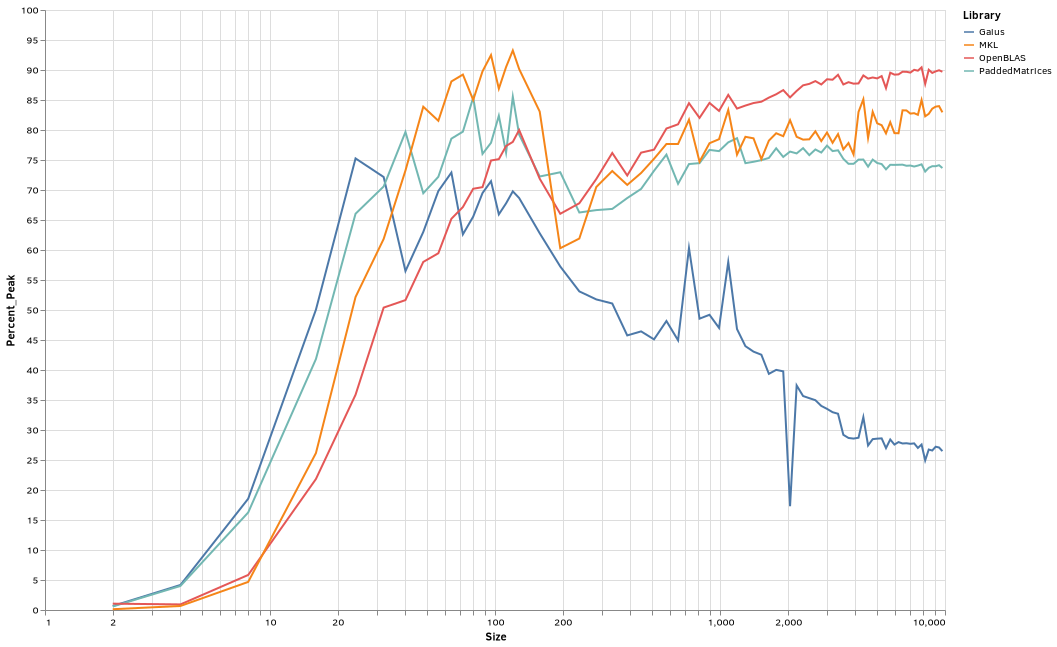
Here I wanted to talk about my experiments in PaddedMatrices.
I'd also suggest that if Gaius's performance were at least as good, I could use it and have PaddedMatrices mostly just define array types. My discussion of matmul here however will focus on Julia's base array type, rather than anything defined in PaddedMatrices -- which is why it'd make just as much sense for that code to live in a separate repo.
Although the implementation does currently make use of the PtrArray type defined in PaddedMatrices.
I'm seeing a phenomenal performance improvement by OpenBLAS on that release.
Interestingly, beyond around 200x200, OpenBLAS was now the fastest by a fairly comfortable margin.
It also looks like my implementation needs work. Aside from being slower than more OpenBLAS and MKL, it seems to slowly decline as size increases beyond 1000x1000, while OpenBLAS improves steadily and MKL sporadically.
But it's a marked improvement over Gaius on my computer -- hovering around 75% of peak CPU, while Gaius declined to barely more than a third of that by the largest tested sizes.
using Gaius, StructArrays, LinearAlgebra, BenchmarkTools
using PaddedMatrices: jmul!
BLAS.set_num_threads(1); Base.Threads.nthreads()
randa(::Type{T}, dim...) where {T} = rand(T, dim...)
randa(::Type{T}, dim...) where {T <: Signed} = rand(T(-100):T(200), dim...)
const LIBDIRECTCALLJIT = "/home/chriselrod/.julia/dev/LoopVectorization/benchmark/libdcjtest.so"
istransposed(x) = false
istransposed(x::Adjoint) = true
istransposed(x::Transpose) = true
mkl_set_num_threads(N::Integer) = ccall((:set_num_threads, LIBDIRECTCALLJIT), Cvoid, (Ref{UInt32},), Ref(N % UInt32))
function mklmul!(C::AbstractVecOrMat{Float32}, A::AbstractVecOrMat{Float32}, B::AbstractVecOrMat{Float32})
M, N = size(C); K = size(B, 1)
ccall(
(:sgemmjit, LIBDIRECTCALLJIT), Cvoid,
(Ptr{Float32},Ptr{Float32},Ptr{Float32},Ref{UInt32},Ref{UInt32},Ref{UInt32},Ref{Bool},Ref{Bool}),
parent(C), parent(A), parent(B),
Ref(M % UInt32), Ref(K % UInt32), Ref(N % UInt32),
Ref(istransposed(A)), Ref(istransposed(B))
)
end
function mklmul!(C::AbstractVecOrMat{Float64}, A::AbstractVecOrMat{Float64}, B::AbstractVecOrMat{Float64})
M, N = size(C); K = size(B, 1)
ccall(
(:dgemmjit, LIBDIRECTCALLJIT), Cvoid,
(Ptr{Float64},Ptr{Float64},Ptr{Float64},Ref{UInt32},Ref{UInt32},Ref{UInt32},Ref{Bool},Ref{Bool}),
parent(C), parent(A), parent(B),
Ref(M % UInt32), Ref(K % UInt32), Ref(N % UInt32),
Ref(istransposed(A)), Ref(istransposed(B))
)
end
mkl_set_num_threads(1)
function runbench(::Type{T}) where {T}
(StructVector ∘ map)([2, 4, 8:8:128..., round.(Int, (10:65) .^2.2)...]) do sz
n, k, m = sz, sz, sz
C1 = zeros(T, n, m)
C2 = zeros(T, n, m)
C3 = zeros(T, n, m)
C4 = zeros(T, n, m)
A = randa(T, n, k)
B = randa(T, k, m)
opb = @elapsed mul!(C1, A, B)
if 2opb < BenchmarkTools.DEFAULT_PARAMETERS.seconds
opb = min(opb, @belapsed mul!($C1, $A, $B)) #samples=100
end
lvb = @elapsed blocked_mul!(C2, A, B)
if 2lvb < BenchmarkTools.DEFAULT_PARAMETERS.seconds
lvb = min(lvb, @belapsed blocked_mul!($C2, $A, $B)) #samples=100
end
@assert C1 ≈ C2
pmb = @elapsed jmul!(C3, A, B)
if 2pmb < BenchmarkTools.DEFAULT_PARAMETERS.seconds
pmb = min(pmb, @belapsed jmul!($C3, $A, $B)) #samples=100
end
@assert C1 ≈ C3
if T <: Integer
@show (matrix_size=sz, lvBLAS=lvb, OpenBLAS=opb, PaddedMatrices = pmb)
else
mklb = @elapsed mklmul!(C4, A, B)
if 2mklb < BenchmarkTools.DEFAULT_PARAMETERS.seconds
mklb = min(mklb, @belapsed mklmul!($C4, $A, $B)) #samples=100
end
@assert C1 ≈ C4
@show (matrix_size=sz, lvBLAS=lvb, OpenBLAS=opb, PaddedMatrices = pmb, MKL = mklb)
end
end
end
tf64 = runbench(Float64);
tf32 = runbench(Float32);
ti64 = runbench(Int64);
ti32 = runbench(Int32);
gflops(sz, st) = 2e-9 * sz^3 /st
using VectorizationBase: REGISTER_SIZE, FMA3
# I don't know how to query GHz;
# Your best bet would be to check your bios
# Alternatives are to look up your CPU model or `watch -n1 "cat /proc/cpuinfo | grep MHz"`
# Boosts and avx downclocking complicate it.
const GHz = 4.1
const W64 = REGISTER_SIZE ÷ sizeof(Float64) # vector width
const FMA_RATIO = FMA3 ? 2 : 1
const INSTR_PER_CLOCK = 2 # I don't know how to query this, but true for most recent CPUs
const PEAK_DGFLOPS = GHz * W64 * FMA_RATIO * INSTR_PER_CLOCK
using DataFrames, VegaLite
function create_df(res)
df = DataFrame(
Size = res.matrix_size,
Gaius = res.lvBLAS,
PaddedMatrices = res.PaddedMatrices,
OpenBLAS = res.OpenBLAS,
MKL = res.MKL
);
dfs = stack(df, [:Gaius, :PaddedMatrices, :OpenBLAS, :MKL], variable_name = :Library, value_name = :Time);
dfs.GFLOPS = gflops.(dfs.Size, dfs.Time);
dfs.Percent_Peak = 100 .* dfs.GFLOPS ./ PEAK_DGFLOPS;
dfs
end
res = create_df(tf64)
plt = res |> @vlplot(
:line, color = :Library,
x = {:Size, scale={type=:log}}, y = {:Percent_Peak},#, scale={type=:log}},
width = 900, height = 600
)
save(joinpath(PICTURES, "gemmf64.png"), plt)It could use some work on threading. It eventually hung -> crashed on interrupt, which is a known issue with multi threading on Julia master.
julia> tf64 = runbench(Float64);
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 2, lvBLAS = 2.3133534136546185e-8, OpenBLAS = 1.61001001001001e-8, PaddedMatrices = 2.432831325301205e-8, MKL = 9.716261879619851e-8)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 4, lvBLAS = 2.709547738693467e-8, OpenBLAS = 1.1704939626783753e-7, PaddedMatrices = 2.841608040201005e-8, MKL = 1.4730528846153845e-7)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 8, lvBLAS = 4.726619433198381e-8, OpenBLAS = 1.4663221153846155e-7, PaddedMatrices = 5.7628687690742625e-8, MKL = 1.6828853754940714e-7)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 16, lvBLAS = 1.292370203160271e-7, OpenBLAS = 2.966718146718147e-7, PaddedMatrices = 1.4987575392038602e-7, MKL = 2.406112469437653e-7)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 24, lvBLAS = 2.877228464419476e-7, OpenBLAS = 5.840718232044199e-7, PaddedMatrices = 3.277236842105263e-7, MKL = 4.06315e-7)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 32, lvBLAS = 6.516871165644171e-7, OpenBLAS = 1.0868e-6, PaddedMatrices = 7.048827586206896e-7, MKL = 8.12183908045977e-7)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 40, lvBLAS = 5.594e-6, OpenBLAS = 1.9357e-6, PaddedMatrices = 1.2344e-6, MKL = 1.3357e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 48, lvBLAS = 6.238e-6, OpenBLAS = 2.9292222222222223e-6, PaddedMatrices = 2.477444444444444e-6, MKL = 2.0276666666666667e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 56, lvBLAS = 5.435e-6, OpenBLAS = 4.584571428571428e-6, PaddedMatrices = 3.721e-6, MKL = 3.086625e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 64, lvBLAS = 5.819e-6, OpenBLAS = 6.3324e-6, PaddedMatrices = 5.145333333333333e-6, MKL = 3.002e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 72, lvBLAS = 1.8404e-5, OpenBLAS = 1.1107e-5, PaddedMatrices = 7.32275e-6, MKL = 3.200625e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 80, lvBLAS = 2.0688e-5, OpenBLAS = 2.1968e-5, PaddedMatrices = 9.406e-6, MKL = 3.353125e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 88, lvBLAS = 1.9789e-5, OpenBLAS = 2.0916e-5, PaddedMatrices = 1.3432e-5, MKL = 3.8824285714285714e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 96, lvBLAS = 1.8742e-5, OpenBLAS = 2.2784e-5, PaddedMatrices = 1.7908e-5, MKL = 4.099428571428571e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 104, lvBLAS = 2.8341e-5, OpenBLAS = 2.3449e-5, PaddedMatrices = 2.0834e-5, MKL = 4.346714285714285e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 112, lvBLAS = 2.9761e-5, OpenBLAS = 2.3784e-5, PaddedMatrices = 2.5557e-5, MKL = 4.823285714285715e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 120, lvBLAS = 3.4951e-5, OpenBLAS = 2.3948e-5, PaddedMatrices = 3.3876e-5, MKL = 4.676857142857143e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 128, lvBLAS = 3.4679e-5, OpenBLAS = 2.4699e-5, PaddedMatrices = 4.0365e-5, MKL = 5.17e-6)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 158, lvBLAS = 4.6798e-5, OpenBLAS = 5.6155e-5, PaddedMatrices = 8.2639e-5, MKL = 1.0184e-5)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 195, lvBLAS = 6.4276e-5, OpenBLAS = 6.7389e-5, PaddedMatrices = 0.000157312, MKL = 1.3662e-5)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 237, lvBLAS = 0.000102349, OpenBLAS = 8.5743e-5, PaddedMatrices = 0.000276445, MKL = 2.4355e-5)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 282, lvBLAS = 0.000129655, OpenBLAS = 9.3392e-5, PaddedMatrices = 0.000390776, MKL = 3.1123e-5)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 332, lvBLAS = 0.000178715, OpenBLAS = 0.000143093, PaddedMatrices = 0.00061251, MKL = 4.6239e-5)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 387, lvBLAS = 0.000251371, OpenBLAS = 0.000233954, PaddedMatrices = 0.000880218, MKL = 8.6194e-5)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 446, lvBLAS = 0.000341801, OpenBLAS = 0.000334483, PaddedMatrices = 0.001141395, MKL = 0.000148388)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 509, lvBLAS = 0.000471455, OpenBLAS = 0.000403684, PaddedMatrices = 0.001459838, MKL = 0.000218345)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 578, lvBLAS = 0.000601629, OpenBLAS = 0.000588513, PaddedMatrices = 0.00173781, MKL = 0.000281904)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 651, lvBLAS = 0.000865018, OpenBLAS = 0.000740441, PaddedMatrices = 0.002665009, MKL = 0.000396309)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 728, lvBLAS = 0.000850863, OpenBLAS = 0.000860389, PaddedMatrices = 0.003238482, MKL = 0.000501772)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 811, lvBLAS = 0.001391089, OpenBLAS = 0.001634212, PaddedMatrices = 0.00392088, MKL = 0.000721424)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 898, lvBLAS = 0.001917808, OpenBLAS = 0.001884708, PaddedMatrices = 0.004728201, MKL = 0.000931751)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 990, lvBLAS = 0.002527852, OpenBLAS = 0.002173313, PaddedMatrices = 0.005980197, MKL = 0.001318157)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 1088, lvBLAS = 0.003033522, OpenBLAS = 0.00255263, PaddedMatrices = 0.00694296, MKL = 0.001701482)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 1190, lvBLAS = 0.004519446, OpenBLAS = 0.003599941, PaddedMatrices = 0.008287474, MKL = 0.002416439)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 1297, lvBLAS = 0.005846859, OpenBLAS = 0.004166108, PaddedMatrices = 0.010642048, MKL = 0.002729079)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 1409, lvBLAS = 0.007676825, OpenBLAS = 0.005031821, PaddedMatrices = 0.012124711, MKL = 0.003461087)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 1527, lvBLAS = 0.009942827, OpenBLAS = 0.006043474, PaddedMatrices = 0.014811819, MKL = 0.004338835)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 1649, lvBLAS = 0.01252906, OpenBLAS = 0.007397781, PaddedMatrices = 0.016704083, MKL = 0.005259515)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 1777, lvBLAS = 0.015304498, OpenBLAS = 0.008571394, PaddedMatrices = 0.019045784, MKL = 0.006528608)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 1910, lvBLAS = 0.019378427, OpenBLAS = 0.009448816, PaddedMatrices = 0.022792723, MKL = 0.008063704)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 2048, lvBLAS = 0.051137142, OpenBLAS = 0.010611481, PaddedMatrices = 0.025143273, MKL = 0.010806103)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 2191, lvBLAS = 0.030902612, OpenBLAS = 0.013496804, PaddedMatrices = 0.030446266, MKL = 0.011869482)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 2340, lvBLAS = 0.040938443, OpenBLAS = 0.015844881, PaddedMatrices = 0.033634225, MKL = 0.015386527)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 2494, lvBLAS = 0.047911804, OpenBLAS = 0.018747578, PaddedMatrices = 0.040595921, MKL = 0.018101961)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 2654, lvBLAS = 0.058224365, OpenBLAS = 0.022381999, PaddedMatrices = 0.044077997, MKL = 0.020562614)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 2819, lvBLAS = 0.073470818, OpenBLAS = 0.027041187, PaddedMatrices = 0.050594931, MKL = 0.025797043)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 2989, lvBLAS = 0.090583819, OpenBLAS = 0.030988165, PaddedMatrices = 0.056894353, MKL = 0.030153094)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 3165, lvBLAS = 0.10973272, OpenBLAS = 0.037257813, PaddedMatrices = 0.067711555, MKL = 0.03372817)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 3346, lvBLAS = 0.13072293, OpenBLAS = 0.042420543, PaddedMatrices = 0.078059161, MKL = 0.037653038)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 3533, lvBLAS = 0.171608963, OpenBLAS = 0.053996652, PaddedMatrices = 0.084271564, MKL = 0.047052213)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 3725, lvBLAS = 0.212338202, OpenBLAS = 0.063929694, PaddedMatrices = 0.126757958, MKL = 0.054310823)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 3923, lvBLAS = 0.247940048, OpenBLAS = 0.074915892, PaddedMatrices = 0.158934426, MKL = 0.063976922)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 4127, lvBLAS = 0.295284462, OpenBLAS = 0.085741933, PaddedMatrices = 0.175556075, MKL = 0.070077551)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 4336, lvBLAS = 0.315173005, OpenBLAS = 0.095162078, PaddedMatrices = 0.196636965, MKL = 0.08202249)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 4551, lvBLAS = 0.426154178, OpenBLAS = 0.108096275, PaddedMatrices = 0.221490565, MKL = 0.100128825)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 4771, lvBLAS = 0.452505485, OpenBLAS = 0.124190155, PaddedMatrices = 0.245447973, MKL = 0.105866294)
(matrix_size = sz, lvBLAS = lvb, OpenBLAS = opb, PaddedMatrices = pmb, MKL = mklb) = (matrix_size = 4997, lvBLAS = 0.504627015, OpenBLAS = 0.146173103, PaddedMatrices = 0.277543906, MKL = 0.125505135)
^Cfatal: error thrown and no exception handler available.
InterruptException()
jl_mutex_unlock at /home/chriselrod/Documents/languages/julia-old/src/locks.h:143 [inlined]
jl_task_get_next at /home/chriselrod/Documents/languages/julia-old/src/partr.c:441
poptaskref at ./task.jl:702
wait at ./task.jl:709 [inlined]
task_done_hook at ./task.jl:444
jl_apply at /home/chriselrod/Documents/languages/julia-old/src/julia.h:1687 [inlined]
jl_finish_task at /home/chriselrod/Documents/languages/julia-old/src/task.c:198
start_task at /home/chriselrod/Documents/languages/julia-old/src/task.c:697
unknown function (ip: (nil))
So OpenBLAS and MKL were both close 88% at this point.
PaddedMatrices was at just under half the theoretical peak, and Gaius was at about 14%.
A lot of room for improvement in both cases.
PaddedMatrices is very slow to start using threads. In the copy and paste from when the benchmarks were running, Gaius was faster until 2191 x 2191 matrices, where they were equally fast, but by 4997 x 4997, PaddedMatrices was approaching twice as fast, and at 9737 it was three times faster -- but still far behind OpenBLAS and MKL.
MKL did very well with multi-threading, even at relatively small sizes.
jmult! could be modified to ramp up thread use more intelligently.
I've also compiled BLIS, so I'll add it to future benchmarks as well.
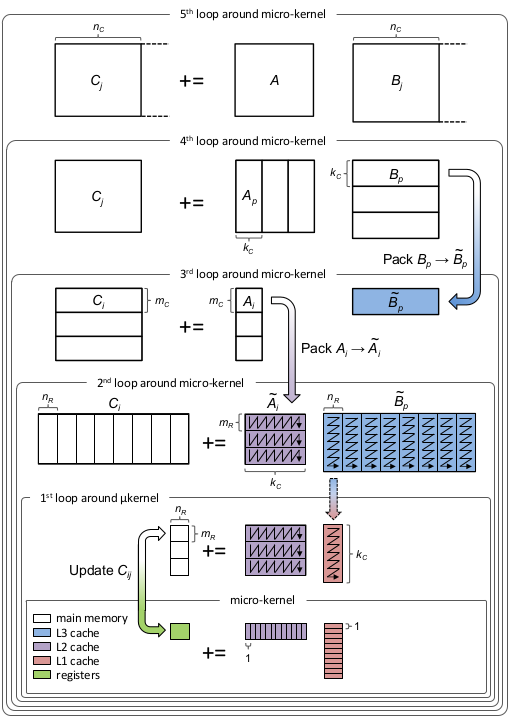
The above BLIS loop link also talks about threading. BLIS threads any of the loops aside from the k loop (I don't think you can multi-thread that one). 'PaddedMatrices.jmult!' threads both the 3rd and 5th. However, rather than threading in a smart way (i.e., in a manner reflecting the total number of threads), it spawns a new task for per iteration. When there are a lot of iterations, that's an excessive number of high-overhead tasks.
On the otherhand, the outer most loop takes steps of size 600 on my computer -- which also means it takes a long time before it uses many threads at all.
Would you be in favor of replacing the name-sake recursive implementation with this nested loop-based GEMM implementation?