mikelankamp / fpm Goto Github PK
View Code? Open in Web Editor NEWC++ header-only fixed-point math library
Home Page: https://mikelankamp.github.io/fpm
License: MIT License
C++ header-only fixed-point math library
Home Page: https://mikelankamp.github.io/fpm
License: MIT License































































































































fpm is very nice! Converting numeric_limits values to float is behaving unexpectedly when there are zero integral bits.
#include <cstdint>
#include <fpm/fixed.hpp>
#include <fpm/ios.hpp>
#include <iostream>
#include <iomanip>
using fixed_0_15 = fpm::fixed<std::int16_t, std::int32_t, 15>;
int main() {
auto max = std::numeric_limits<fixed_0_15>::max();
auto lowest = std::numeric_limits<fixed_0_15>::lowest();
std::cout << "fixed_0_15"
<< " max " << max
<<" lowest "<< lowest
<< std::endl;
std::cout << "static_cast<float>(fixed_0_15)"
<< " max " << static_cast<float>(max)
<<" lowest "<< static_cast<float>(lowest)
<< std::endl;
std::cout << "float(fixed_0_15)"
<< " max " << float(max)
<<" lowest "<< float(lowest)
<< std::endl;
}$ c++ -std=c++17 -Ifpm/include fpm_limits.cpp && ./a.out
fixed_0_15 max 0.999969 lowest -1
static_cast<float>(fixed_0_15) max -0.999969 lowest 1
float(fixed_0_15) max -0.999969 lowest 1
The fixed_0_15 is an attempt to model the q15 data type used in the ARM CMSIS DSP library. The trouble may be because FRACTION_MULT cannot be represented in the base type int16_t. I think FRACTION_MULT should use the IntermediateType. The tests pass with this change:
- static constexpr BaseType FRACTION_MULT = BaseType(1) << FractionBits;
+ static constexpr IntermediateType FRACTION_MULT = BaseType(1) << FractionBits;Unlike floatingspoint, overflow can occur more quickly when fixed-point operations are used. In applications such as filters or control algorithms, overflow detection would be useful.
Example
fpm::fixed_8_24 x {100}, y;
y = x * 10;
An optional switchable overflow detection would be good. At least for the basic arithmetic operations + - * /.
In the case of multiplication it might be easy to implement:
inline fixed& operator*=(const fixed& y) noexcept
{
auto value = (static_cast<IntermediateType>(m_value) * y.m_value) / (FRACTION_MULT / 2);
// Draft:
if (value < 2*std::numeric_limits<BaseType>::min() || value > 2*std::numeric_limits<BaseType>::max())
{error_reaction(…);}
m_value = static_cast<BaseType>((value / 2) + (value % 2));
return *this;
}
}Is there any interest in this? Maybe I will deal with it in the near future.
Hi Mike,
Thanks for the great library!
I faced an issue when trying to convert a fixed_16_16 number to a fixed<std::int64_t, __int128, 32>. In essence, it seems that the from_fixed_point function in fixed.hpp could not handle an increase number of bits for both the BaseType and the FractionBits jointly. I handled this by modifying the code as follows:
template <unsigned int NumFractionBits, typename T, typename std::enable_if<(NumFractionBits <= FractionBits)>::type* = nullptr>
static constexpr inline fixed from_fixed_point(T value) noexcept
{
T tmpT = T(1) << (FractionBits - NumFractionBits);
BaseType tmpBT = static_cast<BaseType>(value)*static_cast<BaseType>(tmpT);
return fixed(tmpBT, raw_construct_tag{});
}
This seems to do the trick, but I thought I'll mention it in case it may be of interest to others.
Cheers,
Mathieu
When calling the function sqrt() I stumbled across a message from my compiler:
Error: Unsupported intrinsic: llvm.ctlz.i64
Reason: the function find_highest_bit() uses intrinsic functions (for performance reasons). I use a modified gcc here which does not support intrinsic calls.
I have adapted my code as follows, possibly this would be also an option for the main branch:
By using a preprocessor switch FPM_NO_INTRINSIC you can prevent the use of intrinsic calls
and at the same time the code works on many compilers which are not supported so far.
inline long find_highest_bit(unsigned long long value) noexcept
{
assert(value != 0);
#if defined(FPM_NO_INTRINSIC) // Note: Non-optimised Version
int count = 0;
while (value >>= 1) {count ++;}
return count;
#elif defined(_MSC_VER)
unsigned long index;
#if defined(_WIN64)
_BitScanReverse64(&index, value);
#else
if (_BitScanReverse(&index, static_cast<unsigned long>(value >> 32)) != 0) {
index += 32;
} else {
_BitScanReverse(&index, static_cast<unsigned long>(value & 0xfffffffflu));
}
#endif
return index;
#elif defined(__GNUC__) || defined(__clang__)
return sizeof(value) * 8 - 1 - __builtin_clzll(value);
#else
# error "your platform does not support find_highest_bit()"
#endif
}(Admittedly, the code is slow, if necessary I can include an optimized version with bitmasks).
One question: Is there a reason why find_highest_bit() returns a datatype long instead of int?
Hi,
Before all, thanks for sharing this amazing project. I just wanted to ask for some help regarding this very particular use case I have.
// My use case
inline bool parseNumberDoubleWrapper(const char*& ptr, const char* end, double& number)
{
// Convert double to fpm fixed representation
fpm::fixed_16_16 n { number };
// Execute parsing algorithm built on top of fpm types.
bool b = parseNumber(ptr, end, n);
// Create a double from the fpm::fixed_16_16 value
// This static cast triggers fpm's function pasted below.
number = static_cast<double>(n); // <----- my problem is here
// Return parsing status
return b;
}
The static cast above is triggering this function in fpm:
// Explicit conversion to a floating-point type
template <typename T, typename std::enable_if<std::is_floating_point<T>::value>::type* = nullptr>
constexpr inline explicit operator T() const noexcept
{
return static_cast<T>(m_value) / FRACTION_MULT;
}
operator T() computes the final double using double division. Would it be possible to construct the double without relying on the double data type operations (in this case division)? I was wondering if this function could be re-written to compute the same result using n.raw_value() somehow (and not using any double operation at all).
To contextualise, my requirement is not to emit any floating point instruction at all but still be able to cast to double. Even a hacky workaround for this is useful.
Best regards,
Manuel.
C++17 introduces to_chars and from_chars, a new and improved way of converting numbers to and from text (instead of stream operators). Implement the same for fpm.
This is a very interesting project! I wonder to what extent it aims to support CPU:s with native instructions for fixed-point operations?
For instance, some machines support certain standard Q number formats, such as Q31, Q15 and Q7. There's also the notion of halving and saturating addition. My current CPU project, MRISC32, supports some of these concepts (and so do many DSP:s and SIMD ISA:s).
Other things that may be good to support are CPU instructions for count leading zeros and similar (e.g. for calculating sqrt), which is usually available via compiler intrinsics (e.g. GCC __builtin_clz).
The current docs say:
"Note: It's recommended to use a signed integer type for BaseType ... since overflow and underflow are undefined for signed integer types."
I imagine that is meant to say "unsigned" ? You don't want the undefined behavior, right?
Hi Mike and thanks for the library!
I am working with a deterministic codebase and I have question about initializing fixed-point numbers without having to resort to floats for initialization. Say I need to init a number to 0.25. I can use a float to init an fpl number like so:
fpm::fixed_16_16 b { 0.25 };
However, here we are using a float to init the value. Now, I don't know the risks of using a float for this when it comes to determinism but it would be nice to avoid floats altogether if possible. Is there a way to init an fpm number using a fraction or something? Eg, the above could be initialized like this:
fpm::fixed_16_16 b;
b.initFraction(1, 4);
Thanks!
Is there any way to do this? Thanks.
Hi,
I have the following setup:
#include <fpm/math.hpp>
using number = fpm::fixed<int64_t, __int128_t, 32>;
number x = number(50) * (number::pi() / number(100));
// x is 1.5708, really close to half pi but raw value is off by one (base type) from ::half_pi()
number cosX = cos(x);
// inside the cos->sin function we reduce x to a value of two but it is also off by one (base type) and hence returns the wrong result here.
Could this be caused by this:
static constexpr fixed pi() { return from_fixed_point<61>(7244019458077122842ll); }
I tried changing this to calculate fixed(355)/fixed(113) (approximation of pi) and use this instead and it seems to fix the issue but could the from_fixed_point function not be correctly converting between fixed point types?
Thanks,
Luis
According to https://en.cppreference.com/w/cpp/types/numeric_limits
min() and lowest() return different values for floating point types:
min():
Returns the minimum finite value representable by the numeric type T.
For floating-point types with denormalization, min() returns the minimum positive normalized value.
Note that this behavior may be unexpected, especially when compared to the behavior of min() for integral types._
fpm min() and lowest() return the same value (smallest negative number).
In my opinion, fpm min() should behave more like floating point min() here.
Is there a reason why min() is implemented this way?
Do you have benchmarks for measuring the performance of double/float against fpm? Or plan to add this.
P.S is the fpm can be automatically vectorized by the compilers
So it is not a big deal, but there is not link that I saw to get to this repo. For convenance, I suggest you add a link so peple can look at the code.
Many systems libfixmath packages: have https://repology.org/project/libfixmath/versions
Please allow to use them instead of downloading libfixmath.
since we use "fixed point", then we are much eagger to avoid "pi" in our program code.
For example, in the atan function, if x is signed and x is the lowest value, -x will be equal to x. So the function will keep calling itself and cause a stack overflow.
First of all, thank you for writing this fantastic library!
I want to suggest adding a template argument for enabling/disabling rounding operations, similar to the macro FIXMATH_NO_ROUNDING found in libfixmath. A template is better than a compiler macro because this option could be enabled/disabled for a particular type.
The rationale for adding this feature is performance, specifically on embedded processors where every CPU cycle can be precious. A quick test I ran on the Raspberry Pi RP2040 shows that changing the multiplication operation to not use rounding gives a 2x speedup. In some scenarios the saved cycles are worth the sacrifice of precision.
Rounding can be enabled by default with a default template argument to preserve backwards compatibility.
I could make a pull-request to add this feature, but I wanted to see if other people supported the feature before doing so, or if anybody had alternative suggestions.
The following code generates an error message under different clang versions, because std::round() is not a constexpr function in C++11/14.
static constexpr fpm::fixed_16_16 delta {1.234};
//error: constexpr variable 'delta' must be initialized by a constant expression
//static constexpr fpm::fixed_16_16 delta {1.234};
// ^~~~~~~~~~~~~
//.\include\fpm/fixed.hpp: note: non-constexpr function 'round' cannot be used in a constant expression
// : m_value(static_cast<BaseType>(std::round(val * FRACTION_MULT)))I suggest the following workaround: replace std::round()
// Converts an floating-point number to the fixed-point type.
// Like static_cast, this truncates bits that don't fit.
template <typename T, typename std::enable_if<std::is_floating_point<T>::value>::type* = nullptr>
constexpr inline explicit fixed(T val) noexcept
//: m_value(static_cast<BaseType>(std::round(val * FRACTION_MULT)))
: m_value(static_cast<BaseType>((val >= 0.0) ? (val * FRACTION_MULT + 0.5) : (val * FRACTION_MULT - 0.5)))
{}On Godbolt you can see the behavior (without fpm header)
https://godbolt.org/z/34cns5fnK
Advantage: This allows constants to be defined at compile time without the detour via from_fixed_point<..>....
It would be good to mention what support for different rounding modes the library supports.
One thing that annoyed me about libfixmath is that its docs just says it supports "proper" rounding, but doesn't say what kind (it's actually round-half-away-from-zero). Default for IEEE floating point is "round half to even," (if I recall correctly) though that's more annoying to implement in fixed point.
Some libraries have only one mode supported, some have it configurable; would be nice to know where this one stands.
Hi.
Thank you for this amazing class. I want to leave my feedback.
First. There are no shift operators.
template <typename I, typename std::enable_if<std::is_integral<I>::value>::type* = nullptr>
inline fixed& operator>>=(I y) noexcept
{
m_value >>= y;
return *this;
}
template <typename I, typename std::enable_if<std::is_integral<I>::value>::type* = nullptr>
inline fixed& operator<<=(I y) noexcept
{
m_value <<= y;
return *this;
}
template <typename B, typename I, unsigned int F, typename T, typename std::enable_if<std::is_integral<T>::value>::type* = nullptr>
constexpr inline fixed<B, I, F> operator>>(const fixed<B, I, F>& x, T y) noexcept
{
return fixed<B, I, F>(x) >>= y;
}
template <typename B, typename I, unsigned int F, typename T, typename std::enable_if<std::is_integral<T>::value>::type* = nullptr>
constexpr inline fixed<B, I, F> operator<<(const fixed<B, I, F>& x, T y) noexcept
{
return fixed<B, I, F>(x) <<= y;
}I spent a whole day to understand why fixed doesn't work in my case. 🤔 The problem was in this string.
const int count = static_cast<int>(sweep >> (16 - k));When you use just std::int32_t for type, this will work. But in case of fixed this doesn't return internal value. Because I save inside fixed a floating-point value, this approach is incorrect. It confuses. I am not familiar with fixed-point types. But I do not undersatnd purpose of conversion to integrals.
Correct code in my case.
const int count = (sweep >> (16 - k)).raw_value();RT
Question for your expertise for what seems to be an uncommon-but-not-rare situation:
What are the risks and limitations exactly of using the same int type for BaseType and IntermediateType?
Eg, fpm::fixed<std::int64_t, std::int64_t, 16>
I've looked into the fpm code, ran some unit tests, and otherwise messed around with the above for a while, and it seems like the above 64bit with 16 fractional bits type works pretty well. However, I'm not familiar with how the fractional portion works exactly and overall not sure what the limitations and risks of this would be (other than needing to restrict myself to some sub-range of numbers at the risk of very easy underflows and overflows).
Problem Context:
Earlier I attempted to a BaseType of int64_t and IntermediateType of boost's int128_t, but unfortunately that's far too slow for my needs (10x slower than fixed_16_16 and far higher than my performance budget as mentioned in #21). Thus, I'm looking for workarounds for my size constraints
Notably, I don't really need a very large working number range- I'm creating a game where typically one unit == 1cm (Unreal units), and as long as I get at least 2km (so 20000) for range of world units then I can easily fit all my needs.
However, that 20,000 max is before any underlying calculations. For example, one of my more problematic operations is getting a length of a vector, which involves squaring and adding 3x. Thus, at the very least my range needs to support 20000^2, and given that's above the range of fixed_16_16 and fixed_24_8, I need to go into the realm of 64bit BaseType numbers.
And now we're unfortunately back to the beginning where a BaseType of int64_t needs a size above it, and boost's int128_t is unfortunately extremely slow.
However... my numeric range isn't that large. Thus, if I drop the need for lossless operations and heavily restrict myself to a very limited range (which will definitely be error-prone but doable), then I can use the same IntermediateType as BaseType. In other words, it should be viable to use fpm::fixed<std::int64_t, std::int64_t, 16> (or something akin to it).
I've tested this (after commenting out the sizeof static assert), and after some tweaking with number of fractional bits, it's surprisingly working well. On the other hand, I'm not sure exactly what the risks and limitations are.
For example, I'd expect that I'd need a working range that fits the following:
[sqrt of range<TOTALBITS - FRACTIONALBITS>]/3
Thus, with fixed<int64_t, int64_t, 20>, I'd expect the safe numeric working range to be about...
sqrt(2^(64-20)-1)/3 = ~1,398,101.3
However, even 45000 * 45000 overflows with that fixed point type, while fixed<int64_t, int64_t, 16> does not overflow here.
All in all, I'm largely guess and checking with the limitations of this approach at the moment, and thus would greatly appreciate any insight you can provide here.
In addition, I hope this write up will also help someone in the future who faces similar issues as well. Cuz dang, this was a surprising amount of work to even get this far. Makes me hella glad this solid library exists again- yay for well-written and flexible yet easy to understand library!
A detail in index.md is not correct:
This defines a signed 16.16 fixed-point number with a range of -32768 to 65535.999985... and a resolution of 0.0000153...
The correct value should be 32767.999985.
The following test code leads to an assertion
fpm::fixed_16_16 x {fpm::fixed_16_16::from_raw_value(-2147483647 - 1) };
std::cout << x << std::endl;Message: Assertion failed!
File: fpm/ios.hpp, Line 99
Expression: value.raw >= 0
Reason in Line91: value.raw = -value.raw; not possible for INT32_MIN.
Here, the type should be std::float_denorm_style:
Line 375 in 728156d
Window's header minwindef.h define the macro min() and max().
When this file is included before fixed.hpp, this fail to compile because min/max method of numeric_limit<fixed> are refering to the windows macro as showed in the screenshot below.
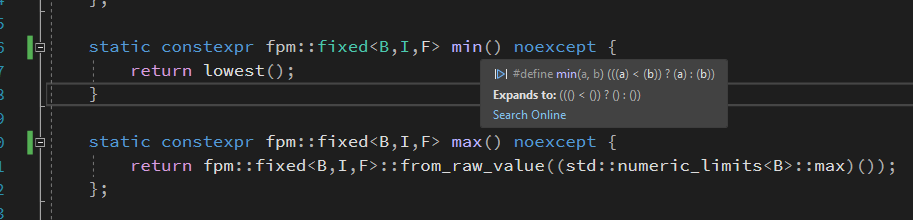
I did not look that much into the subject but it seems to be a reccurent problem for libraries that are using min/max methods and are co-existing with the windows header in an application.
The solution I use for now is the include fixed.hpp before the header that include minwindef.h.
I think, this information might be worth to be included as a note in the documentation or somewhere else.
Binary operators like:
template <typename B, typename I, unsigned int F, bool R>
constexpr inline fixed<B, I, F, R> operator+(const fixed<B, I, F, R>& x, const fixed<B, I, F, R>& y) noexcept
{
return fixed<B, I, F, R>(x) += y;
}
are defined as constexpr but the += operator is never constexpr which results in a "cannot result in a constant expression" error.
What I'm doing is to read float numbers from a JSON file, and I don't know how to read it into a fpm value.
I'm making a deterministic app, so I tried to avoid any float number when possible.
Like this one:
std::string a_number = "3.1415926";
How to convert it to a fpm value with deterministic?
Is the value returned by raw_value() the same across all platforms for a given fixed point value?
That's for serialization and sending into network and ensure portability.
I assume yes but just to be sure.
I would like to use all bits to represent fractions. For signed types this seems to work: a fpm::fixed<int8_t, int16_t, 7> gives a range of [-1, 0.992188].
This doesn't work for unsigned types however. fpm::fixed<uint8_t, uint16_t, 7> gives a range of [0, 1.99219]. A fpm::fixed<uint8_t, uint16_t, 8> would give the expected result, but this type is blocked by a static_assert.
I couldnt get a working result when I tried this
float mydivide (float x0, float y0){
fpm::fixed_16_16 x {x0};
fpm::fixed_16_16 y {x0};
fpm::fixed_16_16 z = x/y;
return static_cast<float> (z) ;
}
printf("0.65/0.4 = %f \n", mydivide(0.65, 0.4));
this returns
0.65/0.4 = 1.000000
Hi!
Thank you for your library. I want to see this library in Conan (dependency manager for C++). That's not so hard to prepare a recipe for your library, but the only one limitation for now is a lack of any release.
Can you please release your library with any version? It will be very helpful.
Thanks a lot!
Currently I'm using a fixed_32_32 via using int64_t as base type with boost::multiprecision::int128_t as the intermediate type. The one blocker to doing this is the following:
Line 26 in 8b488e3
To my understanding, this static assert fails as the boost multiprecision library uses uint8_ts under the hood (for some reason). If I comment out the static assert and run my unit tests, all my current unit tests pass.
Thus, a light assumption I'm making at the moment is that boost::multiprecision types do work as intermediate types with standard signed ints, but they are (likely) needlessly failing fpm static asserts.
Opening this issue to request some sort of workaround to support these types as an intermediate type (eg, disable signed check specifically for boost::multiprecision types or perhaps do more direct static asserts),
Is it possible to cast from e.g. fixed_8_24 to fixed_16_16 without an intermediate step via a float value?
With simple assignments "fixed2 = fixed1" the compiler reports an
>no known conversion for argument 1 from 'fpm::fixed_8_24' ... to 'const fpm::fixed<int, long long int, 16>&'
There is a function from_fixed_point(T value), but i dont understand it.
I would have expected that the value is corrected by the difference of the FractionBits between new and old datatype.
I was wondering how to use larger base types for example Q32.16 and use all the multiplication and division routines. Is there any plan to support this?
Hi everyone, as the title says, i was trying to use cpp_int defined in boost::multiprecision as base type. But when i declare a fixed point using cpp_int like this: using position = fpm::fixed<boost_int16_t, int128_t, 16>; i get some errors:
fpm/fixed.hpp:21:47: error: static assertion failed: BaseType must be an integral type
21 | static_assert(std::is_integral::value, "BaseType must be an integral type");
fpm/fixed.hpp:47:56: error: no match for 'operator*' (operand types are 'double' and 'const boost::multiprecision::number<boost::multiprecision::backends::cpp_int_backend<15, 15, boost::multiprecision::signed_magnitude, boost::multiprecision::unchecked, void> >')
47 | : m_value(static_cast(std::round(val * FRACTION_MULT)))
And some other. Do you have any suggestions?
The fpm::isnormal function returns true for every fixed point number, but the equivalent STL function returns false for std::isnormal(0.0).
https://www.cplusplus.com/reference/cmath/isnormal/
My proposed solution would be:
template <typename B, typename I, unsigned int F>
constexpr inline bool isnormal(fixed<B, I, F>) noexcept
{
return x.raw_value() != B{0};
}According to the readme fpm runs from C++11 or higher.
If the include file "include\fpm\ios.hpp" is included, the gcc compiler reports:
ios.hpp:645:68: error: use of 'auto' in lambda parameter declaration only available with -std=c++14 or -std=gnu++14
if (std::all_of(significand.begin(), significand.end(), [](auto x){ return x == 0; })) {
C++11 doesn't support generic lambdas.
Suggestion: Note in the readme that output via ostream only works from C++14 or higher.
(Or replace the lambda with a functor to be compatible with C++11)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.