portable, zero-overhead C++ types for explicitly data-parallel programming
Development here is going to move on to std::simd for C++26. For the TS
implementation reach for
GCC/libstdc++.
std::experimental::simd is shipping with GCC since version 11.
This package implements ISO/IEC TS 19570:2018 Section 9 "Data-Parallel Types". The implementation derived from https://github.com/VcDevel/Vc.
By default, the install.sh script places the std::experimental::simd
headers into the directory where the standard library of your C++ compiler
(identified via $CXX) resides.
It is only tested and supported with GCC trunk, even though it may work with older GCC versions.
- x86_64 is the main development platform and thoroughly tested. This includes support from SSE-only up to AVX512 on Xeon Phi or Xeon CPUs.
- aarch64, arm, and ppc64le was tested and verified to work. No significant performance evaluation was done.
- In any case, a fallback to correct execution via builtin arithmetic types is available for all targets.
$ ./install.shUse --help to learn about the available options.
Let's start from the code for calculating a 3D scalar product using builtin floats:
using Vec3D = std::array<float, 3>;
float scalar_product(Vec3D a, Vec3D b) {
return a[0] * b[0] + a[1] * b[1] + a[2] * b[2];
}Using simd, we can easily vectorize the code using the native_simd<float>
type (Compiler Explorer):
using std::experimental::native_simd;
using Vec3D = std::array<native_simd<float>, 3>;
native_simd<float> scalar_product(Vec3D a, Vec3D b) {
return a[0] * b[0] + a[1] * b[1] + a[2] * b[2];
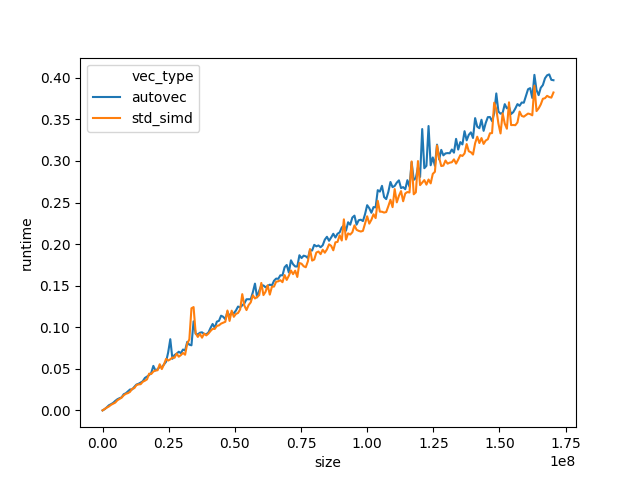
}The above will scale to 1, 4, 8, 16, etc. scalar products calculated in parallel, depending on the target hardware's capabilities.
For comparison, the same vectorization using Intel SSE intrinsics is more verbose, uses prefix notation (i.e. function calls), and neither scales to AVX or AVX512, nor is it portable to different SIMD ISAs:
using Vec3D = std::array<__m128, 3>;
__m128 scalar_product(Vec3D a, Vec3D b) {
return _mm_add_ps(_mm_add_ps(_mm_mul_ps(a[0], b[0]), _mm_mul_ps(a[1], b[1])),
_mm_mul_ps(a[2], b[2]));
}none. It's header-only.
However, to build the unit tests you will need:
- cmake >= 3.0
- GCC >= 9.1
To execute all AVX512 unit tests, you will need the Intel SDE.
$ make testThis will create a build directory, run cmake, compile the tests, and execute the tests.
https://en.cppreference.com/w/cpp/experimental/simd
- J. Hoberock, "Working Draft, C++ Extensions for Parallelism Version 2", 2019
- M. Kretz, "Extending C++ for Explicit Data-Parallel Programming via SIMD Vector Types", Goethe University Frankfurt, Dissertation, 2015.
- P. Esterie, M. Gaunard, J. Falcou and J. Lapresté, "Exploiting Multimedia Extensions in C++: A Portable Approach," in Computing in Science & Engineering, vol. 14, no. 5, pp. 72-77, Sept.-Oct. 2012.
- M. Kretz and V. Lindenstruth, "Vc: A C++ library for explicit vectorization", Software: Practice and Experience, 2011.
- J. Falcou and J. Serot, "E.V.E., An Object Oriented SIMD Library.", Scalable Computing: Practice and Experience, vol. 6, no. 4, pp. 72-77, 2005.
The simd headers, tests, and benchmarks are released under the terms of the
3-clause BSD license.
Note that the code in libstdc++ is distributed under GPL3 with runtime library exception.