kevinzg / facebook-scraper Goto Github PK
View Code? Open in Web Editor NEWScrape Facebook public pages without an API key
License: MIT License
Scrape Facebook public pages without an API key
License: MIT License



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")





















































































































































































This is the code
for post in get_posts('iamforloveofwater', pages=50, extra_info=True):
#print (post)
print (post['text'][:100])
temp=pd.DataFrame(data=post)
dj=dj.append(temp,verify_integrity=False)
Error: ValueError: If using all scalar values, you must pass an index
e.g. https://www.facebook.com/groups/483818411801540/
there is nothing:
get_posts('groups/483818411801540', pages=1)
Is there a way to query for a keyword across all posts? Or do I have to pick a specific user page?
Add feature to extract post data from a user's timeline. It can be added as an additional parameter to the get_posts() method similar to the group parameter.
Just need to do
paragraphs = article.find('p', first=false)
and then loop through the paragraphs to append text
Hi, I have tried your library, very easy to use. However, while scraping the facebook groups, it doesn't return anything. I've tried with public groups too. Returns nothing and emptiness just like my 2019...xD
can you please look into this? Thanks.
I just installed the library and I'm trying to run the example at the README, but I get an error
Traceback (most recent call last):
File "/Users/fernandagomes/dev/deni_dashbot/main_executer.py", line 49, in <module>
for p in posts:
File "/Users/fernandagomes/dev/deni_dashbot/deni_env/lib/python3.6/site-packages/facebook_scraper.py", line 55, in get_posts
html = response.html
AttributeError: 'Response' object has no attribute 'html'
Any idea on why this is happening? I tried with many different pages.
Hi, the link of 'image' returned by get_posts is different from the link you get with 'show image' on browser and it gives back an image on a lower resolution.
Would it be possible to change it in order to get the highest resolution?
The facebook scraper seems to return NoneType on video post and flow an exception on this.
I've tried to run this code as it is, by providing my login credentials and the facebook group id. However, I'm not getting any response neither any message on the terminal. It's all blank. Can anyone here guide me?
Hi would it be possible to deal with posts with more than one image, maybe returning a list of images?
I want to get post text from https://www.facebook.com/doubledowncasino/ this fb page
I also tried with login credentials but not working help me please
get_posts('doubledowncasino', pages=2, credentials=('***@gmail.com','******'))
It happened since yesterday, I can't extract text from facebook page anymore
Background: https://stackoverflow.com/questions/50008296/facebook-json-badly-encoded
The text received can be encoded in latin_1/cp1251/utf-8.
I suffered from this page: https://www.facebook.com/mosburger.hk/
Temporaily workaround:
text = post['text']
try:
text = text.encode('latin_1').decode('utf-8')
except UnicodeEncodeError:
pass
except UnicodeDecodeError:
try:
text = text.encode('cp1251').decode('utf-8')
except:
passPlease, I have a group of pages that I want to capture posts. However, I discovered on the way that some of them are already disabled or no longer available. Example: https://www.facebook.com/DanielFreitasDeputadoFederal
In such a situation is there a way to automatically check beforehand if the page is available? And return some warning message
Or is it better to do it manually first?
This is my code.
from facebook_scraper import get_posts
for post in get_posts(group='EatsleeprepeatESR'):
print(post['text'][:50])
Gives this error :
TypeError: get_posts() got an unexpected keyword argument 'group'
What am I doing wrong?
The group data don't have a "post_time" field (return None). I fixed and pull request to your repo on #63
When "Continue Reading" is displayed in a post, only a fraction of the text is returned (when "see more" is displayed it works well).
I very much appreciate you work on this. Thank you.
There seems to be a limit of about 300 posts that are able to be collected. How can i remedy this and collect all of a persons posts ?
Thank You
Apparently after the login function run, later request still get the response as if the user hasn't logged in.
With one private group, I was able to scrape the posts (there are only 3 or 4 in the group) however in a larger private group with more activity where I am also an admin, I get an error of Couldn't get any posts.
Could it be a facebook group setting that differs between the group that works and the one that doesn't? I know the smaller group was recently created, and basically has the default facebook settings. Also I ran this again and outputted some of the html to a file, and now it is titled "Security Check". So I think it is presenting a captcha now.
I am getting this error. Never happened before.
json.decoder.JSONDecodeError: Extra data: line 1 column 4002 (char 4001)
Hi there,
Thanks for your great efforts. It's great to see this kind of package since FB changed its API policy last year.
I was trying to leverage your code to collect some data. The following is my code. However, when I executed my code, I got the "AttributeError: 'NoneType' object has no attribute 'html'. Do you know how to fix the issue?
d = []
for post in get_posts('Chrysler', pages=1000):
d.append({'time': post['time'], 'post_id': post['post_id'], 'text': post['text'][:20000], 'like':
post['likes'], 'comment':post['comments'],'share': post['shares'] , 'URL':post['post_url'], 'link':post['link']})
Obj1= pd.DataFrame(d)
Obj1.to_csv("fgc_Chrysler.csv")
Thank a lot!
from facebook_scraper import get_posts
for post in get_posts(group='234176430922917', credentials=('xxxx', 'xxxx')):
print(post)
When executing the above code, only about 20 posts are collected while the group has hundreds of new posts a day.
Moreover, the time of all posts is none. Is it normal?
Thank you very much.
Hi!
i get the following error trying to install with pip
Collecting facebook-scraper
Could not find a version that satisfies the requirement facebook-scraper (from versions: )
No matching distribution found for facebook-scraper
thanks!
for post in get_posts(group='EatsleeprepeatESR/', credentials={'email' : '[email protected]' , 'pass' : '*****************'}):
print(post['text'][:50])
This is my code. Despite of providing my correct credentials, it gives me error:
" warnings.warn('login unsuccessful')
UserWarning: login unsuccessful"
Please, I did:
from facebook_scraper import get_posts
for post in get_posts('cezinhademadureira', pages=1):
print(post['text'])
And for this page the return is empty. I noticed that it's an old page and hasn't been updated in a while. Is there a solution in these cases?
For longer post, only a fraction of the text is being returned. this is different from the issue #2 as more than one paragraph is being shown but not the full text. In my use cases, there seems to be a limit of around 700 characters after which "... more" is displayed at the end of the returned fraction.
Has anyone ran into this issue, any fix ?
Thank you
It would be useful to add author name for group posts
Hi!
Cannot find proxy support in the library, am I wrong?
Regards,
Vlad
It seems Facebook changed its code and the scraper is only getting 2 posts now.
I'll try to fix this over the weekend but if anyone has looked into it please share your findings here. PRs with a fix are also welcomed.
I noticed it pulls the total likes, is there a way to get the reactions specifically.
AttributeError: 'Element' object has no attribute 'tag'
Firstly, thank you so much giving us this amazing scraper, I really appreciate your hard work that went into building this.
Now to the issue:
https://www.facebook.com/littlekiteskerala/posts/5538187418970292 . Also, sometimes number of shares returned are 0, and I am unable to figure out why?
Cheers and stay safe
When using get_posts only the first image url gets scraped. Is there a way to get all of them?
Thank you
eg 'type': video,
'source_url': link,
Thank you
I have noticed, that your script only scraps total number of likes and it dose not take reactions at all
Also shares are not working at all
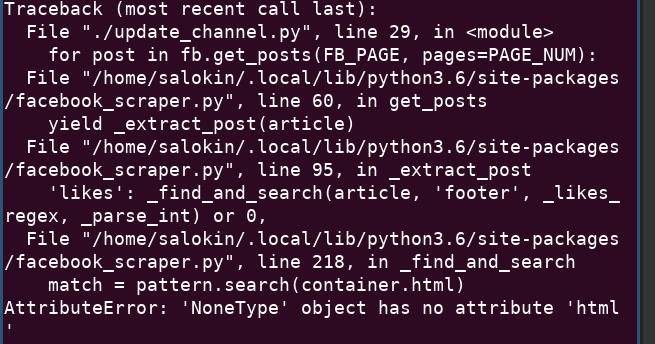
For some posts, in the function _find_and_search the container returned is of type None. The subsequent pattern search explicitly looks for the attribute html which then leads to an exception.
Hi there,
With facebook-scraper, I was able to get posts by the page owner (I call it firm-generated posts). However, at the firm's FB page (see BMW's page in the following as one example), each individual user is also allowed to posts something in that page. See "Visitors Posts" in the left side.
Is there anyone know how to modify the code to get "Visitors Posts" as well?
https://www.facebook.com/pg/BMWUSA/posts/?ref=page_internal
Thanks a lot!
Sometimes the shares field returns 0 when in fact a post has been shared multiple times, just FYI.
First, I would like to say thank for your work, this script is very useful.
I ran get_post with a absurdly big number just to get all the post of the post.
After downloading 144 post I got this
` File ".../facebook_post_downloader/venv/lib/python3.6/site-packages/facebook_scraper.py", line 75, in _get_posts
yield _extract_post(article)
File ".../facebook_post_downloader/venv/lib/python3.6/site-packages/facebook_scraper.py", line 102, in _extract_post
text, post_text, shared_text = _extract_text(article)
File ".../facebook_post_downloader/venv/lib/python3.6/site-packages/facebook_scraper.py", line 137, in _extract_text
nodes = article.find('p, header')
AttributeError: 'NoneType' object has no attribute 'find'
Process finished with exit code 1
`
I was expecting a graceful exit from the generator.
If I'm not mistaken, at the moment scraping several pages in a row would have _login_user triggered for each _get_posts call. This might be flagged by facebook as suspicious.
In my usecase I fixed it this way:
def _get_posts(path, pages=10, timeout=5, sleep=0, credentials=None):
"""Gets posts for a given account."""
global _session, _timeout
url = f'{_base_url}/{path}'
if _session is None:
_session = HTMLSession()
_session.headers.update(_headers)
if credentials:
_login_user(*credentials)That however this isn't optimal for people who use several different accounts in their workloads, so I believe it should be discussed.
I get the following info from nintendo, with extra_info=True:

But, I can see the timestamp from when the text was posted.
How I can see the timestamp?
Thank you for this great package. I need a way to scrape certain Facebook pages that require the user to be logged in. I believe some of these pages (think alcohol and tobacco related products) only need the user to be logged in so they can check the user's age/DOB and restrict young users from viewing the page (though I'm not 100% certain about this). I've forked this repo and modified the code so that I can provide my login information to log the session in before scraping so that I can scrape these restricted pages. If I submit a pull request to add this feature, is this something people would be interested in? I am admittedly not a professional software developer and may not implement the feature in the most optimal way, but I have it working and would be glad to try and share if folks are interested.
Time for posts from the current year do not include the current year in the post. They are in the format of May 29 at 1:35
The code is expecting you provide the year.
Second issue is for recent post they are relative to "current" time. They show up as 2 mins or 4 hrs
I am fixing it locally on my version, I am not sure if you accept merge requests etc.
Empty responses from private Facebook pages
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.