megvii-model / yolof Goto Github PK
View Code? Open in Web Editor NEWLicense: MIT License
License: MIT License
























































































































which file can create model and so I can use torch.onnx._export to convert pth to onnx?
I noticed that there is already a cvpods directory in the project. Do I need to download cvpods again?
Do I need to delete the existing cvpods if I download it again?
How to install cvpods if I don’t need to download it? Because if I use pip install -e cvpods --user to install directly, it will be unavailable due to lack of setup.py.

Thanks for the authors' contributions. I have the problem about uniform matching. For example, assuming that Two Objects are close, the anchors around the two adjacent objects will be assigned the information of the two object at the same time. How to solve this problem ?
Hello, I want to use the under the tools folder 'train_net' script to train the yolof-res101-dc5-1x version of the network, but because the first card of my group's server is occupied by others, I want to use other cards to train, I did not find the statement to modify the GPU number in 'setup' script. so I put num_ gpu,num_ machines and machines_ rank parameters are all changed to 1, but they are still trained with GPU: 0. How to solve it?
Thanks !
I don't find relevent code in YOLOF and cvpods
Can I get a model config and pre-trained weights of the model denoted in this table?

[09/30 05:59:20 c2.utils.dump.events]: eta: 0:00:21 iter: 89940/90000 total_loss: 0.481 loss_cls: 0.193 loss_box_reg: 0.285 time: 0.3588 data_time: 0.0090 lr: 0.000300 max_mem: 5200M
[09/30 05:59:28 c2.utils.dump.events]: eta: 0:00:14 iter: 89960/90000 total_loss: 0.482 loss_cls: 0.206 loss_box_reg: 0.293 time: 0.3588 data_time: 0.0070 lr: 0.000300 max_mem: 5200M
[09/30 05:59:35 c2.utils.dump.events]: eta: 0:00:07 iter: 89980/90000 total_loss: 0.507 loss_cls: 0.205 loss_box_reg: 0.297 time: 0.3588 data_time: 0.0104 lr: 0.000300 max_mem: 5200M
[09/30 05:59:43 c2.checkpoint.checkpoint]: Saving checkpoint to ./output/model_final.pth
[09/30 05:59:43 c2.data.build]: TransformGens used: [ResizeShortestEdge(short_edge_length=(800, 800), max_size=1333, sample_style='choice')] in testing
[09/30 05:59:44 c2.data.datasets.coco]: Loaded 5000 images in COCO format from /home/fsr/code/YOLOF/datasets/coco/annotations/instances_val2017.json
[09/30 05:59:44 c2.evaluation.evaluator]: Start inference on 2500 data samples
Traceback (most recent call last):
File "/home/fsr/code/YOLOF/tools/train_net.py", line 109, in
args=(args,),
File "/home/fsr/code/YOLOF/cvpods/engine/launch.py", line 53, in launch
daemon=False,
File "/home/laocheng/anaconda3/envs/dh/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 230, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/home/laocheng/anaconda3/envs/dh/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 188, in start_processes
while not context.join():
File "/home/laocheng/anaconda3/envs/dh/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 136, in join
signal_name=name
torch.multiprocessing.spawn.ProcessExitedException: process 0 terminated with signal SIGKILL
Traceback (most recent call last):
Traceback (most recent call last):
File "", line 1, in
File "", line 1, in
File "/home/laocheng/anaconda3/envs/dh/lib/python3.7/multiprocessing/spawn.py", line 105, in spawn_main
File "/home/laocheng/anaconda3/envs/dh/lib/python3.7/multiprocessing/spawn.py", line 105, in spawn_main
exitcode = _main(fd)
exitcode = _main(fd)
File "/home/laocheng/anaconda3/envs/dh/lib/python3.7/multiprocessing/spawn.py", line 115, in _main
File "/home/laocheng/anaconda3/envs/dh/lib/python3.7/multiprocessing/spawn.py", line 115, in _main
self = reduction.pickle.load(from_parent)
self = reduction.pickle.load(from_parent)
_pickle.UnpicklingError: pickle data was truncated
_pickle.UnpicklingError: pickle data was truncated
How can I solve this problem when you need to test after you save the file
hello, when i run with only one GPU, i get the error "RuntimeError: Default process group has not been initialized, please make sure to call init_process_group."
Hi! I really appreciate the authors for doing such an inspiring job and sharing the code.
Somehow, I am kind of confused by the Sec. 4.1 of the paper. In my understanding, comparing MiMo, SiSo using C5 may cause some problems in detecting small object (High level feature with low resolution is preferred for large scale objects). To bridge the gap between SiSo and MiMo, why should we focus on larger objects? Fig 4 discusses about receptive fields. However, receptive fields of low level feature is smaller than C5, if SiSo has the receptive field problem, MiMo should have too!
So, I don't really understand this part. I will be glad if you point me out the problem.
Thanks in advance.
Is there a simple bash command for object detection based on video ?
Hi, author, I have the following problems in running your model
Traceback (most recent call last):
File "/DATA/xiexu/yolo/cvpods/tools/train_net.py", line 109, in
args=(args,),
File "/home/xiexu/.local/lib/python3.7/site-packages/cvpods/engine/launch.py", line 56, in launch
main_func(*args)
File "/DATA/xiexu/yolo/cvpods/tools/train_net.py", line 74, in main
runner = runner_decrator(RUNNERS.get(cfg.TRAINER.NAME))(cfg, build_model)
File "/home/xiexu/.local/lib/python3.7/site-packages/cvpods/engine/runner.py", line 86, in init
self.data_loader = self.build_train_loader(cfg)
File "/home/xiexu/.local/lib/python3.7/site-packages/cvpods/engine/runner.py", line 307, in build_train_loader
return build_train_loader(cfg)
File "/home/xiexu/.local/lib/python3.7/site-packages/cvpods/data/build.py", line 130, in build_train_loader
transform_gens = build_transform_gens(cfg.INPUT.AUG.TRAIN_PIPELINES)
File "/home/xiexu/.local/lib/python3.7/site-packages/cvpods/data/build.py", line 69, in build_transform_gens
return build(pipelines)
File "/home/xiexu/.local/lib/python3.7/site-packages/cvpods/data/build.py", line 58, in build
tfm = TRANSFORMS.get(aug)(**args)
File "/home/xiexu/.local/lib/python3.7/site-packages/cvpods/utils/registry.py", line 66, in get
"No object named '{}' found in '{}' registry!".format(name, self._name)
KeyError: "No object named 'RandomShift' found in 'transforms' registry!"
I did not understand this code, can anyone help me understand this code?

Hi, we have tried the YOLOF code following your README, the code can start training correctly. However, after a few hundred(400~500) iterations, the YOLOF report: " AssertionError: Box regression deltas become infinite or NaN!"
We have tried to reduce the Learning Ratio defined as " cfg.SOLVER.OPTIMIZER.BASE_LR" from original to 0.005, but it doesn't work.
Could you please give us some advice?
Thanks a lot!
Sanyaoshanren
How to use pretraining weights for training? After downloading the pretraining weight, which folder should I put it in? How to call the pretraining weight file?
Thanks!
I use res50-C5
when I don't use the pre-training model, the accuracy is only 59%. After using the pre-training model, the accuracy reaches 80%.
However, my experiment on YOLOv5s is only 75%.
Should I use the pre-training model? What may be the reason for my situation?

Hello, I'm debugging the train under the tools folder 'train_net.py'.But in the cvpods folder, on line 11 of the deform_conv script :
from cvpods import C. report an error here:
cannot import name ' C 'from' cvpods'
Why is this? Do I need to install any plug-ins?
Thanks!
https://1drv.ms/u/s!AgM0VtBH3kV9imGxZX3n_TMQGtbP?e=YMgpGJ
is not an aviliable link, and also the models' link.
Hi,
Great and very interesting work!
I wonder if you've experimented with anchor-free methods and YOLOF.
In ATSS they show a retinanet-style network that is anchor-free (only 1 anchor).
Could this be achieved with YOLOF?

I think the following passage may be the main cause of the NAN problem:
normalized_cls_score = cls_score + objectness - torch.log(
1. + torch.clamp(cls_score.exp(), max=self.INF) + torch.clamp(
objectness.exp(), max=self.INF))
There is an exp operation in this code, and clip is used to clip it to avoid explosion, but this still has hidden dangers, that is, before clipping, the exp may have exploded and overflowed, so the clip is useless at this time.
So, I changed to clip first and then exp,:
normalized_cls_pred = cls_pred + obj_pred - torch.log(
1. +
torch.clamp(cls_pred, max=DEFAULT_EXP_CLAMP).exp() +
torch.clamp(obj_pred, max=DEFAULT_EXP_CLAMP).exp())
where DEFAULT_EXP_CLAMP = log(INF).
After above modification, NAN problem no longer encountered.
just use pytorch can make the yolof eather. So why are you make this easy project that complex? And can not install .
hello, when i train the model on 4 GPU, i met the following error, if train it on 1 gpu, the error disappear:
[04/08 14:39:50 c2.utils.dump.events]: eta: 4:24:06 iter: 6960/22500 total_loss: 0.748 loss_cls: 0.333 loss_box_reg: 0.420 time: 1.0219 data_time: 0.6507 lr: 0.010000 max_mem: 5233M
/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:60: lambda ->auto::operator()(int)->auto: block: [0,0,0], thread: [121,0,0] Assertion index >= -sizes[i] && index < sizes[i] && "index out of bounds" failed.
ERROR [04/08 14:39:54 c2.engine.base_runner]: Exception during training:
Traceback (most recent call last):
File "/media/6855ca5f-2432-4ace-ab31-3877011231fc/CODE_detection/YOLOF/cvpods/engine/base_runner.py", line 84, in train
self.run_step()
File "/media/6855ca5f-2432-4ace-ab31-3877011231fc/CODE_detection/YOLOF/cvpods/engine/base_runner.py", line 185, in run_step
loss_dict = self.model(data)
File "/home/env/python3.6env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in call
result = self.forward(*input, **kwargs)
File "/home/env/python3.6env/lib/python3.6/site-packages/torch/nn/parallel/distributed.py", line 447, in forward
output = self.module(*inputs[0], **kwargs[0])
File "/home/env/python3.6env/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in call
result = self.forward(*input, **kwargs)
File "../yolof_base/yolof.py", line 135, in forward
pred_logits, pred_anchor_deltas)
File "../yolof_base/yolof.py", line 216, in losses
pred_class_logits[valid_idxs],
RuntimeError: copy_if failed to synchronize: device-side assert triggered
[04/08 14:39:54 c2.engine.hooks]: Overall training speed: 6961 iterations in 1:58:34 (1.0221 s / it)
[04/08 14:39:54 c2.engine.hooks]: Total training time: 2:04:42 (0:06:08 on hooks)
terminate called after throwing an instance of 'c10::Error'
what(): CUDA error: device-side assert triggered (insert_events at /pytorch/c10/cuda/CUDACachingAllocator.cpp:764)
hello, how to train the SiMo model
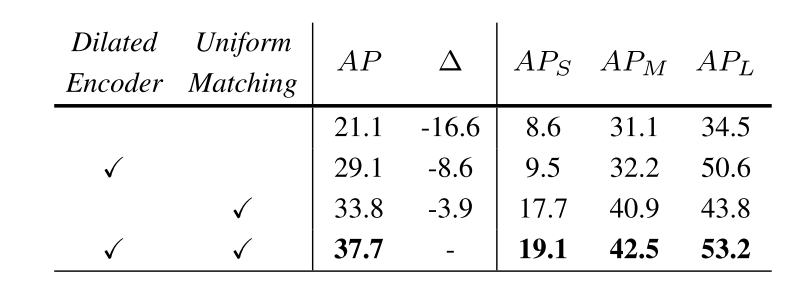
hello, the effect of large objects is a 9.3% difference, which is not small compared to others

COCOEvaluator(dataset_name, output_dir=output_folder))
TypeError: init() missing 2 required positional arguments: 'cfg' and 'distributed'
训练可以进行 但是输入验证集出现了这问题
Hi! I have questions to disturb you.
When trying to run train_net.py, I have no way to solve 'from config import config'.when the error exists'no mudule named ''config',I try to 'pip install config'.But there are still errors.I have searched for some way,but no way works.Can you help me ?
I delete IMS_PER_DEVICE, and change IMS_PER_BATCH from 64 to 16 and use pods_train --num_gpu 1 to train. Then Default process group is not initialized is reported. It seems to YOLOF use SyncBN, but I didn't find it in config.py. Thanks.

Hi. In your paper, Fig 1 shows SiMo style can get competitively good results, but I am wondering about the detailed architecture during experiments. How do you generate multiple outputs with a single input? Do you pick up outputs from the deeper layers to make predictions like how SSD has done?
I follow the instructions and install dependencies,
cd /YOLOF/playground/detection/coco/yolof/yolof.res50.C5.1x
But when I input:
pods_train --num-gpus 2
I get a problem:
python3: can't open file '/tmp/pip-req-build-6jhijoew/tools/train_net.py': [Errno 2] No such file or directory
this what happen?
hello, figure4 in your paper shows the scales of receptive field, how to analyse the receptive field, can you release the code or tool,thx
i have only one gpu (8gb)
here is my log.txt
log.txt
how do i set learning rate warming iter and so on
Thanks for sharing your research!
I have one question.
What's the difference between YOLOF_CSP_D_53_DC5_9x_stage2_3x and YOLOF_CSP_D_53_DC5_9x?
Hello! I'm trying to re-train this YOLOF in a single 3090 GPU with the batchsize of 32. However, even though I tried to modify some of the parameters like base-lr, steps and something else, the best AP I can get is 35.7688, which is much worse than the AP of 37.7 in your paper. Do you have any suggestions about how to modify base-learning rate, steps and warmup settings?
Thank you!
I have trained the model.And I want to run your model by using some video exaples to evaluate the result. How to modify the code?

Thank you for your great work. But I still don't understand figure 4 in your paper. (green dots stand for? 3 consecutive dots, 2 consecutive dots, 1 consecutive dot mean?)
If it's possible, please describe the figure 4.
Thank you so much!
Including an individual cvpods will cause name conflicts if a user have already install cvpods.
So please remove all cvpods related stuff and only keep your experiments.
For example,
when I run
cd playground/detection/coco/yolof/yolof.res50.C5.1x
pods_train --num-gpus 8
i get a problem:
YOLOF/cvpods/_C.cpython-37m-x86_64-linux-gnu.so: undefined symbol: Z39tree_filter_refine_backward_edge_weightRKN2at6TensorES2_S2_S2_S2_S2_S2_S2_S2
How should I solve it?
How do I train on a custom dataset?
The paper points out the importance of balance matching of label assign, but actually in the code you ignores the anchor(pred) whose iou>NEG_IGNORE_THRESHOLD or < POS_IGNORE_THRESHOLD, which may break the balance?
Also, it seems you ignore the anchor(pred) whose iou > NEG_IGNORE_THRESHOLD only make sense with max-iou label assign, why you use the the anchor(pred) whose iou is maxium or between NEG_IGNORE_THRESHOLD and NEG_IGNORE_THRESHOLD ?
YOLOF/playground/detection/coco/yolof/yolof_base/yolof.py
Lines 186 to 231 in 8628813
[04/14 13:57:07 c2.utils.env.env]: Using a generated random seed 7889427
Traceback (most recent call last):
File "/media/ubun/CC7251E47251D3B4/yoloseries/YOLOF-main/tools/train_net.py", line 109, in
args=(args,),
File "/home/ubun/cvpods/cvpods/engine/launch.py", line 53, in launch
daemon=False,
File "/home/ubun/anaconda3/envs/detectron2/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 230, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/home/ubun/anaconda3/envs/detectron2/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 188, in start_processes
while not context.join():
File "/home/ubun/anaconda3/envs/detectron2/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 150, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 1 terminated with the following error:
Traceback (most recent call last):
File "/home/ubun/anaconda3/envs/detectron2/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 59, in _wrap
fn(i, *args)
File "/home/ubun/cvpods/cvpods/engine/launch.py", line 88, in _distributed_worker
main_func(*args)
File "/media/ubun/CC7251E47251D3B4/yoloseries/YOLOF-main/tools/train_net.py", line 74, in main
runner = runner_decrator(RUNNERS.get(cfg.TRAINER.NAME))(cfg, build_model)
File "/home/ubun/cvpods/cvpods/engine/runner.py", line 86, in init
self.data_loader = self.build_train_loader(cfg)
File "/home/ubun/cvpods/cvpods/engine/runner.py", line 307, in build_train_loader
return build_train_loader(cfg)
File "/home/ubun/cvpods/cvpods/data/build.py", line 130, in build_train_loader
transform_gens = build_transform_gens(cfg.INPUT.AUG.TRAIN_PIPELINES)
File "/home/ubun/cvpods/cvpods/data/build.py", line 69, in build_transform_gens
return build(pipelines)
File "/home/ubun/cvpods/cvpods/data/build.py", line 58, in build
tfm = TRANSFORMS.get(aug)(**args)
File "/home/ubun/cvpods/cvpods/utils/registry.py", line 66, in get
"No object named '{}' found in '{}' registry!".format(name, self._name)
KeyError: "No object named 'RandomShift' found in 'transforms' registry!"
according to your code, the uniform matcher seems calculate the L1 distance between pred_bbox/anchor with target among batch imgs. but i think it should be computed within single img. another question is that i do not understand the fusion method of the anchor indices and the pred_box indices, why simply add the two indices?https://github.com/megvii-model/YOLOF/blob/61a8accf957dceef11ea8029f121922b5f60901e/playground/detection/coco/yolof/yolof_base/uniform_matcher.py#L77
您好,感谢您的工作。 我在调试yolof代码中有些有一些不理解 希望得到您的帮助。
Env:
I ran the following command:
cd playground/detection/coco/yolof/yolof.cspdarknet53.DC5.3x
pods_train --num-gpus 8
Actual results:
Traceback (most recent call last):
File "/ssd/serser/cvpods/tools/train_net.py", line 109, in <module>
args=(args,),
File "/ssd/serser/cvpods/cvpods/engine/launch.py", line 53, in launch
daemon=False,
File "/ssd/serser/venv/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 230, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/ssd/serser/venv/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 188, in start_processes
while not context.join():
File "/ssd/serser/venv/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 150, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 0 terminated with the following error:
Traceback (most recent call last):
File "/ssd/serser/venv/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 59, in _wrap
fn(i, *args)
File "/ssd/serser/cvpods/cvpods/engine/launch.py", line 88, in _distributed_worker
main_func(*args)
File "/ssd/serser/cvpods/tools/train_net.py", line 74, in main
runner = runner_decrator(RUNNERS.get(cfg.TRAINER.NAME))(cfg, build_model)
File "/ssd/serser/cvpods/cvpods/engine/runner.py", line 86, in __init__
self.data_loader = self.build_train_loader(cfg)
File "/ssd/serser/cvpods/cvpods/engine/runner.py", line 307, in build_train_loader
return build_train_loader(cfg)
File "/ssd/serser/cvpods/cvpods/data/build.py", line 130, in build_train_loader
transform_gens = build_transform_gens(cfg.INPUT.AUG.TRAIN_PIPELINES)
File "/ssd/serser/cvpods/cvpods/data/build.py", line 69, in build_transform_gens
return build(pipelines)
File "/ssd/serser/cvpods/cvpods/data/build.py", line 58, in build
tfm = TRANSFORMS.get(aug)(**args)
File "/ssd/serser/cvpods/cvpods/utils/registry.py", line 66, in get
"No object named '{}' found in '{}' registry!".format(name, self._name)
KeyError: "No object named 'JitterCrop' found in 'transforms' registry!"
Have anyones trained this code in pascal voc? I had implemented a version of tensorflow codes, but it performed slightly worsh compared with RetinaNet and FCOS. And there is my codes: https://github.com/JiXuKong/YOLOF
I am using pythorch 1.11 and cuda with 11.3 , but the error come out . What version are you guys using?
YOLOF/playground/detection/coco/yolof/yolof_base/encoder.py
Lines 64 to 78 in 6189487
Why the weight initialization method for lateral_conv and fpn_conv is different from the weight initialization method for conv layer in dilated_encoder_blocks?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.