dewenzeng / positional_cl Goto Github PK
View Code? Open in Web Editor NEWcode for paper Positional Contrastive Learning for Volumetric Medical Image Segmentation
code for paper Positional Contrastive Learning for Volumetric Medical Image Segmentation





















































It puzzles me how this finetuning works since I can only get ~0.67 on M=6 on HVSMR Dataset using ACDC pretrained model.
My settings are:
--batch_size 4 --epochs 100 --lr 1e-4 --min_lr 5e-6 --initial_filter_size 48 --classes 4 --dataset hvsmr --patch_size 352 352
Could you please provide me your settings for that?
pkgs:
batchgenerators 0.23
report bugs:
notice:
model = torch.nn.DataParallel(model, device_ids=args.multiple_device_id) in train_contrast.py reported error, which is due to parser.add_argument("--multiple_device_id", type=tuple, default=(0,1)) in myconfig.py
but in fact, when it comes to multiple GPUs, maybe we should name the specific GPUs we request, like
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3"
in train_contrast.py before the main function.
a very large gap between the reported results and mines, did I miss any important tricks?
The details of my experiments are presented as follows,
1, fix two bugs:
2, prepare acdc dataset via generate_acdc.py
3, prepare running scripts:
(1) from scratch:
python train_supervised.py --device cuda:0 --batch_size 10 --epochs 200 --data_dir ./dir_for_labeled_data --lr 5e-4 --min_lr 5e-6 --dataset acdc --patch_size 352 352 --experiment_name supervised_acdc_random_sample_6_ --initial_filter_size 48 --classes 4 --enable_few_data --sampling_k 6;
(2) contrastive learning:
python train_contrast.py --device cuda:0 --batch_size 32 --epochs 300 --data_dir ./dir_for_unlabeled_data --lr 0.01 --do_contrast --dataset acdc --patch_size 352 352 --experiment_name contrast_acdc_pcl_temp01_thresh035_ --slice_threshold 0.35 --temp 0.1 --initial_filter_size 48 --classes 512 --contrastive_method pcl;
python train_contrast.py --device cuda:0 --batch_size 32 --epochs 300 --data_dir ./dir_for_unlabeled_data --lr 0.01 --do_contrast --dataset acdc --patch_size 352 352 --experiment_name contrast_acdc_gcl_temp01_thresh035_ --slice_threshold 0.35 --temp 0.1 --initial_filter_size 48 --classes 512 --contrastive_method gcl;
python train_contrast.py --device cuda:0 --batch_size 32 --epochs 300 --data_dir ./dir_for_unlabeled_data --lr 0.01 --do_contrast --dataset acdc --patch_size 352 352 --experiment_name contrast_acdc_simclr_temp01_thresh035_ --slice_threshold 0.35 --temp 0.1 --initial_filter_size 48 --classes 512 --contrastive_method simclr;
(3) finetuning:
python train_supervised.py --device cuda:0 --batch_size 10 --epochs 100 --data_dir ./dir_for_labeled_data --lr 5e-5 --min_lr 5e-6 --dataset acdc --patch_size 352 352 --experiment_name supervised_acdc_simclr_sample_6_ --initial_filter_size 48 --classes 4 --enable_few_data --sampling_k 6 --restart --pretrained_model_path ./results/contrast_acdc_simclr_temp01_thresh035_2021-12-05_09-43-38/model/latest.pth;
python train_supervised.py --device cuda:1 --batch_size 10 --epochs 100 --data_dir ./dir_for_labeled_data --lr 5e-5 --min_lr 5e-6 --dataset acdc --patch_size 352 352 --experiment_name supervised_acdc_gcl_sample_6_ --initial_filter_size 48 --classes 4 --enable_few_data --sampling_k 6 --restart --pretrained_model_path ./results/contrast_acdc_gcl_temp01_thresh035_2021-12-04_03-46-35/model/latest.pth;
python train_supervised.py --device cuda:1 --batch_size 10 --epochs 100 --data_dir ./dir_for_labeled_data --lr 5e-5 --min_lr 5e-6 --dataset acdc --patch_size 352 352 --experiment_name supervised_acdc_pcl_sample_6_ --initial_filter_size 48 --classes 4 --enable_few_data --sampling_k 6 --restart --pretrained_model_path ./results/contrast_acdc_pcl_temp01_thresh035_2021-12-02_21-48-13/model/latest.pth;
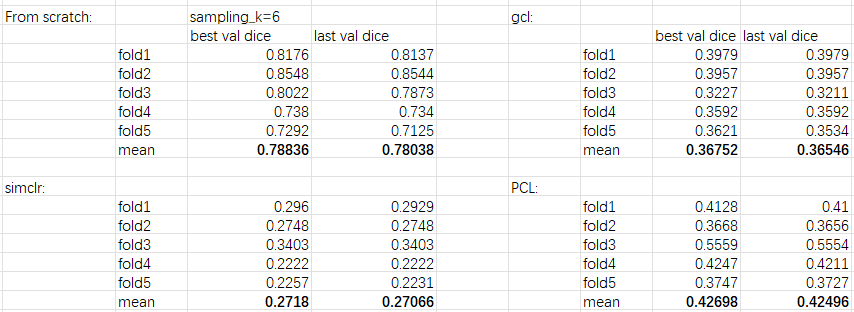
4, experimental results(ubuntu16.04, pytorch1.9, NVIDIA 2080Ti * 2, Dice metric, take sample_k=6 as an example):
Hi, I'm trying to run train_supervised.py using acdc dataset. The patchsize used in the pre-training stage is (352,352), as showed in the run_script.sh, the patchsize used in the fine-tuning stage is (512,512) (for chd dataset). I'm wondering what patchsize is selected for acdc dataset, thank you!
Hi, I'm trying to train the contrastive encoder from scratch on the ACDC data set, however, unlike your result shown on #3, my loss is stuck at 5.5597 from epoch 0 to epoch 30 until I cancelled it due to long time running. I'm wondering if I missed any tricks?
My results:



I run the code with:
python3 train_contrast.py --device cuda:0 --batch_size 25 --epochs 300 --data_dir "./dataset/02_08_2022/acdc/unlabeled/" --lr 0.1 --do_contrast --dataset acdc --patch_size 352 352 \
--experiment_name contrast_acdc_pcl_temp01_thresh035 --slice_threshold 0.35 --temp 0.1 --initial_filter_size 48 --classes 512 --contrastive_method pcl
Here I set the batch_size to 25 to avoid the memory crush.
I would like to congratulate the authors for this outstanding paper!
I am wondering if your team can share the code of another MICCAI21 paper (Federated Contrastive Learning for Volumetric Medical Image Segmentation), both papers will help us a lot for Contrastive Learning in the medical domain.
thanks.
Dear Zeng
When training the PCL model with the CHD dataset, using the parameters you provided, the GPU utilization is zero most of the time, and fully occupied for a period, making the training speed very slow. I would like to inquire about your training configuration and training time, and whether you have encountered this problem.
thanks!
Hi, i'm trying to run the code train_supervised.py, there is something wrong with the package metrics. There is no class named SegmentationMetrics when import this package. I would like to ask how this metrics package should be imported, thank you!
Hello! Thank you for the great paper and for providing your code as open source.
I have been having some difficulty reproducing the fine-tuning results from table 1 in the paper. I'm working with the ACDC dataset.
Here are the steps I have followed:
generate_acdc.py, yielding two output folders - one for labeled data, one for unlabeled.CUDA_VISIBLE_DEVICES=0 python train_supervised.py --device cuda:0 --batch_size 10 --epochs 100 --data_dir <ACDC_dir/labeled_dir> --lr 5e-5 --min_lr 5e-6 --dataset acdc --patch_size 352 352 \ --experiment_name supervised_acdc_pcl_sample_2 --initial_filter_size 48 --classes 4 --enable_few_data --sampling_k 2 --restart --pretrained_model <pretrained_model.pth>.I am trying to reproduce the table's first column, so am setting sampling_k=2.
I am getting the following validation dice results (at the end of the 100 epochs):
| Fold | Validation dice |
|---|---|
| 0 | 0.1878 |
| 1 | 0.2449 |
| 2 | 0.2729 |
| 3 | 0.1103 |
| 4 | 0.1079 |
Average validation dice = 0.185 << 0.671
Running the same experiment, but setting sampling_k=6 (i.e. the second column) I get an average validation dice = (0.6847 + 0.7170 + 0.5431 + 0.5345 + 0.640) / 5.0 = 0.624 < 0.850
I would appreciate any help or guidance! Please let me know if I am doing something wrong, or if I am interpreting my results incorrectly.
Hi,
Could you please share the HVSMR dataset? I cannot download the dataset now...
I tried to use the below script to generate the npy data. However, no npy files are generated.
python generate_acdc.py -i raw_image_dir -out_labeled save_dir_for_unlabeled_data -out_unlabeled save_dir_for_unlabeled_data
Would you please help check? Thanks.
Do you mind sharing the dataset after preprocessing? That will help a lot. : )
Thank you very much, and we will also cite your work.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.