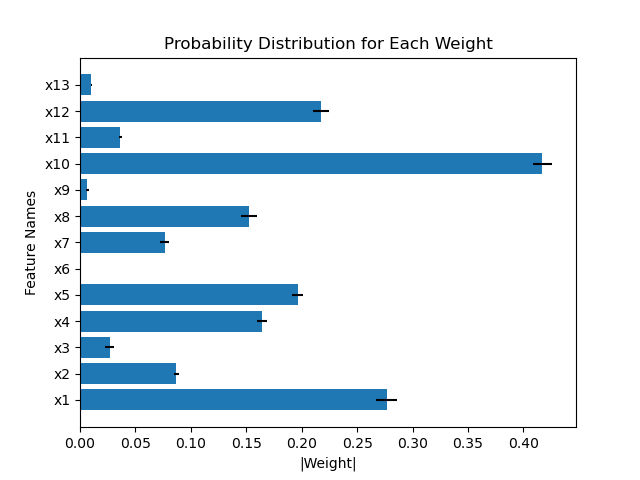
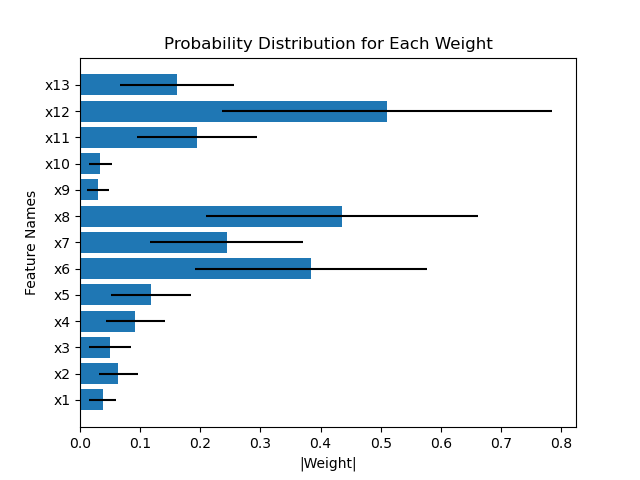
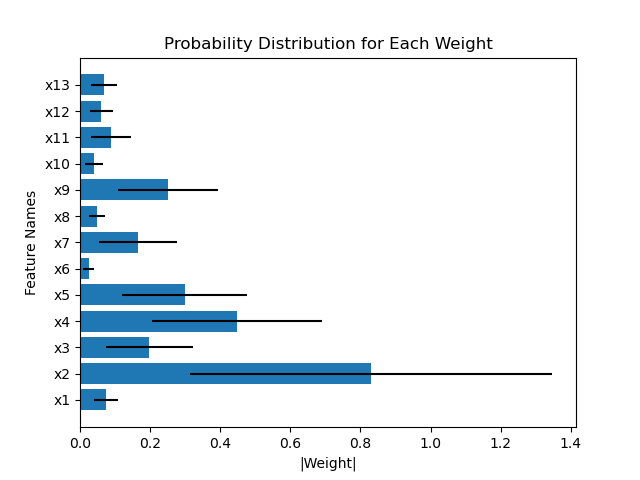
This repository contains all code for the paper Interpretable Outcome Prediction with Sparse Bayesian Neural Networks in Intensive Care which can be found here.
Abstract: Clinical decision making is challenging because of pathological complexity, as well as large amounts of heterogeneous data generated by various medical instruments. In recent years, machine learning tools have been developed to aid clinical decision making. Especially models for outcome prediction in intensive care units (ICUs) could help, for example, with decisions about resource allocation. However, flexible tools such as deep neural networks are rarely deployed in healthcare systems due to a lack of interpretability. In this work, we propose a novel interpretable Bayesian neural network (BNN) architecture, which offers both the flexibility of artificial neural networks and interpretability in terms of feature selection. In particular, we employ a sparsity inducing prior distribution in a tied manner to learn which features are important for performing outcome prediction. In addition, our model is fully probabilistic. Thus, the model provides probabilistic outcome prediction results, as well as information about the importance of different input features (i.e. clinical measurements). We evaluate our approach on the task of mortality prediction using two cohorts from real-world intensive care units. Collaborating with healthcare experts, we found that our approach can provide novel insights into the importance of different clinical measurements, in addition to the predicted outcome results. This suggests that our model can support medical experts in their decision making.
The code runs in Python 3.7 and Pytorch 1.1. To install the package please first clone the repo. After that, navigate to the project and run the following command in your command line. This will install the horseshoe_bnn package.
pip install -e .Other requirements can be installed using the requirements file located in the repo:
pip install -r requirements.txtIf you use this code in your research, please cite the following publication:
@article{popkes2019, title={Interpretable Outcome Prediction with Sparse Bayesian Neural Networks in Intensive Care}, author={Popkes, Anna-Lena and Overweg, Hiske and Ercole, Ari and Li, Yingzhen and Hern{'a}ndez-Lobato, Jos{'e} Miguel and Zaykov, Yordan and Zhang, Cheng}, journal={arXiv preprint arXiv:1905.02599}, year={2019} }
Popkes, Anna-Lena, et al. "Interpretable Outcome Prediction with Sparse Bayesian Neural Networks in Intensive Care." arXiv preprint arXiv:1905.02599 (2019).
Popkes, A. L., Overweg, H., Ercole, A., Li, Y., Hernández-Lobato, J. M., Zaykov, Y., & Zhang, C. (2019). Interpretable Outcome Prediction with Sparse Bayesian Neural Networks in Intensive Care. arXiv preprint arXiv:1905.02599.
- Instructions on how to download the dataset can be found here
- Details on the dataset, including preprocessing and features can be found in our paper
- This dataset is not publically available
- Details on the dataset, including preprocessing and features can be found in our paper
- To demonstrate the functioning of our networks and evaluator we use a publically available dataset, available within sckikit-learn
- The example script for running the evaluator uses this dataset
A script which trains and evaluates all models on the Boston Housing dataset can be found here. The script contains an example of how to train the models using the evaluator. To run the example script please follow the installation instructions. After that, navigate to the folder horseshoe_bnn/evaluation/ and run the following command. This will run all models on the Boston Housing dataset and print results to the console.
python evaluate_all_models.pyThe code for the individual models is located here.
├── LICENSE
├── README.md <- The top-level README for developers using this project.
│
├── requirements.txt <- The requirements file for reproducing the analysis environment
│
├── test <- All pytest test code
│
├── mimic_preprocessing <- Scripts to preprocess the MIMIC-III dataset
│
├── horseshoe_bnn <- All source code
│ │
│ ├── __init__.py <- Makes horseshoe_bnn a Python module
│ │
│ ├── data_handling <- Scripts to handle data
│ │ │
│ │ ├── dataset.py <- Custom Dataset class
│ │ └── dataset_to_dataloaders.py <- Function to convert Dataset instance to Pytorch dataloader
│ │
│ │
│ ├── evaluation <- Scripts to evaluate models
│ │ │
│ │ ├── evaluator.py <- Evaluator
│ │ └── evaluate_all_models.py <- Example script how to run evaluation
│ │
│ ├── metrics.py <- Metric classes
│ ├── models.py <- All model classes
│ ├── distributions.py <- Distribution classes
│ ├── network_layers.py <- BNN network layer classes
│ ├── aggregation_result.py <- Aggregation result class
│ └── parameters.py <- Parameter classes
│
└──
This repository is licensed under the Microsoft Research license.
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.microsoft.com.
When you submit a pull request, a CLA-bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., label, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.

![microsoft-github-policy-service[bot] avatar](https://avatars.githubusercontent.com/in/95686?v=4 "microsoft-github-policy-service[bot]")