





Ruby grammar for tree-sitter.
Ruby grammar for tree-sitter
License: MIT License
Ruby grammar for tree-sitter.



































































































































INPUT versus ALT0. Both are constants, but they have different colors.
Thanks!

Create a new ruby file and put the following text in it
module A
module B
class C
def D
puts 'test'
end
end
end
endTry to fold using either the fold handles or the fold-at-indent-level-* functions.
You can fold ruby code at modules the same as at classes and methods
Modules don't fold (at all)
Static elements of word and symbol lists are ignored:
$ node_modules/.bin/tree-sitter parse <(echo '%w(foo bar)')
(program [0, 0] - [1, 0]
(array [0, 0] - [0, 11]))
$ node_modules/.bin/tree-sitter parse <(echo '%W(foo bar)')
(program [0, 0] - [1, 0]
(array [0, 0] - [0, 11]))
$ node_modules/.bin/tree-sitter parse <(echo '%i(abc def)')
(program [0, 0] - [1, 0]
(array [0, 0] - [0, 11]))
$ node_modules/.bin/tree-sitter parse <(echo '%I(abc def)')
(program [0, 0] - [1, 0]
(array [0, 0] - [0, 11]))
However in literal types allowing interpolation (%W and %I), interpolated elements behave as expected:
$ node_modules/.bin/tree-sitter parse <(echo '%W(foo #{123} bar #{"456"})')
(program [0, 0] - [1, 0]
(array [0, 0] - [0, 27]
(integer [0, 9] - [0, 12])
(string [0, 20] - [0, 25])))
$ node_modules/.bin/tree-sitter parse <(echo '%I(foo #{123} bar #{"456"})')
(program [0, 0] - [1, 0]
(array [0, 0] - [0, 27]
(integer [0, 9] - [0, 12])
(string [0, 20] - [0, 25])))
It also appears that the AST does not distinguish between regular word lists and symbol lists.
Code
{key1:true}
{key?:true}
{key!:true}
Produce (program (hash (ERROR (method_call (identifier) (argument_list (symbol))))))
but it's valid code for ruby interpreter:
irb(main):005:0> {key1:true}
=> {:key1=>true}
irb(main):006:0> {key?:true}
=> {:key?=>true}
irb(main):007:0> {key!:true}
=> {:key!=>true}

require_relative has class: 'syntax--entity syntax--name syntax--function'.
require has class: 'syntax--support syntax--function'.
I think both of them should be belongs to 'syntax--support', right?
#4 implemented all of the other literals, but not heredoc strings/subshells, because:
There’s no way for us to use a matched token as the end delimiter. We would need something essentially like monadic bind to make this work.
Heredoc elements apply to the next line. I don’t know a way to make that work correctly w.r.t. the remainder of the current line:
print (<<END + ", world")
hello
ENDfoo.rb:
# this works
a(b:'c',)
# this works too
a(b_:'c')
# this chokes on the trailing comma
a(b_:'c',)
$ npx tree-sitter parse foo.rb
(program [0, 0] - [8, 0]
(comment [0, 0] - [0, 12])
(method_call [1, 0] - [1, 9]
method: (identifier [1, 0] - [1, 1])
arguments: (argument_list [1, 1] - [1, 9]
(pair [1, 2] - [1, 7]
key: (symbol [1, 2] - [1, 3])
value: (string [1, 4] - [1, 7]
(string_content [1, 5] - [1, 6])))))
(comment [3, 0] - [3, 16])
(method_call [4, 0] - [4, 9]
method: (identifier [4, 0] - [4, 1])
arguments: (argument_list [4, 1] - [4, 9]
(method_call [4, 2] - [4, 8]
method: (identifier [4, 2] - [4, 4])
arguments: (argument_list [4, 4] - [4, 8]
(symbol [4, 4] - [4, 8]
(string_content [4, 6] - [4, 7]))))))
(comment [6, 0] - [6, 12])
(method_call [7, 0] - [7, 10]
method: (identifier [7, 0] - [7, 1])
arguments: (argument_list [7, 1] - [7, 10]
(method_call [7, 2] - [7, 8]
method: (identifier [7, 2] - [7, 4])
arguments: (argument_list [7, 4] - [7, 8]
(symbol [7, 4] - [7, 8]
(string_content [7, 6] - [7, 7]))))
(ERROR [7, 8] - [7, 9]))))
foo.rb 0 ms (ERROR [7, 8] - [7, 9])
The parser fails on expressions like /#{ }/n complaining that there should be an identifier after the #{ . The ruby interpreter does not complain about this.
Several examples can be found at:
https://github.com/ruby/ruby/blob/c565dfb09ad7d55fa671f65cea7088a914bf1931/test/ruby/test_m17n.rb#L785
Thanks for this excellent project!
I'm using nvim-treesitter and 8fd340f and seeing Symbols highlighted the same as Constants. Is there a way to distinguish between the two so I can highlight them differently?
Here's screenshots using :TSHighlightCapturesUnderCursor from nvim-treesitter/playground


For example here, PI_BANK() is being highlighted as a constant, but it's actually a method call.
Vim seems to get this right, but I think it does so by looking for a ():

The file in question comes from metasploit-framework: windows_registry_parser.rb.
It appears that the parser errors on uppercase int literal prefixes:
class WindowsRegistryParser
# SK magic value: 'sk'
SK_MAGIC = 0X7269
endI.e. 0X7269 fails, but 0x7269 does not.
Apparently, these prefixes are case insensitive. Oddly enough, it looks like this only errors out for hex values - decimal, octal, and binary appear to work. It couldn't hurt to double check me here, though.
"#{ foo; bar }"is accepted by MRI, but not by tree-sitter:
program [0, 0] - [1, 0])
string [0, 0] - [0, 15])
interpolation [0, 1] - [0, 14])
method_call [0, 4] - [0, 12])
method: identifier [0, 4] - [0, 7])
ERROR [0, 7] - [0, 8])
arguments: argument_list [0, 9] - [0, 12])
identifier [0, 9] - [0, 12])
An infinite loop can be triggered in the scanner when an input ends with a symbol, e.g.
$ echo -n ':foo' >/tmp/symbol
$ hexdump -C /tmp/symbol
00000000 3a 66 6f 6f |:foo|
00000004
$ /node_modules/.bin/tree-sitter parse /tmp/symbol
^CI believe this caused by this loop:
tree-sitter-ruby/src/scanner.cc
Lines 357 to 359 in 7a1ecb7
When we reach the end of the buffer, ->lookahead is zero so is not an identifier character and advance(...) is a no-op so we never make any forward progress.
Given the following Ruby code:
class Example
def bar; end
private
def foo; end
endToday tree-sitter-ruby produces:
(program [0, 0] - [6, 0]
(class [0, 0] - [5, 3]
(constant [0, 6] - [0, 13])
(method [1, 2] - [1, 14]
(identifier [1, 6] - [1, 9]))
(identifier [3, 2] - [3, 9])
(method [4, 2] - [4, 14]
(identifier [4, 6] - [4, 9]))))@maxbrunsfeld what do you think about changing the parse tree to communicate private or protected members? It'd be great from a client perspective if the parse tree could reflect the visibility of a member e.g. private_method or protected_constant (with the default always indicating public visibility). One advantage is that clients wouldn't require state to track what visibility scope (nor have to make a check against each identifier) in the parse tree for protected or private, but I'm guessing this would require an additional piece of state on the external scanner and would further complicate the grammar. What do you think?
tree-sitter-ruby misparses this code:
a.() {}(program [0, 0] - [1, 0]
(method_call [0, 0] - [0, 7]
(call [0, 0] - [0, 4]
(identifier [0, 0] - [0, 1])
(argument_list_with_parens [0, 2] - [0, 4]))
(argument_list [0, 5] - [0, 7]
(hash [0, 5] - [0, 7]))))
I think this is related to #73, but interestingly the grammar parses do blocks and non-empty brace blocks correctly:
$ node_modules/.bin/tree-sitter parse <(echo 'a.() { 123 }')
(program [0, 0] - [1, 0]
(method_call [0, 0] - [0, 12]
(call [0, 0] - [0, 4]
(identifier [0, 0] - [0, 1])
(argument_list_with_parens [0, 2] - [0, 4]))
(block [0, 5] - [0, 12]
(integer [0, 7] - [0, 10]))))
$ node_modules/.bin/tree-sitter parse <(echo 'a.() do end')
(program [0, 0] - [1, 0]
(method_call [0, 0] - [0, 11]
(call [0, 0] - [0, 4]
(identifier [0, 0] - [0, 1])
(argument_list_with_parens [0, 2] - [0, 4]))
(do_block [0, 5] - [0, 11])))
They were in the old (non-tree-sitter) grammar, but they don't appear to be anymore:

Looks like this might also be a problem for other things like symbols.
Example:
Cß = 1❯ tree-sitter parse test.rb -d
new_parse {}
process { version: '0',
version_count: '1',
state: '1',
row: '0',
col: '0' }
lex_external { state: '2', row: '0', column: '0' }
lex_internal { state: '232', row: '0', column: '0' }
consume { character: '\'C\'' }
lexed_lookahead { sym: 'constant', size: '2' }
shift { state: '40' }
process { version: '0',
version_count: '1',
state: '40',
row: '0',
col: '2' }
lex_external { state: '9', row: '0', column: '2' }
lex_internal { state: '571', row: '0', column: '2' }
retry_in_error_mode {}
lex_external { state: '1', row: '0', column: '2' }
lex_internal { state: '0', row: '0', column: '2' }
skip_unrecognized_character {}
consume { character: '\'�\'' }
lex_external { state: '1', row: '0', column: '4' }
skip { character: '\' \'' }
lex_internal { state: '0', row: '0', column: '4' }
skip { character: '\' \'' }
consume { character: '\'=\'' }
lexed_lookahead { sym: 'ERROR', size: '2' }
handle_error {}
shift { state: '0' }
process { version: '0',
version_count: '1',
state: '0',
row: '0',
col: '4' }
lex_external { state: '1', row: '0', column: '4' }
skip { character: '\' \'' }
lex_internal { state: '0', row: '0', column: '4' }
skip { character: '\' \'' }
consume { character: '\'=\'' }
lexed_lookahead { sym: '=', size: '2' }
recover { state: '13442' }
process { version: '0',
version_count: '2',
state: '13442',
row: '0',
col: '8' }
lex_external { state: '75', row: '0', column: '8' }
skip { character: '\' \'' }
lex_internal { state: '1510', row: '0', column: '8' }
skip { character: '\' \'' }
consume { character: '\'1\'' }
lexed_lookahead { sym: 'integer', size: '2' }
shift { state: '13484' }
process { version: '1',
version_count: '2',
state: '0',
row: '0',
col: '8' }
lex_external { state: '1', row: '0', column: '8' }
skip { character: '\' \'' }
lex_internal { state: '0', row: '0', column: '8' }
skip { character: '\' \'' }
consume { character: '\'1\'' }
lexed_lookahead { sym: 'integer', size: '2' }
recover { state: '13484' }
process { version: '0',
version_count: '3',
state: '13484',
row: '0',
col: '12' }
lex_external { state: '69', row: '0', column: '12' }
consume { character: '\'\n\'' }
lexed_lookahead { sym: '_line_break', size: '2' }
reduce { sym: '_primary', child_count: '1' }
reduce { sym: '_arg', child_count: '1' }
reduce { sym: '_arg_or_splat_arg', child_count: '1' }
reduce { sym: 'optional_parameter', child_count: '3' }
repair_error {}
no_repair_found {}
reduce { sym: 'right_assignment_list', child_count: '1' }
reduce { sym: 'assignment', child_count: '3' }
repair_error {}
halt_other { version: '0' }
halt_other { version: '1' }
halt_other { version: '2' }
halt_other { version: '3' }
repair_found { sym: 'assignment', child_count: '3', cost: '101' }
reduce { sym: '_arg', child_count: '1' }
reduce { sym: '_statement', child_count: '1' }
reduce { sym: '_top_level_statement', child_count: '1' }
shift { state: '219' }
condense {}
process { version: '0',
version_count: '1',
state: '219',
row: '1',
col: '0' }
lex_external { state: '2', row: '1', column: '0' }
lex_internal { state: '703', row: '1', column: '0' }
lexed_lookahead { sym: 'END', size: '0' }
reduce { sym: '_terminator', child_count: '1' }
reduce { sym: '_statements', child_count: '2' }
reduce { sym: 'program', child_count: '1' }
accept {}
condense {}
done {}
test.rb 40 ms ERROR [0, 1] - [0, 2]
:$0Found by @tclem.
Hello,
I cannot load this Language through wasm.
import Parser from "web-tree-sitter"
await Parser.init()
const parser = new Parser()
const Lang = await Parser.Language.load("tree-sitter-ruby.wasm")
parser.setLanguage(Lang)Error:
{
"errorMessage": "e[Object.keys(...).find(...)] is not a function",
"errorType": "TypeError",
"stackTrace": [
"TypeError: e[Object.keys(...).find(...)] is not a function",
" at /home/xxx/code/xxx/node_modules/web-tree-sitter/tree-sitter.js:1:45617",
" at handler (/home/xxx/code/xxx/.webpack/index/webpack:home/xxx/code/xxx/index.ts:23:16)"
]
}
The code fails on const Lang = await Parser.Language.load("tree-sitter-ruby.wasm").
Testing with tree-sitter-javascript.wasm works.
Both wasm files have been generated using https://github.com/tree-sitter/tree-sitter/tree/master/lib/binding_web#generate-wasm-language-files
As the code is working with another Language, I guess it's not an issue related with web-tree-sitter but with the ruby Language.
Let me know If you need anything else to figure out the issue.
print DATA
__END__
hi there!The file in question comes from metasploit-framework: enum_ie.rb.
Minimized example:
def is_86
pid = session.sys.process.open.pid
return session.sys.process.each_process.find { |i| i["pid"] == pid} ["arch"] == "x86"
endIt appears to be failing on the { |i| i["pid"] == pid} portion.
$ tree-sitter parse loop-iter.rb
...
loop-iter.rb 0 ms (ERROR [2, 47] - [2, 69])
$ ruby -c loop-iter.rb
Syntax OK
This code fails to parse right now because the ?" gets tokenized as a character literal
a > b ?"a":"b"Possibly related: #40
The tree-sitter parser for Ruby fails on https://github.com/jimweirich/builder/blob/c80100f8205b2e918dbff605682b01ab0fabb866/lib/builder/xchar.rb#L173
I reduced the code to the following. The problem is that the parser expects a ; or linebreak after case n while the ruby interpreter seems to be fine if it is missing.
n = 1
case n when 1
puts "one" end
The following heredoc is wrongly parsed. It looks like the single quotes have no effect.
x = <<'NO_INTERPOLATION'
This should not be interpolated #{interpolation}
NO_INTERPOLATION
program [0, 0] - [4, 0])
assignment [0, 0] - [0, 24])
left: identifier [0, 0] - [0, 1])
right: heredoc_beginning [0, 4] - [0, 24])
heredoc_body [0, 24] - [2, 16])
interpolation [1, 32] - [1, 48])
identifier [1, 34] - [1, 47])
heredoc_end [2, 0] - [2, 16])
I think it should be
program [0, 0] - [4, 0])
assignment [0, 0] - [0, 24])
left: identifier [0, 0] - [0, 1])
right: heredoc_beginning [0, 4] - [0, 24])
heredoc_body [0, 24] - [2, 16])
heredoc_end [2, 0] - [2, 16])
Hey
I am sorry but i couldnt find an irc or something
I am trying to change the grammar output for personal needs a bit and i am wondering about some things:
is it possible to somehow generate a named node for optional even if it doesnt match? i tried choice between optional and nil_node where nil_node accepts empty string but this doesnt seem nice
overally is there a way to add a named "nil_node" in some places always? it should just be generated , equivalently to always matching an empty string, but i am not sure how to do it as it seems to break other stuff
Currently, because of the way the method rule is structured, these two methods' syntax trees are identical in structure:
def one
two
three
end
def one.two
three
end
/cc @tclem
The title is a bit vague because I'm not sure what Ruby construct is causing this issue. I suspect it may be the squiggly heredoc, but I'm not sure. The following is a minimized example of a valid Ruby file in the Homebrew repository:
def_node_matcher :example_or_group_or_include?, <<~PATTERN
{
#{block_pattern(
'{#Examples.all #ExampleGroups.all #Includes.all}'
)}
#{send_pattern('{#Examples.all #Includes.all}')}
}
PATTERN$ npx tree-sitter parse test.rb
(program [0, 0] - [8, 0]
(method_call [0, 0] - [0, 58]
method: (identifier [0, 0] - [0, 16])
arguments: (argument_list [0, 17] - [0, 58]
(symbol [0, 17] - [0, 46])
(heredoc_beginning [0, 48] - [0, 58])))
(ERROR [0, 58] - [3, 56]
(identifier [2, 6] - [2, 19])
(string [3, 6] - [3, 56]))
(heredoc_body [3, 56] - [7, 7]
(interpolation [5, 4] - [5, 52]
(method_call [5, 6] - [5, 51]
method: (identifier [5, 6] - [5, 18])
arguments: (argument_list [5, 18] - [5, 51]
(string [5, 19] - [5, 50]))))
(heredoc_end [7, 0] - [7, 7])))
test.rb 0 ms (ERROR [0, 58] - [3, 56])
$ ruby -c test.rb
Syntax OK
However, if we change the block_pattern portion slightly it successfully parses:
def_node_matcher :example_or_group_or_include?, <<~PATTERN
{
#{block_pattern('{#Examples.all #ExampleGroups.all #Includes.all}')}
#{send_pattern('{#Examples.all #Includes.all}')}
}
PATTERN$ npx tree-sitter parse test.rb
(program [0, 0] - [6, 0]
(method_call [0, 0] - [0, 58]
method: (identifier [0, 0] - [0, 16])
arguments: (argument_list [0, 17] - [0, 58]
(symbol [0, 17] - [0, 46])
(heredoc_beginning [0, 48] - [0, 58])))
(heredoc_body [0, 58] - [5, 7]
(interpolation [2, 4] - [2, 72]
(method_call [2, 6] - [2, 71]
method: (identifier [2, 6] - [2, 19])
arguments: (argument_list [2, 19] - [2, 71]
(string [2, 20] - [2, 70]))))
(interpolation [3, 4] - [3, 52]
(method_call [3, 6] - [3, 51]
method: (identifier [3, 6] - [3, 18])
arguments: (argument_list [3, 18] - [3, 51]
(string [3, 19] - [3, 50]))))
(heredoc_end [5, 0] - [5, 7])))
$ ruby -c test.rb
Syntax OK
The file in question comes from brew: regexp_match.rb.
The following is a reduced example:
def correct_operator(corrector, recv, arg, oper = nil)
op_range = correction_range(recv, arg)
replace_with_match_predicate_method(corrector, recv, arg, op_range)
corrector.insert_after(arg.loc.expression, ')') unless op_range.source.end_with?('(')
corrector.insert_before(recv.loc.expression, '!') if oper == :!~
endIt appears that the parse error is coming from :!~, which is the 'not pattern match' operator (!~).
$ tree-sitter parse not-pattern-match.rb
(ERROR [0, 0] - [8, 0]
...
not-pattern-match.rb 1 ms (ERROR [0, 0] - [8, 0])
$ ruby -c not-pattern-match.rb
Syntax OK
def bar
enshould result in an error, but instead parses:
(program [0, 0] - [2, 0]
(method [0, 0] - [2, 0]
(identifier [0, 4] - [0, 7])
(identifier [1, 0] - [1, 2])
(string [2, 0] - [2, 0])))
I appreciate that tree-sitter is faster & more efficient than the old grammar, but the change is a bit disappointing. Symbols, constants, numbers, and boolean values (true/false) are now all the same color with all of the built-in themes I've tried (Base16 Tomorrow Dark, Atom Dark, One Dark).
Examples w/ Base16 Tomorrow Dark. Before:

Tree-sitter:

Was this intentional or is it just a WiP?
My version of Node has
> process.platform
'linux'
> process.arch
'x64'
> process.versions.modules
'67'
> process.version
'v11.15.0'
can you recompile and release for 67 (and preemptively for 69)?
While investigating #146 , I discovered that the tree for a comparison of an indexed object appears incorrect.
Consider the following program:
x [0] == 1tree-sitter-ruby will emit the following CST:
(program [0, 0] - [1, 0]
(call [0, 0] - [0, 10]
method: (identifier [0, 0] - [0, 1])
arguments: (argument_list [0, 2] - [0, 10]
(binary [0, 2] - [0, 10]
left: (array [0, 2] - [0, 5]
(integer [0, 3] - [0, 4]))
right: (integer [0, 9] - [0, 10])))))
That is, this is interpreted as equivalent to:
x([0] == 1)whereas Ruby evaluates this as:
(x[0]) == 1This can be confirmed by running
x = [1, 2, 3]
z = x [0] == 1
puts zwhich prints true.
I believe the correct CST should be:
(program [0, 0] - [1, 0]
(binary [0, 0] - [0, 10]
left: (element_reference [0, 0] - [0, 5]
object: (identifier [0, 0] - [0, 1])
(integer [0, 3] - [0, 4]))
right: (integer [0, 9] - [0, 10])))
The file in question comes from metasploit-framework: rbmysql.rb.
The following is a minimal example:
if ret[0] == ?\xff
f, errno, marker, @sqlstate, message = ret.unpack("Cvaa5a*")
endThe parse error comes from ?\xff.
I'm not a Ruby expert, but this appears to be the ASCII character code for a hex character. See Numeric literals.
$ tree-sitter parse cond-hex.rb
...
cond-hex.rb 0 ms (ERROR [0, 13] - [0, 16])
$ ruby -c cond-hex.rb
Syntax OK
Parsing multiple \r characters seems to cause very slow parse times, e.g.
wgoKDQ0NDQ0NDQ0NDQ0NDQ0NDQ0NDQ0NDQ0NDWk=
00000000 c2 0a 0a 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d |................|
00000010 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d 0d 69 |............i|
0000001d
I don't fully understand the code, but I believe it is related to the fall-through logic in scan_parser. Should this be something like:
case '\r':
if (lexer->lookahead != '\n') return true;
skip(lexer);
case '\n':
A lone \r isn't strictly whitespace but the interpreter seems to handle it anyway:
$ printf "puts\r123" | ruby
-:1: warning: encountered \r in middle of line, treated as a mere space
123
test.rb:
Time.new(2002, 10, 31, 2, 2, 2.123456789r, "+02:00")$ npx tree-sitter parse test.rb
(program [0, 0] - [1, 0]
(method_call [0, 0] - [0, 52]
method: (call [0, 0] - [0, 8]
receiver: (constant [0, 0] - [0, 4])
method: (identifier [0, 5] - [0, 8]))
arguments: (argument_list [0, 8] - [0, 52]
(integer [0, 9] - [0, 13])
(integer [0, 15] - [0, 17])
(integer [0, 19] - [0, 21])
(integer [0, 23] - [0, 24])
(integer [0, 26] - [0, 27])
(float [0, 29] - [0, 40])
(ERROR [0, 40] - [0, 41])
(string [0, 43] - [0, 51]))))
test.rb 0 ms (ERROR [0, 40] - [0, 41])
This is the rational 'r' suffix for a literal: https://ruby-doc.org/core-2.5.0/Rational.html
Ruby 2.6 added the ability to do a rescue without a corresponding begin inside a block. That means code like
arr.each do |thing|
begin
try(thing)
rescue error
handle_it
end
endcan be rewritten a little shorter (omitting the begin, and fixing the indentation):
arr.each do |thing|
try(thing)
rescue error
handle_it
endExpected behavior:
All end tags are syntax highlighted
Actual behavior:
The method's end tag loses highlighting:
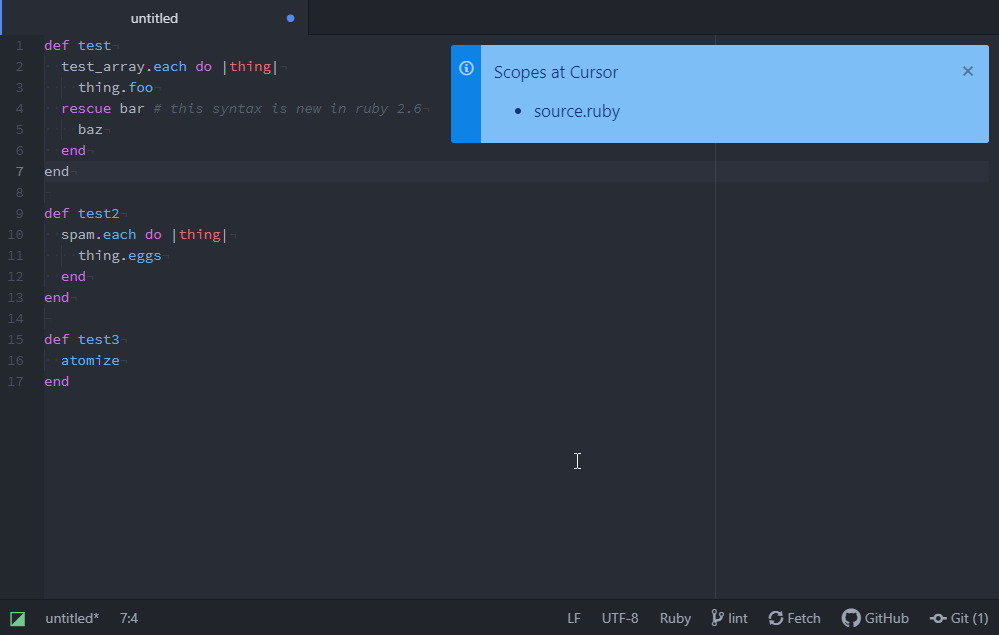
Reproduces how often:
100% of the time
atom --version
Atom : 1.40.0
Electron: 3.1.10
Chrome : 66.0.3359.181
Node : 10.2.0
apm --version
apm 2.4.2
npm 6.2.0
node 10.2.1 x64
atom 1.40.0
python 3.7.2
git 2.16.2.windows.1
visual studio
OS: Windows 10 Enterprise (1809)
I originally logged this as atom/language-ruby#274
❯ cat test.rb
if a
else
# comment
endProduces the tree:
❯ tree-sitter parse test.rb
(program [0, 0] - [4, 0]
(if [0, 0] - [3, 3]
(identifier [0, 3] - [0, 4])
(else [1, 0] - [2, 2])
(comment [2, 2] - [2, 11])))Instead I would expect the comment to be a child of else like so:
(program [0, 0] - [4, 0]
(if [0, 0] - [3, 3]
(identifier [0, 3] - [0, 4])
(else [1, 0] - [2, 2])
(comment [2, 2] - [2, 11])))Ruby’s %w/%W, and %i/%I syntaxes are array literals containing strings and symbols respectively. However, the parse tree won’t contain nodes with the appropriate names, even with the changes described in tree-sitter/tree-sitter#29.
I would like this source:
%w(hello world)to end up with this parse tree:
(program (expression.literal.array (expression.literal.string) (expression.literal.string)))
However, note that the elements of the array would not be parsed via the string production; they’d be parsed via the array and named string sort of by fiat.
@maxbrunsfeld: Is there any way to assign names like that? API like this might do it:
rules: {
array: choice(
seq('[', commaSep($.expression), ']'),
seq('%w(', sep({ string: /[^\s]+/ }, /\s+/), ')'),
…
),
…
}Motivated by #4.
The grammar accepts the following code:
x.(123)(456)And produces the following syntax tree:
(program [0, 0] - [1, 0]
(method_call [0, 0] - [0, 12]
(call [0, 0] - [0, 7]
(identifier [0, 0] - [0, 1])
(argument_list_with_parens [0, 2] - [0, 7]
(integer [0, 3] - [0, 6])))
(argument_list [0, 7] - [0, 12]
(integer [0, 8] - [0, 11]))))
This is because the call rule accepts dot-call syntax including argument list, but method_call unconditionally sequences call with another argument list:
call: $ => prec.left(PREC.BITWISE_AND + 1, seq(
$._primary,
choice('.', '&.'),
repeat($.heredoc_end),
choice($.identifier, $.operator, $.constant, $.argument_list_with_parens)
)),
method_call: $ => {
const receiver = choice($._variable, $.scope_resolution, $.call)
return choice(
seq(receiver, $.argument_list),
seq(receiver, prec(PREC.CURLY_BLOCK, seq($.argument_list, $.block))),
seq(receiver, prec(PREC.DO_BLOCK, seq($.argument_list, $.do_block))),
prec(PREC.CURLY_BLOCK, seq(receiver, $.block)),
prec(PREC.DO_BLOCK, seq(receiver, $.do_block))
)
},By comparison, Ruby rejects the example code:
$ ruby -c -e 'x.(123)(456)'
-e:1: syntax error, unexpected '(', expecting end-of-input
x.(123)(456)
^
#102 added support for prebuilding against ABI 64. If a new version could be cut with the binaries built against that ABI that'd be awesome!
Thanks!
@ivar-1For that ruby code, tree-sitter currently produces this incorrect tree:
(program [0, 0] - [1, 0]
(method_call [0, 0] - [0, 7]
(instance_variable [0, 0] - [0, 5])
(argument_list [0, 5] - [0, 7]
(unary [0, 5] - [0, 7]
(integer [0, 6] - [0, 7])))))
If you add in the spaces like so, you get the right tree.
@ivar - 1(program [0, 0] - [1, 0]
(binary [0, 0] - [0, 9]
(instance_variable [0, 0] - [0, 5])
(integer [0, 8] - [0, 9])))
puts <<HERE
hello #{<<HERE}
world
HERE
HERE
In the following parse tree the ranges of the heredoc bodies are not right
program [0, 0] - [6, 0])
method_call [0, 0] - [0, 11])
method: identifier [0, 0] - [0, 4])
arguments: argument_list [0, 5] - [0, 11])
heredoc_beginning [0, 5] - [0, 11])
heredoc_body [0, 11] - [3, 4])
interpolation [1, 8] - [1, 17])
heredoc_beginning [1, 10] - [1, 16])
heredoc_end [3, 0] - [3, 4])
heredoc_body [3, 4] - [4, 4])
heredoc_end [4, 0] - [4, 4])
foo rescue …The grammar does not distinguish between identifiers used as hash keys and symbols using the 1.9 hash syntax:
$ node_modules/.bin/tree-sitter parse <(echo '{ foo: bar }')
(program [0, 0] - [1, 0]
(hash [0, 0] - [0, 12]
(pair [0, 2] - [0, 10]
(identifier [0, 2] - [0, 5])
(identifier [0, 7] - [0, 10]))))
$ node_modules/.bin/tree-sitter parse <(echo '{ foo => bar }')
(program [0, 0] - [1, 0]
(hash [0, 0] - [0, 14]
(pair [0, 2] - [0, 12]
(identifier [0, 2] - [0, 5])
(identifier [0, 9] - [0, 12]))))
The first example should parse as (pair (symbol) (identifier))
For e.g. keyword args.
Complex number literals can be any number (integer, float or rational) followed by an i. The grammar currently only allows complex integers.
In addition complex and rational literals are a single token, things like 3 r or 4 i should be rejected.
See also https://ruby-doc.org/core-3.0.0/doc/syntax/literals_rdoc.html
First of all, thank you for this amazing project, which has made something I'm working on much easier to implement! In the process of using tree-sitter, I noticed that it produces an unexpected result for the following syntax:
format.json { render :key => value }This produced the following syntax tree:
(program (method_call (call (identifier) (identifier)) (argument_list (hash (pair (method_call (identifier) (argument_list (symbol))) (identifier))))))
However, the expected result was:
(program (method_call (call (identifier) (identifier)) (block (method_call (identifier) (argument_list (pair (symbol) (identifier)))))))
Basically, it looks like tree-sitter is treating the contents of the curlies as a method call that's receiving a hash whose key is itself a method call, instead of a method call with an implicit hash as its only argument. For reference, the expected output is produced from any of the following forms:
format.json { render(:key => value) }
format.json { render {:key => value} }
format.json { render key: value }Given that, it seems like the unexpected behavior is only triggered when using hash rockets. I tried parsing the code that produced the unexpected tree using whitequark's Ruby parser, and it correctly produced the block form.
Thanks again for this project, and sorry for being the bearer of bug news. If you need any more information, just let me know!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.