jrzaurin / pytorch-widedeep Goto Github PK
View Code? Open in Web Editor NEWA flexible package for multimodal-deep-learning to combine tabular data with text and images using Wide and Deep models in Pytorch
License: Apache License 2.0
A flexible package for multimodal-deep-learning to combine tabular data with text and images using Wide and Deep models in Pytorch
License: Apache License 2.0


































































































































At the moment there are two inconsistencies of different nature:
TabTransformer model are called blks. However, if you install from github those blocks are called tab_transformer_blks, which is a name more consistent with the other two models (TabMlp and TabResnet). This inconsistency will be fixed in the coming releaseTabResnet model are named tab_resnet. A more consistent name would be tab_resnet_blksAll this needs to be fixed in the next version
Hello everyone.
Can I customize the loss function? Train the model?
good luck
Hello, I would like to use the widedeep model together with pytorch-metric-learning, which uses (embedding, label) pairs. Is it possible to extract the embedding from the model in an easy fashion, e.g. perhaps with like an identity head component?
Thank you!
Hi, I think it is a corner case if seq = [] when preprocessing texts. It could lead to error in the following line.
Currently the default text component is simply a stack of LSTMs:
while the image component component can be a pretrained ResNet:
In an ideal situation, the text component could also be a pre-trained architecture, maybe the AWD-LSTM replicating the code in the ULMFit paper and available in the fastai library. Maybe bringing BERT and company, or the SHA-RNN.
The DeepDense component is at the moment a series of dense layers:
It would be good to offer the possibility of using Resnet blocks as well, as they do in packages like AutoGluon Tabular their Figure 1.
Hey, I'm trying to write a custom metric to allow computing AUC score after each epoch's end. I tried using torchmetric's AUC but it seems that the attribute num_classes is required and I can't set it on torchmetric's AUC.
It seems weird since for Accuracy num_classes is inferred from the shape of y_pred and I can't set num_classes on it as well.
This is where I am so far:
from pytorch_widedeep.metrics import Metric
from sklearn.metrics import roc_auc_score
class CustomAUC(Metric):
def __init__(self, num_classes): # here I'm forcing the parameter on init
if num_classes > 2:
raise ValueError("AUC for multiclass problems is not currently supported.")
self.num_classes = num_classes
self._name = "auc"
def reset(self):
# I don't know what should be put here
pass
def __call__(self, y_pred, y_true):
yp = y_pred.clone().detach().cpu().numpy()
yt = y_true.clone().detach().cpu().numpy()
return roc_auc_score(yt, yp)
Right now is working but I was wondering if there is (it surely does) a better way to write this piece of code. Suggestions are welcomed!
Thank you, awesome library
first of all. thanks for your work. I am a little confuse about the split of the wide and deep feature. embeddings_cols, continuous_cols, standardize_cols, wide_cols, crossed_cols, already_dummies. embeddings_cols is the category feature. continuous_cols is continuous feature. what's the different between standardize_cols and continuous_cols? the wide_cols feature is similar to the category feature. crossed_cols I know you want to get the interaction feature.how to select the element to constitute interaction feature? thanks in advance.
Good day! I was wondering if we could use 'softmax' activation function for classification problems? I was trying to use TabResnet and FTTransformer for multi-class classification problem and the last layer is a linear. I was hoping if I can apply 'softmax'? or is it automatically implied?
Thanks.
when i import packages, it occurs this error:
from pytorch_widedeep import Trainer
ImportError: cannot import name 'Trainer'
why is that happening?
This new model would be great to implement: https://arxiv.org/abs/2106.01342
They mention that they even found performance improvements in the TabTransformer architecture by embedding continuous variables (variable-specific linear layer to go form 1 -> n_embeddings). I have made a fork and implemented this as an option in tab_transformer. Okay to make a PR?
hello,i want to know why the input need to be "input = torch.cat([1 - input, input], axis=1)",what the meaning of 1-input. the input should be original input that not the sigmoid result,because you use F.binary_cross_entropy_loss_withlogits instead of binary_cross_entropy.
The issue is related to the use of F.binary_cross_entropy_with_logits instead of F.binary_cross_entropy. The problem is that I use a sigmoid activation in the case of a binary classification and no activation for a multiclass problem. Therefore, although the use of F.binary_cross_entropy_with_logits is correct for multiclass, is not the case for binary.
also the method get_weight applies a sigmoid activation to the entries, which is only correct for multiclass.
Need to fix all this
See here:
The idea is to use simple attention mechanisms for those simple(r) models to help with model interpretability. See branch.
hello,Javier:
you do a good job, thank you very much. but still a little suggestions, most people usually meet extremely imbalanced data, maybe recall metrics will be better than accuracy, so in order to improve the effect ,you can add recall or precision metrics ~
thank you again for you contribution~
train_set and test_set both use preprocess_wide built by WidePreprocessor(wide_cols=wide_cols, crossed_cols=cross_cols)
exception occupied when i save model toch.save(model, a.model) and then use toch.load(a.model) and then preprocess_wide.transform to predict my label.
exception like this:
This WidePreprocessor instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator.
please help me !
Add losses that show promising results for regression prediction in scenarios with highly imbalanced datasets used e.g. in Life Time Value prediction
Getting the following error while training.
File "train.py", line 58, in <module>
val_split=0.1,
File "/Users/shin/miniconda3/envs/transaction_env/lib/python3.7/site-packages/pytorch_widedeep/training/trainer_utils.py", line 284, in __call__
return wrapped(*args, **kwargs)
File "/Users/shin/miniconda3/envs/transaction_env/lib/python3.7/site-packages/pytorch_widedeep/training/trainer_utils.py", line 284, in __call__
return wrapped(*args, **kwargs)
File "/Users/shin/miniconda3/envs/transaction_env/lib/python3.7/site-packages/pytorch_widedeep/training/trainer_utils.py", line 284, in __call__
return wrapped(*args, **kwargs)
[Previous line repeated 10 more times]
File "/Users/shin/miniconda3/envs/transaction_env/lib/python3.7/site-packages/pytorch_widedeep/training/trainer.py", line 577, in fit
train_score, train_loss = self._train_step(data, targett, batch_idx)
File "/Users/shin/miniconda3/envs/transaction_env/lib/python3.7/site-packages/pytorch_widedeep/training/trainer.py", line 993, in _train_step
y = target.view(-1, 1).float() if self.method != "multiclass" else target
AttributeError: 'tuple' object has no attribute 'view'
main inspiration : https://towardsdatascience.com/five-tips-for-automatic-python-documentation-7513825b760e
integrate Deep Imbalanced Regression into the library https://github.com/YyzHarry/imbalanced-regression
Hi pytorch_widedeep team,
First of all thank you for your contributions to the wide_deep field. Recently I am doing a task about classification. The essence is similar to the predicted adult salary level shown in the example in the project readme. All of my input data has been processed as numerical values. The data contains continuous values and some indicators are discrete values (such as: 0,1,2...). In addition, the data contains missing values. My task is a five-category problem.
Question one:
I used the code used to predict adult wages in the readme, changed the data input part and changed "binary" to "multiclass" to adapt to my task.When I executing the following code:
wide_preprocessor = WidePreprocessor(wide_cols=wide_cols, crossed_cols=cross_cols)
X_wide = wide_preprocessor.fit_transform(df_train)
wide = Wide(wide_dim=np.unique(X_wide).shape[0], pred_dim=1)
tab_preprocessor = TabPreprocessor(embed_cols=embed_cols, continuous_cols=cont_cols)
X_tab = tab_preprocessor.fit_transform(df_train)
deeptabular = TabMlp(
mlp_hidden_dims=[64, 32],
column_idx=tab_preprocessor.column_idx,
embed_input=tab_preprocessor.embeddings_input,
continuous_cols=cont_cols,
)
model = WideDeep(wide=wide, deeptabular=deeptabular)
I got the following error: "RuntimeWarning: invalid value encountered in true_divide". I understand that it is caused by the occurrence of 0 divided by 0, but the error message given by the code is not enough for me to locate the problem segment. I would like to ask how to solve the problem?
Question two:
In the process of using the function to divide the training set into the validation set:
trainer = Trainer(model, objective="multiclass", metrics=[Accuracy])
trainer.fit(
X_wide=X_wide,
X_tab=X_tab,
target=target,
n_epochs=15,
batch_size=16,
val_split=0.1,
)
I reported the error "IndexError: index 648 is out of bounds for axis 0 with size 530" exceeding the index range of the training set. I have no solution.
Upload the source code to the attachment, and see the ipynb file running results for detailed error information. Looking forward to your answer~
liver_predict.zip
In the implementation of TensorFlow, wide part uses FTRL and deep part uses AdaGrad.
Wide part and deep part use one optimizer in your implementation. How to use different optimizer ?
Thank you.
when I use joblib to dump the preprocess_deep and preprocess_wide:
from joblib import dump, load
...
# deepdense
preprocess_deep = DensePreprocessor(embed_cols=embed_cols, continuous_cols=cont_cols)
X_deep = preprocess_deep.fit_transform(df_train)
# dump my preprocess_deep
dump(preprocess_deep, 'preprocess_deep.pkl')
deepdense = DeepDense(
hidden_layers=[64, 32],
deep_column_idx=preprocess_deep.deep_column_idx,
embed_input=preprocess_deep.embeddings_input,
continuous_cols=cont_cols,
)
...
preprocess_deep = load("preprocess_deep.pkl")
X_deep_te = preprocess_deep.transform(df_test)
error:
Traceback (most recent call last):
File "wide_deep_baseline_train.py", line 90, in
X_deep_te = preprocess_deep.transform(df_test)
File "/usr/local/lib/python3.7/site-packages/pytorch_widedeep/preprocessing/_preprocessors.py", line 273, in transform
df_emb = self.label_encoder.transform(df_emb)
File "/usr/local/lib/python3.7/site-packages/pytorch_widedeep/utils/dense_utils.py", line 98, in transform
df_inp[k] = df_inp[k].apply(lambda x: v[x])
File "/usr/local/lib64/python3.7/site-packages/pandas/core/series.py", line 4200, in apply
mapped = lib.map_infer(values, f, convert=convert_dtype)
File "pandas/_libs/lib.pyx", line 2402, in pandas._libs.lib.map_infer
File "/usr/local/lib/python3.7/site-packages/pytorch_widedeep/utils/dense_utils.py", line 98, in
df_inp[k] = df_inp[k].apply(lambda x: v[x])
KeyError: nan
first, thanks for the package!
i observed a strange behaviour when doing regression, maybe that's expected, but was not for me.
i tried to use transformations, so before i had:
train_transforms = []
model.compile (method = 'regression', .... transforms = train_transforms)
and then later with new data
model.predict (X_wide=..., X_deep=......)
this worked fine.
but after changing the transformations to
from torchvision import transforms as tf
train_transforms = [
tf.ToPILImage(),
tf.RandomCrop(512, padding=64),
tf.ToTensor()
]
model.compile (.... transforms = train_transforms)
suddenly i got much too high values when predicting. i figured that might stem from the transformations, so i added
transform_val = [
tf.ToPILImage(),
tf.ToTensor()
]
and added the 'transforms_val = transform_val' parameter to model.compile and changed def _predict in wide.deep.py accordingly:
if X_test is not None:
test_set = WideDeepDataset(**X_test, transforms=self.transforms_val) # type: ignore
else:
load_dict = {"X_wide": X_wide, "X_deep": X_deep}
if X_text is not None:
load_dict.update({"X_text": X_text})
if X_img is not None:
load_dict.update({"X_img": X_img})
test_set = WideDeepDataset(**load_dict, transforms=self.transforms_val)
this worked. was that change necessary or did i do something wrong and could have the same effect without changes?
Good day. I'm testing pytorch-widedeep on tabular data (specifically TabResnet). I followed the steps as shown here in this article: https://towardsdatascience.com/pytorch-widedeep-deep-learning-for-tabular-data-9cd1c48eb40d. When I attempted to run the code to instantiate WideDeep, an error shows saying WideDeep is not defined. I can't seem to find any workaround on this one. I was wondering if you could enlighten me on this. (Still new to this, sorry!) Thanks!
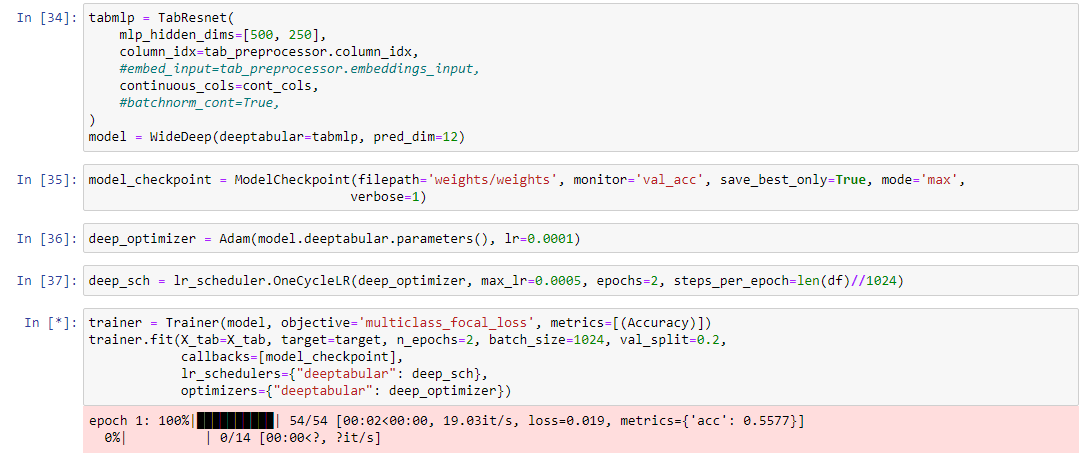
Good day! So I attempted to use the ModelCheckpoint callback in the hopes of saving the best weights throughout the training process. I was just testing so I temporarily placed 2 epochs as the number of epochs. When I checked the file folder (based on the filepath), I didn't find any '.pt' files. I checked the callbacks documentation and it seems that I didn't miss anything. May I ask if someone could enlighten me on this? I would appreciate your help!
(See screenshot below for reference)
Hi,
Thanks for the code. Where can I get the airbnb data? Is there a link?
Best regards!
Add simple uncertainty prediciton using Monte Carlo, ie DropOut, method using approach from following paper:
Hello, I was going through the sample tutorial notebooks provided by you. In the notebook: Save and Load Model and Artifacts,
when we want to evaluate our saved model on new data, you have kept "Target" in the dataframe which is in fact our Label column. The values from this column aren't available to us in the real-world and are something we are expecting our model to predict. How we are providing this as an input column (along with others) to the preprocessor, while this is something which we should be predicting instead? Is this correct?

Hi,
Sorry i'm new to this library but it seems to me that there is a lack of consistency in the transition between tabprocessor and deeptabular steps or at least it would be nice to have a snippet in the examples.
If I start with the most basic example for tabprocessor
df = pd.read_csv(...)
embed_cols = [...]
cont_cols = [...]
tab_preprocessor = TabPreprocessor(embed_cols=embed_cols, continuous_cols=cont_cols)
X_tab = tab_preprocessor.fit_transform(df)
Here's my concern:
This works
tabmlp = TabMlp(
mlp_hidden_dims=[200, 100],
column_idx=tab_preprocessor.column_idx,
embed_input=tab_preprocessor.embeddings_input,
continuous_cols=cont_cols,
)
outputs_mlp = tabmlp(torch.from_numpy(X_tab))
And this not
tabtransformer = TabTransformer(
mlp_hidden_dims=[200, 100],
column_idx=tab_preprocessor.column_idx,
embed_input=[(emb[0], emb[2]) for emb in tab_preprocessor.embeddings_input], # Here i already have to change embeddings format
continuous_cols=cont_cols
)
outputs_transformer = tabtransformer(torch.from_numpy(X_tab))
The error I get
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-7-fe7de00feead> in <module>
----> 1 embeddings = tabtransformer(torch.from_numpy(X_tab))
~/anaconda3/envs/matching/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
~/anaconda3/envs/matching/lib/python3.8/site-packages/pytorch_widedeep/models/tab_transformer.py in forward(self, X)
428 def forward(self, X: Tensor) -> Tensor:
429
--> 430 embed = [
431 self.embed_layers["emb_layer_" + col](
432 X[:, self.column_idx[col]].long()
~/anaconda3/envs/matching/lib/python3.8/site-packages/pytorch_widedeep/models/tab_transformer.py in <listcomp>(.0)
429
430 embed = [
--> 431 self.embed_layers["emb_layer_" + col](
432 X[:, self.column_idx[col]].long()
433 ).unsqueeze(1)
~/anaconda3/envs/matching/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
~/anaconda3/envs/matching/lib/python3.8/site-packages/torch/nn/modules/sparse.py in forward(self, input)
154
155 def forward(self, input: Tensor) -> Tensor:
--> 156 return F.embedding(
157 input, self.weight, self.padding_idx, self.max_norm,
158 self.norm_type, self.scale_grad_by_freq, self.sparse)
~/anaconda3/envs/matching/lib/python3.8/site-packages/torch/nn/functional.py in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)
1914 # remove once script supports set_grad_enabled
1915 _no_grad_embedding_renorm_(weight, input, max_norm, norm_type)
-> 1916 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
1917
1918
IndexError: index out of range in self
Thank you in advance for your help !
Initially, the activation function for a multi-class problems was F.softmax(). This is not necessary when using F.cross_entropy since the latter already applies a logSoftmax to the inputs.
I fix this for the .fit method but stills needs to be fixed for the predict_proba method.
Note that this will not change the accuracy metric since Softmax does not change argmax (i.e preserves the rank order of the inputs).
Hi! I have been getting state-of-the-art results from this library. So, kudos to the team!
I was wondering if I could use 'CUDA' or GPU as my device instead of CPU?
Thank you.
The models SAINT, FTTransformer and TabFastFormer contain the code
if self.n_cont and not self.n_cat and not self.embed_continuous:
raise ValueError(
"If only continuous features are used 'embed_continuous' must be set to 'True'"
)
The variable self.embed_continuous is not set anywhere, probably it has been used in an older version of the code and was then replaced by True later. For data sets without categorical features, this code raises an error. Removing this code should resolve the issue.
Hi! This is an amazing package, things are very clearly documented and very easy to use on any of my cases.
One question I have is how I can adapt the code here to a minibatch scenario. Looking into the trainer class definition, the fit method does initiate a custom dataloader on the dataset passed into it. So I should be able to write a custom dataloader to take care of data loading.
But where I need some pointers is how I can transform the data. The current code doesn't look like it can easily be adapted to handle partial fits, can you provide some suggestions?
##My thought on how to work around it:
I'm mainly using the TabPreprocessor. In the fit function, it first prepares embeddings for categorical features. If I create a dataframe that contains the same columns as real data and put in dummy examples that contain all possible combinations of categorical features it should work fine.
For the second step of standardizing continuous features, I'm thinking I can just write some dummy values before calling fit and overwriting the StandardScaler object with one that was already fit to all of my data.
Does this workaround seem like it would work to you? Any immediate concerns you might have? I'm currently working on this and will post any questions here. After this tight deadline, I'll also be happy to implement something more permanent to handle minibatches.
Thank you for the great work and sharing !
What is MLP? Multi-layer process? Multi Layer Perceptron?
The example in the DeepDense class doc string is missing continuous_cols param.
4 categorical columns and one continuous column are created, though when creating the network the continuous_cols is not specified so even though you pass a 5 column tensor to the model with model(X_deep) the result is not using the 5th column at all. For e.g if after running the example you do X_deep[:, 4]=0 and then run model(X_deep) again you get the same result as before.
Need to add the arg continuous_cols=['e'] to fix.
Sum: The original question mentioned that according to the project of "Predicting Adult Salary Levels", I changed the input classification category, "RuntimeWarning" appeared and split the validation set based on the training set and encountered the problem of exceeding the index. The original problem address is as follows:#68
(
)Is there any particular reason why an adding bias function is placed after a dropout function?
Is there a problem that occurs when the dropout function is placed after the adding bias function?
features like longitude and latitude should, a priori, not be standardised/normalised. This is why there is a parameter in the DeepPreprocessor already_standard to pass features that should not go through the standardise process.
In the Airbnb example, while the list already_standard is defined, is never used. Review the code and fix (either remove the definition or use the parameter)
Right now there is the assumption that the model needs to be comprised by at least the wide and the deep components.
The idea would be to allow the use of individual components alone
Hello, Javier.
Thank you very much.
You do a great job. It is so easy to use. I love your work.
I tried to use pytorch-widedeep to learn my own data, where there are about 30M unique ids.
I noticed that the wide model first builds one-hot-vectors and then inputs them to a dense layer, and found that the one-hot-encoder from sklearn costs a lot of memories.
I think maybe it is equal to input the index of the categories to an Embedding layer, which decreases the memory occupation. However, I am not sure how it will affect the performance.
At the moment the metrics are not reseted before evaluation which means that if you print metrics as well as losses, the metrics will be computed considering the entire dataset (this does not affect losses).
A fix will happen asap in the current version (will only be available in github) and there is a new version coming where it will also be fixed (available in both, github and pypi)
Hey , I was implementing this binary classification on adult census dataset using pytorch-widedeep in which I am trying to calculate AUROC metric using torchmetric's AUROC at the epoch's end but i am getting this error ,
trainer = Trainer(model, objective="binary", metrics=[AUROC])
trainer.fit( X_wide=X_wide, X_tab=X_tab, target=target, n_epochs=5, batch_size=64, val_split=0.2 )
TypeError: '>' not supported between instances of 'NoneType' and 'int'
Looking for help regarding this .
Thank you, awesome library
With your library, when I test it, your code doesn't seem to save the file for tab_preprocessor(standard scaler, laben ecoder).
Do you know where to save it?
At the moment the main class WideDeep is a gigantic class that does everything, builds the model, compile it, trains, validates, predict:
It would be useful for me to have someone else having a look to the code and discuss about other potential structures. For example, would it be useful to have a Warmer separated class to warm up different component and Trainer separated class to train/validate/predict?
how can I get the adult dataset?
In Scikit-learn a common workflow would be to define your hyperparameter space, the model to be tested and fit like that:
model_cv = RandomizedSearchCV(model(), hyperparameter_space, cv=cv, n_iter=n_iter)
model_cv.fit(x_train, y_train)
Now in pytorch-widedeep the recommended path for training a single model is:
trainer = Trainer(model, objective="binary", metrics=[Accuracy])
trainer.fit(X_wide=X_wide, X_tab=X_tab, target=target, n_epochs=5, batch_size=256, val_split=0.1)
So, how could I do a random search for the best hyperparameter of a model (for example: TabNet or TabTransformer) in a cross validated way ? If I just put the trainer object in the RandomizedSearchCV of the first example and define the hyperparameter space of the model could I make it work right ? If that's not possible, what would be other way to do it ?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.