yeslogic / fathom Goto Github PK
View Code? Open in Web Editor NEW🚧 (Alpha stage software) A declarative data definition language for formally specifying binary data formats. 🚧
License: Apache License 2.0
🚧 (Alpha stage software) A declarative data definition language for formally specifying binary data formats. 🚧
License: Apache License 2.0
Would be more consistent to use:
Array(u16be, 34)
Instead of:
[u16be; 34]
This requires us to allow values in type abstractions and applications though.
At the moment our concrete syntax is highly coupled to the syntax we use for type checking and our proofs. It might make sense to separate these to allow for cleaner proofs and type checking, and allow us to add new features without altering the core language too much.
For example, PADS/ML has DDC:


The tricky thing is doing this in such a way that preserves good error messages (see #2).
Currently the array constructor has this type:
Array : {0..} -> Type -> Type
index (len:nat) (t:Type) : Array len t -> {0..<len} -> t
However at some point we may need something like this:
Array (len:{0..}) : ({0..<len} -> Type) -> Type
index (len:nat) (f:{0..<len} -> Type) (i:{0..<len}) : Array len f -> f i
Crazy stuff, but it allows us to create arrays of fixed-size offsets to things of different types. There may be an easier way to do this, though. :)
Currently the output in my tests looks like:
---- edid stdout ----
thread 'edid' panicked at 'called `Result::unwrap()` on an `Err` value: UnboundType(Span { lo: BytePos(142), hi: BytePos(148) }, "Header")', src/libcore/result.rs:860:4
note: Run with `RUST_BACKTRACE=1` for a backtrace.
It would be cool to have really nice error output. I've got some utility functions started in src/source.rs that might help map the byte positions and spans to source locations, but I haven't yet actually started a proper error message formatter.
Here are some examples of what the output might look like:



calc.lalrpop:6:5: 6:34: Ambiguous grammar detected
The following symbols can be reduced in two ways:
Expr "*" Expr "*" Expr
They could be reduced like so:
Expr "*" Expr "*" Expr
├─Expr──────┘ │
└─Expr───────────────┘
Alternatively, they could be reduced like so:
Expr "*" Expr "*" Expr
│ └─Expr──────┤
└─Expr───────────────┘
Hint: This looks like a precedence error related to `Expr`. See the LALRPOP
manual for advice on encoding precedence.
These will allow us to add computed fields.
An example of this shows up in the EDID format where the default gamma is stored in the gamma_mod field as a u8. This is then converted to the actual gamma using the following calculation: (gamma_mod + 100) as f32 - 100.0f32.
I propose the following syntax:
binary-type ::=
...
"compute" host-type "from" host-expr
This would then allow us to define DisplayParams as:
DisplayParams = struct {
input_flags: u8,
screen_size_h: u8,
screen_size_v: u8,
gamma_mod: u8,
gamma: compute f32 from (gamma_mod + 100) as f32 - 100.0f32,
features_flags: u8,
};
We could alternatively use the following syntax for defining computed types:
binary-type ::=
...
"compute" host-expr ":" host-type
This is closer to IPADS, but it means that the type is all the way at the end. Thoughts?
#16 got rid of the spans from the AST, but these are important for error reporting. We should add these back!
Some possibilities:
Curried style (like ML and Haskell):
MyArray a = struct {
len : u32,
data : [a; len],
};
MyArrayU8 = MyArray u8;
Tupled style:
MyArray(T) = struct {
len : u32,
data : [T; len],
};
MyArrayU8 = MyArray(u8);
I'm thinking I might go with the first one for now seeing as it's more in line with the underlying syntax I have right now.
I split Pikelet up into subcrates (see pikelet-lang/pikelet#172), and it seems to work nicely! Would be nice to reflect this change in the DDL.
The pretty crate is a good starting point for this.
As noted in #83 (comment), codegen is currently broken on more complex examples such as:
MyArray(T) = struct {
len : u16le,
data : [T; len],
};
Foo(T, U, V) = struct {
blah : [U; 32u16],
rlen : u32be,
data : MyArray(struct {
// NOTE: capture of type parameter, T
l : T,
// NOTE: capture of type parameter, V
// NOTE: capture of field value, rlen
r : [V; rlen],
}),
};
The resulting codegen is:
// auto-generated: "ddl 0.1.0"
extern crate ddl_util;
use self::ddl_util::FromBinary;
use std::io;
use std::io::prelude::*;
#[derive(Debug, Clone)]
pub struct MyArray<T> {
pub len: u16,
pub data: Vec<T>,
}
impl<T> FromBinary for MyArray<T> where
T: FromBinary,
{
fn from_binary<R: Read>(reader: &mut R) -> io::Result<MyArray<T>> {
let len = ddl_util::from_u16le(reader)?;
let data = ddl_util::from_array(0..len, || T::from_binary(reader))?;
Ok::<_, io::Error>(MyArray {
len: len,
data: data,
})
}
}
#[derive(Debug, Clone)]
pub struct MyArrayArg0 {
pub l: T,
pub r: Vec<V>,
}
#[derive(Debug, Clone)]
pub struct Foo<T, U, V> {
pub blah: Vec<U>,
pub rlen: u32,
pub data: MyArray<MyArrayArg0>,
}
impl<T, U, V> FromBinary for Foo<T, U, V> where
T: FromBinary,
U: FromBinary,
V: FromBinary,
{
fn from_binary<R: Read>(reader: &mut R) -> io::Result<Foo<T, U, V>> {
let blah = ddl_util::from_array(0..32u16, || U::from_binary(reader))?;
let rlen = ddl_util::from_u32be(reader)?;
let data = MyArray::from_binary(reader)?;
Ok::<_, io::Error>(Foo {
blah: blah,
rlen: rlen,
data: data,
})
}
}Note that the type parameters have not been propagated to MyArrayArg0, nor is there any FromBinary impl for that type. I'm thinking I might merge this PR for now and make a new issue for fixing this. There is no way of passing the dependent field's data to the struct either, which suggests that even without value parameters on types (see #81) we still need a context parameter on FromBinary::from_binary (see #81 (comment)).
A quick survey turns up the following crates:
Or we could roll our own.
Would be nice to use one that enforces the lifetime of symbols by using lifetime parameters.
For example:
Array(T) = struct {
len: u32,
data: [T; len],
}
Should create:
pub struct Array<T> {
pub len: u32,
pub data: Vec<T>,
}in the generated Rust code.
Some ideas for syntax sugar we might like to add later.
It would be handy to be able to pun field names in where/as types when the name is going to be repeated several times. In extreme cases it might be handy to be able to avoid mentioning the name at all, for example:
field: u16 where field: field == 0
field: u16 where field == 0
field: u16 == 0
[struct { ... very long definition ... }; length]
bit nasty.
It would be nice to generate an on-demand parser that stores a reference to the current parse state, allowing one to read parts of a file without having to load the entire thing.
At the moment we use a parser combinator IR for the owned, eager parser, but perhaps another IR would be better for this purpose.
At the moment the generated code is not tested against rustc. We should fix this! Perhaps also have sample projects set up using cargo, so that folks know how to do it in their own projects.
I've been trying to add tests as I go, but we should add a .travis.yml and once this repo is public, hook it up to the repo for testing. Then we can start to have a more regular PR-driven workflow where we only merge if the build is green.
.travis.ymlI'm thinking it might be neat to have some sort of 'built-in' HasRepr type class thing (naming up for 🚲 🏠 ing). This would allow us to constrain type parameters to things that are able to be encoded/decoded:
Compute : {A B : Type} {{HasRepr A}} -> (Repr A -> B) -> Type;
Reserved : (A : Type) {{HasRepr A}} -> Repr A -> Type;
We would have the following instancey things:
impl HasRepr U8;
impl HasRepr U16Le;
impl HasRepr U32Le;
impl HasRepr U64Le;
impl HasRepr U16Be;
impl HasRepr U32Be;
impl HasRepr U64Be;
impl HasRepr S8;
impl HasRepr S16Le;
impl HasRepr S32Le;
impl HasRepr S64Le;
impl HasRepr S16Be;
impl HasRepr S32Be;
impl HasRepr S64Be;
impl HasRepr F32Le;
impl HasRepr F64Le;
impl HasRepr F32Be;
impl HasRepr F64Be;
impl {A : Type} {len : int {0..}} {{HasRepr A}} HasRepr (Array len A); // ??
// something for structs...?
At the moment our arithmetic expression syntax is very rich, combining the following:
-x, x + y, x - y, x * y, x / y!x, x << y, x >> y, x & y, x | y, x ^ yI'm still a bit unclear as to how thos will interact with the other features of the language, like array sizes and pointer offsets. Do we want to think about overflow and overflow as well?
We could use something like mdbook for this, which is what other Rust libraries use for documentation. It has support for MathJax, which could be very handy for an appendix on the theoretical underpinnings of the language.
At some point we're going to encounter constraints that aren't part of the type of any individual value, like this example:
x: U16BE,
y: U16BE,
where x + y < 100
In some cases these can be reformulated into individual types, but this can make their expression less straightforward and is not always possible.
Nevertheless, we should probably avoid diving headlong into constraint solvers until we have some very compelling motivating examples.
// Dumps the entire contents of the module to the top level
import prelude (..);
// adds the `ObjectId` type to the top level
import bson (ObjectId);
// allows for the access of `foo.Bar
import foo;
At the moment we won't try to do any module directory traversal. For now we'll require folks to add modules manually:
let bson = Module::from_parse(bson_src.parse()?)?;
let foo = Module::from_parse(foo_src.parse()?)?;
let my_module = Module::from_parse(my_module_src.parse()?)?;
// Create a program with the default prelude
let program = ProgramBuilder::default()
.add_module("bson", bson)
.add_module("foo", foo)
.add_module("my_module", my_module)
.finish()?; // Correctly binds any remaining free variables and checks for cyclic dependencies#40 converted bound variables to have both a scope and a binding indices. This should allow us to move forward on adding mutual recursion for top level definitions. The side-effect of this is that we'll be able to write our data-definitions in a top-down style, which is easier to read.
Important reading is the final part of The Locally Nameless Representation.
Start by adding a pointer type:
ptr : bintype -> type
We have these functions for working with pointers:
deref {T} : ptr T -> T
offset {S T} : ptr S -> nat -> ptr T
(Option 1) Labels
A binary type for "labels" that matches the empty sequence of zero bytes and returns a host value of type ptr(unit) representing the current position in the buffer.
For example, placing a label field at the start of a struct can be used to capture its base address to be used to resolve subsequent offset fields in the struct into pointers that can be dereferenced.
(Option 2) Addr of self
A pseudofunction addr() which can be used in expressions and returns the address of the current field with type ptr T where T is the binary type of the current field. This can be used to implement labels but I don't think it is any more expressive in practice.
(Option 3) Addr of fields
A pseudofunction addr(field) which returns the address of the specified field. More convenient but no more expressive.
"DDL" is kind of.... boring. And it seems that the file extension is already taken, on Github at least!
At the moment we use a mix of Boxed and unboxed node types throughout the codebase. Perhaps we could instead use Rc for this. We could also implement ToOwned and to allow us to use Cow semantics in some places… 🤔
Currently I'm attempting to record the typing rules in the check module. It might pay however to define the semantics in a tool that is better suited for the job, especially something that will allow us to eventually more rigorously define correctness proofs.
We might need some simple type inference at the expression level. For example when numeric suffixes are left off, or for empty array literals, variant introduction, etc.
External DSLs have a considerable degree of cost associated with them, but they also give a great deal of flexibility regarding possible compilation targets. Here are some ideas:
This will allow us to use them to generate rustdoc comments during codegen
When doing code-gen for most of our back-ends (currently Rust and Graphvis), we will need to fully-name our structs before doing code-generation. So nested structs will need their own names, preferably with a nice naming scheme derived from whatever parent type they were nested in.
This is important for being able to cleanly express magic number fields in structs. For example:
Header = struct {
/// Fixed header pattern
magic: [u8; 8u32] where x => x == [0x00u8, 0xffu8, 0xffu8, 0xffu8, 0xffu8, 0xffu8, 0xffu8, 0x00u8],
...
}
At the moment I'm trying to compile the AST directly into Rust source code (see #6). Here is an example of my terrible flailing about.
@mikeday mentioned at one of our meetings that it might make sense to do a transformation to a more imperative IR before we start code-gen. Not sure what that would look like though. Things get kind of hairy once you start needing to schedule constraints, and compile iterators, etc.
Based on some confusion I had today in #29, I think Type::Cond and binary.type.cond should be renamed to Type::Assert and binary.type.assert respectively. This ensures that it is obvious that these result in a parse failure if the predicate returns false, as opposed to 'condition' that implies that a type is optional.
This would allow us to make a VS Code extension, along with allowing for the creation of editors that also support the LSP.
This would allow us to pass values as type parameters.
For example, the htmx table requires:
HorizontalMetrics(num_glyphs : u16, number_of_h_metrics : u16) = struct {
/// Paired advance width and left side bearing values for each glyph.
/// Records are indexed by glyph ID.
h_metrics : [LongHorMetric; number_of_h_metrics],
/// Left side bearings for glyph IDs greater than or equal to `number_of_h_metrics`.
left_side_bearings : [i16be; num_glyphs - number_of_h_metrics],
};
LongHorMetric = struct {
/// Advance width, in font design units.
advance_width : u16be,
/// Glyph left side bearing, in font design units.
lsb : i16be,
};
Proposed syntax:
TypeParam ::=
Ident -- Type parameter
Ident ":" HostType -- Value parameter
TypeDefinition ::=
Ident "=" Type
Ident "(" TypeParam* ")" "=" Type
Tricky thing would be disambiguating type params vs values during application, eg. Array(T, len) - are len and T types or values? Dependently typed languages solve this by merging their type and value syntaxes and having more complicated type system semantics. 1ML solves this by requiring you to explicitly disambiguate type variables using the type keyword.
I'm guessing during compilation we would partition the parameter lists by universe, moving the value parameters to runtime values on the stack.
The DDL is currently based off Pikelet, which is very structural when it comes to type definitions. I'm thinking that it will be easier for us to switch the DDL to use nominal type definitions however. This has a number of advantages:
fold and unfold operations (we can hide these in the constructors)The downside is that sometimes it's convenient not to have to name types. But I don't find that argument super convincing given the constraints we have for the DDL. I'll leave that experimentation for Pikelet!
At some stage during the process of lowering our AST to the Rust we will need to uncurry both type and function applications, similar to how BuckleScript does it when compiling to Javascript. Another option would be to have types and functions uncurried from the start. This would cause our syntax and semantics to diverge from the language formalism more, but might be easier to deal with in the end.
We want users to be able to say that the field of a struct must be aligned on a 2-, 4-, or 8-byte boundary. This could be implemented dynamically by simply rounding up the current pointer to the next alignment boundary. However, as with array bounds checks, it would be nice to know at compile time that this isn't necessary because the field will always be aligned, and perhaps to warn the user if it's not known at compile time.
Similarly, if a field is not explicitly required to be aligned, we might be able to generate better code if we know that reads will always be aligned in practice.
To perform these alignment checks it is sufficient to accumulate the size of a struct in mod 8 arithmetic. The difficulty is that sizes may be variable, and we will thus need to prove that a field is appropriately aligned for all possible substitutions. We could do this exhaustively, since there are only 8 possible values for each variable, but that would only be feasible for about four variables.
So we need to look at sizeof a bit more abstractly. An expression representing the size of a type can be constructed as follows:
Since a complete solution is probably intractable we need to draw a somewhat arbitrary line as to how far the analysis goes. So we have a trade-off: we want something effective for proving alignment as much as possible but that is also easy to explain to users.
I would like to propose that we perform the following analysis:
k1 * x^2 + k2 * x * y + k3 * x + k4 where x and y are variables and k1 .. k4 are the coefficients. Note that we are interested in the size in mod 8, so we can replace any coefficient with its value in mod 8. In particular, if any coefficient, or indeed any of its factors, is a multiple of 8 then the value in mod 8 is zero, so the entire term can be discarded. As a corollary, any field can be left out of this analysis if its type has a total size that has already been determined to have the necessary alignment.If all of the coefficients are multiples of n then the polynomial must also be a multiple of n, so the inference in rule 4 is sound. It is not complete, however: x^2 + x is always even, although we would not infer this.
This proposal doesn't cover conditional types. Again, we can deal with these by exhaustively checking all possibilities, but it would eventually become intractable. We could recursively analyse each branch, then take the minimum alignment of the two sides as the alignment of the whole, but I'm not sure this is the best idea either. For example, if a struct has two u8 fields then a conditional that is either two bytes or six bytes, should we be able to conclude that the next field is 4-aligned?
It can be useful to do a bit of look-ahead when parsing. One way would be to add a lookahead constructor that binds a parsed value as usual, but then resets the input position back to where it was at the start. This would be similar to an intersection type, in that the binary data overlaps with that of the following type, but there would be no requirement that the two types have the same end-point.
For example:
struct A {
data0: lookahead(...)
data: ...
}
The advantage of this is that the type of data can depend on the values read in for data0.
One use case would be in parsing the OpenType GSUB table (see #28). This table has offsets to other tables which contain indices into each other. In order to get the correct bounds for these indices, we can look-ahead at the tables just enough to read their length, then start again and read the tables, in any order, checking bounds on index values as we go.
This method works even if there are cyclic dependencies between the tables concerned. E.g., if there are two tables and the correctness of each table depends on the size of the other.
OpenType has lots of union types! We should have a nice way of describing them.
At the moment build scripts look like this:
extern crate ddl;
use std::env;
use std::fs::File;
use std::io::prelude::*;
use std::str::FromStr;
use ddl::syntax::ast::Program;
fn main() {
let src = {
let mut src_file = File::open("src/edid.ddl").unwrap();
let mut src = String::new();
src_file.read_to_string(&mut src).unwrap();
src
};
let mut program = Program::from_str(&src).unwrap();
program.substitute(&ddl::syntax::ast::base_defs());
ddl::syntax::check::check_program(&program).unwrap();
let ir = ddl::ir::ast::Program::from(&program);
let out_dir = env::var("OUT_DIR").unwrap();
let mut file = File::create(out_dir + "/edid.rs").unwrap();
write!(file, "{}", ddl::codegen::LowerProgram(&ir)).unwrap();
}Blegh!
Would be nice to have a cleaner API for working with the compiler, especially for build scripts.
Some formats require being able to be parametric over endianness. For example, exif:
Exif = struct {
endianness : u16le =
| 0x4949
| 0x4d4d
,
body : Body(
match endianness {
0x4949 -> Le,
0x4d4d -> Be,
}
),
};
Body(e : Endianness) = struct {
version : u16(e),
...
};
Kaitai Struct handles this by having two separate definitions for the big endian and little endian forms, but they recognise that this is a bit of a hack.
I kind of feel like that this hints at a more fundamental representation of the base integer types that might be useful to figure out... 🤔
Host expressions should have include a cast expression to allow for explicit casts between numeric types. These should be in the form:
host-expr ::=
...
host-expr "as" host-type
Example:
struct {
width: u32le,
height: u8,
data: [u8; width * height as u32],
}
Expr typeas in Rust. Might be harder to maintain consistent semantics across other languages though. 🤔Based on our discussion today about offsets and slices:
Add a binary type for slices that takes a length, the binary type that it should be parsed as, and some optional flags. A slice occupies the same space as [u8; len] but will be parsed as a different binary type. The optional flags can specify whether this binary type must occupy the entire slice or whether there can be trailing bytes left over, and whether links from within the slice can go outside of it. Parsing an entire file can then be considered equivalent to parsing a self-contained slice of the same size.
A label or address type is a zero-length binary type which evaluates to the host value of the current address. An address value can be used as the base address of an offset to create a link.
A link type is a zero-length binary type which takes an address and another binary type to parse at that address. This other binary type can potentially be a slice, so you could have:
offset: u32,
length: u32,
table: link(make_address(base, offset), slice(length, table_type(tag), SelfContained))
Assuming that table_type is a type-level function that maps tag values to binary types, make_address is an expression-level function that combines an address with an integer to make a new address, and SelfContained is a flag indicating that links within this slice cannot go outside it.
In order to start making our push to go end-to-end via Allsorts, we need a backend for generating Rust code. This will probably be similar to how LALRPOP does it, but I would like to generate more readable code than it does.
The unsafe slices branch shows what a resulting decoder might look like note that this is a very simple case however, and we will need to do more trickery in cases where we have anonymous structs, unions, and have unknown-sized types in the middle of structs.
Currently we have the following types:
Pos : Type; // opaque type that refers to a position in a stream
OffsetPos : Pos -> int {0..} -> Type -> Type;OffsetPos (which might be renamed to Link) queues a position to be parsed later on. These queued positions are then added to a HashMap later. This is fine, but at the moment we have no way to allow binary data to depend on data located elsewhere via a Pos. This would require that we be able to dereference data at a Pos. This could be problematic because it could lead to infinite loops without some form of dynamic or static checks.
More discussion of the problems surrounding this can be found at #28.
struct Test {
start : Pos,
len_offset : U16Be,
len : Link start len_offset U32Be,
data : Array (deref len) U8,
}
LALRPOP has support for error recovery (see code example). We should make use of this!
This would help to improve our error messages (see #2), and also give us better support for interactive editing (see #35).
Match types allow for branching based on previously parsed data.
For example:
const TRIANGLE : u32 = 0u32;
const RECTANGLE : u32 = 1u32;
const CIRCLE : u32 = 2u32;
ShapeType = union {
triangle : u32be where x : u32 => x == TRIANGLE,
rectangle : u32be where x : u32 => x == RECTANGLE,
circle : u32be where x : u32 => x == CIRCLE,
};
Point = {
x: f32be,
y: f32be,
};
Data = struct {
shape_type : ShapeType,
length: u32be,
data : [match shape_type {
TRIANGLE => [Point; 3],
RECTANGLE => [Point; 4],
CIRCLE => struct { center: Point, radius: f32be },
}; length],
};
Offset32 = u32be;
MyStruct = {
offset: Offset32;
}
Will try cause the following rustc error:
error[E0599]: no function or associated item named `read` found for type `u32` in the current scope
--> /Users/brendan/...
|
480 | let offset = Offset32::read(reader)?;
| ^^^^^^^^^^^^^^ function or associated item not found in `u32`
|
= note: the method `read` exists but the following trait bounds were not satisfied:
`&mut u32 : std::io::Read`
We might need to keep track of a context during compilation to allow us to lookup whether a type is an alias or something else, and what that alias points to...
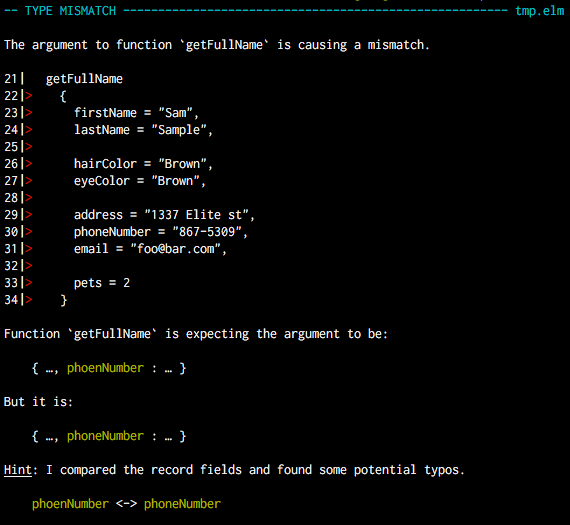
The motivating example is how to type check this record:
record {
len: U16BE,
data: Array len U8
}
given that U16BE is a binary type, different from the host integer type that the Array constructor expects:
Array : {0..} -> Type -> Type
This is an instance of the more general question of when and how to convert binary types into host types during type checking and evaluation.
Assume we have a function that maps the primitive binary types to suitable host types:
host : Type -> Type
host U8 = {0..<2^8}
host U16BE = {0..<2^16}
host U16LE = {0..<2^16}
We can extend it to fold over type constructors:
host (Array n t) = Array n (host t)
host (Record {...}) = Record {...host applied to all of its fields...}
host (Cond e t1 t2) = Cond e (host t1) (host t2)
Finally it is the identity function for every other type:
host t = t otherwise
We can assume the existence of a related function that acts similarly on values:
host_value (t: Type) : t -> host t
There are several ways we can apply this type relation during type checking and evaluation, but they all seem to produce the same result.
If we apply the host function to the problematic record type it becomes much more reasonable:
record {
len: {0..<2^16},
data: Array len {0..<2^8}
}
This is indeed the type of the record we expect to receive after parsing is finished and it type checks successfully, but is type checking the converted type sufficient to ensure the validity of the original type? Also there is an awkward chicken and egg problem if we require the input to the host function to be a valid type, as that means we have to type check it before conversion, suggesting that the host function is more of a macro-style rewrite rule that operates on untyped terms.
Instead of converting the whole type in one go before type checking, apply the host function to every identifier that is looked up from the environment during type checking. This should be equivalent to converting the whole type, but interleaving the conversion with type checking allows it to only be applied to subterms which have already been type checked.
Introduce the host type conversion into the dependent pair / record construction, so that instead of being {x:t, T(x)} it becomes {x:t, T(host_value t x)}. This may be a sounder theoretical basis than converting on lookup, even if it is identical in practice.
Introduce the host type conversion by rewriting expressions, so that the problematic record type becomes:
record {
len: U16BE,
data: Array (host_value U16BE len) U8
}
If this inserts a call to host_value on every field reference then it seems equivalent to all of the preceding suggestions, but may be slightly less convenient to implement.
A different strategy would be to add the host type conversion to the subtype relation:
t ≤ host t
This would solve the example problem, but perhaps it would have different implications to the approaches given above, depending on how subtyping can be used.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.