

A library for differentiable nonlinear optimization
Paper • Blog • Webpage • Tutorials • Docs
Theseus is an efficient application-agnostic library for building custom nonlinear optimization layers in PyTorch to support constructing various problems in robotics and vision as end-to-end differentiable architectures.
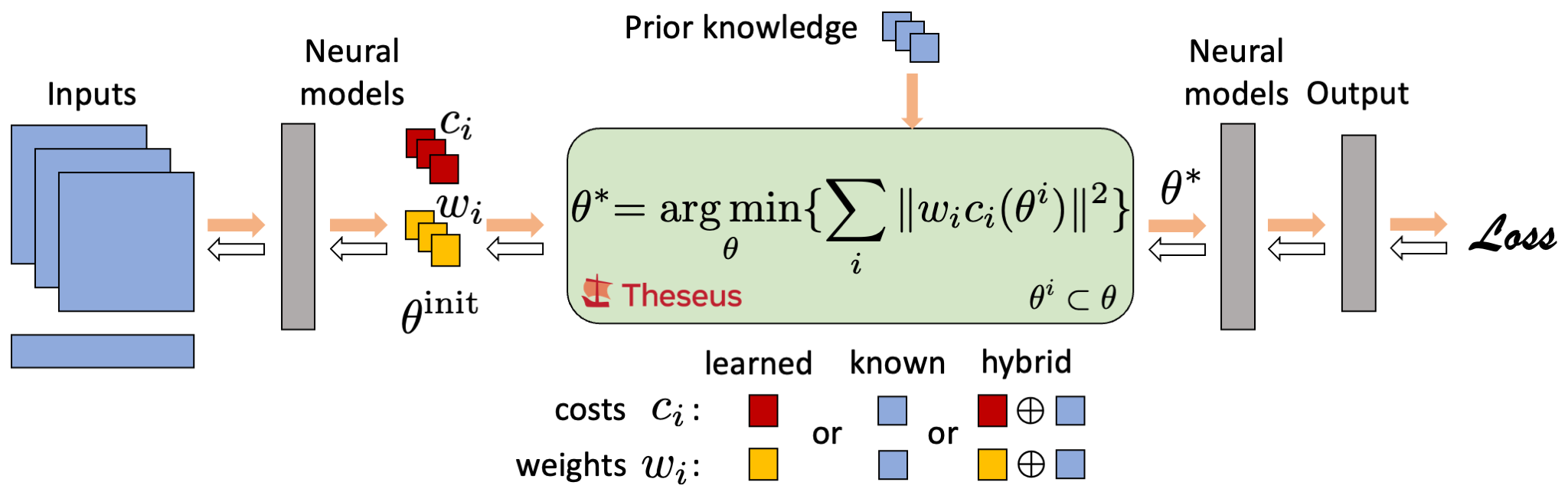
Differentiable nonlinear optimization provides a general scheme to encode inductive priors, as the objective function can be partly parameterized by neural models and partly with expert domain-specific differentiable models. The ability to compute gradients end-to-end is retained by differentiating through the optimizer which allows neural models to train on the final task loss, while also taking advantage of priors captured by the optimizer.
Our implementation provides an easy to use interface to build custom optimization layers and plug them into any neural architecture. Following differentiable features are currently available:
- Second-order nonlinear optimizers
- Gauss-Newton (GN), Levenberg–Marquardt (LM), Trust Region, Dogleg
- Other nonlinear optimizers
- Cross Entropy Method (CEM)
- Linear solvers
- Dense: Cholesky, LU; Sparse: CHOLMOD, LU (GPU-only), BaSpaCho
- Commonly used costs, AutoDiffCostFunction, RobustCostFunction
- Lie groups based on torchlie
- Robot kinematics based on torchkin
We support several features that improve computation times and memory consumption:
- Sparse linear solvers
- Batching and GPU acceleration
- Automatic vectorization
- Backward modes
- We strongly recommend you install Theseus in a venv or conda environment with Python 3.8-3.10.
- Theseus requires
torchinstallation. To install for your particular CPU/CUDA configuration, follow the instructions in the PyTorch website. - For GPU support, Theseus requires nvcc to compile custom CUDA operations. Make sure it matches the version used to compile pytorch with
nvcc --version. If not, install it and ensure its location is on your system's$PATHvariable. - Theseus also requires
suitesparse, which you can install via:sudo apt-get install libsuitesparse-dev(Ubuntu).conda install -c conda-forge suitesparse(Mac).
-
pypi
pip install theseus-ai
We currently provide wheels with our CUDA extensions compiled using CUDA 11.6 and Python 3.10. For other CUDA versions, consider installing from source or using our build script.
Note that
pypiinstallation doesn't include our experimental Theseus Labs. For this, please install from source. -
The simplest way to install Theseus from source is by running the following (see further below to also include BaSpaCho)
git clone https://github.com/facebookresearch/theseus.git && cd theseus pip install -e .
If you are interested in contributing to Theseus, instead install
pip install -e ".[dev]" pre-commit installand follow the more detailed instructions in CONTRIBUTING.
-
Installing BaSpaCho extensions from source
By default, installing from source doesn't include our BaSpaCho sparse solver extension. For this, follow these steps:
-
Compile BaSpaCho from source following instructions here. We recommend using flags
-DBLA_STATIC=ON -DBUILD_SHARED_LIBS=OFF. -
Run
git clone https://github.com/facebookresearch/theseus.git && cd theseus BASPACHO_ROOT_DIR=<path/to/root/baspacho/dir> pip install -e .
where the BaSpaCho root dir must have the binaries in the subdirectory
build.
-
python -m pytest testsBy default, unit tests include tests for our CUDA extensions. You can add the option -m "not cudaext"
to skip them when installing without CUDA support. Additionally, the tests for sparse solver BaSpaCho are automatically
skipped when its extlib is not compiled.
Simple example. This example is fitting the curve Objective with a single CostFunction that computes the residual Objective and the GaussNewton optimizer are encapsulated into a TheseusLayer. With Adam and MSE loss, TheseusLayer.
import torch
import theseus as th
x_true, y_true, v_true = read_data() # shapes (1, N), (1, N), (1, 1)
x = th.Variable(torch.randn_like(x_true), name="x")
y = th.Variable(y_true, name="y")
v = th.Vector(1, name="v") # a manifold subclass of Variable for optim_vars
def error_fn(optim_vars, aux_vars): # returns y - v * exp(x)
x, y = aux_vars
return y.tensor - optim_vars[0].tensor * torch.exp(x.tensor)
objective = th.Objective()
cost_function = th.AutoDiffCostFunction(
[v], error_fn, y_true.shape[1], aux_vars=[x, y],
cost_weight=th.ScaleCostWeight(1.0))
objective.add(cost_function)
layer = th.TheseusLayer(th.GaussNewton(objective, max_iterations=10))
phi = torch.nn.Parameter(x_true + 0.1 * torch.ones_like(x_true))
outer_optimizer = torch.optim.Adam([phi], lr=0.001)
for epoch in range(10):
solution, info = layer.forward(
input_tensors={"x": phi.clone(), "v": torch.ones(1, 1)},
optimizer_kwargs={"backward_mode": "implicit"})
outer_loss = torch.nn.functional.mse_loss(solution["v"], v_true)
outer_loss.backward()
outer_optimizer.step()See tutorials, and robotics and vision examples to learn about the API and usage.
If you use Theseus in your work, please cite the paper with the BibTeX below.
@article{pineda2022theseus,
title = {{Theseus: A Library for Differentiable Nonlinear Optimization}},
author = {Luis Pineda and Taosha Fan and Maurizio Monge and Shobha Venkataraman and Paloma Sodhi and Ricky TQ Chen and Joseph Ortiz and Daniel DeTone and Austin Wang and Stuart Anderson and Jing Dong and Brandon Amos and Mustafa Mukadam},
journal = {Advances in Neural Information Processing Systems},
year = {2022}
}Theseus is MIT licensed. See the LICENSE for details.
- Join the community on Github Discussions for questions and sugesstions.
- Use Github Issues for bugs and features.
- See CONTRIBUTING if interested in helping out.
Theseus is made possible by the following contributors:
Made with contrib.rocks.




























































































































































