ardatan / graphql-tools Goto Github PK
View Code? Open in Web Editor NEW:wrench: Utility library for GraphQL to build, stitch and mock GraphQL schemas in the SDL-first approach
Home Page: https://www.graphql-tools.com
License: MIT License
:wrench: Utility library for GraphQL to build, stitch and mock GraphQL schemas in the SDL-first approach
Home Page: https://www.graphql-tools.com
License: MIT License
Here's a draft spec for GraphQL schema decorators: https://github.com/apollostack/graphql-tools/blob/master/graphql-decorator-spec.md
It's only a draft so far. I'd love to get feedback on the following points:
Feedback on points not listed above is of course also appreciated!
The main motivation for decorators is to make Apollo highly extensible, so anyone can easily write their decorators, which the whole community can use.
Is there a documentation for this. I'm unable to figure out where to pass this arguments. I have tried passing it to apolloServer.
graphQLServer.use('/graphql', apolloServer({
graphiql: true,
pretty: true,
schema: Schema,
resolvers: Resolvers,
resolverValidationOptions: { requireResolversForNonScalar: false }
//mocks: Mocks,
}));
As discussed on Slack I created a repo with list of unexpected results here. Seems that only non-nullable arrays are not mocked correctly.
Interfaces and unions are currently not mocked, I believe. The straightforward solution is to randomly pick an implementing type each time a field returns a Union or Interface, and then mock that type.
Sorry in advance for the long text. This is essentially a braindump because I'm still figuring things out.
Having thought about it a little more, I think what I've been calling loaders until now is actually three layers that can be separated (I'm not sure if the names I found are really the best):
Connectors
Each type has its own connector, which means they're schema specific and not that reusable between projects. They're also somewhat optional because that code could be written in the resolve function, but I would recommend using the connector abstraction anyway for modularity.
Connectors are exposed to the resolve functions via the context. Resolve functions call the connectors, which will have an API that has methods like the following:
Connectors will also have to support writing, not just fetching. So you should be able to update an object through the connector. Create, Update and Delete are the basic cases. Arbitrary mutations are still confusing me a bit. If they implement complex logic maybe that should be in the connector as well and not in the resolve function? I’ll have to think more about it.
In general, the methods on the connectors will most likely closely reflect the backend operations available, but they may also abstract over the backend operations by combining multiple of them into a single operation. For the discourse API we need to get a CSRF token sometimes, but that’s not an operation that a connector would expose, but only use internally.
I think it’s important that we aim for simplicity over efficiency at first. What I mean by that is that if you wanted to delete a whole list of objects, you would have to call delete for each of the objects. If folks need to optimize further, it should be easy to do if they can swap out the db loader at any time and replace it with their own.
Hm… is that too much boilerplate? Too much abstraction? It should be easy to get started with, and it shouldn’t scare people off. Ideally it would be the right thing for a small project, as well as for a huge project.
Loaders
The loaders are the place where batching and caching/memoizing happens. They are specific to the backend, which means they are reusable between projects.
If the backend is standardized - like SQL for example - then we can write just one generic loader for it. If the backend is not standardized - eg. most RESTful APIs - then we will most likely have to write a loader for each API flavor, of which there may be many. We may even have to write a loader for each endpoint the API exposes if the endpoints don't share a common style.
SQL, Mongo & most other DBs : the loader is essentially a query builder (like knex). It's not an ORM.
RESTful APIs: the loader is custom to that API, maybe even to the particular endpoint. This is necessary because there's usually no standard way of batching requests, and because the . If the API doesn't provide any way to batch requests or cache individual nodes then an inefficient standard loader could be used which essentially caches the whole response, but only for that exact request.
DataLoader should be helpful for this. Initially we could just build our loaders with DataLoader, but I think we'll want to have more control and more efficiency later so we'll probably move beyond it.
Let’s say we have requests to load a bunch of objects by attribute or ID in SQL. Without you needing to write code, the loader should be able to batch these requests. SELECTs from the same table and selecting on the same set of fields should happen in one query (concatenated OR, then match back to original request when data is returned - for efficiency, you might attach that condition to the columns of the query so you know which one it matched). It should be possible to turn batching on and off and to bypass it for individual elements. SQL loader can probably extend DataLoader. SQL loader v1 should be pretty generic, if possible it won't make use of any Postgres, MySQL, MSSQL or Oracle specific stuff. It should produce queries, which are then passed to a DB adapter (transport) that deals with sending requests and getting responses.
For REST, the story is a bit different. There we cannot really do any batching unless the backend supports it. I think the right way to go there is to put a bit of pressure on the REST backends to support this kind of batched fetching. It’s only required as an optimization though, so people can get started without it. If we wait long enough, these classical REST endpoints will all but disappear, I believe.
Transport
The transport (not a great name, a bit of a collision) is what sends the actual data over the wire as far as we're concerned. It just takes the request given by the loader and passes back the response when it arrives. Examples for transports: node http, DDP, node MySQL adapter, node Postgres adapter etc.
Okay, that was quite a lot of text. I feel like I need to work on some specific examples to refine the ideas, because right now I don't know if this really fits in practice, but I wanted to write this here so we can start a discussion.
Let me know what you think @jbaxleyiii @stubailo .
PS: ORMs fit into the picture above, but not perfectly. They fulfill the role of Connector and Loader, but they don't do any batching for us afaik. Maybe they don't even do caching. To let people use these, we'll have to figure out how to make them support batching and caching in the way we want. It may be easy, but I haven't looked into that yet.
Referenced from apollographql/apollo#29 (comment)
I have an issue that below query
query Test($id_0:ID!) {
node(id:$id_0) {
...F0
},
}
fragment F0 on Viewer {
items(names:["part"]) {
name
},
id
}
variables
{"id_0": "4a2cb025-ad18-4646-942e-503ee4b80ee6"}
gives this response about 9 out of 10 times
{
"data": {
"node": {}
}
}
and, the correct response
{
"data": {
"node": {
"items": [
{
"name": "part"
}
],
"id": "b61633aa-07ad-4b2d-b9ad-9aca77bc82ef"
}
}
}
otherwise.
I tried to reproduce it in your tests, but I wasn't quite sure about setting up same schema. Looking at the code, do you see any reason for this behavior.
thanks.
bsr.
We want to have a minimal example of how loaders would work. What I still have to do for this is:
It would be nice if there was a way to run some code at the end of every request, for example to release resources back to a pool.
What do you think about making graphql a peer dependency to be in line with graphql-relay, express-graphql and graphiql?
This will make it easier to upgrade graphql without having to wait for graphql-tools to update its dependencies.
Right now due to the way in which we simulate a root resolve function (wrapping the query and mutation resolvers), when the simulated root resolve function returns null or undefined, the query resolve function still runs. This differs from the behavior of normal resolve functions.
A fix is started on the fix-root-resolve-undefined branch, but it messes with a bunch of other things, such as catch undefined and print errors, so it needs some work to get the tests to pass.
This repo should just be tools for graphql-js, but right now there's also the apolloServer function, which bundles a bunch of them together. It would make more sense to split that off into its own repository.
Hi,
I can't load the attachConnectorsToContext tool as described here: http://docs.apollostack.com/apollo-server/connectors.html. It seems it isn't included in the src/index.js
By the way: Are the connectors from the tutorial the same as the connectors from the docs here conceptually?
The first is to connect to my dbs, the second to have a cache for the current query. I see they fit together but it's confusing as the names are almost the same but for slightly different purposes. Is it on purpose?
Thx!
During the upgrade from 0.1.0, this hit us pretty hard. Any reason why it wouldn't be true by default?
https://github.com/apollostack/graphql-tools/blob/master/src/schemaGenerator.js#L73
According to http://docs.apollostack.com/graphql-tools/guide.html data is resolved in the following order:
In this scenario, step 2 appears to be happening first, before the resolve function for the user field on the type RootQuery, due to the occurrence of the console.log 's happening in the following code. Thus, the resolver functions of the User type are not receiving the resolved User, but rather a mocked version.
When commenting out the addMockFunctionsToSchema block below, the resolver functions execute and resolve as expected according to the spec; however, no mock data can be used, of course, for other types not listed in this example.
Running on a Meteor (v1.4.0.1) server using the following packages:
// schema
type User {
_id: ID
first_name: String
last_name: String
}
type RootQuery {
user(_id: ID): User
}
// mocks
User: () => ({
first_name: "First name",
last_name: "Last name"
})
// resolvers
RootQuery: {
async user(_, { _id }) {
/*
The User I'm getting from the db here is as expected
*/
const User = Meteor.users.findOne({ _id });
console.log(User);
return User;
}
},
User: {
first_name(User) {
/*
I should be expecting the User returned from the RootQuery
to be User here, correct? I'm actually getting a mocked User here instead
*/
console.log(User); // outputs to log before the log in the RootQuery
return User.profile.first_name;
},
last_name(User) {
/*
Same scenario as above
*/
console.log(User);
return User.profile.last_name;
}
}
// schema setup
const ExecutableSchema = makeExecutableSchema({
typeDefs: Schema,
resolvers: Resolvers,
allowUndefinedInResolve: true,
resolverValidationOptions: {
requireResolversForArgs: false,
requireResolversForNonScalar: false
}
});
addMockFunctionsToSchema({
schema: ExecutableSchema,
mocks: Mocks,
preserveResolvers: true
});Add support for the HAPI web framework while continuing support for Express. The intent here is to offer support for both frameworks in a consistent manor such that the API works well with each framework and detects which binding is being used.
Every function that this package exports should have a short documentation for the alpha milestone. There should be a guide that walks you through setting up a GraphQL server with graphql-tools.
Should be fixed some time. Until then, just call the tools functions yourself separately.
schema {
query: RootQuery
}
type RootQuery {
organization(id: Int, name: String): Organization
organizations(limit: Int, skip: Int): [Organization]
project(id: Int, name: String): Project
projects(limit: Int, skip: Int): [Project]
}
...
type Project(myParameter:String) { // <-------- Doesn't work
id: Int!
name: String!
description: String
organization: Organization
tasks: [Task]
}
Is there a way to add the functionality shown in the example above? I've tried the above approach, but it gives me a syntax error Expected {, found (
I cannot create a enum schema with forward slash ("/").
i.e. the following does not work:
enum Test {
ABC
Dog
Dog/Cat
}
Support for custom scalar types with validators would be great.
From what I understand, you cannot create custom scalar types with validators in the schema string, the only way is via the GraphQLScalarType and co as done in the link above so the way I see it is buildSchemaFromTypeDefinitions would accept an array of GraphQL schema strings, GraphQLSchemas and GraphQLTypes...
It would make sense to rewrite the tests in this way:
(PS: I probably won't do this any time soon, but PRs very much appreciated)
It's not clear how to define type/args descriptions using type definitions - or if it is even possible.
For instance, using vanilla graphql-js:
export const User = new GraphQLObjectType({
name: 'User',
description: 'A user with an account.'
fields: () => ({
username: {
type: new GraphQLNonNull(GraphQLString),
description: 'A unique name for the user'
},
})
});I expected this to add descriptions, but it doesn't:
export const schema = [`
# A user with an account.
type User {
# A unique name for the user.
username: String!
}
`];mockServer ignores the resolve function for implementation of union or interface types. For example this mockMap:
const mockMap = {
Int: () => 12345,
Bird: () => ({ returnInt: () => 54321 }),
Bee: () => ({ returnInt: () => 54321 }),
};on this schema:
type Bird {
returnInt: Int
}
type Bee {
returnInt: Int
}
union BirdsAndBees = Bird | Bee
type RootQuery {
returnBirdsAndBees: [BirdsAndBees]
}
schema {
query: RootQuery
}
with the following query:
{
returnBirdsAndBees {
... on Bird {
returnInt
returnString
}
... on Bee {
returnInt
returnEnum
}
}
}returns 12345 instead of 54321
This is because loaders get attached for every query in the root resolve function, and we don't know whether the context is an object until we run a query.
We can fix this if we control the server as well, because then we can ensure that the context is an object, and we could throw an internal server error if the context provided is not an object. That's a good argument for using all our tools in combination.
IDs are currently generated with uuid.v4() by default, which cannot be given a seed value. The workaround is to override the default ID generator with your own function, which takes a seed.
Instead of creating mock data at random for every request, we could create a certain number of mock objects at startup (or lazily) and then return those. References between types could be stored as __id.
This kind of mocking will require you to write something like functions if the field has any arguments, but it may be worth it depending on the requirements.
I'd like to leave few comments and possible improvements on graphql-tools API.
Everything boils down to: improve composability and extensibility.
The main painpoint seems to be makeExecutableSchema. Currently it has 6 parameters, and soon it'll have 20. I think Apollo-Server could follow UNIX philosophy and instead of exposing single function responsible for multiple things, let it expose basic blocks for building schemas (aka commands), and way to connect them (aka pipes). makeExecutableSchema encourages the opposite.
So the first proposal is: Please make graphql-tools what they sound to be, and deprecate omnipotent makeExecutableSchema, instead documenting building blocks like buildFromTypeDefinitions or addResolveFunctions, and provide a standard way to compose them.
How to make these functions better composable? I think you could take route http://ramdajs.com/ or lodash/fp or redux took: instead of exposing functions operating directly on schema, let expose functions that return schema/type decorators.
This means changing current "interface" of graphql-tools functions (GraphQLSchema, Options) => GraphQLSchema to decorator-style Options => GraphQLSchema => GraphQLSchema, and making type GraphQLDecorator: GraphQLSchema => GraphQLSchema a base building block.
const baseDecorator = combineDecorators(
addTypeDefinitions(definitions),
addErrorLogging(logger)
)
const developmentDecorator = combineDecorators(
baseDecorator,
addMockResolvers(mocks),
assertResolveFunctionsPresent(resolverValidationOptions)
)
const productionDecorator = combineDecorators(
baseDecorator,
addResolveFunctions(resolvers)
)
const baseSchema = new GraphQLSchema();
const developmentSchema = applyDecorator(developmentDecorator, baseSchema);
const productionSchema = applyDecorator(productionDecorator, baseSchema);Here are all the types used in above example:
interface GraphQLDecorator {
<T>(type: T): T;
}
interface GraphQLSchemaDecorator extends GraphQLDecorator<GraphQLSchema> {
(schema: GraphQLSchema): GraphQLSchema;
}
// Decorator constructors
function addTypeDefinitions(definitions: AddTypeDefinitionsOptions): GraphQLSchemaDecorator;
function addErrorLogging(logger: AddErrorLoggingOptions): GraphQLSchemaDecorator;
function addMockResolvers(mocks: AddMocksResolverOptions): GraphQLSchemaDecorator;
function assertResolveFunctions(options?: AssertResolveFunctionsOptions): GraphQLSchemaDecorator;
// Composing function
function <T>combineDecorators(...decorators: GraphQLDecorator<T>[]): GraphQLDecorator<T>
// Applying function
function <T>applyDecorator(decorator: GraphQLDecorator<T>, type: T): T
// Resulting types
function baseDecorator: GraphQLSchemaDecorator
function productionDecorator: GraphQLSchemaDecorator
function baseSchema: GraphQLSchema
function developmentSchema: GraphQLSchema
function productionSchema: GraphQLSchemaWhile decorator constructors as well as composing function could be allowed to mutate GraphQLSchema for performance, but the applyDecorator can be used copy input type first, and only then apply provided decorator, it someone doesn't want to mutate original type / schema.
I hope you'll appreciate how regular graphql-tools API could be :)
The changes would be exhaustive, so maybe it would be better to deprecate this part of graphql-tools and instead move these functions to graphql-decorators package.
src/tracing.js was deleted from this package, but the prepublish script doesn't seem to guarantee that dist is empty, so it actually still exists in the published 0.6.0 even though the reference to it in index.js is gone.
Because of some recent changes to the parser in graphql-js I'm using the master branch on github for that, but the npm version isn't up to date. Npm installing from github doesn't work because of the npmignore file in that repo, so for the time being the 'vanilla-parser' branch requires cloning graphql-js into a folder that's side-by-side with apollo-server. I'm hoping there will be a new version of graphql on npm soon, which would make this problem go away. If anyone has another good solution, please make a pull-request. The main criteria is that running npm install is sufficient for getting all the dependencies of apollo-server after cloning the git repo.
Edit: it's also possible to make a pull-request to graphql-js, but I don't know what the right changes would be there. Any npm experts out there?
Right now you can define sclars, interfaces and unions just fine, but there is no easy way to attach the functions they need to them. Off the top of my head (probably incomplete):
Hi, I'm actively working with apollo and loving the experience. I just want to contribute with an opinion on a possible improvement of schema handling. What I feel that is a drawback of the current approach is the monolithic definion of Apollo schema, which does not provide extensibility through packages. It is quite difficult to produce modules or import packages that add on top of current functionality (e.g. authentication packages, system modules and more).
What would be great is to have the possibility to define functionality per domain element, where each domain element would export the list of:
schema
resolvers
queries
queryResolvers
mutations
mutationResolvers
With a current approach it is possible to define only schema and resolvers and import it into Apollo, queries and mutations got left behind. I got this working in my apollo-mantra project but it's a rather silly solution which heavily depends on my custom functionality and makes no sense to share it. Would you consider implementing something like this in core?
It would be nice to be able to import schema definitions with a .graphql extension, but it appears that require.extensions has been deprecated and there are some good reasons not to use it.
If we don't use require.extensions, the .graphql files would have to be transpiled, which requires a bit more setup, but would be more maintainable in the future. The transpilation setup could be mitigated by having a boilerplate and really good documentation. I'm also under the impression that most people are now using Babel by default, so it might not actually be such a big hassle to require a transpilation step.
@stubailo What do you think?
Right now Enum types do not have a default mock resolver. The workaround is to define your own mock resolver.
Hello
I am trying out Apollostack and so far it's been great! I have a problem though :)
This question might be better asked on sequelize forums, but maybe there's some apollo feature I am not aware of ...
I have a sequelize model with parent->children relation on the same table, and I need to access parent data from inside the child's resolve functions or from inside sequelize's instance methods.
This is my sequelize model Location
module.exports = function(sequelize, DataTypes) {
return sequelize.define('Location', {
parent_id: {
type: DataTypes.INTEGER(11),
allowNull: true,
},
name: {
type: DataTypes.STRING,
allowNull: false,
},
slug: {
type: DataTypes.STRING,
allowNull: false,
}
},{
tableName: 'location',
freezeTableName: true,
instanceMethods: {
getUrl: function() {
// here I need to check if this instance is a child
// and return a different url for child
return '';
}
},
classMethods: {
associate: function(m) {
m.Location.belongsTo(m.Location, {
foreignKey: 'parent_id',
as: 'Parent'
});
m.Location.hasMany(m.Location, {
foreignKey: 'parent_id',
as: 'Locations'
});
}
}
});
};
And this are my resolve functions
const resolveFunctions = {
RootQuery: {
location(root, { slug }, context){
return Location.find({ where: { slug }, include:[{ model: Location, as: 'Locations' }] });
}
},
Location: {
parent(location){
return location.getParent();
},
locations(location){
return location.getLocations();
},
url(location){
// or here ...
// check if this location is child
// and return a different url
return location.getUrl();
}
}
}
What would be the best way to do this?
This is the solution I have come up with ... I manually inject parent data into child.
const resolveFunctions = {
RootQuery: {
// ...
},
Location: {
locations(location){
if (!location.Locations) {
return [];
}
// I can manually "inject" parent into each location
// this way I can access this.parent from within getUrl() inside instanceMethods
return location.Locations.map(l => {
l.parent = location.dataValues;
return l;
});
}
}
}
When the mocks option is passed to apolloServer function the resolvers are ignored. This is a problem for union types which require that a resolveType function is specified.
A test case can be found in this issue. But it looks like an easy fix after being diagnosed by @helfer, so I'll submit a pull request.
The Adrenaline library offers a way to verify that a query is valid against a particular schema, you can read more detailed explanations here.
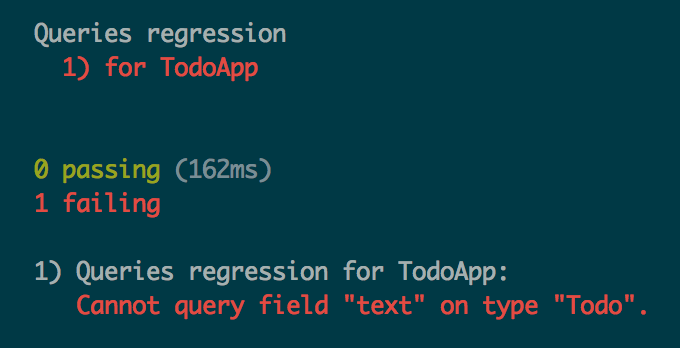
This can be useful to implement a test that would import all queries on the client and verify that there are still valid after a change in the server schema. I would be great to have something similar in the Apollo ecosystem.
Set up a page for documentation similar to the Meteor guide.
@stubailo Can you help me set this up? We could set up the one for apollo-client at the same time.
@helfer do you want me to go through and setup typescript like we did with apollo-client?
graphql uses a defaultResolveFn on all fields that don't provide one (scalar and non-scalar)
This is nice in the case that your resolved data for a parent type is already nested in the same way (via ORM, NoSQL, etc)
Type Definition:
type Account {
id: ID!
address: Address
firstName: String!
lastName: String
}
type Address {
street: String
city: String
county: String
state: String
postalCode: String
country: String
longitude: Float
latitude: Float
status: String
}
Data resolved by a parent type:
{
id: 'xxxx-xxxx-xxxx-xxxx',
address: {
street: '1234 Avenue',
city: 'Anywhere',
state: 'NY',
}
}
I shouldn't have to define a resolve method for data that matches my GraphQL schema.
Does removing this restriction break graphql-tools in any way?
The README currently says that the loaders get attached to the context automatically, but that's not yet the case. For the time being, they have to be imported and referenced directly in the resolvers.
Right now the line that throws an error if resolverValidationOptions is not an object is not covered.
Shorthand and schema definition:
Documentation, Examples + Guide:
A clear story for loading, batching, caching and auth
Tracing:
Note: Struck todos are no longer relevant to graphql-tools because they should be implemented in either apollo-server or tracer-agent.
Using different versions of graphql-js for generating the schema and executing queries doesn't work, because graphql-js uses instanceof to check if a schema is a graphql schema.
When installing from github, it seems that npm installs multiple copies of the apollo-server package, even when they are the same version. This leads to the issue above showing up all the time. Creating an experimental npm package should do the trick, but we'd have to do it for apollo-server and our fork of graphql-js (and express-graphql, if we want to use that as well). Hopefully a new npm version of graphql-js will solve this problem soon, because it's quite a hassle.
generateSchema is deprecated and shouldn't be used any more.
The function signature for makeExecutableSchema provided in the documentation is incorrect. Is there a certain git tag that stays true to the documentation or is the npm package in constant flux?
Should the documentation be updated together with changes that would affect it?
Further work based on PR #45
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.