R implementation of Uniform Manifold Approximation and Projection
![]()
Uniform manifold approximation and projection (UMAP) is a technique for dimensional reduction. The original algorithm is described by McInnes, Heyes, and Melville and is implemented in a python package umap. This package provides an interface to the UMAP algorithm in R, including a translation of the original algorithm into R with minimal dependencies.
The figure below shows dimensional reduction on the MNIST digits dataset. This dataset consists of 70,000 observations in a 784-dimensional space and labeled by ten distinct classes. The output of this package's `umap' function provides the plot layout, i.e. the arrangement of dots on the plane. The coloring, added to visualize how the known labels are positioned within the layout, demonstrates separation of the underlying data groups.
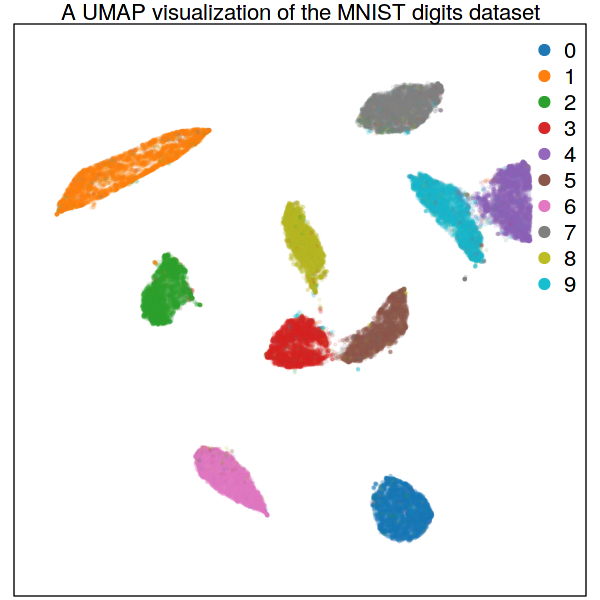
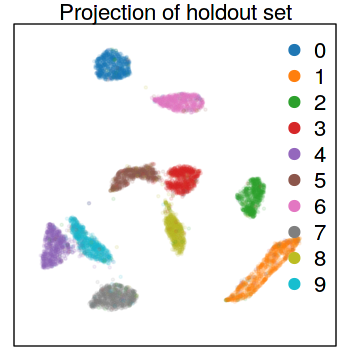
The package also allows to project data onto an existing embedding. Below, the first figure shows a map created from a subset of 60,000 observations from the MNIST data. The second figure is a projection of the held-out 10,000 observations onto the layout defined by the training data.

More information on usage can be found in the package vignettes.
The package provides two implementations of the UMAP algorithm.
The default implementation is one written in R and Rcpp. This implementation follows the original python code. However, any bugs or errors should be regarded as arising solely from this implementation, not from the original. The implementation has minimal dependencies and should work on most platforms. (The MNIST graphic is generated based on this default implementation).
A second implementation is a wrapper for the python package. This offers similar functionality to another existing package umapr. To use this implementation, additional installation steps are required; see documentation for the python package for details.
Note: an independent R implementation of UMAP is also available in package uwot, also available on CRAN.
Many thanks to the R and github communities for comments, corrections, and bug reports.
The original UMAP algorithm is described in the following article
McInnes, Leland, and John Healy. "UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction." arXiv:1802.03426.
MIT License.










































































































