This package is developed for automated whole-genome de-novo TE annotation and benchmarking the annotation performance of TE libraries.
The EDTA package was designed to filter out false discoveries in raw TE candidates and generate a high-quality non-redundant TE library for whole-genome TE annotations. Selection of initial search programs were based on benckmarkings on the annotation performance using a manually curated TE library in the rice genome.
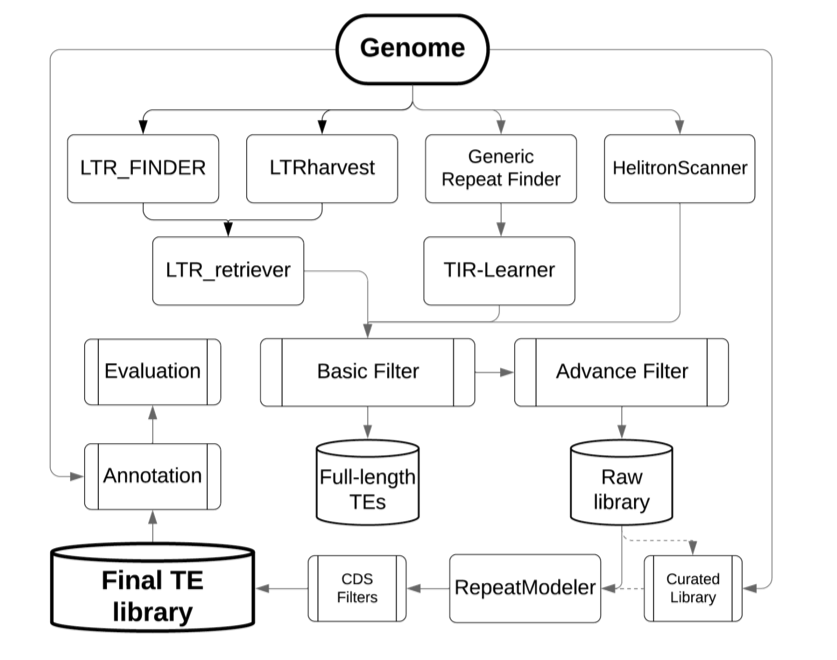
For benchmarking of a testing TE library, I have provided the curated TE annotation (v6.9.5) for the rice genome (TIGR7/MSU7 version). You may use the lib-test.pl script to compare the annotation performance of your method/library to the methods we have tested (usage shown below).
conda create -n EDTA
conda activate EDTA
python2 -m pip install --user numpy==1.14.3 biopython==1.74 pp
conda config --env --add channels anaconda --add channels conda-forge --add channels biocore --add channels bioconda --add channels cyclus
conda install -n EDTA -y cd-hit repeatmodeler muscle mdust repeatmasker=4.0.9_p2 blast-legacy java-jdk perl perl-text-soundex multiprocess regex tensorflow=1.14.0 keras=2.2.4 scikit-learn=0.19.0 biopython pandas glob2 python=3.6 trf
git clone https://github.com/oushujun/EDTA
./EDTA/EDTA.pl
More information: https://hub.docker.com/r/kapeel/edta
docker pull kapeel/edta
Activate the EDTA program:
conda activate EDTA
You got a genome and you want to get a high-quality TE library:
perl EDTA.pl [options]
-genome [File] The genome FASTA
-species [Rice|Maize|others] Specify the species for identification of TIR candidates. Default: others
-step [all|filter|final|anno] Specify which steps you want to run EDTA.
all: run the entire pipeline (default)
filter: start from raw TEs to the end.
final: start from filtered TEs to finalizing the run.
anno: perform whole-genome annotation/analysis after TE library construction.
-overwrite [0|1] If previous results are found, decide to overwrite (1, rerun) or not (0, default).
-cds [File] Provide a FASTA file containing the coding sequence (no introns, UTRs, nor TEs) of this genome or its close relative.
-curatedlib [file] Provided a curated library to keep consistant naming and classification for known TEs.
All TEs in this file will be trusted 100%, so please ONLY provide MANUALLY CURATED ones here.
This option is not mandatory. It's totally OK if no file is provided (default).
-sensitive [0|1] Use RepeatModeler to identify remaining TEs (1) or not (0, default).
This step is very slow and MAY help to recover some TEs.
-anno [0|1] Perform (1) or not perform (0, default) whole-genome TE annotation after TE library construction.
-evaluate [0|1] Evaluate (1) classification consistency of the TE annotation. (-anno 1 required). Default: 0.
This step is slow and does not affect the annotation result.
-exclude [File] Exclude bed format regions from TE annotation. Default: undef. (-anno 1 required).
-threads|-t [int] Number of theads to run this script (default: 4)
-help|-h Display this help info
Identify intact elements of a paticular TE type:
1.Get raw libraries from a genome (specify -type ltr|tir|helitron in different runs)
perl EDTA_raw.pl [options]
-genome [File] The genome FASTA
-species [Rice|Maize|others] Specify the species for identification of TIR candidates. Default: others
-type [ltr|tir|helitron|all] Specify which type of raw TE candidates you want to get. Default: all
-overwrite [0|1] If previous results are found, decide to overwrite (1, rerun) or not (0, default).
-threads|-t [int] Number of theads to run this script
-help|-h Display this help info
2.Finish the rest of the EDTA analysis (specify -overwrite 0 and it will automatically pick up existing results in the work folder)
perl EDTA.pl -overwrite 0 [options]
If you developed a new TE method/got a TE library and want to compare it's annotation performance to the methods we have tested, you can:
1.annotate the rice genome with your test library:
RepeatMasker -pa 36 -q -no_is -norna -nolow -div 40 -lib custom.TE.lib.fasta -cutoff 225 rice_genome.fasta
2.Test the annotation performance of a particular TE category.
perl lib-test.pl -genome genome.fasta -std genome.stdlib.RM.out -tst genome.testlib.RM.out -cat [options]
-genome [file] FASTA format genome sequence
-std [file] RepeatMasker .out file of the standard library
-tst [file] RepeatMasker .out file of the test library
-cat [string] Testing TE category. Use one of LTR|nonLTR|LINE|SINE|TIR|MITE|Helitron|Total|Classified
-N [0|1] Include Ns in total length of the genome. Defaule: 0 (not include Ns).
-unknown [0|1] Include unknown annotations to the testing category. This should be used when
the test library has no classification and you assume they all belong to the
target category specified by -cat. Default: 0 (not include unknowns)
eg.
perl lib-test.pl -genome rice_genome.fasta -std ./EDTA/database/Rice_MSU7.fasta.std6.9.5.out -tst rice_genome.fasta.test.out -cat LTR
Please cite our paper if you find EDTA is useful:
Ou S., Su W., Liao Y., Chougule K., Agda J. R. A., Hellinga A. J., Lugo C. S. B., Elliott T. A., Ware D., Peterson T., Jiang N.✉, Hirsch C. N.✉ and Hufford M. B.✉ (2019). Benchmarking Transposable Element Annotation Methods for Creation of a Streamlined, Comprehensive Pipeline. Genome Biol. 20(1): 275.
Please also cite the software packages that were used in EDTA, listed in the EDTA/bin directory.
You may download the rice genome here.
If you have any issues with installation and usage, please check if similar issues have been reported in Issues or open a new issue. If you are (looking for) happy users, please read or write successful cases here.