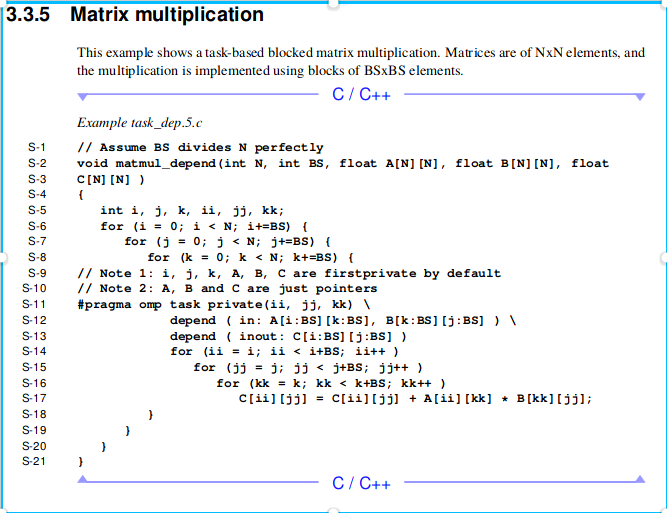
![]()
"Good artists borrow, great artists steal." -- Pablo Picasso
Weave (codenamed "Project Picasso") is a multithreading runtime for the Nim programming language.
It is continuously tested on Linux, MacOS and Windows for the following CPU architectures: x86, x86_64 and ARM64 with the C and C++ backends.
Weave aims to provide a composable, high-performance, ultra-low overhead and fine-grained parallel runtime that frees developers from the common worries of "are my tasks big enough to be parallelized?", "what should be my grain size?", "what if the time they take is completely unknown or different?" or "is parallel-for worth it if it's just a matrix addition? On what CPUs? What if it's exponentiation?".
Thorough benchmarks track Weave performance against industry standard runtimes in C/C++/Cilk language on both Task parallelism and Data parallelism with a variety of workloads:
- Compute-bound
- Memory-bound
- Load Balancing
- Runtime-overhead bound (i.e. trillions of tasks in a couple milliseconds)
- Nested parallelism
Benchmarks are issued from recursive tree algorithms, finance, linear algebra and High Performance Computing, game simulations. In particular Weave displays as low as 3x to 10x less overhead than Intel TBB and GCC OpenMP on overhead-bound benchmarks.
At implementation level, Weave unique feature is being-based on Message-Passing instead of being based on traditional work-stealing with shared-memory deques.
⚠️ Disclaimer:Only 1 out of 2 complex synchronization primitives was formally verified to be deadlock-free. They were not submitted to an additional data race detection tool to ensure proper implementation.
Furthermore worker threads are state-machines and were not formally verified either.
Weave does limit synchronization to only simple SPSC and MPSC channels which greatly reduces the potential bug surface.
Weave can be simply installed with
nimble install weaveor for the devel version
nimble install weave@#masterWeave requires at least Nim v1.2.0
The latest changes are available in the file.
A raytracing demo is available, head over to demos/raytracing.

- Weave, a state-of-the-art multithreading runtime
Weave provides a simple API based on spawn/sync which works like async/await for IO-based futures.
The traditional parallel recursive Fibonacci would be written like this:
import weave
proc fib(n: int): int =
# int64 on x86-64
if n < 2:
return n
let x = spawn fib(n-1)
let y = fib(n-2)
result = sync(x) + y
proc main() =
var n = 20
init(Weave)
let f = fib(n)
exit(Weave)
echo f
main()Weave provides nestable parallel for loop.
A nested matrix transposition would be written like this:
import weave
func initialize(buffer: ptr UncheckedArray[float32], len: int) =
for i in 0 ..< len:
buffer[i] = i.float32
proc transpose(M, N: int, bufIn, bufOut: ptr UncheckedArray[float32]) =
## Transpose a MxN matrix into a NxM matrix with nested for loops
parallelFor j in 0 ..< N:
captures: {M, N, bufIn, bufOut}
parallelFor i in 0 ..< M:
captures: {j, M, N, bufIn, bufOut}
bufOut[j*M+i] = bufIn[i*N+j]
proc main() =
let M = 200
let N = 2000
let input = newSeq[float32](M*N)
# We can't work with seq directly as it's managed by GC, take a ptr to the buffer.
let bufIn = cast[ptr UncheckedArray[float32]](input[0].unsafeAddr)
bufIn.initialize(M*N)
var output = newSeq[float32](N*M)
let bufOut = cast[ptr UncheckedArray[float32]](output[0].addr)
init(Weave)
transpose(M, N, bufIn, bufOut)
exit(Weave)
main()You might want to use loops with a non unit-stride, this can be done with the following syntax.
import weave
init(Weave)
# expandMacros:
parallelForStrided i in 0 ..< 100, stride = 30:
parallelForStrided j in 0 ..< 200, stride = 60:
captures: {i}
log("Matrix[%d, %d] (thread %d)\n", i, j, myID())
exit(Weave)We separate the list depending on the threading context
The root thread is the thread that started the Weave runtime. It has special privileges.
init(Weave),exit(Weave)to start and stop the runtime. Forgetting this will give you nil pointer exceptions on spawn.
The thread that callsinitwill become the root thread.syncRoot(Weave)is a global barrier. The root thread will not continue beyond until all tasks in the runtime are finished.
A worker thread is automatically created per (logical) core on the machine. The root thread is also a worker thread. Worker threads are tuned to maximize throughput of computational tasks.
-
spawn fnCall(args)which spawns a function that may run on another thread and gives you an awaitableFlowvarhandle. -
newFlowEvent,trigger,spawnOnEventandspawnOnEvents(experimental) to delay a task until some dependencies are met. This allows expressing precise data dependencies and producer-consumer relationships. -
sync(Flowvar)will await a Flowvar and block until you receive a result. -
isReady(Flowvar)will check ifsyncwill actually block or return the result immediately. -
syncScopeis a scope barrier. The thread will not move beyond the scope until all tasks and parallel loops spawned and their descendants are finished.syncScopeis composable, it can be called by any thread, it can be nested. It has the syntax of a block statement:syncScope(): parallelFor i in 0 ..< N: captures: {a, b} parallelFor j in 0 ..< N: captures: {i, a, b} spawn foo()
In this example, the thread encountering syncScope will create all the tasks for parallel loop i, will spawn foo() and then will be waiting at the end of the scope. A thread blocked at the end of its scope is not idle, it still helps processing all the work existing and that may be created by the current tasks.
-
parallelFor,parallelForStrided,parallelForStaged,parallelForStagedStridedare described above and in the experimental section. -
loadBalance(Weave)gives the runtime the opportunity to distribute work. Insert this within long computation as due to Weave design, it's the busy workers that are also in charge of load balancing. This is done automatically when usingparallelFor. -
isSpawned(Flowvar)allows you to build speculative algorithm where a thread is spawned only if certain conditions are valid. See thenqueensbenchmark for an example. -
getThreadId(Weave)returns a unique thread ID. The thread ID is in the range 0 ..< number of threads.
The max number of worker threads can be configured by the environment variable WEAVE_NUM_THREADS
and default to your number of logical cores (including HyperThreading).
Weave uses Nim's countProcessors() in std/cpuinfo
Weave can also be run as a background service and process jobs similar to the Executor concept in C++.
Jobs will be processed in FIFO order.
Experimental: The distinction between spawn/sync on a Weave thread and submit/waitFor on a foreign thread may be removed in the future.
A background service can be started with either:
thr.runInBackground(Weave)- or
thr.runInBackground(Weave, signalShutdown: ptr Atomic[bool])
with thr an uninitialized Thread[void] or Thread[ptr Atomic[bool]]
Then the foreign thread should call:
setupSubmitterThread(Weave): Configure a thread so that it can send jobs to a background Weave service and on shutdownwaitUntilReady(Weave): Block the foreign thread until the Weave runtime is ready to accept jobs.
and for shutdown
teardownSubmitterThread(Weave): Cleanup Weave resources allocated on the thread.
Once setup, a foreign thread can submit jobs via:
submit fnCall(args)which submits a function to the Weave runtime and gives you an awaitablePendinghandle.newFlowEvent,trigger,submitOnEventandsubmitOnEvents(experimental) to delay a task until some dependencies are met. This allows expressing precise data dependencies and producer-consumer relationships.waitFor(Pending)which await a Pending job result and blocks the current threadisReady(Pending)will check ifwaitForwill actually block or return the result immediately.isSubmitted(job)allows you to build speculative algorithm where a job is submitted only if certain conditions are valid.
Within a job, tasks can be spawned and parallel for constructs can be used.
If runInBackground() does not provide fine enough control, a Weave background event loop
can be customized using the following primitive:
- at a very low-level:
- The root thread primitives:
init(Weave)andexit(Weave) processAllandTryPark(Weave): Process all pending jobs and try sleeping. The sleep may fail to avoid deadlocks if a job is submitted concurrently. This should be used in awhile trueevent loop.
- The root thread primitives:
- at a medium level:
runForever(Weave): Start a never-ending event loop that processes all pending jobs and sleep until new work arrives.runUntil(Weave, signalShutdown: ptr Atomic[bool]): Start an event-loop that quits on signal.
For example:
proc runUntil*(_: typedesc[Weave], signal: ptr Atomic[bool]) =
## Start a Weave event loop until signal is true on the current thread.
## It wakes-up on job submission, handles multithreaded load balancing,
## help process tasks
## and spin down when there is no work anymore.
preCondition: not signal.isNil
while not signal[].load(moRelaxed):
processAllandTryPark(Weave)
syncRoot(Weave)
proc runInBackground*(
_: typedesc[Weave],
signalShutdown: ptr Atomic[bool]
): Thread[ptr Atomic[bool]] =
## Start the Weave runtime on a background thread.
## It wakes-up on job submissions, handles multithreaded load balancing,
## help process tasks
## and spin down when there is no work anymore.
proc eventLoop(shutdown: ptr Atomic[bool]) {.thread.} =
init(Weave)
Weave.runUntil(shutdown)
exit(Weave)
result.createThread(eventLoop, signalShutdown)Weave supports all platforms with pthread and Windows.
Missing pthread functionality may be emulated or unused.
For example on MacOS, the pthread implementation does not expose barrier functionality or affinity settings.
The syncScope feature will not compile correctly in C++ mode if it is used in a for loop.
Upstream: nim-lang/Nim#14118
Windows 32-bit targets cannot use the MinGW compiler as it is missing support
for EnterSynchronizationBarrier. MSVC should work instead.
Weave uses a flexible and efficient memory subsystem that has been optimized for a wide range of hardware: low power Raspberry Pi, phones, laptops, desktops and 30+ cores workstations.
It currently assumes by default that 16KB at least are available on your hardware for a memory pool and that this memory pool can grow as needed.
This can be tuned with -d:WV_MemArenaSize=2048 to have the base pool use 2KB for example.
The pool size should be a multiple of 256 bytes.
PRs to improve support of very restricted devices are welcome.
A Backoff mechanism is enabled by default. It allows workers with no tasks to sleep instead of spinning aimlessly and burning CPU cycles.
It can be disabled with -d:WV_Backoff=off.
Weave multithreading is cooperative, idle threads send steal requests instead of actively stealing in other workers queue. This is called "work-requesting" in the literature as opposed to "work-stealing".
This means that a thread sleeping or stuck in a long computation may starve other threads and they will spin burning CPU cycles.
- Don't sleep or block a thread as this blocks Weave scheduler. This is a similar to
async/awaitlibraries. - If you really need to sleep or block the root thread, make sure to empty all the tasks beforehand with
syncRoot(Weave)in the root thread. The child threads will be put to sleep until new tasks are spawned. - The
loadBalance(Weave)call can be used in the middle of heavy computations to force the worker to answer steal requests. This is automatically done inparallelForloops.loadBalance(Weave)is a very fast call that makes a worker thread checks its queue and dispatch its pending tasks to others. It does not block.
We call the root thread the thread that called init(Weave)
Experimental features might see API and/or implementation changes.
For example both parallelForStaged and parallelReduce allow reductions but parallelForStaged is more flexible, it however requires explicit use of locks and/or atomics.
LazyFlowvars may be enabled by default for certain sizes or if escape analysis become possible or if we prevent Flowvar from escaping their scope.
Loops can be awaited. Awaitable loops return a normal Flowvar.
This blocks the thread that spawned the parallel loop from continuing until the loop is resolved. The thread does not stay idle and will steal and run other tasks while being blocked.
Calling sync on the awaitable loop Flowvar will return true for the last thread to exit the loop and false for the others.
- Due to dynamic load-balancing, an unknown amount of threads will execute the loop.
- It's the thread that spawned the loop task that will always be the last thread to exit.
The
falsevalue is only internal toWeave.
⚠️ This is not a barrier: if that loop spawns tasks (including via a nested loop) and exits, the thread will continue, it will not wait for the grandchildren tasks to be finished. Use asyncScopesection to wait on all tasks and descendants including grandchildren.
import weave
init(Weave)
# expandMacros:
parallelFor i in 0 ..< 10:
awaitable: iLoop
echo "iteration: ", i
let wasLastThread = sync(iLoop)
echo wasLastThread
exit(Weave)Weave provides a parallelForStaged construct with supports for thread-local prologue and epilogue.
A parallel sum would look like this:
proc sumReduce(n: int): int =
let res = result.addr # For mutation we need to capture the address.
parallelForStaged i in 0 .. n:
captures: {res}
awaitable: iLoop
prologue:
var localSum = 0
loop:
localSum += i
epilogue:
echo "Thread ", getThreadID(Weave), ": localsum = ", localSum
res[].atomicInc(localSum)
let wasLastThread = sync(iLoop)
init(Weave)
let sum1M = sumReduce(1000000)
echo "Sum reduce(0..1000000): ", sum1M
doAssert sum1M == 500_000_500_000
exit(Weave)parallelForStagedStrided is also provided.
Weave provides a parallel reduction construct that avoids having to use explicit synchronization like atomics or locks
but instead uses Weave sync(Flowvar) under-the-hood.
Syntax is the following:
proc sumReduce(n: int): int =
var waitableSum: Flowvar[int]
# expandMacros:
parallelReduceImpl i in 0 .. n, stride = 1:
reduce(waitableSum):
prologue:
var localSum = 0
fold:
localSum += i
merge(remoteSum):
localSum += sync(remoteSum)
return localSum
result = sync(waitableSum)
init(Weave)
let sum1M = sumReduce(1000000)
echo "Sum reduce(0..1000000): ", sum1M
doAssert sum1M == 500_000_500_000
exit(Weave)In the future the waitableSum will probably be not required to be declared beforehand.
Or parallel reduce might be removed to only keep parallelForStaged.
Dataflow parallelism allows expressing fine-grained data dependencies between tasks. Concretely a task is delayed until all its dependencies are met and once met, it is triggered immediately.
This allows precise specification of data producer-consumer relationships.
In contrast, classic task parallelism can only express control-flow dependencies (i.e. parent-child function calls relationships) and classic tasks are eagerly scheduled.
In the literature, it is also called:
- Stream parallelism
- Pipeline parallelism
- Graph parallelism
- Data-driven task parallelism
Tagged experimental as the API and its implementation are unique compared to other libraries/language-extensions. Feedback welcome.
No specific ordering is required between calling the event producer and its consumer(s).
Dependencies are expressed by a handle called FlowEvent.
An flow event can express either a single dependency, initialized with newFlowEvent()
or a dependencies on parallel for loop iterations, initialized with newFlowEvent(start, exclusiveStop, stride)
To await on a single event pass it to spawnOnEvent or the parallelFor invocation.
To await on an iteration, pass a tuple:
(FlowEvent, 0)to await precisely and only for iteration 0. This works with bothspawnOnEventorparallelFor(via a dependsOnEvent statement)(FlowEvent, loop_index_variable)to await on a whole iteration range. For exampleThis only works withparallelFor i in 0 ..< n: dependsOnEvent: (e, i) # Each "i" will independently depends on their matching event body
parallelFor. TheFlowEventiteration domain and theparallelFordomain must be the same. As soon as a subset of the pledge is ready, the correspondingparallelFortasks will be scheduled.
import weave
proc echoA(eA: FlowEvent) =
echo "Display A, sleep 1s, create parallel streams 1 and 2"
sleep(1000)
eA.trigger()
proc echoB1(eB1: FlowEvent) =
echo "Display B1, sleep 1s"
sleep(1000)
eB1.trigger()
proc echoB2() =
echo "Display B2, exit stream"
proc echoC1() =
echo "Display C1, exit stream"
proc main() =
echo "Dataflow parallelism with single dependency"
init(Weave)
let eA = newFlowEvent()
let eB1 = newFlowEvent()
spawnOnEvent eB1, echoC1()
spawnOnEvent eA, echoB2()
spawnOnEvent eA, echoB1(eB1)
spawn echoA(eA)
exit(Weave)
main()import weave
proc echoA(eA: FlowEvent) =
echo "Display A, sleep 1s, create parallel streams 1 and 2"
sleep(1000)
eA.trigger()
proc echoB1(eB1: FlowEvent) =
echo "Display B1, sleep 1s"
sleep(1000)
eB1.trigger()
proc echoB2(eB2: FlowEvent) =
echo "Display B2, no sleep"
eB2.trigger()
proc echoC12() =
echo "Display C12, exit stream"
proc main() =
echo "Dataflow parallelism with multiple dependencies"
init(Weave)
let eA = newFlowEvent()
let eB1 = newFlowEvent()
let eB2 = newFlowEvent()
spawnOnEvents eB1, eB2, echoC12()
spawnOnEvent eA, echoB2(eB2)
spawnOnEvent eA, echoB1(eB1)
spawn echoA(eA)
exit(Weave)
main()You can combine data parallelism and dataflow parallelism.
Currently parallel loops only support one dependency (single, fixed iteration or range iteration).
Here is an example with a range iteration dependency. Note: when sleeping threads are unresponsive, meaning a sleeping thread cannot schedule other ready tasks.
import weave
proc main() =
init(Weave)
let eA = newFlowEvent(0, 10, 1)
let pB = newFlowEvent(0, 10, 1)
parallelFor i in 0 ..< 10:
captures: {eA}
sleep(i * 10)
eA.trigger(i)
echo "Step A - stream ", i, " at ", i * 10, " ms"
parallelFor i in 0 ..< 10:
dependsOn: (eA, i)
captures: {pB}
sleep(i * 10)
pB.trigger(i)
echo "Step B - stream ", i, " at ", 2 * i * 10, " ms"
parallelFor i in 0 ..< 10:
dependsOn: (pB, i)
sleep(i * 10)
echo "Step C - stream ", i, " at ", 3 * i * 10, " ms"
exit(Weave)
main()Flowvars can be lazily allocated, this reduces overhead by at least 2x on very fine-grained tasks like Fibonacci or Depth-First-Search that may spawn trillions of tasks in less than
a couple hundreds of milliseconds. This can be enabled with -d:WV_LazyFlowvar.
Weave has not been tested with GC-ed types. Pass a pointer around or use Nim channels which are GC-aware. If it works, a heads-up would be valuable.
This might improve with Nim ARC/newruntime.
Curious minds can access the low-level runtime statistic with the flag -d:WV_metrics
which will give you the information on number of tasks executed, steal requests sent, etc.
Very curious minds can also enable high resolution timers with -d:WV_metrics -d:WV_profile -d:CpuFreqMhz=3000 assuming you have a 3GHz CPU.
The timers will give you in this order:
Time spent running tasks, Time spent recv/send steal requests, Time spent recv/send tasks, Time spent caching tasks, Time spent idle, Total
A number of configuration options are available in weave/config.nim.
In particular:
-d:WV_StealAdaptativeInterval=25defines the number of steal requests after which thieves reevaluate their steal strategy (steal one task or steal half the victim's tasks). Default: 25-d:WV_StealEarly=0allows worker to steal early, when only `WV_StealEraly tasks are leftin their queue. Default: don't steal early
Weave provides an unique scheduler with the following properties:
- Message-Passing based: unlike alternative work-stealing schedulers, this means that Weave is usable on any architecture where message queues, channels or locks are available and not only atomics. Architectures without atomics include distributed clusters or non-cache coherent processors like the Cell Broadband Engine (for the PS3) that favors Direct memory Access (DMA), the many-core mesh Tile CPU from Mellanox (EzChip/Tilera) with 64 to 100 ARM cores, or the network-on-chip (NOC) CPU Epiphany V from Adapteva with 1024 cores, or the research CPU Intel SCC.
- Scalable:
As the number of cores in computer is growing steadily, developers need to find new avenues of parallelism
to exploit them.
Unfortunately existing framework requires computation to take 10000 cycles at minimum (Intel TBB)
which corresponds to 3.33 µs on a 3 GHz CPU to amortize the cost of scheduling.
This burden the developers with questions of grain size, heuristics on distributing parallel loop
for the common case and mischeduling on recursive tree algorithms with potentially very low compute-intensive leaves.
- Weave uses an adaptative work-stealing scheduler that adapts its stealing strategy depending on each core load and the intensity of tasks. Small tasks will be packaged into chunks to amortize scheduling overhead.
- Weave also uses an adaptative lazy loop splitting strategy. Loops will only be split when needed. There is no partitioning issue or grain size issue, or estimating if the workload is memory-bound or compute-bound, see PyTorch OpenMP woes on parallel map.
- Weave aims efficient multicore scaling for very fine-grained tasks starting from the 2000 cycles range upward (0.67 µs on 3GHz).
- Fast and low-overhead: While the number of cores have been growing steadily, many programs are now hitting the limit of memory bandwidth and require tuning allocators, cache lines, CPU caches. Enormous care has been given to optimize Weave to keep it very low-overhead. Weave uses efficient memory allocation and caches to avoid stressing the system allocator and prevent memory fragmentation. Soon, a thread-safe caching system that can release memory to the OS will be added to prevent reserving memory for a long-time.
- Ergonomic and composable: Weave API is based on futures similar to async/await for concurrency. The task dependency graph is implicitly built when awaiting a result An OpenMP-syntax is planned.
The "Project Picasso" RFC is available for discussion in Nim RFC #160 or in the (potentially outdated) picasso_RFC.md file
Weave is based on the research by Andreas Prell. You can read his PhD Thesis or access his C implementation.
Several enhancements were built into Weave, in particular:
- Memory management was carefully studied to allow releasing memory to the OS while still providing very high performance and solving the decades old cactus stack problem. The solution, coupling a threadsafe memory pool with a lookaside buffer, is inspired by Microsoft's Mimalloc and Snmalloc, a message-passing based allocator (also by Microsoft). Details are provided in the multiple Markdown file in the memory folder.
- The channels were reworked to not use locks. In particular the MPSC channel (Multi-Producer Single-Consumer) supports batching for both producers and consumers without any lock.
Licensed and distributed under either of
- MIT license: LICENSE-MIT or http://opensource.org/licenses/MIT
or
- Apache License, Version 2.0, (LICENSE-APACHEv2 or http://www.apache.org/licenses/LICENSE-2.0)
at your option. These files may not be copied, modified, or distributed except according to those terms.