vikrant7 / mobile-vod-bottleneck-lstm Goto Github PK
View Code? Open in Web Editor NEWImplementation of Mobile Video Object Detection with Temporally-Aware Feature Maps using PyTorch
Implementation of Mobile Video Object Detection with Temporally-Aware Feature Maps using PyTorch













































































































The model cannot detect anything using the pretrained model of lstm1. Do you have a demo video?
Please help me , Where i need to modify the code for testing with custom data ?
Thanking you.
First thank you for your share code.
Could show same documets to guide us how to use the release code?
Thank you for your contribution .
Traceback (most recent call last):
File "evaluate.py", line 227, in
true_case_stat[class_index],
KeyError: 1
python train_mvod_basenet.py --datasets E:\ImageNetVID\ILSVRC2015 --batch_size 30 --num_epochs 10 --width_mult 1
2019-10-15 07:37:33,897 - root - INFO - Use Cuda.
2019-10-15 07:37:33,897 - root - INFO - Namespace(base_net_lr=None, batch_size=30, checkpoint_folder='models/', datasets='E:\ImageNetVID\ILSVRC2015', debug_steps=100, gamma=0.1, lr=0.003, milestones='80,100', momentum=0.9, num_epochs=10, num_workers=4, pretrained=None, resume=None, scheduler='multi-step', ssd_lr=None, t_max=120, use_cuda=True, validation_epochs=5, weight_decay=0.0005, width_mult=1.0)
2019-10-15 07:37:34,100 - root - INFO - Prepare training datasets.
2019-10-15 07:37:34,507 - root - INFO - using default Imagenet VID classes.
2019-10-15 07:37:34,507 - root - INFO - Stored labels into file models/vid-model-labels.txt.
2019-10-15 07:37:34,507 - root - INFO - Train dataset size: 76859
2019-10-15 07:37:34,507 - root - INFO - Prepare Validation datasets.
2019-10-15 07:37:34,569 - root - INFO - using default Imagenet VID classes.
2019-10-15 07:37:34,569 - root - INFO - <datasets.vid_dataset.ImagenetDataset object at 0x0000021307FEEE80>
2019-10-15 07:37:34,569 - root - INFO - validation dataset size: 11080
2019-10-15 07:37:34,569 - root - INFO - Build network.
2019-10-15 07:37:34,678 - root - INFO - Initializing weights of base net
2019-10-15 07:37:34,694 - root - INFO - Initializing weights of SSD
2019-10-15 07:37:39,750 - root - INFO - Learning rate: 0.003, Base net learning rate: 0.003, Extra Layers learning rate: 0.003.
2019-10-15 07:37:39,766 - root - INFO - Uses MultiStepLR scheduler.
2019-10-15 07:37:39,766 - root - INFO - Start training from epoch 0.
Traceback (most recent call last):
File "train_mvod_basenet.py", line 282, in
device=DEVICE, debug_steps=args.debug_steps, epoch=epoch)
File "train_mvod_basenet.py", line 115, in train
for i, data in enumerate(loader):
File "D:\Tool\Anaconda\Anaconda3-5.2.0\lib\site-packages\torch\utils\data\dataloader.py", line 819, in iter
return _DataLoaderIter(self)
File "D:\Tool\Anaconda\Anaconda3-5.2.0\lib\site-packages\torch\utils\data\dataloader.py", line 560, in init
w.start()
File "D:\Tool\Anaconda\Anaconda3-5.2.0\lib\multiprocessing\process.py", line 105, in start
self._popen = self._Popen(self)
File "D:\Tool\Anaconda\Anaconda3-5.2.0\lib\multiprocessing\context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "D:\Tool\Anaconda\Anaconda3-5.2.0\lib\multiprocessing\context.py", line 322, in _Popen
return Popen(process_obj)
File "D:\Tool\Anaconda\Anaconda3-5.2.0\lib\multiprocessing\popen_spawn_win32.py", line 65, in init
reduction.dump(process_obj, to_child)
File "D:\Tool\Anaconda\Anaconda3-5.2.0\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
AttributeError: Can't pickle local object 'TrainAugmentation.init..'
all dependency prepared
Opencv
Python3.6
Pytorch1.0
by the way, i work under windows
could you help tell what is the problem?
Hi,I notice that in the paper the forward part is this

But in your code, this part is

Why you plus c*self.wci and self.wcf in the code putting the ct-1 into the functions?
And you involve the cc into the calculation of co which is also different from the paper. What is that meaning?

Thank you very much!
Hi,
How can I fix the following runtime error of inplace operation? Do the leaf tensors h and c have inplace operations? Thanks in advance.
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation.
Hello,I tested the model on ILSVRC2015 using the models/lstm5/WM-1.0-test.pth you provided, but each time the scores and boxes are the same value, the final result is very poor, can you provide the corresponding help? thank you very much.
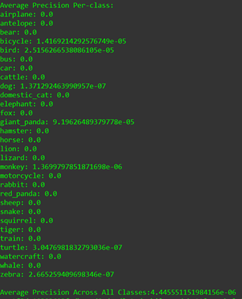
Hi @vikrant7 , thanks for this great implementation, I have learned a lot from it.
After each iteration of a sequence, you detach the hidden state and cell state of the lstm cell from the graph to cut backpropagation, do you think it's also necessary to re-initilize them, since hidden state and cell state should be zero for the start of a new sequence?
I use the following script to do training:
python3 train_mvod_basenet.py --datasets /home/sma/2TB/VID2015/ILSVRC/Data/VID --batch_size 60 --num_epochs 30 --width_mult 1
But got errors below:
2019-12-07 00:37:48,954 - root - INFO - Namespace(base_net_lr=None, batch_size=60, cache_path=None, checkpoint_folder='models/', datasets='/home/sma/2TB/VID2015/ILSVRC/Data/VID', debug_steps=100, gamma=0.1, lr=0.003, milestones='80,100', momentum=0.9, num_epochs=30, num_workers=4, pretrained=None, resume=None, scheduler='multi-step', ssd_lr=None, t_max=120, use_cuda=True, validation_epochs=5, weight_decay=0.0005, width_mult=1.0)
2019-12-07 00:37:48,954 - root - INFO - Prepare training datasets.
Traceback (most recent call last):
File "train_mvod_basenet.py", line 206, in
target_transform=target_transform)
File "/home/sma/2TB/RCN/mobile-vod-bottleneck-lstm/datasets/vid_dataset_new.py", line 190, in init
self.root = pathlib.Path(root)
File "/home/sma/anaconda3/envs/directron2/lib/python3.6/pathlib.py", line 1001, in new
self = cls._from_parts(args, init=False)
File "/home/sma/anaconda3/envs/directron2/lib/python3.6/pathlib.py", line 656, in _from_parts
drv, root, parts = self._parse_args(args)
File "/home/sma/anaconda3/envs/directron2/lib/python3.6/pathlib.py", line 640, in _parse_args
a = os.fspath(a)
TypeError: expected str, bytes or os.PathLike object, not NoneType
Any idea why this happens?
Thanks,
2020-02-19 06:11:13,289 - root - INFO - Use Cuda.
2020-02-19 06:11:13,289 - root - INFO - Namespace(base_net_lr=None, batch_size=10, cache_path=None, checkpoint_folder='models/', datasets='./datasets/ILSVRC2015/', debug_steps=100, freeze_net=True, gamma=0.1, lr=0.0003, milestones='80,100', momentum=0.9, num_epochs=1, num_workers=1, pretrained='./models/basenet/WM-1.0-Epoch-29-Loss-166.12886941432953.pth', resume=None, scheduler='multi-step', sequence_length=5, ssd_lr=None, t_max=120, use_cuda=True, validation_epochs=5, weight_decay=0.0005, width_mult=1.0)
2020-02-19 06:11:13,290 - root - INFO - Prepare training datasets.
class
2020-02-19 06:11:13,292 - root - INFO - using default Imagenet VID classes.
2020-02-19 06:11:13,350 - root - INFO - gt roidb loaded from datasets/ILSVRC2015/train_VID_seq_gt_db.pkl
2020-02-19 06:11:13,352 - root - INFO - Stored labels into file models/vid-model-labels.txt.
2020-02-19 06:11:13,352 - root - INFO - Train dataset size: 330
2020-02-19 06:11:13,352 - root - INFO - Prepare Validation datasets.
class
2020-02-19 06:11:13,353 - root - INFO - using default Imagenet VID classes.
2020-02-19 06:11:13,354 - root - INFO - gt roidb loaded from datasets/ILSVRC2015/val_VID_seq_gt_db.pkl
2020-02-19 06:11:13,354 - root - INFO - <datasets.vid_dataset_new.VIDDataset object at 0x7f4bee441fd0>
2020-02-19 06:11:13,354 - root - INFO - validation dataset size: 0
2020-02-19 06:11:13,354 - root - INFO - Build network.
2020-02-19 06:11:13,371 - root - INFO - Initializing weights of base net
2020-02-19 06:11:13,390 - root - INFO - Initializing weights of lstm
2020-02-19 06:11:17,248 - root - INFO - Initializing weights of SSD
2020-02-19 06:11:17,260 - root - INFO - Loading weights from pretrained netwok
2020-02-19 06:11:17,316 - root - INFO - Freeze net.
2020-02-19 06:11:17,327 - root - INFO - Learning rate: 0.0003, Base net learning rate: 0.0003, Extra Layers learning rate: 0.0003.
2020-02-19 06:11:17,327 - root - INFO - Start training from epoch 0.
/usr/local/lib/python3.6/dist-packages/torch/nn/_reduction.py:43: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
warnings.warn(warning.format(ret))
Traceback (most recent call last):
File "train_mvod_lstm1.py", line 295, in
val_loss, val_regression_loss, val_classification_loss = val(val_loader, net, criterion, DEVICE)
File "train_mvod_lstm1.py", line 187, in val
return running_loss / num, running_regression_loss / num, running_classification_loss / num
ZeroDivisionError: float division by zero
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [256, 256, 1, 1]] is at version 5; expected version 4 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
I don't know how to modify it, I would like to ask you,thank you!
hi @vikrant7 , thanks for sharing your implementation!
It's more of a question than a issue, in mvod_bottleneck_lstm1.py line 303, you init BottleneckLSTM with height=10 and width=10:
self.bottleneck_lstm1 = BottleneckLSTM(input_channels=1024alpha, hidden_channels=256alpha, height=10, width=10, batch_size=batch_size)
Why is that not the height and width of the input image? Correct me if I'm wrong since I don't know conv-lstm well.
Thanks in advance!
2020-02-12 11:40:16,745 - root - INFO - Use Cuda.
2020-02-12 11:40:16,745 - root - INFO - Namespace(base_net_lr=None, batch_size=10, cache_path=None, checkpoint_folder='models/', datasets='./datasets/ILSVRC2015/', debug_steps=100, freeze_net=True, gamma=0.1, lr=0.0003, milestones='80,100', momentum=0.9, num_epochs=30, num_workers=4, pretrained='./models/lstm1/WM-1.0-Epoch-29.pth', resume=None, scheduler='multi-step', sequence_length=10, ssd_lr=None, t_max=120, use_cuda=True, validation_epochs=5, weight_decay=0.0005, width_mult=1.0)
2020-02-12 11:40:16,746 - root - INFO - Prepare training datasets.
class
2020-02-12 11:40:16,748 - root - INFO - using default Imagenet VID classes.
2020-02-12 11:40:16,805 - root - INFO - gt roidb loaded from datasets/ILSVRC2015/train_VID_seq_gt_db.pkl
2020-02-12 11:40:16,807 - root - INFO - Stored labels into file models/vid-model-labels.txt.
2020-02-12 11:40:16,807 - root - INFO - Train dataset size: 330
2020-02-12 11:40:16,807 - root - INFO - Prepare Validation datasets.
class
2020-02-12 11:40:16,808 - root - INFO - using default Imagenet VID classes.
2020-02-12 11:40:16,809 - root - INFO - gt roidb loaded from datasets/ILSVRC2015/val_VID_seq_gt_db.pkl
2020-02-12 11:40:16,809 - root - INFO - <datasets.vid_dataset_new.VIDDataset object at 0x7ff3717af0f0>
2020-02-12 11:40:16,809 - root - INFO - validation dataset size: 0
2020-02-12 11:40:16,809 - root - INFO - Build network.
2020-02-12 11:40:16,825 - root - INFO - Initializing weights of base net
2020-02-12 11:40:16,843 - root - INFO - Initializing weights of lstm
2020-02-12 11:40:19,735 - root - INFO - Initializing weights of lstm
2020-02-12 11:40:19,740 - root - INFO - Initializing weights of ssd
2020-02-12 11:40:19,750 - root - INFO - Loading weights from pretrained netwok
Traceback (most recent call last):
File "train_mvod_lstm2.py", line 242, in
initialize_model(net)
File "train_mvod_lstm2.py", line 202, in initialize_model
net.load_state_dict(model_dict)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 830, in load_state_dict
self.class.name, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for MobileVOD:
size mismatch for pred_decoder.fmaps_2.0.weight: copying a param with shape torch.Size([64, 256, 1, 1]) from checkpoint, the shape in current model is torch.Size([32, 64, 1, 1]).
size mismatch for pred_decoder.fmaps_2.0.bias: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([32]).
size mismatch for pred_decoder.fmaps_2.2.0.weight: copying a param with shape torch.Size([64, 1, 3, 3]) from checkpoint, the shape in current model is torch.Size([32, 1, 3, 3]).
size mismatch for pred_decoder.fmaps_2.2.0.bias: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([32]).
size mismatch for pred_decoder.fmaps_2.2.2.weight: copying a param with shape torch.Size([128, 64, 1, 1]) from checkpoint, the shape in current model is torch.Size([64, 32, 1, 1]).
size mismatch for pred_decoder.fmaps_2.2.2.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for pred_decoder.fmaps_3.0.weight: copying a param with shape torch.Size([64, 128, 1, 1]) from checkpoint, the shape in current model is torch.Size([32, 64, 1, 1]).
size mismatch for pred_decoder.fmaps_3.0.bias: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([32]).
size mismatch for pred_decoder.fmaps_3.2.0.weight: copying a param with shape torch.Size([64, 1, 3, 3]) from checkpoint, the shape in current model is torch.Size([32, 1, 3, 3]).
size mismatch for pred_decoder.fmaps_3.2.0.bias: copying a param with shape torch.Size([64]) from checkpoint, the shape in current model is torch.Size([32]).
size mismatch for pred_decoder.fmaps_3.2.2.weight: copying a param with shape torch.Size([128, 64, 1, 1]) from checkpoint, the shape in current model is torch.Size([64, 32, 1, 1]).
size mismatch for pred_decoder.fmaps_3.2.2.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for pred_decoder.fmaps_4.0.weight: copying a param with shape torch.Size([32, 128, 1, 1]) from checkpoint, the shape in current model is torch.Size([32, 64, 1, 1]).
size mismatch for pred_decoder.regression_headers.2.0.weight: copying a param with shape torch.Size([256, 1, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 1, 3, 3]).
size mismatch for pred_decoder.regression_headers.2.0.bias: copying a param with shape torch.Size([256]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for pred_decoder.regression_headers.2.2.weight: copying a param with shape torch.Size([24, 256, 1, 1]) from checkpoint, the shape in current model is torch.Size([24, 64, 1, 1]).
size mismatch for pred_decoder.regression_headers.3.0.weight: copying a param with shape torch.Size([128, 1, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 1, 3, 3]).
size mismatch for pred_decoder.regression_headers.3.0.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for pred_decoder.regression_headers.3.2.weight: copying a param with shape torch.Size([24, 128, 1, 1]) from checkpoint, the shape in current model is torch.Size([24, 64, 1, 1]).
size mismatch for pred_decoder.regression_headers.4.0.weight: copying a param with shape torch.Size([128, 1, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 1, 3, 3]).
size mismatch for pred_decoder.regression_headers.4.0.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for pred_decoder.regression_headers.4.2.weight: copying a param with shape torch.Size([24, 128, 1, 1]) from checkpoint, the shape in current model is torch.Size([24, 64, 1, 1]).
size mismatch for pred_decoder.classification_headers.2.0.weight: copying a param with shape torch.Size([256, 1, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 1, 3, 3]).
size mismatch for pred_decoder.classification_headers.2.0.bias: copying a param with shape torch.Size([256]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for pred_decoder.classification_headers.2.2.weight: copying a param with shape torch.Size([186, 256, 1, 1]) from checkpoint, the shape in current model is torch.Size([186, 64, 1, 1]).
size mismatch for pred_decoder.classification_headers.3.0.weight: copying a param with shape torch.Size([128, 1, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 1, 3, 3]).
size mismatch for pred_decoder.classification_headers.3.0.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for pred_decoder.classification_headers.3.2.weight: copying a param with shape torch.Size([186, 128, 1, 1]) from checkpoint, the shape in current model is torch.Size([186, 64, 1, 1]).
size mismatch for pred_decoder.classification_headers.4.0.weight: copying a param with shape torch.Size([128, 1, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 1, 3, 3]).
size mismatch for pred_decoder.classification_headers.4.0.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for pred_decoder.classification_headers.4.2.weight: copying a param with shape torch.Size([186, 128, 1, 1]) from checkpoint, the shape in current model is torch.Size([186, 64, 1, 1]).
hi vikrant
how did you achieved MAP=42 after two epoch?
i trained mobilenet V2 + ssdlite, but almost after 20 epoch i got MAP=30.
i started with lr=0.002 and schedulate it with Cosine. also, i used pre-trained mobilenet v2 classification (trained on imagenet) as pre-trained basenet and i loaded it's weights on my model.
2020-01-16 16:31:09,554 - root - INFO - Use Cuda.
2020-01-16 16:31:09,554 - root - INFO - Namespace(base_net_lr=None, batch_size=60, cache_path=None, checkpoint_folder='models/', datasets='./datasets/ILSVRC2015/', debug_steps=100, freeze_net=False, gamma=0.1, lr=0.0003, milestones='80,100', momentum=0.9, num_epochs=30, num_workers=1, pretrained=None, resume=None, scheduler='multi-step', sequence_length=10, ssd_lr=None, t_max=120, use_cuda=True, validation_epochs=5, weight_decay=0.0005, width_mult=1.0)
2020-01-16 16:31:09,576 - root - INFO - Prepare training datasets.
class
2020-01-16 16:31:09,851 - root - INFO - using default Imagenet VID classes.
2020-01-16 16:31:10,226 - root - INFO - gt roidb loaded from datasets/ILSVRC2015/train_VID_seq_gt_db.pkl
2020-01-16 16:31:10,458 - root - INFO - Stored labels into file models/vid-model-labels.txt.
2020-01-16 16:31:10,458 - root - INFO - Train dataset size: 60
2020-01-16 16:31:10,458 - root - INFO - Build network.
2020-01-16 16:31:10,491 - root - INFO - Initializing weights of base net
2020-01-16 16:31:10,510 - root - INFO - Initializing weights of lstm
2020-01-16 16:31:19,438 - root - INFO - Initializing weights of SSD
2020-01-16 16:31:19,460 - root - INFO - Learning rate: 0.0003, Base net learning rate: 0.0003, Extra Layers learning rate: 0.0003.
2020-01-16 16:31:19,461 - root - INFO - Start training from epoch 0.
/usr/local/lib/python3.6/dist-packages/torch/nn/_reduction.py:43: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
warnings.warn(warning.format(ret))
Traceback (most recent call last):
File "train_mvod_lstm1.py", line 292, in
device=DEVICE, debug_steps=args.debug_steps, epoch=epoch, sequence_length=args.sequence_length)
File "train_mvod_lstm1.py", line 132, in train
loss.backward(retain_graph=True)
File "/usr/local/lib/python3.6/dist-packages/torch/tensor.py", line 166, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/usr/local/lib/python3.6/dist-packages/torch/autograd/init.py", line 99, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: CUDA out of memory. Tried to allocate 188.00 MiB (GPU 0; 15.90 GiB total capacity; 14.55 GiB already allocated; 138.88 MiB free; 179.10 MiB cached)
python train_mvod_basenet.py --datasets /home/feimiao/Documents/tuyaxin/mobile-vod-bottleneck-lstm-master/ILSVRC/ --batch_size 60 --num_epochs 30 --width_mult 1
2019-12-10 16:59:33,761 - root - INFO - Namespace(base_net_lr=None, batch_size=60, cache_path=None, checkpoint_folder='models/', datasets='/home/feimiao/Documents/tuyaxin/mobile-vod-bottleneck-lstm-master/ILSVRC/', debug_steps=100, gamma=0.1, lr=0.003, milestones='80,100', momentum=0.9, num_epochs=30, num_workers=4, pretrained=None, resume=None, scheduler='multi-step', ssd_lr=None, t_max=120, use_cuda=True, validation_epochs=5, weight_decay=0.0005, width_mult=1.0)
2019-12-10 16:59:33,763 - root - INFO - Prepare training datasets.
Traceback (most recent call last):
File "train_mvod_basenet.py", line 207, in
target_transform=target_transform)
File "/home/feimiao/Documents/tuyaxin/mobile-vod-bottleneck-lstm-master/datasets/vid_dataset_new.py", line 190, in init
self.root = pathlib.Path(root)
File "/home/feimiao/anaconda3/envs/MVOD/lib/python3.7/pathlib.py", line 1003, in new
self = cls._from_parts(args, init=False)
File "/home/feimiao/anaconda3/envs/MVOD/lib/python3.7/pathlib.py", line 658, in _from_parts
drv, root, parts = self._parse_args(args)
File "/home/feimiao/anaconda3/envs/MVOD/lib/python3.7/pathlib.py", line 642, in _parse_args
a = os.fspath(a)
TypeError: expected str, bytes or os.PathLike object, not NoneType
NoneType error occurred when I trained.In my opinion, the problem lies in the 'train_VID_gt_db.pkl' file. How can I get the 'train_VID_gt_db.pkl' file?
Thank and hope for your reply.
Hello, please allow me to ask how to use your code and trained model to annotate your own video data files and get the visualization results as shown in your paper? Thank you
when i run the code:
python train_mvod_basenet.py --datasets {path to ILSVRC2015 root dir} --batch_size 60 --num_epochs 30 --width_mult 1
there is an error: train_mvod_basenet.py: error: unrecognized arguments: to ILSVRC2015 root dir}
how can i solve it?
Hi,
I'm training the network using train_mvod_lstm1.py with a sequence of images(video) as an input(without any basenet or pretrained model) from the train_VID_seqs_list.txt.
I got the models as well as checkpoints after completion of training.
To predict on the test data set i'm using evaluate.py where it is reading individual frame and predicting for it.But i'm expecting that prediction should happen in sequence level that is read a set of frames as sequence and give a output.
I have a question that will the evaluate.py in the existing repo. work for testing the data in sequence level or is it to predict individual frames only?
Thank you
Hi,
I am currently training basenet but I am observing that training is taking huge amount of time, not normally found in this type of datasets and models. I can achieve 0.4mAP after 3 days for training on a NVIDIA GeForce RTC 2080.
Have you been able to make a training which achieve paper's mAP? Where do you think is the issue?
Thank in advance.
python train_mvod_basenet.py --datasets /home/amit/ILSVRC2015_VID_initial/ILSVRC201 --batch_size 60 --num_epochs 30 --width_mult 1
2020-01-03 10:40:12,053 - root - INFO - Namespace(base_net_lr=None, batch_size=60, cache_path=None, checkpoint_folder='models/', datasets='/home/amit/ILSVRC2015_VID_initial/ILSVRC201', debug_steps=100, gamma=0.1, lr=0.003, milestones='80,100', momentum=0.9, num_epochs=30, num_workers=4, pretrained=None, resume=None, scheduler='multi-step', ssd_lr=None, t_max=120, use_cuda=True, validation_epochs=5, weight_decay=0.0005, width_mult=1.0)
2020-01-03 10:40:12,204 - root - INFO - Prepare training datasets.
Traceback (most recent call last):
File "train_mvod_basenet.py", line 207, in
target_transform=target_transform)
File "/home/amit/Downloads/mobile-vod-bottleneck-lstm-master/datasets/vid_dataset_new.py", line 190, in init
self.root = pathlib.Path(root)
File "/home/amit/anaconda3/lib/python3.7/pathlib.py", line 1010, in new
self = cls._from_parts(args, init=False)
File "/home/amit/anaconda3/lib/python3.7/pathlib.py", line 665, in _from_parts
drv, root, parts = self._parse_args(args)
File "/home/amit/anaconda3/lib/python3.7/pathlib.py", line 649, in _parse_args
a = os.fspath(a)
TypeError: expected str, bytes or os.PathLike object, not NoneType
please help
I try to resume from checkpoint data, as blow.
python train_mvod_basenet.py --datasets ./ILSVRC --cache_path ./ --batch_size 60 --num_epochs 30 --width_mult 1 --resume models/basenet/WM-1.0-Epoch-15-Loss-111.27649793882628.pth
But, I can not restart training from epoch 15
2020-03-26 14:53:06,380 - root - INFO - Prepare training datasets.
2020-03-26 14:53:06,610 - root - INFO - using default Imagenet VID classes.
2020-03-26 14:53:22,396 - root - INFO - gt roidb loaded from ./train_VID_gt_db.pkl
2020-03-26 14:53:22,396 - root - INFO - Stored labels into file models/vid-model-labels.txt.
2020-03-26 14:53:22,396 - root - INFO - Train dataset size: 1086132
2020-03-26 14:53:22,396 - root - INFO - Prepare Validation datasets.
2020-03-26 14:53:22,398 - root - INFO - using default Imagenet VID classes.
2020-03-26 14:53:22,527 - root - INFO - gt roidb loaded from ./val_VID_gt_db.pkl
2020-03-26 14:53:22,527 - root - INFO - <datasets.vid_dataset_new.ImagenetDataset object at 0x7fe89f1a8be0>
2020-03-26 14:53:22,527 - root - INFO - validation dataset size: 11080
2020-03-26 14:53:22,527 - root - INFO - Build network.
2020-03-26 14:53:22,540 - root - INFO - Initializing weights of base net
2020-03-26 14:53:22,563 - root - INFO - Initializing weights of SSD
Updating weights from resume model
2020-03-26 14:53:23,626 - root - INFO - Learning rate: 0.003, Base net learning rate: 0.003, Extra Layers learning rate: 0.003.
2020-03-26 14:53:23,626 - root - INFO - Start training from epoch 0.
Please teach me how to resume from checkpoint data!
Thank you!
Thank you for your efforts.
And I note that datasets/vid_dataset.py is used in evaluate.py, datasets/vid_dataset_new.py is used in datasets/vid_dataset_new.py. So what's the difference between datasets/vid_dataset.py and datasets/vid_dataset_new.py ?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.