsys 的 EDA 平台之后,**公司内部也存在相当大的私人担忧,即美国可能会禁止哪些人。
那么,什么会激励**向单一行业投入730 亿美元呢?部分原因与激励台积电在三年内投资约 1000 亿美元以增加研究和产能的原因相同。因为需求量很大。然而,就**而言,部分原因还在于它是战略政策。
[
图 12:**“半导体企业”数量(金融时报,2020)
**围绕特定行业进行大量炒作并非完全新颖。轻松融资、国家利益、地方利益_和_市场需求的结合,都为特定行业创造了令人振奋的嗡嗡声。在遥远的过去,它是创业和城市化。在过去的几年里,它是人工智能和大数据。今天是半导体。
从主题上看,该行业对美中脱钩的想法充满热情。在美国严重依赖**进行低端生产(例如用于 COVID-19 救济的大部分关键医疗设备和 N95 口罩)的情况下,**对半导体的依赖也有所回报。如前所述,大部分半导体和无晶圆厂公司都位于美国,大多数代工厂都优先考虑与美国的关系,但大部分需求来自**。
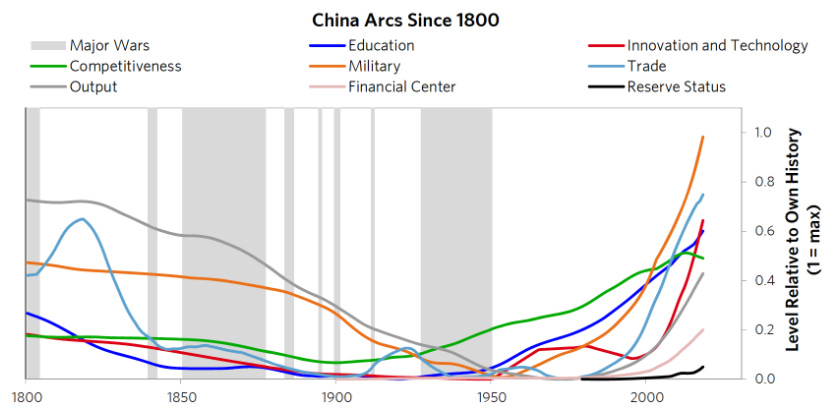
这两个国家如何驾驭贸易和动态超出了本文的范围。YouTube 上的亚洲协会有一系列由政策制定者和行业领袖就_美国和**的未来进行的小组讨论_。我推荐这一集关于技术的关于半导体的讨论。雷·达里奥(Ray Dalio)的_《不断变化的世界秩序》_ 很好地解读了几个世纪以来权力从一个国家到另一个国家的转变。达利欧书中的结论是,权力确实发生了转变,随着权力的转变,会出现一些关键的发展模式。
[
图 13:世界大国的兴衰模式(Ray Dalio ,2020)
[
图 14:**沿着不同的弧线发展(Ray Dalio ,2020)
所以,是的,**寻求技术独立是为了争取国家权力。这也是几千年来不同帝国的国家一个国家上演的事情。我意识到在世界历史的背景下讨论半导体有点夸张。然而,鉴于芯片对我们世界的未来至关重要,它可能是围绕这个行业可以拥有的最重要的框架。半导体制造不同于汽车制造。赢家通吃的情况要多得多,一旦赢家根深蒂固,就更难更换赢家。
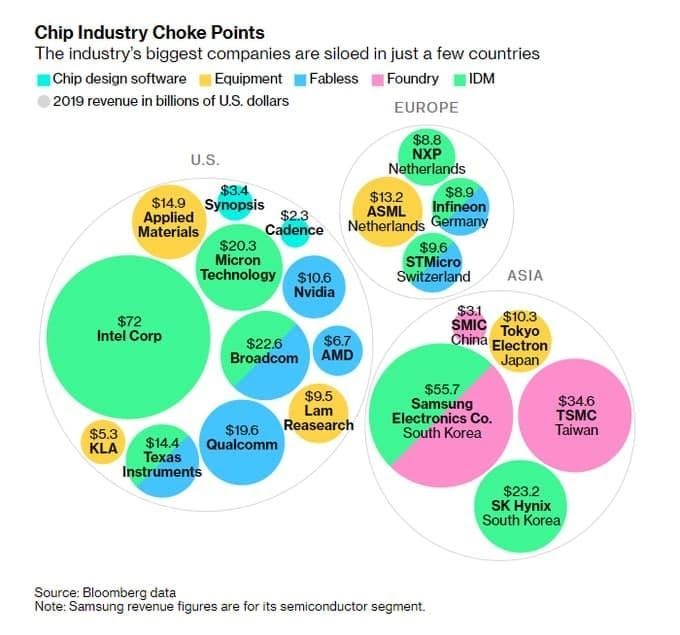
鉴于当今美国电力行业的集中度,**的电力竞标需要进一步确定。看图 15,很容易看出**如何将内部半导体能力和安全供应视为与其经济和国家安全有着内在联系的。这并非没有道理:近年来,美国的政策越来越多地针对**供应链的脆弱性。这是一个先有鸡还是先有蛋的局面。**希望内部化,因为美国想要阻止**不断增长的实力。美国想要阻止**内部化,因为它让**变得更强大。
[
图 15:按收入规模划分的半导体公司(Bloomberg,2019 年)
在 COVID-19 成为媒体头条之前,“科技冷战”风靡一时。最近,华为和其他几家**计算巨头被禁止使用美国设备制造其内部处理器。由于Lam,KLA和AMAT在这里基本上是垄断者,而台积电(华为最大的合作伙伴)在半导体方面严重依赖它们,因此华为基本上被芯片行业淘汰了。
对于许多较小的**公司来说,这样的政策可能会抹杀之前的市场领导者,这是一件令人担忧的事情。因此,推动技术自治不仅仅是国家主导的。许多较小的市场参与者也在努力平衡他们现有的美国关系和在另一项政策修订的情况下发展当地的应急措施。重要的是要看到,这不仅仅是一个异想天开的***选择对**政权下注。相反,这是国家安全指令、现有市场成员在其供应链中引入冗余以及大量新进入者追逐轻松补贴的共同努力。
我在腾讯的深潜中写道:
“ **的第十四个五年计划 包括以技术为中心的重点,其中提到了区块链和金融科技。将这些作为流行语很容易写下来,但政府将 4IR 技术列为战略重点,这表明自上而下大力推动在其中许多领域的全球领导地位。**知道他们在制造业方面具有竞争优势,并希望通过开发这些用例来推动这一发展。分布式账本技术可以改善供应链,云计算可以连接价值链的不同点(参见上下文:超越微信——制造),人工智能和物联网逐步实现生产自动化。”
您可以在此处找到第 14 届 5YP 的中文版,其中英文注释突出显示了半导体部件,由 Covington Research 提供。**特色的读者可能已经熟悉该计划。第 14 个计划涉及半导体制造的几个特定领域,将受到特别关注:
在本文的第 2 部分中,我将解开一些源自 5YP 的较低级别的政策。
到目前为止,我已将**的半导体独立作为一项国家战略,将冗余注入数百家企业的供应链,以防止美国依赖美国。还有另一个动机:市场需求量太荒谬了。
有许多来源给出了为什么半导体需求方面将出现空前增长的众多原因。_ _ 这些来自 Lam Research 投资者日的图表很好地概括了整个行业的_时代精神。_至于当前的需求,毕马威的 2021 年行业展望显示了一些驱动因素。这几乎是你所期望的——任何有技术的东西在某种程度上都依赖于半导体。
在全球范围内,我们正在生成比以往更多的数据,训练比以往更好的 AI/ML 模型,并且通过 5G 的推出,使用比以往更多的东西来收集、发送和接收数据。这是物联网的基础。自动驾驶汽车、深度学习、机器人技术、工业自动化、数据中心需求、云计算、AR/VR 和加密货币方面的进步越来越大。
[
图 16:Lam Research 投资者日(2020 年;数字未按比例)
[
图 17:毕马威全球半导体行业展望(2021 年)
弗拉基米尔·普京在 2017 年发表了评论,“谁成为人工智能的领导者,谁就会成为世界的**者”。《人工智能超能力》的作者李开复认为_:“人工智能将比人类历史上的任何事情都更能改变世界。不仅仅是电力。”_
目前,**在人工智能出版物和专利方面处于世界领先地位,约占全球发表的关于该主题的研究论文总数的 28%。仅靠研究并不能提供持久的优势,但数据生成、数据管理和计算机科学人才可以。
在阿里巴巴、腾讯和字节跳动之间,**的计算机科学生态系统是世界上最好的。当国家强制要求时,隐私问题也少得多。**庞大的数据库(主要由其科技巨头编制)是**处于人工智能发展前沿的关键原因4 。
在这份 Seagate报告中,所生成数据的全球增长率约为 26%。**是30%左右。到 2025 年,**将成为全球生成和获取数据最多的国家——主要由拥有如此多的互连设备驱动。
希捷预计,到 2025 年,世界上每个连接的人(当时约占总人口的 75%)每天将使用超过 4,900 次数据,大约每 18 秒一次。引用Westfield Capital Management 的话:
“当今世界上 90% 的可用数据是在过去 2 年中生成的——预计到 2025 年将增长到 180 zettabytes(即 21 个零)。将 zettabyte 放入上下文中,仅存储一个 zettabyte 需要 1,000 个数据中心,或大约 20% 的曼哈顿土地面积”。
所有这些数据都是人工智能研究的关键。这就是为什么**的技术独立对其经济如此重要的原因。Kaplan et有一份白皮书。人。关于神经语言模型(人工智能技术)如何扩展。总结一下:
模型的性能与规模相关。除了模型架构之外,规模还与:
参数的数量,
数据集的大小,以及
可用的计算量。
这可能会持续一段时间,至少在我们达到该比例关系的上限之前是这样。这是缩放假设,它很有争议。
如此处提出的想法是,一旦我们找到一个可扩展的架构,就像大脑一样,可以相当统一地应用,我们可以简单地训练更大的神经网络,更复杂的行为就会自然而然地出现。更强大的神经网络“只是”放大的弱神经网络,就像人类大脑看起来很像 放大的灵长类动物大脑一样。
[
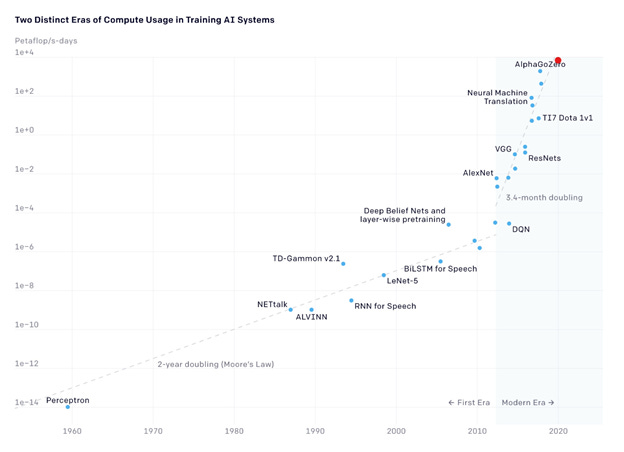
图 18:GPT-3,迄今为止训练过的最强大的 AI,是红点(~3624 petaflop/s-days;OpenAI via mule ;2020)
因此,这里的三个约束是数据、计算和这两者的美元成本。让我们假设成本对于大型科技公司或积极主动的主权者来说不是问题。因此,约束是数据和计算。但是我们已经确定,我们几乎无法跟上我们正在生成的数据,所以真正的计算(存储和处理)是主要的限制因素。
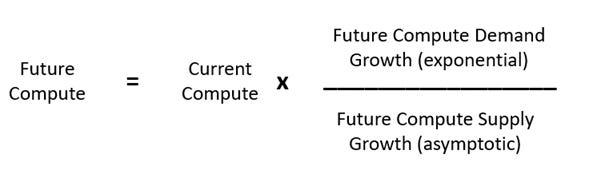
未来计算的消耗方程将如下所示:
[
图 19:未来计算消耗方程(mule ,2020)
如果训练模型开始为扩展而扩展,那么对计算的需求将会非常陡峭。然而,抛开需求呈指数增长这一事实(我们将回到这一点),让我们来看看未来的供应增长。
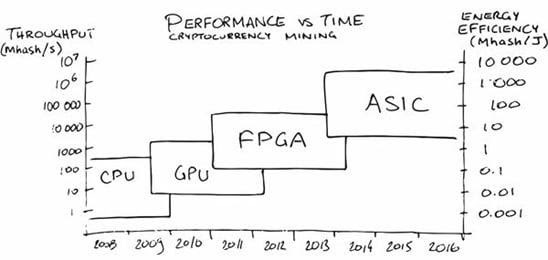
为了改善未来的计算供应,我们过去依赖几何缩小和功率缩放。但我们在这两个问题上都碰壁了。芯片,至少是那些建立在硅上的芯片,不会比假设的 1nm 小很多。所以我们要么在非硅(如GaN或石墨烯)上构建芯片,这意味着我们需要一个全新的技术堆栈。或者我们通过异构计算取得进展(正如我们在 CPU 到 GPU 到 ASIC 的进展中所做的那样)。
[
图 20:异构计算的进展(mule ,2020)
异构计算是构建特定用途芯片的一种奇特方式,它的工作原理是制造真正擅长某件事的芯片,但仅此而已。Fuchs 和 Wentzlaff对这种方法的可能限制进行了研究,TL;DR 是各种应用程序将具有不同的收益递减率,但所有的收益都会随着时间的推移而减少。这里也有限制。
另一个建议是把一堆“愚蠢”的芯片堆叠在一起,并通过拥有大量芯片来蛮力算法。最大的问题是能源成本。虽然让一堆低效的芯片一起工作可以完成非常复杂的算法,但算法越先进,这种方法就变得越昂贵。这使得它从长远来看是不可持续的,而且目前在经济上也没有竞争力。
归根结底,这是一个马尔萨斯指数增长(需求)在渐近高原(供应)。半导体现在很有价值,计算不是当前的限制。未来,计算肯定会成为制约因素,而半导体将变得更加重要。
目前,与逻辑处理相比,许多 AI/ML 项目更受输入/输出速度的限制。解决这个问题意味着拥有更好的内存速度。这可能以自动内存缓存的形式出现,但更有可能意味着 NAND 和 DRAM 的增长。无论哪种方式,如果公司或国家想要开发具有竞争力的人工智能流程——**也这样做——那么他们_必须_控制自己的计算和内存供应。
我们已经讨论了“什么”和“为什么”。接下来我们将看看“谁”、“如何”和“何时”。这是一个微妙的空间,不同的派对都想要不同的东西。这将在第 2 部分中介绍。
第 1 部分到此结束。我们讨论了全球半导体行业、开发完全独立供应链的高成本、挑战和限制,以及需要构建的各种流程。这就是_**_试图破坏的东西。
我们还研究了**_为何_试图破坏它。在努力满足市场需求、保持国家韧性以及争取控制本世纪最重要的资源方面,**对半导体产能的渴望既是必要的,也是微妙的。说“**的愿望”意味着有一个庞大的实体在稻田里大声疾呼,宣扬着全**的蜂巢式意图。这是非常不准确的。
**是由无数政党组成的。企业,无论是公共的还是私人的,都有全球和本地的关系。他们受到人民、家庭和各级政府的影响。试图平衡这些关系是很困难的。许多企业因国家对“半导体”品牌公司的高估值而兴奋不已。其他人则谨慎行事,试图平衡与美国和**供应商的关系,同时避免美国的制裁并遵守政治局的本地化要求。总之,它可能与您熟悉的任何业务非常相似。
试图解开**新兴产业的动态将是本文第 2 部分的尝试。在此之前,感谢您的阅读。
by Henry Robinson, April 26, 2010
The ‘CAP’ theorem is a hot topic in the design of distributed data storage systems. However, it’s often widely misused. In this post I hope to highlight why the common ‘consistency, availability and partition tolerance: pick two’ formulation is inadequate for distributed systems. In fact, the lesson of the theorem is that the choice is almost always between sequential consistency and high availability.
It’s very common to invoke the ‘CAP theorem’ when designing, or talking about designing, distributed data storage systems. The theorem, as commonly stated, gives system designers a choice between three competing guarantees:
This is often summarised as a single sentence: “consistency, availability, partition tolerance. Pick two.”. Short, snappy and useful.
At least, that’s the conventional wisdom. Many modern distributed data stores, including those often caught under the ‘NoSQL’ net, pride themselves on offering availability and partition tolerance over strong consistency; the reasoning being that short periods of application misbehavior are less problematic than short periods of unavailability. Indeed, Dr. Michael Stonebraker posted an article on the ACM’s blog bemoaning the preponderance of systems that are choosing the ‘AP’ data point, and that consistency and availability are the two to choose. However for the vast majority of systems, I contend that the choice is almost always between consistency and availability, and unavoidably so.
Dr. Stonebraker’s central thesis is that, since partitions are rare, we might simply sacrifice ‘partition-tolerance’ in favour of sequential consistency and availability – a model that is well suited to traditional transactional data processing and the maintainance of the good old ACID invariants of most relational databases. I want to illustrate why this is a misinterpretation of the CAP theorem.
We first need to get exactly what is meant by ‘partition tolerance’ straight. Dr. Stonebraker asserts that a system is partition tolerant if processing can continue in both partitions in the case of a network failure.
“If there is a network failure that splits the processing nodes into two groups that cannot talk to each other, then the goal would be to allow processing to continue in both subgroups.”
This is actually a very strong partition tolerance requirement. Digging into the history of the CAP theorem reveals some divergence from this definition.
Seth Gilbert and Professor Nancy Lynch provided both a formalisation and a proof of the CAP theorem in their 2002 SIGACT paper. We should defer to their definition of partition tolerance – if we are going to invoke CAP as a mathematical truth, we should formalize our foundations, otherwise we are building on very shaky ground. Gilbert and Lynch define partition tolerance as follows:
“The network will be allowed to lose arbitrarily many messages sent from one node to another”
Note that Gilbert and Lynch’s definition isn’t a property of a distributed application, but a property of the network in which it executes. This is often misunderstood: partition tolerance is not something we have a choice about designing into our systems. If you have a partition in your network, you lose either consistency (because you allow updates to both sides of the partition) or you lose availability (because you detect the error and shutdown the system until the error condition is resolved). Partition tolerance means simply developing a coping strategy by choosing which of the other system properties to drop. This is the real lesson of the CAP theorem – if you have a network that may drop messages, then you cannot have both availability and consistency, you must choose one. We should really be writing Possibility of Network Partitions => not(availability and consistency), but that’s not nearly so snappy.
Dr. Stonebraker’s definition of partition tolerance is actually a measure of availability – if a write may go to either partition, will it eventually be responded to? This is a very meaningful question for systems distributed across many geographic locations, but for the LAN case it is less common to have two partitions available for writes. However, it is encompassed by the requirement for availability that we already gave – if your system is available for writes at all times, then it is certainly available for writes during a network partition.
So what causes partitions? Two things, really. The first is obvious – a network failure, for example due to a faulty switch, can cause the network to partition. The other is less obvious, but fits with the definition from Gilbert and Lynch: machine failures, either hard or soft. In an asynchronous network, i.e. one where processing a message could take unbounded time, it is impossible to distinguish between machine failures and lost messages. Therefore a single machine failure partitions it from the rest of the network. A correlated failure of several machines partitions them all from the network. Not being able to receive a message is the same as the network not delivering it. In the face of sufficiently many machine failures, it is still impossible to maintain availability and consistency, not because two writes may go to separate partitions, but because the failure of an entire ‘quorum’ of servers may render some recent writes unreadable.
This is why defining P as ‘allowing partitioned groups to remain available’ is misleading – machine failures are partitions, almost tautologously, and by definition cannot be available while they are failed. Yet, Dr. Stonebraker says that he would suggest choosing CA rather than P. This feels rather like we are invited to both have our cake and eat it. Not ‘choosing’ P is analogous to building a network that will never experience multiple correlated failures. This is unreasonable for a distributed system – precisely for all the valid reasons that are laid out in the CACM post about correlated failures, OS bugs and cluster disasters – so what a designer has to do is to decide between maintaining consistency and availability. Dr. Stonebraker tells us to choose consistency, in fact, because availability will unavoidably be impacted by large failure incidents. This is a legitimate design choice, and one that the traditional RDBMS lineage of systems has explored to its fullest, but it implicitly protects us neither from availability problems stemming from smaller failure incidents, nor from the high cost of maintaining sequential consistency.
When the scale of a system increases to many hundreds or thousands of machines, writing in such a way to allow consistency in the face of potential failures can become very expensive (you have to write to one more machine than failures you are prepared to tolerate at once). This kind of nuance is not captured by the CAP theorem: consistency is often much more expensive in terms of throughput or latency to maintain than availability.Systems such as ZooKeeper are explicitly sequentially consistent because there are few enough nodes in a cluster that the cost of writing to quorum is relatively small. The Hadoop Distributed File System (HDFS) also chooses consistency – three failed datanodes can render a file’s blocks unavailable if you are unlucky. Both systems are designed to work in real networks, however, where partitions and failures will occur*, and when they do both systems will become unavailable, having made their choice between consistency and availability. That choice remains the unavoidable reality for distributed data stores.
Further Reading
*For more on the inevitably of failure modes in large distributed systems, the interested reader is referred to James Hamilton’s LISA ’07 paper On Designing and Deploying Internet-Scale Services.
Daniel Abadi has written an excellent critique of the CAP theorem.
James Hamilton also responds to Dr. Stonebraker’s blog entry, agreeing (as I do) with the problems of eventual consistency but taking issue with the notion of infrequent network partitions.
原文:http://blog.cloudera.com/blog/2010/04/cap-confusion-problems-with-partition-tolerance/
$ jstat -gcutil -h4 <pid> [<interval> <count>]
| Column | Description |
|---|---|
| S0 | Survivor space 0 utilization as a percentage of the space's current capacity. |
| S1 | Survivor space 1 utilization as a percentage of the space's current capacity. |
| E | Eden space utilization as a percentage of the space's current capacity. |
| O | Old space utilization as a percentage of the space's current capacity. |
| P | Permanent space utilization as a percentage of the space's current capacity. |
| YGC | Number of young generation GC events. |
| YGCT | Young generation garbage collection time. |
| FGC | Number of full GC events. |
| FGCT | Full garbage collection time. |
| GCT | Total garbage collection time. |
Formally, an RDD is a read-only, partitioned collection of records.
RDDs provide a restricted form of shared memory, based on coarse grained transformations rather than fine-grained updates to shared state.
RDDs can only be created through deterministic operations on either
We call these operations transformations to differentiate them from other operations on RDDs. Examples of transformations include map, filter, and join.
Finally, users can control two other aspects of RDDs:
persistence and partitioning.

In a nutshell, we propose representing each RDD
through a common interface that exposes five pieces of
information:
a set of partitions, which are atomic piecesa set of dependencies on parent RDDsa function for computing the dataset based on its parents;metadata about its partitioning schemeFor example, an RDD representing an HDFS file has a partition for each block of the file and knows which machines each block is on. Meanwhile, the result of a map on this RDD has the same partitions, but applies
the map function to the parent’s data when computing its elements.

参考:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.



































































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}