| CI/CD | |
| Package |    |
| Meta | |
| Chat |  |
Mesa allows users to quickly create agent-based models using built-in core components (such as spatial grids and agent schedulers) or customized implementations; visualize them using a browser-based interface; and analyze their results using Python's data analysis tools. Its goal is to be the Python-based alternative to NetLogo, Repast, or MASON.
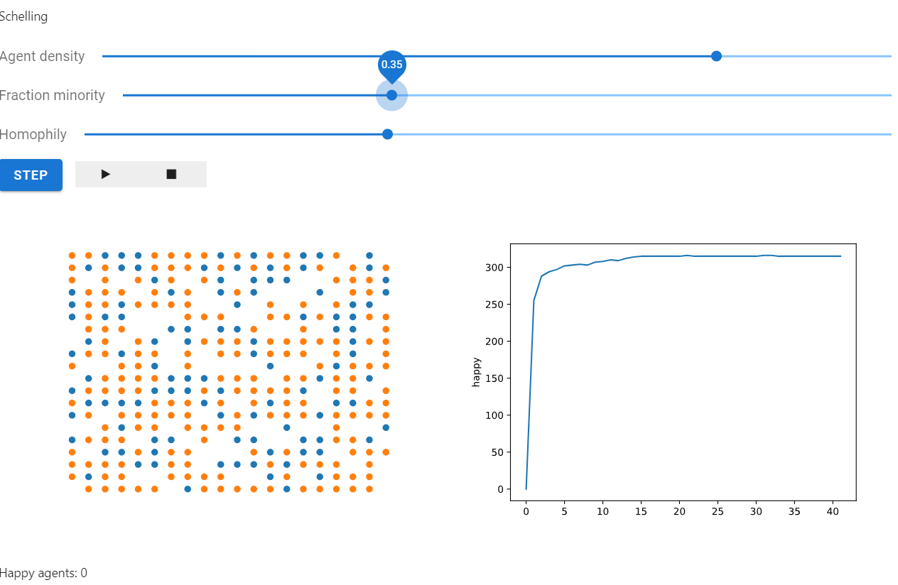
Above: A Mesa implementation of the Schelling segregation model, this can be displayed in browser windows or Jupyter.
- Modular components
- Browser-based visualization
- Built-in tools for analysis
- Example model library
Getting started quickly:
pip install mesaYou can also use pip to install the github version:
pip install -U -e git+https://github.com/projectmesa/mesa@main#egg=mesaOr any other (development) branch on this repo or your own fork:
pip install -U -e git+https://github.com/YOUR_FORK/mesa@YOUR_BRANCH#egg=mesaFor resources or help on using Mesa, check out the following:
- Intro to Mesa Tutorial (An introductory model, the Boltzmann Wealth Model, for beginners or those new to Mesa.)
- Complexity Explorer Tutorial (An advanced-beginner model, SugarScape with Traders, with instructional videos)
- Mesa Examples (A repository of seminal ABMs using Mesa and examples of employing specific Mesa Features)
- Docs (Mesa's documentation, API and useful snippets)
- Discussions (GitHub threaded discussions about Mesa)
- Matrix Chat (Chat Forum via Matrix to talk about Mesa)
You can run Mesa in a Docker container in a few ways.
If you are a Mesa developer, first install Docker Compose and then, in the folder containing the Mesa Git repository, you run:
$ docker compose up
# If you want to make it run in the background, you instead run
$ docker compose up -dThis runs the Schelling model, as an example.
With the docker-compose.yml file in this Git repository, the docker compose up command does two important things:
- It mounts the mesa root directory (relative to the docker-compose.yml file) into /opt/mesa and runs pip install -e on that directory so your changes to mesa should be reflected in the running container.
- It binds the docker container's port 8765 to your host system's port 8765 so you can interact with the running model as usual by visiting localhost:8765 on your browser
If you are a model developer that wants to run Mesa on a model, you need to:
- make sure that your model folder is inside the folder containing the docker-compose.yml file
- change the
MODEL_DIRvariable in docker-compose.yml to point to the path of your model - make sure that the model folder contains an app.py file
Then, you just need to run docker compose up -d to have it
accessible from localhost:8765.
Want to join the Mesa team or just curious about what is happening with Mesa? You can...
- Join our Matrix chat room in which questions, issues, and ideas can be (informally) discussed.
- Come to a monthly dev session (you can find dev session times, agendas and notes on Mesa discussions).
- Just check out the code on GitHub.
If you run into an issue, please file a ticket for us to discuss. If possible, follow up with a pull request.
If you would like to add a feature, please reach out via ticket or join a dev session (see Mesa discussions). A feature is most likely to be added if you build it!
Don't forget to checkout the Contributors guide.
To cite Mesa in your publication, you can use the CITATION.bib.



![deepsource-autofix[bot] avatar](https://avatars.githubusercontent.com/in/57168?v=4 "deepsource-autofix[bot]")
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")














![pre-commit-ci[bot] avatar](https://avatars.githubusercontent.com/in/68672?v=4 "pre-commit-ci[bot]")

































































































































































































