This repository is now deprecated, please consider using mindsdb proper for a high level automatic machine learning solution or using the new lightwood if you want something lower-level.

![]()



MindsDB is an Explainable AutoML framework for developers built on top of Pytorch. It enables you to build, train and test state of the art ML models in as simple as one line of code.

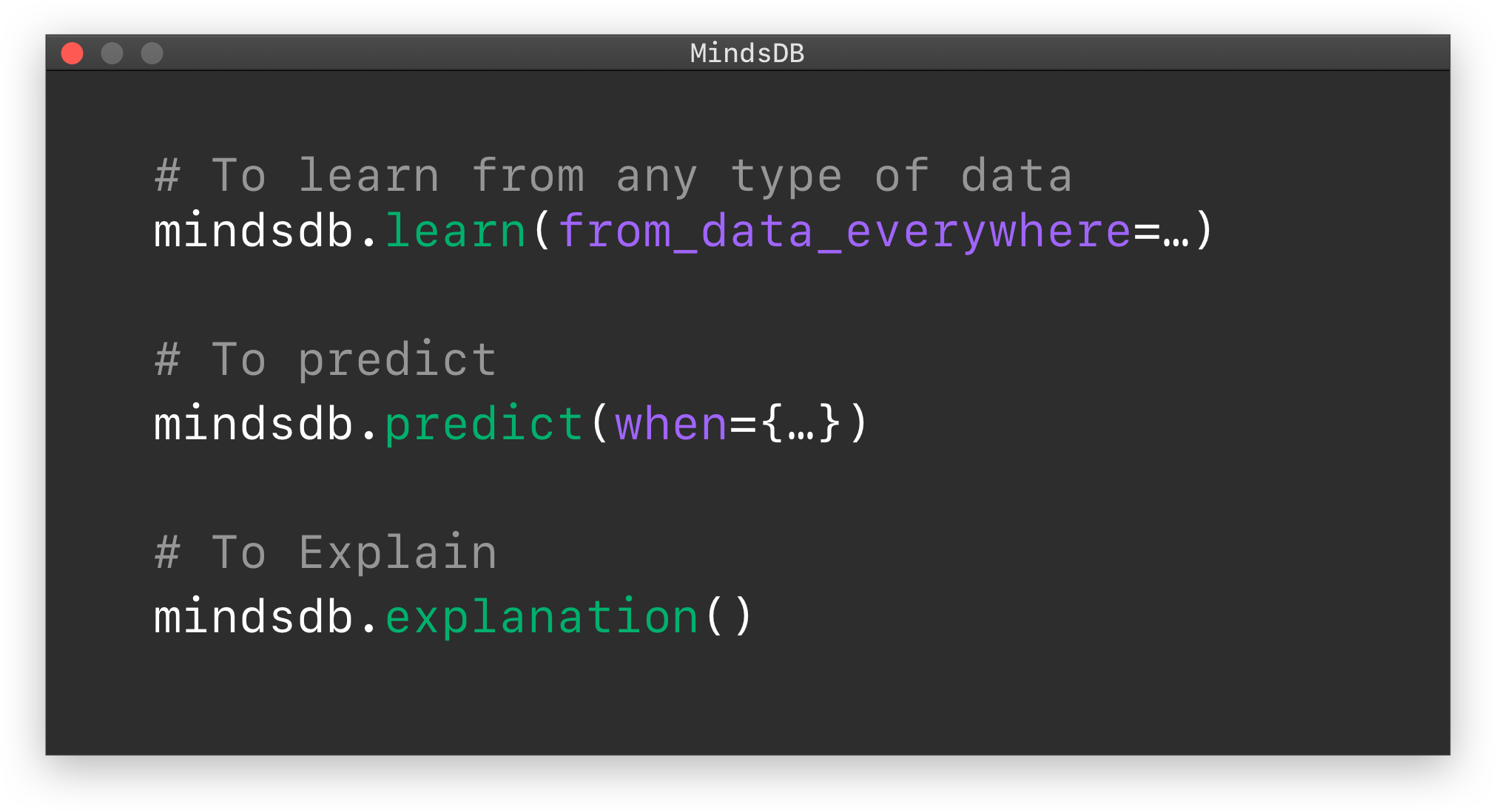
- Installing MindsDB
- Learning from Examples
- MindsDB Explainability GUI
- Frequently Asked Questions
- Provide Feedback to Improve MindsDB
- Desktop: You can use MindsDB on your own computer in under a minute, if you already have a python environment setup, just run the following command:
pip install mindsdb_native --userNote: Python 64 bit version is required. Depending on your environment, you might have to use
pip3instead ofpipin the above command.*
If for some reason this fail, don't worry, simply follow the complete installation instructions which will lead you through a more thorough procedure which should fix most issues.
- Docker: If you would like to run it all in a container simply:
sh -c "$(curl -sSL https://raw.githubusercontent.com/mindsdb/mindsdb/master/distributions/docker/build-docker.sh)"Once you have MindsDB installed, you can use it as follows:
Import MindsDB:
from mindsdb_native import PredictorOne line of code to train a model:
# tell mindsDB what we want to learn and from what data
Predictor(name='home_rentals_price').learn(
to_predict='rental_price', # the column we want to learn to predict given all the data in the file
from_data="https://s3.eu-west-2.amazonaws.com/mindsdb-example-data/home_rentals.csv" # the path to the file where we can learn from, (note: can be url)
)One line of code to use the model:
# use the model to make predictions
result = Predictor(name='home_rentals_price').predict(when_data={'number_of_rooms': 2, 'initial_price': 2000, 'number_of_bathrooms':1, 'sqft': 1190})
# you can now print the results
print('The predicted price is between ${price} with {conf} confidence'.format(price=result[0].explanation['rental_price']['confidence_interval'], conf=result[0].explanation['rental_price']['confidence']))Visit the documentation to learn more
- Google Colab: You can also try MindsDB straight here
To contibute to MindsDB please checkout the Contribution guide.
Made with contributors-img.
Please help us by reporting any issues you may have while using MindsDB.




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")




































































