median-research-group / libmtl Goto Github PK
View Code? Open in Web Editor NEWA PyTorch Library for Multi-Task Learning
License: MIT License
A PyTorch Library for Multi-Task Learning
License: MIT License
Thank you for this excellent library. I'm wondering if you would consider supporting single-input problems where there are incomplete labels for each task.
A simple example:
label for img1: [0, 1, 1, 0, 1, ..., 0, 0, 1]
label for img2: [1, ?, ?, 1, 1, ..., 1, ?, 0]
label for img3: [1, 0, ?, 1, 0, ..., 0, 1, ?]
(? is a missing label - the label doesn't specify whether or not img2 has a pedestrian or not.)
One could consider this as a multi-input problem, just duplicate the dataset and exclude missing labels for each task -> create 30 datasets. However, this is wasteful to train separate 30 task-specific forward networks without parameter sharing. Even just propagating forward 30 times for a single image is an inefficient usage of computational resources.
Please let me know if I have the wrong assumptions about how LibMTL works, or if my problem could easily be solved by current api. Thank you!
Hello LibMTL team,
I went through your code, and I am not sure which part could be extended to support loading and saving the models to disk.
The model inside the Trainer is not picklable, and I was wondering if you could hint me to the components that would need to be saved and loaded for instance to resume training or postpone testing,
Best,
Salah
when I try to run this trainer , .next() can't run
-> "AttributeError: 'dict_keyiterator' object has no attribute 'next'"
I use:
python=3.7
torch=11.3
This method has been deleted in python 3?
Why not use next(iter)?
or what should I do to fix it?


我的网络里用到了fpn,有的head用了fpn的第一层输出,其它head用到了其它层的输出。
我要怎么确定fpn的网络公共部分

Hi, I found that the value -0.5 was used when initializing the parameter in line 19 of uw.py.
My doubt is why this value is not 0, since the variable loss_scale is equivalent to log \sigma in the original paper.
self.loss_scale = nn.Parameter(torch.tensor([-0.5]*self.task_num, device=self.device))感觉还挺自豪的,谢谢你的工作
Hi,
Thanks for open sourcing this wonderful repo. I have a question regarding the following line
Line 96 in d05c80c
self.base_result = new_result else the improvement will always be compared over base_result, and we would not get the best checkpoint. I may be missing something, but the results on my experiments doesn't look correct to me.I ran the demo of office-31and found some errors in this example:
The version of pip is not the same version published on github
The operating environment is as follows:
In train.py, .next() can't run

After I modified this syntax, the new problem appeared again
data = data.to(self.device, non_blocking=True)
I want to know if this is a version reason or something else
Thank you for your excellent contribution!
I have a question about the performance of MTAN with PCGrad.
In my experiment, the result of NYUv2 is very different from the PCGrad official performance (although I not used UW in this experiment)

(sorry for this image to very small)
Also, when I experimented to the resnet50-HPS without weighting method, the result is beyond the MTAN official performance.

I tried your official training command line in all cases and used the dataset in your Dropbox.
Is that result the right phenomenon?
Thank you in advance!
Most of the research papers for the implemented architectures and weighting methods seem to deal with single-input-multi-output tasks such as simultaneous object detection and segmentation from a single image. However, LibMTL also supports multi-input tasks, where each task has its own data (e.g. MNIST where each digit has its own task-specific layers). Is there a set of research papers that discuss this approach? I'm curious to learn how LibMTL evaluates the loss in these situations. I can dig into the code to get a deeper understanding, but in the meantime, if there are papers that discuss this, it would really help to have some links (and maybe update the docs).
Thanks!
您好,请问为什么有些方法会限制 rep_grad 为 True 或 False。
例如:GradDrop 只能为 True。而像PCGrad、GradVac、CAGrad等都只能为False。
Hi, I would like to ask you question about the Cross Stitch implementation.
In your code you create cross_unit as torch.ones(4, self.task_num). So for each of the 4 resnet layers you have tensor of task_num values. For example with 2 tasks it would be tensor(4, 2) and each layer has a 1x2 cross unit. But in the paper in equation (1) for two tasks they have a matrix of 2x2. Is there a reason that you have a 1x2 cross unit, did I misunderstand something in the paper ?

LibMTL/LibMTL/architecture/Cross_stitch.py
Lines 23 to 35 in 3928656
self.cross_unit = nn.Parameter(torch.ones(4, self.task_num, self.task_num)) # matrix for each layer
def forward(self, inputs):
s_rep = {task: self.resnet_conv[task](inputs) for task in self.task_name}
ss_rep = {i: [0]*self.task_num for i in range(4)}
for i in range(4):
for tn, task in enumerate(self.task_name):
if i == 0:
ss_rep[i][tn] = self.resnet_layer[str(i)][tn](s_rep[task])
else:
cross_rep = sum([self.cross_unit[i-1][tn][j]*ss_rep[i-1][j] for j in range(self.task_num)]) # access matrix row of each task
ss_rep[i][tn] = self.resnet_layer[str(i)][tn](cross_rep)
return ss_rep[3]Hi, thanks for your wonderful project. There are some questions I want to confirm when I apply the MGDA weighting method, could you please give me an answer, thanks!
For the above two problems, I try to give my answer, the first is the representation generated by the representation layer (sharing parameters), and the second is whether using the gradients of representations.
In this case, my third problem is what is the purpose of the variable rep_grad when it is in MGDA?
It's used to implement the MGDA-UB? I realize that it will save the gradients of self.rep_tasks in the function of _compute_grad() in abstract_weighting.py, so I made such an assumption.
I'm a little bit confused about these technique detail, hope you can help me, thanks again!
In the uw original paper, the objective function is:

and according to the paper,

the second item  is diffirent with first item
is diffirent with first item  in denominators.
in denominators.
But in you code, loss = (losses/(2*self.loss_scale.exp())+self.loss_scale/2).sum(), without distinction between the denominators of these two.
Is that correct?
Thanks for your excellent work!
Could LibMTL provide visualization support? We can easily visualize the training progress of the model by using visualization tools, like tensorboardX, or Visdom.
Thanks
Hi,
First of all, this is a fantastic library! Amazing work.
My question: can LibMTL can be used in time-series applications? I.e. do we only need to provide encoder/decoder architectures such as LSTMs? Would the loss-weighting methods need to be extended in any way?
I'm fairly new to MTL, so pardon the naive question.
Thanks,
Madhu
你好 我看代码里面有这些weighting 但是例子中没有使用 这块要使用的化 需要怎么设置呢
代码里面没看到这些weight的相关代码
您好!Gradvac原文中提到了网络不同层间的梯度相似度最后收敛到不同的值,所以对不同任务以及不同层设置了不同的目标值。
原文描述如下:
To incorporate these three factors, we exploit an exponential moving average (EMA) variable for tasks i, j and parameter
group k (e.g. the k-th layer) as:
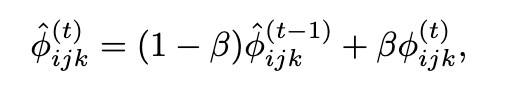
但你们实现的Gradvac仍然只是对不同任务间设置了不同目标值。这是否合理?
Hi, I know it's kinda OOT but I am curious whether I can apply multi-task learning to graph neural network. What I learn from HPS, we shall share the encoder/decoder across the layer. I am curious should I create an encoder on top of the graph layer? Kinda stuck in this experiment, any suggestion would be helpful. Thanks
The library is really interesting.
It would be very useful a Colaboratory notebook to test it online.
Line 196 in 3928656
self.model中并不总是有train_loss_buffer这个变量,只有GradNorm和DWA里面有
Hi there, I had a hard time reproducing the AlignMTL results. I am wondering if you have encountered the same issue? Have you guys evaluated AlignMTL under HPS?
Thanks,
Max
hi,你有什么对梯度更新的可视化办法吗,或者之后在libmtl里有计划实现
I have found someone says set num_workers=0 will work,but it's too slow...My system is Ubuntu
Exception ignored in: <function _MultiProcessingDataLoaderIter.del at 0x7f7c408fce60>
Traceback (most recent call last):
File "/home/user/miniconda3/envs/IB/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 1510, in del
self._shutdown_workers()
File "/home/user/miniconda3/envs/IB/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 1493, in _shutdown_workers
if w.is_alive():
File "/home/user/miniconda3/envs/IB/lib/python3.7/multiprocessing/process.py", line 151, in is_alive
assert self._parent_pid == os.getpid(), 'can only test a child process'
AssertionError: can only test a child process
When I try to save the trained model i.e. full model using the following command -
torch.save(model, "<path>")
It throws this error
AttributeError: Can't pickle local object 'Trainer._prepare_model.<locals>.MTLmodel'
Is it possible to currently pass in arguments to initialize the encoders and decoders?
For example, given this linear encoder class:
class SimpleLinearEncoder(nn.Module):
def __init__(self, n_features, n_hidden1, n_output):
super(SimpleLinearEncoder, self).__init__()
self.encoder = torch.nn.Sequential(
torch.nn.Linear(n_features, n_hidden1),
torch.nn.ReLU(),
torch.nn.Linear(n_hidden1, n_output)
)
def forward(self, x):
return self.encoder(x)
In order to create an encoder with 20 inputs, 10 neurons in the hidden layer and 4 outputs without setting them as default argument values, can we pass in these parameters to kwargs? E.g:
kwargs = {"weight_args": {"alpha": 1.5}, "arch_args": {}, "n_features": 20, "n_hidden1": 10, "n_output": 4 }
model = Trainer(task_dict=task_dict,
weighting=weighting_method.__dict__[mtl_weighting_method],
architecture=architecture_method.__dict__[mtl_architecture],
encoder_class=SimpleLinearEncoder,
decoders=decoders,
rep_grad=False,
multi_input=True,
optim_param={'optim': 'sgd', 'lr': 0.005, 'weight_decay': 0.00005, 'momentum': 0.9},
scheduler_param={'scheduler': 'step', 'step_size': 100, 'gamma': 0.5},
**kwargs)
I wasn't able to get the above to work, and my naive guess is that it's because of these lines in the LibMTL.architecture classes, e.g. HPS:
self.encoder = self.encoder_class()
I'm new to PyTorch so perhaps I'm missing an easy solution.
Thanks.
�你好,非常感谢您的工作,但在多卡使用时出现了如下问题想请教:
https://github.com/median-research-group/LibMTL/blob/main/LibMTL/weighting/abstract_weighting.py#L43

配置:�MGDA+hardParam
另外还有个问题想请教一下:
作者你好,不知道是否有v1.1.6的最新文档呢?我看新加的一些参数例如cfg等等都没有完整的例子与介绍,文档还是原来的版本
Trainer class use fails with the error "No module named 'torchvision.models.utils'"
Full stack here -
Traceback (most recent call last):
File "src/main/pipelines/train_nsfw_mtl.py", line 11, in
from LibMTL import Trainer
File "/azureml-envs/azureml_8a26314e09753d45d0790003a01faf79/lib/python3.8/site-packages/LibMTL/init.py", line 2, in
from . import model
File "/azureml-envs/azureml_8a26314e09753d45d0790003a01faf79/lib/python3.8/site-packages/LibMTL/model/init.py", line 1, in
from LibMTL.model.resnet import resnet18
File "/azureml-envs/azureml_8a26314e09753d45d0790003a01faf79/lib/python3.8/site-packages/LibMTL/model/resnet.py", line 3, in
from torchvision.models.utils import load_state_dict_from_url
ModuleNotFoundError: No module named 'torchvision.models.utils'
The issue is fixed by using 'torch.hub' instead.
After raining the training script, where will the model be saved?
MGDA-UB原文中求representation的梯度,对于PLE和MMOE这类模型来说,representation是经过gate加权求和后的representation?
Hi,
Thank you for putting up a such a fantastic MTL experimentation library. I used it for my own datasets and all looked good except when i observed weights of encoder/decoders during training rounds and it seems that only encoder weights get updated after any iteration or epochs but decoders weights remain same. When i just freeze the encoder layers (self.model.encoder.requires_grad_(False))and not the decoders layers than the training loss remain same in all iterations/epochs which means that decoders weights are not updating during training rounds. I tried with HPS architecture and EW weighting. Kindly can you help to debug what can contribute to this issue?
hello,I need these structures or weighting strategies for yolov5, what should i do?
Hello, first of all, thank you for your great work.
I saved the best model while running the Office example, but I want to export this model as an ONNX model and use tools like Netron to understand the model structure. How can I add code to the framework? Can you add an exported component for exporting various models, such as onnx, mnn, tflite
libMTL is a nice library. But how to use libMTL for multitask regression? Could you provide an example?
问题1:
比如,有task_a和task_b,他们的训练样本是非同源的,task_a的训练样本量是100000,task_b的训练样本量是1000。
如果我用一个dataloader去取数据,同一个batch里可能都是task_a的训练样本,一个叠代只训练了task_a这个任务,无法做多任务的梯度策略。
————————————————————————————————————————————————————
问题2:
同样是多任务非同源训练数据不均衡,如果是task_a、task_b、task_c三任务的话,还可能一个batch里只有task_a和task_c的样本,没有task_b的样本,如果是这样的话,又要怎么去应用梯度策略?
您好,请问您的项目支持混合精度训练吗(梯度回传)?
我尝试了nashmtl,以下是我的vscode配置列表:

我发现当我修改权重更新频率后,会报错如下:

Hi, great work.
Did you guys try to run gradient surgery methods with distributed dataparallel in pytorch. I couldn't run it due to calling backwards multiple times creating gradient syncing issues in distributed learning
When running train_qm9.py file, the program prints the following information and then becomes unresponsive, as if it has entered an infinite loop. What could be the possible reasons for this issue?
在运行train_qm9.py的时候,程序打印以下信息后就再无动静,似乎进入了死循环?请问可能是什么原因造成的呢?
General Configuration:
Wighting: EW
Architecture: HPS
Rep_Grad: False
Multi_Input: False
Seed: 0
Save Path: None
Load Path: None
Device: cuda:0
Optimizer Configuration:
optim: adam
lr: 0.0001
weight_decay: 1e-05
Total Params: 617675
Trainable Params: 617675
Non-trainable Params: 0
LOG FORMAT | 0_LOSS MAE | 1_LOSS MAE | 2_LOSS MAE | 3_LOSS MAE | 5_LOSS MAE | 6_LOSS MAE | 12_LOSS MAE | 13_LOSS MAE | 14_LOSS MAE | 15_LOSS MAE | 11_LOSS MAE | TIME
I introduced L1Metric class ,I get a error:
AttributeError: 'L1Metric' object has no attribute 'abs_record'
class L1Metric(AbsMetric):
r"""Calculate the Mean Absolute Error (MAE).
"""
def __init__(self):
super(L1Metric, self).__init__()
def update_fun(self, pred, gt):
r"""
"""
abs_err = torch.abs(pred - gt)
self.record.append(abs_err)
self.bs.append(pred.size()[0])
def score_fun(self):
r"""
"""
records = np.array(self.abs_record)
batch_size = np.array(self.bs)
return [(records*batch_size).sum()/(sum(batch_size))]
L1Metric class inherit AbsMetric class,but AbsMetric class has no attribute 'abs_record',So I guess there are maybe some problems,of course,this property may also come from other places
class AbsMetric(object):
r"""An abstract class for the performance metrics of a task.
Attributes:
record (list): A list of the metric scores in every iteration.
bs (list): A list of the number of data in every iteration.
"""
def __init__(self):
self.record = []
self.bs = []
@property
def update_fun(self, pred, gt):
r"""Calculate the metric scores in every iteration and update :attr:`record`.
Args:
pred (torch.Tensor): The prediction tensor.
gt (torch.Tensor): The ground-truth tensor.
"""
pass
@property
def score_fun(self):
r"""Calculate the final score (when an epoch ends).
Return:
list: A list of metric scores.
"""
pass
def reinit(self):
r"""Reset :attr:`record` and :attr:`bs` (when an epoch ends).
"""
self.record = []
self.bs = []
Line 63 in 70f0f00
if epoch == 0 and self.base_result is None and mode==('val' if self.has_val else 'test'): should be
我实验下来也这样,在我的网络里提升有限。
大佬,你怎么看这篇paper
https://arxiv.org/pdf/2209.11379.pdf
Thanks for this great repo, it is very useful!
Could you please add support for the Nash-MTL method described in the paper "Multi-Task Learning as a Bargaining Game"?
Paper: https://arxiv.org/abs/2202.01017
Official code: https://github.com/AvivNavon/nash-mtl
Thanks
您好,我在更换损失函数的时候有两个问题想请教一下,谢谢!
目前使用的版本是1.1.6
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/LibMTL/core/trainer.py", line 461, in train
train_losses[tn] = self._compute_loss(
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/LibMTL/core/trainer.py", line 304, in _compute_loss
train_losses = self.losses[task_name].update_loss(preds[task_name], gts)
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/LibMTL/loss/abstract_loss.py", line 59, in update_loss
loss = self.compute_loss(pred, gt)
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/LibMTL/loss/KLDivLoss.py", line 19, in compute_loss
loss = self.loss_fn(pred, gt)
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/loss.py", line 465, in forward
return F.kl_div(input, target, reduction=self.reduction, log_target=self.log_target)
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/functional.py", line 2916, in kl_div
reduced = torch.kl_div(input, target, reduction_enum, log_target=log_target)
RuntimeError: The size of tensor a (64) must match the size of tensor b (31) at non-singleton dimension 1
修改的代码
decoder_soft_loss = nn.KLDivLoss(reduction="batchmean")(
nn.functional.log_softmax(unlearned_decoder / 10.0, dim=1),
nn.functional.softmax(init_decoder / 10.0, dim=1))
其中unlearned_decoder 是模型输出的pred,init_decoder 是初始化模型输出的pred
错误信息
File "train_office.py", line 12, in <module>
Officemodel.kd_train()
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/LibMTL/core/trainer.py", line 712, in kd_train
w = self.model.backward(train_losses, **weighting_arg)
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/LibMTL/weighting/DWA.py", line 40, in backward
loss.backward()
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/torch/_tensor.py", line 396, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/miniconda3/envs/pytorch/lib/python3.8/site-packages/torch/autograd/__init__.py", line 173, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [512, 31]], which is output 0 of AsStridedBackward0, is at version 5; expected version 4 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.