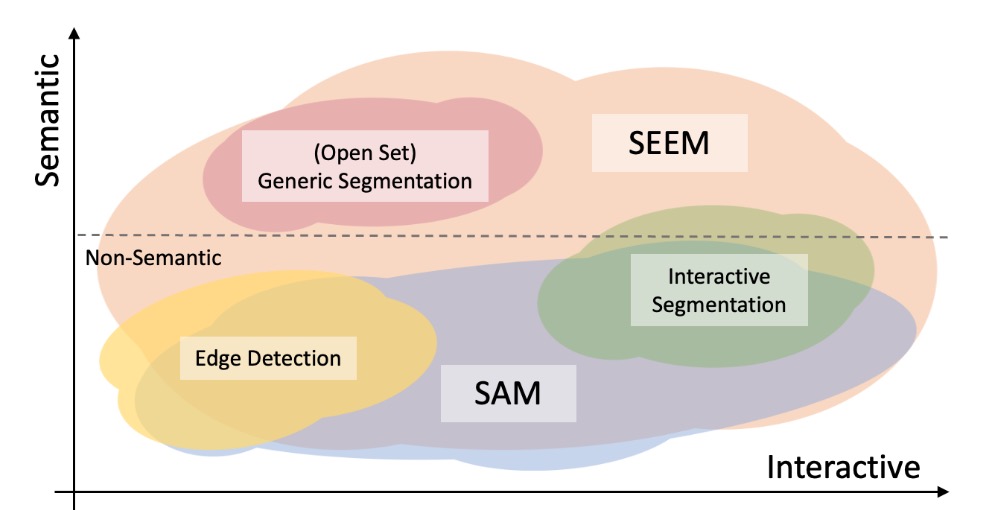
Model vit_h seems to be working fine but vit_b and vit_l throw an error.
This is the error I get:
RuntimeError Traceback (most recent call last)
Cell In [10], line 13
10 mask = infile.replace('.tif', f'_{model_type}_segmented.tif')
11 checkpoint = os.path.join(out_dir, models[model_type])
---> 13 sam = SamGeo(
14 checkpoint = checkpoint,
15 model_type = model_type,
16 device = device,
17 sam_kwargs = None,
18 )
File C:\Python39\lib\site-packages\samgeo\samgeo.py:87, in SamGeo.init(self, model_type, checkpoint, automatic, device, sam_kwargs)
84 self.logits = None
86 # Build the SAM model
---> 87 self.sam = sam_model_registryself.model_type
88 self.sam.to(device=self.device)
89 # Use optional arguments for fine-tuning the SAM model
File C:\Python39\lib\site-packages\segment_anything\build_sam.py:38, in build_sam_vit_b(checkpoint)
37 def build_sam_vit_b(checkpoint=None):
---> 38 return _build_sam(
39 encoder_embed_dim=768,
40 encoder_depth=12,
41 encoder_num_heads=12,
42 encoder_global_attn_indexes=[2, 5, 8, 11],
43 checkpoint=checkpoint,
44 )
File C:\Python39\lib\site-packages\segment_anything\build_sam.py:106, in _build_sam(encoder_embed_dim, encoder_depth, encoder_num_heads, encoder_global_attn_indexes, checkpoint)
104 with open(checkpoint, "rb") as f:
105 state_dict = torch.load(f)
--> 106 sam.load_state_dict(state_dict)
107 return sam
File C:\Python39\lib\site-packages\torch\nn\modules\module.py:2041, in Module.load_state_dict(self, state_dict, strict)
2036 error_msgs.insert(
2037 0, 'Missing key(s) in state_dict: {}. '.format(
2038 ', '.join('"{}"'.format(k) for k in missing_keys)))
2040 if len(error_msgs) > 0:
-> 2041 raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
2042 self.class.name, "\n\t".join(error_msgs)))
2043 return _IncompatibleKeys(missing_keys, unexpected_keys)
RuntimeError: Error(s) in loading state_dict for Sam:
Unexpected key(s) in state_dict: "image_encoder.blocks.12.norm1.weight", "image_encoder.blocks.12.norm1.bias", "image_encoder.blocks.12.attn.rel_pos_h", "image_encoder.blocks.12.attn.rel_pos_w", "image_encoder.blocks.12.attn.qkv.weight", "image_encoder.blocks.12.attn.qkv.bias", "image_encoder.blocks.12.attn.proj.weight", "image_encoder.blocks.12.attn.proj.bias", "image_encoder.blocks.12.norm2.weight", "image_encoder.blocks.12.norm2.bias", "image_encoder.blocks.12.mlp.lin1.weight", "image_encoder.blocks.12.mlp.lin1.bias", "image_encoder.blocks.12.mlp.lin2.weight", "image_encoder.blocks.12.mlp.lin2.bias", "image_encoder.blocks.13.norm1.weight", "image_encoder.blocks.13.norm1.bias", "image_encoder.blocks.13.attn.rel_pos_h", "image_encoder.blocks.13.attn.rel_pos_w", "image_encoder.blocks.13.attn.qkv.weight", "image_encoder.blocks.13.attn.qkv.bias", "image_encoder.blocks.13.attn.proj.weight", "image_encoder.blocks.13.attn.proj.bias", "image_encoder.blocks.13.norm2.weight", "image_encoder.blocks.13.norm2.bias", "image_encoder.blocks.13.mlp.lin1.weight", "image_encoder.blocks.13.mlp.lin1.bias", "image_encoder.blocks.13.mlp.lin2.weight", "image_encoder.blocks.13.mlp.lin2.bias", "image_encoder.blocks.14.norm1.weight", "image_encoder.blocks.14.norm1.bias", "image_encoder.blocks.14.attn.rel_pos_h", "image_encoder.blocks.14.attn.rel_pos_w", "image_encoder.blocks.14.attn.qkv.weight", "image_encoder.blocks.14.attn.qkv.bias", "image_encoder.blocks.14.attn.proj.weight", "image_encoder.blocks.14.attn.proj.bias", "image_encoder.blocks.14.norm2.weight", "image_encoder.blocks.14.norm2.bias", "image_encoder.blocks.14.mlp.lin1.weight", "image_encoder.blocks.14.mlp.lin1.bias", "image_encoder.blocks.14.mlp.lin2.weight", "image_encoder.blocks.14.mlp.lin2.bias", "image_encoder.blocks.15.norm1.weight", "image_encoder.blocks.15.norm1.bias", "image_encoder.blocks.15.attn.rel_pos_h", "image_encoder.blocks.15.attn.rel_pos_w", "image_encoder.blocks.15.attn.qkv.weight", "image_encoder.blocks.15.attn.qkv.bias", "image_encoder.blocks.15.attn.proj.weight", "image_encoder.blocks.15.attn.proj.bias", "image_encoder.blocks.15.norm2.weight", "image_encoder.blocks.15.norm2.bias", "image_encoder.blocks.15.mlp.lin1.weight", "image_encoder.blocks.15.mlp.lin1.bias", "image_encoder.blocks.15.mlp.lin2.weight", "image_encoder.blocks.15.mlp.lin2.bias", "image_encoder.blocks.16.norm1.weight", "image_encoder.blocks.16.norm1.bias", "image_encoder.blocks.16.attn.rel_pos_h", "image_encoder.blocks.16.attn.rel_pos_w", "image_encoder.blocks.16.attn.qkv.weight", "image_encoder.blocks.16.attn.qkv.bias", "image_encoder.blocks.16.attn.proj.weight", "image_encoder.blocks.16.attn.proj.bias", "image_encoder.blocks.16.norm2.weight", "image_encoder.blocks.16.norm2.bias", "image_encoder.blocks.16.mlp.lin1.weight", "image_encoder.blocks.16.mlp.lin1.bias", "image_encoder.blocks.16.mlp.lin2.weight", "image_encoder.blocks.16.mlp.lin2.bias", "image_encoder.blocks.17.norm1.weight", "image_encoder.blocks.17.norm1.bias", "image_encoder.blocks.17.attn.rel_pos_h", "image_encoder.blocks.17.attn.rel_pos_w", "image_encoder.blocks.17.attn.qkv.weight", "image_encoder.blocks.17.attn.qkv.bias", "image_encoder.blocks.17.attn.proj.weight", "image_encoder.blocks.17.attn.proj.bias", "image_encoder.blocks.17.norm2.weight", "image_encoder.blocks.17.norm2.bias", "image_encoder.blocks.17.mlp.lin1.weight", "image_encoder.blocks.17.mlp.lin1.bias", "image_encoder.blocks.17.mlp.lin2.weight", "image_encoder.blocks.17.mlp.lin2.bias", "image_encoder.blocks.18.norm1.weight", "image_encoder.blocks.18.norm1.bias", "image_encoder.blocks.18.attn.rel_pos_h", "image_encoder.blocks.18.attn.rel_pos_w", "image_encoder.blocks.18.attn.qkv.weight", "image_encoder.blocks.18.attn.qkv.bias", "image_encoder.blocks.18.attn.proj.weight", "image_encoder.blocks.18.attn.proj.bias", "image_encoder.blocks.18.norm2.weight", "image_encoder.blocks.18.norm2.bias", "image_encoder.blocks.18.mlp.lin1.weight", "image_encoder.blocks.18.mlp.lin1.bias", "image_encoder.blocks.18.mlp.lin2.weight", "image_encoder.blocks.18.mlp.lin2.bias", "image_encoder.blocks.19.norm1.weight", "image_encoder.blocks.19.norm1.bias", "image_encoder.blocks.19.attn.rel_pos_h", "image_encoder.blocks.19.attn.rel_pos_w", "image_encoder.blocks.19.attn.qkv.weight", "image_encoder.blocks.19.attn.qkv.bias", "image_encoder.blocks.19.attn.proj.weight", "image_encoder.blocks.19.attn.proj.bias", "image_encoder.blocks.19.norm2.weight", "image_encoder.blocks.19.norm2.bias", "image_encoder.blocks.19.mlp.lin1.weight", "image_encoder.blocks.19.mlp.lin1.bias", "image_encoder.blocks.19.mlp.lin2.weight", "image_encoder.blocks.19.mlp.lin2.bias", "image_encoder.blocks.20.norm1.weight", "image_encoder.blocks.20.norm1.bias", "image_encoder.blocks.20.attn.rel_pos_h", "image_encoder.blocks.20.attn.rel_pos_w", "image_encoder.blocks.20.attn.qkv.weight", "image_encoder.blocks.20.attn.qkv.bias", "image_encoder.blocks.20.attn.proj.weight", "image_encoder.blocks.20.attn.proj.bias", "image_encoder.blocks.20.norm2.weight", "image_encoder.blocks.20.norm2.bias", "image_encoder.blocks.20.mlp.lin1.weight", "image_encoder.blocks.20.mlp.lin1.bias", "image_encoder.blocks.20.mlp.lin2.weight", "image_encoder.blocks.20.mlp.lin2.bias", "image_encoder.blocks.21.norm1.weight", "image_encoder.blocks.21.norm1.bias", "image_encoder.blocks.21.attn.rel_pos_h", "image_encoder.blocks.21.attn.rel_pos_w", "image_encoder.blocks.21.attn.qkv.weight", "image_encoder.blocks.21.attn.qkv.bias", "image_encoder.blocks.21.attn.proj.weight", "image_encoder.blocks.21.attn.proj.bias", "image_encoder.blocks.21.norm2.weight", "image_encoder.blocks.21.norm2.bias", "image_encoder.blocks.21.mlp.lin1.weight", "image_encoder.blocks.21.mlp.lin1.bias", "image_encoder.blocks.21.mlp.lin2.weight", "image_encoder.blocks.21.mlp.lin2.bias", "image_encoder.blocks.22.norm1.weight", "image_encoder.blocks.22.norm1.bias", "image_encoder.blocks.22.attn.rel_pos_h", "image_encoder.blocks.22.attn.rel_pos_w", "image_encoder.blocks.22.attn.qkv.weight", "image_encoder.blocks.22.attn.qkv.bias", "image_encoder.blocks.22.attn.proj.weight", "image_encoder.blocks.22.attn.proj.bias", "image_encoder.blocks.22.norm2.weight", "image_encoder.blocks.22.norm2.bias", "image_encoder.blocks.22.mlp.lin1.weight", "image_encoder.blocks.22.mlp.lin1.bias", "image_encoder.blocks.22.mlp.lin2.weight", "image_encoder.blocks.22.mlp.lin2.bias", "image_encoder.blocks.23.norm1.weight", "image_encoder.blocks.23.norm1.bias", "image_encoder.blocks.23.attn.rel_pos_h", "image_encoder.blocks.23.attn.rel_pos_w", "image_encoder.blocks.23.attn.qkv.weight", "image_encoder.blocks.23.attn.qkv.bias", "image_encoder.blocks.23.attn.proj.weight", "image_encoder.blocks.23.attn.proj.bias", "image_encoder.blocks.23.norm2.weight", "image_encoder.blocks.23.norm2.bias", "image_encoder.blocks.23.mlp.lin1.weight", "image_encoder.blocks.23.mlp.lin1.bias", "image_encoder.blocks.23.mlp.lin2.weight", "image_encoder.blocks.23.mlp.lin2.bias", "image_encoder.blocks.24.norm1.weight", "image_encoder.blocks.24.norm1.bias", "image_encoder.blocks.24.attn.rel_pos_h", "image_encoder.blocks.24.attn.rel_pos_w", "image_encoder.blocks.24.attn.qkv.weight", "image_encoder.blocks.24.attn.qkv.bias", "image_encoder.blocks.24.attn.proj.weight", "image_encoder.blocks.24.attn.proj.bias", "image_encoder.blocks.24.norm2.weight", "image_encoder.blocks.24.norm2.bias", "image_encoder.blocks.24.mlp.lin1.weight", "image_encoder.blocks.24.mlp.lin1.bias", "image_encoder.blocks.24.mlp.lin2.weight", "image_encoder.blocks.24.mlp.lin2.bias", "image_encoder.blocks.25.norm1.weight", "image_encoder.blocks.25.norm1.bias", "image_encoder.blocks.25.attn.rel_pos_h", "image_encoder.blocks.25.attn.rel_pos_w", "image_encoder.blocks.25.attn.qkv.weight", "image_encoder.blocks.25.attn.qkv.bias", "image_encoder.blocks.25.attn.proj.weight", "image_encoder.blocks.25.attn.proj.bias", "image_encoder.blocks.25.norm2.weight", "image_encoder.blocks.25.norm2.bias", "image_encoder.blocks.25.mlp.lin1.weight", "image_encoder.blocks.25.mlp.lin1.bias", "image_encoder.blocks.25.mlp.lin2.weight", "image_encoder.blocks.25.mlp.lin2.bias", "image_encoder.blocks.26.norm1.weight", "image_encoder.blocks.26.norm1.bias", "image_encoder.blocks.26.attn.rel_pos_h", "image_encoder.blocks.26.attn.rel_pos_w", "image_encoder.blocks.26.attn.qkv.weight", "image_encoder.blocks.26.attn.qkv.bias", "image_encoder.blocks.26.attn.proj.weight", "image_encoder.blocks.26.attn.proj.bias", "image_encoder.blocks.26.norm2.weight", "image_encoder.blocks.26.norm2.bias", "image_encoder.blocks.26.mlp.lin1.weight", "image_encoder.blocks.26.mlp.lin1.bias", "image_encoder.blocks.26.mlp.lin2.weight", "image_encoder.blocks.26.mlp.lin2.bias", "image_encoder.blocks.27.norm1.weight", "image_encoder.blocks.27.norm1.bias", "image_encoder.blocks.27.attn.rel_pos_h", "image_encoder.blocks.27.attn.rel_pos_w", "image_encoder.blocks.27.attn.qkv.weight", "image_encoder.blocks.27.attn.qkv.bias", "image_encoder.blocks.27.attn.proj.weight", "image_encoder.blocks.27.attn.proj.bias", "image_encoder.blocks.27.norm2.weight", "image_encoder.blocks.27.norm2.bias", "image_encoder.blocks.27.mlp.lin1.weight", "image_encoder.blocks.27.mlp.lin1.bias", "image_encoder.blocks.27.mlp.lin2.weight", "image_encoder.blocks.27.mlp.lin2.bias", "image_encoder.blocks.28.norm1.weight", "image_encoder.blocks.28.norm1.bias", "image_encoder.blocks.28.attn.rel_pos_h", "image_encoder.blocks.28.attn.rel_pos_w", "image_encoder.blocks.28.attn.qkv.weight", "image_encoder.blocks.28.attn.qkv.bias", "image_encoder.blocks.28.attn.proj.weight", "image_encoder.blocks.28.attn.proj.bias", "image_encoder.blocks.28.norm2.weight", "image_encoder.blocks.28.norm2.bias", "image_encoder.blocks.28.mlp.lin1.weight", "image_encoder.blocks.28.mlp.lin1.bias", "image_encoder.blocks.28.mlp.lin2.weight", "image_encoder.blocks.28.mlp.lin2.bias", "image_encoder.blocks.29.norm1.weight", "image_encoder.blocks.29.norm1.bias", "image_encoder.blocks.29.attn.rel_pos_h", "image_encoder.blocks.29.attn.rel_pos_w", "image_encoder.blocks.29.attn.qkv.weight", "image_encoder.blocks.29.attn.qkv.bias", "image_encoder.blocks.29.attn.proj.weight", "image_encoder.blocks.29.attn.proj.bias", "image_encoder.blocks.29.norm2.weight", "image_encoder.blocks.29.norm2.bias", "image_encoder.blocks.29.mlp.lin1.weight", "image_encoder.blocks.29.mlp.lin1.bias", "image_encoder.blocks.29.mlp.lin2.weight", "image_encoder.blocks.29.mlp.lin2.bias", "image_encoder.blocks.30.norm1.weight", "image_encoder.blocks.30.norm1.bias", "image_encoder.blocks.30.attn.rel_pos_h", "image_encoder.blocks.30.attn.rel_pos_w", "image_encoder.blocks.30.attn.qkv.weight", "image_encoder.blocks.30.attn.qkv.bias", "image_encoder.blocks.30.attn.proj.weight", "image_encoder.blocks.30.attn.proj.bias", "image_encoder.blocks.30.norm2.weight", "image_encoder.blocks.30.norm2.bias", "image_encoder.blocks.30.mlp.lin1.weight", "image_encoder.blocks.30.mlp.lin1.bias", "image_encoder.blocks.30.mlp.lin2.weight", "image_encoder.blocks.30.mlp.lin2.bias", "image_encoder.blocks.31.norm1.weight", "image_encoder.blocks.31.norm1.bias", "image_encoder.blocks.31.attn.rel_pos_h", "image_encoder.blocks.31.attn.rel_pos_w", "image_encoder.blocks.31.attn.qkv.weight", "image_encoder.blocks.31.attn.qkv.bias", "image_encoder.blocks.31.attn.proj.weight", "image_encoder.blocks.31.attn.proj.bias", "image_encoder.blocks.31.norm2.weight", "image_encoder.blocks.31.norm2.bias", "image_encoder.blocks.31.mlp.lin1.weight", "image_encoder.blocks.31.mlp.lin1.bias", "image_encoder.blocks.31.mlp.lin2.weight", "image_encoder.blocks.31.mlp.lin2.bias".
size mismatch for image_encoder.pos_embed: copying a param with shape torch.Size([1, 64, 64, 1280]) from checkpoint, the shape in current model is torch.Size([1, 64, 64, 768]).
size mismatch for image_encoder.patch_embed.proj.weight: copying a param with shape torch.Size([1280, 3, 16, 16]) from checkpoint, the shape in current model is torch.Size([768, 3, 16, 16]).
size mismatch for image_encoder.patch_embed.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.0.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.0.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.0.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.0.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.0.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.0.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.0.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.0.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.0.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.0.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.0.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.0.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.0.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.0.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.1.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.1.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.1.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.1.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.1.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.1.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.1.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.1.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.1.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.1.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.1.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.1.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.1.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.1.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.2.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.2.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.2.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([127, 64]).
size mismatch for image_encoder.blocks.2.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([127, 64]).
size mismatch for image_encoder.blocks.2.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.2.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.2.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.2.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.2.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.2.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.2.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.2.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.2.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.2.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.3.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.3.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.3.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.3.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.3.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.3.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.3.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.3.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.3.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.3.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.3.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.3.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.3.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.3.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.4.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.4.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.4.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.4.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.4.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.4.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.4.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.4.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.4.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.4.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.4.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.4.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.4.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.4.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.5.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.5.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.5.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([127, 64]).
size mismatch for image_encoder.blocks.5.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([127, 64]).
size mismatch for image_encoder.blocks.5.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.5.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.5.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.5.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.5.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.5.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.5.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.5.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.5.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.5.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.6.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.6.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.6.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.6.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.6.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.6.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.6.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.6.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.6.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.6.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.6.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.6.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.6.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.6.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.7.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.7.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.7.attn.rel_pos_h: copying a param with shape torch.Size([127, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.7.attn.rel_pos_w: copying a param with shape torch.Size([127, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.7.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.7.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.7.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.7.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.7.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.7.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.7.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.7.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.7.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.7.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.8.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.8.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.8.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([127, 64]).
size mismatch for image_encoder.blocks.8.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([127, 64]).
size mismatch for image_encoder.blocks.8.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.8.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.8.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.8.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.8.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.8.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.8.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.8.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.8.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.8.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.9.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.9.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.9.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.9.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.9.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.9.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.9.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.9.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.9.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.9.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.9.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.9.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.9.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.9.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.10.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.10.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.10.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.10.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([27, 64]).
size mismatch for image_encoder.blocks.10.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.10.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.10.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.10.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.10.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.10.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.10.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.10.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.10.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.10.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.11.norm1.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.11.norm1.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.11.attn.rel_pos_h: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([127, 64]).
size mismatch for image_encoder.blocks.11.attn.rel_pos_w: copying a param with shape torch.Size([27, 80]) from checkpoint, the shape in current model is torch.Size([127, 64]).
size mismatch for image_encoder.blocks.11.attn.qkv.weight: copying a param with shape torch.Size([3840, 1280]) from checkpoint, the shape in current model is torch.Size([2304, 768]).
size mismatch for image_encoder.blocks.11.attn.qkv.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for image_encoder.blocks.11.attn.proj.weight: copying a param with shape torch.Size([1280, 1280]) from checkpoint, the shape in current model is torch.Size([768, 768]).
size mismatch for image_encoder.blocks.11.attn.proj.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.11.norm2.weight: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.11.norm2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.blocks.11.mlp.lin1.weight: copying a param with shape torch.Size([5120, 1280]) from checkpoint, the shape in current model is torch.Size([3072, 768]).
size mismatch for image_encoder.blocks.11.mlp.lin1.bias: copying a param with shape torch.Size([5120]) from checkpoint, the shape in current model is torch.Size([3072]).
size mismatch for image_encoder.blocks.11.mlp.lin2.weight: copying a param with shape torch.Size([1280, 5120]) from checkpoint, the shape in current model is torch.Size([768, 3072]).
size mismatch for image_encoder.blocks.11.mlp.lin2.bias: copying a param with shape torch.Size([1280]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for image_encoder.neck.0.weight: copying a param with shape torch.Size([256, 1280, 1, 1]) from checkpoint, the shape in current model is torch.Size([256, 768, 1, 1]).






















![pre-commit-ci[bot] avatar](https://avatars.githubusercontent.com/in/68672?v=4 "pre-commit-ci[bot]")