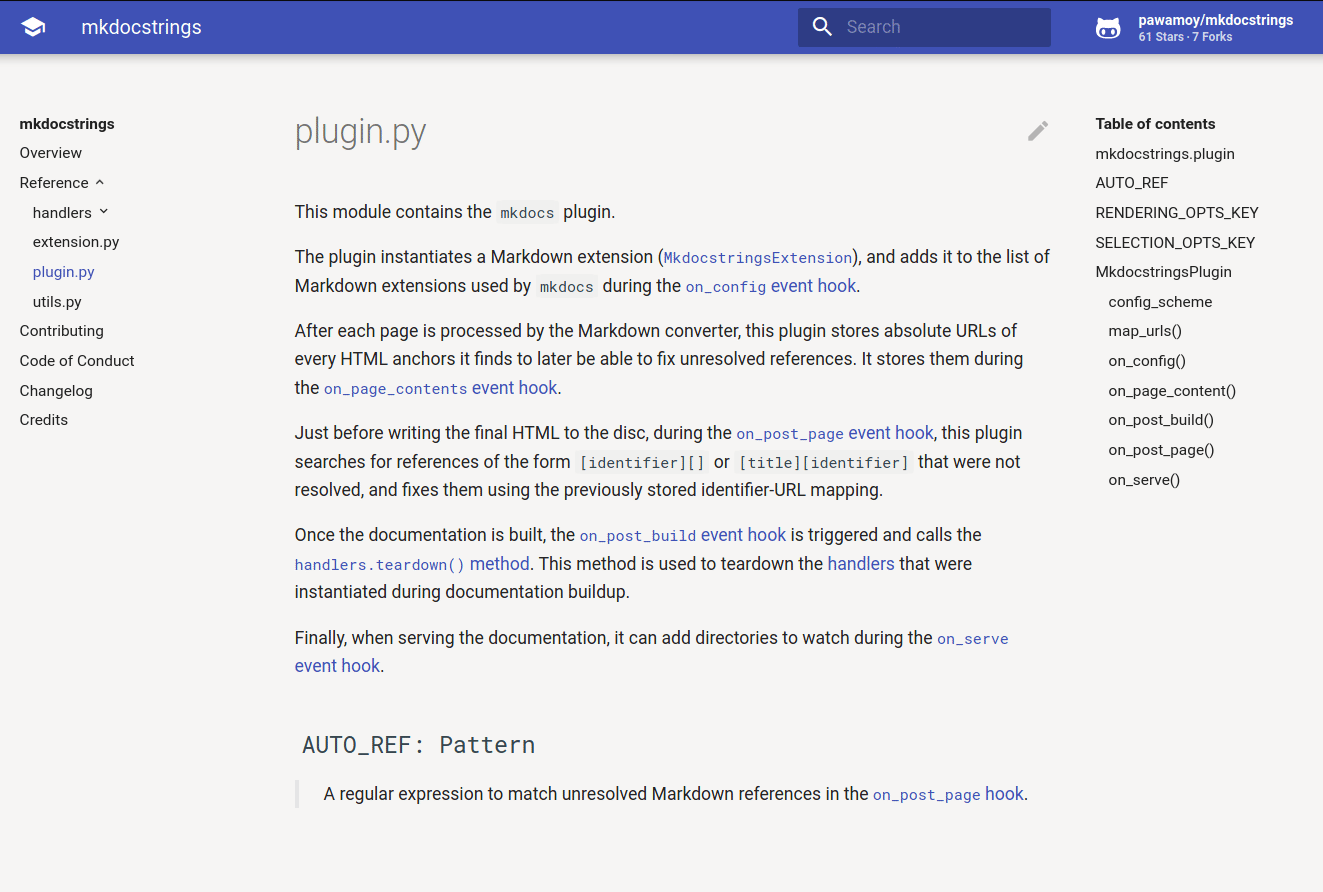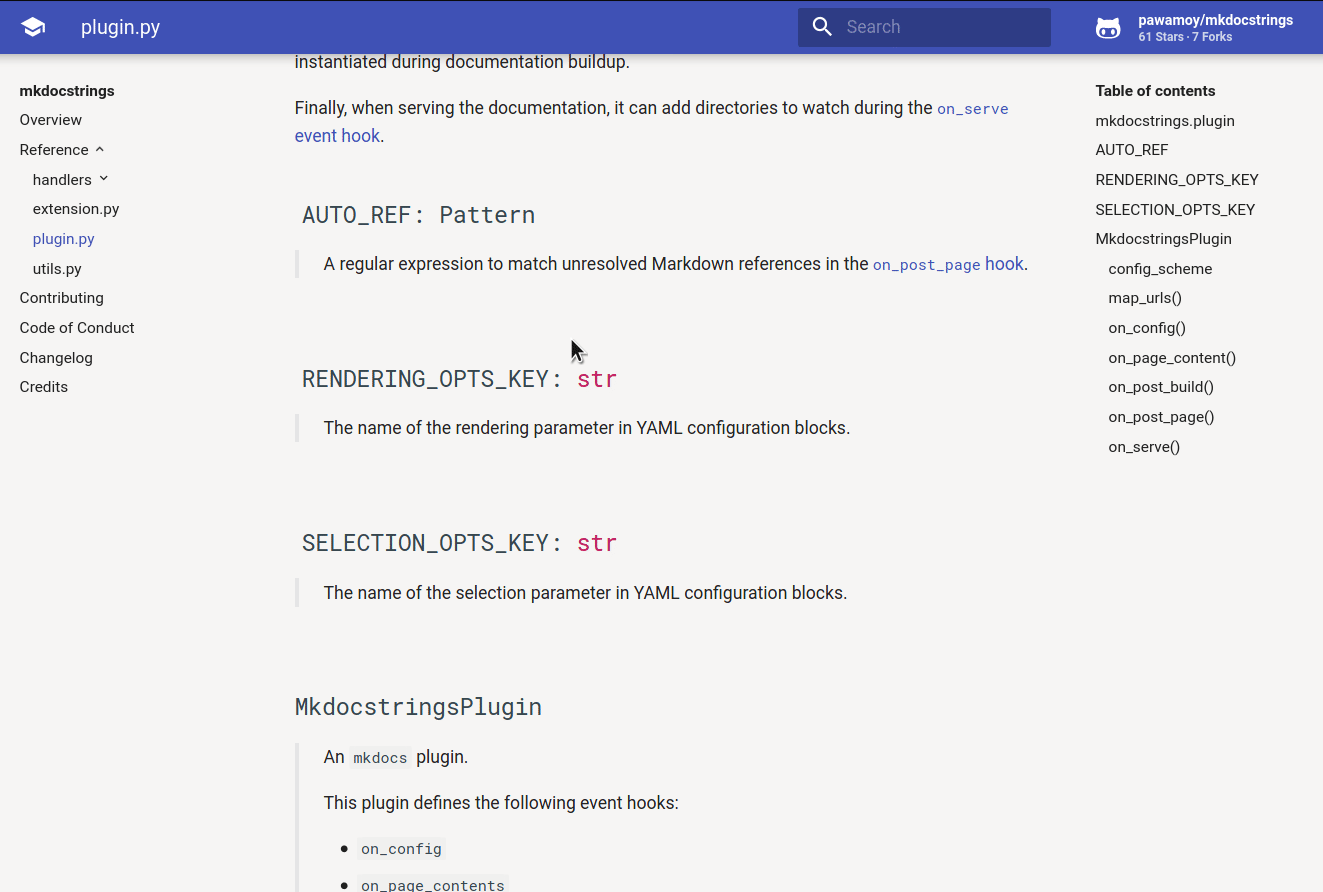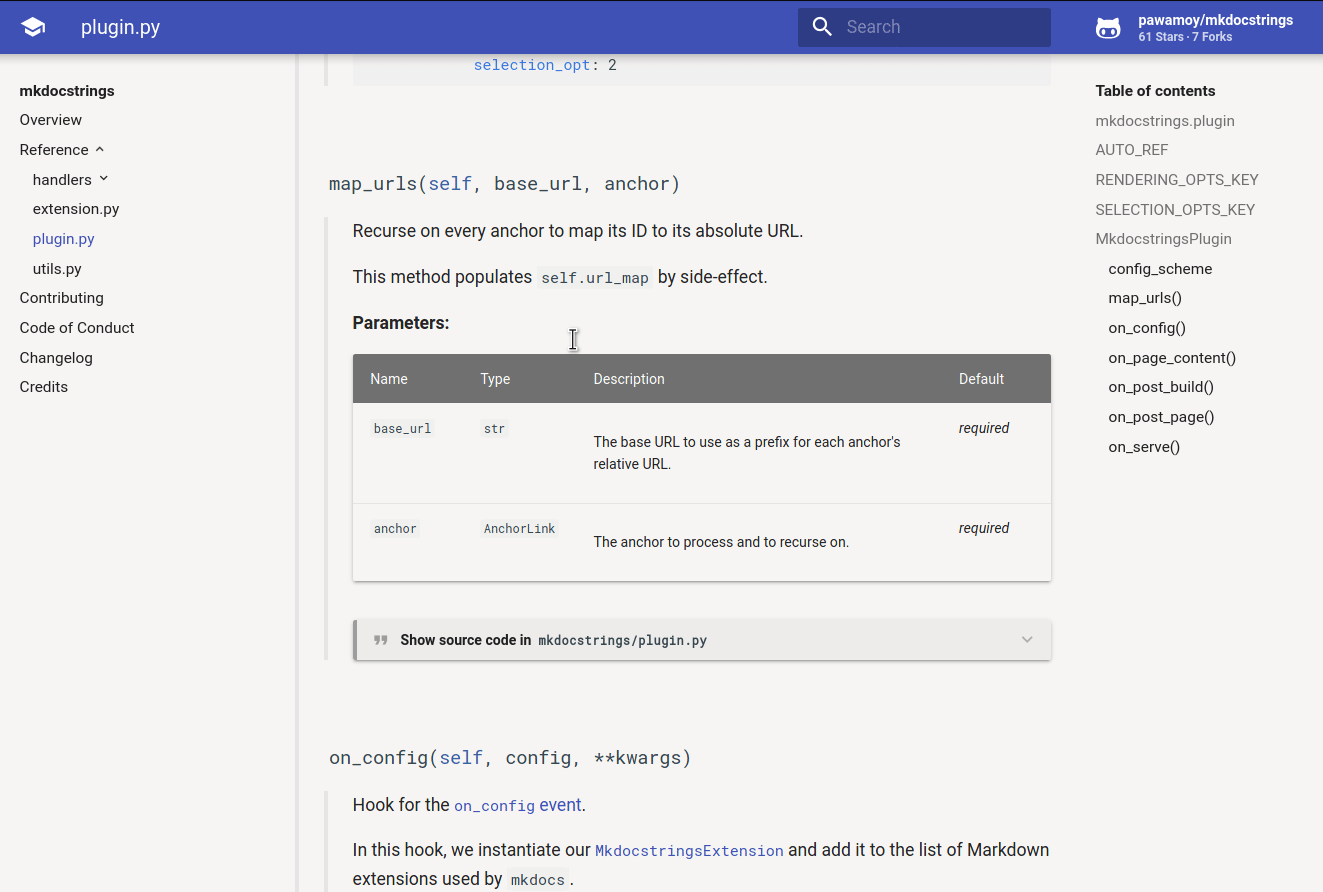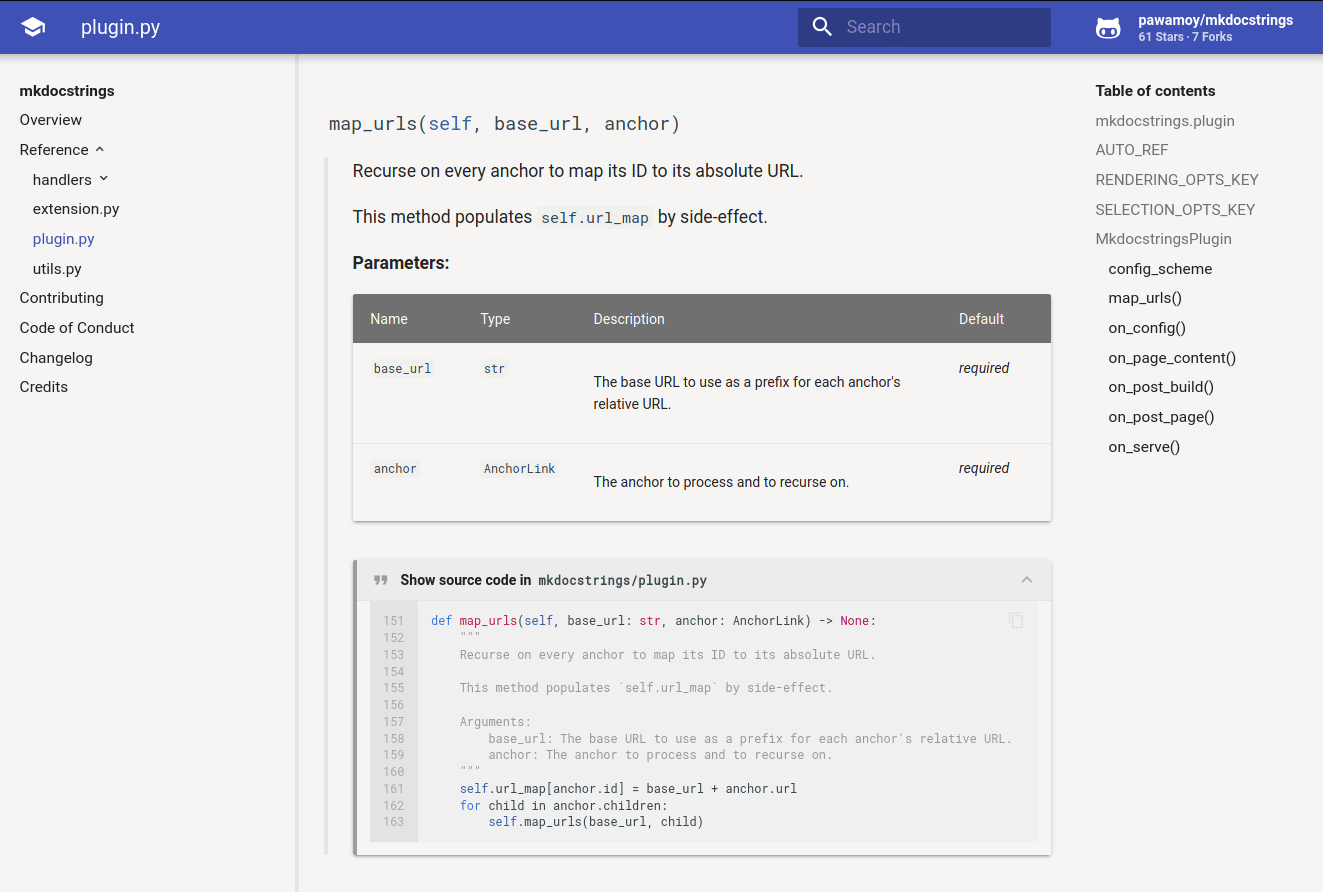
![]()



Automatic documentation from sources, for MkDocs. Come have a chat or ask questions on our Gitter channel.
Features - Installation - Quick usage
-
Language-agnostic: just like MkDocs, mkdocstrings is written in Python but is language-agnostic. It means you can use it with any programming language, as long as there is a handler for it. We currently have handlers for the C, Crystal, Python, TypeScript, and VBA languages, as well as for shell scripts/libraries. Maybe you'd like to add another one to the list? 😉
-
Multiple themes support: each handler can offer multiple themes. Currently, we offer the :star: Material theme ⭐ as well as basic support for the ReadTheDocs and MkDocs themes for the Python handler.
-
Cross-references across pages: mkdocstrings makes it possible to reference headings in other Markdown files with the classic Markdown linking syntax:
[identifier][]or[title][identifier]-- and you don't need to remember which exact page this object was on. This works for any heading that's produced by a mkdocstrings language handler, and you can opt to include any Markdown heading into the global referencing scheme.Note: in versions prior to 0.15 all Markdown headers were included, but now you need to opt in.
-
Cross-references across sites: similarly to Sphinx's intersphinx extension, mkdocstrings can reference API items from other libraries, given they provide an inventory and you load that inventory in your MkDocs configuration.
-
Inline injection in Markdown: instead of generating Markdown files, mkdocstrings allows you to inject documentation anywhere in your Markdown contents. The syntax is simple:
::: identifierfollowed by a 4-spaces indented YAML block. The identifier and YAML configuration will be passed to the appropriate handler to collect and render documentation. -
Global and local configuration: each handler can be configured globally in
mkdocs.yml, and locally for each "autodoc" instruction. -
Reasonable defaults: you should be able to just drop the plugin in your configuration and enjoy your auto-generated docs.
mkdocstrings is used by well-known companies, projects and scientific teams: Ansible, Apache, FastAPI, Google, Jitsi, Microsoft, Prefect, Pydantic, and more...
With pip:
pip install mkdocstringsYou can install support for specific languages using extras, for example:
pip install 'mkdocstrings[crystal,python]'See the available language handlers.
With conda:
conda install -c conda-forge mkdocstringsIn mkdocs.yml:
site_name: "My Library"
theme:
name: "material"
plugins:
- search
- mkdocstringsIn one of your markdown files:
# Reference
::: my_library.my_module.my_classSee the Usage section of the docs for more examples!















































































