by Letian Fu*, Long Lian*, Renhao Wang, Baifeng Shi, Xudong Wang, Adam Yala†, Trevor Darrell†, Alexei A. Efros†, Ken Goldberg† at UC Berkeley and UCSF
[Paper] | [Project Page] | [Citation]
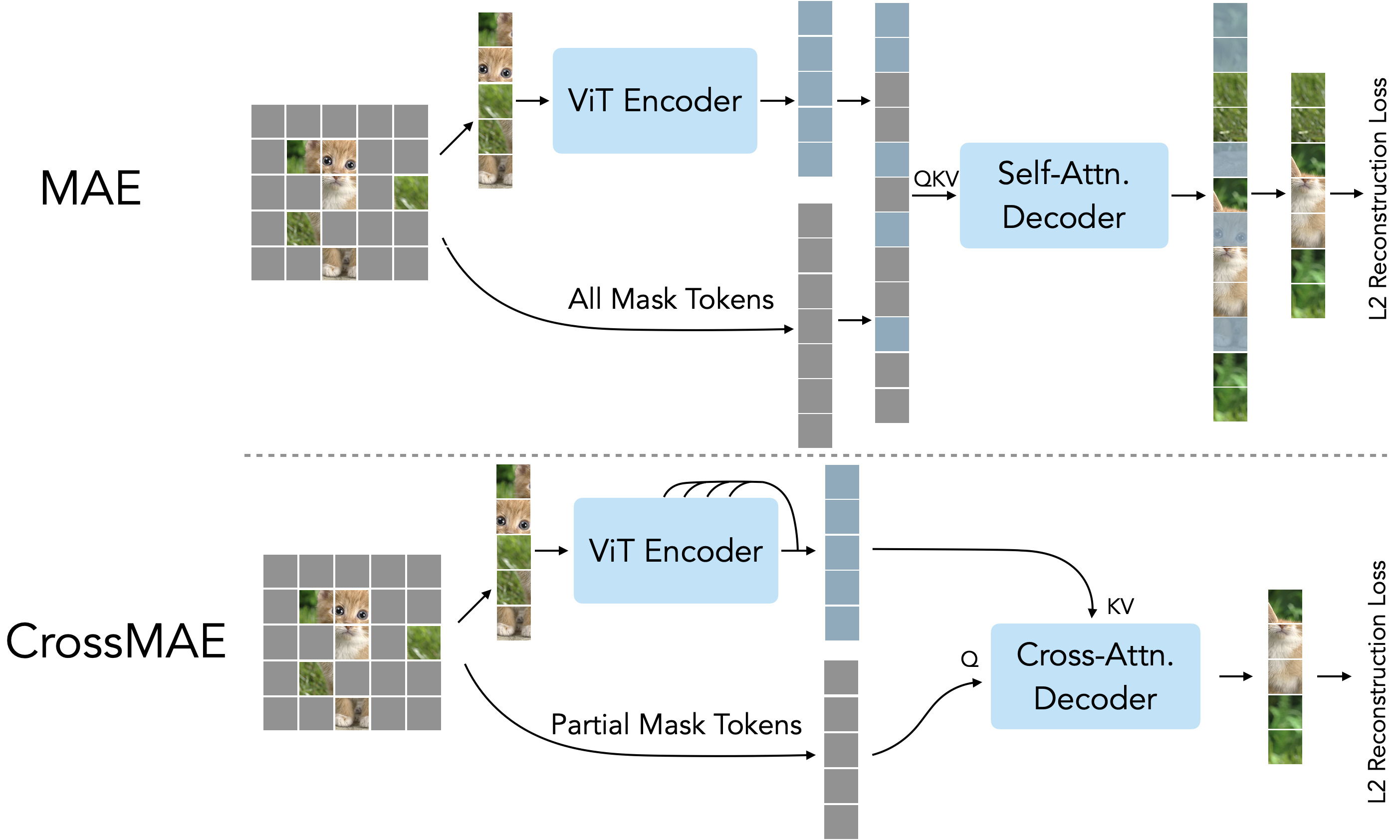
This is a PyTorch implementation of the CrossMAE paper Rethinking Patch Dependence for Masked Autoencoders. The code is based on the original MAE repo. The codebase supports CrossMAE and MAE, with timm==0.9.7, torch==2.0.0, and flash-attn 2.
The encoder part of CrossMAE matches exactly with MAE. Therefore, we use the same code for fine-tuning. We also encourage you to try CrossMAE checkpoints in your downstream applications. These models are trained on ImageNet-1k for 800 epochs (except that 448 models are trained for 400 epochs), with masking ratio and kept mask ratio both set to 0.75, except that ViT-H is with masking ratio 0.75 and kept mask ratio 0.25.
| ViT-Small | ViT-Base | ViT-Base448 | ViT-Large | ViT-Huge | |
|---|---|---|---|---|---|
| pretrained checkpoint | download | download | download | download | download |
| fine-tuned checkpoint | download | download | download | download | download |
| Reference ImageNet accuracy (ours) | 79.318 | 83.722 | 84.598 | 85.432 | 86.256 |
| MAE ImageNet accuracy (baseline) | 84.8 | 85.9 |
With the efficiency of CrossMAE, it's possible to train CrossMAE on one single RTX 4090 on a personal computer. The CPU is i9-14900k, with 96GB RAM.
Instructions and trained models
The training and fine-tuning command (with ${IMAGENET_DIR} the directory for imagenet, ViT-S as an example):
CUDA_VISIBLE_DEVICES=0 OMP_NUM_THREADS=1 torchrun --nproc_per_node=1 --master_port 2780 main_pretrain.py --batch_size 512 --accum_iter 8 --model mae_vit_small_patch16 --norm_pix_loss --blr 1.5e-4 --weight_decay 0.05 --data_path ${IMAGENET_DIR} --num_workers 16 --multi_epochs_dataloader --output_dir output/imagenet-crossmae-vits-pretrain-wfm-mr0.75-kmr0.25-dd12-ep800 --cross_mae --weight_fm --decoder_depth 12 --mask_ratio 0.75 --kept_mask_ratio 0.75 --epochs 800 --warmup_epochs 40 --use_input
CUDA_VISIBLE_DEVICES=0 OMP_NUM_THREADS=1 torchrun --nproc_per_node=1 --master_port 2860 main_finetune.py --batch_size 512 --accum_iter 2 --model vit_small_patch16 --finetune output/imagenet-crossmae-vits-pretrain-wfm-mr0.75-kmr0.25-dd12-ep800/checkpoint.pth --epoch 100 --blr 5e-4 --layer_decay 0.65 --weight_decay 0.05 --drop_path 0.1 --reprob 0.25 --mixup 0.8 --cutmix 1.0 --dist_eval --data_path ${IMAGENET_DIR} --num_workers 12 --output_dir output/imagenet-crossmae-vits-finetune-wfm-mr0.75-kmr0.25-dd12-ep800 --multi_epochs_dataloader
# Reference results:
# * Acc@1 79.462 Acc@5 94.864 loss 0.907| pretrained checkpoint | fine-tuned checkpoint | reference ImageNet accuracy |
|---|---|---|
| download | download | 79.462 |
Please install the dependencies in requirements.txt:
# Optionally create a conda environment
conda create -n crossmae python=3.10 -y
conda activate crossmae
# Install dependencies
pip install -r requirements.txtTo pre-train ViT-Base, run the following on 4 GPUs:
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port 1234 main_pretrain.py --batch_size 1024 --model mae_vit_base_patch16 --norm_pix_loss --blr 1.5e-4 --weight_decay 0.05 --data_path ${IMAGENET_DIR} --num_workers 20 --enable_flash_attention2 --multi_epochs_dataloader --output_dir output/imagenet-crossmae-vitb-pretrain-wfm-mr0.75-kmr0.25-dd12-ep800 --cross_mae --weight_fm --decoder_depth 12 --mask_ratio 0.75 --kept_mask_ratio 0.25 --epochs 800 --warmup_epochs 40 --use_inputTo train ViT-Small or ViT-Large, set --model mae_vit_small_patch16 or --model mae_vit_large_patch16. You can use --accum_iter to perform gradient accumulation if your hardware could not fit the batch size. FlashAttention 2 should be installed with pip install flash-attn --no-build-isolation.
To pre-train ViT-Base, run the following on 4 GPUs:
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port 1234 main_finetune.py --batch_size 256 --model vit_base_patch16 --finetune output/imagenet-crossmae-vitb-pretrain-wfm-mr0.75-kmr0.25-dd12-ep800/checkpoint.pth --epoch 100 --blr 5e-4 --layer_decay 0.65 --weight_decay 0.05 --drop_path 0.1 --reprob 0.25 --mixup 0.8 --cutmix 1.0 --dist_eval --data_path ${IMAGENET_DIR} --output_dir output/imagenet-crossmae-vitb-finetune-wfm-mr0.75-kmr0.25-dd12-ep800 --enable_flash_attention2 --multi_epochs_dataloaderEvaluate ViT-Base in a single GPU (${IMAGENET_DIR} is a directory containing {train, val} sets of ImageNet). ${FINETUNED_CHECKPOINT_PATH} is the path to the fine-tuned checkpoint:
python main_finetune.py --eval --resume ${FINETUNED_CHECKPOINT_PATH} --model vit_base_patch16 --batch_size 16 --data_path ${IMAGENET_DIR}This should give:
* Acc@1 83.722 Acc@5 96.686 loss 0.729
You could replace vit_base_patch16 with vit_small_patch16 or vit_large_patch16 to evaluate ViT-S or ViT-L. To work with 448 input resolution, please append --input_size 448 to the command line.
This project is under the CC-BY-NC 4.0 license. See LICENSE for details.
Please give us a star 🌟 on Github to support us!
Please cite our work if you find our work inspiring or use our code in your work:
@article{fu2024rethinking,
title={Rethinking Patch Dependence for Masked Autoencoders},
author={Letian Fu and Long Lian and Renhao Wang and Baifeng Shi and Xudong Wang and Adam Yala and Trevor Darrell and Alexei A. Efros and Ken Goldberg},
journal={arXiv preprint arXiv:2401.14391},
year={2024}
}



















































































