jshttp / content-disposition Goto Github PK
View Code? Open in Web Editor NEWCreate and parse HTTP Content-Disposition header
License: MIT License
Create and parse HTTP Content-Disposition header
License: MIT License























































































































Highlighted part is not handled in parsing!
If this is meant to become the go-to solution for parsing content-disposition headers, it should ideally support as many optional features as possible.
One that should be relatively easy to support is continuations. See the test case:
attachment; filename*0="foo."; filename*1="html"
should be parsed as:
{type: 'attachment', parameters: {filename: 'foo.html'}}but is instead parsed as:
{type: 'attachment', parameters: {'filename*0': 'foo.', 'filename*1': 'html'}}Also note the next test case:
attachment; filename*0*=UTF-8''foo-%c3%a4; filename*1=".html"
This currently results in garbage as the encoding prefix is not parsed.
Thanks for this package! Would browser support be practical to implement? It would be great to use this library in browser extensions.
if content-disposition header only ends with ;
e.g.
contentDisposition.parse('attachment; filename="foo.bar";');TypeError: invalid parameter format
at Function.parse (/dummy/node_modules/content-disposition/index.js:369:11)
also, if not passed type
contentDisposition.parse('filename="foo.bar"');TypeError: invalid type format
at Function.parse (/dummy/node_modules/content-disposition/index.js:311:11)
I think need to able to parse without type too.
version of the lib: 0.5.1
According to my observations, if the Cyrillic alphabet has more than 42-43 characters, the library starts to work incorrectly
Hello,
Since I've installed backstopjs, I can't use anymore content-disposition correctly, as backstop installs the path package and content-disposition also uses it but without installing it.
Maybe this package was done only for node but it worked well also for as web oriented. But if you install path, it's broken.
Do you have any idea how to fix that? 😊
This question is legit only if you think your lib should also work for web, not only for node.
Thanks!
Suddenly npm install stopped working because of this error. Please double-check your latest version something is not quite right.
npm ERR! code ETARGET
npm ERR! notarget No matching version found for [email protected].
npm ERR! notarget In most cases you or one of your dependencies are requesting
npm ERR! notarget a package version that doesn't exist.
The following header cannot be parsed: "Attachment; filename=[torrent.cd].Big_Buck_Bunny_1080p.torrent"
var PARAM_REGEXP = /;[\x09\x20]*([!#$%&'*+.0-9A-Z^_`a-z|~-]+)[\x09\x20]*=[\x09\x20]*("(?:[\x20!\x23-\x5b\x5d-\x7e\x80-\xff]|\\[\x20-\x7e])*"|[!#$%&'*+.0-9A-Z^_`a-z|~-]+)[\x09\x20]*/g // eslint-disable-line no-control-regex
var match = PARAM_REGEXP.exec('attachment; filename=%E6%B4%BB%E5%8A%A8%E5%B9%B3%E5%8F%B0 - %E6%91%87%E4%B8%80%E6%91%87%E6%B4%BB%E5%8A%A8%E9%85%8D%E7%BD%AE.pptx')this cannot match space.
should change PARAM_REGEXP to:
var PARAM_REGEXP = /;[\x09\x20]*([!#$%&'*+.0-9A-Z^_`a-z|~-]+)[\x09\x20]*=[\x09\x20]*("(?:[\x20!\x23-\x5b\x5d-\x7e\x80-\xff]|\\[\x20-\x7e])*"|[!#$%&'*+.0-9A-Z^_`a-z|~-\s]+)[\x09\x20]*/g // eslint-disable-line no-control-regexand then in here, should decodeURIComponent the value:
// decode value like: "%2B" means "+", it's very normal.
params[key] = decodeURIComponent(value)Related to #13
Should parse fail when content-disposition header contains a parameter which field is not decodable ?
Today it fails. Shouldn't it only ignore the parameter and move on ?
BUG:
I receive header with filename with @ symbol.
Steps to reproduce:
ContentDisposition.parse("attachment; [email protected]");Expected Results:
Should works fine
Actual Results:
will throw Error invalid parameter format
The readme file mentions "ISO-8859-1" 10 times!
However, it looks that it confuses (based on how it works) "ISO-8859-1" aka "Latin1" aka "ByteString" with "ASCII string", which contains 0-127 bytes.
While ByteString contains 0-255 bytes.
For example, it can't produce the headers like it the most forums do.
Like this one:
https://xenforo.com/community/attachments/_圖片_🖼_image_-png.266690/?hash=b66fd2461d70a0c017941f3bcf7b5e4a
For filename _圖片_🖼_image_.png it produces String with:
inline; filename="_??_??_image_.png"; filename*=UTF-8''_%E5%9C%96%E7%89%87_%F0%9F%96%BC_image_.png
while it should be ByteString with:
inline; filename="_圖片_🖼_image_.png"; filename*=UTF-8''_%E5%9C%96%E7%89%87_%F0%9F%96%BC_image_.png
In the console it display so:
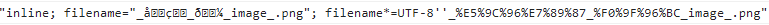
Yes, it's correct, since it's ByteString.
Then the code that parses the headers should convert this ByteString to String.
https://developer.mozilla.org/en-US/docs/Web/API/DOMString/Binary
https://webidl.spec.whatwg.org/#idl-ByteString
https://web.archive.org/web/20210608032047/https://developer.mozilla.org/en-US/docs/Web/API/ByteString
https://web.archive.org/web/20210731105134/https://developer.mozilla.org/en-US/docs/Web/API/Headers/get
v0.5.4
a file name may contain parenthesis, i.e: "myFile(1).jpg"
content-disposition does not support such file name.
This library will only generate the extended filename parameter if the filename is not representable in ISO-8859-1 (checking against NON_LATIN1_REGEXP).
However, some clients will not try to interpret the filename as ISO-8859-1. Chromium's Content-Disposition parsing code tries to interpret it as UTF-8, a referrer_charset, and the native OS default charset in turn. This ends up sometimes working for normal downloads in Chromium since it passes a referrer_charset that defaults to windows-1252. But this doesn't work for some other locales or cases where this referrer_charset isn't passed (like downloads in Electron).
It seems like it would be useful to generate the extended parameter when the utf8 and latin1 representations don't match.
Webpack v5 removed the Nodejs polyfills for the web client builds.
This package requires Node.js's path module.
That means if your frontend project is using this package and you want to upgrade to Webpack v5, you will have to install node-polyfill-webpack-plugin.
These polyfills are quite heavy: https://bundlephobia.com/package/[email protected]
Could we replace this line
Line 22 in 73bf21e
basename function?So I get a "invalid parameter format" exception with this
require('content-disposition').parse('attachment; filename="sample.zip";');
due to the trailing semicolon since the final check in the parse function
if (index !== -1 && index !== string.length) {
returns false, index is one less than string.length.
Now I don't know if the trailing semicolon is valid according to the spec but I got this from an actual webserver and browsers apparently don't mind.
I'd love to use this library to generate other content-dispositions headers in multipart messages. One of the use cases is form-data, where the individual fields have a content-disposition of form-data; name=fieldNameGoesHere.
This module has no problem parsing that, but it blows up when you try to generate a header without a filename.
To maintain backwards-compatibility as much as possible, I'd suggest making the filename argument optional if an options argument is provided instead, i.e.:
contentDisposition({type: 'form-data', {parameters: name: 'fieldNameGoesHere'}})
(Side note: I'd love to have the API actually be type, parameters rather than filename, options, but that would not only break backwards-compatibility, it'd also make the module less convenient for its original purpose (i.e. generating content-disposition headers for file attachments). I can only imagine this as a major version update with the old API as an additional method.)
Hey there, first thanks for this great library!
I can see that this library supports to generate the content-disposition header from a utf8 filename and allows parsing utf8 encoded filename from the header. But I can see that my browser (chrome 58) when uploading a file with a utf8 filename does not do a proper utf8 encoding of the filename (it looks like: Content-Disposition: form-data; filename="ö").
My current use-case is: I'm using this library as a middleware to parse the Content-Disposition header to upload a file to AWS-S3 and set the disposition header there as well. Now the parsing throws a "Invalid Format" exception. I feel it would be great if the lib would just accept this and can generate a valid utf8 encoded header when doing:
const parsed = contentDisposition.parse(headers['content-disposition']);
const header = contentDisposition(parsed.params.filename, { type: parsed.type });Would do you think about it?
I would like to use this library on a frontend to parse content disposition header and get only filename from it.
Unfortunately at the moment it's not possible to do while web pack cannot import modules that are not even suppose to be used:
var basename = require('path').basename
var Buffer = require('safe-buffer').Buffer
Module not found: Error: Can't resolve 'path' in '...\node_modules\content-disposition'
BREAKING CHANGE: webpack < 5 used to include polyfills for node.js core modules by default.
This is no longer the case. Verify if you need this module and configure a polyfill for it.
If you want to include a polyfill, you need to:
- add a fallback 'resolve.fallback: { "path": require.resolve("path-browserify") }'
- install 'path-browserify'
If you don't want to include a polyfill, you can use an empty module like this:
resolve.fallback: { "path": false }
ERROR in ./node_modules/content-disposition/node_modules/safe-buffer/index.js 4:13-30
Module not found: Error: Can't resolve 'buffer' in '..\content-disposition\node_modules\safe-buffer'
Would be nice if those modules are imported only when they are really required and allow to use regex part only separately.
Some tests in this project use deep-equal module instead of assert.deepEqual(), however deep-equal never throws, it just returns a boolean, so the tests with just deep-equal will never fail. Tests with deep-equal should probably use assert.ok().
not sure whether this shoulld be supported per spec but i get emails with the following content disposition:
attachment;\tfilename="Saturn_V__-_Kennedy_Space_Center_MyUglyPhotos.com_FullSize.jpg"
note the \t instead of a space. this seems unsupported. when i replace the tab with space it works fine.
var contentDisposition = require('content-disposition');
//error
contentDisposition.parse('attachment; filename="file.zip";');
//no error
contentDisposition.parse('attachment; filename="file.zip"');
/*
node_modules/content-disposition/index.js:369
throw new TypeError('invalid parameter format')
^
TypeError: invalid parameter format
at Function.parse (node_modules/content-disposition/index.js:369:11)
at Object.<anonymous> (content-disposition.js:3:20)
at Module._compile (module.js:541:32)
at Object.Module._extensions..js (module.js:550:10)
at Module.load (module.js:458:32)
at tryModuleLoad (module.js:417:12)
at Function.Module._load (module.js:409:3)
at Timeout.Module.runMain [as _onTimeout] (module.js:575:10)
at tryOnTimeout (timers.js:224:11)
at Timer.listOnTimeout (timers.js:198:5)
*/When getting a file from an image host (this one, specifically: https://api.typeform.com/responses/files/021c75a337027977e5a216a97c3a93de77e6706df6ff381f1bce6bc6ad0cc65d/A%CC%88laze.jpg) the content-disposition header is the following:
attachment; filename=f4f1ac339c07-�laze.jpg
Note the control character (\x84) before laze. When passed into contentDisposition.parse, an error is thrown.
I'm not sure if this is a bug on the image host's side (likely caused by the non-ASCII Ã) or this library (control characters should be allowed in filenames, but aren't).
If it's a bug here, I'm happy to expand the regex. Otherwise, feel free to close this issue and I'll talk to the server hosts.
Thank you!
Hiya. Is it in the scope of this module to parse (as opposed to generate) Content-Disposition headers? If not, have any suggestion of what to use instead?
I am getting invalid parameter format on this content-disposition header value:
inline; filename="beijing 6 copy 4.jpeg"; filename*=UTF-8''beijing 6 copy 4.jpeg
Not sure if this is correct according to the RFC or not, so please excuse if the issue is invalid. It does look funky though...
I'm using this great package to set the proper content disposition on files I upload to S3 using aws-sdk.
In some cases I get this error:
SignatureDoesNotMatch: The request signature we calculated does not match the signature you provided. Check your key and signing method.
The file I'm trying to upload has a non-breaking-space in it.
Here's the relevant aws-sdk issue
Hello,
I encountered a server that returns content-disposition: attachment; filename="file.png"; filename*=utf8''file.png which is, according to RFC 5987, malformed because the charset should be utf-8, rather than utf8. When trying to decode content-disposition, it will fail at
Line 286 in 9908a22
utf8 or fallback to filename) that would be appreciated.Those cause an exception, since the regex does not detect a valid parameter after that semicolon...
They could be removed using cd.replace(/;$/, '')
TIL how complicated encoding this header field could be 😅, man the internet feels broken with times.
It looks like the package was created in 2014, will it hit stable aka a major version anytime soon? What is preventing it from hitting a major version?
Can't use it in browser...
Module not found: Error: Can't resolve 'path' in 'node_modules/content-disposition'
http_filename: '小說名字.epub',
attachment: `attachment; filename="????.epub"; filename*=UTF-8''%E5%B0%8F%E8%AA%AA%E5%90%8D%E5%AD%97.epub`A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.